Verwenden der Apache Hive-Replikation in Azure HDInsight-Clustern
Im Zusammenhang mit Datenbanken und Warehouses ist die Replikation der Prozess der Duplizierung von Entitäten von einem Warehouse zu einem anderen. Die Duplizierung kann sich auf eine gesamte Datenbank oder auf eine kleinere Ebene, z. B. eine Tabelle oder Partition, beziehen. Das Ziel ist es, über ein Replikat zu verfügen, das sich immer dann ändert, wenn sich die Basisentität ändert. Die Replikation auf Apache Hive konzentriert sich auf die Notfallwiederherstellung und bietet eine unidirektionale Replikation der primären Kopie. In HDInsight-Clustern kann mithilfe von Hive Replication eine unidirektionale Replikation des Hive-Metastors und des zugehörigen zugrunde liegenden Data Lakes auf Azure Data Lake Storage Gen2 durchgeführt werden.
Hive Replication hat sich im Laufe der Jahre weiterentwickelt, wobei neuere Versionen eine bessere Funktionalität bieten und schneller sowie weniger ressourcenintensiv sind. In diesem Artikel wird auf Hive Replication (Replv2) eingegangen, das sowohl in Clustertypen von HDInsight 3.6 als auch HDInsight 4.0 unterstützt wird.
Vorteile von replv2
Hive ReplicationV2 (auch Replv2 genannt) bietet die folgenden Vorteile gegenüber der ersten Version der Hive-Replikation, welche die Hive-Befehle IMPORT und EXPORT verwendet hat:
- Ereignisbasierte inkrementelle Replikation
- Zeitpunktreplikation
- Reduzierte Bandbreitenanforderungen
- Verringerung der Anzahl von Zwischenkopien
- Replikationsstatus wird beibehalten
- Eingeschränkte Replikation
- Unterstützung für ein Hub-and-Spoke-Modell
- Unterstützung für ACID-Tabellen (in HDInsight 4.0)
Replikationsphasen
Die ereignisbasierte Hive-Replikation wird zwischen den primären und sekundären Clustern konfiguriert. Diese Replikation besteht aus zwei verschiedenen Phasen: dem Bootstrapping und den inkrementellen Ausführungen.
Bootstrapping
Das Bootstrapping soll einmal ausgeführt werden, um den Basiszustand der Datenbanken vom primären zum sekundären Cluster zu replizieren. Sie können das Bootstrapping bei Bedarf so konfigurieren, dass es eine Teilmenge der Tabellen in der Zieldatenbank einbezieht, für die die Replikation aktiviert werden muss.
Inkrementelle Ausführungen
Nach dem Bootstrapping werden inkrementelle Ausführungen auf dem primären Cluster automatisiert, und die während dieser inkrementellen Ausführungen erzeugten Ereignisse werden auf dem sekundären Cluster wiedergegeben. Wenn der sekundäre Cluster mit dem primären Cluster gleichzieht, wird der sekundäre Cluster mit den Ereignissen des primären Clusters konsistent.
Replikationsbefehle
Hive bietet eine Reihe von REPL-Befehlen – DUMP, LOAD und STATUS – zur Orchestrierung des Ereignisflusses. Der Befehl DUMP erzeugt ein lokales Protokoll aller DDL/DML-Ereignisse auf dem primären Cluster. Der Befehl LOAD ist ein Ansatz, um Metadaten und Daten, die in der Ausgabe der extrahierten Replikationssicherung protokolliert wurden, verzögert zu kopieren und er wird auf dem Zielcluster ausgeführt. Der Befehl STATUS wird vom Zielcluster aus ausgeführt, um die letzte Ereignis-ID anzugeben, dass die letzte Replikationslast erfolgreich repliziert wurde.
Festlegen der Replikationsquelle
Bevor Sie mit der Replikation beginnen, stellen Sie sicher, dass die zu replizierende Datenbank als Replikationsquelle festgelegt ist. Sie könnten den Befehl DESC DATABASE EXTENDED <db_name> verwenden, um festzustellen, ob der Parameter repl.source.for auf den Namen der Richtlinie festgelegt ist.
Wenn die Richtlinie geplant und der Parameter repl.source.for nicht festgelegt ist, müssen Sie diesen Parameter zunächst mithilfe von ALTER DATABASE <db_name> SET DBPROPERTIES ('repl.source.for'='<policy_name>') festlegen.
