Visualisierungstypen
In diesem Artikel werden die Arten von Visualisierungen beschrieben, die in Azure Databricks-Notebooks und in Databricks SQL verwendet werden können. Außerdem wird gezeigt, wie Sie ein Beispiel für jeden Visualisierungstyp erstellen.
Hinweis
Informationen zu den für AI/BI-Dashboards verfügbaren Visualisierungstypen finden Sie unter Dashboardvisualisierungstypen.
Balkendiagramm
Balkendiagramme stellen die Änderung der Metriken im Laufe der Zeit oder die Proportionalität dar, ähnlich wie ein Kreisdiagramm.
Hinweis
Balkendiagramme unterstützen Back-End-Aggregationen und Abfragen, die mehr als 64.000 Datenzeilen zurückgeben, ohne Resultsets abzuschneiden.
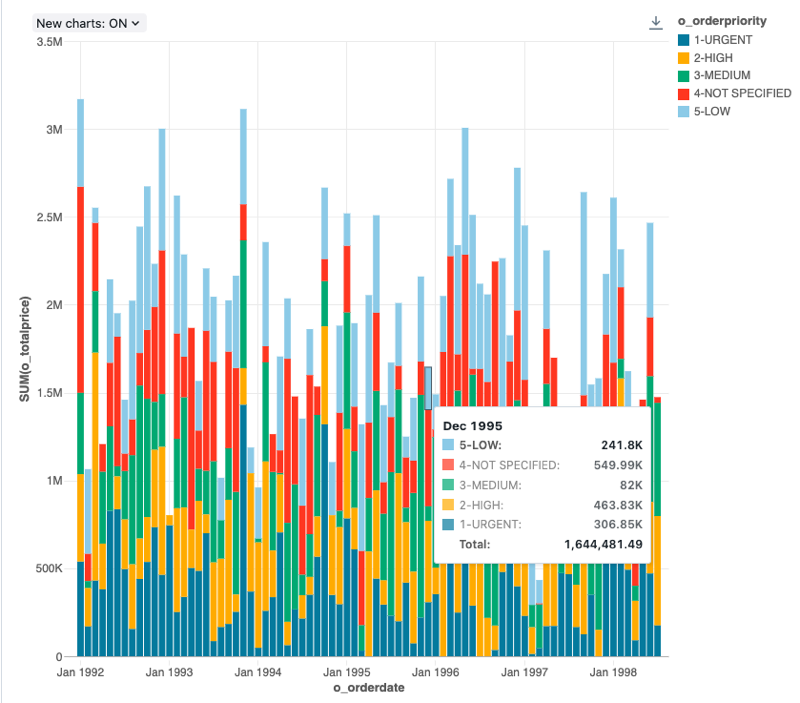
Konfigurationswerte: Für diese Balkendiagrammvisualisierung wurden die folgenden Werte festgelegt:
- X-Spalte:
- Datasetspalte:
o_orderdate - Datumsebene:
Months
- Datasetspalte:
- Y-Spalten:
- Datasetspalte:
o_totalprice - Aggregationstyp:
Sum
- Datasetspalte:
- Gruppieren nach (Datasetspalte):
o_orderpriority - Stapel:
Stack - Name der X-Achse (Standardwert überschreiben):
Order month - Name der Y-Achse (Standardwert überschreiben):
Total price
Konfigurationsoptionen: Informationen zu Konfigurationsoptionen für Balkendiagramme finden Sie unter Konfigurationsoptionen für Diagramme.
SQL-Abfrage: Für diese Balkendiagrammvisualisierung wurde die folgende SQL-Abfrage verwendet, um das Dataset zu generieren:
select * from samples.tpch.orders
Liniendiagramm
Liniendiagramme stellen die Änderung an einer oder mehreren Metriken im Laufe der Zeit dar.
Hinweis
Liniendiagramme unterstützen Back-End-Aggregationen und Abfragen, die mehr als 64.000 Datenzeilen zurückgeben, ohne Resultsets abzuschneiden.
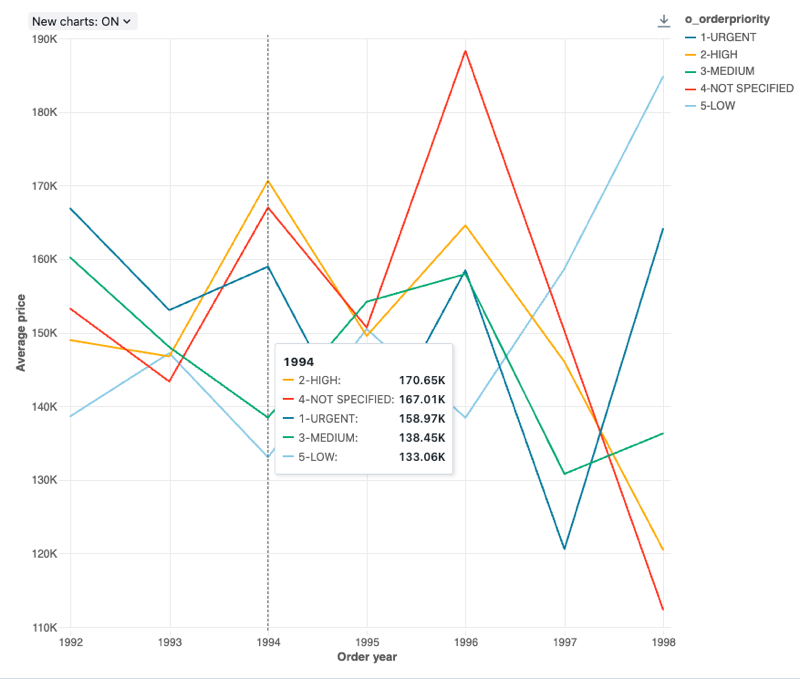
Konfigurationswerte: Für diese Liniendiagrammvisualisierung wurden die folgenden Werte festgelegt:
- X-Spalte:
- Datasetspalte:
o_orderdate - Datumsebene:
Years
- Datasetspalte:
- Y-Spalten:
- Datasetspalte:
o_totalprice - Aggregationstyp:
Average
- Datasetspalte:
- Gruppieren nach (Datasetspalte):
o_orderpriority - Name der X-Achse (Standardwert überschreiben):
Order year - Name der Y-Achse (Standardwert überschreiben):
Average price
Konfigurationsoptionen: Informationen zu Konfigurationsoptionen für Liniendiagramme finden Sie unter Konfigurationsoptionen für Diagramme.
SQL-Abfrage: Für diese Liniendiagrammvisualisierung wurde die folgende SQL-Abfrage verwendet, um das Dataset zu generieren:
select * from samples.tpch.orders
Flächendiagramm
Flächendiagramme kombinieren das Linien- und Balkendiagramm, um zu veranschaulichen, wie sich die numerischen Werte von einer oder mehreren Gruppen über den Verlauf einer zweiten Variablen ändern, in der Regel die Zeit. Sie werden häufig verwendet, um Änderungen des Verkaufstrichters im Laufe der Zeit zu zeigen.
Hinweis
Flächendiagramme unterstützen Back-End-Aggregationen und Abfragen, die mehr als 64.000 Datenzeilen zurückgeben, ohne Resultsets abzuschneiden.
