Erweitern großer Sprachmodelle mit Retrieval-unterstützter Generierung oder Feinabstimmung
In einer Reihe von Artikeln besprechen wir die Wissensabrufmechanismen, mit denen große Sprachmodelle (LLMs) Antworten generieren. Standardmäßig hat ein LLM nur Zugriff auf seine Schulungsdaten. Sie können das Modell jedoch erweitern, um Echtzeitdaten oder private Daten einzuschließen.
Der erste Mechanismus ist Retrieval-augmented generation (RAG). RAG ist eine Form der Vorverarbeitung, die die semantische Suche mit kontextuellem Priming kombiniert. Die kontextuelle Voreinstellung wird ausführlich in Schlüsselkonzepte und Überlegungen zum Aufbau generativer KI-Lösungen behandelt.
Der zweite Mechanismus ist Feinabstimmung. Bei der Feinabstimmung wird ein LLM nach dem ersten breiten Training auf einem bestimmten Dataset weiter trainiert. Ziel ist es, die LLM anzupassen, um Aufgaben besser zu erledigen oder Konzepte zu verstehen, die mit dem Dataset zusammenhängen. Dieser Prozess hilft dem Modell, seine Genauigkeit und Effizienz bei der Verarbeitung spezifischer Eingabetypen oder Domänen zu spezialisieren oder zu verbessern.
In den folgenden Abschnitten werden diese beiden Mechanismen ausführlicher beschrieben.
Grundlagen von RAG
RAG wird häufig verwendet, um das Szenario "Chat über meine Daten" zu aktivieren. In diesem Szenario verfügt eine Organisation über einen potenziell großen Korpus von Textinhalten, z. B. Dokumente, Dokumentationen und andere proprietäre Daten. Sie verwendet diesen Korpus als Grundlage für Antworten auf Benutzeraufforderungen.
Auf hoher Ebene erstellen Sie einen Datenbankeintrag für jedes Dokument oder für einen Dokumententeil, der als -Abschnittbezeichnet wird. Der Chunk wird über sein Embedding indiziert, d.h. einen Vektor (Array) von Zahlen, die Facetten des Dokuments darstellen. Wenn ein Benutzer eine Abfrage sendet, durchsuchen Sie die Datenbank nach ähnlichen Dokumenten und übermitteln dann die Abfrage und die Dokumente an die LLM, um eine Antwort zu verfassen.
Hinweis
Wir verwenden den Begriff Retrieval-augmented Generation (RAG), um dem gerecht zu werden. Der Prozess der Implementierung eines RAG-basierten Chatsystems, wie er in diesem Artikel beschrieben wird, kann unabhängig davon angewandt werden, ob Sie externe Daten in einer unterstützenden Funktion (RAG) oder als Kernstück der Antwort (RCG) verwenden möchten. Diese Unterscheidung wird in den meisten Büchern über RAG nicht angesprochen.
Erstellen eines Indexes von vektorisierten Dokumenten
Der erste Schritt zum Erstellen eines RAG-basierten Chatsystems besteht darin, einen Vektordatenspeicher zu erstellen, der die Vektoreinbettung des Dokuments oder Abschnitts enthält. Betrachten Sie das folgende Diagramm, in dem die grundlegenden Schritte zum Erstellen eines vektorisierten Indexes von Dokumenten beschrieben werden.

Das Diagramm stellt eine Datenpipelinedar. Die Pipeline ist für das Einbinden, Verarbeiten und Verwalten der Daten verantwortlich, die das System verwendet. Die Pipeline enthält Vorverarbeitungsdaten, die in der Vektordatenbank gespeichert werden sollen, und stellt sicher, dass die in das LLM eingespeisten Daten im richtigen Format vorliegen.
Der gesamte Prozess wird durch den Begriff einer Einbettung gesteuert, bei der es sich um eine numerische Darstellung von Daten (in der Regel Wörter, Ausdrücke, Sätze oder sogar ganze Dokumente) handelt, die die semantischen Eigenschaften der Eingabe auf eine Weise erfasst, die von Machine Learning-Modellen verarbeitet werden kann.
