Bauen Sie fortgeschrittene Retrieval-Augmented Generation Systeme
Dieser Artikel entdeckt die Retrieval-Augmented Generation (RAG) im Detail. Wir beschreiben die Arbeit und Überlegungen, die für Entwickler erforderlich sind, um eine produktionsfähige RAG-Lösung zu erstellen.
Um mehr über zwei Optionen für den Aufbau einer „Chat-über-die-Daten“-Anwendung zu erfahren, einem der wichtigsten Anwendungsfälle für generative KI in Unternehmen, lesen Sie Erweiterung von LLMs mit RAG oder Fine-Tuning.
Das folgende Diagramm veranschaulicht die Schritte oder Phasen der RAG:
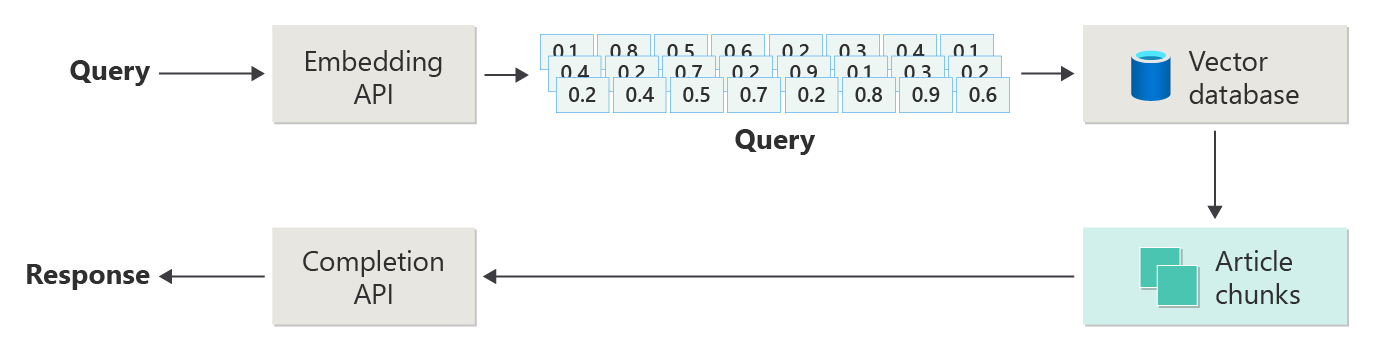
Diese Darstellung wird naive RAG genannt. Es ist eine nützliche Möglichkeit, zunächst die Mechanismen, Rollen und Verantwortlichkeiten zu verstehen, die zum Implementieren eines RAG-basierten Chatsystems erforderlich sind.
Eine echte Implementierung verfügt jedoch über viele weitere Vorverarbeitungs- und Nachbearbeitungsschritte, um die Artikel, Abfragen und Antworten für die Verwendung vorzubereiten. Das folgende Diagramm ist eine realistischere Darstellung einer RAG, die manchmal als fortgeschrittene RAG bezeichnet wird:

Dieser Artikel bietet ein konzeptionelles Framework für das Verständnis der Vorverarbeitungs- und Nachbearbeitungsphasen in einem echten RAG-basierten Chatsystem:
- Aufnahmephase
- Inferenz-Pipeline-Phase
- Auswertungsphase
Datenerfassung
Beim Einbinden geht es in erster Linie darum, die Dokumente Ihrer Organisation so zu speichern, dass sie leicht abgerufen werden können, um die Frage eines Benutzers zu beantworten. Die Herausforderung besteht darin, sicherzustellen, dass sich die Teile der Dokumente, die am besten mit der Abfrage des Benutzers übereinstimmen, befinden und während der Ableitung verwendet werden. Der Abgleich erfolgt in erster Linie durch vektorisierte Einbettungen und eine Kosinus-Ähnlichkeitssuche. Der Zuordnungsvorgang wird jedoch dadurch erleichtert, dass man die Beschaffenheit des Inhalts (z. B. Muster und Form) sowie die Strategie der Datenorganisation (die Struktur der Daten, wenn sie in der Vektordatenbank gespeichert werden) versteht.
Beim Einbinden müssen Entwickler die folgenden Schritte berücksichtigen:
- Vorverarbeitung und Extraktion von Inhalten
- Chunking-Strategie
- Abteilungsorganisation
- Updatestrategie
Vorverarbeitung und Extraktion von Inhalten
Saubere und genaue Inhalte sind eine der besten Möglichkeiten, um die Gesamtqualität eines RAG-basierten Chatsystems zu verbessern. Um saubere, genaue Inhalte zu erhalten, beginnen Sie mit der Analyse der Form und Struktur der Dokumente, die indiziert werden sollen. Entsprechen die Dokumente bestimmten Inhaltsmustern wie dokumentation? Wenn nicht, welche Arten von Fragen können die Dokumente beantworten?