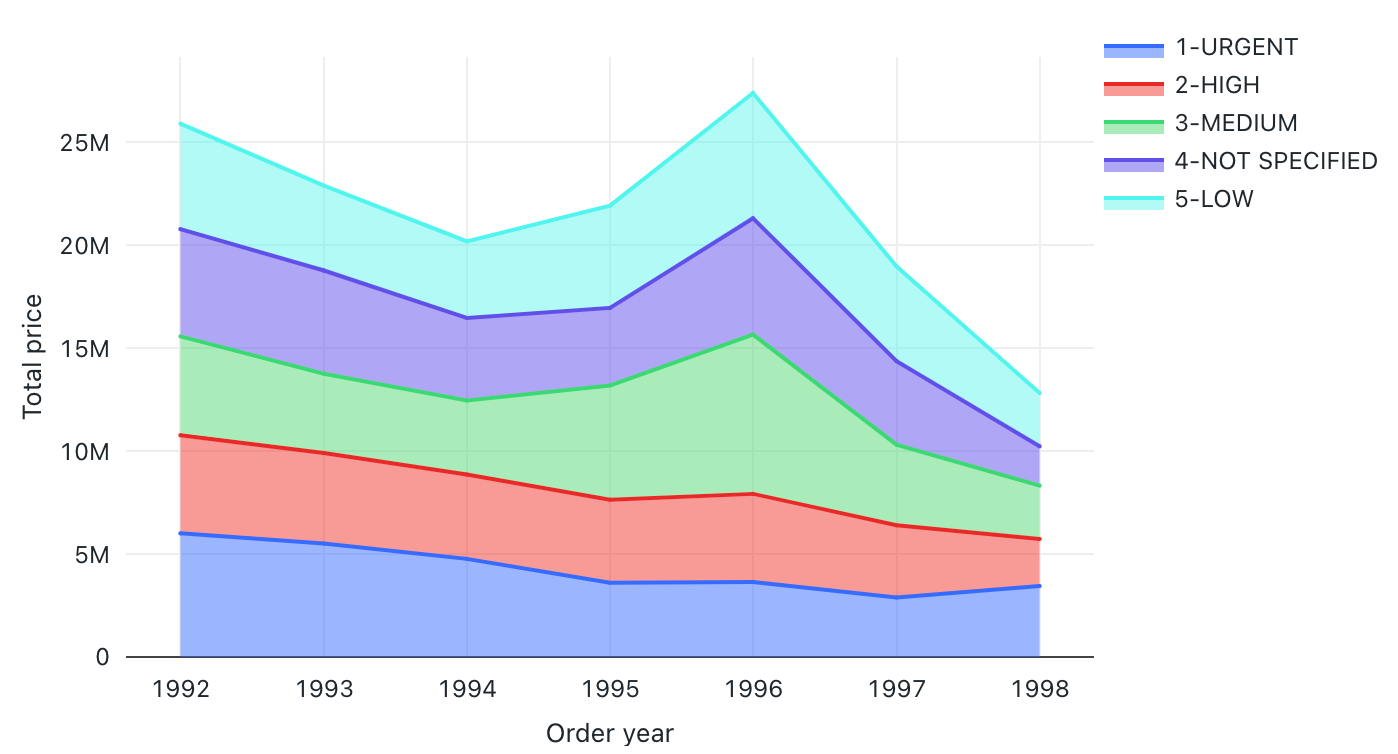
Konfigurationswerte: Für diese Flächendiagrammvisualisierung wurden die folgenden Werte festgelegt:
- X-Spalte:
- Datasetspalte:
o_orderdate - Datumsebene:
Years
- Datasetspalte:
- Y-Spalten:
- Datasetspalte:
o_totalprice - Aggregationstyp:
Sum
- Datasetspalte:
- Gruppieren nach (Datasetspalte):
o_orderpriority - Stapel:
Stack - Name der X-Achse (Standardwert überschreiben):
Order year - Name der Y-Achse (Standardwert überschreiben):
Total price
Konfigurationsoptionen: Informationen zu Konfigurationsoptionen für Flächendiagramme finden Sie unter Konfigurationsoptionen für Diagramme.
SQL-Abfrage: Für diese Flächendiagrammvisualisierung wurde die folgende SQL-Abfrage verwendet, um das Dataset zu generieren:
select * from samples.tpch.orders
Kreisdiagramme
Kreisdiagramme veranschaulichen die Proportionalität zwischen Metriken. Sie sind nicht für die Übertragung von Zeitreihendaten gedacht.
Hinweis
Kreisdiagramme unterstützen Back-End-Aggregationen und Abfragen, die mehr als 64.000 Datenzeilen zurückgeben, ohne Resultsets abzuschneiden.
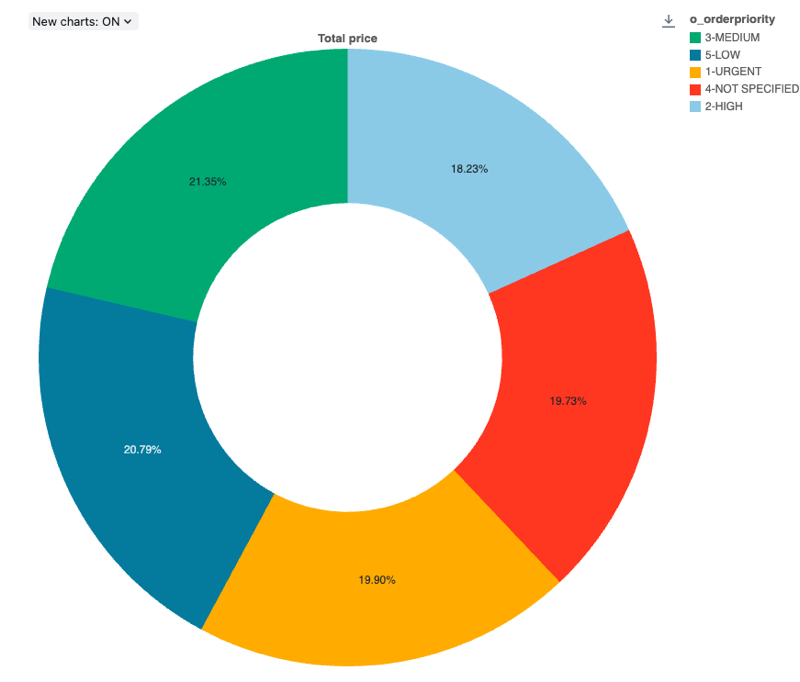
Konfigurationswerte: Für diese Kreisdiagrammvisualisierung wurden die folgenden Werte festgelegt:
- X-Spalte (Datasetspalte):
o_orderpriority - Y-Spalten:
- Datasetspalte:
o_totalprice - Aggregationstyp:
Sum
- Datasetspalte:
- Bezeichnung (Standardwert überschreiben):
Total price
Konfigurationsoptionen: Informationen zu Konfigurationsoptionen für Kreisdiagramme finden Sie unter Konfigurationsoptionen für Diagramme.
SQL-Abfrage: Für diese Kreisdiagrammvisualisierung wurde die folgende SQL-Abfrage verwendet, um das Dataset zu generieren:
select * from samples.tpch.orders
Histogramme
Ein Histogramm zeichnet die Häufigkeit auf, mit der ein gegebener Wert in einem Dataset auftritt. Ein Histogramm hilft Ihnen zu verstehen, ob ein Dataset Werte enthält, die um eine kleine Anzahl von Bereichen gruppiert sind oder mehr verteilt sind. Ein Histogramm wird als Balkendiagramm angezeigt, in dem Sie die Anzahl der eindeutigen Balken (auch als Intervalle bezeichnet) steuern.
Hinweis
Histogramme unterstützen Back-End-Aggregationen und Abfragen, die mehr als 64.000 Datenzeilen zurückgeben, ohne Resultsets abzuschneiden.
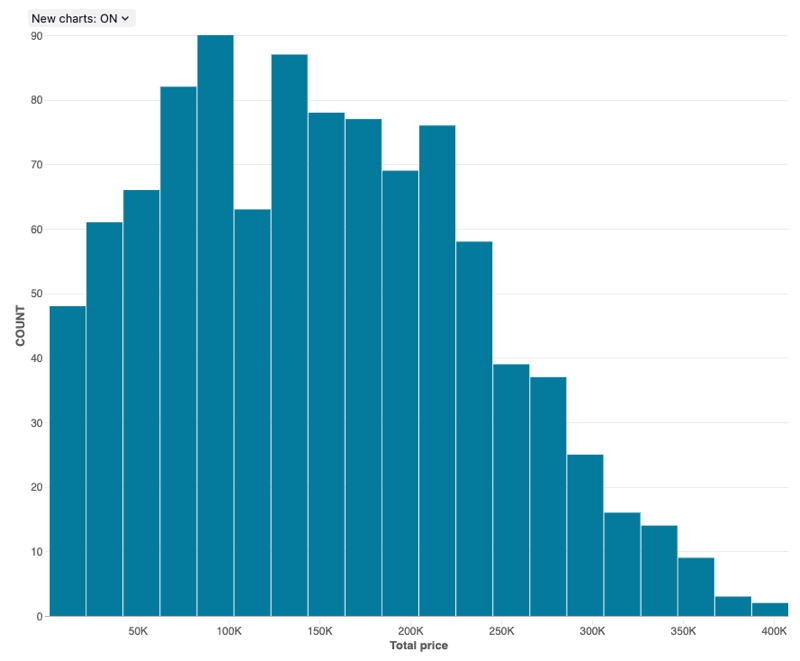
Konfigurationswerte: Für diese Histogrammvisualisierung wurden die folgenden Werte festgelegt:
- X-Spalte (Datasetspalte):
o_totalprice - Anzahl der Bins: 20
- Name der X-Achse (Standardwert überschreiben):
Total price
Konfigurationsoptionen: Informationen zu Konfigurationsoptionen für Histogramme finden Sie unter Konfigurationsoptionen für Histogramme.