Um eine Einbettung zu erstellen, senden Sie den Teil des Inhalts (Sätze, Absätze oder ganze Dokumente) an die Azure OpenAI Embeddings-API. Die API gibt einen Vektor zurück. Jeder Wert im Vektor stellt ein Merkmal (Dimension) des Inhalts dar. Dimensionen können Themen, semantische Bedeutung, Syntax und Grammatik, Wort- und Ausdrucksverwendung, Kontextbeziehungen, Stil oder Ton umfassen. Alle Werte des Vektors zusammen stellen den dimensionalen Raum des Inhalts dar. Wenn Sie sich eine 3D-Darstellung eines Vektors vorstellen, der drei Werte enthält, befindet sich ein Vektor in einem bestimmten Bereich der Ebene der XYZ-Ebene. Was geschieht, wenn Sie über 1.000 Werte oder noch mehr verfügen? Obwohl es menschen nicht möglich ist, ein 1.000-Dimension-Diagramm auf einem Blatt Papier zu zeichnen, um es verständlicher zu machen, haben Computer kein Problem, diesen Grad des dimensionalen Raums zu verstehen.
Im nächsten Schritt des Diagramms wird das Speichern des Vektors und des Inhalts (oder eines Zeigers auf die Position des Inhalts) und andere Metadaten in einer Vektordatenbank dargestellt. Eine Vektordatenbank ist wie jede Datenbankart, aber mit zwei Unterschieden:
- Vektordatenbanken verwenden einen Vektor als Index, um nach Daten zu suchen.
- Vektordatenbanken implementieren einen Algorithmus namens Kosinusähnliche Suche, auch Nächster Nachbar genannt. Der Algorithmus verwendet Vektoren, die den Suchkriterien am ehesten entsprechen.
Mit dem Korpus von Dokumenten, die in einer Vektordatenbank gespeichert sind, können Entwickler eine Retriever-Komponente erstellen, um Dokumente abzurufen, die der Abfrage des Benutzers entsprechen. Die Daten werden verwendet, um den LLM mit dem zu versorgen, was er zur Beantwortung der Abfrage des Benutzers benötigt.
Anfragen mit Ihren Dokumenten beantworten
Ein RAG-System verwendet zunächst die semantische Suche, um Artikel zu finden, die dem LLM beim Erstellen einer Antwort hilfreich sein könnten. Der nächste Schritt besteht darin, die übereinstimmenden Artikel mit dem ursprünglichen Prompt des Benutzers an das LLM zu senden, um eine Antwort zu kombinieren.
Betrachten Sie das folgende Diagramm als eine einfache RAG-Implementierung (manchmal auch naive RAG genannt):
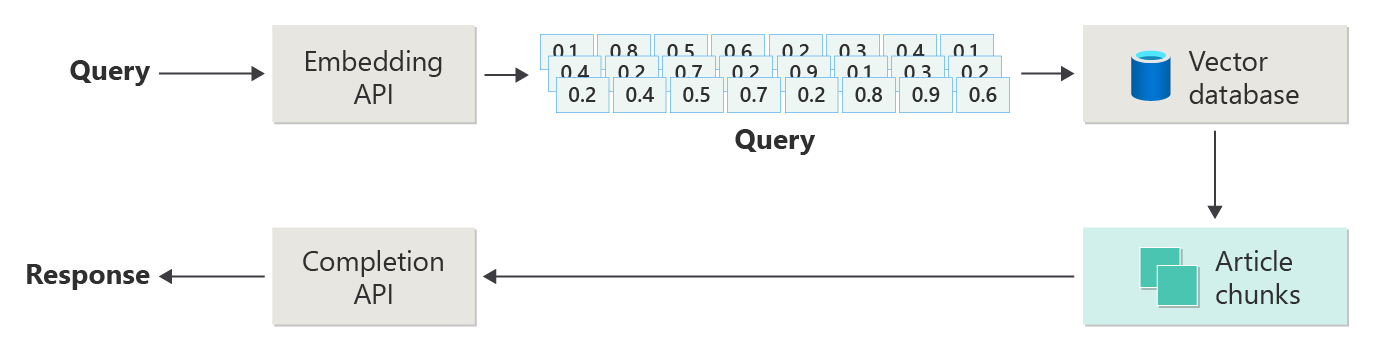
Im Diagramm sendet ein Benutzer eine Abfrage. Der erste Schritt besteht darin, eine Einbettung für den Prompt des Benutzers zu erstellen, um einen Vektor zurückzugeben. Der nächste Schritt besteht darin, die Vektordatenbank nach den Dokumenten (oder Teilen von Dokumenten) zu durchsuchen, die am ehesten übereinstimmen.
