Notebook-Computeressourcen
In diesem Artikel werden die Optionen für Notebook-Computeressourcen behandelt. Sie können ein Notebook für eine All-Purpose Compute-Ressource, serverloses Computing oder SQL-Befehle ausführen. Zudem können Sie ein SQL-Warehouse verwenden, wobei es sich um einen computeoptimierten Typ für die SQL-Analyse handelt. Weitere Informationen zu Computetypen finden Sie unter Compute.
Serverloses Computing für Notebooks
Serverloses Computing ermöglicht es Ihnen, Ihr Notebook schnell mit On-Demand-Computing-Ressourcen zu verbinden.
Zum Anfügen an die serverlose Berechnung klicken Sie im Notizbuch auf das Dropdownmenü "Verbinden", und wählen Sie "Serverless" aus.
Weitere Informationen finden Sie unter Serverloses Computing für Notebooks.
Anhängen eines Notizbuchs an eine allgemeine Rechenressource
Um ein Notebook an eine All-Purpose Compute-Ressource anzufügen, benötigen Sie die CAN ATTACH TO-Berechtigung für die Computeressource.
Wichtig
Solange ein Notizbuch an eine Computeressource angefügt ist, verfügt jeder Benutzer mit der Berechtigung CAN RUN für das Notizbuch über implizite Berechtigung für den Zugriff auf die Computeressource.
Um ein Notizbuch mit einer Rechenressource zu verbinden, klicken Sie auf die Bereichauswahl in der Notizbuch-Werkzeugleiste und wählen Sie die Ressource aus dem Dropdown-Menü aus.
Das Menü zeigt eine Auswahl an universellen Compute- und SQL-Warehouses, die Sie kürzlich verwendet haben oder gerade laufen.
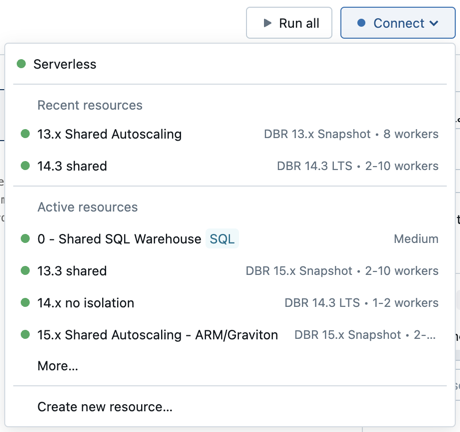
Klicken Sie auf Mehr..., um aus allen verfügbaren Compute-Instanzen auszuwählen. Wählen Sie aus den verfügbaren allgemeinen Berechnungsdiensten oder SQL-Systemen.
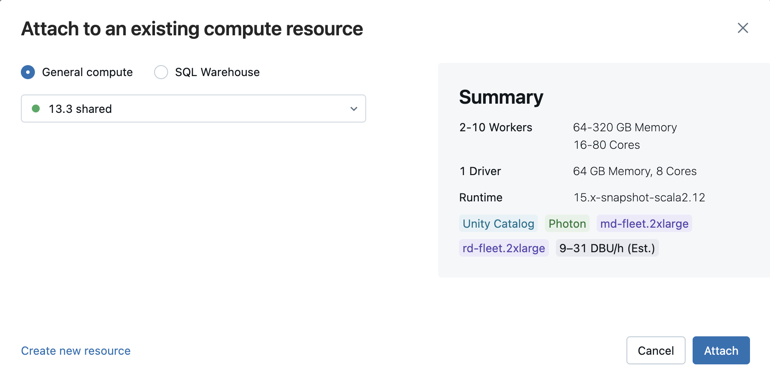
Sie können auch eine neue All-Purpose Compute-Ressource erstellen, indem Sie Neue Ressource erstellen... im Dropdownmenü auswählen.
Wichtig
Für ein angefügtes Notebook sind die folgenden Apache Spark-Variablen definiert.
| Klasse | Variablenname |
|---|---|
SparkContext |
sc |
SQLContext/HiveContext |
sqlContext |
SparkSession (Spark 2.x) |
spark |
SparkSession, SparkContext und SQLContext sollten nicht erstellt werden. Dies würde zu inkonsistentem Verhalten führen.
