KI-Agenten im Code erstellen
In diesem Artikel wird gezeigt, wie Sie einen KI-Agent in Python mit Mosaik AI Agent Framework und beliebten Bibliotheken für die Agenterstellung wie LangGraph, PyFunc und OpenAI erstellen.
Anforderungen
Databricks empfiehlt die Installation der neuesten Version des MLflow Python-Clients bei der Entwicklung von Agents.
Um Agents mithilfe des Ansatzes in diesem Artikel zu erstellen und bereitzustellen, müssen Sie über die folgenden Mindestpaketversionen verfügen:
databricks-agentsVersion 0.16.0 und höhermlflowVersion 2.20.2 und höher- Python 3.10 oder höher. Sie können serverlose Rechenkapazität oder Databricks Runtime 13.3 LTS und höher verwenden, um die Anforderung zu erfüllen.
%pip install -U -qqqq databricks-agents>=0.16.0 mlflow>=2.20.2
Databricks empfiehlt auch die Installation der Databricks AI Bridge Integrationspakete beim Erstellen von Agenten. Diese Integrationspakete (z. B. databricks-langchain, databricks-openai) bieten eine gemeinsame API-Ebene für die Interaktion mit Databricks AI-Features wie Databricks AI/BI Genie und Vector Search über Agent-Erstellungsframeworks und SDKs hinweg.
LangChain/LangGraph
%pip install -U -qqqq databricks-langchain
OpenAI
%pip install -U -qqqq databricks-openai
Reine Python-Agenten
%pip install -U -qqqq databricks-ai-bridge
Verwende ChatAgent zum Erstellen von Agenten
Databricks empfiehlt die Verwendung der ChatAgent-Schnittstelle von MLflow zum Erstellen von Agents auf Produktionsniveau. Diese Chatschemaspezifikation wurde für Agentszenarien entwickelt und ähnelt dem OpenAI-ChatCompletion-Schema, das jedoch nicht streng kompatibel ist. ChatAgent fügt auch Funktionen für Agents hinzu, die mehrfache Interaktionen und Toolaufrufe ermöglichen.
Das Erstellen Ihres Agents mithilfe von ChatAgent bietet die folgenden Vorteile:
Erweiterte Agent-Funktionen
- Streamingausgabe: Aktivieren Sie interaktive Benutzererfahrungen, indem Sie die Streamingausgabe in kleineren Blöcken streamen.
- Umfassender Nachrichtenverlauf bei Toolaufrufen: Rückgabe mehrerer Nachrichten, einschließlich zwischengeschalteter Nachrichten, für eine verbesserte Qualität und Konversationsverwaltung.
- Unterstützung bei der Bestätigung von Toolaufrufen
- Multi-Agent-Systemunterstützung
Vereinfachte Entwicklung, Bereitstellung und Überwachung
- Frameworkunabhängige Integration von Databricks-Features: Schreiben Sie Ihren Agent in einem Framework Ihrer Wahl, und profitieren Sie von einer sofort einsatzbereiten Kompatibilität mit dem KI-Playground, der Agent-Bewertung und der Agent-Überwachung.
- Typisierte Erstellungsschnittstellen: Schreiben Sie Agent-Code mit typisierten Python-Klassen, und nutzen Sie dabei das AutoVervollständigen von IDE und Notebook.
- Automatische Signaturableitung: MLflow leitet automatisch
ChatAgentSignaturen ab, wenn der Agent protokolliert, was die Registrierung und Bereitstellung vereinfacht. Weitere Informationen finden Sie unter Ableiten der Modellsignatur während der Protokollierung. - AI Gateway-erweiterte Inferencetabellen: AI-Gateway-Ableitungstabellen werden automatisch für bereitgestellte Agents aktiviert und bieten Zugriff auf detaillierte Anforderungsprotokollmetadaten.
Informationen zum Erstellen einer ChatAgent finden Sie in den Beispielen im folgenden Abschnitt und unter MLflow-Dokumentation – Was ist die ChatAgent-Schnittstelle.
Beispiele für ChatAgent
In den folgenden Notebooks wird gezeigt, wie Sie Streaming- und Nicht-Streaming-ChatAgents mithilfe der beliebten Bibliotheken OpenAI und LangGraph erstellen.