SQL-Abfrage: Für diese Histogrammvisualisierung wurde die folgende SQL-Abfrage verwendet, um das Dataset zu generieren:
select * from samples.tpch.orders
Wärmebilder
Wärmebilder vereinen Merkmale von Balkendiagrammen, Stapeln und Blasendiagrammen, sodass Sie numerische Daten mithilfe von Farben visualisieren können. Eine allgemeine Farbpalette für ein Wärmebild zeigt die höchsten Werte in wärmeren Farben wie Orange oder Rot und die niedrigsten Werte in kälteren Farben wie Blau oder Lila an.
Betrachten Sie beispielsweise das folgende Wärmebild, in dem die häufigsten Entfernungen bei Taxifahrten an jedem Tag visualisiert und die Ergebnisse nach Wochentag, Entfernung, Gesamtpreis gruppiert werden.
Hinweis
Wärmebilder unterstützen Back-End-Aggregationen und Abfragen, die mehr als 64.000 Datenzeilen zurückgeben, ohne Resultsets abzuschneiden.
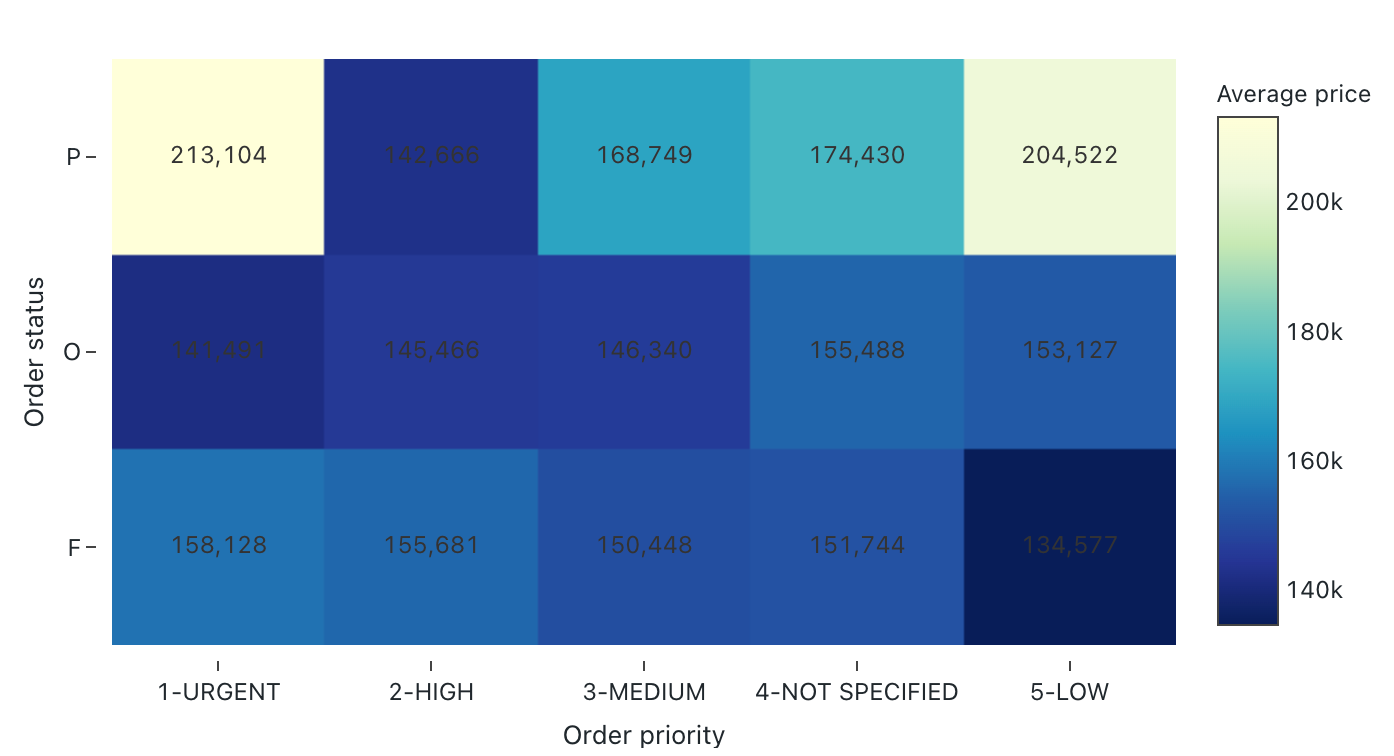
Konfigurationswerte: Für diese Wärmebildvisualisierung wurden die folgenden Werte festgelegt:
- X-Spalte (Datasetspalte):
o_orderpriority - Y-Spalten (Datasetspalte):
o_orderstatus - Farbspalte:
- Datasetspalte:
o_totalprice - Aggregationstyp:
Average
- Datasetspalte:
- Name der X-Achse (Standardwert überschreiben):
Order priority - Name der Y-Achse (Standardwert überschreiben):
Order status - Farbname (Standardwert außer Kraft setzen):
Average price - Farbschema (Standardwert überschreiben):
YIGnBu
Konfigurationsoptionen: Informationen zu Konfigurationsoptionen für Wärmebilder finden Sie unter Konfigurationsoptionen für Wärmebilder.
SQL-Abfrage: Für diese Wärmebildvisualisierung wurde die folgende SQL-Abfrage verwendet, um das Dataset zu generieren:
select * from samples.tpch.orders
Punktdiagramm
Punktdiagramme werden häufig verwendet, um die Beziehung zwischen zwei numerischen Variablen zu visualisieren. Darüber hinaus kann eine dritte Dimension farbcodiert werden, um zu veranschaulichen, wie sich die numerischen Variablen in verschiedenen Gruppen unterscheiden.
Hinweis
Punktdiagramme unterstützen Back-End-Aggregationen und Abfragen, die mehr als 64.000 Datenzeilen zurückgeben, ohne Resultsets abzuschneiden.