Verwenden eines Notebooks mit einem SQL-Warehouse
Wenn ein Notebook an ein SQL-Warehouse angefügt ist, können Sie SQL- und Markdown-Zellen ausführen. Das Ausführen einer Zelle in einer anderen Sprache (z. B. Python oder R) löst einen Fehler aus. SQL-Zellen, die in einem SQL-Warehouse ausgeführt werden, werden im Abfrageverlauf des SQL-Warehouses angezeigt. Die Benutzer*innen, die eine Abfrage ausgeführt haben, können das Abfrageprofil vom Notebook aus anzeigen, indem sie auf die verstrichene Zeit am unteren Rand der Ausgabe klicken.
Die Ausführung eines Notebooks erfordert ein Pro- oder serverloses SQL-Warehouse. Sie benötigen Zugriff auf den Arbeitsbereich und das SQL-Warehouse.
Gehen Sie wie folgt vor, um ein Notebook an ein SQL-Warehouse anzufügen:
Klicken Sie in der Notebooksymbolleiste auf die Computeauswahl. Im Dropdownmenü werden Computeressourcen angezeigt, die derzeit ausgeführt werden oder die Sie kürzlich verwendet haben. SQL-Warehouses sind mit der
 gekennzeichnet.
gekennzeichnet.Wählen Sie im Menü ein SQL-Warehouse aus.
Um alle verfügbaren SQL-Warehouses anzuzeigen, wählen Sie im Dropdownmenü Mehr... aus. Ein Dialogfeld mit den für das Notebook verfügbaren Computeressourcen wird angezeigt. Wählen Sie SQL Warehouse aus, wählen Sie das gewünschte Warehouse aus, und klicken Sie auf Anfügen.
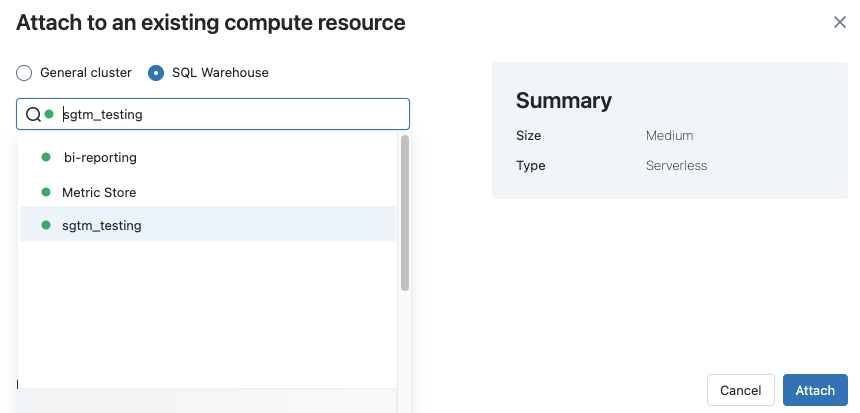
Sie können auch ein SQL Warehouse als Computeressource für ein SQL-Notebook auswählen, wenn Sie einen Workflow oder einen geplanten Auftrag erstellen.
Einschränkungen von SQL-Warehouses
Weitere Informationen finden Sie unter Bekannte Einschränkungen von Databricks-Notebooks.
Trennen eines Notebooks
Klicken Sie zum Trennen eines Notebooks von einer Computeressource auf die Computeauswahl auf der Notebooksymbolleiste, und zeigen Sie mit der Maus auf die angefügte Compute in der Liste, um ein Menü auf der Seite anzuzeigen. Wählen Sie im seitlichen Menü Trennen aus.
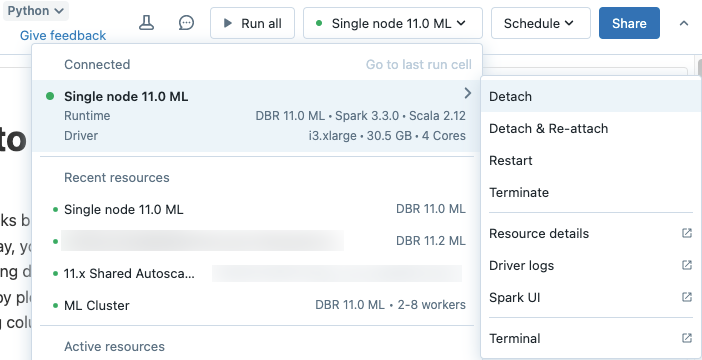
Sie können Notizbücher auch von einer Allzweck-Rechenressource trennen, indem Sie die Registerkarte Notizbücher auf der Detailseite der Rechenressource verwenden.
Tipp
Azure Databricks empfiehlt, nicht verwendete Notizbücher von der Berechnung zu trennen. Dadurch wird Arbeitsspeicher auf dem Treiber freigegeben.