Ausführen einer Auswertung und Anzeigen der Ergebnisse
Wichtig
Dieses Feature befindet sich in der Public Preview.
In diesem Artikel wird beschrieben, wie Sie eine Auswertung ausführen und die Ergebnisse während der Entwicklung Ihrer KI-Anwendung anzeigen. Informationen zum Überwachen der Qualität der bereitgestellten Agents für den Produktionsverkehr finden Sie unter Überwachen der Qualität Ihres Agents für den Produktionsdatenverkehr.
Zum Auswerten eines Agents müssen Sie einen Auswertungssatz angeben. Ein Auswertungssatz besteht mindestens aus einer Reihe von Anforderungen an Ihre Anwendung, die entweder aus einem kuratierten Satz von Auswertungsanforderungen oder aus Ablaufverfolgungen von benutzenden Personen des Agenten stammen können. Weitere Informationen finden Sie unter Auswertungssätze und Auswertungseingabeschema des Agenten.
Ausführen einer Auswertung
Verwenden Sie zum Ausführen einer Auswertung die Methode mlflow.evaluate() aus der MLflow-API, und geben Sie model_type als databricks-agent an, um die Agent-Auswertung auf Databricks und integrierten KI-Richtern zu aktivieren.
Im folgenden Beispiel wird eine Reihe globaler Antwortrichtlinien für den KI-Richter für globale Richtlinien angegeben, durch die bei der Auswertung ein Fehler auftritt, wenn Antworten nicht den Richtlinien entsprechen. Durch diesen Ansatz müssen Sie keine Bezeichnungen pro Anforderung sammeln, um Ihren Agent auszuwerten.
import mlflow
from mlflow.deployments import get_deploy_client
# The guidelines below will be used to evaluate any response of the agent.
global_guidelines = [
"If the request is unrelated to Databricks, the response must should be a rejection of the request",
"If the request is related to Databricks, the response must should be concise",
"If the request is related to Databricks and question about API, the response must have code",
"The response must be professional."
]
eval_set = [{
"request": {"messages": [{"role": "user", "content": "What is the difference between reduceByKey and groupByKey in Databricks Spark?"}]}
}, {
"request": "What is the weather today?",
}]
# Define a very simple system-prompt agent.
@mlflow.trace(span_type="AGENT")
def llama3_agent(messages):
SYSTEM_PROMPT = """
You are a chatbot that answers questions about Databricks.
For requests unrelated to Databricks, reject the request.
"""
return get_deploy_client("databricks").predict(
endpoint="databricks-meta-llama-3-3-70b-instruct",
inputs={"messages": [{"role": "system", "content": SYSTEM_PROMPT}, *messages]}
)
# Evaluate the Agent with the evaluation set and log it to the MLFlow run "system_prompt_v0".
with mlflow.start_run(run_name="system_prompt_v0") as run:
mlflow.evaluate(
data=eval_set,
model=lambda request: llama3_agent(**request),
model_type="databricks-agent",
evaluator_config={
"databricks-agent": {
"global_guidelines": global_guidelines
}
}
)
In diesem Beispiel werden die folgenden Richter ausgeführt, die keine Bezeichnungen für die Grundwahrheit benötigen: Richtlinientreue, Relevanz für Abfragen, Sicherheit.
Wenn Sie einen Agent mit einem Abrufer verwenden, werden die folgenden Richter ausgeführt: Quellenübereinstimmung, Blockrelevanz
mlflow.evaluate() berechnet außerdem Latenz- und Kostenmetriken für jeden Auswertungsdatensatz und aggregiert Ergebnisse für alle Eingaben für eine bestimmte Ausführung. Diese werden als Auswertungsergebnisse bezeichnet. Auswertungsergebnisse werden in der eingeschlossenen Ausführung zusammen mit Informationen protokolliert, die von weiteren Befehlen wie Modellparametern protokolliert werden. Wenn Sie mlflow.evaluate() außerhalb einer MLflow-Ausführung aufrufen, wird eine neue Ausführung erstellt.
Auswerten mit Ground-Truth-Bezeichnungen
Im folgenden Beispiel werden die Ground-Truth-Bezeichnungen pro Zeile angegeben: expected_facts und guidelines, die die Richter für Richtigkeit und Richtlinien ausführen. Einzelne Auswertungen werden mithilfe von Ground-Truth-Bezeichnungen separat pro Zeile behandelt.
%pip install databricks-agents
dbutils.library.restartPython()
import mlflow
from mlflow.types.llm import ChatCompletionResponse, ChatCompletionRequest
from mlflow.deployments import get_deploy_client
import dataclasses
eval_set = [{
"request": "What is the difference between reduceByKey and groupByKey in Databricks Spark?",
"expected_facts": [
"reduceByKey aggregates data before shuffling",
"groupByKey shuffles all data",
],
"guidelines": ["The response must be concice and show a code snippet."]
}, {
"request": "What is the weather today?",
"guidelines": ["The response must reject the request."]
}]
# Define a very simple system-prompt agent.
@mlflow.trace(span_type="AGENT")
def llama3_agent(messages):
SYSTEM_PROMPT = """
You are a chatbot that answers questions about Databricks.
For requests unrelated to Databricks, reject the request.
"""
return get_deploy_client("databricks").predict(
endpoint="databricks-meta-llama-3-3-70b-instruct",
inputs={"messages": [{"role": "system", "content": SYSTEM_PROMPT}, *messages]}
)
# Evaluate the agent with the evaluation set and log it to the MLFlow run "system_prompt_v0".
with mlflow.start_run(run_name="system_prompt_v0") as run:
mlflow.evaluate(
data=eval_set,
model=lambda request: llama3_agent(**request),
model_type="databricks-agent"
)
In diesem Beispiel werden zusätzlich zu den oben genannten Richtern die folgenden ausgeführt: Korrektheit, Relevanz, Sicherheit
Wenn Sie einen Agent mit einem Abrufer verwenden, wird der folgende Richter ausgeführt: Zulänglichkeit des Kontexts
Anforderungen
Azure KI-gesteuerte KI-Hilfsfunktionen müssen für Ihren Arbeitsbereich aktiviert sein.
