RStudio in Azure Databricks
Sie können RStudio verwenden, eine beliebte integrierte Entwicklungsumgebung (IDE) für R, um eine Verbindung mit Azure Databricks-Computeressourcen in Azure Databricks-Arbeitsbereichen herzustellen. Verwenden Sie RStudio Desktop, um von Ihrem lokalen Entwicklungscomputer aus eine Verbindung mit einem Azure Databricks-Cluster oder einem SQL-Warehouse herzustellen. Ferner können Sie Ihren Webbrowser verwenden, um sich bei Ihrem Azure Databricks-Arbeitsbereich anzumelden und dann innerhalb dieses Arbeitsbereichs eine Verbindung mit einem Azure Databricks-Cluster herzustellen, auf dem RStudio Server installiert ist.
Herstellen einer Verbindung mit RStudio Desktop
Verwenden Sie RStudio Desktop, um von Ihrem lokalen Entwicklungscomputer aus eine Verbindung mit einem Azure Databricks-Remotecluster oder einem SQL-Warehouse herzustellen. Zum Herstellen einer Verbindung können Sie in diesem Szenario eine ODBC-Verbindung verwenden und ODBC-Paketfunktionen für R aufrufen, die in diesem Abschnitt beschrieben werden.
Hinweis
Sie können keine Pakete wie SparkR oder Sparklyr in diesem RStudio Desktop-Szenario verwenden, es sei denn, Sie verwenden zugleich Databricks Connect. Als Alternative zu RStudio können Sie Ihren Webbrowser verwenden, um sich bei Ihrem Azure Databricks-Arbeitsbereich anzumelden und dann innerhalb dieses Arbeitsbereichs eine Verbindung mit einem Azure Databricks-Cluster herzustellen, auf dem RStudio Server installiert ist.
So richten Sie RStudio Desktop auf Ihrem lokalen Entwicklungscomputer ein:
- Laden Sie R 3.3.0 oder höher herunter, und installieren Sie es.
- Laden Sie RStudio Desktop herunter, und führen Sie die Anwendung aus.
- Starten Sie RStudio Desktop.
(Optional) So erstellen Sie ein RStudio-Projekt:
- Starten Sie RStudio Desktop.
- Klicken Sie auf Datei > Neues Projekt.
- Wählen Sie Neues Verzeichnis > Neues Projekt aus.
- Wählen Sie ein neues Verzeichnis für das Projekt aus, und klicken Sie dann auf Projekt erstellen.
So erstellen Sie ein R-Skript:
- Klicken Sie bei geöffnetem Projekt auf Datei > Neue Datei > R-Skript.
- Klicken Sie auf Datei > Speichern unter.
- Benennen Sie die Datei, und klicken Sie dann auf Speichern.
So stellen Sie eine Verbindung mit dem Azure Databricks-Remotecluster oder einem SQL-Warehouse mithilfe von ODBC für R her:
Rufen Sie die Werte für Serverhostname, Port und HTTP-Pfad für Ihren Remotecluster oder das SQL-Warehouse ab. Für einen Cluster befinden sich diese Werte auf der Registerkarte JDBC/ODBC der erweiterten Optionen. Für ein SQL-Warehouse befinden sich diese Werte auf der Registerkarte Verbindungsdetails.
Rufen Sie ein persönliches Zugriffstoken für Azure Databricks ab.
Hinweis
Als bewährte Methode für die Sicherheit empfiehlt Databricks, dass Sie bei der Authentifizierung mit automatisierten Tools, Systemen, Skripten und Anwendungen persönliche Zugriffstoken verwenden, die zu Dienstprinzipalen und nicht zu Benutzern des Arbeitsbereichs gehören. Informationen zum Erstellen von Token für Dienstprinzipale finden Sie unter Verwalten von Token für einen Dienstprinzipal.
Installieren und konfigurieren Sie den Databricks ODBC-Treiber für Windows, macOS oder Linux, je nach dem Betriebssystem Ihres lokalen Computers.
Richten Sie einen ODBC-Datenquellennamen (DSN) auf Ihrem Remotecluster oder in Ihrem SQL-Warehouse für Windows, macOS oder Linux ein, je nach dem Betriebssystem Ihres lokalen Computers.
Installieren Sie über die RStudio-Konsole (Ansicht > Fokus auf Konsole verschieben) die Pakete odbc und DBI von CRAN:
require(devtools) install_version( package = "odbc", repos = "http://cran.us.r-project.org" ) install_version( package = "DBI", repos = "http://cran.us.r-project.org" )Laden Sie nach der Rückkehr zu Ihrem R-Skript (Ansicht > Fokus auf Quelle verschieben) die installierten
odbc- undDBI-Pakete:library(odbc) library(DBI)Rufen Sie die ODBC-Version der dbConnect-Funktion im
DBI-Paket auf, und geben Sie denodbc-Treiber imodbc-Paket sowie den von Ihnen erstellten ODBC-DSN an, z. B. einen ODBC-DSNDatabricks.conn = dbConnect( drv = odbc(), dsn = "Databricks" )Rufen Sie einen Vorgang über den ODBC-DSN auf, z. B. eine
SELECT-Anweisung über die Funktion dbGetQuery imDBI-Paket, wobei Sie den Namen der Verbindungsvariable und die eigentlicheSELECT-Anweisung angeben, beispielsweise aus einer Tabelle namensdiamondsin einem Schema (Datenbank) mit dem Namendefault:print(dbGetQuery(conn, "SELECT * FROM default.diamonds LIMIT 2"))
Das vollständige R-Skript lautet wie folgt:
library(odbc)
library(DBI)
conn = dbConnect(
drv = odbc(),
dsn = "Databricks"
)
print(dbGetQuery(conn, "SELECT * FROM default.diamonds LIMIT 2"))
Klicken Sie zum Ausführen des Skripts in der Quellansicht auf Quelle. Dies sind die Ergebnisse für das vorstehende R-Skript:
_c0 carat cut color clarity depth table price x y z
1 1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
2 2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
Herstellen einer Verbindung mit einem von Databricks gehosteten RStudio Server
Wichtig
Der von Databricks gehostete RStudio Server ist veraltet und ist nur in Databricks Runtime-Versionen 15.4 und früheren Versionen verfügbar. Weitere Informationen finden Sie unter Einstufung des RStudio Server als veraltet.
Melden Sie sich über einen Webbrowser bei Ihrem Azure Databricks-Arbeitsbereich an und stellen Sie dann innerhalb dieses Arbeitsbereichs eine Verbindung mit einem Azure Databricks-Compute her, auf dem RStudio Server in diesem Arbeitsbereich installiert ist.
Weitere Informationen finden Sie unter Herstellen einer Verbindung mit einem von Databricks gehosteten RStudio Server
RStudio-Integrationsarchitektur
Wenn Sie RStudio Server auf Azure Databricks verwenden, wird der RStudio Server-Daemon auf dem Treiberknoten eines Azure Databricks ausgeführt. Die RStudio-Webbenutzeroberfläche wird über eine Azure Databricks-Web-App per Proxis verbunden. Das bedeutet, dass Sie keine Änderungen an Ihrer Clusternetzwerkkonfiguration vornehmen müssen. Dieses Diagramm veranschaulicht die Architektur der RStudio-Integrationskomponente.
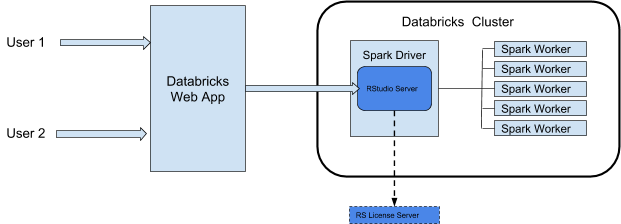
Warnung
Azure Databricks erstellt Proxys des RStudio-Webdienstes über Port 8787 auf dem Spark-Treiber des Clusters. Dieser Webproxy ist nur für die Verwendung mit RStudio vorgesehen. Wenn Sie andere Webdienste an Port 8787 starten, können Sie Ihre Benutzer potenziellen Sicherheitslücken aussetzen. Weder Databricks noch Microsoft sind für Probleme verantwortlich, die sich aus der Installation nicht unterstützter Software in einem Cluster ergeben.
Anforderungen
Der Cluster muss ein Allzweckcluster sein.
Sie müssen für dieses Cluster über die Berechtigung KANN ANFÜGEN AN verfügen. Der Clusteradministrator kann Ihnen diese Berechtigung erteilen. Siehe Compute-Berechtigungen.
Für den Cluster darf keineTabellenzugriffssteuerung, automatische Beendigung oder Passthrough für Anmeldeinformationen aktiviert sein.
Das Cluster darf nicht den FreigegebenenZugriffsmodus verwenden.
Für den Cluster darf die Spark-Konfiguration
spark.databricks.pyspark.enableProcessIsolationauftruefestgelegt sein.Wenn Sie die Pro Edition verwenden möchten, benötigen Sie eine unverankerte RStudio Server Pro-Lizenz.
Hinweis
Obwohl der Cluster einen Zugriffsmodus verwenden kann, der Unity Catalog unterstützt, können Sie RStudio Server von diesem Cluster nicht für den Zugriff auf Daten in Unity Catalog verwenden.
Erste Schritte: Betriebssystemedition von RStudio Server
RStudio Server Open Source Edition ist auf Azure Databricks-Clustern vorinstalliert, die Databricks Runtime for Machine Learning (Databricks Runtime ML) verwenden.
Gehen Sie wie folgt vor, um die RStudio Server OS Edition auf einem Cluster zu öffnen:
Öffnen Sie die Detailseite des Clusters.
Starten Sie den Cluster, und klicken Sie dann auf die Registerkarte Apps:
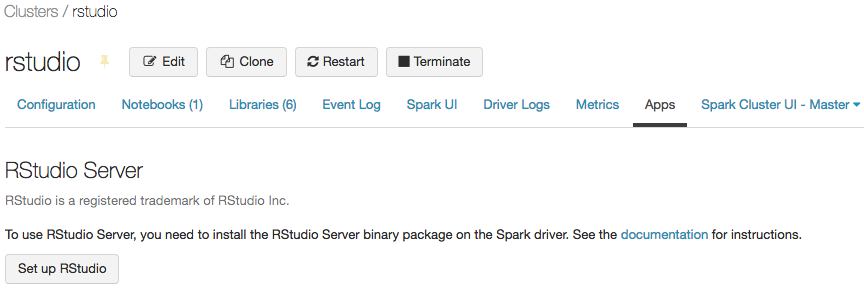
Klicken Sie auf der Registerkarte Apps auf die Schaltfläche RStudio einrichten. Dadurch wird ein einmaliges Kennwort für Sie generiert. Klicken Sie auf den Link anzeigen, um ihn anzuzeigen und das Kennwort zu kopieren.
Klicken Sie auf den Link RStudio öffnen, um die Benutzeroberfläche auf einer neuen Registerkarte zu öffnen. Geben Sie Ihren Benutzernamen und Ihr Kennwort in das Anmeldeformular ein, und melden Sie sich an.
Über die RStudio-Benutzeroberfläche können Sie das Paket
SparkRimportieren und eine SitzungSparkReinrichten, um Spark-Aufträge in Ihrem Cluster zu starten.library(SparkR) sparkR.session() # Query the first two rows of a table named "diamonds" in a # schema (database) named "default" and display the query result. df <- SparkR::sql("SELECT * FROM default.diamonds LIMIT 2") showDF(df)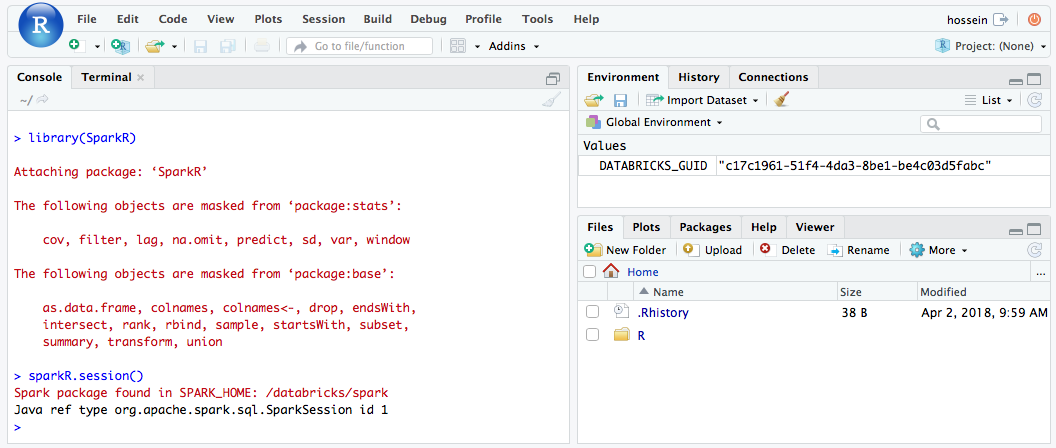
Sie können auch das Paket Sparklyr anfügen und eine Spark-Verbindung einrichten.
library(sparklyr) sc <- spark_connect(method = "databricks") # Query a table named "diamonds" and display the first two rows. df <- spark_read_table(sc = sc, name = "diamonds") print(x = df, n = 2)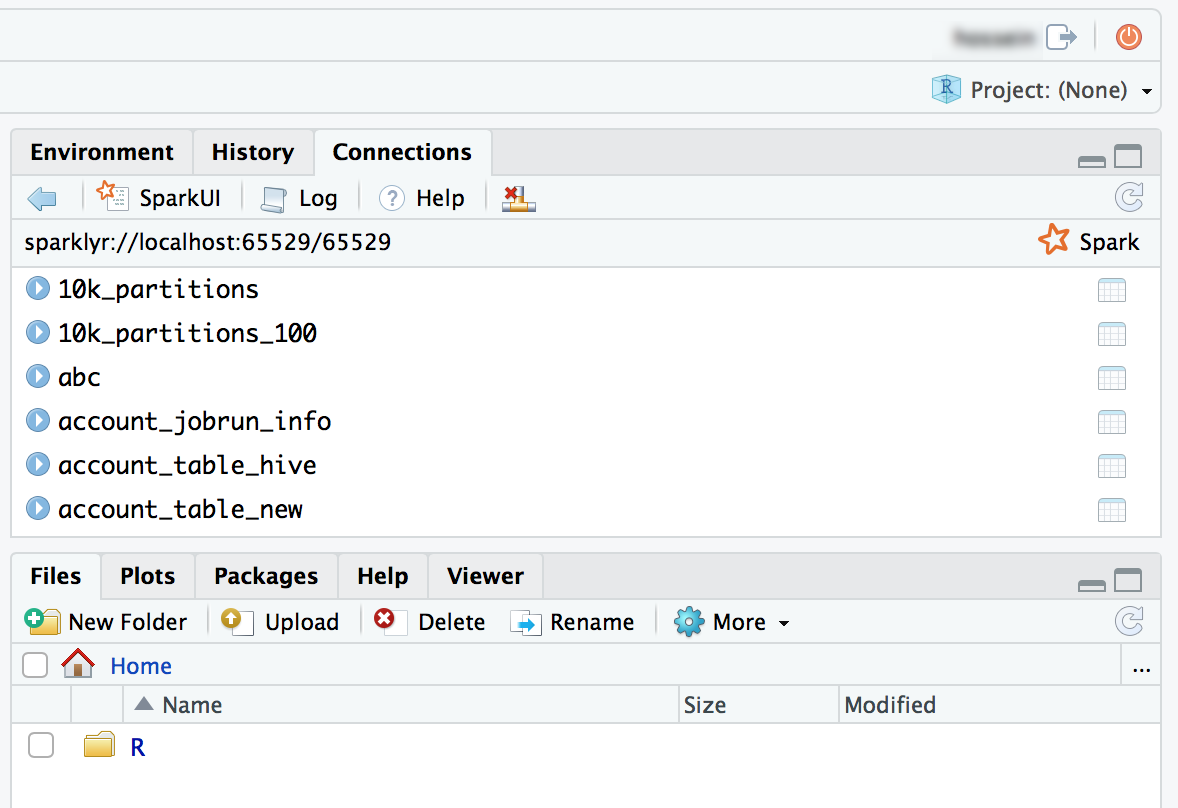
Erste Schritte: RStudio Workbench
In diesem Abschnitt erfahren Sie, wie Sie RStudio Workbench (früher RStudio Server Pro) in einem Azure Databricks-Cluster einrichten und verwenden. Je nach Lizenz kann RStudio Workbench auch RStudio Server Pro enthalten.
Einrichten des RStudio-Lizenzservers
Um RStudio Workbench in Azure Databricks verwenden zu können, müssen Sie Ihre Pro-Lizenz in eine Floating-Lizenz umwandeln. Wenden Sie sich an help@rstudio.com, um Unterstützung zu erhalten. Nachdem Ihre Lizenz umgewandelt wurde, müssen Sie einen Lizenzserver für RStudio Workbench einrichten.
So richten Sie einen Lizenzserver ein:
- Starten Sie eine kleine Instanz in Ihrem Cloudanbieternetzwerk. Der Lizenzserver-Daemon ist sehr einfach.
- Laden Sie die entsprechende Version des RStudio-Lizenzservers herunter, installieren Sie sie auf Ihrer Instanz, und starten Sie den Dienst. Ausführliche Anweisungen finden Sie im Administratorhandbuch zu RStudio Workbench.
- Stellen Sie sicher, dass der Port des Lizenzservers für Azure Databricks geöffnet ist.
Installieren von RStudio Workbench
Zum Einrichten von RStudio Workbench in einem Azure Databricks-Cluster müssen Sie ein Initialisierungsskript erstellen, um das Binärpaket von RStudio Workbench zu installieren und für die Verwendung Ihres Lizenzservers für die Lizenzleasing zu konfigurieren.
Hinweis
Wenn Sie RStudio Workbench unter einer Databricks Runtime-Version installieren möchten, die bereits das RStudio Server Open Source Edition-Paket enthält, müssen Sie dieses Paket zunächst deinstallieren, damit die Installation erfolgreich ist.
Im Folgenden finden Sie ein Beispiel für eine .sh-Datei, die Sie als Initialisierungsskript an einem Speicherort speichern können, z. B. in Ihrem Basisverzeichnis als Arbeitsbereichsdatei, in einem Unity Catalog-Volume oder im Objektspeicher. Weitere Informationen finden Sie unter Initialisierungsskripts im Clusterbereich. Das Skript führt auch zusätzliche Authentifizierungskonfigurationen durch, die die Integration in Azure Databricks optimiert.
Warnung
Clusterspezifische Initialisierungsskripts in DBFS werden nicht mehr unterstützt. Das Speichern von Initialisierungsskripts in DBFS ist in einigen Arbeitsbereichen möglich und dient der Unterstützung von Legacy-Workloads, wird aber nicht empfohlen. Alle in DBFS gespeicherten Initialisierungsskripts sollten migriert werden. Anweisungen zur Migration finden Sie unter Migrieren von Initialisierungsskripts aus DBFS.
#!/bin/bash
set -euxo pipefail
if [[ $DB_IS_DRIVER = "TRUE" ]]; then
sudo apt-get update
sudo dpkg --purge rstudio-server # in case open source version is installed.
