Erstellen eines Spark-Clusters in HDInsight auf AKS (Vorschau)
Wichtig
Azure HDInsight auf AKS wurde am 31. Januar 2025 eingestellt. Erfahren Sie mehr darüber mit dieser Ankündigung.
Sie müssen Ihre Workloads zu Microsoft Fabric oder ein gleichwertiges Azure-Produkt migrieren, um eine abrupte Beendigung Ihrer Workloads zu vermeiden.
Wichtig
Dieses Feature befindet sich derzeit in der Vorschau. Die zusätzlichen Nutzungsbedingungen für Microsoft Azure Previews weitere rechtliche Bestimmungen enthalten, die für Azure-Features gelten, die in der Betaversion, in der Vorschau oder auf andere Weise noch nicht in die allgemeine Verfügbarkeit veröffentlicht werden. Informationen zu dieser spezifischen Vorschau finden Sie unter Azure HDInsight auf AKS-Vorschauinformationen. Für Fragen oder Funktionsvorschläge senden Sie bitte eine Anfrage an AskHDInsight mit den Details und folgen Sie uns, um weitere Updates zu Azure HDInsight Communityzu erhalten.
Sobald die Abonnementvoraussetzungen und Ressourcenvoraussetzungen Schritte abgeschlossen sind und Sie einen Clusterpool bereitgestellt haben, verwenden Sie weiterhin das Azure-Portal, um einen Spark-Cluster zu erstellen. Sie können das Azure-Portal verwenden, um einen Apache Spark-Cluster im Clusterpool zu erstellen. Anschließend können Sie ein Jupyter-Notizbuch erstellen und es verwenden, um Spark SQL-Abfragen für Apache Hive-Tabellen auszuführen.
Geben Sie im Azure-Portal Clusterpools ein, und wählen Sie Clusterpools aus, um zur Seite "Clusterpools" zu wechseln. Wählen Sie auf der Seite "Clusterpools" den Clusterpool aus, in dem Sie einen neuen Spark-Cluster hinzufügen können.
Klicken Sie auf der Seite für einen bestimmten Clusterpool auf + Neuer Cluster.
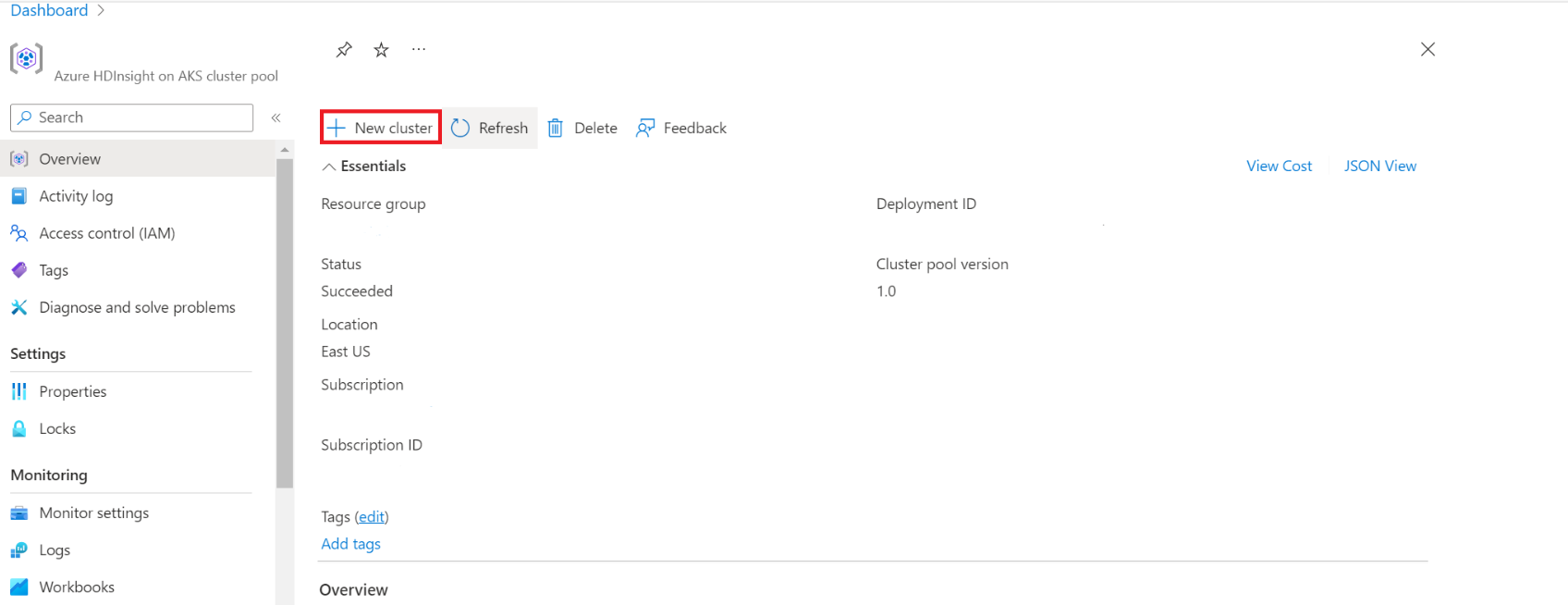
In diesem Schritt wird die Seite zum Erstellen des Clusters geöffnet.
