Zugreifen auf Apache Hadoop YARN-Anwendungsprotokolle unter Linux-basiertem HDInsight
Informieren Sie sich, wie Sie auf Protokolle für Apache Hadoop YARN-Anwendungen (Yet Another Resource Negotiator) in einem Apache Hadoop-Cluster in Azure HDInsight zugreifen.
Was ist Apache YARN?
YARN unterstützt mehrere Programmierungsmodelle (u. a. Apache Hadoop MapReduce), indem die Ressourcenverwaltung von der Zeitplanung/Überwachung von Anwendungen getrennt wird. YARN verwendet einen globalen ResourceManager (RM), workerknotenbezogene NodeManager (NMs) und anwendungsbezogene ApplicationMaster (AMs). Der anwendungsbezogene AM handelt Ressourcen (CPU, Arbeitsspeicher, Datenträger, Netzwerk) für die Ausführung Ihrer Anwendung mit dem RM aus. Der RM arbeitet mit NMs zusammen, um diese Ressourcen zu gewähren, die als Container zugewiesen werden. Der AM ist zuständig für die Nachverfolgung des Status der Container, die ihm vom RM zugewiesen wurden. Je nach Art der Anwendung kann diese viele Container benötigen.
Jede Anwendung kann aus mehreren Anwendungsversuchen bestehen. Tritt bei einer Anwendung ein Fehler auf, kann ein neuer Versuch unternommen werden. Jeder Versuch wird in einem Container ausgeführt. In gewisser Weise stellt ein Container den Kontext für die Standardeinheit für Aufgaben bereit, die von einer YARN-Anwendung ausgeführt werden. Alle Aufgaben, die im Kontext eines Containers erledigt werden, erfolgen auf dem einzelnen Workerknoten, auf dem der Container angegeben wurde. Weitere Informationen finden Sie unter Hadoop: Schreiben von YARN-Anwendungen oder Apache Hadoop YARN.
Zur Skalierung Ihres Clusters für einen höheren Verarbeitungsdurchsatz können Sie die Autoskalierung oder das manuelle Skalieren Ihrer Cluster mit einigen verschiedenen Sprachen verwenden.
YARN Timeline Server
Der Apache Hadoop YARN Timeline Server bietet allgemeine Informationen zu abgeschlossenen Anwendungen.
YARN Timeline Server umfasst die folgenden Arten von Daten:
- Die Anwendungs-ID, ein eindeutiger Bezeichner einer Anwendung
- Der Benutzer, der die Anwendung gestartet hat
- Informationen zu den erfolgten Versuchen, die Anwendung abzuschließen
- Die bei Anwendungsversuchen verwendeten Container
YARN-Anwendungen und -Protokolle
Anwendungsprotokolle (und dazugehörige Containerprotokolle) sind für das Beheben von Problemen bei Hadoop-Anwendungen besonders wichtig. YARN bietet mit der Protokollaggregation ein nützliches Framework für das Sammeln, Zusammenführen und Speichern von Anwendungsprotokollen.
Durch die Protokollaggregationsfunktion wird der Zugriff auf Anwendungsprotokolle deterministischer. Sie aggregiert Protokolle in allen Containern auf einem Workerknoten und speichert sie als eine aggregierte Protokolldatei pro Workerknoten. Das Protokoll wird, nachdem eine Anwendung beendet wurde, im Standarddateisystem gespeichert. Ihre Anwendung mag Hunderte oder Tausende von Containern verwenden, doch Protokolle für alle auf einem einzelnen Workerknoten vorhandenen Container werden immer zu einer zentralen Datei zusammengeführt. Es wird also nur ein Protokoll pro Workerknoten von Ihrer Anwendung genutzt. Die Protokollaggregation ist für HDInsight-Cluster ab Version 3.0 standardmäßig aktiviert. Aggregierte Protokolle befinden sich im Standardspeicher für den Cluster. Der folgende Pfad ist der HDFS-Pfad für die Protokolle:
/app-logs/<user>/logs/<applicationId>
user steht hier für den Namen des Benutzers, der die Anwendung gestartet hat. applicationId ist der eindeutige Bezeichner, der einer Anwendung durch den YARN-RM zugewiesen wird.
Die zusammengeführten Protokolle sind nicht unmittelbar lesbar, da sie in einem TFile-Binärformat mit Indizierung nach Container geschrieben werden. Verwenden Sie die YARN-ResourceManager-Protokolle oder CLI-Tools, um diese Protokolle für relevante Anwendungen oder Container im Nur-Text-Format anzuzeigen.
Yarn-Protokolle in einem ESP-Cluster
Der benutzerdefinierten mapred-site in Ambari müssen zwei Konfigurationen hinzugefügt werden.
Navigieren Sie in einem Webbrowser zu
https://CLUSTERNAME.azurehdinsight.net, wobeiCLUSTERNAMEder Name Ihres Clusters ist.Navigieren Sie über die Ambari-Benutzeroberfläche zu MapReduce2>Configs>Advanced>Custom mapred-site (MapReduce2 > Konfigurationen > Erweitert > Benutzerdefinierte mapred-Website).