Erstellen Sie zumindest Schritte in der Pipeline zum Einbinden von Dokumenten:
- Standardisieren von Textformaten
- Behandeln von Sonderzeichen
- Entfernen von nicht verknüpften, veralteten Inhalten
- Konto für versionsierte Inhalte
- Konto für die Inhaltserfahrung (Registerkarten, Bilder, Tabellen)
- Extrahieren von Metadaten
Einige dieser Informationen (z. B. Metadaten) können nützlich sein, wenn sie mit dem Dokument in der Vektordatenbank aufbewahrt wird, das während des Abruf- und Auswertungsprozesses in der Ableitungspipeline verwendet werden soll. Es kann auch mit dem Text-Chunk kombiniert werden, um die Vektoreinbettung des Chunks zu beeinflussen.
Chunking-Strategie
Als Entwickler müssen Sie entscheiden, wie Sie ein größeres Dokument in kleinere Abschnitte aufteilen. Chunking kann die Relevanz der ergänzenden Inhalte verbessern, die an das LLM gesendet werden, um die Abfragen der Benutzer korrekt zu beantworten. Überlegen Sie auch, wie Sie die Teilabschnitte nach dem Abruf verwenden. Systemdesigner sollten gemeinsame Industrietechniken untersuchen und einige Experimente durchführen. Sie können Ihre Strategie sogar in einer begrenzten Kapazität in Ihrer Organisation testen.
Entwickler müssen Folgendes berücksichtigen:
- Optimierung der Blockgröße: Bestimmen Sie die ideale Blockgröße, und wie Sie einen Block festlegen. Nach Abschnitt? Nach Absatz? Nach Satz?
- Überlappende und gleitende Fensterblöcke: Bestimmen Sie, ob der Inhalt in diskrete Blöcke unterteilt werden soll, oder überlappen sich die Blöcke? Sie können sogar beides tun, in einem Sliding Window Design.
- Small2Big: Wenn das Chunking auf einer granularen Ebene wie einem einzelnen Satz erfolgt, ist der Inhalt dann so organisiert, dass es einfach ist, die benachbarten Sätze oder den Absatz zu finden, der den Satz enthält? Wenn Sie diese Informationen abrufen und dem LLM zur Verfügung stellen, könnte es mehr Kontext zur Beantwortung von Abfragen der Benutzer erhalten. Weitere Informationen finden Sie im nächsten Abschnitt.
Abteilungsorganisation
In einem RAG-System ist die strategische Organisation Ihrer Daten in der Vektordatenbank ein Schlüssel zum effizienten Abrufen relevanter Informationen zur Erweiterung des Erzeugungsprozesses. Hier sind die Arten von Indizierungs- und Abrufstrategien, die Sie berücksichtigen können:
- hierarchische Indizes: Bei diesem Ansatz werden mehrere Ebenen von Indizes erstellt. Ein Index der obersten Ebene (ein Zusammenfassungsindex) schränkt den Suchbereich schnell auf eine Teilmenge potenziell relevanter Blöcke ein. Ein Index der zweiten Ebene (ein Teilindex) bietet genauer ausgestaltete Hinweise auf die tatsächlichen Daten. Diese Methode kann den Abrufvorgang erheblich beschleunigen, da sie die Anzahl der Einträge, die im detaillierten Index durchsucht werden müssen, reduziert, indem zuerst der Zusammenfassungsindex gefiltert wird.
- Spezialisierte Indizes: Je nach Art der Daten und der Beziehungen zwischen Blöcken können Sie spezielle Indizes wie graphbasierte oder relationale Datenbanken verwenden:
- Graphbasierte Indizes sind nützlich, wenn die Blöcke über miteinander verbundene Informationen oder Beziehungen verfügen, die den Abruf verbessern können, z. B. Zitatnetzwerke oder Wissensdiagramme.
- Relationale Datenbanken können effektiv sein, wenn die Blöcke in einem tabellarischen Format strukturiert sind. Verwenden Sie SQL-Abfragen, um Daten basierend auf bestimmten Attributen oder Beziehungen zu filtern und abzurufen.
- Hybridindizes: Ein Hybridansatz kombiniert mehrere Indizierungsmethoden, um ihre Stärken auf Ihre Gesamtstrategie anzuwenden. Sie können z. B. einen hierarchischen Index für die anfängliche Filterung und einen graphbasierten Index verwenden, um beziehungen zwischen Blöcken während des Abrufs dynamisch zu untersuchen.
