Migrieren eines HDInsight-Clusters zu einer neueren Version
Um die neuesten HDInsight-Funktionen nutzen zu können, wird empfohlen, HDInsight-Cluster regelmäßig zur neuesten Version zu migrieren. HDInsight unterstützt keine direkten Upgrades, bei denen ein vorhandener Cluster auf eine neuere Komponentenversion aktualisiert wird. Sie müssen einen neuen Cluster mit der gewünschten Komponenten- und Plattformversion erstellen und dann die Anwendungen migrieren, um den neuen Cluster zu verwenden. Befolgen Sie die nachstehenden Leitlinien zum Migrieren Ihrer HDInsight-Clusterversionen.
Hinweis
Wenn Sie einen Hive-Cluster mit einem primären Speichercontainer erstellen, kopieren Sie ihn aus einem vorhandenen HDInsight-Cluster. Kopieren Sie nicht den vollständigen Inhalt. Kopieren Sie nur die konfigurierten Datenordner.
Migrationsaufgaben
Der Workflow für ein Upgrade eines HDInsight-Clusters ist wie folgt.
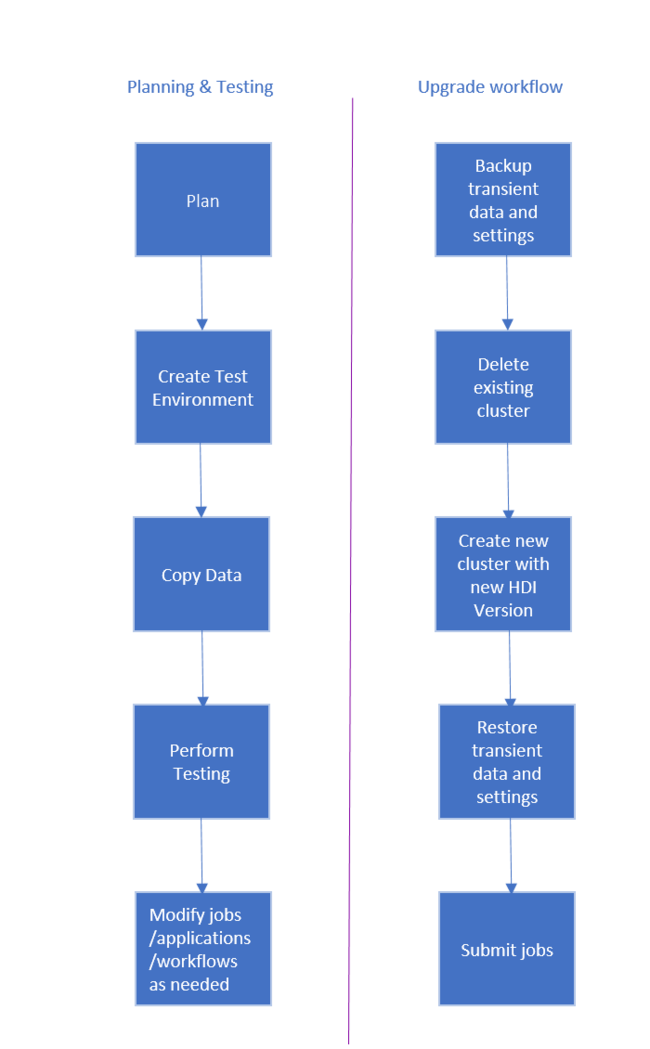
- Lesen Sie jeden Abschnitt dieses Dokuments, um zu verstehen, welche Änderungen möglicherweise erforderlich sind, wenn Sie Ihren HDInsight-Cluster aktualisieren.
- Erstellen Sie einen Cluster als Test-/Qualitätssicherungsumgebung. Weitere Informationen zur Erstellung eines Clusters finden Sie unter Erstellen von Linux-basierten Hadoop-Clustern in HDInsight.
- Kopieren Sie vorhandene Aufträge, Datenquellen und Senken in die neue Umgebung.
- Führen Sie Überprüfungstests durch, um sicherzustellen, dass Ihre Aufträge im neuen Cluster wie erwartet funktionieren.
Nachdem Sie überprüft haben, dass alles erwartungsgemäß funktioniert, planen Sie eine Ausfallzeit für die Migration. Führen Sie während dieser Ausfallzeit die folgenden Aktionen durch:
- Sichern Sie alle Daten, die vorübergehend lokal auf dem Clusterknoten gespeichert sind. Das sind beispielsweise auf einem Hauptknoten direkt gespeicherte Daten.
- Löschen Sie den vorhandenen Cluster.
- Erstellen Sie einen Cluster im gleichen VNET-Subnetz mit der aktuellen (oder einer unterstützten) HDI-Version, die den gleichen Standarddatenspeicher wie der vorherige Cluster verwendet. Dadurch wird dem neuen Cluster ermöglicht, weiterhin mit Ihren vorhandenen Produktionsdaten zu arbeiten.
- Importieren Sie alle vorübergehenden Daten, die Sie gesichert haben.
