Automatisches Skalieren von Azure HDInsight-Clustern
Das kostenlose Feature Autoskalierung von Azure HDInsight kann die Anzahl der Workerknoten in Ihrem Cluster auf der Grundlage von Clustermetriken und der vom Kunden eingeführten Skalierungsrichtlinien automatisch herauf- oder heruntersetzen. Das Feature „Autoskalierung“ skaliert die Anzahl von Knoten innerhalb vorgegebener Grenzwerte – entweder auf der Grundlage von Leistungsmetriken oder nach einem definierten Zeitplan mit Vorgängen zum Hoch- und Herunterskalieren.
Funktionsweise
Das Feature „Autoskalierung“ verwendet zwei Arten von Bedingungen zum Auslösen von Skalierungsereignissen: Schwellenwerte für verschiedene Clusterleistungsmetriken (die sogenannte lastbasierte Skalierung) und zeitbasierte Trigger (zeitplanbasierte Skalierung). Die lastbasierte Skalierung ändert die Anzahl der Knoten in Ihrem Cluster innerhalb eines von Ihnen festgelegten Bereichs, um eine optimale CPU-Auslastung zu gewährleisten und die Betriebskosten zu minimieren. Bei der zeitplanbasierten Skalierung wird die Anzahl von Knoten in Ihrem Cluster auf der Grundlage eines Zeitplans mit Vorgängen zum Hoch- und Herunterskalieren geändert.
Das folgende Video vermittelt einen Überblick über die Herausforderungen, für die die Autoskalierung Abhilfe schafft. Außerdem wird erläutert, wie dieses Feature Ihnen bei der Kostenkontrolle mit HDInsight helfen kann.
Auswählen von last- oder zeitplanbasierter Skalierung
Die zeitplanbasierte Skalierung kann verwendet werden:
- Wenn Ihre Aufträge nach festen Zeitplänen und für eine vorhersagbare Dauer ausgeführt werden sollen oder Sie eine geringe Auslastung zu bestimmten Tageszeiten erwarten. Beispiel: Test- und Entwicklungsumgebungen nach Büroschluss am Tagesende.
Die lastbasierte Skalierung kann verwendet werden:
- Wenn die Auslastungsmuster im Laufe des Tages erheblich und unvorhersehbar schwanken. Beispiel: Reihenfolge bei der Datenverarbeitung mit zufälligen Schwankungen in den Auslastungsmustern basierend auf verschiedenen Faktoren.
Clustermetriken
Die automatische Skalierung überwacht kontinuierlich die Cluster und sammelt die folgenden Metriken:
| Metrik | BESCHREIBUNG |
|---|---|
| CPU insgesamt für ausstehende | Die Gesamtanzahl von Kernen, die zum Starten der Ausführung aller ausstehenden Container erforderlich sind. |
| Arbeitsspeicher insgesamt für ausstehende | Die Gesamtgröße des Arbeitsspeichers (in MB), die zum Starten der Ausführung aller ausstehenden Container erforderlich ist. |
| Freie CPUs insgesamt | Die Summe aller nicht verwendeten Kerne auf den aktiven Workerknoten. |
| Freier Arbeitsspeicher insgesamt | Die Summe aller nicht verwendeten Kerne (in MB) auf den aktiven Workerknoten. |
| Verwendeter Arbeitsspeicher pro Knoten | Die Last auf einem Workerknoten. Ein Workerknoten, auf dem 10GB Arbeitsspeicher verwendet werden, ist höher ausgelastet als ein Workerknoten, auf dem 2GB verwendet werden. |
| Anzahl der Anwendungsmaster pro Knoten | Die Anzahl der Anwendungsmastercontainer (Application Master, AM), die auf einem Workerknoten ausgeführt werden. Ein Workerknoten, der 2 AM-Container hostet, gilt als wichtiger als ein Workerknoten, der 0 AM-Container hostet. |
Die oben aufgeführten Metriken werden alle 60 Sekunden überprüft. Die Autoskalierung trifft auf Basis dieser Metriken Entscheidungen zum zentralen Hoch- und Herunterskalieren.
Eine vollständige Liste der Clustermetriken finden Sie unter Unterstützte Metriken für Microsoft.HDInsight/Cluster.
Lastbasierte Skalierungsbedingungen
Wenn die folgenden Bedingungen erkannt werden, gibt die Autoskalierung eine Skalierungsanforderung aus:
| Zentrales Hochskalieren | Zentrales Herunterskalieren |
|---|---|
| „CPU insgesamt für ausstehende“ ist seit mehr als 3–5 Minuten größer als die Menge der freien CPU-Leistung insgesamt. | „CPU insgesamt für ausstehende“ ist länger als 3-5 Minuten kleiner als die Anzahl der insgesamt freien CPUs. |
| „Arbeitsspeicher insgesamt für ausstehende“ ist seit mehr als 3–5 Minuten größer als der freie Arbeitsspeicher insgesamt. | „Arbeitsspeicher insgesamt für ausstehende“ ist länger als 3-5 Minuten kleiner als der insgesamt freie Arbeitsspeicher. |
Beim zentralen Hochskalieren gibt die Autoskalierung eine Anforderung aus, die erforderliche Anzahl von Knoten hinzuzufügen. Das zentrale Hochskalieren basiert auf der erforderlichen Anzahl von neuen Workerknoten zum Erfüllen der aktuellen CPU- und Arbeitsspeicheranforderungen.