Bereitstellen von Eingaben für einen Auswertungslauf
Es gibt zwei Möglichkeiten zum Bereitstellen von Eingaben für einen Auswertungslauf:
Stellen Sie zuvor generierte Ausgaben bereit, die mit dem Auswertungssatz verglichen werden sollen. Diese Option wird empfohlen, wenn Sie Ausgaben aus einer Anwendung auswerten möchten, die bereits in der Produktion bereitgestellt wird, oder wenn Sie Auswertungsergebnisse zwischen Auswertungskonfigurationen vergleichen möchten.
Mit dieser Option geben Sie einen Auswertungssatz an, wie im folgenden Code dargestellt. Der Auswertungssatz muss zuvor generierte Ausgaben enthalten. Ausführlichere Beispiele finden Sie unter Beispiel: Übergeben zuvor generierter Ausgaben an die Agent-Auswertung.
evaluation_results = mlflow.evaluate( data=eval_set_with_chain_outputs_df, # pandas DataFrame with the evaluation set and application outputs model_type="databricks-agent", )Übergeben Sie die Kette als Eingabeargument.
mlflow.evaluate()fordert die Anwendung für jede Eingabe im Auswertungssatz auf und meldet Qualitätsbewertungen und andere Metriken für jede generierte Ausgabe. Diese Option wird empfohlen, wenn Ihre Anwendung mithilfe von MLflow mit aktivierter MLflow-Ablaufverfolgung protokolliert wurde oder wenn Ihre Anwendung als Python-Funktion in einem Notizbuch implementiert wird. Diese Option wird nicht empfohlen, wenn Ihre Anwendung außerhalb von Databricks entwickelt wurde oder außerhalb von Databricks bereitgestellt wird.Mit dieser Option geben Sie den Auswertungssatz und die Anwendung im Funktionsaufruf an, wie im folgenden Code dargestellt. Ausführlichere Beispiele finden Sie unter Beispiel: Übergeben einer Anwendung an die Agent-Auswertung.
evaluation_results = mlflow.evaluate( data=eval_set_df, # pandas DataFrame containing just the evaluation set model=model, # Reference to the MLflow model that represents the application model_type="databricks-agent", )
Ausführliche Informationen zum Bewertungssatzschema finden Sie unter Agent Evaluation Input Schema.
Auswertungsausgaben
Die Agentauswertung gibt ihre Ausgaben mlflow.evaluate() als Datenframes zurück und protokolliert diese Ausgaben auch bei der MLflow-Ausführung. Sie können die Ausgaben im Notizbuch oder von der Seite der entsprechenden MLflow-Ausführung überprüfen.
Überprüfen der Ausgabe im Notizbuch
Der folgende Code zeigt einige Beispiele zum Überprüfen der Ergebnisse einer Auswertung aus Ihrem Notizbuch.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
###
# Run evaluation
###
evaluation_results = mlflow.evaluate(..., model_type="databricks-agent")
###
# Access aggregated evaluation results across the entire evaluation set
###
results_as_dict = evaluation_results.metrics
results_as_pd_df = pd.DataFrame([evaluation_results.metrics])
# Sample usage
print(f"The percentage of generated responses that are grounded: {results_as_dict['response/llm_judged/groundedness/percentage']}")
###
# Access data about each question in the evaluation set
###
per_question_results_df = evaluation_results.tables['eval_results']
# Show information about responses that are not grounded
per_question_results_df[per_question_results_df["response/llm_judged/groundedness/rating"] == "no"].display()
Der per_question_results_df Datenrahmen enthält alle Spalten im Eingabeschema und alle Auswertungsergebnisse, die für jede Anforderung spezifisch sind. Weitere Informationen zu den berechneten Ergebnissen finden Sie unter How quality, cost, and latency are bewertung by Agent Evaluation.
Überprüfen der Ausgabe mithilfe der MLflow-Benutzeroberfläche
Auswertungsergebnisse sind auch in der MLflow-Benutzeroberfläche verfügbar. Um auf die MLflow-Benutzeroberfläche zuzugreifen, klicken Sie auf das Experiment-Symbol ![]() in der rechten Randleiste des Notebooks und dann auf die entsprechende Ausführung, oder klicken Sie auf die Links, die in den Zellenergebnissen für die Notebookzelle angezeigt werden, in der Sie
in der rechten Randleiste des Notebooks und dann auf die entsprechende Ausführung, oder klicken Sie auf die Links, die in den Zellenergebnissen für die Notebookzelle angezeigt werden, in der Sie mlflow.evaluate() ausgeführt haben.
Überprüfen der Auswertungsergebnisse für eine einzelne Ausführung
In diesem Abschnitt wird beschrieben, wie Sie die Auswertungsergebnisse für eine einzelne Ausführung überprüfen. Informationen zum Vergleichen von Ergebnissen über mehrere Ausführungsläufe hinweg finden Sie unter Vergleichen von Auswertungsergebnissen.
Übersicht über Qualitätsbewertungen durch LLM-Richter
Bewertungen pro Anfrage sind in databricks-agents Version 0.3.0 und höher verfügbar.
Um eine Übersicht über die LLM-bewertete Qualität jeder Anforderung im Evaluierungssatz anzuzeigen, klicken Sie auf der Seite "MLflow-Ausführung" auf die Registerkarte "Auswertungsergebnisse ". Auf dieser Seite wird eine Zusammenfassungstabelle der einzelnen Auswertungsausführungen angezeigt. Klicken Sie für weitere Details auf die Evaluation ID einer Ausführung.
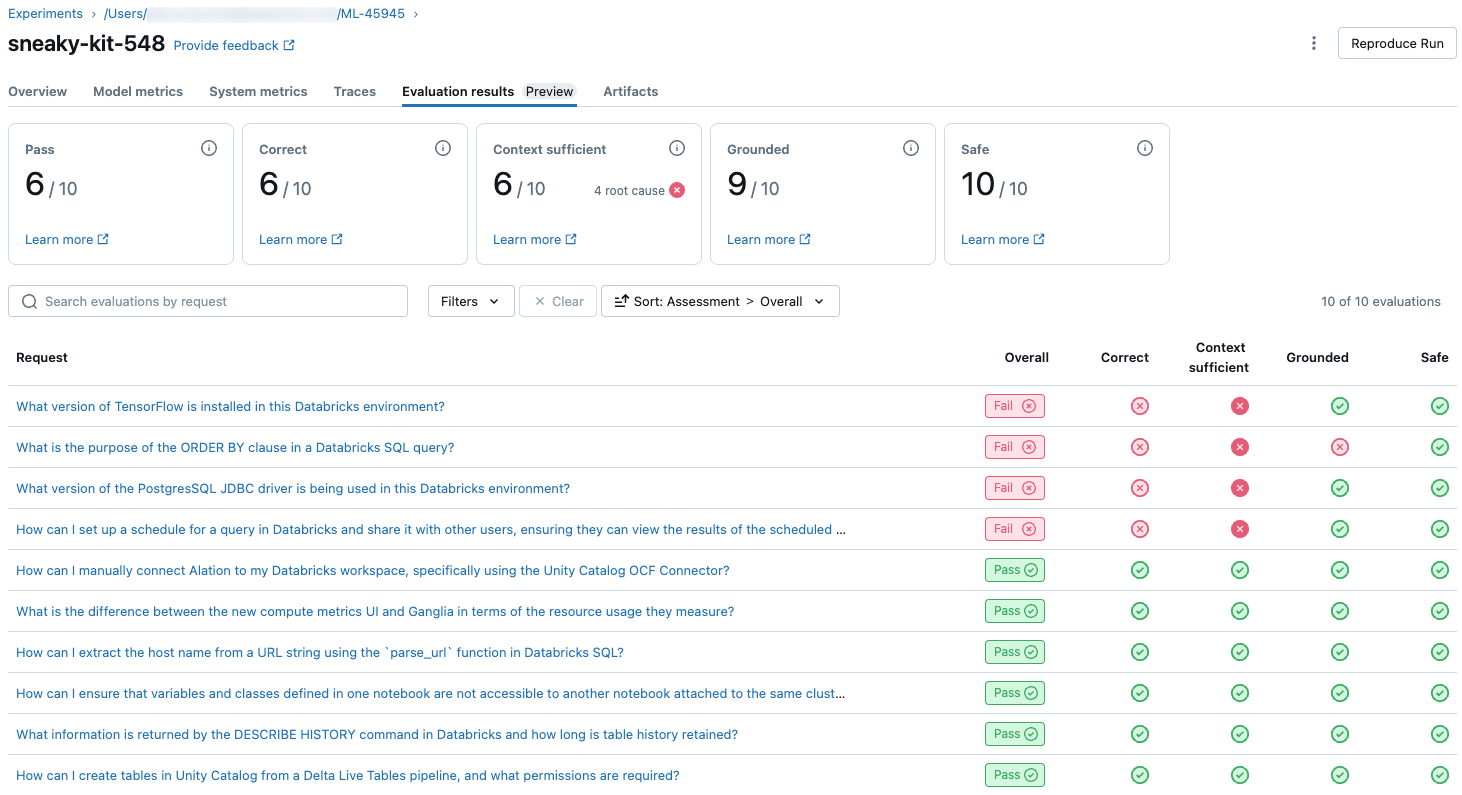
Diese Übersicht zeigt die Bewertungen verschiedener Richter für jede Anforderung, den Status "Quality-pass/-fail" jeder Anforderung basierend auf diesen Bewertungen und die Ursache für fehlgeschlagene Anforderungen. Wenn Sie auf eine Zeile in der Tabelle klicken, gelangen Sie zur Detailseite für diese Anforderung, die Folgendes enthält:
- Modellausgabe: Die generierte Antwort aus der agentischen App und deren Ablaufverfolgung, falls enthalten.
- Erwartete Ausgabe: Die erwartete Antwort für jede Anforderung.
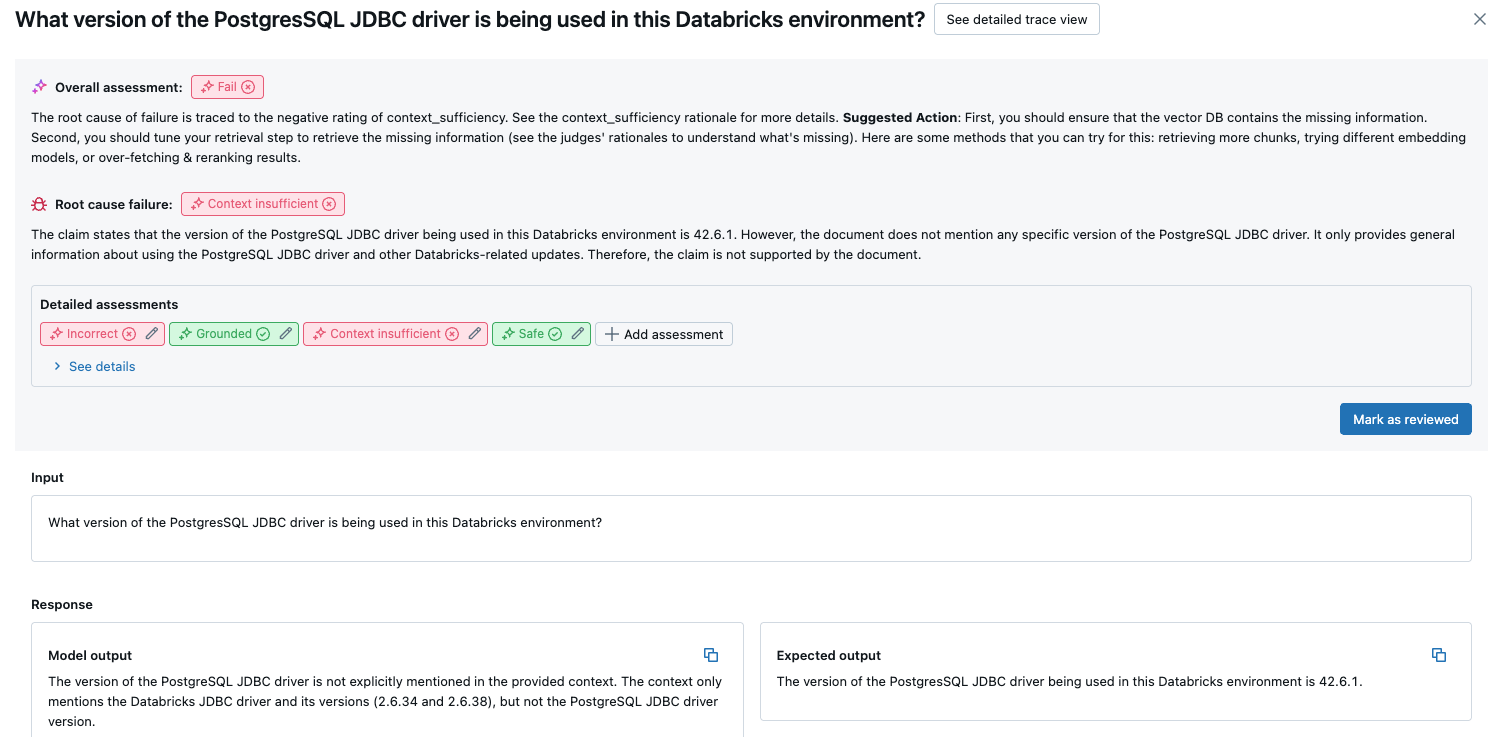
- Detaillierte Bewertungen: Die Bewertungen der LLM-Richter zu diesen Daten. Klicken Sie auf Details anzeigen, um die von den Richtern bereitgestellten Begründungen anzuzeigen.
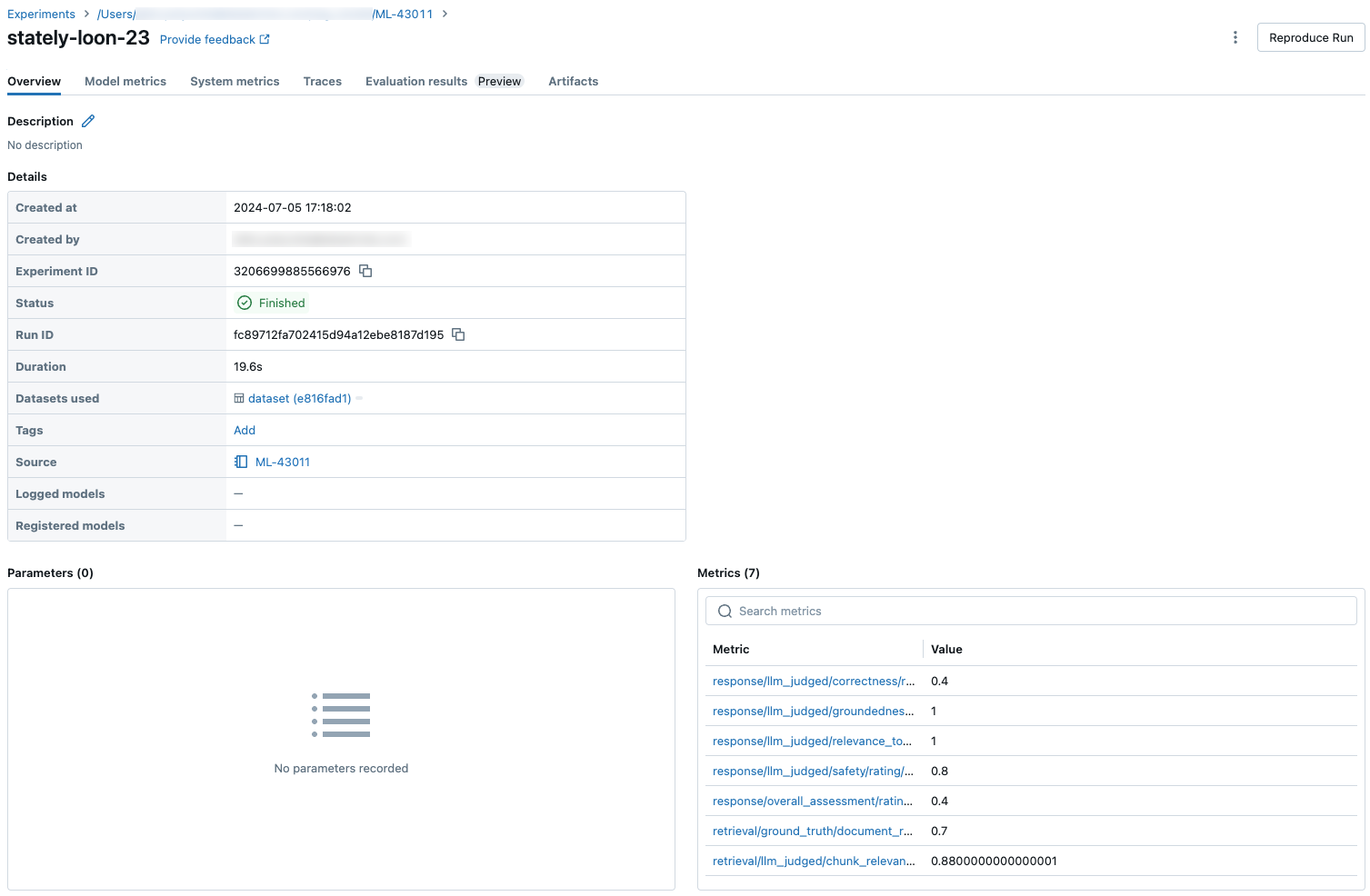
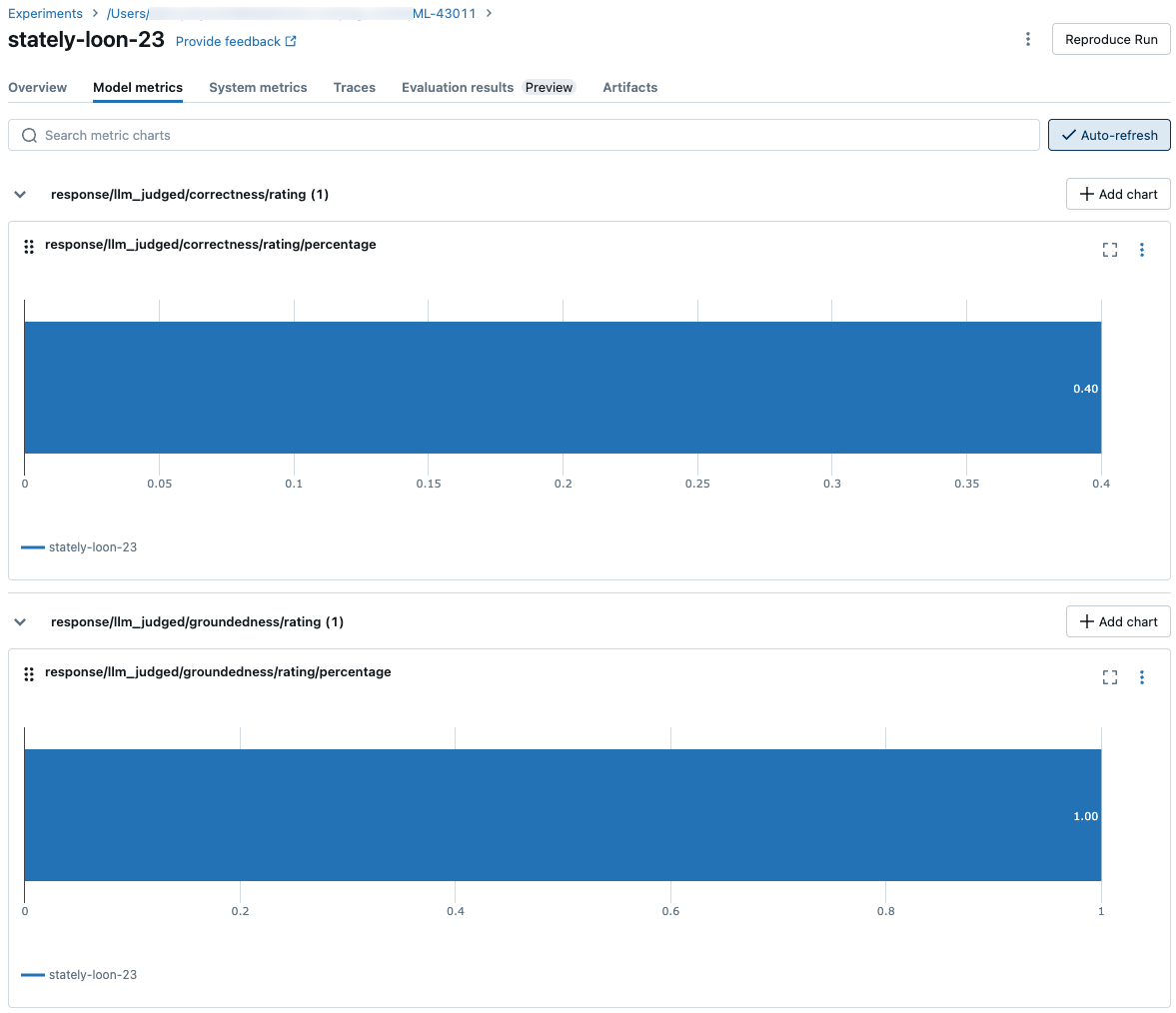
Aggregierte Ergebnisse im gesamten Auswertungssatz
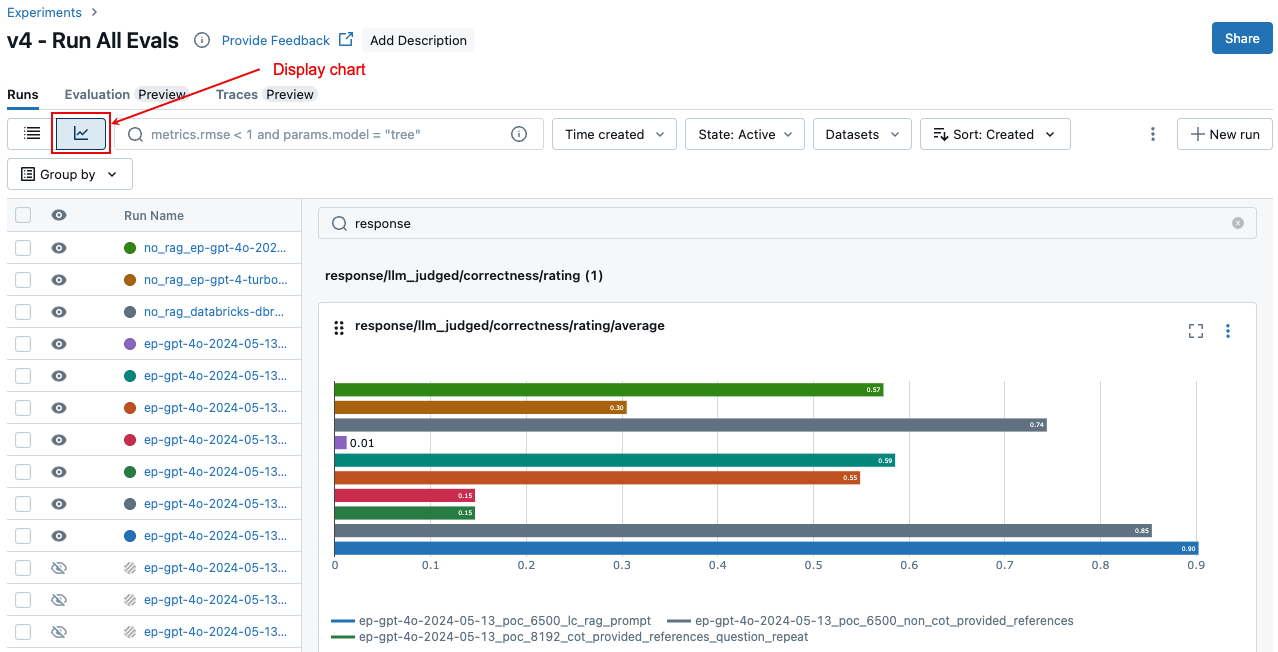
Um aggregierte Ergebnisse im gesamten Auswertungssatz anzuzeigen, klicken Sie auf die Registerkarte "Übersicht " (für numerische Werte) oder auf die Registerkarte "Modellmetriken " (für Diagramme).
Vergleichen von Auswertungsergebnissen über alle Ausführungsläufe hinweg
Es ist wichtig, Auswertungsergebnisse über Ausführungen hinweg zu vergleichen, um zu sehen, wie Ihre agentische Anwendung auf Änderungen reagiert. Das Vergleichen von Ergebnissen kann Ihnen helfen, zu verstehen, ob sich Ihre Änderungen positiv auf die Qualität auswirken oder Sie bei der Problembehandlung beim Ändern des Verhaltens unterstützen.