Kosinus-Ähnlichkeit ist ein Maß, mit dem bestimmt wird, wie ähnlich zwei Vektoren sind. Im Wesentlichen bewertet die Metrik den Kosinus des Winkels zwischen ihnen. Eine Kosinusähnlichkeit, die nahe 1 liegt, weist auf eine hohe Ähnlichkeit (ein kleiner Winkel) hin. Eine Ähnlichkeit in der Nähe von -1 zeigt Unähnlichkeit an (ein Winkel von fast 180 Grad). Diese Metrik ist für Aufgaben wie Dokumentähnlichkeit von entscheidender Bedeutung, wobei das Ziel darin besteht, Dokumente zu finden, die ähnliche Inhalte oder Bedeutung haben.
Nächste-Nachbar-Algorithmen arbeiten dadurch, dass sie die nächstgelegenen Vektoren (Nachbarn) für einen Punkt im Vektorraum finden. Im Algorithmus k-nearest neighbors (KNN) bezieht sich k auf die Anzahl der zu berücksichtigenden nächsten Nachbarn. Dieser Ansatz wird häufig bei der Klassifizierung und Regression verwendet, wobei der Algorithmus die Kennzeichnung eines neuen Datenpunkts auf der Grundlage der Mehrheit der Kennzeichnungen seiner k nächsten Nachbarn im Trainingsset festlegt. KNN und Kosinusgleichheit werden häufig in Systemen wie Empfehlungsmodulen verwendet, wobei das Ziel darin besteht, Elemente zu finden, die den Einstellungen eines Benutzers am ähnlichsten sind, dargestellt als Vektoren im Einbettungsraum.
Sie nehmen die besten Ergebnisse aus dieser Suche und senden die passenden Inhalte mit dem Prompt des Benutzers, um eine Antwort zu generieren, die (hoffentlich) von passenden Inhalten geprägt ist.
Herausforderungen und Überlegungen
Ein RAG-System hat seine Herausforderungen bei der Umsetzung. Datenschutz ist von größter Bedeutung. Das System muss Benutzerdaten verantwortungsbewusst verarbeiten, insbesondere, wenn sie Informationen aus externen Quellen abruft und verarbeitet. Rechenanforderungen können ebenfalls erheblich sein. Sowohl der Abrufvorgang als auch die generativen Prozesse sind ressourcenintensiv. Die Sicherstellung der Genauigkeit und Relevanz von Antworten bei der Verwaltung von Verzerrungen in den Daten oder dem Modell ist eine weitere wichtige Betrachtung. Entwickler müssen diese Herausforderungen sorgfältig bewältigen, um effiziente, ethische und wertvolle RAG-Systeme zu schaffen.
Erstellen von fortgeschrittenen Retrieval-erweiterten Generierungssystemen gibt Ihnen weitere Informationen zum Aufbau von Daten- und Inferenz-Pipelines, um ein produktionsreifes RAG-System zu ermöglichen.
Wenn Sie sofort mit dem Erstellen einer generativen KI-Lösung experimentieren möchten, empfehlen wir, einen Blick auf "Erste Schritte mit dem Chat" mit Ihrem eigenen Datenbeispiel für Python zu werfen. Das Lernprogramm ist auch für .NET-, Java-und JavaScript-verfügbar.
Feinabstimmung eines Modells
Im Zusammenhang mit einem LLM ist die Feinabstimmung der Prozess, bei dem die Parameter des Modells durch Training auf einem domänenspezifischen Dataset angepasst werden, nachdem das LLM zunächst auf einem großen, vielfältigen Dataset trainiert wurde.