Ausrichtungsoptimierung
Um die Relevanz und Genauigkeit der abgerufenen Blöcke zu verbessern, richten Sie sie eng an die Frage oder Abfragetypen aus, die sie beantworten. Eine Strategie besteht darin, für jeden Chunk eine hypothetische Frage zu generieren und einzufügen, die die Frage repräsentiert, für deren Beantwortung der Chunk am besten geeignet ist. Dies hilft auf verschiedene Arten:
- Verbesserte Übereinstimmung: Während des Abrufs kann das System die eingehende Abfrage mit diesen hypothetischen Fragen vergleichen, um die beste Übereinstimmung zu finden und somit die Relevanz der abgerufenen Datenblöcke zu verbessern.
- Schulungsdaten für Machine Learning-Modelle: Diese Kopplungen von Fragen und Blöcken können Schulungsdaten sein, um die Machine Learning-Modelle zu verbessern, die die zugrunde liegenden Komponenten des RAG-Systems sind. Das RAG-System lernt, welche Arten von Fragen von den einzelnen Chunks am besten beantwortet werden können.
- direkte Abfragebehandlung: Wenn eine echte Benutzerabfrage eng mit einer hypothetischen Frage übereinstimmt, kann das System den entsprechenden Block schnell abrufen und verwenden und die Antwortzeit beschleunigen.
Die hypothetische Frage jedes Chunks wirkt wie eine Kennzeichnung, die den Suchalgorithmus anleitet, so dass er gezielter und kontextbezogener vorgehen kann. Diese Art von Optimierung ist nützlich, wenn die Blöcke eine vielzahl von Informationsthemen oder -typen abdecken.
Aktualisieren von Strategien
Wenn Ihre Organisation Dokumente indiziert, die häufig aktualisiert werden, müssen Sie einen aktualisierten Korpus beibehalten, um sicherzustellen, dass die Retriever-Komponente auf die aktuellsten Informationen zugreifen kann. Die Retriever-Komponente ist die Logik im System, die die Abfrage für die Vektordatenbank ausführt, und gibt dann Ergebnisse zurück. Hier sind einige Strategien zum Aktualisieren der Vektordatenbank in diesen Systemtypen:
Inkrementelle Aktualisierungen:
- Regelmäßige Intervalle: Planen Sie Aktualisierungen in regelmäßigen Intervallen (z. B. täglich oder wöchentlich), abhängig von der Häufigkeit der Dokumentänderungen. Diese Methode stellt sicher, dass die Datenbank regelmäßig in einem bekannten Zeitplan aktualisiert wird.
- Triggerbasierte Updates: Implementieren Sie ein System, in dem eine Aktualisierung die Neuindizierung auslöst. Beispielsweise initiiert jede Änderung oder Ergänzung eines Dokuments automatisch die Neuindizierung in den betroffenen Abschnitten.
Teilweise Aktualisierungen:
- Selektive Neuindizierung: Statt eine gesamte Datenbank neu zu indizieren, aktualisieren Sie nur die geänderten Korpusteile. Dieser Ansatz kann effizienter als die vollständige Neuindizierung sein, insbesondere für große Datasets.
- Delta-Codierung: Speichern Sie nur die Unterschiede zwischen den vorhandenen Dokumenten und ihren aktualisierten Versionen. Durch diesen Ansatz wird die Datenverarbeitungslast reduziert, da keine unveränderten Daten verarbeitet werden müssen.This approach reduces the data processing load by avoiding the need to process unchanged data.
Versionsverwaltung:
- Snapshotting: Verwalten von Dokumentkorpusversionen zu unterschiedlichen Zeitpunkten. Diese Technik bietet einen Sicherungsmechanismus und ermöglicht es dem System, auf frühere Versionen zurückzusetzen oder darauf zu verweisen.
- Dokumentversionskontrolle: Verwenden Sie ein Versionssteuerungssystem, um Dokumentänderungen systematisch nachzuverfolgen, um den Änderungsverlauf beizubehalten und den Aktualisierungsprozess zu vereinfachen.
Echtzeitupdates:
- Streamverarbeitung: Wenn die Aktualität von Informationen entscheidend ist, verwenden Sie Streamverarbeitungstechnologien für Echtzeit-Aktualisierungen der Vektordatenbank, sobald Änderungen am Dokument vorgenommen werden.
- Live-Abfragen: Anstatt sich nur auf vorindizierte Vektoren zu verlassen, verwenden Sie einen Ansatz für Live-Abfragen, um aktuelle Antworten zu erhalten, und kombinieren dabei möglicherweise Live-Daten mit zwischenspeichernden Ergebnissen, um effizienter zu sein.
Optimierungstechniken:
Batch-Verarbeitung: Bei der Batch-Verarbeitung werden Änderungen akkumuliert und weniger häufig angewendet, um Ressourcen zu optimieren und den Overhead zu reduzieren.
Hybridansätze: Verschiedene Strategien kombinieren:
- Verwenden Sie schrittweise Updates für kleinere Änderungen.
- Verwenden Sie eine vollständige Neuindizierung für größere Aktualisierungen.