ALTER DATABASE tpcds_orc SET DBPROPERTIES ('repl.source.for'='replpolicy1')
Sichern von Metadaten in Data Lake
Der Befehl REPL DUMP [database name]. => location / event_id wird in der Bootstrap-Phase verwendet, um relevante Metadaten in Azure Data Lake Storage Gen2 zu sichern. Die event_id gibt das minimale Ereignis an, bis zu dem relevante Metadaten in Azure Data Lake Storage Gen2 abgelegt wurden.
repl dump tpcds_orc;
Beispielausgabe:
| dump_dir | last_repl_id |
|---|---|
| /tmp/hive/repl/38896729-67d5-41b2-90dc-46eeed4c5dd0 | 2925 |
Laden von Daten in den Zielcluster
Mit dem Befehl REPL LOAD [database name] FROM [ location ] { WITH ( ‘key1’=‘value1’{, ‘key2’=‘value2’} ) } werden Daten sowohl für die Bootstrap- als auch für die inkrementellen Phasen der Replikation in den Zielcluster geladen. Der [database name] kann derselbe wie für die Quelle oder ein anderer Name auf dem Zielcluster sein. Der [location] stellt den Speicherort aus der Ausgabe eines früheren REPL DUMP-Befehls dar. Das bedeutet, dass der Zielcluster in der Lage sein sollte, mit dem Quellcluster zu kommunizieren. Die WITH-Klausel wurde in erster Linie hinzugefügt, um einen Neustart des Zielclusters zu verhindern und eine Replikation zu ermöglichen.
repl load tpcds_orc from '/tmp/hive/repl/38896729-67d5-41b2-90dc-46eeed4c5dd0';
Ausgabe der zuletzt replizierten Ereignis-ID
Der Befehl REPL STATUS [database name] wird auf Zielclustern ausgeführt und gibt die letzte replizierte event_id aus. Der Befehl ermöglicht es den Benutzern auch zu wissen, in welchen Zustand ihr Zielcluster repliziert wurde. Sie können die Ausgabe dieses Befehls verwenden, um den nächsten REPL DUMP-Befehl für die inkrementelle Replikation zu konstruieren.
repl status tpcds_orc;
Beispielausgabe:
| last_repl_id |
|---|
| 2925 |
Sichern relevanter Daten und Metadaten im Data Lake
Der Befehl REPL DUMP [database name] FROM [event-id] { TO [event-id] } { LIMIT [number of events] } dient dazu, relevante Metadaten und Daten in Azure Data Lake Storage zu sichern. Dieser Befehl wird in der inkrementellen Phase verwendet und wird im Quellwarehouse ausgeführt. FROM [event-id] ist für die inkrementelle Phase erforderlich, und der Wert von event-id kann durch Ausführen des Befehls REPL STATUS [database name] für das Zielwarehouse abgeleitet werden.
repl dump tpcds_orc from 2925;
Beispielausgabe:
| dump_dir | last_repl_id |
|---|---|
| /tmp/hive/repl/38896729-67d5-41b2-90dc-466466agadd0 | 2960 |
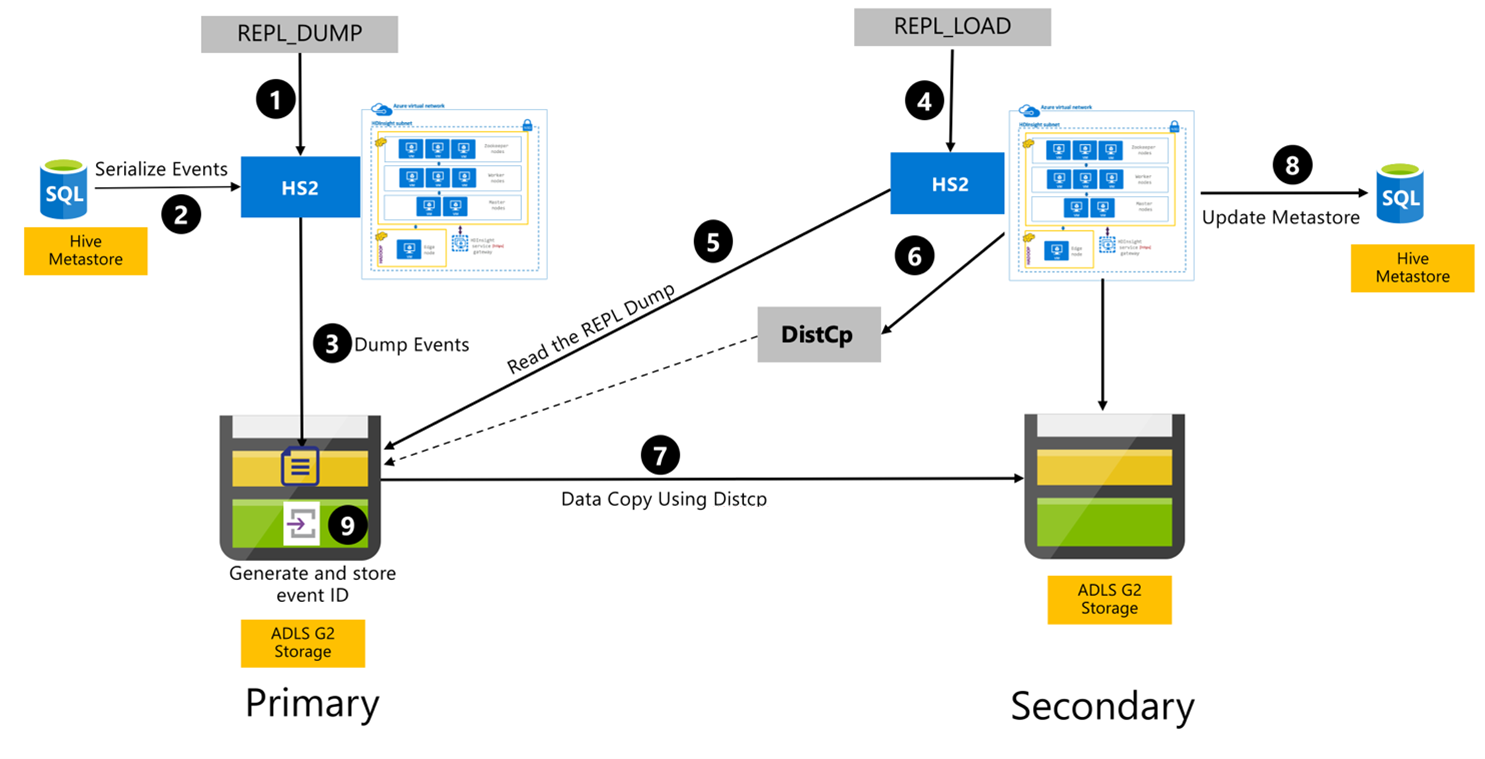
Hive-Replikationsprozess