Toolaufruf-Agent für LangGraph
Toolaufruf-Agent für OpenAI
Chat-Agent für OpenAI
Informationen zum Erweitern der Funktionen dieser Agents durch Hinzufügen von Tools finden Sie unter KI-Agent-Tools.
Erstellen von bereitstellungsbereiten ChatAgents für die Databricks-Modellbereitstellung
Databricks stellt ChatAgents in einer verteilten Umgebung für die Databricks-Modellbereitstellung bereit, sodass dasselbe Replikat während einer mehrteiligen Unterhaltung möglicherweise nicht alle Anforderungen verarbeitet. Beachten Sie die folgenden Auswirkungen auf die Verwaltung des Agent-Status:
Vermeiden einer lokalen Zwischenspeicherung: Bei der Bereitstellung eines
ChatAgentsollte nicht davon ausgegangen werden, dass dasselbe Replikat alle Anforderungen in einer mehrteiligen Unterhaltung verarbeitet. Rekonstruieren Sie den internen Zustand mithilfe eines Schemas fürChatAgentRequest-Wörterbücher für jeden Teil.Threadsicherer Zustand: Entwurfs-Agent-Zustand, der threadsicher sein soll und Konflikte in Multithread-Umgebungen verhindert.
Zustand in der
predict-Funktion initialisieren: Initialisieren Sie den Zustand jedes Mal, wenn diepredict-Funktion aufgerufen wird, nicht während der Initialisierung vonChatAgent. Das Speichern des Zustands auf derChatAgentEbene könnte Informationen zwischen Unterhaltungen leaken und Konflikte verursachen, da ein einzelnesChatAgent-Replikat Anforderungen aus mehreren Unterhaltungen verarbeiten kann.
Benutzerdefinierte Eingaben und Ausgaben
Einige Szenarien erfordern möglicherweise zusätzliche Agenteingaben, z. B. client_type und session_id, oder Ausgaben wie Abrufquellenlinks, die nicht in den Chatverlauf für zukünftige Interaktionen einbezogen werden sollten.
Für diese Szenarien unterstützt MLflow ChatAgent die Felder custom_inputs und custom_outputsnativ.
Warnung
Die Überprüfungs-App „Agent Evaluation“ bietet derzeit keine Unterstützung für das Rendern von Ablaufverfolgungen für Agents mit zusätzlichen Eingabefeldern.
In den folgenden Beispielen erfahren Sie, wie Sie benutzerdefinierte Eingaben und Ausgaben für OpenAI/PyFunc- und LangGraph-Agents festlegen.
OpenAI + PyFunc-Notebook für benutzerdefinierte Schema-Agenten
Benutzerdefiniertes Schema-Agent-Notizbuch für LangGraph
Bereitstellen von custom_inputs in der AI Playground- und Agent Review-App
Wenn Ihr Agent zusätzliche Eingaben mithilfe des Felds custom_inputs akzeptiert, können Sie diese Eingaben sowohl im AI Playground als auch in der Agent-Überprüfungs-Appmanuell bereitstellen.
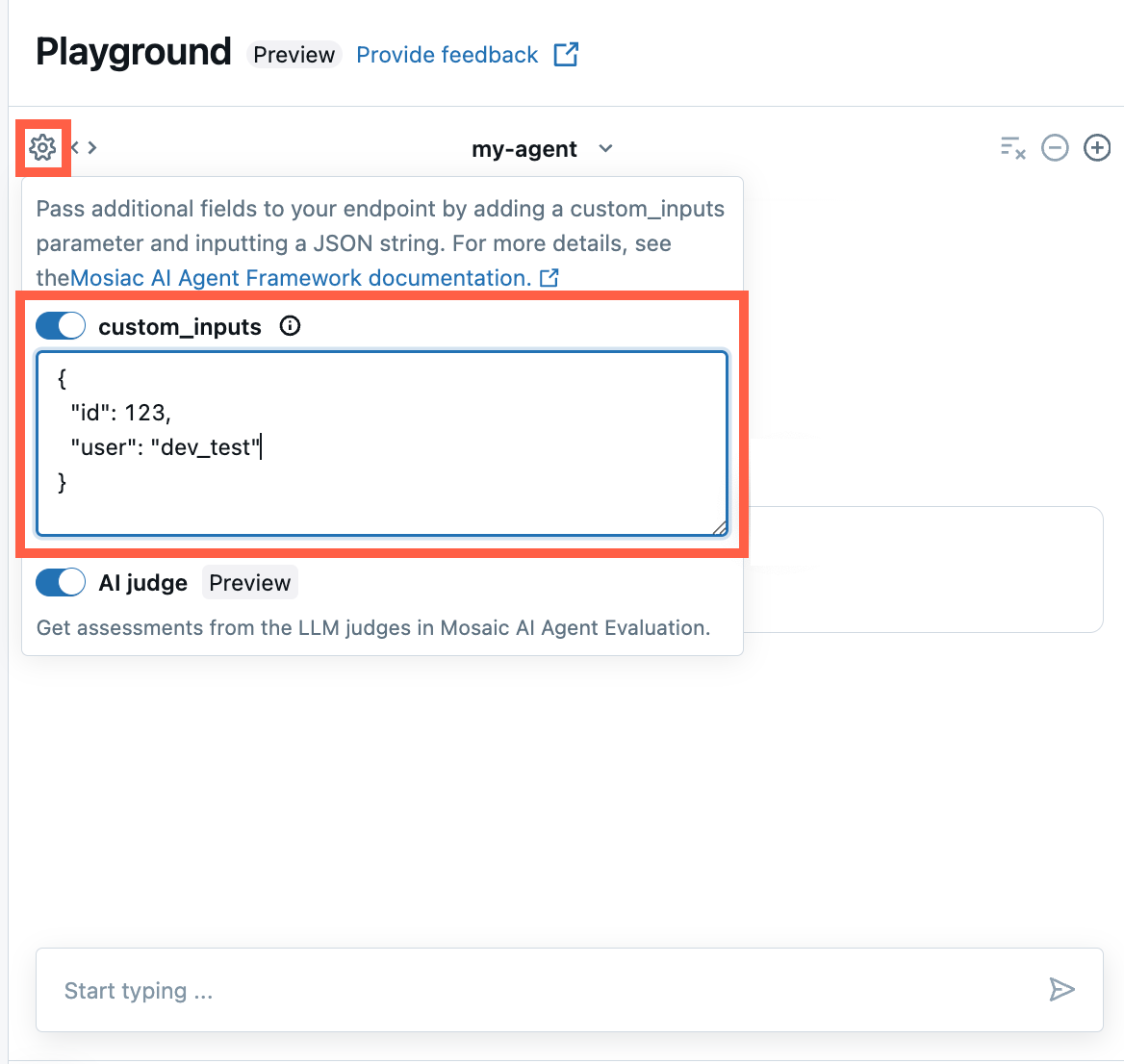
Wählen Sie in der AI Playground- oder in der Agent Review-App das Zahnradsymbol
 aus.
aus.Aktivieren Sie custom_inputs.
Stellen Sie ein JSON-Objekt bereit, das dem definierten Eingabeschema Ihres Agents entspricht.
Geben Sie benutzerdefinierte Retriever-Schemata an
KI-Agents verwenden häufig Retriever, um unstrukturierte Daten aus Vektorsuchindizes zu finden und abzufragen. Beispielsweise finden Sie Retriever-Tools unter Tools für unstrukturiertes Abrufen des KI-Agents.
Verfolgen Sie diese Retriever in Ihrem Agent mit MLflow RETRIEVER, um Databricks-Produktfeatures zu aktivieren, einschließlich:
- Automatisches Anzeigen von Links zu abgerufenen Quelldokumenten in der AI Playground-Benutzeroberfläche
- Automatisierte Ausführung der Abrufübereinstimmung und der Relevanzbewertung in der Agentenbewertung
Anmerkung
Databricks empfiehlt die Verwendung von Retriever-Tools, die von Databricks AI Bridge-Paketen wie databricks_langchain.VectorSearchRetrieverTool und databricks_openai.VectorSearchRetrieverTool bereitgestellt werden, da sie bereits dem MLflow-Retriever-Schema entsprechen. Weitere Informationen finden Sie unter Lokale Entwicklung von Abrufertools für die Vektorsuche mit AI Bridge.