- Dokumentieren Sie strukturelle Änderungen, die am Korpus vorgenommen werden.
Die Auswahl der richtigen Updatestrategie oder die richtige Kombination hängt von bestimmten Anforderungen ab, einschließlich:
- Dokumentkorpusgröße
- Aktualisierungshäufigkeit
- Echtzeitdatenanforderungen
- Ressourcenverfügbarkeit
Bewerten Sie diese Faktoren basierend auf den Anforderungen der spezifischen Anwendung. Jeder Ansatz hat Kompromisse in Komplexität, Kosten und Aktualisierungslatenz.
Rückschlusspipeline
Ihre Artikel werden aufgeteilt, vektorisiert und in einer Vektordatenbank gespeichert. Konzentrieren Sie sich jetzt auf die Lösung von Fertigstellungsproblemen.
Um die genauesten und effizienten Fertigstellungen zu erhalten, müssen Sie viele Faktoren berücksichtigen:
- Ist die Abfrage des Benutzers so formuliert, dass sie die Ergebnisse liefert, nach denen der Benutzer sucht?
- Verstößt die Abfrage des Benutzers gegen eine der Richtlinien der Organisation?
- Wie schreiben Sie die Abfrage des Benutzers neu, um die Wahrscheinlichkeit zu verbessern, dass die nächstgelegenen Übereinstimmungen in der Vektordatenbank gefunden werden?
- Wie bewerten Sie Abfrageergebnisse, um sicherzustellen, dass der Artikelabschnitt an der Abfrage ausgerichtet ist?
- Wie bewerten und modifizieren Sie Abfrageergebnisse, bevor Sie sie an das LLM weitergeben, um sicherzustellen, dass die wichtigsten Details in die Vervollständigung aufgenommen werden?
- Wie bewerten Sie die Antwort des LLM, um sicherzustellen, dass der Abschluss des LLM die ursprüngliche Abfrage des Benutzers beantwortet?
- Wie stellen Sie sicher, dass die Antwort des LLM mit den Richtlinien der Organisation übereinstimmt?
Die gesamte Inferenzpipeline wird in Echtzeit ausgeführt. Es gibt keine richtige Möglichkeit, Ihre Vorverarbeitungs- und Nachbearbeitungsschritte zu entwerfen. Wahrscheinlich werden Sie eine Kombination aus Programmlogik und anderen Aufrufen des LLM wählen. Einer der wichtigsten Aspekte ist der Kompromiss zwischen der Erstellung der möglichst genauen und kompatiblen Pipeline sowie der Kosten und Latenz, die erforderlich sind, um dies zu ermöglichen.
Lassen Sie uns spezifische Strategien in jeder Phase der Inferenzpipeline identifizieren.
Schritte zur Vorverarbeitung von Abfragen
Die Abfragevorverarbeitung erfolgt unmittelbar nach der Übermittlung der Abfrage durch den Benutzer:

Das Ziel dieser Schritte besteht darin, sicherzustellen, dass der Benutzer Fragen stellt, die sich im Bereich Ihres Systems befinden, und die Abfrage des Benutzers vorzubereiten, um die Wahrscheinlichkeit zu erhöhen, dass er die bestmöglichen Artikelabschnitte mithilfe der Kosinusgleichheit oder der Suche "nächster Nachbar" findet.
Richtlinienüberprüfung: Dieser Schritt umfasst Logik, mit der bestimmte Inhalte identifiziert, entfernt, gekennzeichnet oder abgelehnt werden. Einige Beispiele sind das Entfernen personenbezogener Daten, das Entfernen von Expletiven und das Identifizieren von "Jailbreak"-Versuchen. Jailbreaking bezieht sich auf Versuche von Benutzern, die integrierten Sicherheits-, Ethik- oder Betriebsrichtlinien des Modells zu umgehen oder zu manipulieren.
Umformulierung der Abfrage: Dieser Schritt kann von der Erweiterung von Akronymen und der Entfernung von Slang bis hin zur Umformulierung der Frage reichen, um sie abstrakter zu stellen und übergeordnete Konzepte und Prinzipien zu extrahieren (step-back prompting).
Eine Variante des Step-back Prompting ist Hypothetical Document Embeddings (HyDE). HyDE verwendet die LLM, um die Frage des Benutzers zu beantworten, erstellt eine Einbettung für diese Antwort (die hypothetische Dokumenteinbettung), und verwendet dann die Einbettung, um eine Suche für die Vektordatenbank auszuführen.
Unterabfragen
Der Verarbeitungsschritt für Unterabfragen basiert auf der ursprünglichen Abfrage. Wenn die ursprüngliche Abfrage lang und komplex ist, kann es nützlich sein, sie programmgesteuert in mehrere kleinere Abfragen zu unterteilen und dann alle Antworten zu kombinieren.
