Verwenden von Delta Lake in Azure HDInsight auf AKS mit Apache Spark™ Cluster (Vorschau)
Wichtig
Azure HDInsight auf AKS wurde am 31. Januar 2025 eingestellt. Erfahren Sie mehr über durch diese Ankündigung.
Sie müssen Ihre Workloads zu Microsoft Fabric oder ein gleichwertiges Azure-Produkt migrieren, um eine abrupte Beendigung Ihrer Workloads zu vermeiden.
Wichtig
Dieses Feature befindet sich derzeit in der Vorschau. Die zusätzlichen Nutzungsbedingungen für Microsoft Azure Previews weitere rechtliche Bestimmungen enthalten, die für Azure-Features gelten, die in der Betaversion, in der Vorschau oder auf andere Weise noch nicht in die allgemeine Verfügbarkeit veröffentlicht werden. Informationen zu dieser spezifischen Vorschau finden Sie unter Azure HDInsight auf AKS - Vorschau Informationen. Für Fragen oder Featurevorschläge senden Sie bitte eine Anfrage an AskHDInsight mit den Details und folgen Sie uns, um weitere Updates von der Azure HDInsight Communityzu erhalten.
Azure HDInsight auf AKS ist ein verwalteter cloudbasierter Dienst für Big Data Analytics, der Organisationen bei der Verarbeitung großer Datenmengen hilft. In diesem Lernprogramm wird gezeigt, wie Sie Delta Lake in Azure HDInsight auf AKS mit Apache Spark-Cluster™ verwenden.
Voraussetzung
Erstellen eines Apache Spark-Clusters™ in Azure HDInsight auf AKS
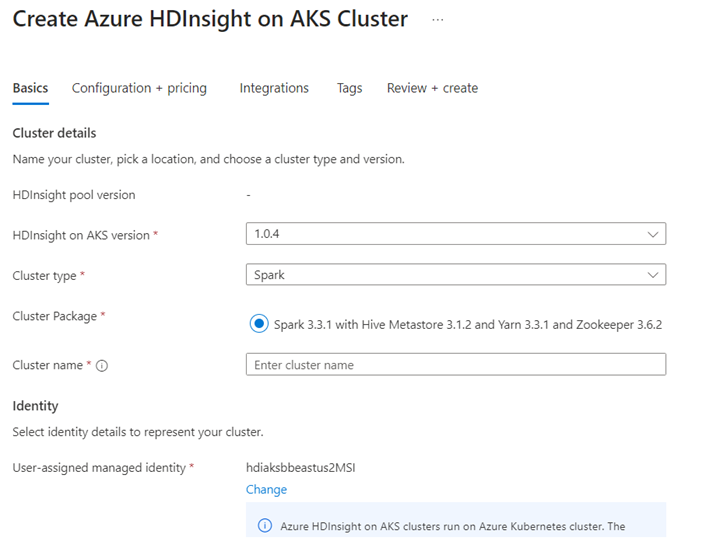
Führen Sie das Delta Lake-Szenario im Jupyter-Notizbuch aus. Erstellen Sie ein Jupyter-Notizbuch, und wählen Sie beim Erstellen eines Notizbuchs "Spark" aus, da sich das folgende Beispiel in Scala befindet.
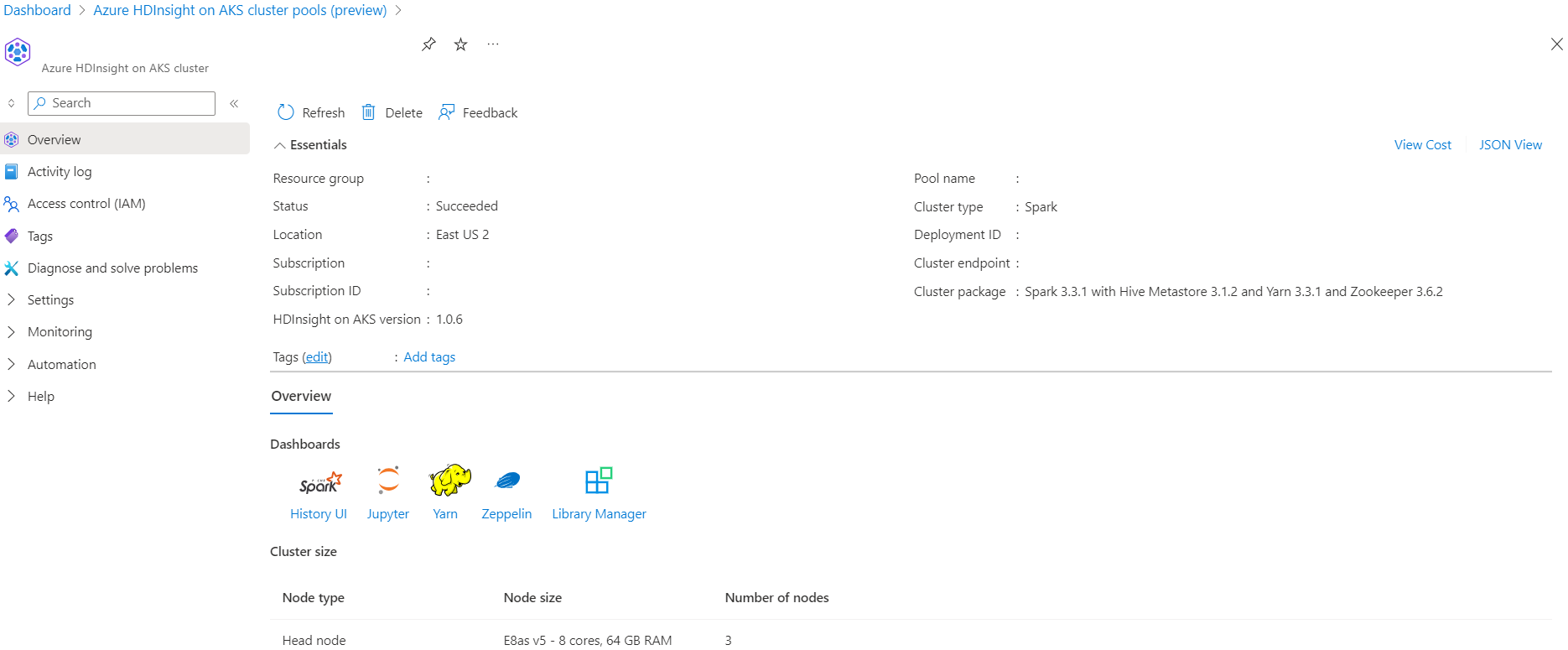


