Referenz zu Databricks Connect
Hinweis
Dieser Artikel behandelt Databricks Connect für Databricks Runtime 13.0 und höher.
Informationen zum schnellen Einstieg in Databricks Connect für die Databricks Runtime 13.0 und höher finden Sie unter Databricks Connect.
Weitere Informationen zu Databricks Connect für frühere Databricks Runtime-Versionen finden Sie unter Databricks Connect für Databricks Runtime 12.2 LTS und früher.
Mit Databricks Connect können Sie beliebte IDEs wie Visual Studio Code und PyCharm, Notebookserver und andere benutzerdefinierte Anwendungen mit Azure Databricks-Clustern verbinden.
Dieser Artikel erläutert die Funktionsweise von Databricks Connect, führt Sie durch die ersten Schritte mit Databricks Connect und erläutert, wie Sie Probleme beheben, die bei der Verwendung von Databricks Connect auftreten können.
Übersicht
Databricks Connect ist eine Clientbibliothek für die Databricks Runtime. Damit können Sie Aufträge mithilfe von Spark-APIs schreiben und remote in einem Azure Databricks-Cluster statt in der lokalen Spark-Sitzung ausführen.
Wenn Sie beispielsweise den DataFrame-Befehl spark.read.format(...).load(...).groupBy(...).agg(...).show() mit Databricks Connect ausführen, wird die logische Darstellung des Befehls an den in Azure Databricks ausgeführten Spark-Server gesendet, um im Remotecluster ausgeführt zu werden.
Mit Databricks Connect haben Sie folgende Möglichkeiten:
Führen Sie umfangreiche Spark-Aufträge aus einer beliebigen Python-Anwendung aus. Überall dort, wo Sie
import pysparkverwenden können, können Sie Spark-Aufträge jetzt direkt über Ihre Anwendung ausführen, ohne IDE-Plug-Ins installieren oder Spark-Übermittlungsskripts verwenden zu müssen.Hinweis
Databricks Connect für Databricks Runtime 13.0 und höher unterstützt derzeit nur die Ausführung von Python-Anwendungen.
Beim Arbeiten in einem Remotecluster können Sie Code in Ihrer IDE schrittweise durchlaufen und debuggen.
Sie können bei der Entwicklung von Bibliotheken schnell iterieren. Sie müssen den Cluster nicht neu starten, nachdem Sie die Abhängigkeiten der Python-Bibliothek in Databricks Connect geändert haben, da jede Clientsitzung im Cluster von den anderen isoliert ist.
Sie können Cluster im Leerlauf ohne Verlust bereits abgeschlossener Arbeitsschritte herunterfahren. Da die Clientanwendung vom Cluster entkoppelt ist, ist sie von Clusterneustarts oder -upgrades nicht betroffen, was normalerweise dazu führen würde, dass alle in einem Notebook definierten Variablen, RDDs und Datenrahmenobjekte verloren gehen.
Für Databricks Runtime 13.0 und höher basiert Databricks Connect jetzt auf Open-Source-Spark Connect. Spark Connect führt eine entkoppelte Client/Server-Architektur für Apache Spark ein, die Remotekonnektivität mit Spark-Clustern über die DataFrame-API und nicht aufgelöste logische Pläne als Protokoll ermöglicht. Mit dieser auf Spark Connect basierenden „V2“-Architektur wird Databricks Connect zu einem schlanken Client, der einfach und leicht zu bedienen ist. Spark Connect kann überall eingebettet werden, um eine Verbindung mit Azure Databricks herzustellen: in IDEs, Notebooks und Anwendungen, sodass einzelne Benutzer wie auch Partner neue (interaktive) Benutzererfahrungen basierend auf Databricks Lakehouse erstellen können. Weitere Informationen zu Spark Connect finden Sie unter Einführung in Spark Connect.
Databricks Connect bestimmt, wo Ihr Code ausgeführt und debuggt wird, wie in der folgenden Abbildung dargestellt.
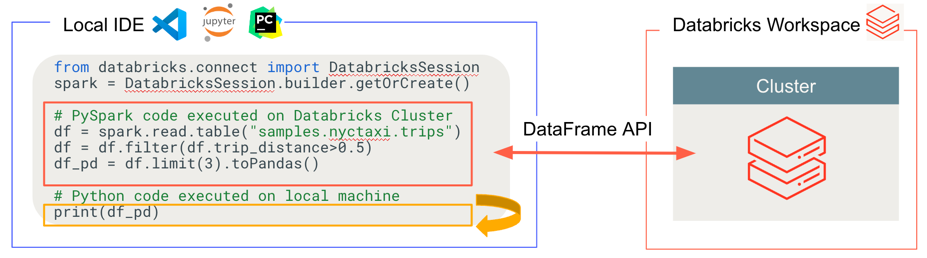
- Für die Ausführung von Code: Der gesamte Python-Code wird lokal ausgeführt, während der gesamte PySpark-Code, einschließlich DataFrame-Vorgängen, im Cluster im Azure Databricks-Remotearbeitsbereich ausgeführt wird. Die Ausführungsantworten werden an den lokalen Aufrufer zurückgesendet.
- Zum Debuggen von Code: Der gesamte Python-Code wird lokal debuggt, während der gesamte PySpark-Code weiterhin im Cluster im Azure Databricks-Remotearbeitsbereich ausgeführt wird. Der Kerncode der Spark-Engine kann nicht direkt vom Client aus debuggt werden.
Anforderungen
In diesem Abschnitt werden die Anforderungen für Databricks Connect aufgelistet.
Ein Azure Databricks-Arbeitsbereich und sein entsprechendes Konto, die für Unity Catalog aktiviert sind. Weitere Informationen finden Sie unter Erste Schritte mit Unity Catalog und Aktivieren eines Arbeitsbereichs für Unity Catalog.
Ein Cluster mit installierter Databricks Runtime 13.0 oder höher.
Es werden nur Cluster unterstützt, die mit Unity Catalog kompatibel sind. Dazu gehören Cluster mit zugewiesenen oder freigegebenen Zugriffsmodi. Weitere Informationen finden Sie unter Zugriffsmodi.
Sie müssen Python 3 auf Ihrem Entwicklungscomputer installieren, und die Nebenversion Ihrer Python-Clientinstallation muss mit der Python-Nebenversion Ihres Azure Databricks-Clusters identisch sein. In der folgenden Tabelle sind die mit der jeweiligen Databricks Runtime-Version installierten Python-Versionen aufgeführt.
Databricks Runtime-Version Python-Version 13.2 ML, 13.2 3.10 13.1 ML, 13.1 3.10 13.0 ML, 13.0 3.10 Hinweis
Wenn Sie PySpark-UDFs verwenden möchten, ist es wichtig, dass die installierte Nebenversion Ihres Entwicklungscomputers mit der Nebenversion von Python übereinstimmt, die mit der im Cluster installierten Databricks Runtime enthalten ist.
Databricks empfiehlt dringend, eine virtuelle Python-Umgebung für jede Python-Version zu aktivieren, die Sie mit Databricks Connect verwenden. Mithilfe virtueller Python-Umgebungen kann sichergestellt werden, dass Sie die richtigen Versionen von Python und Databricks Connect zusammen verwenden. Dies kann dazu beitragen, damit verbundene technische Probleme zu reduzieren oder die Zeit zum Beheben dieser Probleme zu verkürzen.
Wenn Sie beispielsweise venv (virtual environment, virtuelle Umgebung) auf Ihrem Entwicklungscomputer verwenden und ihr Cluster Python 3.10 ausführt, müssen Sie eine
venv-Umgebung mit dieser Version erstellen. Der folgende Beispielbefehl generiert die Skripts, um einevenv-Umgebung mit Python 3.10 zu aktivieren, und dieser Befehl platziert diese Skripts dann in einem ausgeblendeten Ordner mit Namen.venvinnerhalb des aktuellen Arbeitsverzeichnisses:# Linux and macOS python3.10 -m venv ./.venv # Windows python3.10 -m venv .\.venvUm diese Skripts zu verwenden, um diese
venv-Umgebung zu aktivieren, lesen Sie Funktionsweise von venvs (virtual environments, virtuelle Umgebungen).Die Databricks Connect-Haupt- und Nebenpaketversion sollte mit Ihrer Databricks Runtime-Version übereinstimmen. Databricks empfiehlt, dass Sie immer das neueste Paket von Databricks Connect verwenden, die mit Ihrer Databricks Runtime-Version übereinstimmt. Beispiel: Wenn Sie einen Databricks Runtime 13.1-Cluster verwenden, sollten Sie auch das
databricks-connect==13.1.*-Paket verwenden.Hinweis
Eine Liste mit verfügbaren Databricks Connect-Releases und Wartungsupdates finden Sie in den Versionshinweisen zu Databricks Connect.
Die Verwendung des neuesten Databricks Connect-Pakets, das Ihrer Databricks Runtime-Version entspricht, ist keine Anforderung. Ab Databricks Runtime 13.0 können Sie das Databricks Connect-Paket für alle Versionen von Databricks Runtime unter oder über der Version des Databricks Connect-Pakets verwenden. Wenn Sie jedoch Features verwenden möchten, die in späteren Versionen der Databricks Runtime verfügbar sind, müssen Sie das Databricks Connect-Paket entsprechend aktualisieren.