Beispielsweise könnte eine Frage zu wissenschaftlichen Entdeckungen in der Physik lauten: "Wer hat bedeutende Beiträge zur modernen Physik, Albert Einstein oder Niels Bohr geleistet?"
Das Aufteilen komplexer Abfragen in Unterabfragen macht sie besser verwaltbar:
- Subquery 1: "Was sind die wichtigsten Beiträge von Albert Einstein zur modernen Physik?"
- Subquery 2: "Was sind die wichtigsten Beiträge von Niels Bohr zur modernen Physik?"
Die Ergebnisse dieser Unterabfragen detailieren die wichtigsten Theorien und Entdeckungen jedes Physikers. Zum Beispiel:
- Für Einstein können Beiträge die Theorie der Relativität, den photoelektrischen Effekt und E=mc^2enthalten.
- Für Bohr könnten Beiträge Bohrs Modell des Wasserstoffatoms, Bohrs Arbeiten zur Quantenmechanik und Bohrs Prinzip der Komplementarität umfassen.
Wenn diese Beiträge skizziert sind, können sie bewertet werden, um weitere Unterabfragen zu bestimmen. Zum Beispiel:
- Subquery 3: "Wie haben Einsteins Theorien die Entwicklung der modernen Physik beeinflusst?"
- Subquery 4: "Wie haben Bohrs Theorien die Entwicklung der modernen Physik beeinflusst?"
Diese Unterabfragen untersuchen den Einfluss jedes Wissenschaftlers auf die Physik, z. B.:
- Wie Einsteins Theorien zu Fortschritten in der Kosmologie und Quantentheorie geführt haben
- Wie Bohrs Arbeit dazu beitrug, atomische Struktur und Quantenmechanik zu verstehen
Die Kombination der Ergebnisse dieser Unterabfragen kann dazu beitragen, dass das Sprachmodell eine umfassendere Antwort darüber bildet, wer auf der Grundlage ihrer theoretischen Fortschritte bedeutende Beiträge zur modernen Physik geleistet hat. Diese Methode vereinfacht die ursprüngliche komplexe Abfrage, indem sie auf spezifischere, antwortbare Komponenten zugreift und diese Ergebnisse dann zu einer kohärenten Antwort synthesiert.
Abfragerouter
Ihre Organisation kann sich entscheiden, ihren Inhaltskorpus in mehrere Vektorspeicher oder in ganze Abrufsysteme aufzuteilen. In diesem Szenario können Sie einen Abfragerouter verwenden. Ein Abfragerouter wählt die am besten geeignete Datenbank oder den geeignetsten Index aus, um die besten Antworten auf eine bestimmte Abfrage bereitzustellen.
Ein Abfragerouter funktioniert in der Regel an einem Punkt, nachdem der Benutzer die Abfrage formuliert hat, aber bevor er die Abfrage an Abrufsysteme sendet.
Hier ist ein vereinfachter Workflow für einen Abfragerouter:
- Abfrageanalyse: Das LLM oder eine andere Komponente analysiert die eingehende Abfrage, um deren Inhalt, Kontext und die Art der wahrscheinlich benötigten Informationen zu verstehen.
- Indexauswahl: Basierend auf der Analyse wählt der Abfragerouter einen oder mehrere Indizes aus potenziell mehreren verfügbaren Indizes aus. Jeder Index kann für verschiedene Arten von Daten oder Abfragen optimiert werden. Einige Indizes eignen sich z. B. eher für faktenbezogene Abfragen. Andere Indizes können in der Bereitstellung von Meinungen oder subjektiven Inhalten excelieren.
- Abfrageverteilung: Die Abfrage wird an den ausgewählten Index weitergeleitet.
- Aggregation der Ergebnisse: Die Antworten aus den ausgewählten Indizes werden abgerufen und möglicherweise aggregiert oder weiterverarbeitet, um eine umfassende Antwort zu erhalten.
- Antwortgenerierung: Der letzte Schritt umfasst das Generieren einer kohärenten Reaktion auf die abgerufenen Informationen, möglicherweise die Integration oder Synthesierung von Inhalten aus mehreren Quellen.
Ihre Organisation verwendet möglicherweise mehrere Abrufmodule oder Indizes für die folgenden Anwendungsfälle:
- Spezialisierung auf Datentypen: Einige Indizes können sich auf Nachrichtenartikel, andere auf akademische Arbeiten und wiederum andere auf allgemeine Webinhalte oder bestimmte Datenbanken wie für medizinische oder rechtliche Informationen spezialisiert haben.
- Optimierung des Abfragetypen: Bestimmte Indizes können für schnelles faktisches Nachschlagen optimiert werden (z. B. Datumsangaben oder Ereignisse). Andere sind möglicherweise besser geeignet, um sie bei komplexen Denkaufgaben oder bei Abfragen einzusetzen, die ein tiefes Fachwissen erfordern.