Zum Herunterskalieren gibt die Autoskalierung eine Anforderung zum Entfernen einiger Knoten aus. Das zentrale Herunterskalieren basiert auf der Anzahl der AM-Container (Application Master) pro Knoten und den aktuellen CPU- und Arbeitsspeicheranforderungen. Der Dienst erkennt auch, welche Knoten aufgrund der aktuellen Auftragsausführung für die Entfernung in Frage kommen. Der Vorgang des Herunterskalierens deaktiviert zunächst die Knoten und entfernt sie dann aus dem Cluster.
Überlegungen zur Dimensionierung von Ambari DB für die Autoskalierung
Es wird empfohlen, Ambari DB richtig zu dimensionieren, um die Vorteile der Autoskalierung zu nutzen. Kunden sollten die richtige Datenbankebene und benutzerdefinierte Ambari DB-Einstellungen für große Cluster verwenden. Lesen Sie die Empfehlungen zur Dimensionierung von Datenbank und Hauptknoten.
Clusterkompatibilität
Wichtig
Die Azure HDInsight-Funktion für die automatische Skalierung wurde mit allgemeiner Verfügbarkeit am 7. November 2019 für Spark- und Hadoop-Cluster veröffentlicht und enthält Verbesserungen, die in der Vorschauversion des Features nicht verfügbar sind. Wenn Sie vor dem 7. November 2019 einen Spark-Cluster erstellt haben und die automatische Skalierung in Ihrem Cluster verwenden möchten, wird empfohlen, einen neuen Cluster zu erstellen und für den neuen Cluster enable Autoscale.
Autoskalierung für Interactive Query (LLAP) wurde am 27. August 2020 für die allgemeine Verfügbarkeit für HDI 4.0 veröffentlicht. Die automatische Skalierung ist nur für Spark-, Hadoop- und Interactive Query-Cluster verfügbar.
Die folgende Tabelle beschreibt die Clustertypen und Versionen, die mit dem Feature „Autoskalierung“ kompatibel sind.
| Version | Spark | Hive | Interactive Query | hbase | Kafka |
|---|---|---|---|---|---|
| HDInsight 4.0 ohne ESP | Ja | Ja | Ja* | Nein | Nein |
| HDInsight 4.0 mit ESP | Ja | Ja | Ja* | Nein | Nein |
| HDInsight 5.0 ohne ESP | Ja | Ja | Ja* | Nein | Nein |
| HDInsight 5.0 mit ESP | Ja | Ja | Ja* | Nein | Nein |
* Interactive Query-Cluster können nur für zeitplanbasierte, aber nicht für auslastungsbasierte Skalierung konfiguriert werden.
Erste Schritte
Erstellen eines Clusters mit lastbasierter Autoskalierung
Um das Feature „Autoskalierung“ mit lastbasierter Skalierung zu aktivieren, führen Sie als Teil des normalen Clustererstellungsvorgangs folgende Schritte aus:
Aktivieren Sie auf der Registerkarte Konfiguration + Preise das Kontrollkästchen
Enable autoscale.Wählen Sie Lastbasiert unter Autoskalierungstyp aus.
Geben Sie die gewünschten Werte für die folgenden Eigenschaften ein:
- Anfängliche Anzahl von Workerknoten für Workerknoten.
- Minimale Anzahl von Workerknoten.
- Maximale Anzahl von Workerknoten.