Szenario
- Read NYC Taxi Laminat Data Format - Liste der Parkett dateien URLs werden von NYC Taxi & Limousine Commissionbereitgestellt.
- Führen Sie für jede URL (Datei) eine Transformation durch, und speichern Sie sie im Delta-Format.
- Berechnen Sie die durchschnittliche Entfernung, die durchschnittlichen Kosten pro Meile und die durchschnittlichen Kosten aus der Delta-Tabelle mithilfe der inkrementellen Last.
- Speichern Sie berechneten Wert aus Schritt#3 im Delta-Format im KPI-Ausgabeordner.
- Delta-Tabelle im Ausgabeordner "Delta-Format" erstellen (automatische Aktualisierung).
- Der KPI-Ausgabeordner verfügt über mehrere Versionen der durchschnittliche Entfernung und die durchschnittlichen Kosten pro Meile für eine Reise.
Erforderliche Konfigurationen für Delta Lake bereitstellen
Delta Lake mit Apache Spark-Kompatibilitätsmatrix – Delta Lake, ändern Sie die Delta Lake-Version basierend auf der Apache Spark-Version.
%%configure -f
{ "conf": {"spark.jars.packages": "io.delta:delta-core_2.12:1.0.1,net.andreinc:mockneat:0.4.8",
"spark.sql.extensions":"io.delta.sql.DeltaSparkSessionExtension",
"spark.sql.catalog.spark_catalog":"org.apache.spark.sql.delta.catalog.DeltaCatalog"
}
}