- Algorithmische Unterschiede: In verschiedenen Engines können unterschiedliche Retrieval-Algorithmen zum Einsatz kommen, wie z. B. vektorbasierte Ähnlichkeitssuche, traditionelle schlagwortbasierte Suche oder fortschrittlichere semantische Verständnismodelle.
Stellen Sie sich ein RAG-basiertes System vor, das in einem medizinischen Beratungskontext verwendet wird. Das System hat Zugriff auf mehrere Indizes:
- Ein medizinischer Forschungspapierindex, der für detaillierte und technische Erläuterungen optimiert ist
- Ein klinischer Fallstudienindex, der praxisnahe Beispiele für Symptome und Behandlungen bereitstellt
- Ein allgemeiner Gesundheitsinformationsindex für grundlegende Abfragen und Informationen über die öffentliche Gesundheit
Wenn ein Benutzer eine technische Frage zu den chemischen Wirkungen eines neuen Medikaments stellt, kann der Abfragerouter den Index des medizinischen Forschungspapiers aufgrund seiner Tiefe und technischen Fokus priorisieren. Für eine Frage zu typischen Symptomen einer gemeinsamen Krankheit kann der allgemeine Gesundheitsindex jedoch für seinen breiten und leicht verständlichen Inhalt gewählt werden.
Schritte nach dem Abrufen von Verarbeitungsschritten
Die Nachbearbeitung erfolgt, nachdem die Abrufkomponente relevante Inhaltsabschnitte aus der Vektordatenbank abgerufen hat.

Mit den gefundenen Inhalts-Chunks besteht der nächste Schritt darin, die Nützlichkeit des Artikel-Chunks bei der Erweiterung des LLM Prompts zu überprüfen, bevor der Prompt für das LLM vorbereitet wird.
Hier sind einige Aspekte des Prompts zu berücksichtigen:
- Das Einschließen zu viel ergänzender Informationen kann dazu führen, dass die wichtigsten Informationen ignoriert werden.
- Die Einbeziehung irrelevanter Informationen kann die Antwort negativ beeinflussen.
Eine weitere Überlegung ist das Nadel im Heuhaufen-Problem, ein Begriff, der sich auf eine bekannte Eigenart einiger LLMs bezieht, bei der der Inhalt am Anfang und am Ende eines Prompts für das LLM ein größeres Gewicht hat als der Inhalt in der Mitte.
Berücksichtigen Sie schließlich die maximale Länge des Kontextfensters des LLM und die Anzahl der Token, die für die Vervollständigung außergewöhnlich langer Prompts erforderlich sind (insbesondere bei Abfragen in großem Umfang).
Um diese Probleme zu beheben, kann eine Pipeline nach dem Abruf die folgenden Schritte umfassen:
- Filterergebnisse: Stellen Sie in diesem Schritt sicher, dass die von der Vektordatenbank zurückgegebenen Artikelblöcke für die Abfrage relevant sind. Wenn dies nicht der Fall ist, wird das Ergebnis beim Kombinieren des LLM Prompts ignoriert.
- Re-Ranking: Reiht die aus dem Vektor-Store abgerufenen Artikel-Chunks, um sicherzustellen, dass die relevanten Details in der Nähe der Edges (Anfang und Ende) des Prompts liegen.
- Prompt Datenkomprimierung: Verwenden Sie ein kleines, kostengünstiges Modell, um mehrere Artikel-Chunks zu komprimieren und in einem einzigen komprimierten Prompt zusammenzufassen, bevor Sie den Prompt an das LLM senden.
Schritte nach abschluss der Verarbeitung
Die Verarbeitung nach der Vervollständigung erfolgt, nachdem die Abfrage des Benutzers und alle Inhalts-Chunks an das LLM gesendet wurden:

Die Richtigkeitsprüfung erfolgt nach der Vervollständigung des LLM durch den Prompt. Eine Pipeline nach abschluss der Verarbeitung kann die folgenden Schritte umfassen:
- Faktenüberprüfung: Die Absicht besteht darin, bestimmte Ansprüche im Artikel zu identifizieren, die als Fakten dargestellt werden, und dann diese Fakten auf Richtigkeit zu überprüfen. Wenn der Schritt der Faktenüberprüfung fehlschlägt, kann es sinnvoll sein, das LLM erneut abzufragen, in der Hoffnung, eine bessere Antwort zu erhalten, oder dem Benutzer eine Fehlermeldung zu übermitteln.
- Richtlinienüberprüfung: Die letzte Verteidigungslinie, um sicherzustellen, dass Antworten keine schädlichen Inhalte enthalten, unabhängig davon, ob für den Benutzer oder für die Organisation.