- Starten Sie Aufträge/Verarbeiten Sie weiterhin mithilfe des neuen Clusters.
Workloadspezifischer Leitfaden
Die folgenden Dokumente enthalten Anleitungen zum Migrieren bestimmter Workloads:
Sichern und Wiederherstellen
Weitere Informationen zur Datenbanksicherung und -wiederherstellung finden Sie unter Wiederherstellen einer Datenbank in Azure SQL-Datenbank mit automatisierten Datenbanksicherungen.
Upgradeszenarien
Wie bereits erwähnt, empfiehlt Microsoft, HDInsight-Cluster regelmäßig auf die neueste Version zu migrieren, um von neuen Features und Fehlerbehebungen zu profitieren. Sehen Sie sich die folgende Liste von Gründen an, aus denen wir ein Löschen und erneutes Bereitstellen eines Clusters anfordern würden:
- Die Clusterversion lautet Eingestellt, und es liegt ein Clusterproblem vor, das durch eine neuere Version behoben würde.
- Es wird festgestellt, dass die Grundursache eines Clusterproblems im Zusammenhang mit einer zu kleinen VM steht. Sehen Sie sich die von Microsoft empfohlene Knotenkonfiguration an.
- Ein Kunde öffnet einen Supportfall, und das Microsoft-Entwicklerteam stellt fest, dass das Problem bereits in einer neueren Clusterversion behoben wurde.
- Eine Standard-Metastore-Datenbank (Ambari, Hive, Oozie, Ranger) hat ihr Auslastungslimit erreicht. Microsoft bittet Sie, den Cluster mithilfe einer benutzerdefinierten Metastore-Datenbank neu zu erstellen.
- Die Grundursache eines Clusterproblems ist ein nicht unterstützter Vorgang. Nachfolgend sind einige der häufigsten nicht unterstützten Vorgänge aufgeführt:
- Verschieben oder Hinzufügen eines Diensts in Ambari. Lesen Sie die Informationen zu den Clusterdiensten in Ambari. Eine der im Menü „Dienstaktionen“ verfügbaren Aktionen ist [Dienstname] verschieben. Eine weitere Aktion ist [Dienstname] hinzufügen. Beide Optionen werden nicht unterstützt.
- Beschädigung des Python-Pakets. HDInsight-Cluster sind von den integrierten Python-Umgebungen (Python 2.7 und Python 3.5) abhängig. Die direkte Installation von benutzerdefinierten Paketen in diesen standardmäßig integrierten Umgebungen kann zu unerwarteten Änderungen der Bibliotheksversionen und zur Unterbrechung des Clusters führen. Informieren Sie sich, wie Sie benutzerdefinierte externe Python-Pakete für Ihre Spark-Anwendungen sicher installieren.
- Drittanbietersoftware. Kunden haben die Möglichkeit, Drittanbietersoftware in ihren HDInsight-Clustern zu installieren. Wir empfehlen jedoch, den Cluster neu zu erstellen, wenn er die vorhandene Funktionalität unterbricht.
- Mehrere Workloads im gleichen Cluster. In HDInsight 4.0 erfordert Hive Warehouse Connector separate Cluster für Spark- und Interactive Query-Workloads. Führen Sie diese Schritte aus, um beide Cluster in Azure HDInsight einzurichten. Auch die Integration von Spark in HBASE erfordert zwei unterschiedliche Cluster.
- Benutzerdefiniertes Kennwort für die Ambari-Datenbank wurde geändert. Das Kennwort für die Ambari-Datenbank wird während der Clustererstellung festgelegt, und es gibt zurzeit keinen Mechanismus, um es zu aktualisieren. Wenn ein Kunde den Cluster mit einer benutzerdefinierten Ambari-Datenbank bereitstellt, hat er die Möglichkeit, das Datenbankkennwort in der SQL-Datenbank zu ändern. Es gibt jedoch keine Möglichkeit zum Aktualisieren dieses Kennworts für einen ausgeführten HDInsight-Cluster.
- Ändern von HDInsight Load Balancern. Die HDInsight-Lastenausgleichsmodule, die automatisch für den Ambari- und SSH-Zugriff bereitgestellt werden, sollten nicht geändert oder gelöscht werden. Wenn Sie die HDInsight-Lastenausgleichsfunktionen ändern und dadurch die Clusterfunktionalität unterbrochen wird, wird empfohlen, den Cluster erneut bereitzustellen.
- Wiederverwenden von Ranger 4.X-Datenbanken in 5.X. HDInsight 5.1 verfügt über Apache Ranger-Version 2.3.0. Dabei handelt es sich um ein Hauptversionsupgrade von 1.2.0 in HDInsight 4.X-Clustern. Die Wiederverwendung einer HDInsight 4.X Ranger-Datenbank in HDInsight 5.1 verhindert aufgrund von Unterschieden im DB-Schema, dass der Ranger-Dienst gestartet wird. Sie müssen eine leere Ranger-Datenbank erstellen, um HDInsight 5.1-ESP-Cluster erfolgreich bereitzustellen.