LLMs werden auf einem breiten Dataset geschult, die Sprachstruktur, den Kontext und eine breite Palette von Kenntnissen erfassen. In dieser Phase lernen Sie allgemeine Sprachmuster kennen. Feinabstimmungen fügen dem vortrainierten Modell basierend auf einem kleineren, spezifischen Dataset weitere Schulungen hinzu. Diese sekundäre Schulungsphase zielt darauf ab, das Modell anzupassen, um bestimmte Aufgaben besser zu erledigen oder bestimmte Domänen zu verstehen, ihre Genauigkeit und Relevanz für diese spezialisierten Anwendungen zu verbessern. Bei der Feinabstimmung werden die Gewichtungen des Modells angepasst, um die Nuancen dieses kleineren Datasets besser vorherzusagen oder zu verstehen.
Ein paar Überlegungen:
- Spezialisierung: Feinabstimmung passt das Modell auf bestimmte Aufgaben an, z. B. rechtliche Dokumentanalyse, medizinische Textinterpretation oder Kundendienstinteraktionen. Diese Spezialisierung macht das Modell in diesen Bereichen effektiver.
- Effizienz: Es ist effizienter, ein vortrainiertes Modell für eine bestimmte Aufgabe zu optimieren, als ein Modell von Grund auf neu zu trainieren. Feinabstimmung erfordert weniger Daten und weniger Rechenressourcen.
- Anpassungsfähigkeit: Die Feinabstimmung bietet die Möglichkeit, das Modell an neue Aufgaben oder Domänen anzupassen, die nicht Teil der ursprünglichen Trainingsdaten waren. Die Anpassungsfähigkeit von LLMs macht sie zu vielseitigen Tools für verschiedene Anwendungen.
- Verbesserte Leistung: Bei Aufgaben, die sich von den Daten unterscheiden, auf die das Modell ursprünglich trainiert wurde, kann die Feinabstimmung zu einer besseren Leistung führen. Durch die Feinabstimmung wird das Modell so angepasst, dass es die spezifische Sprache, den Stil oder die Terminologie versteht, die in der neuen Domäne verwendet werden.
- Personalisierung: In einigen Anwendungen kann die Feinabstimmung dazu beitragen, die Antworten oder Vorhersagen des Modells so zu personalisieren, dass sie den spezifischen Anforderungen oder Vorlieben eines Benutzers oder einer Organisation entsprechen. Die Feinabstimmung hat jedoch bestimmte Nachteile und Einschränkungen. Wenn Sie diese Faktoren verstehen, können Sie entscheiden, wann Sie sich für die Feinabstimmung gegenüber Alternativen wie RAG entscheiden.
- Datenbedarf: Die Feinabstimmung erfordert ein ausreichend großes und hochwertiges Dataset, das auf die Zielaufgabe oder Domäne zugeschnitten ist. Das Sammeln und Zusammenstellen dieses Datasets kann schwierig und ressourcenintensiv sein.
- Risiko der Überanpassung: Überanpassung ist ein Risiko, insbesondere bei einem kleinen Dataset. Überanpassung führt dazu, dass das Modell bei den Trainingsdaten gut abschneidet, aber schlecht bei neuen, unbekannten Daten. Die Verallgemeinerbarkeit ist bei einer Überanpassung eingeschränkt.
- Kosten und Ressourcen: Obwohl weniger ressourcenintensiv als das Training von Grund auf, erfordert das Fine-Tuning immer noch Rechenressourcen, insbesondere für große Modelle und Datensätze. Die Kosten können für einige Benutzer oder Projekte unertragbar sein.
- Wartung und Aktualisierung: Feinabgestimmte Modelle benötigen möglicherweise regelmäßige Updates, um wirksam zu bleiben, da sich domänenspezifische Informationen im Laufe der Zeit ändern. Für diese fortlaufende Wartung sind zusätzliche Ressourcen und Daten erforderlich.
- Modelldrift: Da das Modell auf spezifische Aufgaben abgestimmt ist, kann es etwas von seinem allgemeinen Sprachverständnis und seiner Vielseitigkeit verlieren. Dieses Phänomen wird Modelldrift genannt.