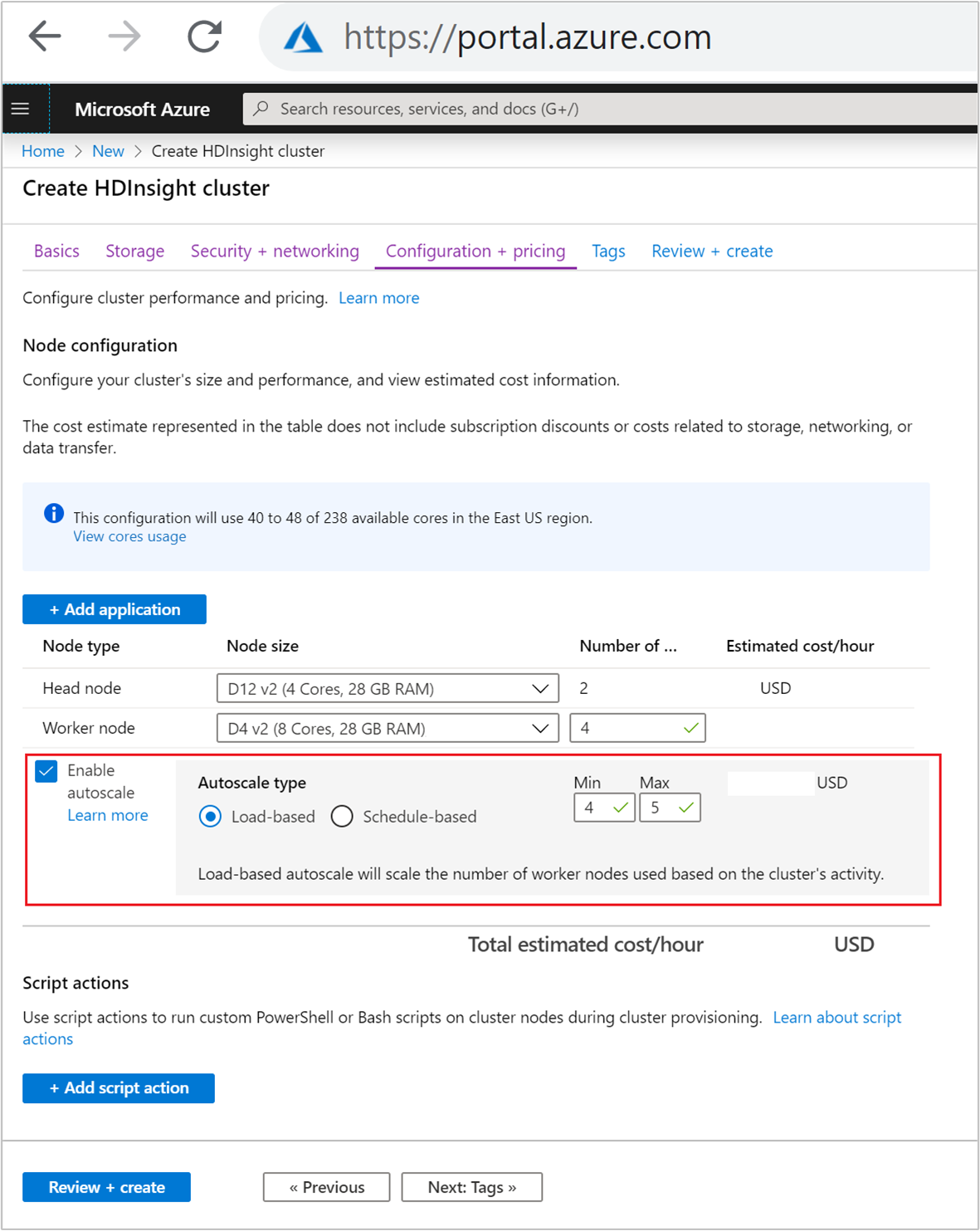
Die anfängliche Anzahl der Workerknoten kann vom Mindest- bis zum Höchstwert reichen. Dieser Wert definiert die Anfangsgröße des Clusters bei der Erstellung. Die Mindestzahl der Workerknoten sollte auf drei oder mehr festgelegt werden. Die Skalierung des Clusters auf weniger als drei Knoten kann dazu führen, dass der Cluster aufgrund unzureichender Dateireplikation im abgesicherten Modus hängen bleibt. Weitere Informationen finden Sie unter Hängenbleiben im abgesicherten Modus.
Erstellen eines Clusters mit zeitplanbasiert Autoskalierung
Um das Feature „Autoskalierung“ mit zeitplanbasierter Skalierung zu aktivieren, führen Sie als Teil des normalen Clustererstellungsvorgangs folgende Schritte aus:
Aktivieren Sie auf der Registerkarte Konfiguration + Preise das Kontrollkästchen
Enable autoscale.Geben Sie die Anzahl der Knoten für Workerknoten ein. Damit wird begrenzt, wie hoch der Cluster skaliert werden kann.
Wählen Sie unter Autoskalierungstyp die Option Zeitplanbasiert aus.
Wählen Sie Konfigurieren aus, um das Fenster Konfiguration der Autoskalierung zu öffnen.
Wählen Sie Ihre Zeitzone aus, und klicken Sie dann auf + Bedingung hinzufügen.
Wählen Sie die Tage der Woche, an denen die neue Bedingung angewendet werden soll.
Bearbeiten Sie die Zeit, zu der die Bedingung wirksam werden soll, und die Anzahl der Knoten, auf die der Cluster skaliert werden soll.
Fügen Sie gegebenenfalls weitere Bedingungen hinzu.