Daten auflisten
Anmerkung
Diese Datei-URLs stammen von NYC Taxi & Limousine Commission.
import java.io.File
import java.net.URL
import org.apache.commons.io.FileUtils
import org.apache.hadoop.fs._
// data file object is being used for future reference in order to read parquet files from HDFS
case class DataFile(name:String, downloadURL:String, hdfsPath:String)
// get Hadoop file system
val fs:FileSystem = FileSystem.get(spark.sparkContext.hadoopConfiguration)
val fileUrls= List(
"https://d37ci6vzurychx.cloudfront.net/trip-data/fhvhv_tripdata_2022-01.parquet"
)
// Add a file to be downloaded with this Spark job on every node.
val listOfDataFile = fileUrls.map(url=>{
val urlPath=url.split("/")
val fileName = urlPath(urlPath.size-1)
val urlSaveFilePath = s"/tmp/${fileName}"
val hdfsSaveFilePath = s"/tmp/${fileName}"
val file = new File(urlSaveFilePath)
FileUtils.copyURLToFile(new URL(url), file)
// copy local file to HDFS /tmp/${fileName}
// use FileSystem.copyFromLocalFile(boolean delSrc, boolean overwrite, Path src, Path dst)
fs.copyFromLocalFile(true,true,new org.apache.hadoop.fs.Path(urlSaveFilePath),new org.apache.hadoop.fs.Path(hdfsSaveFilePath))
DataFile(urlPath(urlPath.size-1),url, hdfsSaveFilePath)
})

Ausgabeverzeichnis erstellen
Der Speicherort, an dem Sie die Delta-Formatausgabe erstellen möchten. Ändern Sie bei Bedarf die Variablen transformDeltaOutputPath und avgDeltaOutputKPIPath.
-
avgDeltaOutputKPIPath– zum Speichern des durchschnittlichen KPI im Delta-Format -
transformDeltaOutputPath– Transformierte Ausgabe im Delta-Format speichern
import org.apache.hadoop.fs._
// this is used to store source data being transformed and stored delta format
val transformDeltaOutputPath = "/nyctaxideltadata/transform"
// this is used to store Average KPI data in delta format
val avgDeltaOutputKPIPath = "/nyctaxideltadata/avgkpi"
// this is used for POWER BI reporting to show Month on Month change in KPI (not in delta format)
val avgMoMKPIChangePath = "/nyctaxideltadata/avgMoMKPIChangePath"
// create directory/folder if not exist
def createDirectory(dataSourcePath: String) = {
val fs:FileSystem = FileSystem.get(spark.sparkContext.hadoopConfiguration)
val path = new Path(dataSourcePath)
if(!fs.exists(path) && !fs.isDirectory(path)) {
fs.mkdirs(path)
}
}
createDirectory(transformDeltaOutputPath)
createDirectory(avgDeltaOutputKPIPath)
createDirectory(avgMoMKPIChangePath)