Die folgenden Schritte sind die sequentiellen Ereignisse, die während des Hive-Replikationsprozesses ablaufen.
Stellen Sie sicher, dass die zu replizierenden Tabellen als Replikationsquelle für eine bestimmte Richtlinie festgelegt sind.
Der Befehl
REPL_DUMPwird an den primären Cluster mit zugehörigen Einschränkungen wie Datenbankname, Ereignis-ID-Bereich und Azure Data Lake Storage Gen2-Speicher-URL ausgegeben.Das System serialisiert eine Sicherung aller verfolgten Ereignisse vom Metastore bis zum letzten Speicher. Diese Sicherung wird im Azure Data Lake Storage Gen2-Speicherkonto auf dem primären Cluster unter der URL gespeichert, die durch
REPL_DUMPangegeben wird.Der primäre Cluster hält die Replikationsmetadaten im Azure Data Lake Storage Gen2-Speicher des primären Clusters aufrecht. Der Pfad ist über die Benutzeroberfläche der Hive-Konfiguration in Ambari konfigurierbar. Der Prozess stellt den Pfad bereit, in dem die Metadaten gespeichert sind, sowie die ID des letzten nachverfolgten DML/DDL-Ereignisses.
Der Befehl
REPL_LOADwird vom sekundären Cluster ausgegeben. Der Befehl zeigt auf den in Schritt 3 konfigurierten Pfad.Der sekundäre Cluster liest die Metadatendatei mit verfolgten Ereignissen, die in Schritt 3 erstellt wurde. Stellen Sie sicher, dass der sekundäre Cluster über eine Netzwerkverbindung mit dem Azure Data Lake Storage Gen2-Speicher des primären Clusters verfügt, in dem die nachverfolgten Ereignisse von
REPL_DUMPgespeichert werden.Der sekundäre Cluster erzeugt „Distributed Copy (
DistCP) Compute“.Der sekundäre Cluster kopiert Daten aus dem Speicher des primären Clusters.
Der Metastore auf dem sekundären Cluster wird aktualisiert.
Die letzte nachverfolgte Ereignis-ID wird im primären Metastore gespeichert.
Die inkrementelle Replikation folgt demselben Prozess und sie erfordert die zuletzt replizierte Ereignis-ID als Eingabe. Dies führt zu einer inkrementellen Kopie seit dem letzten Replikationsereignis. Inkrementelle Replikationen werden normalerweise mit einer vorgegebenen Häufigkeit automatisiert, um die erforderlichen Recovery Point Objectives (RPO) zu erreichen.
Replikationsmuster
Die Replikation wird normalerweise in einer unidirektionalen Weise zwischen dem primären und dem sekundären Cluster konfiguriert, wobei der primäre Cluster die Lese- und Schreibanforderungen erfüllt. Der sekundäre Cluster dient nur zum Lesen von Anforderungen. Im Notfall sind Schreibvorgänge auf dem sekundären Cluster zulässig, aber die umgekehrte Replikation muss auf dem primären Cluster konfiguriert werden.
