Apache Flink® Job-Orchestrierung mit Azure Data Factory Workflow Orchestration Manager (unterstützt von Apache Airflow)
Wichtig
Azure HDInsight auf AKS wurde am 31. Januar 2025 eingestellt. Erfahren Sie mehr mit dieser Ankündigung.
Sie müssen Ihre Workloads zu Microsoft Fabric oder ein gleichwertiges Azure-Produkt migrieren, um eine abrupte Beendigung Ihrer Workloads zu vermeiden.
Wichtig
Dieses Feature befindet sich derzeit in der Vorschau. Die zusätzlichen Nutzungsbedingungen für Microsoft Azure Previews weitere rechtliche Bestimmungen enthalten, die für Azure-Features gelten, die in der Betaversion, in der Vorschau oder auf andere Weise noch nicht in die allgemeine Verfügbarkeit veröffentlicht werden. Informationen zu dieser spezifischen Vorschau finden Sie unter Azure HDInsight auf AKS-Vorschauinformationen. Für Fragen oder Funktionsvorschläge senden Sie bitte eine Anfrage an AskHDInsight mit den Details und folgen Sie uns für weitere Informationen zur Azure HDInsight Community.
In diesem Artikel wird die Verwaltung eines Flink-Auftrags mithilfe Azure REST-API- und der Orchestrierungsdatenpipeline mit Azure Data Factory Workflow Orchestration Manager behandelt. Azure Data Factory Workflow Orchestration Manager Dienst ist eine einfache und effiziente Möglichkeit, Apache Airflow Umgebungen zu erstellen und zu verwalten, wodurch Sie Datenpipelines problemlos in großem Maßstab ausführen können.
Apache Airflow ist eine Open-Source-Plattform, die programmgesteuert komplexe Datenworkflows erstellt, geplant und überwacht. Sie können eine Reihe von Aufgaben definieren, die als Operatoren bezeichnet werden und in gerichtete azyklische Grafen (DAGs) kombiniert werden können, um Datenpipelines darzustellen.
Das folgende Diagramm zeigt die Platzierung von Airflow, Key Vault und HDInsight auf AKS in Azure.

Mehrere Azure-Dienstprinzipale werden basierend auf dem Umfang erstellt, um den benötigten Zugriff einzuschränken und den Lebenszyklus von Clientanmeldeinformationen unabhängig voneinander zu verwalten.
Es wird empfohlen, Zugriffstasten oder geheime Schlüssel regelmäßig zu drehen.
Setupschritte
Laden Sie Ihren Flink Job jar in das Speicherkonto hoch. Dabei kann es sich um das primäre Speicherkonto handeln, das dem Flink-Cluster oder einem anderen Speicherkonto zugeordnet ist, bei dem Sie die Rolle "Speicher-Blob-Datenbesitzer" dem vom Benutzer zugewiesenen MSI zuweisen sollten, das für den Cluster in diesem Speicherkonto verwendet wird.
Azure Key Vault – Sie können diesem Lernprogramm folgen, um einen neuen Azure Key Vault- zu erstellen, falls Sie keins haben.
Erstellen Sie Microsoft Entra-Serviceprinzipal für den Zugriff auf Key Vault – Erteilen Sie die Berechtigung für den Zugriff auf Azure Key Vault mit der Rolle "Key Vault Secrets Officer", und notieren Sie sich "appId", "Kennwort" und "Mandant" aus der Antwort. Wir müssen für Airflow das gleiche verwenden, um Key Vault-Speicher als Backends zum Speichern vertraulicher Informationen zu nutzen.
az ad sp create-for-rbac -n <sp name> --role “Key Vault Secrets Officer” --scopes <key vault Resource ID>Aktivieren Sie Azure Key Vault für Workflow Orchestration Manager, um Ihre vertraulichen Informationen sicher und zentral zu speichern und zu verwalten. Dadurch können Sie Variablen und Verbindungen verwenden, die automatisch in Azure Key Vault gespeichert werden. Die Namen der Verbindungen und Variablen müssen mit dem in AIRFLOW__SECRETS__BACKEND_KWARGS definierten „variables_prefix“ versehen werden. Wenn variables_prefix z. B. einen Wert als hdinsight-aks-Variablen aufweist, sollten Sie für einen Variablenschlüssel "hello" die Variable unter hdinsight-aks-variable -hello speichern.
