Erstellen eines Clusters mit Data Lake Storage Gen2 über das Azure-Portal
Das Azure-Portal ist ein webbasiertes Verwaltungstool für Dienste und Ressourcen, die in der Microsoft Azure-Cloud gehostet werden. In diesem Artikel wird beschrieben, wie Sie mit dem Portal Linux-basierte Azure HDInsight-Cluster erstellen. Weitere Informationen finden Sie unter Einrichten von HDInsight-Clustern.
Warnung
Die Abrechnung für die HDInsight-Cluster erfolgt anteilsmäßig auf Minutenbasis und ist unabhängig von der Verwendung. Daher sollten Sie Ihren Cluster nach der Verwendung unbedingt wieder löschen. Sehen Sie sich die Informationen zum Löschen eines HDInsight-Clusters an.
Wenn Sie kein Azure-Abonnement haben, erstellen Sie ein kostenloses Konto, bevor Sie beginnen.
Konfigurieren Sie mithilfe der folgenden Schritte ein Data Lake Storage Gen2-Konto, um ein Speicherkonto zu konfigurieren, das einen hierarchischen Namespace aufweist.
Erstellen einer benutzerseitig zugewiesenen verwalteten Identität
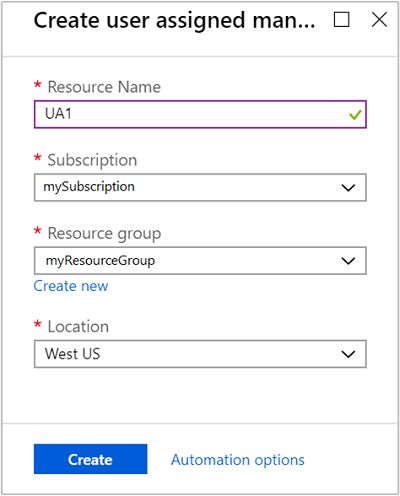
Erstellen Sie eine benutzerseitig zugewiesene verwaltete Identität, falls noch keine vorhanden ist.
- Melden Sie sich beim Azure-Portal an.
- Wählen Sie links oben Ressource erstellen aus.
- Geben Sie im Suchfeld den Suchbegriff Vom Benutzer zugewiesen ein, und klicken Sie auf Benutzerseitig zugewiesene verwaltete Identität.
- Klicken Sie auf Erstellen.
- Geben Sie einen Namen für Ihre verwaltete Identität ein, und wählen Sie das richtige Abonnement, die Ressourcengruppe und den Speicherort aus.
- Klicken Sie auf Erstellen.
Weitere Informationen zur Funktionsweise verwalteter Identitäten in Azure HDInsight finden Sie unter Verwaltete Identitäten in Azure HDInsight.
Erstellen eines Speicherkontos für die Verwendung mit Data Lake Storage Gen2
Erstellen eines Speicherkontos für die Verwendung mit Azure Data Lake Storage Gen2.
- Melden Sie sich beim Azure-Portal an.
- Wählen Sie links oben Ressource erstellen aus.
- Geben Sie im Suchfeld den Suchbegriff Speicher ein, und klicken Sie auf Speicherkonto.
- Klicken Sie auf Erstellen.
- Auf dem
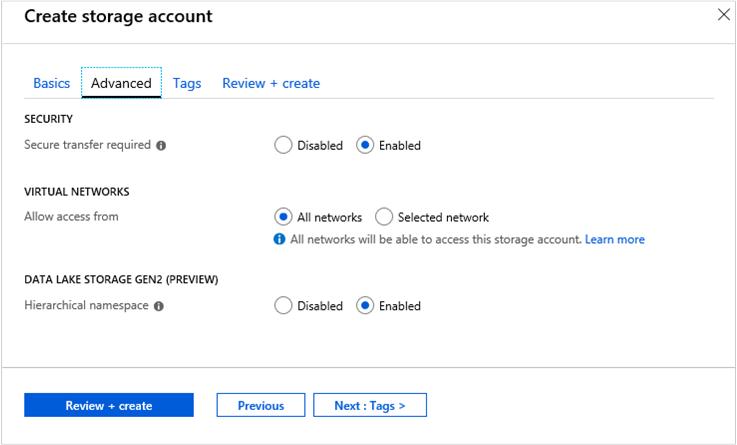
Create storage account-Bildschirm:- Wählen Sie das richtige Abonnement und die Ressourcengruppe aus.