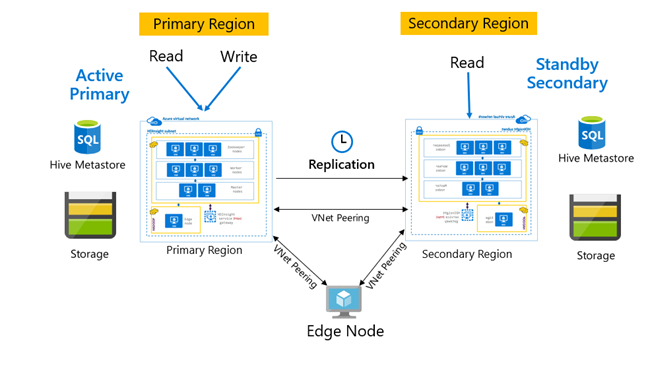
Es gibt viele Muster, die sich für die Hive-Replikation eignen, darunter „Primär – Sekundär“, „Hub-and-Spoke“ sowie „Relay“.
Bei „HDInsight: Aktiver primärer Cluster und sekundärer Standbycluster“ handelt es sich um ein gemeinsames MCDR-Muster (Business Continuity & Disaster Recovery), und HiveReplicationV2 kann dieses Muster mithilfe regional getrennter HDInsight Hadoop-Cluster mit VNet-Peering verwenden. Ein gemeinsamer virtueller Computer, der mit beiden Clustern per Peering verbunden ist, kann zum Hosten der Replikationsautomatisierungsskripts verwendet werden. Weitere Informationen über mögliche HDInsight BCDR-Muster finden Sie in der Dokumentation zur HDInsight Business Continuity.
Hive-Replikation mit Enterprise-Sicherheitspaket
In Fällen, in denen eine Hive-Replikation auf HDInsight Hadoop-Clustern mit Enterprise-Sicherheitspaket geplant ist, müssen Sie die Replikationsmechanismen für Ranger-Metastore und Microsoft Entra Domain Services berücksichtigen.
Verwenden Sie das Replikatgruppenfeature von Microsoft Entra Domain Services, um mehrere Replikate von Microsoft Entra pro Microsoft Entra-Mandanten in mehreren Regionen zu erstellen. Für jede einzelne Replikatgruppe muss das Peering mit virtuellen HDInsight-Netzwerken in ihren entsprechenden Regionen hergestellt werden. Änderungen an Microsoft Entra Domain Services (einschließlich Konfiguration, Benutzeridentität und Anmeldeinformationen, Gruppen, Gruppenrichtlinienobjekte, Computerobjekte und andere Änderungen) werden in dieser Konfiguration mittels Microsoft Entra Domain Services-Replikation auf alle Replikatgruppen in der verwalteten Domäne angewendet.
Ranger-Richtlinien können regelmäßig gesichert und mithilfe der Import-Export-Funktion von Ranger vom primären zum sekundären Cluster repliziert werden. Sie können wählen, ob Sie alle oder eine Teilmenge der Ranger-Richtlinien replizieren möchten, je nachdem, welche Ebene der Autorisierung Sie auf dem sekundären Cluster implementieren möchten.
Beispielcode
Die folgende Codesequenz liefert ein Beispiel dafür, wie Bootstrapping und inkrementelle Replikation für eine Beispieltabelle namens tpcds_orc implementiert werden können.
Legen Sie die Tabelle als Quelle für eine Replikationsrichtlinie fest.
ALTER DATABASE tpcds_orc SET DBPROPERTIES ('repl.source. for'='replpolicy1');Bootstrap-Sicherung auf dem primären Cluster.
repl dump tpcds_orc with ('hive.repl.rootdir'='/tmpag/hiveag/replag');Beispielausgabe:
dump_dir last_repl_id /tmpag/hiveag/replag/675d1bea-2361-4cad-bcbf-8680d305a27a 2925 Bootstrap-Last auf dem sekundären Cluster.
repl load tpcds_orc from '/tmpag/hiveag/replag 675d1bea-2361-4cad-bcbf-8680d305a27a';Überprüfen Sie den
REPL-Status beim sekundären Cluster.repl status tpcds_orc;last_repl_id 2925 Inkrementelle Sicherung auf dem primären Cluster.
repl dump tpcds_orc from 2925 with ('hive.repl.rootdir'='/tmpag/hiveag/ replag');Beispielausgabe:
dump_dir last_repl_id /tmpag/hiveag/replag/31177ff7-a40f-4f67-a613-3b64ebe3bb31 2960 Inkrementelle Last auf dem sekundären Cluster.
repl load tpcds_orc from '/tmpag/hiveag/replag/31177ff7-a40f-4f67-a613-3b64ebe3bb31';Überprüfen Sie den
REPL-Status auf dem sekundären Cluster.repl status tpcds_orc;last_repl_id 2960
Nächste Schritte
Weitere Informationen zu den in diesem Artikel erörterten Themen finden Sie unter: