Abfragegenerive KI-Modelle
In diesem Artikel erfahren Sie, wie Sie Abfrageanforderungen für Basismodelle und externe Modelle formatieren und an Ihren Modellbereitstellungsendpunkt senden.
Informationen zu Abfrageanforderungen für herkömmliche ML- oder Python-Modelle finden Sie unter Abfragen von Bereitstellungsendpunkten für benutzerdefinierte Modelle.
Mosaic AI Model Serving unterstützt Basismodell-APIs und externe Modelle für den Zugriff auf Modelle mit generativer KI. Model Serving verwendet eine einheitliche OpenAI-kompatible API und ein SDK für die Abfrage. Dies ermöglicht das Experimentieren mit und Anpassen von generativen KI-Modellen für die Produktion in unterstützten Clouds und Anbietern.
Mosaic AI Model Serving bietet die folgenden Optionen zum Senden von Bewertungsanforderungen an Endpunkte, die Basismodelle oder externe Modelle bereitstellen:
| Methode | Details |
|---|---|
| OpenAI-Client | Abfragen eines Modells, das von einem Mosaic AI Model Serving-Endpunkt mithilfe des OpenAI-Clients gehostet wird. Geben Sie das Modell an, das den Endpunktnamen als model-Eingabe angibt. Unterstützt für Chat-, Einbettungs- und Abschlussmodelle, die von Foundation Model-APIs oder externen Modellen zur Verfügung gestellt werden. |
| Serving-Benutzeroberfläche | Wählen Sie auf der Seite Serving-Endpunkt die Option Abfrageendpunkt aus. Fügen Sie Eingabedaten des JSON-Formatmodells ein, und klicken Sie auf Anforderung übermitteln. Wenn das Modell ein Eingabebeispiel protokolliert hat, verwenden Sie Beispiel anzeigen, um es zu laden. |
| REST-API | Rufen Sie das Modell mithilfe der REST-API auf, und fragen Sie es ab. Details finden Sie unter POST /serving-endpoints/{name}/invocations. Informationen zum Bewerten von Anforderungen an Endpunkte, die mehreren Modellen dienen, finden Sie unter Abfragen einzelner Modelle hinter einem Endpunkt. |
| MLflow Deployments SDK | Verwenden Sie die Funktion predict() des MLflow Deployments SDK, um das Modell abzufragen. |
| Databricks Python SDK | Das Databricks Python SDK ist eine Ebene über der REST-API. Es behandelt Details auf niedriger Ebene, z. B. die Authentifizierung, wodurch die Interaktion mit den Modellen erleichtert wird. |
| SQL-Funktion | Rufen Sie den Modellrückschluss direkt aus SQL mithilfe der SQL-Funktion „ai_query“ auf. Siehe Abfragen eines bereitgestellten Modells mit ai_query(). |
Anforderungen
- Ein Modellbereitstellungsendpunkt.
- Ein Databricks-Arbeitsbereich in einer unterstützten Region.
- Sie müssen über Databricks-API-Token verfügen, um eine Bewertungsanforderung über den OpenAI-Client, die REST-API oder das MLflow Deployment SDK zu senden.
Wichtig
Als bewährte Sicherheitsmethode für Produktionsszenarien empfiehlt Databricks, Computer-zu-Computer-OAuth-Token für die Authentifizierung während der Produktion zu verwenden.
Für die Test- und Entwicklungsphase empfiehlt Databricks die Verwendung eines persönlichen Zugriffstokens, das Dienstprinzipalen anstelle von Arbeitsbereichsbenutzern gehört. Informationen zum Erstellen von Token für Dienstprinzipale finden Sie unter Verwalten von Token für einen Dienstprinzipal.
Installieren von Paketen
Nachdem Sie eine Abfragemethode ausgewählt haben, müssen Sie zuerst das entsprechende Paket für Ihren Cluster installieren.