Fügen Sie eine der folgenden Gruppen von Eigenschaften hinzu:
Gruppe 1
mapred.acls.enabled=true mapreduce.job.acl-view-job=*Gruppe 2
mapreduce.job.acl-view-job=<user1>,<user2>,<user3>Speichern Sie die Änderungen, und starten Sie alle betroffenen Dienste neu.
YARN-CLI-Tools
Verwenden Sie einen ssh-Befehl zum Herstellen der Verbindung mit dem Cluster. Bearbeiten Sie den folgenden Befehl, indem Sie CLUSTERNAME durch den Namen Ihres Clusters ersetzen, und geben Sie den Befehl dann ein:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netListen Sie alle Anwendungs-IDs der aktuell ausgeführten Yarn-Anwendungen mit dem folgenden Befehl auf:
yarn topNotieren Sie sich in der Spalte
APPLICATIONIDdie ID der Anwendung, deren Protokolle heruntergeladen werden sollen.YARN top - 18:00:07, up 19d, 0:14, 0 active users, queue(s): root NodeManager(s): 4 total, 4 active, 0 unhealthy, 0 decommissioned, 0 lost, 0 rebooted Queue(s) Applications: 2 running, 10 submitted, 0 pending, 8 completed, 0 killed, 0 failed Queue(s) Mem(GB): 97 available, 3 allocated, 0 pending, 0 reserved Queue(s) VCores: 58 available, 2 allocated, 0 pending, 0 reserved Queue(s) Containers: 2 allocated, 0 pending, 0 reserved APPLICATIONID USER TYPE QUEUE #CONT #RCONT VCORES RVCORES MEM RMEM VCORESECS MEMSECS %PROGR TIME NAME application_1490377567345_0007 hive spark thriftsvr 1 0 1 0 1G 0G 1628407 2442611 10.00 18:20:20 Thrift JDBC/ODBC Server application_1490377567345_0006 hive spark thriftsvr 1 0 1 0 1G 0G 1628430 2442645 10.00 18:20:20 Thrift JDBC/ODBC ServerSie können diese Protokolle im Nur-Text-Format anzeigen, indem Sie einen der folgenden Befehle ausführen:
yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> -containerId <containerId> -nodeAddress <worker-node-address>Geben Sie beim Ausführen dieser Befehle die <Anwendungs-ID>, den <Benutzer-der-die-Anwendung-gestartet-hat>, die <Container-ID> und die <Adresse-des-Workerknotens> an.
Weitere Beispielbefehle
Laden Sie Yarn-Containerprotokolle für alle Anwendungsmaster mit folgendem Befehl herunter. In diesem Schritt wird die Protokolldatei
amlogs.txtim Textformat erstellt.yarn logs -applicationId <application_id> -am ALL > amlogs.txtLaden Sie Yarn-Containerprotokolle nur für den neuesten Anwendungsmaster mit folgendem Befehl herunter:
yarn logs -applicationId <application_id> -am -1 > latestamlogs.txtLaden Sie YARN-Containerprotokolle für die ersten beiden Anwendungsmaster mit folgendem Befehl herunter:
yarn logs -applicationId <application_id> -am 1,2 > first2amlogs.txtLaden Sie alle Yarn-Containerprotokolle mit dem folgenden Befehl herunter:
yarn logs -applicationId <application_id> > logs.txtLaden Sie ein Yarn-Containerprotokoll für einen bestimmten Container mit folgendem Befehl herunter:
yarn logs -applicationId <application_id> -containerId <container_id> > containerlogs.txt
YARN-ResourceManager-Benutzeroberfläche
Die YARN-ResourceManager-Benutzeroberfläche wird auf dem Clusterhauptknoten ausgeführt. Der Zugriff erfolgt über die Ambari-Webbenutzeroberfläche. Führen Sie die folgenden Schritte aus, um die YARN-Protokolle anzeigen:
Navigieren Sie in Ihrem Webbrowser zu
https://CLUSTERNAME.azurehdinsight.net. Ersetzen Sie CLUSTERNAME durch den Namen Ihres HDInsight-Clusters.Wählen Sie aus der Liste der Dienste auf der linken Seite den Dienst YARNaus.
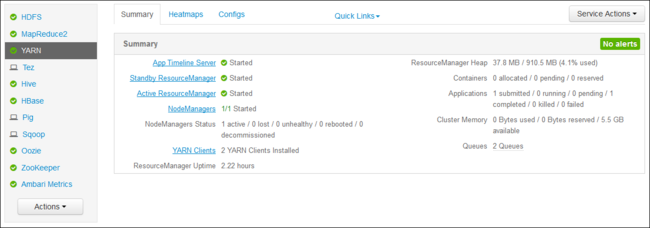
Wählen Sie aus der Dropdownliste Quicklinks einen der Clusterhauptknoten und dann
ResourceManager Logaus.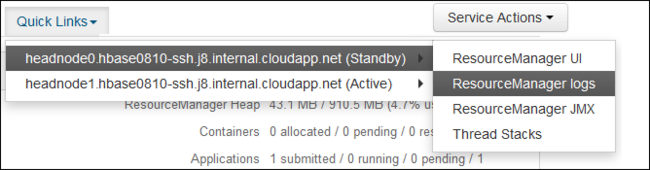
Eine Liste mit Links zu YARN-Protokollen wird angezeigt.