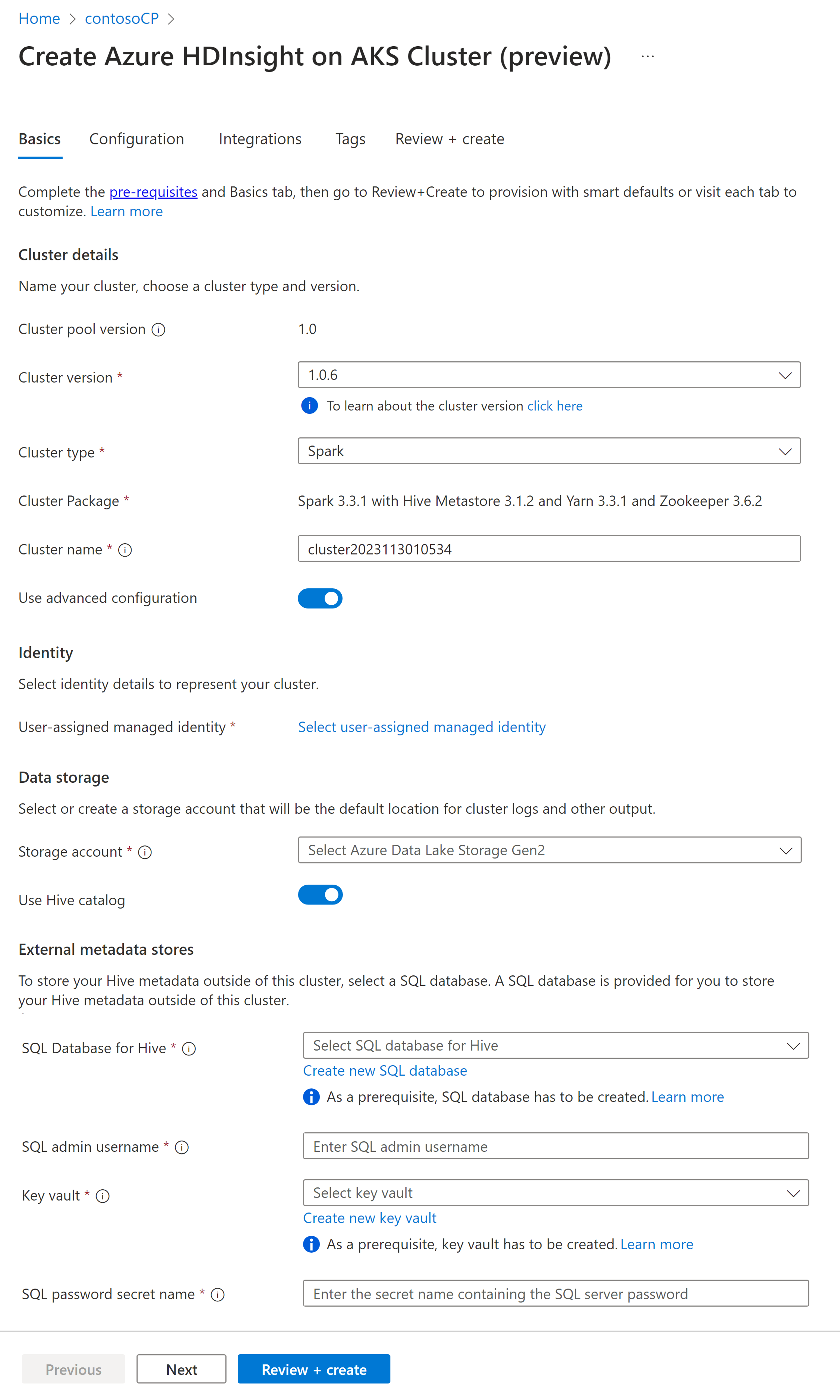
Eigentum Beschreibung Abonnement Das Azure-Abonnement, das im Abschnitt "Voraussetzungen" für die Verwendung mit HDInsight auf AKS registriert wurde, wird vorab ausgefüllt sein. Ressourcengruppe Die gleiche Ressourcengruppe wie der Clusterpool wird vorab befüllt. Region Die gleiche Region wie der Clusterpool und die virtuelle Region werden bereits ausgefüllt. Clusterpool Der Name des Clusterpools wird voreingestellt. HDInsight-Poolversion Die Version des Clusterpools wird im Voraus aus der Auswahl bei der Poolerstellung ausgefüllt. HDInsight für AKS-Version Geben Sie die HDI in der AKS-Version an Clustertyp Wählen Sie in der Dropdownliste "Spark" aus. Cluster-Version Wählen Sie die version der zu verwendenden Bildversion aus. Clustername Geben Sie den Namen des neuen Clusters ein. Vom Benutzer zugewiesene verwaltete Identität Wählen Sie die vom Benutzer zugewiesene verwaltete Identität aus, die als Verbindungszeichenfolge mit dem Speicher funktioniert. Speicherkonto Wählen Sie das zuvor erstellte