OpenAI-Client
Um den OpenAI-Client zu verwenden, muss das databricks-sdk[openai]-Paket für Ihren Cluster installiert sein. Databricks SDK bietet einen Wrapper zum Erstellen des OpenAI-Clients mit automatischer Autorisierung, die für abfragen generative KI-Modelle konfiguriert ist. Führen Sie den folgenden Befehl in Ihrem Notebook oder lokalen Terminal aus:
!pip install databricks-sdk[openai]>=0.35.0
Folgendes ist nur erforderlich, wenn das Paket für ein Databricks-Notebook installiert wird.
dbutils.library.restartPython()
REST-API
Der Zugriff auf die Bereitstellungs-REST-API ist in Databricks Runtime für Machine Learning verfügbar.
MLflow Deployments SDK
!pip install mlflow
Folgendes ist nur erforderlich, wenn das Paket für ein Databricks-Notebook installiert wird.
dbutils.library.restartPython()
Databricks Python SDK
Das Databricks-SDK für Python ist auf allen Azure Databricks-Clustern bereits installiert, die Databricks Runtime 13.3 LTS oder höher verwenden. Für Azure Databricks-Cluster, die Databricks Runtime 12.2 LTS und darunter verwenden, müssen Sie zuerst das Databricks-SDK für Python installieren. Siehe Databricks SDK für Python.
Abfragen eines Chatvervollständigungsmodells
Im Folgenden sind Beispiele zum Abfragen eines Chatmodells aufgeführt. Das Beispiel gilt für das Abfragen eines Chatmodells, das mithilfe einer der Model Serving-Funktionen verfügbar gemacht wird: Foundation Model-APIs oder externe Modelle.
Ein Beispiel für eine Batch-Ableitung finden Sie unter "Batchinference" mithilfe von Foundation-Modell-APIs, die einen bereitgestellten Durchsatz haben.
OpenAI-Client
Nachfolgend sehen Sie eine Chatanforderungen für das DBRX Instruct-Modell, das über den Pay-per-Token-Endpunkt databricks-dbrx-instruct der Foundation Model-APIs in Ihrem Arbeitsbereich verfügbar gemacht wurde.
Um den OpenAI-Client zu verwenden, geben Sie den Endpunktnamen der Modellbereitstellung als model-Eingabe ein.
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
openai_client = w.serving_endpoints.get_open_ai_client()
response = openai_client.chat.completions.create(
model="databricks-dbrx-instruct",
messages=[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "What is a mixture of experts model?",
}
],
max_tokens=256
)
Um Foundation-Modelle außerhalb Ihres Arbeitsbereichs abzufragen, müssen Sie den OpenAI-Client direkt verwenden. Außerdem benötigen Sie Ihre Databricks-Arbeitsbereichsinstanz, um den OpenAI-Client mit Databricks zu verknüpfen. Im folgenden Beispiel wird davon ausgegangen, dass Sie über ein Databricks-API-Token verfügen und openai auf Der Berechnung installiert sind.
import os
import openai
from openai import OpenAI
client = OpenAI(
api_key="dapi-your-databricks-token",
base_url="https://example.staging.cloud.databricks.com/serving-endpoints"
)
response = client.chat.completions.create(
model="databricks-dbrx-instruct",
messages=[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "What is a mixture of experts model?",
}
],
max_tokens=256
)
REST-API
Wichtig
Im folgenden Beispiel werden REST-API-Parameter zum Abfragen von Endpunkten verwendet, die Foundation-Modelle bedienen. Diese Parameter befinden sich in der Public Preview, und die Definition kann sich ändern. Siehe POST /serving-endpoints/{name}/invocations.
Nachfolgend sehen Sie eine Chatanforderungen für das DBRX Instruct-Modell, das über den Pay-per-Token-Endpunkt databricks-dbrx-instruct der Foundation Model-APIs in Ihrem Arbeitsbereich verfügbar gemacht wurde.
curl \
-u token:$DATABRICKS_TOKEN \
-X POST \
-H "Content-Type: application/json" \
-d '{
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": " What is a mixture of experts model?"