Einrichten des Clients
Führen Sie die folgenden Schritte aus, um den lokalen Client für Databricks Connect einzurichten.
Hinweis
Bevor Sie beginnen, den lokalen Databricks Connect-Client einzurichten, müssen Sie die Databricks Connect-Anforderungen erfüllen.
Tipp
Wenn Sie bereits die Databricks-Erweiterung für Visual Studio Code installiert haben, müssen Sie diese Setupanweisungen nicht befolgen.
Die Databricks-Erweiterung für Visual Studio Code verfügt bereits über integrierten Support für Databricks Connect für Databricks Runtime 13.0 und höher. Fahren Sie mit Ausführen oder Debuggen von Python-Code mit Databricks Connect in der Dokumentation für die Databricks-Erweiterung für Visual Studio Code fort.
Schritt 1: Installieren des Databricks Connect-Clients
Wenn Ihre virtuelle Umgebung aktiviert ist, deinstallieren Sie PySpark, falls es bereits installiert ist, indem Sie den
uninstall-Befehl ausführen. Dieser Schritt ist erforderlich, da dasdatabricks-connect-Paket mit PySpark in Konflikt steht. Weitere Informationen finden Sie unter In Konflikt stehende PySpark-Installationen. Um zu überprüfen, ob PySpark bereits installiert ist, führen Sie denshow-Befehl aus.# Is PySpark already installed? pip3 show pyspark # Uninstall PySpark pip3 uninstall pysparkWenn Ihre virtuelle Umgebung immer noch aktiviert ist, installieren Sie den Databricks Connect-Client, indem Sie den
install-Befehl ausführen. Verwenden Sie die--upgrade-Option, um für alle vorhandenen Clientinstallationen ein Upgrade auf die angegebene Version durchzuführen.pip3 install --upgrade "databricks-connect==13.1.*" # Or X.Y.* to match your cluster version.Hinweis
Databricks empfiehlt, die Notation „Punkt-Sternchen“ anzufügen, um
databricks-connect==X.Y.*anstelle vondatabricks-connect=X.Yanzugeben, um sicherzustellen, dass das neueste Paket installiert ist. Dies ist zwar keine Anforderung, aber es hilft sicherzustellen, dass Sie die aktuellen unterstützten Features für diesen Cluster verwenden können.
Schritt 2: Konfigurieren von Verbindungseigenschaften
In diesem Abschnitt konfigurieren Sie Eigenschaften, um eine Verbindung zwischen Databricks Connect und Ihrem Azure Databricks-Remotecluster herzustellen. Diese Eigenschaften umfassen Einstellungen zum Authentifizieren von Databricks Connect bei Ihrem Cluster.
Ab Databricks Connect für Databricks Runtime 13.1 und höher umfasst Databricks Connect das Databricks SDK für Python. Dieses SDK implementiert den Standard für die einheitliche Databricks-Clientauthentifizierung, einen konsolidierten und konsistenten architektonischen und programmgesteuerten Ansatz für die Authentifizierung. Dieser Ansatz gestaltet die Einrichtung und Automatisierung der Authentifizierung mit Azure Databricks zentralisierter und vorhersagbarer. Er ermöglicht Ihnen, die Azure Databricks-Authentifizierung einmal zu konfigurieren und diese Konfiguration dann für mehrere Azure Databricks-Tools und -SDKs ohne weitere Änderungen an der Authentifizierungskonfiguration zu verwenden.
Hinweis
Das Databricks SDK für Python hat noch keine Azure MSI-Authentifizierung implementiert.
Databricks Connect für Databricks Runtime 13.0 unterstützt nur die Authentifizierung mit persönlichem Zugriffstoken in Azure Databricks.
Sammeln Sie die folgenden Konfigurationseigenschaften.
- Den Instanzennamen des Arbeitsbereichs von Azure Databricks. Dies entspricht dem Wert des Serverhostnamens für Ihren Cluster, lesen Sie Abrufen von Verbindungsdetails für einen Cluster.
- Die ID Ihres Clusters. Sie können die Cluster-ID über die URL abrufen. Weitere Informationen finden Sie unter Cluster-URL und -ID.
- Alle anderen Eigenschaften, die für den Databricks-Authentifizierungstyp erforderlich sind, den Sie verwenden möchten, wie im Folgenden gezeigt
Konfigurieren Sie die Verbindung innerhalb Ihres Codes. Databricks Connect sucht nach Konfigurationseigenschaften in der folgenden Reihenfolge, bis diese gefunden werden. Sobald sie gefunden werden, wird die Suche nach den verbleibenden Optionen beendet:
Direkte Konfiguration der Verbindungseigenschaften, die über die
DatabricksSession-Klasse angegeben werden (nur für die Authentifizierung mit persönlichem Zugriffstoken in Azure Databricks)Geben Sie für diese Option, die nur für die Authentifizierung mit persönlichem Zugriffstoken in Azure Databricks gilt, den Instanzname des Arbeitsbereichs, das persönliche Zugriffstoken in Azure Databricks und die ID des Clusters an.