Auswertung
Die Auswertung der Ergebnisse eines nicht deterministischen Systems ist nicht so einfach wie das Ausführen der Komponententests oder Integrationstests, mit denen die meisten Entwickler vertraut sind. Sie müssen mehrere Faktoren berücksichtigen:
- Sind die Benutzer mit den Ergebnissen zufrieden, die sie erhalten?
- Erhalten Benutzer genaue Antworten auf ihre Fragen?
- Wie erfassen Sie Benutzerfeedback? Gibt es Richtlinien, die einschränken, welche Daten Sie über Benutzerdaten sammeln können?
- Für die Diagnose nicht zufriedenstellender Antworten haben Sie Einblick in den gesamten Aufwand, der in die Beantwortung der Frage eingeflossen ist? Behalten Sie ein Protokoll der einzelnen Phasen in der Ableitungspipeline von Eingaben und Ausgaben, damit Sie die Ursachenanalyse durchführen können?
- Wie können Sie Änderungen am System ohne Regression oder Verschlechterung der Ergebnisse vornehmen?
Erfassen und Handeln von Feedback von Benutzern
Wie bereits beschrieben, müssen Sie möglicherweise mit dem Datenschutzteam Ihrer Organisation zusammenarbeiten, um Mechanismen zur Erfassung von Feedback, Telemetrie und zur Protokollierung für forensische Analysen und zur Ursachenanalyse einer Abfragesitzung zu entwerfen.
Der nächste Schritt besteht darin, eine Bewertungspipeline zu entwickeln. Eine Pipeline für die Bewertung hilft bei der komplexen und zeitaufwändigen Analyse des wörtlichen Feedbacks und der Root-Ursachen der von einem KI-System gegebenen Antworten. Diese Analyse ist entscheidend, da sie jede Antwort untersucht, um zu verstehen, wie die KI-Abfrage die Ergebnisse erzeugt hat, die Angemessenheit der aus der Dokumentation verwendeten Inhaltsblöcke und die Strategien, die bei der Aufteilung dieser Dokumente verwendet werden.
Sie umfasst auch alle zusätzlichen Vorverarbeitungs- oder Nachbearbeitungsschritte, die die Ergebnisse verbessern können. Diese ausführliche Untersuchung deckt häufig Inhaltslücken auf, insbesondere, wenn keine geeignete Dokumentation für die Reaktion auf die Abfrage eines Benutzers vorhanden ist.
Das Erstellen einer Bewertungspipeline wird unerlässlich, um den Umfang dieser Aufgaben effektiv zu verwalten. Eine effiziente Pipeline verwendet maßgeschneiderte Werkzeuge, um Metriken auszuwerten, die sich der Qualität der von KI bereitgestellten Antworten annähern. Dieses System optimiert den Prozess der Ermittlung, warum eine bestimmte Antwort auf die Frage eines Benutzers gegeben wurde, welche Dokumente verwendet wurden, um diese Antwort zu generieren, und die Effektivität der Ableitungspipeline, die die Abfragen verarbeitet.
Goldenes Dataset
Eine Strategie zur Auswertung der Ergebnisse eines nicht deterministischen Systems wie ein RAG-Chatsystem besteht darin, ein goldenes Dataset zu verwenden. Ein goldenes Dataset ist ein kuratiertes Set von Fragen und genehmigten Antworten, Metadaten (wie Thema und Art der Frage), Verweise auf Quelldokumente, die als Grundlage für die Antworten dienen können, und sogar Variationen (verschiedene Formulierungen, um die Vielfalt der Art und Weise zu erfassen, wie Benutzer dieselben Fragen stellen könnten).
Ein goldenes Dataset stellt das "best case scenario" dar. Entwickler können das System auswerten, um zu sehen, wie gut es funktioniert, und dann Regressionstests durchführen, wenn sie neue Features oder Updates implementieren.
Bewerten von Schäden
Harms Modeling ist eine Methodik, die darauf abzielt, potenzielle Schäden zu erkennen, Mängel in einem Produkt zu erkennen, die Risiken für Einzelpersonen darstellen können, und proaktive Strategien zur Abmilderung solcher Risiken zu entwickeln.
Ein Tool zur Bewertung der Auswirkungen der Technologie, insbesondere KI-Systeme, würde mehrere Schlüsselkomponenten auf der Grundlage der Prinzipien der Schadensmodellierung enthalten, wie in den bereitgestellten Ressourcen beschrieben.
Zu den wichtigsten Merkmalen eines Tools zur Schadenbewertung gehören u. U.:
Identifizierung der Beteiligten: Das Tool kann Benutzern helfen, verschiedene Interessenträger zu identifizieren und zu kategorisieren, die von der Technologie betroffen sind, einschließlich direkter Benutzer, indirekt betroffener Parteien und anderer Entitäten, z. B. zukünftige Generationen oder nichtmenschliche Faktoren, z. B. Umweltbedenken.