}
]
}' \
https://<workspace_host>.databricks.com/serving-endpoints/databricks-dbrx-instruct/invocations \
MLflow Deployments SDK
Wichtig
Im folgenden Beispiel wird die predict()-API aus dem MLflow Deployments SDK verwendet.
Nachfolgend sehen Sie eine Chatanforderungen für das DBRX Instruct-Modell, das über den Pay-per-Token-Endpunkt databricks-dbrx-instruct der Foundation Model-APIs in Ihrem Arbeitsbereich verfügbar gemacht wurde.
import mlflow.deployments
# Only required when running this example outside of a Databricks Notebook
export DATABRICKS_HOST="https://<workspace_host>.databricks.com"
export DATABRICKS_TOKEN="dapi-your-databricks-token"
client = mlflow.deployments.get_deploy_client("databricks")
chat_response = client.predict(
endpoint="databricks-dbrx-instruct",
inputs={
"messages": [
{
"role": "user",
"content": "Hello!"
},
{
"role": "assistant",
"content": "Hello! How can I assist you today?"
},
{
"role": "user",
"content": "What is a mixture of experts model??"
}
],
"temperature": 0.1,
"max_tokens": 20
}
)
Databricks Python SDK
Nachfolgend sehen Sie eine Chatanforderungen für das DBRX Instruct-Modell, das über den Pay-per-Token-Endpunkt databricks-dbrx-instruct der Foundation Model-APIs in Ihrem Arbeitsbereich verfügbar gemacht wurde.
Dieser Code muss in einem Notebook in Ihrem Arbeitsbereich ausgeführt werden. Weitere Infromationen unter Verwenden des Databricks SDK für Python in einem Azure Databricks-Notebook.
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import ChatMessage, ChatMessageRole
w = WorkspaceClient()
response = w.serving_endpoints.query(
name="databricks-dbrx-instruct",
messages=[
ChatMessage(
role=ChatMessageRole.SYSTEM, content="You are a helpful assistant."
),
ChatMessage(
role=ChatMessageRole.USER, content="What is a mixture of experts model?"
),
],
max_tokens=128,
)
print(f"RESPONSE:\n{response.choices[0].message.content}")
LangChain
Um einen Foundation-Modell-Endpunkt mit LangChain abzufragen, können Sie die ChatDatabricks ChatModel-Klasse verwenden und die endpoint.
Im folgenden Beispiel wird die ChatDatabricks ChatModel-Klasse in LangChain verwendet, um den Foundation-Modell-APIs pay-per-Token-Endpunkt abzufragendatabricks-dbrx-instruct.
%pip install databricks-langchain
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_databricks import ChatDatabricks
messages = [
SystemMessage(content="You're a helpful assistant"),
HumanMessage(content="What is a mixture of experts model?"),
]
llm = ChatDatabricks(endpoint_name="databricks-dbrx-instruct")
llm.invoke(messages)
SQL
Wichtig
Im folgenden Beispiel wird die integrierte SQL-Funktion ai_query verwendet. Diese Funktion befindet sich in der Public Preview, und die Definition kann sich ändern. Siehe Abfragen eines bereitgestellten Modells mit ai_query().
Im Folgenden finden Sie eine Chatanfrage für meta-llama-3-1-70b-instruct, was über den Pay-per-Token-Endpunkt databricks-meta-llama-3-1-70b-instruct der Foundation Model-APIs in Ihrem Arbeitsbereich verfügbar gemacht wurden
Hinweis
Die ai_query()-Funktion unterstützt keine Abfrageendpunkte, die das DBRX- oder DBRX Instruct-Modell bedienen.
SELECT ai_query(
"databricks-meta-llama-3-1-70b-instruct",
"Can you explain AI in ten words?"