- Geben Sie einen Namen für Ihr Speicherkonto mit Data Lake Storage Gen2 ein.
- Klicken Sie auf die Registerkarte Erweitert.
- Klicken Sie auf Aktiviert neben Hierarchischer Namespace unter Data Lake Storage Gen2.
- Klicken Sie auf Überprüfen + erstellen.
- Klicken Sie auf Erstellen
Weitere Informationen zu anderen Optionen während der Erstellung des Speicherkontos finden Sie unter Schnellstart: Erstellen eines Speicherkontos für Azure Data Lake Storage Gen2.
Festlegen von Berechtigungen für verwaltete Identitäten in Data Lake Storage Gen2
Weisen Sie die verwaltete Identität der Rolle Besitzer von Speicherblobdaten im Speicherkonto zu.
Wechseln Sie im Azure-Portal zu Ihrem Speicherkonto.
Wählen Sie die Option Zugriffssteuerung (IAM) aus.
Wählen Sie Hinzufügen > Rollenzuweisung hinzufügen aus.

Wählen Sie auf der Registerkarte Rolle die Option Besitzer von Speicherblobdaten aus.

Wählen Sie auf der Registerkarte Mitglieder die Option Verwaltete Identität und dann Mitglieder auswählen aus.
Wählen Sie Ihr Abonnement aus, anschließend Benutzerseitig zugewiesene verwaltete Identität und dann Ihre benutzerseitig zugewiesene verwaltete Identität.
Wählen Sie auf der Registerkarte Überprüfen und zuweisen die Option Überprüfen und zuweisen aus, um die Rolle zuzuweisen.
Die vom Benutzer zugewiesene Identität, die Sie ausgewählt haben, wird jetzt unter der ausgewählten Rolle aufgelistet.
Weitere Informationen zu Rollenzuweisungen finden Sie unter Zuweisen von Azure-Rollen über das Azure-Portal.
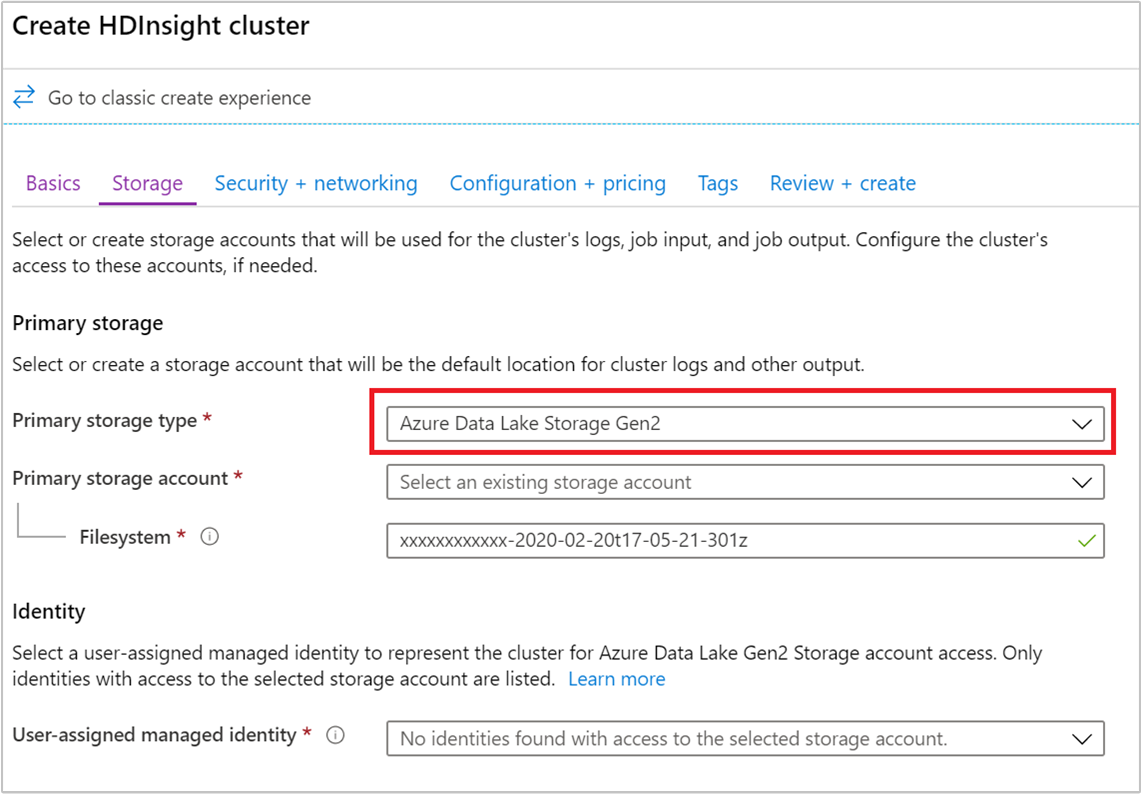
Nachdem das anfängliche Setup abgeschlossen ist, können Sie einen Cluster über das Portal erstellen. Der Cluster muss sich in der gleichen Azure-Region befinden wie das Speicherkonto. Wählen Sie auf der Registerkarte Speicher des Menüs zur Clustererstellung die folgenden Optionen aus:
Wählen Sie für Primärer SpeichertypAzure Data Lake Storage Gen2 aus.
Suchen Sie unter Primäres Speicherkonto das neu erstellte Speicherkonto mit Data Lake Storage Gen2-Speicher, und wählen Sie es aus.