Speicherkonto aus, das als primärer Speicher für den Cluster verwendet werden soll. Containername Wählen Sie den Containernamen (eindeutig) aus, wenn er bereits erstellt ist, oder erstellen Sie einen neuen Container. Hive-Katalog (optional) Auswählen des zuvor erstellten Hive-Metastores (Azure SQL DB) SQL-Datenbank für Hive Wählen Sie in der Dropdownliste die SQL-Datenbank aus, in der Hive-Metastore-Tabellen hinzugefügt werden sollen. SQL-Administratorbenutzername Geben Sie den SQL-Administratorbenutzernamen ein. Schlüsseltresor Wählen Sie in der Dropdownliste das Key Vault aus, das ein Geheimnis mit einem Kennwort für den SQL-Administrator-Benutzernamen enthält. SQL-Passwort-Geheimnisname Geben Sie den geheimen Namen aus dem Key Vault ein, in dem das SQL DB-Kennwort gespeichert ist. Anmerkung
- Derzeit unterstützen HDInsight nur MS SQL Server-Datenbanken.
- Aufgrund der Hive-Einschränkung wird das Zeichen "-" (Bindestrich) im Metastore-Datenbanknamen nicht unterstützt.
Wählen Sie Weiter: Konfiguration + Preisgestaltung, um fortzufahren.