Wenn Ihr Agent Retriever-Abschnitte mit einem benutzerdefinierten Schema umfasst, rufen Sie mlflow.models.set_retriever_schema auf, wenn Sie Ihren Agent im Code definieren. Dadurch werden die Ausgabespalten des Retrievers den erwarteten Feldern von MLflow (primary_key, text_column, doc_uri) zugeordnet.
import mlflow
# Define the retriever's schema by providing your column names
mlflow.models.set_retriever_schema(
# Specify the name of your retriever span
name="vector_search",
# Specify the output column name to treat as the primary key (ID) of each retrieved document
primary_key="chunk_id",
# Specify the output column name to treat as the text content (page content) of each retrieved document
text_column="text_column",
# Specify the output column name to treat as the document URI of each retrieved document
doc_uri="doc_uri",
)
Anmerkung
Die doc_uri Spalte ist besonders wichtig beim Auswerten der Leistung des Retrievers. doc_uri ist der Hauptbezeichner für Dokumente, die vom Abrufer zurückgegeben werden. Damit können Sie sie mit Auswertungssätzen für die Grundwahrheit vergleichen. Weitere Informationen finden Sie unter Auswertungssätze.
Parametrisieren von Agentcode für die Bereitstellung in allen Umgebungen
Sie können Agentcode parametrisieren, um denselben Agentcode in verschiedenen Umgebungen wiederzuverwenden.
Parameter sind Schlüsselwertpaare, die Sie in einem Python-Wörterbuch oder einer .yaml Datei definieren.
Um den Code zu konfigurieren, erstellen Sie eine ModelConfig entweder mithilfe eines Python-Wörterbuchs oder einer .yaml -Datei. ModelConfig ist eine Reihe von Schlüsselwertparametern, die eine flexible Konfigurationsverwaltung ermöglichen. Sie können z. B. während der Entwicklung ein Wörterbuch verwenden und dann in eine .yaml Datei für die Produktionsbereitstellung und CI/CD konvertieren.
Ausführliche Informationen zu ModelConfigfinden Sie in der MLflow-Dokumentation.
Ein Beispiel ModelConfig wird unten gezeigt:
llm_parameters:
max_tokens: 500
temperature: 0.01
model_serving_endpoint: databricks-dbrx-instruct
vector_search_index: ml.docs.databricks_docs_index
prompt_template: 'You are a hello world bot. Respond with a reply to the user''s
question that indicates your prompt template came from a YAML file. Your response
must use the word "YAML" somewhere. User''s question: {question}'
prompt_template_input_vars:
- question
Sie können im Agent-Code über die Datei .yaml oder ein Wörterbuch auf eine Standardkonfiguration (für die Entwicklung) verweisen:
import mlflow
# Example for loading from a .yml file
config_file = "configs/hello_world_config.yml"
model_config = mlflow.models.ModelConfig(development_config=config_file)
# Example of using a dictionary
config_dict = {
"prompt_template": "You are a hello world bot. Respond with a reply to the user's question that is fun and interesting to the user. User's question: {question}",
"prompt_template_input_vars": ["question"],
"model_serving_endpoint": "databricks-dbrx-instruct",
"llm_parameters": {"temperature": 0.01, "max_tokens": 500},
}
model_config = mlflow.models.ModelConfig(development_config=config_dict)
# Use model_config.get() to retrieve a parameter value
# You can also use model_config.to_dict() to convert the loaded config object
# into a dictionary
value = model_config.get('sample_param')
Geben Sie dann beim Protokollieren des Agents den model_config Parameter als log_model an, um einen benutzerdefinierten Satz von Parametern anzugeben, die beim Laden des protokollierten Agents verwendet werden sollen. Weitere Informationen finden Sie in der MLflow-Dokumentation – ModelConfig.
Streamingfehlerausbreitung
Mosaic AI verteilt alle Fehler, die beim Streaming aufgetreten sind, mit dem letzten Token unter databricks_output.error. Es liegt bei dem aufrufenden Client, diesen Fehler ordnungsgemäß zu behandeln und anzuzeigen.
{
"delta": …,
"databricks_output": {
"trace": {...},
"error": {
"error_code": BAD_REQUEST,
"message": "TimeoutException: Tool XYZ failed to execute."
}
}
}