Databricks Runtime für Machine Learning
Databricks Runtime für Machine Learning (Databricks Runtime ML) automatisiert die Erstellung eines Clusters mit vordefiniertem maschinellem Lernen und Deep Learning-Infrastruktur, einschließlich der häufigsten ML- und DL-Bibliotheken. In den Versionshinweisen finden Sie eine vollständige Liste der Bibliotheken in jeder Version von Databricks Runtime ML.
Hinweis
Um in Unity Catalog auf Daten für Workflows zum maschinellen Lernen zuzugreifen, muss der Zugriffsmodus für den Cluster auf Einzelbenutzer (zugewiesen) eingestellt sein. Geteite Cluster sind nicht mit Databricks Runtime für Machine Learning kompatibel. Darüber hinaus wird Databricks Runtime ML nicht für TableACLs-Cluster oder Cluster unterstützt, für die spark.databricks.pyspark.enableProcessIsolation config auf true festgelegt ist.
Erstellen eines Clusters mithilfe von Databricks Runtime ML
Wenn Sie einen Cluster erstellen, wählen Sie im Dropdownmenü für die Databricks Runtime-Version eine Version von Databricks Runtime ML aus. Es sind CPU- und GPU-fähige ML-Runtimes verfügbar.
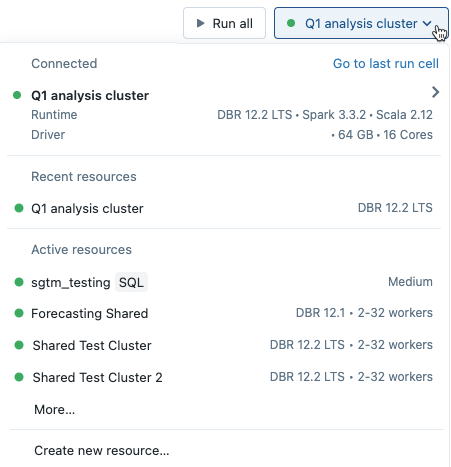
Wenn Sie im Notebook im Dropdownmenü einen Cluster auswählen, wird die Databricks Runtime-Version rechts neben dem Clusternamen angezeigt:
Wenn Sie eine GPU-fähige ML-Runtime auswählen, werden Sie aufgefordert, einen kompatiblen Treibertyp und Workertyp auszuwählen. Inkompatible Instanztypen sind in den Dropdownlisten ausgegraut. GPU-fähige Instanztypen werden unter der Bezeichnung GPU-beschleunigt aufgeführt. Weitere Informationen zum Erstellen von Azure Databricks-GPU-Rechnern finden Sie unter GPU-fähige Rechner. Databricks Runtime ML beinhaltet GPU-Hardwaretreiber und NVIDIA-Bibliotheken wie CUDA.
Photon und Databricks Runtime ML
Wenn Sie einen CPU-Cluster mit Databricks Runtime 15.2 ML oder höher erstellen, haben Sie die Möglichkeit, Photon zu aktivieren. Photon verbessert die Leistung von Anwendungen mit Spark SQL, Spark DataFrames, Feature Engineering, GraphFrames und xgboost4j. Es ist nicht zu erwarten, dass die Leistung von Anwendungen mit Spark-RDDs, pandas-UDFs und nicht-JVM-Sprachen wie Python verbessert wird. Daher profitieren Python-Pakete wie XGBoost, PyTorch und TensorFlow nicht von den Verbesserung durch Photon.
Spark RDD-APIs und Spark MLlib haben eingeschränkte Kompatibilität mit Photon. Bei der Verarbeitung großer Datasets mit Spark RDD oder Spark MLlib können Spark-Speicherprobleme auftreten. Siehe Spark-Speicherprobleme.
In Databricks Runtime ML enthaltene Bibliotheken
Databricks Runtime ML enthält eine Vielzahl von gängigen ML-Bibliotheken. Bei jedem Release werden die Bibliotheken mit neuen Features und Fixes aktualisiert.
Eine Teilmenge der unterstützten Bibliotheken wurde von Databricks als Bibliotheken der obersten Ebene festgelegt. Für diese Bibliotheken bietet Databricks einen schnelleren Aktualisierungsrhythmus, bei dem mit jeder Runtime-Version auf die aktuellen Paketversionen aktualisiert wird (sofern es keine Abhängigkeitskonflikte gibt). Databricks bietet außerdem erweiterte Unterstützung, Tests und eingebettete Optimierungen für Bibliotheken der obersten Ebene.
Eine vollständige Liste der Bibliotheken der obersten Ebene und anderer bereitgestellter Bibliotheken finden Sie in den Versionshinweisen für Databricks Runtime ML.
Sie können zusätzliche Bibliotheken installieren, um eine benutzerdefinierte Umgebung für Ihr Notebook oder Ihren Cluster zu erstellen.
- Um eine Bibliothek für alle Notebooks verfügbar zu machen, die in einem Cluster ausgeführt werden, müssen Sie eine Clusterbibliothek erstellen. Sie können bei der Erstellung auch ein init-Skript verwenden, um Bibliotheken in Clustern zu installieren.
- Verwenden Sie notebookspezifische Python-Bibliotheken, um eine Bibliothek zu installieren, die nur für eine bestimmte Notebooksitzung verfügbar ist.