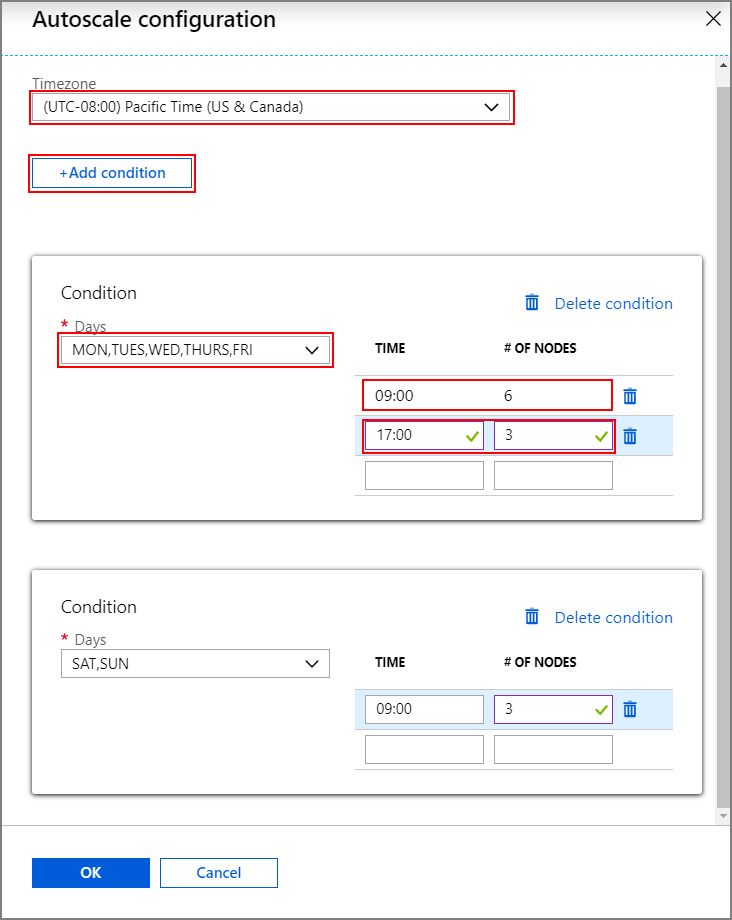
Die Anzahl der Knoten muss zwischen 3 und der maximalen Anzahl der Workerknoten liegen, die Sie vor dem Hinzufügen von Bedingungen eingegeben haben.
Letzte Erstellungsschritte
Wählen Sie den VM-Typ für Workerknoten aus, indem Sie in der Dropdownliste unter Knotengröße eine VM auswählen. Nachdem Sie den VM-Typ für jeden Knotentyp ausgewählt haben, können Sie den Bereich der geschätzten Kosten für den gesamten Cluster sehen. Passen Sie die VM-Typen entsprechend Ihrem Budget an.
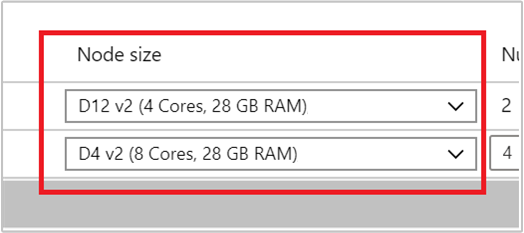
Ihr Abonnement verfügt für jede Region über ein Kapazitätskontingent. Die Gesamtanzahl der Kerne Ihrer Hauptknoten und der maximalen Workerknoten darf das Kapazitätskontingent nicht überschreiten. Dieses Kontingent ist jedoch eine weiche Grenze. Sie können immer ein Supportticket erstellen, um es problemlos erhöhen zu lassen.
Hinweis
Wenn Sie die gesamte Kernkontingentgrenze überschreiten, informiert Sie eine Fehlermeldung darüber, dass die maximale Knotenzahl die Zahl der verfügbaren Kerne in dieser Region überschritten hat, und Sie werden aufgefordert, eine andere Region auszuwählen oder den Support um Erhöhung des Kontingents zu bitten.
Weitere Informationen zum Erstellen von HDInsight-Clustern mit dem Azure-Portal finden Sie unter Erstellen von Linux-basierten Clustern in HDInsight mithilfe des Azure-Portals.
Erstellen eines Clusters mithilfe einer Resource Manager-Vorlage
Lastbasierte Autoskalierung
Sie können einen HDInsight-Cluster mit lastbasierter Autoskalierung über eine Azure Resource Manager-Vorlage erstellen, indem Sie dem Abschnitt computeProfile>workernode einen autoscale-Knoten mit den Eigenschaften minInstanceCount und maxInstanceCount hinzufügen, wie im JSON-Codeschnipsel gezeigt. Eine vollständige Resource Manager-Vorlage finden Sie unter Schnellstartvorlage: Bereitstellen eines Spark-Clusters mit aktivierter lastbasierter Autoskalierung.
{
"name": "workernode",
"targetInstanceCount": 4,
"autoscale": {
"capacity": {
"minInstanceCount": 3,
"maxInstanceCount": 10
}
},
"hardwareProfile": {
"vmSize": "Standard_D13_V2"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
},
"virtualNetworkProfile": null,
"scriptActions": []
}
Zeitplanbasierte Autoskalierung
Sie können einen HDInsight-Cluster mit zeitplanbasierter Autoskalierung und einer Azure Resource Manager-Vorlage erstellen, indem Sie dem Abschnitt computeProfile>workernode einen autoscale-Knoten hinzufügen. Der autoscale-Knoten enthält einen recurrence-Wert mit einer timezone und einem schedule. Damit wird beschrieben, wann die Änderung erfolgen wird. Eine umfassende Resource Manager-Vorlage finden Sie unter Bereitstellen eines Spark-Clusters mit aktivierter zeitplanbasierter Autoskalierung.