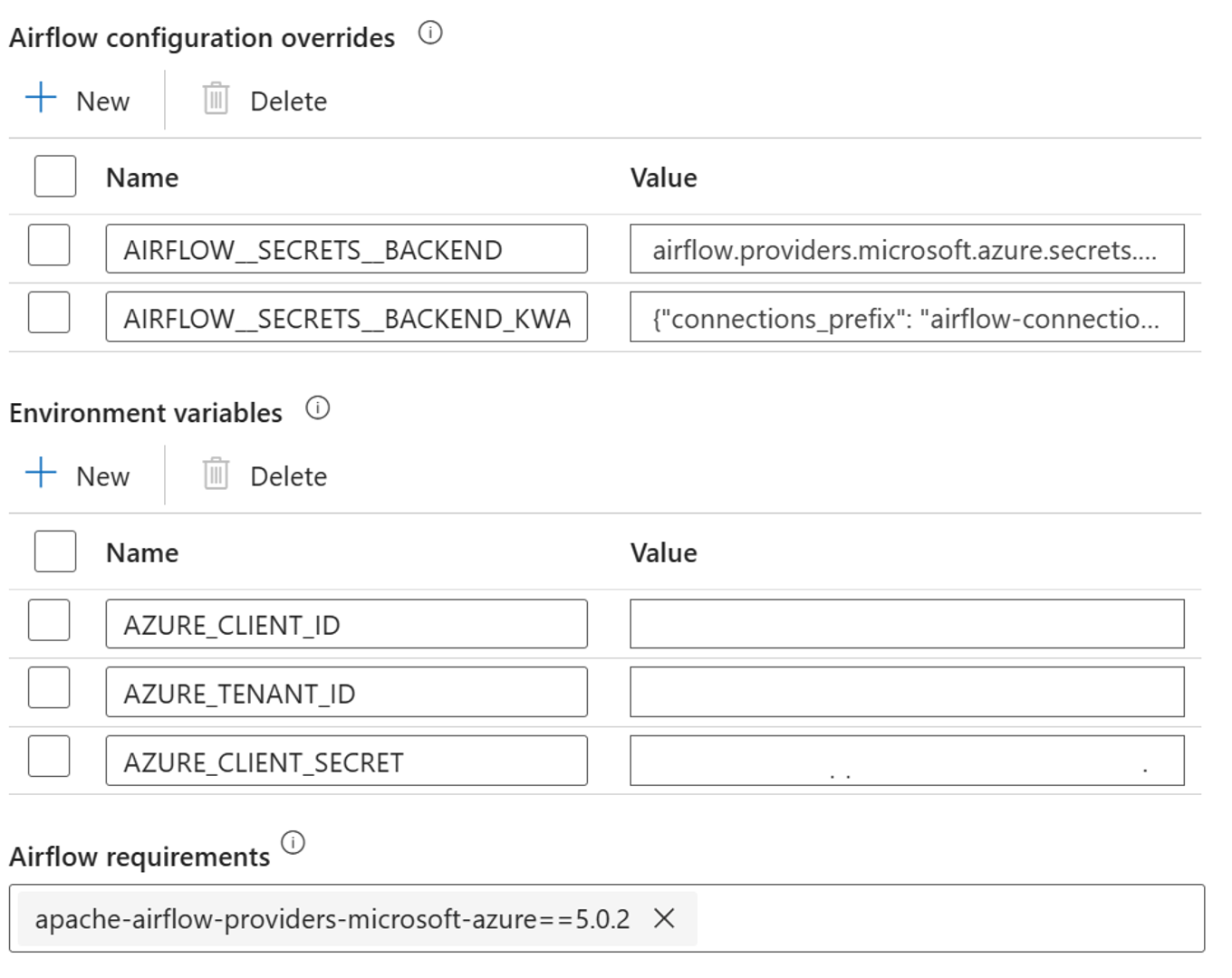
Fügen Sie die folgenden Einstellungen für die Airflow-Konfigurationsüberschreibungen in den Eigenschaften der integrierten Laufzeitumgebung hinzu:
AIRFLOW__SECRETS__BACKEND:
"airflow.providers.microsoft.azure.secrets.key_vault.AzureKeyVaultBackend"AIRFLOW__SECRETS__BACKEND_KWARGS:
"{"connections_prefix": "airflow-connections", "variables_prefix": "hdinsight-aks-variables", "vault_url": <your keyvault uri>}”
Fügen Sie die folgende Einstellung für die Konfiguration der Umgebungsvariablen in den integrierten Laufzeiteigenschaften von Airflow hinzu:
AZURE_CLIENT_ID =
<App Id from Create Azure AD Service Principal>AZURE_TENANT_ID =
<Tenant from Create Azure AD Service Principal>AZURE_CLIENT_SECRET =
<Password from Create Azure AD Service Principal>
Hinzufügen von Airflow-Anforderungen – apache-airflow-providers-microsoft-azure
Erstellen Sie Microsoft Entra-Dienst-Prinzipal für den Zugriff auf Azure – erteilen Sie die Berechtigung für den Zugriff auf den HDInsight AKS-Cluster mit der Rolle des Mitwirkenden. Notieren Sie sich die appId, das Kennwort und den Mandanten aus der Antwort.