Schadenskategorien und Beschreibungen: Das Tool kann eine umfassende Liste potenzieller Schäden enthalten, z. B. Datenschutzverlust, emotionale Not oder wirtschaftliche Ausbeutung. Das Tool kann den Benutzer durch verschiedene Szenarien leiten, veranschaulichen, wie die Technologie diese Schäden verursachen kann, und hilft dabei, sowohl beabsichtigte als auch unbeabsichtigte Folgen zu bewerten.
Schweregrad- und Wahrscheinlichkeitsbewertungen: Das Tool kann Benutzern helfen, den Schweregrad und die Wahrscheinlichkeit jedes identifizierten Schadens zu bewerten. Der Benutzer kann Probleme priorisieren, die zuerst behandelt werden sollen. Beispiele hierfür sind qualitative Bewertungen, die von Daten unterstützt werden, sofern verfügbar.
Minderungsstrategien: Das Tool kann potenzielle Minderungsstrategien vorschlagen, nachdem es Schäden identifiziert und bewertet hat. Beispiele sind Änderungen am Systemdesign, das Hinzufügen von Schutzmaßnahmen und alternative technologische Lösungen, die identifizierte Risiken minimieren.
Feedback-Mechanismen: Das Tool sollte Mechanismen zur Einholung von Feedback von Stakeholdern enthalten, damit der Prozess der Schadensbewertung dynamisch ist und auf neue Informationen und Perspektiven reagieren kann.
Dokumentation und Berichterstellung: Für Transparenz und Rechenschaftspflicht kann das Tool detaillierte Berichte erleichtern, die den Schadenbewertungsprozess, die Ergebnisse und mögliche Maßnahmen zur Risikominderung dokumentieren.
Diese Features können Ihnen helfen, Risiken zu erkennen und zu mindern, aber sie helfen Ihnen auch, ethischere und verantwortungsvolleRE KI-Systeme zu entwerfen, indem Sie von Anfang an ein breites Spektrum von Auswirkungen berücksichtigen.
Weitere Informationen finden Sie in den folgenden Artikeln:
Testen und Überprüfen der Sicherheitsvorkehrungen
In diesem Artikel werden mehrere Prozesse beschrieben, die darauf abzielen, die Möglichkeit zu verringern, dass ein RAG-basiertes Chatsystem ausgenutzt oder kompromittiert wird. Red-Teaming spielt eine entscheidende Rolle bei der Sicherstellung, dass die Behebungen wirksam sind. Red-Teaming beinhaltet die Simulation der Aktionen eines potenziellen Gegners, um potenzielle Schwachstellen oder Sicherheitsrisiken in der Anwendung aufzudecken. Dieser Ansatz ist besonders wichtig bei der Bewältigung des erheblichen Risikos von Jailbreaking.
Entwickler müssen die SICHERHEITsvorkehrungen des RAG-basierten Chatsystems unter verschiedenen Richtlinienszenarien streng bewerten, um sie effektiv zu testen und zu überprüfen. Dieser Ansatz gewährleistet nicht nur die Robustheit, sondern hilft Ihnen auch, die Antworten des Systems auf die strikte Einhaltung von definierten ethischen Standards und betrieblichen Verfahren zu optimieren.
Abschließende Überlegungen zum Anwendungsdesign
Nachfolgend finden Sie eine kurze Liste der Punkte, die Sie berücksichtigen sollten, und andere Aspekte aus diesem Artikel, die sich auf Ihre Entscheidungen im Anwendungsentwurf auswirken können:
- Erkennen Sie die unbestimmte Natur der generativen KI in Ihrem Design an. Planen Sie die Variabilität in den Ausgaben, und richten Sie Mechanismen ein, um Konsistenz und Relevanz bei Antworten sicherzustellen.
- Bewerten Sie die Vorteile der Vorverarbeitung von Benutzeraufforderungen gegen die potenzielle Erhöhung der Latenz und Kosten. Das Vereinfachen oder Ändern von Eingabeaufforderungen vor der Übermittlung kann die Antwortqualität verbessern, aber es kann Komplexität und Zeit zum Antwortzyklus hinzufügen.
- Um die Leistung zu verbessern, untersuchen Sie Strategien zur Parallelisierung von LLM-Anforderungen. Dieser Ansatz kann die Latenz reduzieren, erfordert jedoch eine sorgfältige Verwaltung, um eine höhere Komplexität und potenzielle Kostenauswirkungen zu vermeiden.
Wenn Sie sofort mit dem Aufbau einer generativen KI-Lösung experimentieren möchten, empfehlen wir Ihnen einen Blick auf Get started with chat by using your own data sample for Python. Das Lernprogramm ist auch für .NET-, Java-und JavaScript-verfügbar.