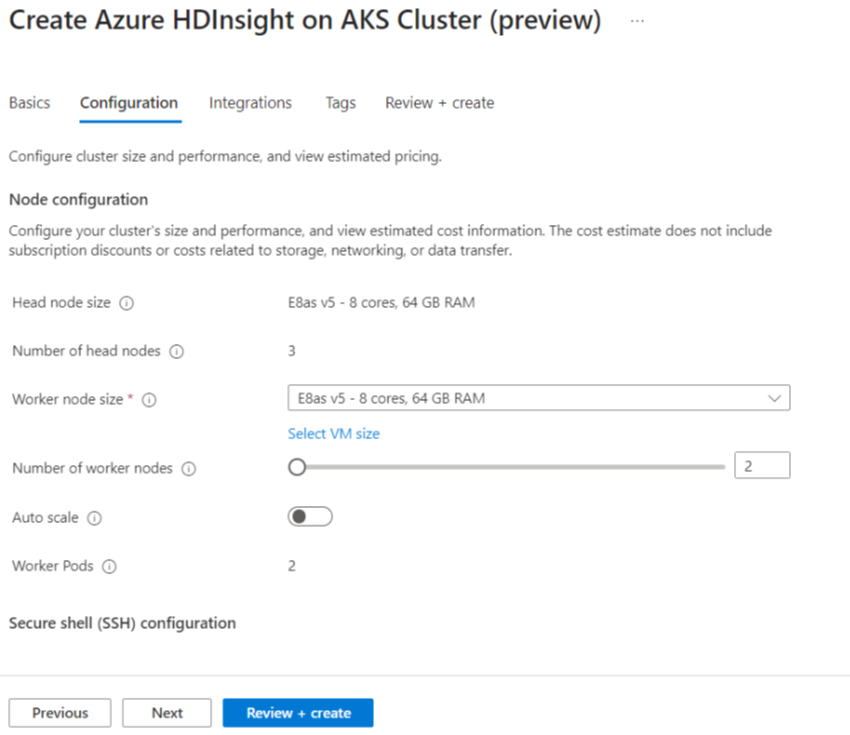
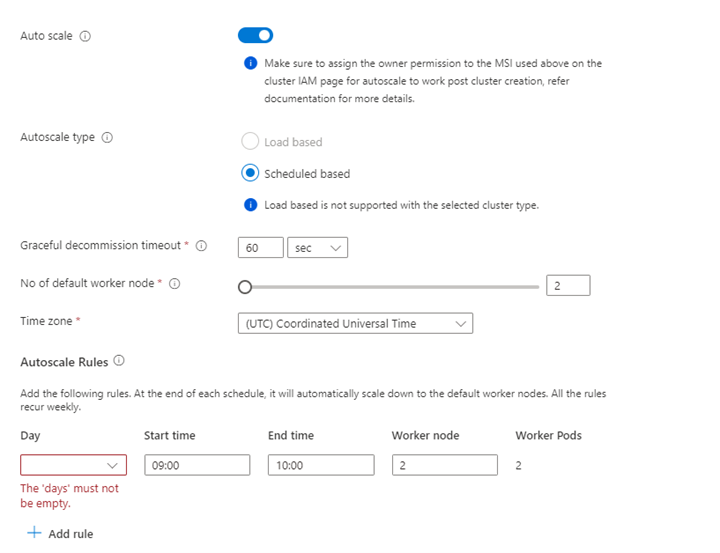
Eigentum Beschreibung Knotengröße Wählen Sie die Knotengröße aus, die für die Spark-Knoten verwendet werden soll. Anzahl der Arbeitsknoten Wählen Sie die Anzahl der Knoten für Spark-Cluster aus. Aus diesen sind drei Knoten für Koordinatoren und Systemdienste reserviert, die verbleibenden Knoten sind Spark-Workern, einem Worker pro Knoten, zugeordnet. In einem Fünf-Knoten-Cluster gibt es z. B. zwei Mitarbeiter Autoskalierung Klicken Sie auf die Umschaltfläche, um die AutoSkala zu aktivieren. Autoskalierungstyp auswählen aus der lastbasierten oder zeitplanbasierten automatischen Skalierung Timeout der reibungslosen Außerbetriebnahme Timeout für sanfte Stilllegung angeben Anzahl der Standardarbeitsknoten Wählen Sie die Anzahl der Knoten für die automatische Skalierung aus. Zeitzone Wählen Sie die Zeitzone aus. Regeln für die automatische Skalierung Wählen Sie den Tag, die Startzeit, die Endzeit und die Anzahl der Arbeitsknoten aus. Aktivieren von SSH Wenn diese Option aktiviert ist, können Sie Präfix und Anzahl von SSH-Knoten definieren. Klicken Sie auf Weiter: Integrationen, um Log Analytics für die Protokollierung zu aktivieren und auszuwählen.
Azure Prometheus für überwachung und Metriken kann nach der Clustererstellung aktiviert werden.