az ad sp create-for-rbac -n <sp name> --role Contributor --scopes <Flink Cluster Resource ID>Erstellen Sie die folgenden Geheimnisse in Ihrem Schlüsselbund mit dem Wert aus der vorherigen AD-Dienstprinzipal-AppId, dem Kennwort und dem Mandanten, die durch die in AIRFLOW__SECRETS__BACKEND_KWARGS definierte Eigenschaft "variables_prefix" präfixiert sind. Der DAG-Code kann ohne variables_prefix auf jede dieser Variablen zugreifen.
hdinsight-aks-variables-api-client-id=
<App ID from previous step>hdinsight-aks-variables-api-secret=
<Password from previous step>hdinsight-aks-variables-tenant-id=
<Tenant from previous step>
from airflow.models import Variable def retrieve_variable_from_akv(): variable_value = Variable.get("client-id") print(variable_value)

DAG-Definition
Ein DAG (Directed Acyclic Graph) ist das Kernkonzept von Airflow. Ein DAG sammelt Aufgaben und organisiert sie mit Abhängigkeiten und Beziehungen, um festzulegen, wie sie ausgeführt werden sollen.
Es gibt drei Möglichkeiten, eine DAG zu deklarieren:
Sie können einen Kontext-Manager verwenden, der die DAG implizit zu allen darin enthaltenen Elementen hinzufügt.
Sie können einen Standardkonstruktor verwenden und die DAG an alle operatoren übergeben, die Sie verwenden.
Sie können den @dag Dekorateur verwenden, um eine Funktion in einen DAG-Generator umzuwandeln (aus airflow.decorators import dag)
DAGs sind nichts ohne Aufgaben auszuführen, und diese sind in Form von Operatoren, Sensoren oder TaskFlow enthalten.
Weitere Informationen zu DAGs, Control Flow, SubDAGs, TaskGroups usw. finden Sie direkt aus Apache Airflow.
DAG-Ausführung
Beispielcode ist auf dem gitverfügbar; laden Sie den Code lokal auf Ihrem Computer herunter, und laden Sie die wordcount.py in einen BLOB-Speicher hoch. Führen Sie die Schritte aus,, um DAG in Ihren Workflow zu importieren, der während des Setups erstellt wurde.
Das Skript wordcount.py ist ein Beispiel für die Orchestrierung einer Flink-Job-Einreichung unter Verwendung von Apache Airflow und HDInsight auf AKS. Die DAG hat zwei Aufgaben:
OAuth TokenabrufenAzure-REST-API von HDInsight Flink aufrufen, um einen neuen Job einzureichen.
Die DAG erwartet, dass der Dienstprinzipal eingerichtet ist, wie es im Verlauf des Setup-Prozesses für die OAuth-Client-Anmeldeinformationen beschrieben wurde, und dass die folgende Eingabekonfiguration für die Ausführung übergeben wird.
Ausführungsschritte
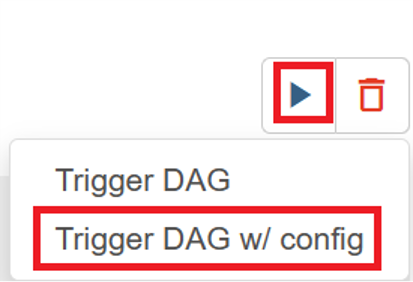
Führen Sie die DAG aus der Airflow UIaus. Sie können die Benutzeroberfläche des Azure Data Factory Workflow Orchestration Manager öffnen, indem Sie auf das Symbol "Monitor" klicken.

Wählen Sie die DAG "FlinkWordCountExample" auf der Seite "DAGs" aus.

Klicken Sie in der oberen rechten Ecke auf das Symbol "Ausführen", und wählen Sie "DAG w/config auslösen" aus.
Übergeben der erforderlichen Konfigurations-JSON
{ "jarName":"WordCount.jar", "jarDirectory":"abfs://filesystem@<storageaccount>.dfs.core.windows.net", "subscription":"<cluster subscription id>", "rg":"<cluster resource group>", "poolNm":"<cluster pool name>", "clusterNm":"<cluster name>" }Klicken Sie auf die Schaltfläche "Trigger", startet sie die Ausführung der DAG.