)
Im Folgenden sehen Sie beispielsweise das erwartete Anforderungsformat für ein Chatmodell bei Verwendung der REST-API. Für externe Modelle können Sie zusätzliche Parameter einschließen, die für eine bestimmte Anbieter- und Endpunktkonfiguration gültig sind. Siehe Zusätzliche Abfrageparameter.
{
"messages": [
{
"role": "user",
"content": "What is a mixture of experts model?"
}
],
"max_tokens": 100,
"temperature": 0.1
}
Es folgt ein erwartbares Antwortformat für eine Anforderung, die mit der REST-API durchgeführt wurde:
{
"model": "databricks-dbrx-instruct",
"choices": [
{
"message": {},
"index": 0,
"finish_reason": null
}
],
"usage": {
"prompt_tokens": 7,
"completion_tokens": 74,
"total_tokens": 81
},
"object": "chat.completion",
"id": null,
"created": 1698824353
}
Abfragen eines Einbettungsmodells
Nachfolgend sehen Sie eine Einbettungsanforderung für das gte-large-en-Modell, das von Foundation Model-APIs zur Verfügung gestellt wird: Das Beispiel gilt für das Abfragen eines Einbettungsmodells, das mithilfe einer der Model Serving-Funktionen verfügbar gemacht wird: Foundation Model-APIs oder externe Modelle.
OpenAI-Client
Um den OpenAI-Client zu verwenden, geben Sie den Endpunktnamen der Modellbereitstellung als model-Eingabe ein.
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
openai_client = w.serving_endpoints.get_open_ai_client()
response = openai_client.embeddings.create(
model="databricks-gte-large-en",
input="what is databricks"
)
Um Foundation-Modelle außerhalb Ihres Arbeitsbereichs abzufragen, müssen Sie den OpenAI-Client direkt verwenden, wie unten gezeigt. Im folgenden Beispiel wird davon ausgegangen, dass Sie über ein Databricks-API-Token verfügen und openai auf Der Berechnung installiert ist. Außerdem benötigen Sie Ihre Databricks-Arbeitsbereichsinstanz, um den OpenAI-Client mit Databricks zu verknüpfen.
import os
import openai
from openai import OpenAI
client = OpenAI(
api_key="dapi-your-databricks-token",
base_url="https://example.staging.cloud.databricks.com/serving-endpoints"
)
response = client.embeddings.create(
model="databricks-gte-large-en",
input="what is databricks"
)
REST-API
Wichtig
Im folgenden Beispiel werden REST-API-Parameter zum Abfragen von Bereitstellungsendpunkten verwendet, die Basismodelle oder externe Modelle bedienen. Diese Parameter befinden sich in der Public Preview, und die Definition kann sich ändern. Siehe POST /serving-endpoints/{name}/invocations.
curl \
-u token:$DATABRICKS_TOKEN \
-X POST \
-H "Content-Type: application/json" \
-d '{ "input": "Embed this sentence!"}' \
https://<workspace_host>.databricks.com/serving-endpoints/databricks-gte-large-en/invocations
MLflow Deployments SDK
Wichtig
Im folgenden Beispiel wird die predict()-API aus dem MLflow Deployments SDK verwendet.
import mlflow.deployments
export DATABRICKS_HOST="https://<workspace_host>.databricks.com"
export DATABRICKS_TOKEN="dapi-your-databricks-token"
client = mlflow.deployments.get_deploy_client("databricks")
embeddings_response = client.predict(
endpoint="databricks-gte-large-en",
inputs={
"input": "Here is some text to embed"
}
)
Databricks Python SDK
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import ChatMessage, ChatMessageRole
w = WorkspaceClient()
response = w.serving_endpoints.query(
name="databricks-gte-large-en",
input="Embed this sentence!"