Erstellen von Delta-Formatdaten aus dem Parquet-Format
Eingabedaten stammen aus
listOfDataFile, wobei die Daten aus https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.page heruntergeladen wurden.Laden Sie die Daten einzeln, um die Zeitreise und Version zu veranschaulichen.
Durchführen von Transformationen und Berechnen des folgenden Geschäfts-KPI bei inkrementeller Last:
- Der durchschnittliche Abstand
- Die durchschnittlichen Kosten pro Meile
- Die durchschnittlichen Kosten
Speichern von transformierten und KPI-Daten im Delta-Format
import org.apache.spark.sql.functions.udf import org.apache.spark.sql.DataFrame // UDF to compute sum of value paid by customer def totalCustPaid = udf((basePassengerFare:Double, tolls:Double,bcf:Double,salesTax:Double,congSurcharge:Double,airportFee:Double, tips:Double) => { val total = basePassengerFare + tolls + bcf + salesTax + congSurcharge + airportFee + tips total }) // read parquet file from spark conf with given file input // transform data to compute total amount // compute kpi for the given file/batch data def readTransformWriteDelta(fileName:String, oldData:Option[DataFrame], format:String="parquet"):DataFrame = { val df = spark.read.format(format).load(fileName) val dfNewLoad= df.withColumn("total_amount",totalCustPaid($"base_passenger_fare",$"tolls",$"bcf",$"sales_tax",$"congestion_surcharge",$"airport_fee",$"tips")) // union with old data to compute KPI val dfFullLoad= oldData match { case Some(odf)=> dfNewLoad.union(odf) case _ => dfNewLoad } dfFullLoad.createOrReplaceTempView("tempFullLoadCompute") val dfKpiCompute = spark.sql("SELECT round(avg(trip_miles),2) AS avgDist,round(avg(total_amount/trip_miles),2) AS avgCostPerMile,round(avg(total_amount),2) avgCost FROM tempFullLoadCompute") // save only new transformed data dfNewLoad.write.mode("overwrite").format("delta").save(transformDeltaOutputPath) //save compute KPI dfKpiCompute.write.mode("overwrite").format("delta").save(avgDeltaOutputKPIPath) // return incremental dataframe for next set of load dfFullLoad } // load data for each data file, use last dataframe for KPI compute with the current load def loadData(dataFile: List[DataFile], oldDF:Option[DataFrame]):Boolean = { if(dataFile.isEmpty) { true } else { val nextDataFile = dataFile.head val newFullDF = readTransformWriteDelta(nextDataFile.hdfsPath,oldDF) loadData(dataFile.tail,Some(newFullDF)) } } val starTime=System.currentTimeMillis() loadData(listOfDataFile,None) println(s"Time taken in Seconds: ${(System.currentTimeMillis()-starTime)/1000}")
Delta-Format mit Delta-Tabelle lesen
- Transformierte Daten lesen
- KPI-Daten lesen
import io.delta.tables._ val dtTransformed: io.delta.tables.DeltaTable = DeltaTable.forPath(transformDeltaOutputPath) val dtAvgKpi: io.delta.tables.DeltaTable = DeltaTable.forPath(avgDeltaOutputKPIPath)
Print-Schema
- Drucke das Delta-Tabellenschema für transformierte und durchschnittliche KPI-Daten1.
// transform data schema dtTransformed.toDF.printSchema // Average KPI Data Schema dtAvgKpi.toDF.printSchema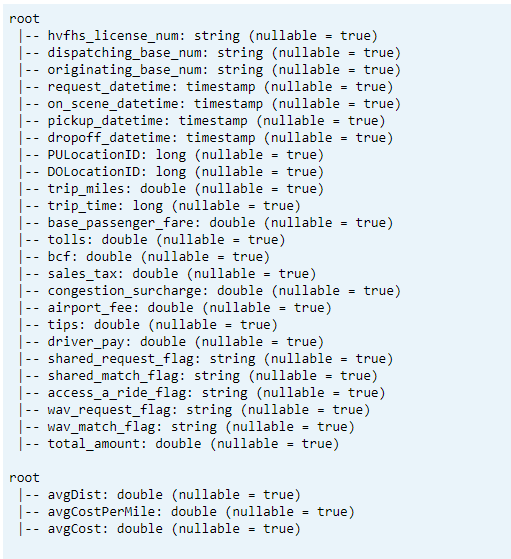
Letzte berechnete KPI aus Datentabelle anzeigen
dtAvgKpi.toDF.show(false)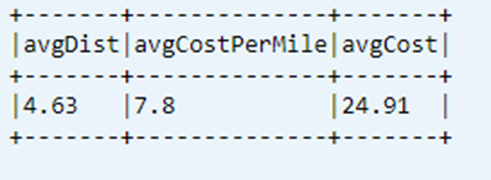


Berechneten KPI-Verlauf anzeigen
In diesem Schritt wird der Verlauf der KPI-Transaktionstabelle von _delta_log angezeigt.
dtAvgKpi.history().show(false)

Anzeigen von KPI-Daten nach jedem Laden der Daten
- Mithilfe von Zeitreisen können Sie KPI-Änderungen nach jedem Ladevorgang anzeigen.
- Sie können alle Versionsänderungen im CSV-Format bei
avgMoMKPIChangePathspeichern, damit Power BI diese Änderungen lesen kann.
val dfTxLog = spark.read.json(s"${transformDeltaOutputPath}/_delta_log/*.json")
dfTxLog.select(col("add")("path").alias("file_path")).withColumn("version",substring(input_file_name(),-6,1)).filter("file_path is not NULL").show(false)

Referenz
- Apache, Apache Spark, Spark und verbundene Open Source-Projektnamen sind Marken der Apache Software Foundation (ASF).