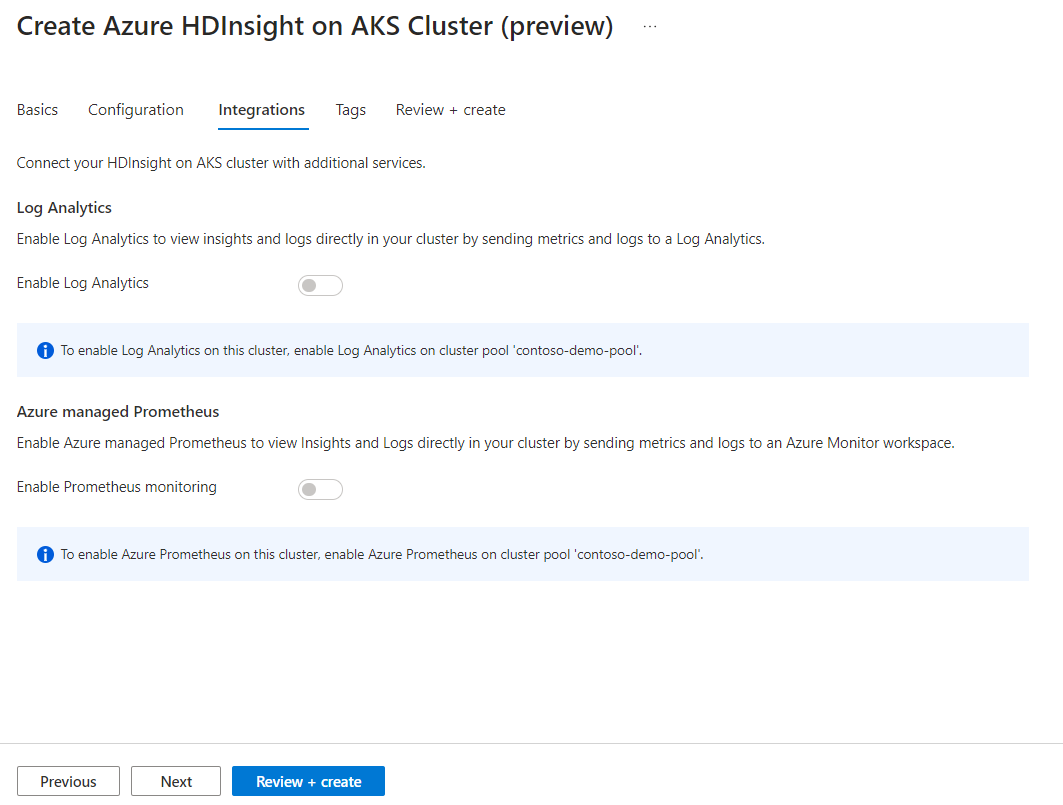
Klicken Sie auf Weiter: Tags, um mit der nächsten Seite fortzufahren.

Geben Sie auf der Seite Tags alle Tags ein, die Sie Ihrer Ressource hinzufügen möchten.
Eigentum Beschreibung Name Wahlfrei. Geben Sie einen Namen wie HDInsight in AKS Private Preview ein, um alle Ressourcen zu identifizieren, die Ihren Ressourcen zugeordnet sind. Wert Lassen Sie diesen Wert leer. Ressource Alle ausgewählten Ressourcen auswählen Klicken Sie auf Weiter: Überprüfen und erstellen Sie.
Suchen Sie auf der Seite Überprüfen und Erstellennach der Meldung "Validierung erfolgreich" oben auf der Seite, und klicken Sie dann auf Erstellen.
Die Bereitstellung wird Seite ausgeführt, auf der der Cluster erstellt wird. Es dauert 5 bis 10 Minuten, um den Cluster zu erstellen. Nachdem der Cluster erstellt wurde, wird die Meldung Ihre Bereitstellung ist abgeschlossen angezeigt. Wenn Sie von der Seite weg navigieren, können Sie Ihre Benachrichtigungen auf den Status überprüfen.
Wechseln Sie zur Clusterübersichtsseite, wo Endpunktlinks angezeigt werden.