)
print(response.data[0].embedding)
LangChain
Um ein Basismodell-APIs-Modell von Databricks in LangChain als Einbettungs-Modell zu verwenden, importieren Sie die Klasse DatabricksEmbeddings, und geben Sie den endpoint Parameter wie folgt an:
%pip install databricks-langchain
from langchain_databricks import DatabricksEmbeddings
embeddings = DatabricksEmbeddings(endpoint="databricks-gte-large-en")
embeddings.embed_query("Can you explain AI in ten words?")
SQL
Wichtig
Im folgenden Beispiel wird die integrierte SQL-Funktion ai_query verwendet. Diese Funktion befindet sich in der Public Preview, und die Definition kann sich ändern. Siehe Abfragen eines bereitgestellten Modells mit ai_query().
SELECT ai_query(
"databricks-gte-large-en",
"Can you explain AI in ten words?"
)
Nachfolgend sehen Sie das erwartete Anforderungsformat für ein Einbettungsmodell. Für externe Modelle können Sie zusätzliche Parameter einschließen, die für eine bestimmte Anbieter- und Endpunktkonfiguration gültig sind. Siehe Zusätzliche Abfrageparameter.
{
"input": [
"embedding text"
]
}
Hier sehen Sie das erwartete Antwortformat:
{
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": []
}
],
"model": "text-embedding-ada-002-v2",
"usage": {
"prompt_tokens": 2,
"total_tokens": 2
}
}
Überprüfen, ob Einbettungen normalisiert sind
Verwenden Sie folgendes, um zu überprüfen, ob die von Ihrem Modell generierten Einbettungen normalisiert werden.
import numpy as np
def is_normalized(vector: list[float], tol=1e-3) -> bool:
magnitude = np.linalg.norm(vector)
return abs(magnitude - 1) < tol
Abfragen eines Textvervollständigungsmodells
OpenAI-Client
Wichtig
Abfragen von Textvervollständigungsmodellen, die mithilfe von Foundation Model-APIs per Token mithilfe des OpenAI-Clients zur Verfügung gestellt werden, werden nicht unterstützt. Es wird nur das Abfragen externer Modelle mit dem OpenAI-Client unterstützt, wie in diesem Abschnitt gezeigt.
Um den OpenAI-Client zu verwenden, geben Sie den Endpunktnamen der Modellbereitstellung als model-Eingabe ein. Im folgenden Beispiel wird das von Anthropic gehostete claude-2-Abschlussmodell mithilfe des OpenAI-Clients abgefragt. Um den OpenAI-Client zu verwenden, füllen Sie das model-Feld mit dem Namen des Modellbereitstellungsendpunkts auf, der das Modell hostet, das Sie abfragen möchten.
In diesem Beispiel wird ein zuvor erstellter Endpunkt anthropic-completions-endpoint verwendet, der für den Zugriff auf externe Modelle vom Anthropic-Modellanbieter konfiguriert ist. Erfahren Sie, wie Sie externe Modellendpunkte erstellen.
Unter Unterstützte Modelle finden Sie weitere Modelle, die Sie abfragen können, sowie deren Anbieter.
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
openai_client = w.serving_endpoints.get_open_ai_client()
completion = openai_client.completions.create(
model="anthropic-completions-endpoint",
prompt="what is databricks",
temperature=1.0
)
print(completion)
REST-API
Nachfolgend finden Sie eine Abschlussanforderung zum Abfragen eines Abschlussmodells, das mithilfe externer Modelle zur Verfügung gestellt wurde.
Wichtig
Im folgenden Beispiel werden REST-API-Parameter zum Abfragen von Endpunkten verwendet, die externen Modellen dienen. Diese Parameter befinden sich in der Public Preview, und die Definition kann sich ändern. Siehe POST /serving-endpoints/{name}/invocations.
curl \
-u token:$DATABRICKS_TOKEN \
-X POST \
-H "Content-Type: application/json" \
-d '{"prompt": "What is a quoll?", "max_tokens": 64}' \
https://<workspace_host>.databricks.com/serving-endpoints/<completions-model-endpoint>/invocations
MLflow Deployments SDK
Nachfolgend finden Sie eine Abschlussanforderung zum Abfragen eines Abschlussmodells, das mithilfe externer Modelle zur Verfügung gestellt wurde.