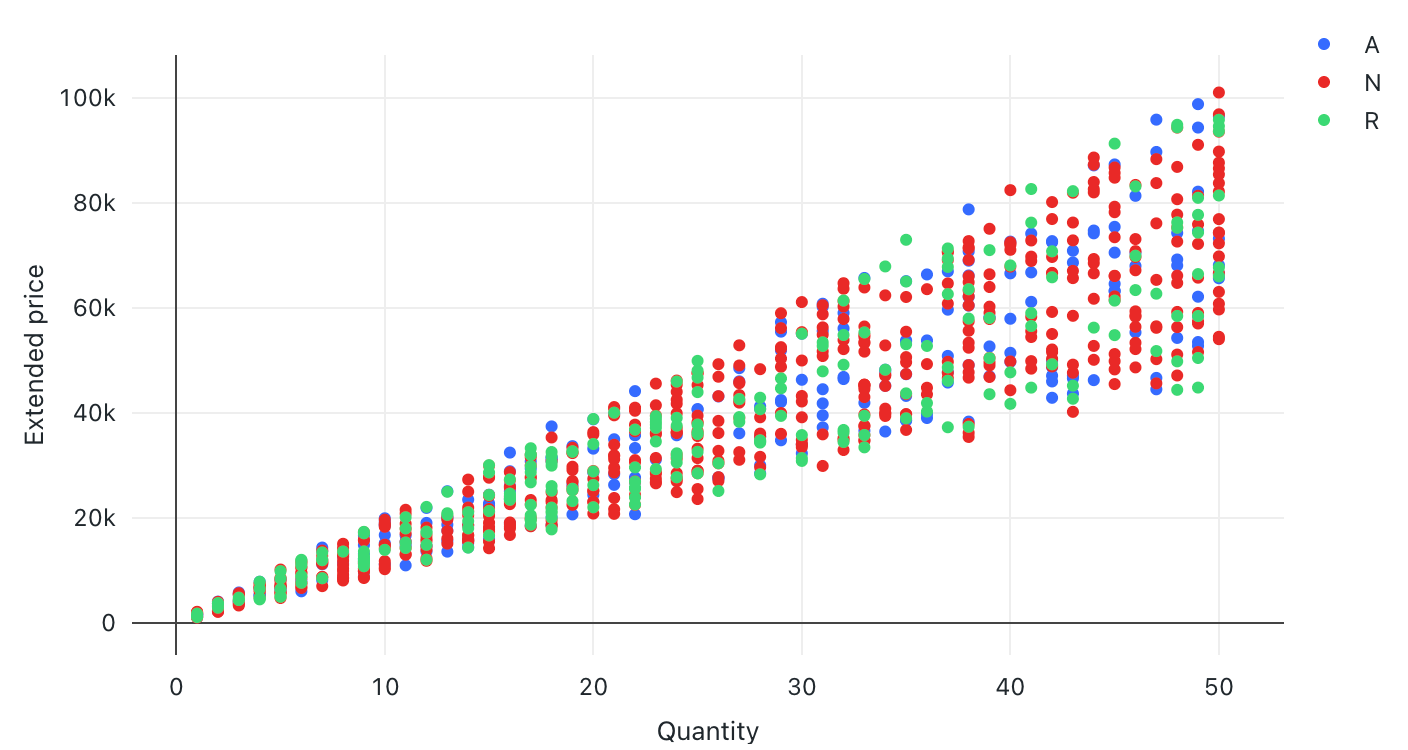
Konfigurationswerte: Für diese Punktdiagrammvisualisierung wurden die folgenden Werte festgelegt:
- X-Spalte (Datasetspalte):
l_quantity - Y-Spalte (Datasetspalte):
l_extendedprice - Gruppieren nach (Datasetspalte):
l_returnflag - Name der X-Achse (Standardwert überschreiben):
Quantity - Name der Y-Achse (Standardwert überschreiben):
Extended price
Konfigurationsoptionen: Informationen zu Konfigurationsoptionen für Punktdiagramme finden Sie unter Konfigurationsoptionen für Diagramme.
SQL-Abfrage: Für diese Punktdiagrammvisualisierung wurde die folgende SQL-Abfrage verwendet, um das Dataset zu generieren:
select * from samples.tpch.lineitem
Blasendiagramm
Blasendiagramme sind Punktdiagramme, bei denen die Größe der einzelnen Punktmarker eine relevante Metrik widerspiegelt.
Hinweis
Blasendiagramme unterstützen Back-End-Aggregationen und Abfragen, die mehr als 64.000 Datenzeilen zurückgeben, ohne Resultsets abzuschneiden.
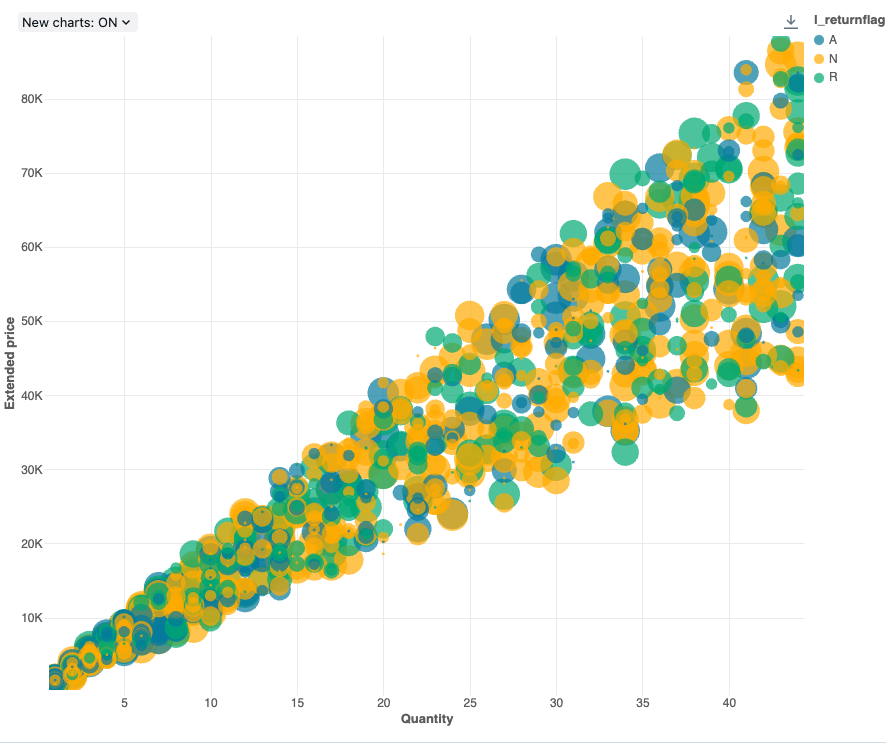
Konfigurationswerte: Für diese Blasendiagrammvisualisierung wurden die folgenden Werte festgelegt:
- X (Datasetspalte):
l_quantity - Y-Spalten (Datasetspalte):
l_extendedprice - Gruppieren nach (Datasetspalte):
l_returnflag - Spalte für Blasengröße (Datasetspalte):
l_tax - Koeffizient für Blasengröße: 20
- Blasengröße proportional zu:
Area - Name der X-Achse (Standardwert überschreiben):
Quantity - Name der Y-Achse (Standardwert überschreiben):
Extended price
Konfigurationsoptionen: Informationen zu Konfigurationsoptionen für Blasendiagramme finden Sie unter Konfigurationsoptionen für Diagramme.
SQL-Abfrage: Für diese Blasendiagrammvisualisierung wurde die folgende SQL-Abfrage verwendet, um das Dataset zu generieren:
select * from samples.tpch.lineitem where l_quantity < 45
Boxplot
Die Boxplotvisualisierung veranschaulicht die Verteilungszusammenfassung numerischer Daten, optional nach Kategorie gruppiert. Mithilfe einer Boxplotvisualisierung können Sie Wertbereiche schnell kategorieübergreifend vergleichen und die Lage, Verteilung und Schiefe der Werte über ihre Quartile visualisieren. In jedem Feld gibt die dunklere Linie den Interquartilsabstand an. Weitere Informationen zum Interpretieren von Boxplotvisualisierungen finden Sie im Artikel zu Boxplot auf Wikipedia.
Hinweis
Boxplots unterstützen nur die Aggregation von bis zu 64.000 Zeilen. Wenn ein Dataset größer als 64.000 Zeilen ist, werden die Daten abgeschnitten.