Vergleichen der Ergebnisse pro Anforderung für alle Ausführungen
Wenn Sie Daten für jede einzelne Anforderung durchlaufen möchten, klicken Sie auf der Seite „Experiment“ auf die Registerkarte Auswertung. Eine Tabelle zeigt jede Frage im Auswertungssatz an. Verwenden Sie die Dropdownmenüs, um die anzuzeigenden Spalten auszuwählen.
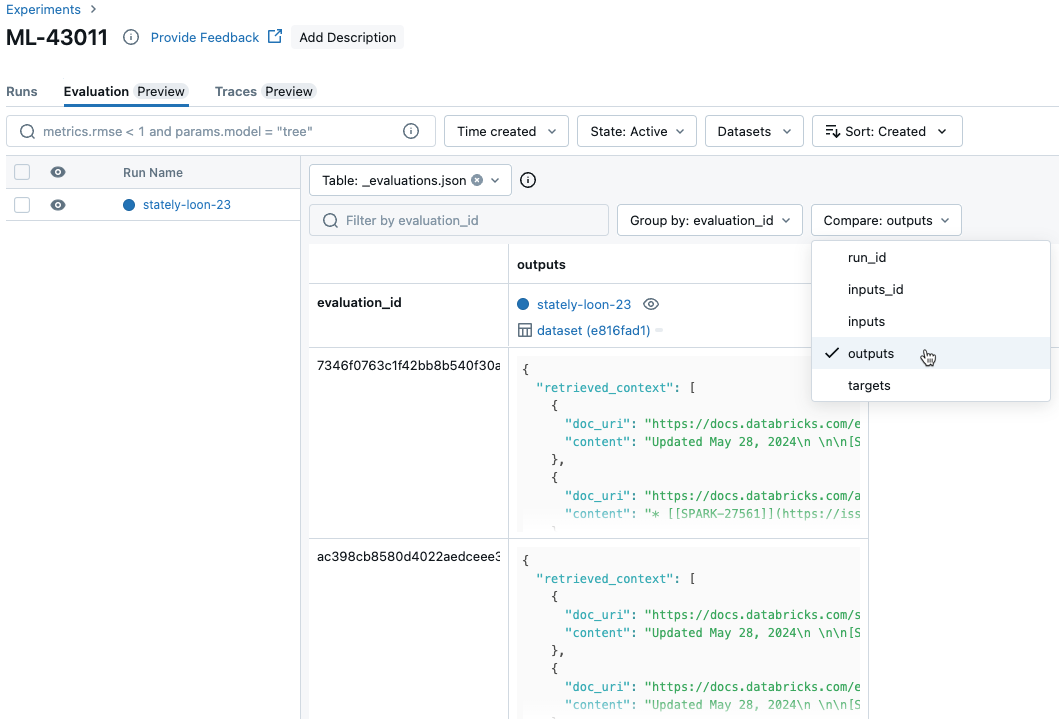
Vergleich aggregierter Ergebnisse für alle Ausgeführten
Sie können auf die gleichen aggregierten Ergebnisse auf der Seite "Experiment" zugreifen, sodass Sie auch Ergebnisse über verschiedene Läufe hinweg vergleichen können. Um auf die Experimentseite zuzugreifen, klicken Sie auf das Symbol „Experiment“ ![]() in der rechten Randleiste des Notebooks, oder klicken Sie auf die Links, die in den Zellenergebnissen für die Notebookzelle angezeigt werden, in der Sie
in der rechten Randleiste des Notebooks, oder klicken Sie auf die Links, die in den Zellenergebnissen für die Notebookzelle angezeigt werden, in der Sie mlflow.evaluate() ausgeführt haben.
Klicken Sie auf der Experiment-Seite auf ![]() . Auf diese Weise können Sie die aggregierten Ergebnisse für die ausgewählte Ausführung visualisieren und mit früheren Läufen vergleichen.
. Auf diese Weise können Sie die aggregierten Ergebnisse für die ausgewählte Ausführung visualisieren und mit früheren Läufen vergleichen.
Welche Richter laufen
Standardmäßig wendet Mosaik AI Agent Evaluation für jeden Auswertungseintrag die Teilmenge der Richter an, die am besten mit den informationen übereinstimmen, die im Datensatz vorhanden sind. Speziell:
- Wenn der Datensatz eine Ground-Truth-Antwort enthält, wendet die Agent-Auswertung die Richter
context_sufficiency,groundedness,correctness,safetyundguideline_adherencean. - Wenn der Datensatz keine Ground-Truth-Antwort enthält, wendet die Agent-Auswertung die Richter
chunk_relevance,groundedness,relevance_to_query,safetyundguideline_adherencean.
Weitere Informationen finden Sie unter:
- Ausführen einer Teilmenge der integrierten Richter
- Benutzerdefinierte KI-Richter
- Bewertung von Qualität, Kosten und Latenz durch Agentenbewertung
Informationen in Bezug auf die Vertrauensstellung und Sicherheit der LLM-Richter finden Sie unter Informationen zu den Modellen, auf denen die LLM-Richter basieren.
Beispiel: Übergeben einer Anwendung an die Agent-Auswertung
Verwenden Sie das mlflow_evaluate() Argument, um eine Anwendung an die Anwendung zu modelübergeben. Es gibt fünf Optionen zum Übergeben einer Anwendung im model Argument.
- Ein Modell, das im Unity-Katalog registriert ist.
- Ein protokolliertes MLflow-Modell im aktuellen MLflow-Experiment.
- Ein PyFunc-Modell, das im Notizbuch geladen wird.
- Eine lokale Funktion im Notizbuch.
- Ein bereitgestellter Agentendpunkt.
In den folgenden Abschnitten finden Sie Codebeispiele, die die einzelnen Optionen veranschaulichen.
Option 1. Modell registriert im Unity-Katalog
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "models:/catalog.schema.model_name/1" # 1 is the version number
model_type="databricks-agent",
)
Option 2. Protokolliertes MLflow-Modell im aktuellen MLflow-Experiment
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
# In the following lines, `6b69501828264f9s9a64eff825371711` is the run_id, and `chain` is the artifact_path that was
# passed with mlflow.xxx.log_model(...).
# If you called model_info = mlflow.langchain.log_model() or mlflow.pyfunc.log_model(), you can access this value using `model_info.model_uri`.