sudo apt-get install -y gdebi-core alien
## Installing RStudio Workbench
cd /tmp
# You can find new releases at https://rstudio.com/products/rstudio/download-commercial/debian-ubuntu/.
wget https://download2.rstudio.org/server/bionic/amd64/rstudio-workbench-2022.02.1-461.pro1-amd64.deb -O rstudio-workbench.deb
sudo gdebi -n rstudio-workbench.deb
## Configuring authentication
sudo echo 'auth-proxy=1' >> /etc/rstudio/rserver.conf
sudo echo 'auth-proxy-user-header-rewrite=^(.*)$ $1' >> /etc/rstudio/rserver.conf
sudo echo 'auth-proxy-sign-in-url=<domain>/login.html' >> /etc/rstudio/rserver.conf
sudo echo 'admin-enabled=1' >> /etc/rstudio/rserver.conf
sudo echo 'export PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin' >> /etc/rstudio/rsession-profile
# Enabling floating license
sudo echo 'server-license-type=remote' >> /etc/rstudio/rserver.conf
# Session configurations
sudo echo 'session-rprofile-on-resume-default=1' >> /etc/rstudio/rsession.conf
sudo echo 'allow-terminal-websockets=0' >> /etc/rstudio/rsession.conf
sudo rstudio-server license-manager license-server <license-server-url>
sudo rstudio-server restart || true
fi
- Ersetzen Sie
<domain>durch ihre Azure Databricks-URL und<license-server-url>durch die URL Ihres Floating License-Servers. - Speichern Sie diese
.sh-Datei als Initialisierungsskript an einem Speicherort, z. B. in Ihrem Basisverzeichnis als Arbeitsbereichsdatei, in einem Unity Catalog-Volume oder im Objektspeicher. Weitere Informationen finden Sie unter Initialisierungsskripts im Clusterbereich. - Fügen Sie vor dem Starten eines Clusters diese
.sh-Datei als Initialisierungsskript aus dem zugehörigen Speicherort hinzu. Anweisungen finden Sie unter "Clusterbereich"-Init-Skripts. - Starten Sie den Cluster.
RStudio Server Pro verwenden
Öffnen Sie die Detailseite des Clusters.
Starten Sie den Cluster, und klicken Sie auf die Registerkarte Apps:
Klicken Sie auf der Registerkarte Apps auf die Schaltfläche RStudio einrichten.
Sie brauchen das Einmalpasswort nicht. Klicken Sie auf den Link RStudio-Benutzeroberfläche öffnen, um eine authentifizierte RStudio Pro-Sitzung zu öffnen.
Über die RStudio-Benutzeroberfläche können Sie das Paket
SparkRanhängen und eine SitzungSparkReinrichten, um Spark-Aufträge in Ihrem Cluster zu starten.library(SparkR) sparkR.session() # Query the first two rows of a table named "diamonds" in a # schema (database) named "default" and display the query result. df <- SparkR::sql("SELECT * FROM default.diamonds LIMIT 2") showDF(df)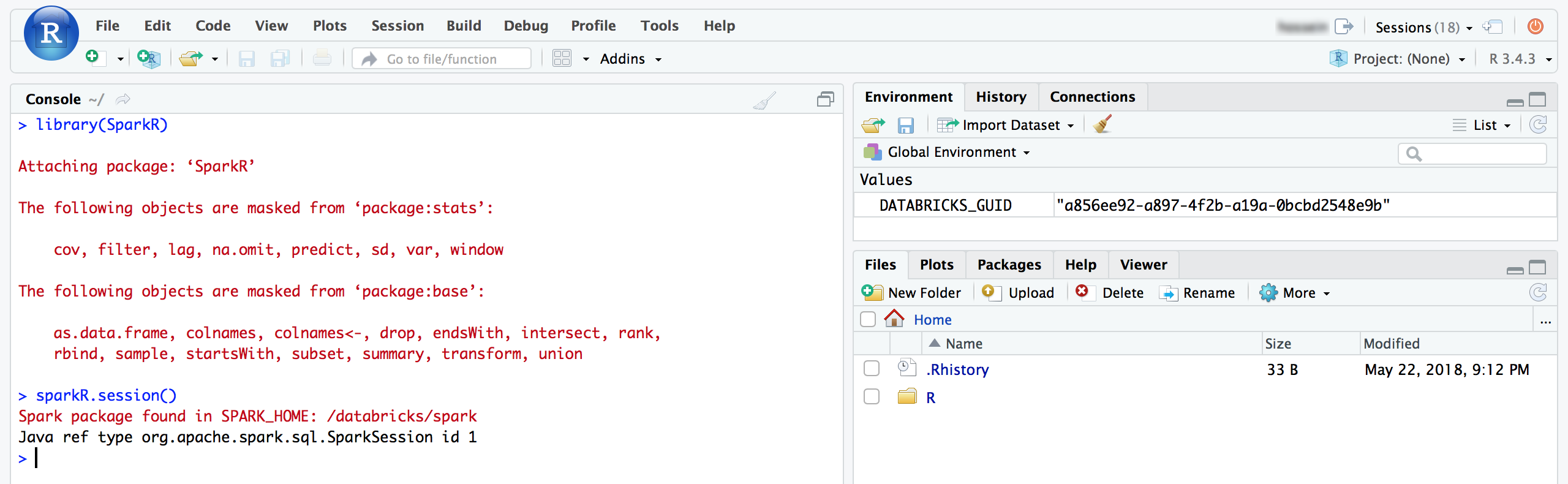
Sie können auch das Paket Sparklyr anfügen und eine Spark-Verbindung einrichten.