{
"autoscale": {
"recurrence": {
"timeZone": "Pacific Standard Time",
"schedule": [
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"timeAndCapacity": {
"time": "11:00",
"minInstanceCount": 10,
"maxInstanceCount": 10
}
}
]
}
},
"name": "workernode",
"targetInstanceCount": 4
}
Aktivieren und Deaktivieren der Autoskalierung für einen aktuell ausgeführten Cluster
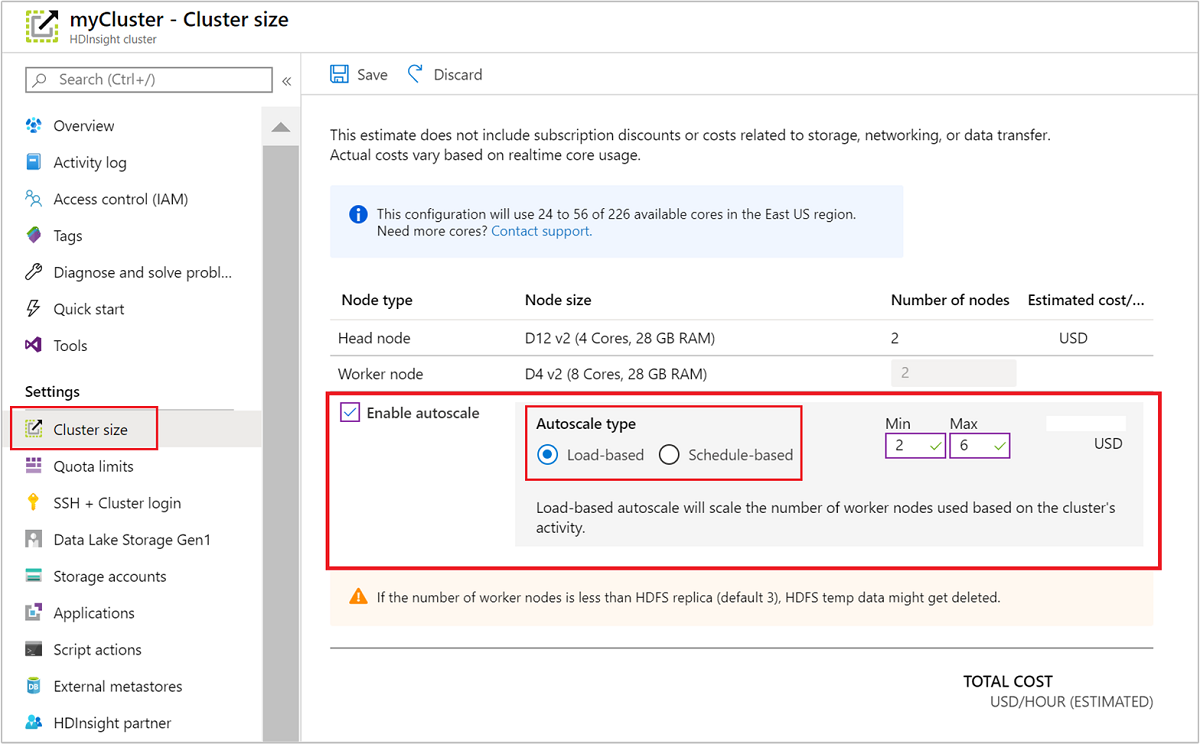
Verwenden des Azure-Portals
Zum Aktivieren der Autoskalierung in einem ausgeführten Cluster wählen Clustergröße unter Einstellungen. Wählen Sie dann Enable autoscale aus. Wählen Sie die gewünschte Art der Autoskalierung, und geben Sie die Optionen für die last- oder zeitplanbasierte Skalierung ein. Klicken Sie abschließend auf Speichern.
Verwenden der REST-API
Um die Autoskalierung für einen aktiven Cluster über die REST-API zu aktivieren oder zu deaktivieren, senden Sie eine POST-Anforderung an den Endpunkt der Autoskalierung:
https://management.azure.com/subscriptions/{subscription Id}/resourceGroups/{resourceGroup Name}/providers/Microsoft.HDInsight/clusters/{CLUSTERNAME}/roles/workernode/autoscale?api-version=2018-06-01-preview
Verwenden Sie die geeigneten Parameter in der Anforderungsnutzlast. Die folgende JSON-Payload kann für enable Autoscale verwendet werden. Verwenden Sie die Nutzlast {autoscale: null}, um Autoskalierung zu deaktivieren.
{ "autoscale": { "capacity": { "minInstanceCount": 3, "maxInstanceCount": 5 } } }
Eine vollständige Beschreibung aller Nutzlastparameter finden Sie im vorherigen Abschnitt über Aktivieren von lastenbasierter Autoskalierung. Es wird davon abgeraten, die Deaktivierung des Diensts für die automatische Skalierung in einem ausgeführten Cluster zu erzwingen.