Anpassen eines Modells durch Feinabstimmung erklärt, wie Sie ein Modell feinabstimmen können. Auf hoher Ebene stellen Sie ein JSON-Dataset mit potenziellen Fragen und bevorzugten Antworten bereit. Die Dokumentation deutet darauf hin, dass durch das Bereitstellen von 50 bis 100 Frage- und Antwortpaaren spürbare Verbesserungen erzielt werden können, aber die richtige Anzahl variiert je nach Anwendungsfall.
Feinabstimmung und RAG
Auf den ersten Blick mag es so aussehen, als gäbe es eine Menge Überschneidungen zwischen Feinabstimmung und RAG. Die Auswahl zwischen Feinabstimmung und Abruferweiterung hängt von den spezifischen Anforderungen Ihres Vorgangs ab, einschließlich Leistungserwartungen, Ressourcenverfügbarkeit und der Notwendigkeit der Domänenspezifität im Vergleich zur Generalisierbarkeit.
Wann Sie Feinabstimmung anstelle von RAG verwenden sollten:
- Aufgabenspezifische Leistung: Feinabstimmung ist vorzuziehen, wenn eine hohe Leistung bei einer bestimmten Aufgabe entscheidend ist und genügend domänenspezifische Daten vorhanden sind, um das Modell effektiv zu trainieren, ohne dass es zu einem signifikanten Overfitting kommt.
- Kontrolle über die Daten: Wenn Sie über eigene oder hochspezialisierte Daten verfügen, die sich erheblich von den Daten unterscheiden, auf denen das Basismodell trainiert wurde, bietet Ihnen die Feinabstimmung die Möglichkeit, dieses einzigartige Wissen in das Modell einfließen zu lassen.
- Beschränkter Bedarf an Echtzeit-Updates: Wenn die Aufgabe nicht erfordert, dass das Modell ständig mit den neuesten Informationen aktualisiert wird, kann die Feinabstimmung effizienter sein, da RAG-Modelle in der Regel Zugriff auf aktuelle externe Datenbanken oder das Internet benötigen, um aktuelle Daten zu beziehen.
Wann sollte man RAG dem Fine-Tuning vorziehen?
- Dynamische Inhalte oder sich entwickelnde Inhalte: RAG eignet sich besser für Aufgaben, bei denen die aktuellsten Informationen kritisch sind. Da RAG-Modelle Daten aus externen Quellen in Echtzeit abrufen können, eignen sie sich besser für Anwendungen wie die Nachrichtengenerierung oder das Beantworten von Fragen zu aktuellen Ereignissen.
- Generalisierung über Spezialisierung: Wenn das Ziel darin besteht, eine starke Leistung in einer breiten Palette von Themen aufrechtzuerhalten, anstatt in einem eng gefassten Bereich herausragend zu sein, ist RAG möglicherweise vorzuziehen. Es verwendet externe Wissensdatenbank, sodass er Antworten über verschiedene Domänen hinweg generieren kann, ohne dass das Risiko besteht, dass es zu einem bestimmten Dataset überpasst.
- Ressourceneinschränkungen: Für Organisationen mit begrenzten Ressourcen für die Datenerfassung und das Modelltraining könnte die Verwendung eines RAG-Ansatzes eine kostengünstige Alternative zur Feinabstimmung bieten, insbesondere wenn das Basismodell bereits relativ gut bei den gewünschten Aufgaben abschneidet.
Abschließende Überlegungen zum Anwendungsdesign
Im Folgenden finden Sie eine kurze Liste der Dinge, die Sie berücksichtigen sollten, und andere Punkte aus diesem Artikel, die Ihre Entscheidungen hinsichtlich des Anwendungsentwurfs beeinflussen können:
- Entscheiden Sie sich je nach den spezifischen Anforderungen Ihrer Anwendung zwischen Feinabstimmung und RAG. Fine-Tuning bietet möglicherweise eine bessere Leistung für spezielle Aufgaben, während RAG Flexibilität und aktuelle Inhalte für dynamische Anwendungen bietet.