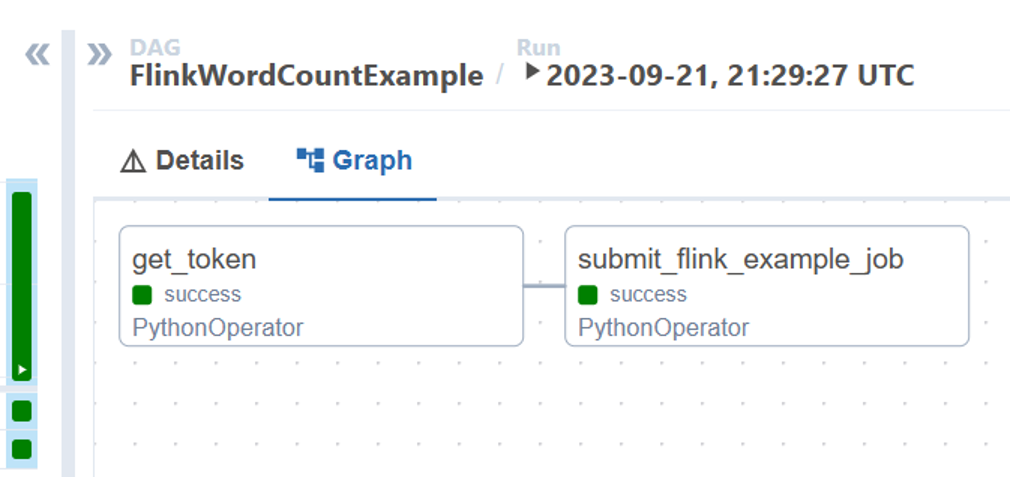
Sie können den Status von DAG-Aufgaben aus der DAG-Ausführung visualisieren.
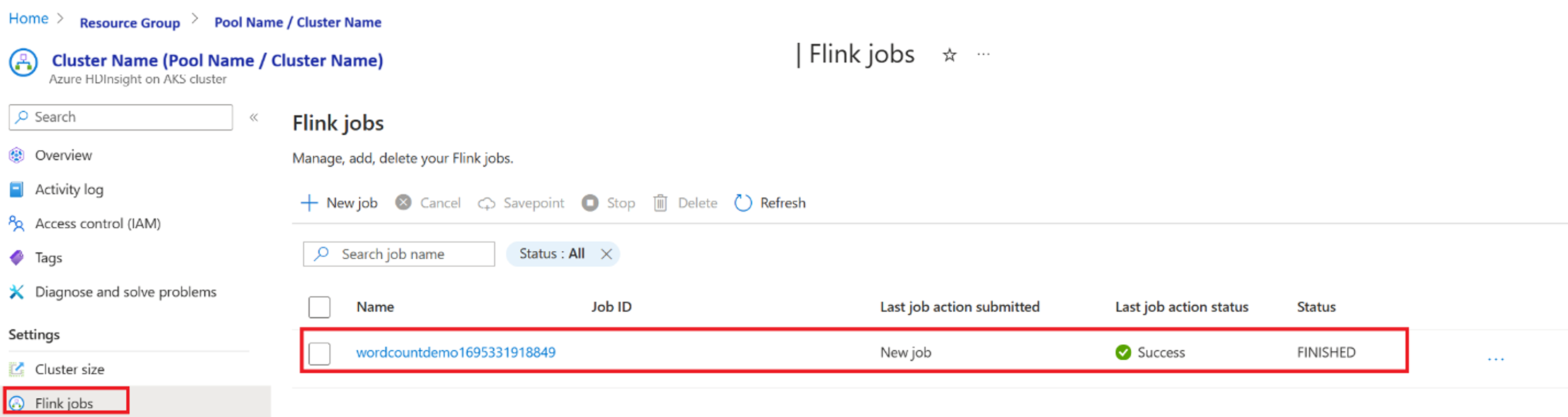
Überprüfen der Auftragsausführung über das Portal
Überprüfen Sie den Job im "Apache Flink Dashboard"






Beispielcode
Dies ist ein Beispiel für das Orchestrieren von Datenpipelines mit Airflow und HDInsight unter Verwendung von AKS.
Die DAG erwartet die Einrichtung des Dienstprinzipals für die OAuth-Clientanmeldeinformationen und die Übergabe der folgenden Eingabekonfiguration für die Ausführung:
{
'jarName':'WordCount.jar',
'jarDirectory':'abfs://filesystem@<storageaccount>.dfs.core.windows.net',
'subscription':'<cluster subscription id>',
'rg':'<cluster resource group>',
'poolNm':'<cluster pool name>',
'clusterNm':'<cluster name>'
}
Referenz
- Siehe Beispielcode.
- Apache Flink Website
- Apache, Apache Airflow, Airflow, Apache Flink, Flink und zugehörige Open Source-Projektnamen sind Marken der Apache Software Foundation (ASF).