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "runs:/6b69501828264f9s9a64eff825371711/chain"
model_type="databricks-agent",
)
Option 3. PyFunc-Modell, das im Notizbuch geladen wird
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = mlflow.pyfunc.load_model(...)
model_type="databricks-agent",
)
Option 4. Lokale Funktion im Notizbuch
Die Funktion empfängt eine wie folgt formatierte Eingabe:
{
"messages": [
{
"role": "user",
"content": "What is MLflow?",
}
],
...
}
Die Funktion muss einen Wert in einem der folgenden drei unterstützten Formate zurückgeben:
Einfache Zeichenfolge, die die Antwort des Modells enthält.
Ein Wörterbuch im
ChatCompletionResponseFormat. Zum Beispiel:{ "choices": [ { "message": { "role": "assistant", "content": "MLflow is a machine learning toolkit.", }, ... } ], ..., }Ein Wörterbuch im
StringResponseFormat, z{ "content": "MLflow is a machine learning toolkit.", ... }. B. .
Im folgenden Beispiel wird eine lokale Funktion verwendet, um einen Foundation-Modellendpunkt umzuschließen und auszuwerten:
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
def model(model_input):
client = mlflow.deployments.get_deploy_client("databricks")
return client.predict(endpoint="endpoints:/databricks-meta-llama-3-1-405b-instruct", inputs={"messages": model_input["messages"]})
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = model
model_type="databricks-agent",
)
Option 5. Bereitgestellter Agentendpunkt
Diese Option funktioniert nur, wenn Sie Agentendpunkte verwenden, die mit databricks.agents.deploy und mit databricks-agents sdk-Version 0.8.0 oder höher bereitgestellt wurden. Verwenden Sie für Foundation-Modelle oder ältere SDK-Versionen Option 4, um das Modell in eine lokale Funktion umzuschließen.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
# In the following lines, `endpoint-name-of-your-agent` is the name of the agent endpoint.
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "endpoints:/endpoint-name-of-your-agent"
model_type="databricks-agent",
)
So übergeben Sie den Auswertungssatz, wenn die Anwendung im mlflow_evaluate() Aufruf enthalten ist
Im folgenden Code data ist ein Pandas DataFrame mit Ihrem Auswertungssatz. Dies sind einfache Beispiele. Ausführliche Informationen finden Sie im Eingabeschema .
# You do not have to start from a dictionary - you can use any existing pandas or Spark DataFrame with this schema.
# Minimal evaluation set
bare_minimum_eval_set_schema = [
{
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
}]
# Complete evaluation set
complete_eval_set_schema = [
{
"request_id": "your-request-id",
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"expected_retrieved_context": [
{
# In `expected_retrieved_context`, `content` is optional, and does not provide any additional functionality.
"content": "Answer segment 1 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_1",
},
{
"content": "Answer segment 2 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_2",
},
],
"expected_response": "There's no significant difference.",
}]
# Convert dictionary to a pandas DataFrame
eval_set_df = pd.DataFrame(bare_minimum_eval_set_schema)
# Use a Spark DataFrame
import numpy as np
spark_df = spark.table("catalog.schema.table") # or any other way to get a Spark DataFrame
eval_set_df = spark_df.toPandas()
Beispiel: Übergeben zuvor generierter Ausgaben an die Agent-Auswertung
In diesem Abschnitt wird beschrieben, wie zuvor generierte Ausgaben im mlflow_evaluate() Aufruf übergeben werden. Informationen zum erforderlichen Bewertungssatzschema finden Sie unter Agent Evaluation Input Schema.
Im folgenden Code data ist ein Pandas DataFrame mit Ihrem Auswertungssatz und ihren Ausgaben, die von der Anwendung generiert werden. Dies sind einfache Beispiele. Ausführliche Informationen finden Sie im Eingabeschema .
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_with_app_outputs_df, # pandas DataFrame with the evaluation set and application outputs
model_type="databricks-agent",
)
# You do not have to start from a dictionary - you can use any existing pandas or Spark DataFrame with this schema.
# Minimum required input
bare_minimum_input_schema = [
{
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"response": "reduceByKey aggregates data before shuffling, whereas groupByKey shuffles all data, making reduceByKey more efficient.",
}]
# Input including optional arguments
complete_input_schema = [
{
"request_id": "your-request-id",
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"expected_retrieved_context": [
{
# In `expected_retrieved_context`, `content` is optional, and does not provide any additional functionality.
"content": "Answer segment 1 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_1",
},
{
"content": "Answer segment 2 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_2",
},
],
"expected_response": "There's no significant difference.",
"response": "reduceByKey aggregates data before shuffling, whereas groupByKey shuffles all data, making reduceByKey more efficient.",
"retrieved_context": [
{
# In `retrieved_context`, `content` is optional. If provided, the Databricks Context Relevance LLM Judge is executed to check the `content`'s relevance to the `request`.
"content": "reduceByKey reduces the amount of data shuffled by merging values before shuffling.",
"doc_uri": "doc_uri_2_1",
},
{
"content": "groupByKey may lead to inefficient data shuffling due to sending all values across the network.",
"doc_uri": "doc_uri_6_extra",
},
],
"guidelines": [
"The response must be in English",
]
}]
# Convert dictionary to a pandas DataFrame
eval_set_with_app_outputs_df = pd.DataFrame(bare_minimum_input_schema)
# Use a Spark DataFrame
import numpy as np
spark_df = spark.table("catalog.schema.table") # or any other way to get a Spark DataFrame
eval_set_with_app_outputs_df = spark_df.toPandas()
Beispiel: Verwenden einer benutzerdefinierten Funktion zum Verarbeiten von Antworten von LangGraph
LangGraph-Agents, insbesondere diejenigen mit Chatfunktionen, können mehrere Nachrichten für einen einzelnen Rückschlussanruf zurückgeben. Es liegt in der Verantwortung des Benutzers, die Antwort des Agents in ein Format zu konvertieren, das die Agentauswertung unterstützt.