Überwachen von automatischen Skalierungsaktivitäten
Clusterstatus
Der im Azure-Portal aufgeführte Clusterstatus kann Ihnen helfen, die Aktivitäten der Autoskalierung zu überwachen.
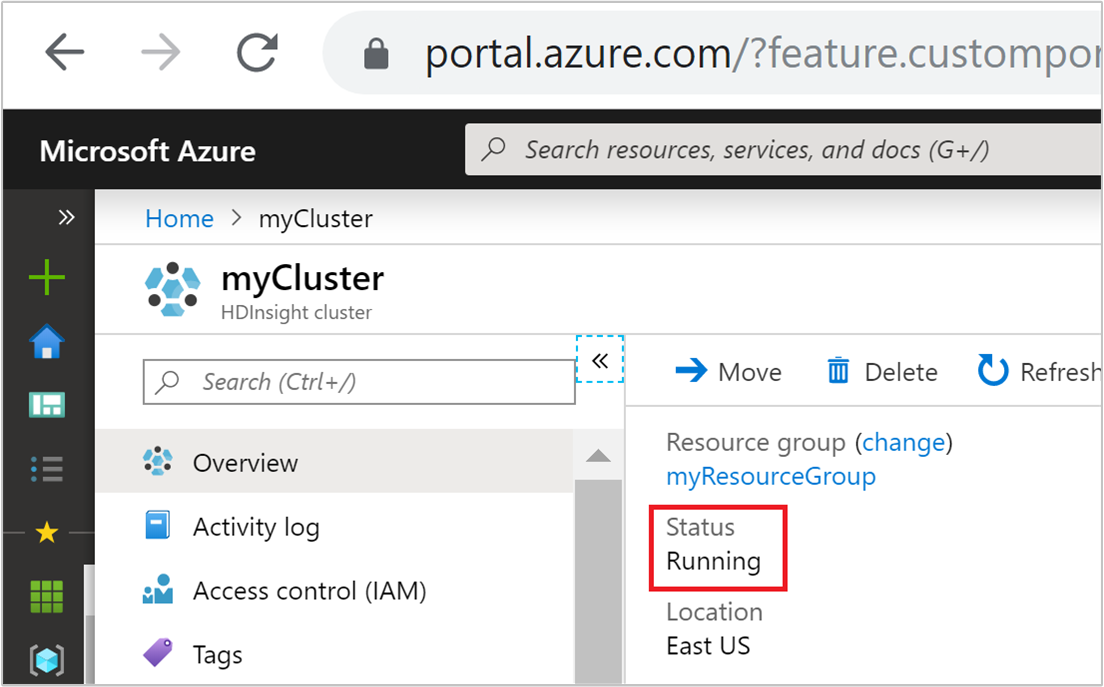
Alle möglicherweise angezeigten Statusmeldungen des Clusters werden in der folgenden Liste erläutert.
| Clusterstatus | BESCHREIBUNG |
|---|---|
| Wird ausgeführt | Der Cluster wird normal ausgeführt. Alle vorherigen Autoskalierungsaktivitäten wurde erfolgreich abgeschlossen. |
| Wird aktualisiert | Die Autoskalierungskonfiguration für den Cluster wird aktualisiert. |
| HDInsight-Konfiguration | Es wird ein Vorgang für das Hoch- oder Herunterskalieren des Clusters ausgeführt. |
| Fehler beim Aktualisieren | HDInsight hat beim Aktualisieren der Autoskalierungskonfiguration Fehler festgestellt. Kunden können wählen, ob sie den Aktualisierungsvorgang wiederholen oder die Autoskalierung deaktivieren möchten. |
| Fehler | Es gibt ein Problem mit dem Cluster, sodass er kann nicht verwendet werden kann. Löschen Sie diesen Cluster, und erstellen Sie einen neuen. |
Um die aktuelle Anzahl der Knoten in Ihrem Cluster anzuzeigen, wechseln Sie zum Diagramm Clustergröße auf der Seite Übersicht für den Cluster. Sie können auch unter Einstellungen die Option Clustergröße auswählen.