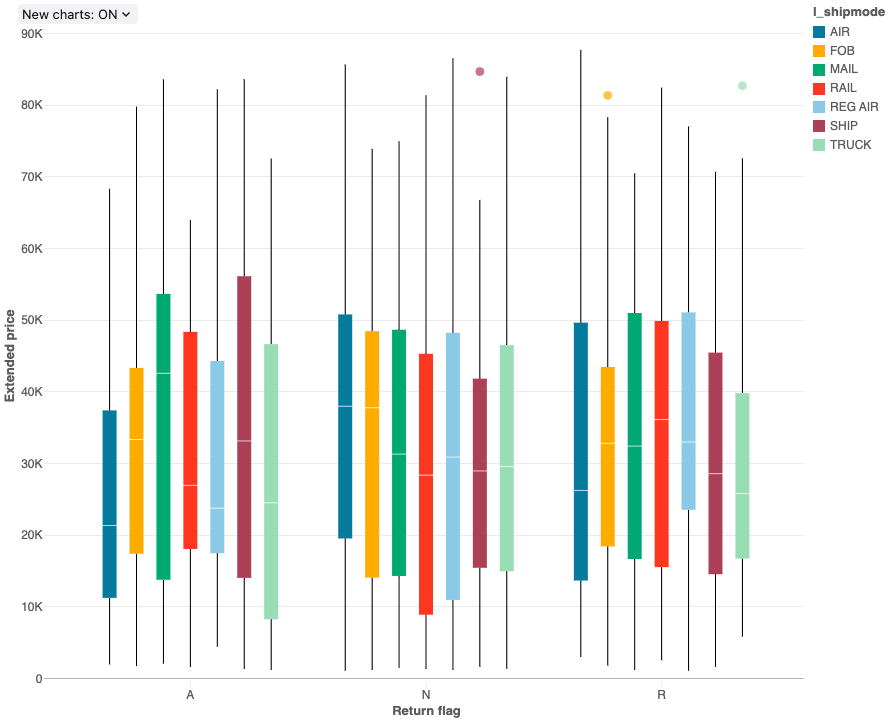
Konfigurationswerte: Für diese Boxplotvisualisierung wurden die folgenden Werte festgelegt:
- X-Spalte (Datasetspalte):
l_returnflag - Y-Spalten (Datasetspalte):
l_extendedprice - Gruppieren nach (Datasetspalte):
l_shipmode - Name der X-Achse (Standardwert überschreiben):
Return flag - Name der Y-Achse (Standardwert überschreiben):
Extended price
Konfigurationsoptionen: Informationen zu Konfigurationsoptionen für Boxplots finden Sie unter Konfigurationsoptionen für Boxplots.
SQL-Abfrage: Für diese Boxplotvisualisierung wurde die folgende SQL-Abfrage verwendet, um das Dataset zu generieren:
select * from samples.tpch.lineitem
Kombinationsdiagramm
Kombinationsdiagramme kombinieren Linien- und Balkendiagramme, um die Änderungen im Laufe der Zeit mit Proportionalität darzustellen.
Hinweis
Kombinationsdiagramme unterstützen Back-End-Aggregationen und Abfragen, die mehr als 64.000 Datenzeilen zurückgeben, ohne Resultsets abzuschneiden.
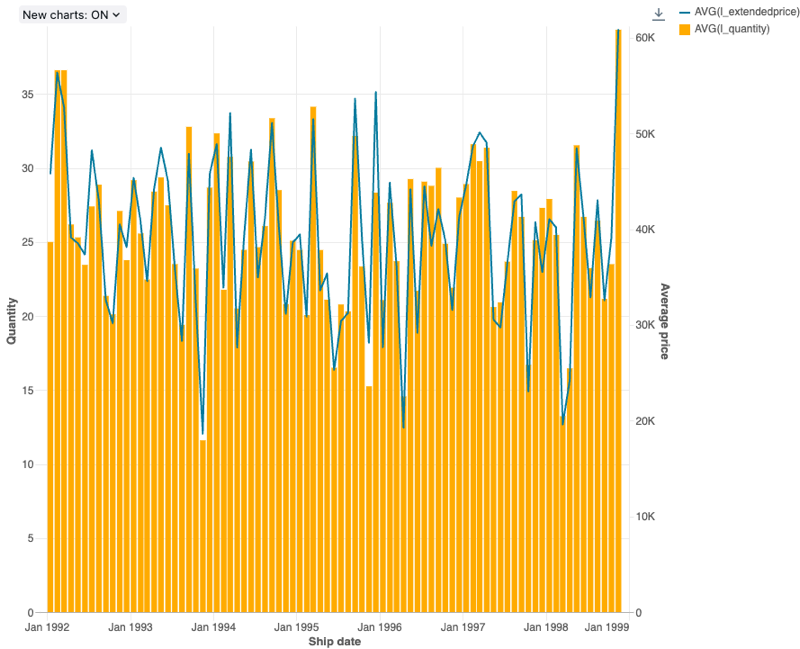
Konfigurationswerte: Für diese Kombinationsdiagrammvisualisierung wurden die folgenden Werte festgelegt:
- X-Spalte:
- Datasetspalte:
l_shipdate - Datumsebene:
Months
- Datasetspalte:
- Y-Spalten:
- Erste Datasetspalte:
l_extendedprice - Aggregationstyp: Durchschnitt
- Zweite Datasetspalte:
l_quantity - Aggregationstyp: Durchschnitt
- Erste Datasetspalte:
- Name der X-Achse (Standardwert überschreiben):
Ship date - Name der linken Y-Achse (Standardwert überschreiben):
Quantity - Name der rechten Y-Achse (Standardwert überschreiben):
Average price - Reihe:
- Order1 (Datasetspalte):
AVG(l_extendedprice) - Y-Achse: rechts
- Typ: Linie
- Order2 (Datasetspalte):
AVG(l_quantity) - Y-Achse: links
- Typ: Balken
- Order1 (Datasetspalte):
Konfigurationsoptionen: Informationen zu Konfigurationsoptionen für Kombinationsdiagramme finden Sie unter Konfigurationsoptionen für Diagramme.
SQL-Abfrage: Für diese Kombinationsdiagrammvisualisierung wurde die folgende SQL-Abfrage verwendet, um das Dataset zu generieren:
select * from samples.tpch.lineitem
Kohortenanalyse
Bei einer Kohortenanalyse werden die Ergebnisse vordefinierter Gruppen, so genannter Kohorten, beim Durchlaufen einer Reihe von Phasen untersucht. Die Kohortvisualisierung aggregiert nur Datumsangaben (monatliche Aggregationen möglich). Es werden keine anderen Daten innerhalb des Resultsets aggregiert. Alle anderen Aggregationen werden innerhalb der Abfrage selbst ausgeführt.
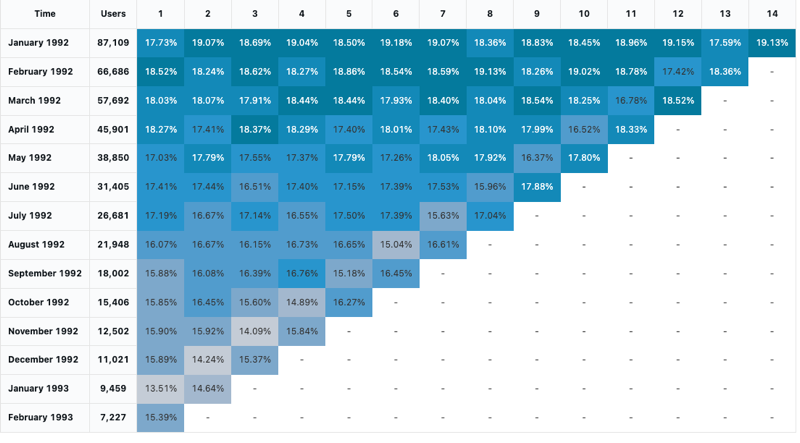
Konfigurationswerte: Für diese Kohortenvisualisierung wurden die folgenden Werte festgelegt:
- Datum (Bucket) (Datenbankspalte):
cohort_month - Phase (Datenbankspalte):
months - Auffüllungsgröße des Bucket (Datenbankspalte):
size - Phasenwert (Datenbankspalte):
active - Zeitintervall:
monthly
Konfigurationsoptionen: Informationen zu Konfigurationsoptionen für Kohorten finden Sie unter Konfigurationsoptionen für Kohortendiagramme.