Wichtig
Im folgenden Beispiel wird die predict()-API aus dem MLflow Deployments SDK verwendet.
import os
import mlflow.deployments
# Only required when running this example outside of a Databricks Notebook
os.environ['DATABRICKS_HOST'] = "https://<workspace_host>.databricks.com"
os.environ['DATABRICKS_TOKEN'] = "dapi-your-databricks-token"
client = mlflow.deployments.get_deploy_client("databricks")
completions_response = client.predict(
endpoint="<completions-model-endpoint>",
inputs={
"prompt": "What is the capital of France?",
"temperature": 0.1,
"max_tokens": 10,
"n": 2
}
)
# Print the response
print(completions_response)
Databricks Python SDK
TThe following is a completions request for querying a completions model made available using external models.
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import ChatMessage, ChatMessageRole
w = WorkspaceClient()
response = w.serving_endpoints.query(
name="<completions-model-endpoint>",
prompt="Write 3 reasons why you should train an AI model on domain specific data sets."
)
print(response.choices[0].text)
SQL
Wichtig
Im folgenden Beispiel wird die integrierte SQL-Funktion ai_query verwendet. Diese Funktion befindet sich in der Public Preview, und die Definition kann sich ändern. Siehe Abfragen eines bereitgestellten Modells mit ai_query().
SELECT ai_query(
"<completions-model-endpoint>",
"Can you explain AI in ten words?"
)
Nachfolgend sehen Sie das erwartete Anforderungsformat für ein Vervollständigungsmodell. Für externe Modelle können Sie zusätzliche Parameter einschließen, die für eine bestimmte Anbieter- und Endpunktkonfiguration gültig sind. Siehe Zusätzliche Abfrageparameter.
{
"prompt": "What is mlflow?",