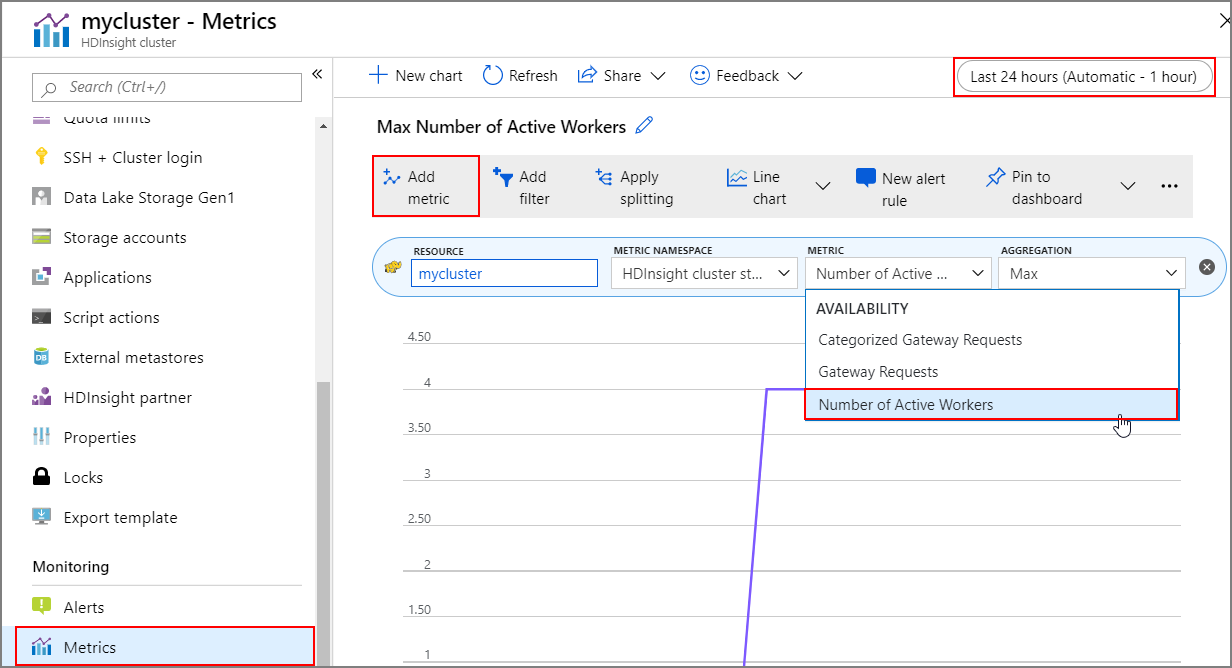
Vorgangsverlauf
Sie können den Verlauf des zentralen Hoch- und Herunterskalierens des Clusters als Teil der Clustermetriken anzeigen. Sie können auch alle Skalierungsaktionen des letzten Tags, der letzten Woche oder eines anderen Zeitraums auflisten.
Wählen Sie unter ÜberwachungMetriken aus. Wählen Sie dann im Dropdownfeld Metrik die Option Metrik hinzufügen und dann Anzahl der aktiven Worker aus. Wählen Sie die Schaltfläche in der rechten oberen Ecke aus, um den Zeitbereich zu ändern.
Bewährte Methoden
Berücksichtigen der Latenz von Vorgängen zum Hoch- und Herunterskalieren
Es kann 10 bis 20 Minuten dauern, bis ein Skalierungsvorgang abgeschlossen ist. Sie sollten diese Verzögerung einplanen, wenn Sie einen benutzerdefinierten Zeitplan einrichten. Wenn Sie beispielsweise um 9:00 Uhr eine Clustergröße von 20 benötigen, sollten Sie den Zeitplantrigger auf einen früheren Zeitpunkt festlegen, z. B. 8:30 Uhr oder früher, damit der Skalierungsvorgang um 9:00 Uhr abgeschlossen ist.
Vorbereiten für das zentrale Herunterskalieren
Beim zentralen Herunterskalieren des Clusters werden die Knoten von Autoskalierung außer Betrieb genommen, um die Zielgröße zu erreichen. Falls auf diesen Knoten Aufgaben ausgeführt werden, wartet die lastbasierte Autoskalierung, bis diese für Spark- und Hadoop-Cluster abgeschlossen sind. Da jeder Workerknoten auch eine Rolle im HDFS innehat, werden die temporären Daten auf die restlichen Workerknoten verschoben. Stellen Sie sicher, dass auf den verbleibenden Knoten genügend Speicherplatz vorhanden ist, um alle temporären Daten zu hosten.
Hinweis
Beim zeitplanbasierten automatischen Herunterskalieren wird keine ordnungsgemäße Außerbetriebnahme unterstützt. Dies kann zu Auftragsfehlern während eines Herunterskalierungsvorgangs führen, und es wird empfohlen, Zeitpläne auf der Grundlage der erwarteten Auftragszeitplanmuster zu planen, um ausreichend Zeit für den Abschluss der laufenden Aufträge einzuplanen. Beim Festlegen der Zeitpläne können Sie sich an der Spanne der Ausführungszeiten in der Vergangenheit orientieren, um Auftragsfehler zu vermeiden.
Konfigurieren der zeitplanbasierten Autoskalierung basierend auf dem Nutzungsmuster
Sie müssen Ihr Clusternutzungsmuster verstehen, wenn Sie die zeitplanbasierte Autoskalierung konfigurieren. Das Grafana-Dashboard kann Ihnen helfen, Ihre Abfragelast und Ausführungsslots zu verstehen. Sie können die verfügbaren Executorslots und die Gesamtzahl der Executorslots über das Dashboard abrufen.
Hier finden Sie eine Methode, mit der Sie schätzen können, wie viele Workerknoten benötigt werden. Es wird empfohlen, einen zusätzlichen Puffer von 10 % einzuplanen, um Abweichungen bei der Workload zu verarbeiten.