Ein Ansatz besteht darin, eine benutzerdefinierte Funktion zum Verarbeiten der Antwort zu verwenden. Das folgende Beispiel zeigt eine benutzerdefinierte Funktion, die die letzte Chatnachricht aus einem LangGraph-Modell extrahiert. Diese Funktion wird dann verwendet mlflow.evaluate() , um eine einzelne Zeichenfolgenantwort zurückzugeben, die mit der ground_truth Spalte verglichen werden kann.
Der Beispielcode nimmt die folgenden Annahmen vor:
- Das Modell akzeptiert Eingaben im Format {"messages": [{"role": "user", "content": "hello"}]}.The model accepts input in the format {"messages": [{"role": "user", "content": "hello"}]}.
- Das Modell gibt eine Liste von Zeichenfolgen im Format ["response 1", "response 2" zurück.
Der folgende Code sendet die verketteten Antworten in diesem Format an den Richter: "Antwort 1nresponse2"
import mlflow
import pandas as pd
from typing import List
loaded_model = mlflow.langchain.load_model(model_uri)
eval_data = pd.DataFrame(
{
"inputs": [
"What is MLflow?",
"What is Spark?",
],
"expected_response": [
"MLflow is an open-source platform for managing the end-to-end machine learning (ML) lifecycle. It was developed by Databricks, a company that specializes in big data and machine learning solutions. MLflow is designed to address the challenges that data scientists and machine learning engineers face when developing, training, and deploying machine learning models.",
"Apache Spark is an open-source, distributed computing system designed for big data processing and analytics. It was developed in response to limitations of the Hadoop MapReduce computing model, offering improvements in speed and ease of use. Spark provides libraries for various tasks such as data ingestion, processing, and analysis through its components like Spark SQL for structured data, Spark Streaming for real-time data processing, and MLlib for machine learning tasks",
],
}
)
def custom_langgraph_wrapper(model_input):
predictions = loaded_model.invoke({"messages": model_input["messages"]})
# Assuming `predictions` is a list of strings
return predictions.join("\n")
with mlflow.start_run() as run:
results = mlflow.evaluate(
custom_langgraph_wrapper, # Pass the function defined above
data=eval_data,
model_type="databricks-agent",
)
print(results.metrics)
Erstellen eines Dashboards mit Metriken
Wenn Sie die Qualität Ihres Agents durchlaufen, möchten Sie möglicherweise ein Dashboard für Ihre Projektbeteiligten freigeben, die zeigen, wie sich die Qualität im Laufe der Zeit verbessert hat. Sie können die Metriken aus ihrer MLflow-Auswertung extrahieren, die Werte in einer Delta-Tabelle speichern und ein Dashboard erstellen.
Das folgende Beispiel zeigt, wie Die Metrikwerte aus der letzten Auswertungsausführung in Ihrem Notizbuch extrahiert und gespeichert werden:
uc_catalog_name = "catalog"
uc_schema_name = "schema"
table_name = "results"
eval_results = mlflow.evaluate(
model=logged_agent_info.model_uri, # use the logged Agent
data=evaluation_set, # Run the logged Agent for all queries defined above
model_type="databricks-agent", # use Agent Evaluation
)
# The `append_metrics_to_table function` is defined below
append_metrics_to_table("<identifier-for-table>", eval_results.metrics, f"{uc_catalog_name}.{uc_schema_name}.{table_name}")
Das folgende Beispiel zeigt, wie Metrikwerte für vergangene Ausführungen extrahiert und gespeichert werden, die Sie im MLflow-Experiment gespeichert haben.
import pandas as pd
def get_mlflow_run(experiment_name, run_name):
runs = mlflow.search_runs(experiment_names=[experiment_name], filter_string=f"run_name = '{run_name}'", output_format="list")
if len(runs) != 1:
raise ValueError(f"Found {len(runs)} runs with name {run_name}. {run_name} must identify a single run. Alternatively, you can adjust this code to search for a run based on `run_id`")
return runs[0]
run = get_mlflow_run(experiment_name ="/Users/<user_name>/db_docs_mlflow_experiment", run_name="evaluation__2024-10-09_02:27:17_AM")
# The `append_metrics_to_table` function is defined below
append_metrics_to_table("<identifier-for-table>", run.data.metrics, f"{uc_catalog_name}.{uc_schema_name}.{table_name}")
Sie können jetzt ein Dashboard mit diesen Daten erstellen.
Der folgende Code definiert die Funktion append_metrics_to_table , die in den vorherigen Beispielen verwendet wird.
# Definition of `append_metrics_to_table`
def append_metrics_to_table(run_name, mlflow_metrics, delta_table_name):
data = mlflow_metrics.copy()
# Add identifying run_name and timestamp
data["run_name"] = run_name
data["timestamp"] = pd.Timestamp.now()
# Remove metrics with error counts
data = {k: v for k, v in mlflow_metrics.items() if "error_count" not in k}
# Convert to a Spark DataFrame(
metrics_df = pd.DataFrame([data])
metrics_df_spark = spark.createDataFrame(metrics_df)
# Append to the Delta table
metrics_df_spark.write.mode("append").saveAsTable(delta_table_name)
Informationen zu den Modellen, die die LLM-Richter unterstützen
- LLM-Richter verwenden möglicherweise Dienste von Drittanbietern, um Ihre GenAI-Anwendungen zu bewerten, einschließlich Azure OpenAI, betrieben von Microsoft.
- Für Azure OpenAI ist in Databricks die Missbrauchsüberwachung deaktiviert, sodass keine Prompts oder Antworten in Azure OpenAI gespeichert werden.
- Für Arbeitsbereiche der Europäischen Union (EU) verwenden LLM-Richter Modelle, die in der EU gehostet werden. Alle anderen Regionen verwenden Modelle, die in den USA gehostet werden.
- Durch die Deaktivierung von Azure KI-gesteuerten KI-Hilfsfeatures wird der LLM-Richter daran gehindert, Azure KI-gesteuerte Modelle aufzurufen.
- Daten, die an den LLM-Richter gesendet werden, werden nicht für eine Modellschulung verwendet.
- LLM-Richter sollen Kunden helfen, ihre RAG-Anwendungen zu bewerten, und LLM-Beurteilungsergebnisse sollten nicht verwendet werden, um eine LLM zu trainieren, zu verbessern oder zu optimieren.