SQL-Abfrage: Für diese Kohortenvisualisierung wurde die folgende SQL-Abfrage verwendet, um das Dataset zu generieren:
-- match each customer with its cohort by month
with cohort_dates as (
SELECT o_custkey, min(date_trunc('month', o_orderdate)) as cohort_month
FROM samples.tpch.orders
GROUP BY 1
),
-- find the size of each cohort
cohort_size as (
SELECT cohort_month, count(distinct o_custkey) as size
FROM cohort_dates
GROUP BY 1
)
-- for each cohort and month thereafter, find the number of active customers
SELECT
cohort_dates.cohort_month,
ceil(months_between(date_trunc('month', samples.tpch.orders.o_orderdate), cohort_dates.cohort_month)) as months,
count(distinct samples.tpch.orders.o_custkey) as active,
first(size) as size
FROM samples.tpch.orders
left join cohort_dates on samples.tpch.orders.o_custkey = cohort_dates.o_custkey
left join cohort_size on cohort_dates.cohort_month = cohort_size.cohort_month
WHERE datediff(date_trunc('month', samples.tpch.orders.o_orderdate), cohort_dates.cohort_month) != 0
GROUP BY 1, 2
ORDER BY 1, 2
Zähleranzeige
Zähler zeigen einen einzelnen Wert hervorgehoben an. Dieser kann auch mit einem Zielwert verglichen werden. Um Zähler zu verwenden, geben Sie an, welche Datenzeile in der Zählervisualisierung für die Wertspalte und die Zielspalte angezeigt werden soll.
Hinweis
Zähler unterstützen nur die Aggregation von bis zu 64.000 Zeilen. Wenn ein Dataset größer als 64.000 Zeilen ist, werden die Daten abgeschnitten.
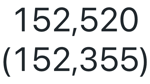
Konfigurationswerte: Für diese Zählervisualisierung wurden die folgenden Werte festgelegt:
- Wertspalte
- Datasetspalte:
avg(o_totalprice) - Zeile 1:
- Datasetspalte:
- Zielspalte:
- Datasetspalte:
avg(o_totalprice) - Zeile 2:
- Datasetspalte:
- Formatzielwert: Enable
SQL-Abfrage: Für diese Zählervisualisierung wurde die folgende SQL-Abfrage verwendet, um das Dataset zu generieren:
select o_orderdate, avg(o_totalprice)
from samples.tpch.orders
GROUP BY 1
ORDER BY 1 DESC
Trichtervisualisierung
Die Trichtervisualisierung hilft dabei, die Änderung in einer Metrik in verschiedenen Phasen zu analysieren. Um den Trichter zu verwenden, geben Sie die Spalten step und value an.
Hinweis
Trichter unterstützen nur die Aggregation von bis zu 64.000 Zeilen. Wenn ein Dataset größer als 64.000 Zeilen ist, werden die Daten abgeschnitten.
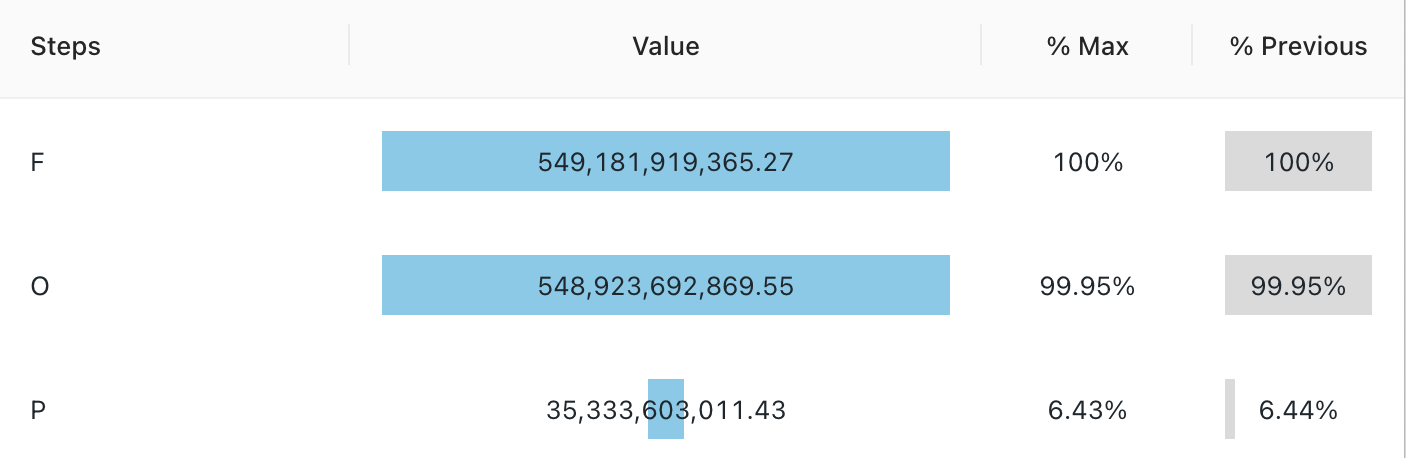
Konfigurationswerte: Für diese Trichtervisualisierung wurden die folgenden Werte festgelegt:
- Schrittspalte (Datasetspalte):
o_orderstatus - Wertspalte (Datasetspalte):
Revenue
SQL-Abfrage: Für diese Trichtervisualisierung wurde die folgende SQL-Abfrage verwendet, um das Dataset zu generieren:
SELECT o_orderstatus, sum(o_totalprice) as Revenue
FROM samples.tpch.orders
GROUP BY 1
Kartenvisualisierung (Choropleth)
In Choroplethenvisualisierungen werden geografische Orte (z. B. Länder oder Staaten) entsprechend den aggregierten Werten der einzelnen Schlüsselspalten eingefärbt. Die Abfrage muss geografische Standorte nach Namen zurückgeben.
Hinweis
Choroplethenvisualisierungen aggregieren keine Daten innerhalb des Resultsets. Alle Aggregationen müssen innerhalb der Abfrage selbst berechnet werden.
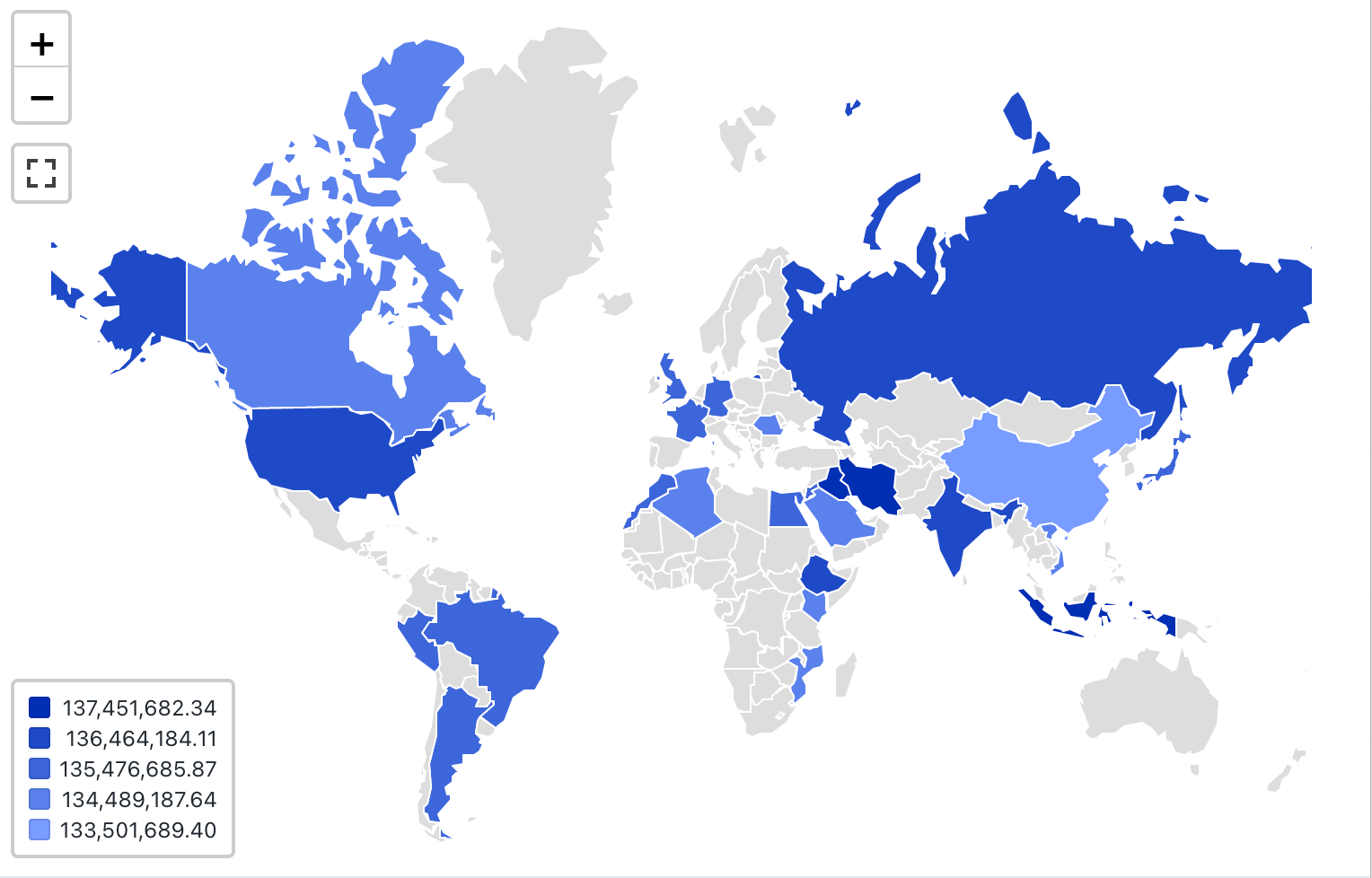
Konfigurationswerte: Für diese Choroplethenvisualisierung wurden die folgenden Werte festgelegt:
- Karte (Datasetspalte):
Countries - Geografische Spalte (Datasetspalte):
Country - Geografischer Typ: Kurzname
- Wertspalte (Datasetspalte):
Revenue - Clusteringmodus: äquidistant
Konfigurationsoptionen: Informationen zu Konfigurationsoptionen für Choroplethen finden Sie unter Konfigurationsoptionen für Choroplethen.