Wählen Sie unter Identität die neu erstellte, vom Benutzer zugewiesene verwaltete Identität aus.
Hinweis
- Zum Hinzufügen eines sekundären Speicherkontos mit Data Lake Storage Gen2 müssen Sie auf der Speicherkontoebene lediglich die zuvor erstellte verwaltete Identität zur neuen Data Lake Storage Gen2-Instanz hinzufügen, die Sie hinzufügen möchten. Beachten Sie, dass das Hinzufügen eines sekundären Speicherkontos mit Data Lake Storage Gen2 über das Blatt „Zusätzliche Speicherkonten“ in HDInsight nicht unterstützt wird.
- Sie können RA-GRS oder RA-ZRS (georedundanter Speicher mit Lesezugriff oder geo- und zonenredundanter Speicher) für das von HDInsight verwendete Azure-Blobspeicherkonto aktivieren. Jedoch wird das Erstellen eines Clusters für den sekundären RA-GRS- oder RA-ZRS-Endpunkt nicht unterstützt.
- HDInsight unterstützt die Einrichtung von Data Lake Storage Gen2 als geozonenredundanten Speicher mit Lesezugriff (read-access geo-zone-redundant storage, RA-GZRS) oder geozonenredundanten Speicher (geo-zone-redundant storage, GZRS) nicht.
Löschen des Clusters
Weitere Informationen finden Sie unter Löschen eines HDInsight-Clusters mithilfe von Browser, PowerShell oder Azure-Befehlszeilenschnittstelle.
Problembehandlung
Falls beim Erstellen von HDInsight-Clustern Probleme auftreten, sehen Sie sich die Voraussetzungen für die Zugriffssteuerung an.
Nächste Schritte
Sie haben die Erstellung eines HDInsight-Clusters erfolgreich abgeschlossen. Als Nächstes wird beschrieben, wie Sie mit Ihrem Cluster arbeiten.
Apache Spark-Cluster
- Anpassen Linux-basierter HDInsight-Cluster mithilfe von Skriptaktionen
- Erstellen einer eigenständigen Anwendung mit Scala
- Ausführen von Remoteaufträgen in einem Apache Spark-Cluster mithilfe von Apache Livy
- Apache Spark mit BI: Durchführen interaktiver Datenanalysen mithilfe von Spark in HDInsight mit BI-Tools
- Apache Spark mit Machine Learning: Vorhersage von Lebensmittelkontrollergebnissen mithilfe von Spark in HDInsight