"max_tokens": 100,
"temperature": 0.1,
"stop": [
"Human:"
],
"n": 1,
"stream": false,
"extra_params":
{
"top_p": 0.9
}
}
Hier sehen Sie das erwartete Antwortformat:
{
"id": "cmpl-8FwDGc22M13XMnRuessZ15dG622BH",
"object": "text_completion",
"created": 1698809382,
"model": "gpt-3.5-turbo-instruct",
"choices": [
{
"text": "MLflow is an open-source platform for managing the end-to-end machine learning lifecycle. It provides tools for tracking experiments, managing and deploying models, and collaborating on projects. MLflow also supports various machine learning frameworks and languages, making it easier to work with different tools and environments. It is designed to help data scientists and machine learning engineers streamline their workflows and improve the reproducibility and scalability of their models.",
"index": 0,
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 5,
"completion_tokens": 83,
"total_tokens": 88
}
}
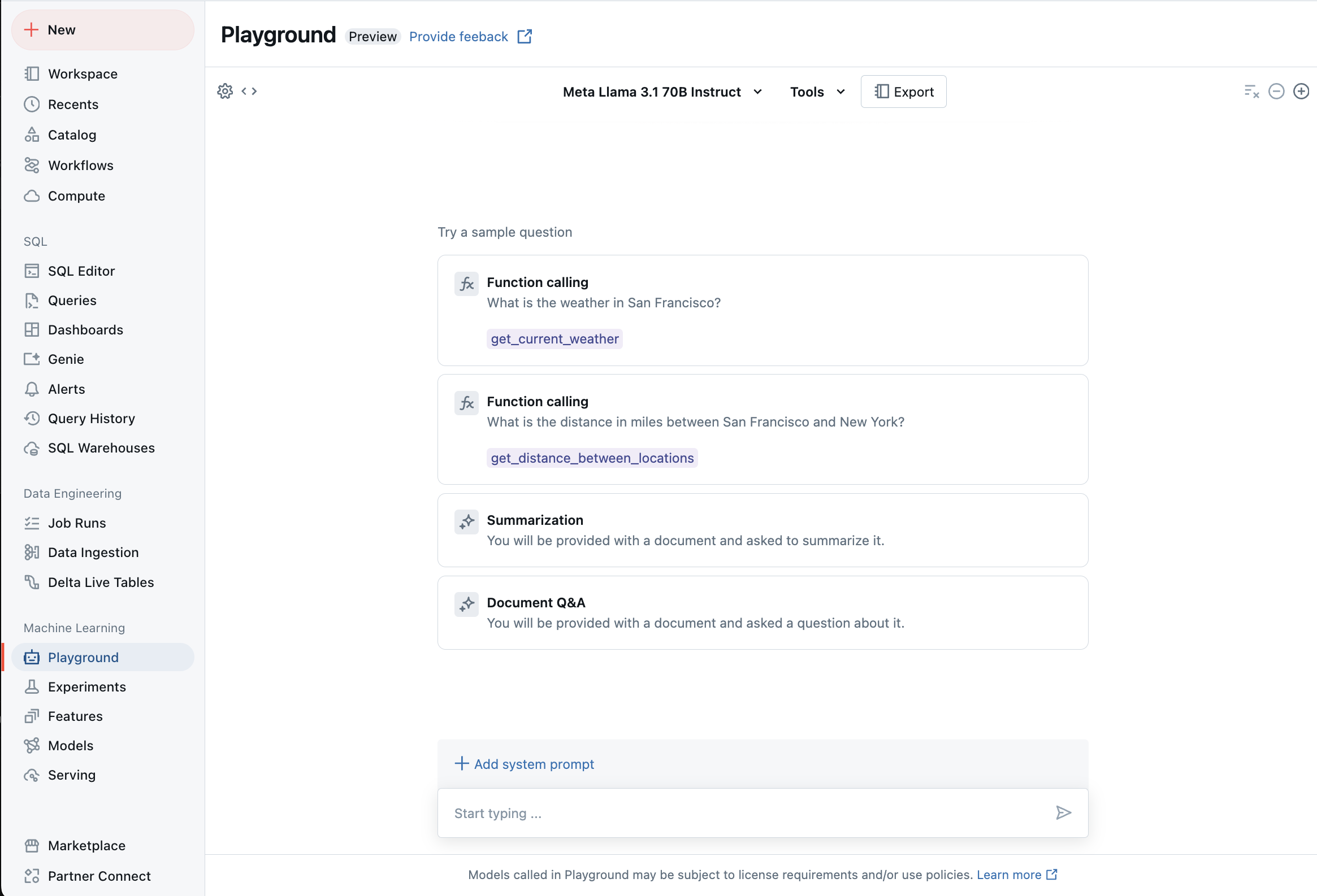
Chatten mit unterstützten LLMs im KI-Playground
Sie können mit unterstützten großen Sprachmodellen interagieren, indem Sie den KI-Playground verwenden. Der KI-Playground ist eine Chat-ähnliche Umgebung, in der Sie LLMs aus Ihrem Azure Databricks-Arbeitsbereich testen, auffordern und vergleichen können.
Zusätzliche Ressourcen
- Rückschlusstabellen für Überwachungs- und Debuggingmodelle
- Batch-Ableitung mithilfe von Foundation Model-APIs bereitgestellter Durchsatz
- Databricks Foundation Model-APIs
- Externe Modelle in Mosaic AI Model Serving
- Lernprogramm: Erstellen externer Modellendpunkte zum Abfragen von OpenAI-Modellen
- Unterstützte Modelle für Pay-per-Token
- Foundation Model-REST-API-Referenz