SQL-Abfrage: Für diese Choroplethenvisualisierung wurde die folgende SQL-Abfrage verwendet, um das Dataset zu generieren:
SELECT
initcap(n_name) as Country,
sum(c_acctbal)
FROM samples.tpch.customer
join samples.tpch.nation where n_nationkey = c_nationkey
GROUP BY 1
Markerkartenvisualisierung
In Markervisualisierungen wird ein Marker an einer Reihe von Koordinaten auf der Karte platziert. Das Abfrageergebnis muss Paare von Breiten- und Längengraden zurückgeben.
Hinweis
Marker aggregieren keine Daten innerhalb des Resultsets. Alle Aggregationen müssen innerhalb der Abfrage selbst berechnet werden.
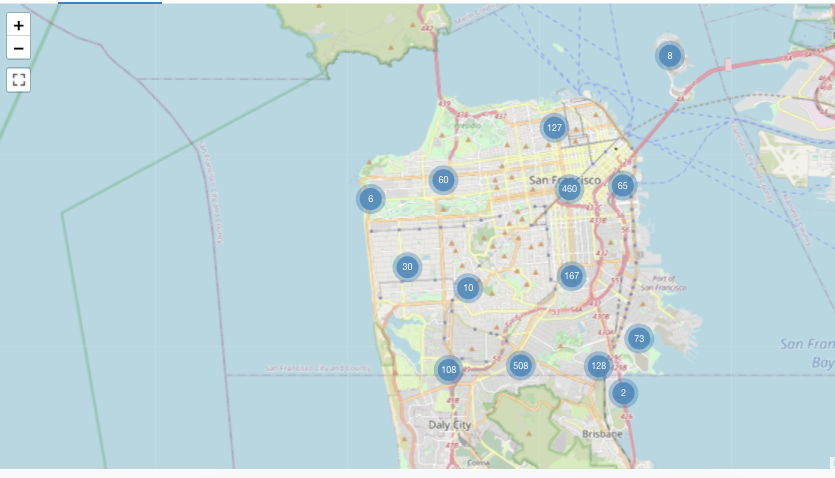
Dieses Markerbeispiel wird aus einem Dataset generiert, das Werte für Breiten- und Längengrade enthält, die in den Databricks-Beispieldatasets nicht verfügbar sind. Konfigurationsoptionen für Choroplethen finden Sie unter Konfigurationsoptionen für Marker.
Pivottabellenvisualisierung
Die Pivottabellenvisualisierung aggregiert Datensätze aus einem Abfrageergebnis in einer neuen tabellarischen Anzeige. Sie ähnelt den Anweisungen PIVOT oder GROUP BY in SQL. Sie konfigurieren die Pivottabellenvisualisierung mit Drag & Drop-Feldern.
Hinweis
Pivottabellen unterstützen Back-End-Aggregationen und Abfragen, die mehr als 64.000 Datenzeilen zurückgeben, ohne Resultsets abzuschneiden. Pivottabellen (Legacy) unterstützen jedoch nur die Aggregation von bis zu 64.000 Zeilen. Wenn ein Dataset größer als 64.000 Zeilen ist, werden die Daten abgeschnitten.
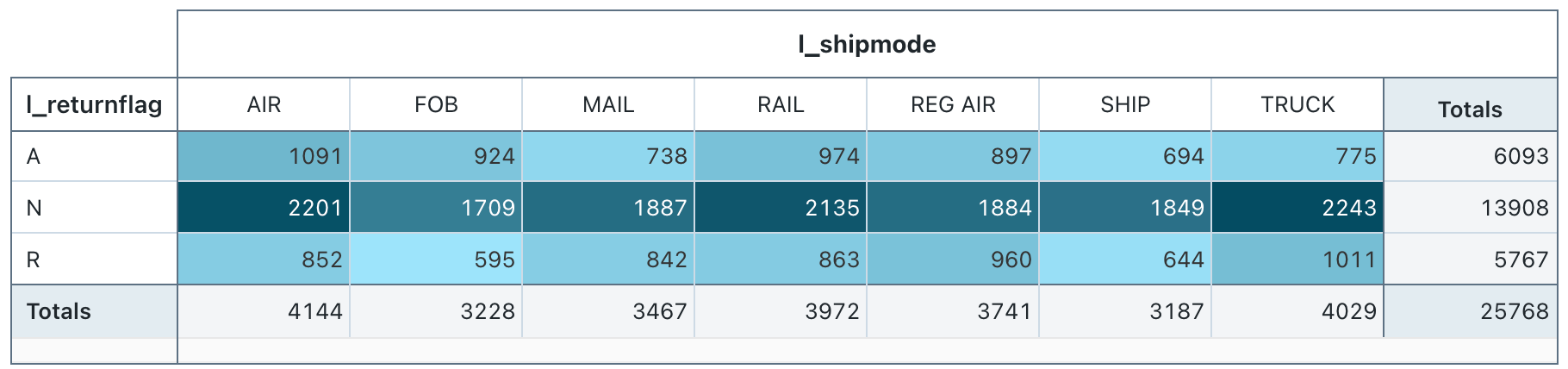
Konfigurationswerte: Für diese Pivottabellenvisualisierung wurden die folgenden Werte festgelegt:
- Zeilen auswählen (Datasetspalte):
l_returnflag - Spalten auswählen (Datasetspalte):
l_shipmode - Cell (Zelle)
- Datasetspalte:
l_quantity - Aggregationstyp: Sum
- Zellen nach Wert einfärben: Ein
- Datasetspalte:
SQL-Abfrage: Für diese Pivottabellenvisualisierung wurde die folgende SQL-Abfrage verwendet, um das Dataset zu generieren:
select * from samples.tpch.lineitem
Sankey
Ein Sankeydiagramm visualisiert den Fluss von einer Gruppe von Werten zu einer anderen.
Hinweis
Sankeyvisualisierungen aggregieren keine Daten innerhalb des Resultsets. Alle Aggregationen müssen innerhalb der Abfrage selbst berechnet werden.

SQL-Abfrage: Für diese Sankeyvisualisierung wurde die folgende SQL-Abfrage verwendet, um das Dataset zu generieren:
SELECT pickup_zip as stage1, dropoff_zip as stage2, sum(fare_amount) as value
FROM samples.nyctaxi.trips
GROUP BY 1, 2
ORDER BY 3 DESC
LIMIT 10
Sunburst-Sequenz
Ein Sunburst-Diagramm visualisiert hierarchische Daten mithilfe konzentrischer Kreise.