library(sparklyr) sc <- spark_connect(method = "databricks") # Query a table named "diamonds" and display the first two rows. df <- spark_read_table(sc = sc, name = "diamonds") print(x = df, n = 2)
FAQ zu RStudio Server
Was ist der Unterschied zwischen RStudio Server Open Source Edition und RStudio Workbench?
RStudio Workbench unterstützt eine Vielzahl von Unternehmensfeatures, die in der Open Source-Edition nicht verfügbar sind. Einen Funktionsvergleich finden Sie auf der Website von RStudio.
Darüber hinaus wird RStudio Server Open Source Edition unter der GNU Affero General Public License (AGPL) verteilt, während die Pro-Version eine kommerzielle Lizenz für Organisationen enthält, die keine AGPL-Software verwenden können.
Schließlich bietet RStudio Workbench professionellen Unternehmenssupport von RStudio, PBC, während RStudio Server Open Source Edition keinen Support bietet.
Kann ich meine RStudio Workbench-/RStudio Server Pro-Lizenz in Azure Databricks verwenden?
Ja, wenn Sie bereits über eine Pro- oder Enterprise-Lizenz für RStudio Server verfügen, können Sie diese Lizenz auf Azure Databricks verwenden. Unter Erste Schritte: RStudio Workbench erfahren Sie, wie Sie RStudio Workbench in Azure Databricks einrichten.
Wo wird RStudio Server ausgeführt? Muss ich zusätzliche Dienste/Server verwalten?
Wie Sie im Diagramm in der RStudio-Integrationsarchitektur sehen können, wird der RStudio Server-Daemon auf dem Treiberknoten (Masterknoten) Ihres Azure Databricks ausgeführt. Mit RStudio Server Open Source Edition müssen Sie keine zusätzlichen Server/Dienste ausführen. Für RStudio Workbench müssen Sie jedoch eine separate Instanz verwalten, auf der der RStudio-Lizenzserver ausgeführt wird.
Kann ich RStudio Server in einem Standardcluster verwenden?
Hinweis
In diesem Artikel wird die Legacy-Clusterbenutzeroberfläche beschrieben. Informationen zur neuen Clusterbenutzeroberfläche (Vorschau), einschließlich Terminologieänderungen für Clusterzugriffsmodi, finden Sie unter Konfigurationsreferenz berechnen. Einen Vergleich der neuen und alten Clustertypen finden Sie unter Änderungen der Clusterbenutzeroberfläche und Clusterzugriffsmodi.
Ja, das ist möglich.
Kann ich RStudio Server in einem Cluster mit automatischer Beendigung verwenden?
Nein, RStudio kann nicht verwendet werden, wenn die automatische Beendigung aktiviert ist. Bei der automatischen Beendigung können nicht gespeicherte Benutzerskripts und Daten in einer RStudio-Sitzung gelöscht werden. Um Benutzer vor diesem Szenario des unbeabsichtigten Datenverlusts zu schützen, ist RStudio in solchen Clustern standardmäßig deaktiviert.