Anzahl der genutzten Executorslots = Gesamtzahl der Executorslots – Gesamtzahl der verfügbaren Executorslots
Anzahl erforderlicher Workerknoten = Anzahl der tatsächlich verwendeten Executorslots / (hive.llap.daemon.num.executors + hive.llap.daemon.task.scheduler.wait.queue.size)
*hive.llap.daemon.num.executors ist konfigurierbar, und der Standardwert lautet 4.
*hive.llap.daemon.task.scheduler.wait.queue.size ist konfigurierbar, und der Standardwert ist 10.
Benutzerdefinierte Skriptaktionen
Benutzerdefinierte Skriptaktionen werden hauptsächlich zum Anpassen der Knoten (HeadNode/WorkerNodes) verwendet – so können unsere Kunden bestimmte Bibliotheken und Tools konfigurieren, die sie verwenden. Ein häufiger Anwendungsfall sind im Cluster ausgeführte Aufträge, für die Abhängigkeiten von der Drittanbieterbibliothek vorhanden sind, die im Besitz des Kunden ist. Diese sollte auf den Knoten verfügbar sein, damit Aufträge erfolgreich ausgeführt werden können. Für die Autoskalierung werden aktuell benutzerdefinierte Skriptaktionen unterstützt, die beibehalten werden. Jedes Mal, wenn dem Cluster beim Hochskalieren neue Knoten hinzugefügt werden, werden diese Skriptaktionen ausgeführt, und danach werden den Knoten Container oder Aufträge zugeordnet. Benutzerdefinierte Skriptaktionen helfen zwar beim Bootstrapping der neuen Knoten, es ist aber ratsam, sie auf ein Minimum zu beschränken, da sich sonst die allgemeine Latenz beim Hochskalieren erhöht, was Auswirkungen auf die geplanten Aufträge haben kann.
Beachten der Clustermindestgröße
Skalieren Sie den Cluster nicht auf weniger als drei Knoten herunter. Die Skalierung des Clusters auf weniger als drei Knoten kann dazu führen, dass der Cluster aufgrund unzureichender Dateireplikation im abgesicherten Modus hängen bleibt. Weitere Informationen finden Sie unter Hängenbleiben im abgesicherten Modus.
Support für Microsoft Entra Domain Services und Skalierungsvorgänge
Wenn Sie einen HDInsight-Cluster mit einem Enterprise-Sicherheitspaket (ESP) verwenden, das mit einer von Microsoft Entra Domain Services verwalteten Domäne verknüpft ist, wird empfohlen, die Last in AMicrosoft Entra Domain Serviceszu drosseln. Bei einer Synchronisierung mit komplexen Verzeichnisstrukturen mit Bereichsumfang wird empfohlen, Auswirkungen auf Skalierungsvorgänge zu vermeiden.
Festlegen der Hive-Konfiguration „Maximum Total Concurrent Queries“ für das Szenario für Spitzenlast
Die Hive-Konfiguration Maximum Total Concurrent Queries (Maximale Anzahl gleichzeitiger Abfragen) in Ambari wird durch Autoskalierungsereignisse nicht geändert. Dies bedeutet, dass der Hive Server 2 Interactive Service jeweils immer nur die angegebene Anzahl gleichzeitiger Abfragen verarbeiten kann, auch wenn die Anzahl der Interactive Query-Daemons last- oder zeitplanbasiert hoch- und herunterskaliert wird. Die allgemeine Empfehlung besteht darin, diese Konfiguration entsprechend dem Spitzenlastszenario festzulegen, damit kein manueller Eingriff erforderlich wird.
Es können jedoch Hive Server 2-Neustartfehler auftreten, wenn nur wenige Workerknoten vorhanden sind und der Wert für die maximale Anzahl gleichzeitiger Abfragen zu hoch konfiguriert ist. Sie benötigen eine Mindestanzahl von Workerknoten, die die angegebene Anzahl von Tez Ams abdecken können (entspricht der „Maximum Total Concurrent Queries“-Konfiguration).
Begrenzungen
Anzahl der Interactive Query-Daemons
Bei Interactive Query-Clustern mit aktivierter Autoskalierung wird bei einer automatischen Hochskalierung/Herunterskalierung auch die Anzahl der Interactive Query-Daemons entsprechend der Anzahl aktiver Workerknoten hochskaliert/herunterskaliert. Die Änderung der Anzahl der Daemons wird nicht in der num_llap_nodes-Konfiguration in Ambari gespeichert. Wenn Hive-Dienste manuell neu gestartet werden, wird die Anzahl der Interactive Query-Daemons entsprechend der Konfiguration in Ambari zurückgesetzt.
Wird der Interactive Query-Dienst manuell neu gestartet, müssen Sie die num_llap_node-Konfiguration (die Anzahl der Knoten, die zum Ausführen des Hive-Interactive Query-Daemons benötigt werden) unter Advanced hive-interactive-env entsprechend der aktuellen Anzahl aktiver Workerknoten ändern. Interactive Query Cluster unterstützt nur die zeitplanbasierte Autoskalierung.
Nächste Schritte
Erfahren Sie mehr über das manuelle Skalieren von Clustern in den Skalierungsrichtlinien.