Hinweis
Sunburst-Sequenzen aggregieren keine Daten innerhalb des Resultsets. Alle Aggregationen müssen innerhalb der Abfrage selbst berechnet werden.
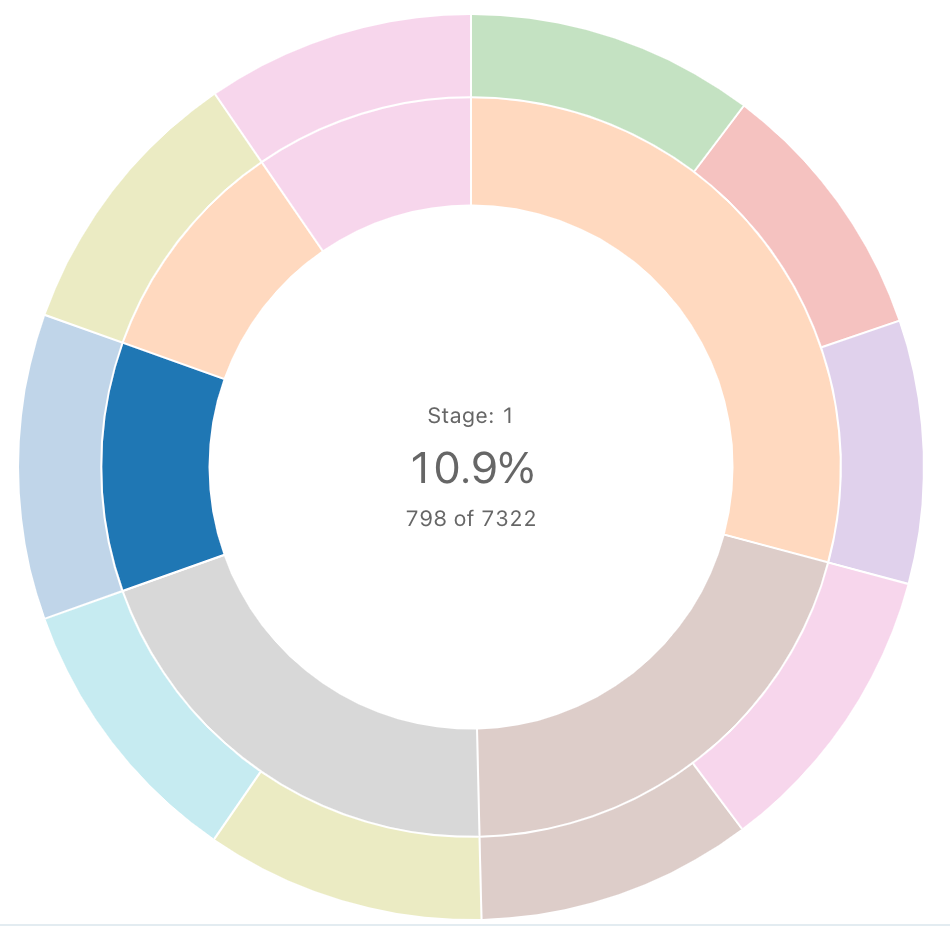
SQL-Abfrage: Für diese Sunburst-Visualisierung wurde die folgende SQL-Abfrage verwendet, um das Dataset zu generieren:
SELECT pickup_zip as stage1, dropoff_zip as stage2, sum(fare_amount) as value
FROM samples.nyctaxi.trips
GROUP BY 1, 2
ORDER BY 3 DESC
LIMIT 10
Tabelle
Die Tabellenvisualisierung zeigt Daten in einer Standardtabelle an, aber mit der Möglichkeit, die Daten manuell neu anzuordnen, auszublenden und zu formatieren. Weitere Informationen finden Sie unter Tabellenoptionen.
Hinweis
Tabellenvisualisierungen aggregieren keine Daten innerhalb des Resultsets. Alle Aggregationen müssen innerhalb der Abfrage selbst berechnet werden.
Konfigurationsoptionen für Tabellen finden Sie unter Konfigurationsoptionen für Tabellen.
Word Cloud
Ein Wortwolke stellt die Häufigkeit, mit der ein Wort in den Daten auftritt, visuell dar.
Hinweis
Wortwolken unterstützen nur die Aggregation von bis zu 64.000 Zeilen. Wenn ein Dataset größer als 64.000 Zeilen ist, werden die Daten abgeschnitten.
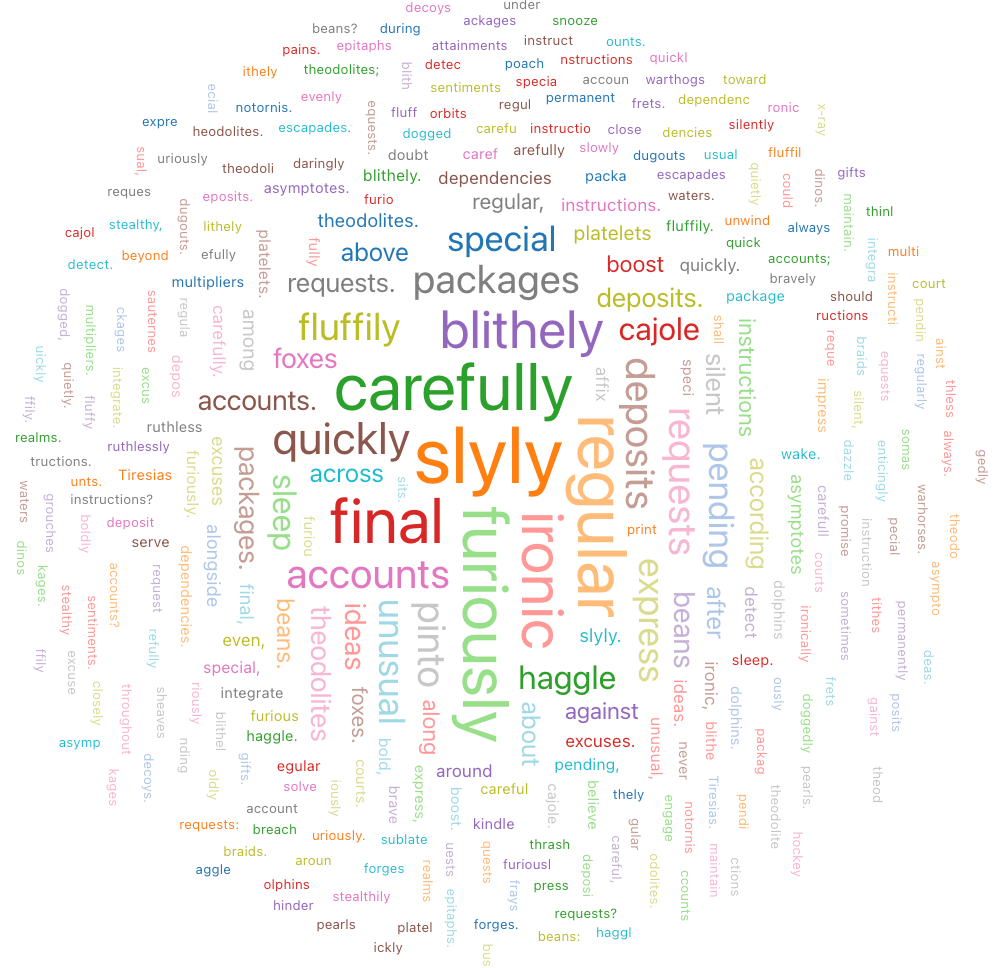
Konfigurationswerte: Für diese Wortwolkenvisualisierung wurden die folgenden Werte festgelegt: test
- Wörterspalte (Datasetspalte):
o_comment - Längenbeschränkung für Wörter: Min = 5
- Frequenzlimit: Min = 2
SQL-Abfrage: Für diese Wortwolkenvisualisierung wurde die folgende SQL-Abfrage verwendet, um das Dataset zu generieren:
select * from samples.tpch.orders