Für Kunden, die Clusterressourcen bereinigen müssen, wenn sie nicht verwendet werden, empfiehlt Databricks die Verwendung von Cluster-APIs, um RStudio-Cluster nach einem Zeitplan zu bereinigen.
Wie sollte ich meine Arbeit in RStudio beibehalten?
Es wird dringend empfohlen, dass Sie Ihre Arbeit mithilfe eines Versionskontrollsystems von RStudio beibehalten. RStudio bietet hervorragende Unterstützung für verschiedene Versionskontrollsysteme und ermöglicht Ihnen das Einchecken und Verwalten Ihrer Projekte. Wenn Sie Ihren Code nicht über eine der folgenden Methoden beibehalten, besteht die Gefahr, dass Ihre Arbeit verloren geht, sobald ein Arbeitsbereichsadministrator den Cluster neu startet oder beendet.
Sie können Ihre Dateien (Code oder Daten) in Was ist DBFS? speichern. Wenn Sie beispielsweise eine Datei unter /dbfs/ speichern, werden die Dateien nicht gelöscht, wenn Ihr Cluster beendet oder neu gestartet wird.
Speichern Sie das R-Notebook in Ihrem lokalen Dateisystem, indem Sie es als Rmarkdown exportieren und die Datei dann in die RStudio-Instanz importieren. Im Blog Sharing R Notebooks using RMarkdown (Freigeben von R Notebooks mit RMarkdown) werden die Schritte ausführlicher beschrieben.
Wie starte ich eine SparkR-Sitzung?
SparkR ist in Databricks Runtime enthalten, aber Sie müssen es in RStudio laden. Führen Sie den folgenden Code in RStudio aus, um eine SparkR-Sitzung zu initialisieren.
library(SparkR)
sparkR.session()
Wenn beim Importieren des SparkR-Pakets ein Fehler auftritt, führen Sie .libPaths() aus und überprüfen Sie, ob /home/ubuntu/databricks/spark/R/lib im Ergebnis enthalten ist.
Wenn sie nicht enthalten ist, überprüfen Sie den Inhalt von /usr/lib/R/etc/Rprofile.site. Listen Sie /home/ubuntu/databricks/spark/R/lib/SparkR auf dem Treiber auf, um zu überprüfen, ob das SparkR-Paket installiert ist.
Wie starte ich eine sparklyr-Sitzung?
Das sparklyr-Paket muss auf dem Cluster installiert sein. Verwenden Sie eine der folgenden Methoden zum Installieren des sparklyr-Pakets.
- Als Azure Databricks-Bibliothek
install.packages()-Befehl- Benutzeroberfläche der RStudio-Paketverwaltung
library(sparklyr)
sc <- spark_connect(method = “databricks”)
Wie lässt sich RStudio in Azure Databricks R-Notebooks integrieren?
Sie können Ihre Arbeit über die Versionskontrolle zwischen Notebooks und RStudio verschieben.
Was ist das Arbeitsverzeichnis?
Wenn Sie ein Projekt in RStudio starten, wählen Sie ein Arbeitsverzeichnis aus. Standardmäßig ist dies das Basisverzeichnis im Treibercontainer (Master), in dem RStudio Server ausgeführt wird. Sie können dieses Verzeichnis auf Wunsch ändern.
Kann ich Shiny-Apps über RStudio starten, das auf Azure Databricks läuft?
Ja, Sie können innerhalb von RStudio Server in Databricks Anwendungen entwickeln und anzeigen.
Ich kann kein Terminal oder Git in RStudio auf Azure Databricks verwenden. Wie kann ich dieses Problem beheben?
Stellen Sie sicher, dass WebSockets deaktiviert sind. In RStudio Server Open Source Edition können Sie dies über die Benutzeroberfläche tun.
In RStudio Server Pro können Sie allow-terminal-websockets=0 zu /etc/rstudio/rsession.conf hinzufügen, um WebSockets für alle Benutzer zu deaktivieren.
Die Registerkarte Apps wird unter den Clusterdetails nicht angezeigt.
Dieses Feature ist nicht für alle Kunden verfügbar. Sie müssen über den Premium-Plan verfügen.