Die folgenden Codebeispiele veranschaulichen, wie die
DatabricksSession-Klasse für die Authentifizierung mit persönlichem Zugriffstoken in Azure Databricks initialisiert wird.Databricks empfiehlt nicht, diese Verbindungseigenschaften direkt in Ihrem Code anzugeben. Stattdessen empfiehlt Databricks, Eigenschaften über Umgebungsvariablen oder Konfigurationsdateien zu konfigurieren, wie in späteren Optionen beschrieben. In den folgenden Codebeispielen wird davon ausgegangen, dass Sie selbst eine Implementierung der vorgeschlagenen
retrieve_*-Funktionen bereitstellen, um die erforderlichen Eigenschaften vom Benutzer oder aus einem anderen Konfigurationsspeicher abzurufen, z. B. dem Azure KeyVault.# By setting fields in builder.remote: from databricks.connect import DatabricksSession spark = DatabricksSession.builder.remote( host = f"https://{retrieve_workspace_instance_name()}", token = retrieve_token(), cluster_id = retrieve_cluster_id() ).getOrCreate() # Or, by using the Databricks SDK's Config class: from databricks.connect import DatabricksSession from databricks.sdk.core import Config config = Config( host = f"https://{retrieve_workspace_instance_name()}", token = retrieve_token(), cluster_id = retrieve_cluster_id() ) spark = DatabricksSession.builder.sdkConfig(config).getOrCreate() # Or, specify a Databricks configuration profile and # the cluster_id field separately: from databricks.connect import DatabricksSession from databricks.sdk.core import Config config = Config( profile = "<profile-name>", cluster_id = retrieve_cluster_id() ) spark = DatabricksSession.builder.sdkConfig(config).getOrCreate() # Or, by setting the Spark Connect connection string in builder.remote: from databricks.connect import DatabricksSession workspace_instance_name = retrieve_workspace_instance_name() token = retrieve_token() cluster_id = retrieve_cluster_id() spark = DatabricksSession.builder.remote( f"sc://{workspace_instance_name}:443/;token={token};x-databricks-cluster-id={cluster_id}" ).getOrCreate()Ein Azure Databricks-Konfigurationsprofilname für alle Azure Databricks-Authentifizierungstypen, der über
profile()angegeben wirdErstellen oder identifizieren Sie für diese Option ein Azure Databricks-Konfigurationsprofil mit dem Feld
cluster_idund allen anderen Felder, die für den Databricks-Authentifizierungstyp erforderlich sind, den Sie verwenden möchten.Die folgenden Konfigurationsprofilfelder sind für die einzelnen Authentifizierungstypen erforderlich:
- Für die Authentifizieren mit persönlichen Azure Databricks-Zugriffstoken:
hostundtoken - Für die OAuth U2M-Authentifizierung (User-to-Machine):
host,azure_tenant_id,azure_client_idundazure_client_secret - Für die Authentifizierung mit Azure-Dienstprinzipal:
host,azure_tenant_id,azure_client_id,azure_client_secretund eventuellazure_workspace_resource_id - Für die Azure CLI-Authentifizierung:
host
Legen Sie dann den Namen dieses Konfigurationsprofils über die
Config-Klasse fest.Alternativ können Sie
cluster_idauch getrennt vom Konfigurationsprofil angeben. Anstatt die Cluster-ID direkt in Ihrem Code anzugeben, wird in den folgenden Codebeispielen davon ausgegangen, dass Sie selbst eine Implementierung der vorgeschlagenenretrieve_cluster_id-Funktion bereitstellen, um die Cluster-ID vom Benutzer oder aus einem anderen Konfigurationsspeicher abzurufen, z. B. dem Azure KeyVault.Beispiele:
# Specify a Databricks configuration profile that contains the # cluster_id field: from databricks.connect import DatabricksSession spark = DatabricksSession.builder.profile("<profile-name>").getOrCreate()- Für die Authentifizieren mit persönlichen Azure Databricks-Zugriffstoken:
Die
SPARK_REMOTE-Umgebungsvariable (nur für die Authentifizierung mit persönlichem Zugriffstoken in Azure Databricks)Legen Sie für diese Option, die nur für die Authentifizierung mit persönlichem Zugriffstoken in Azure Databricks gilt, die
SPARK_REMOTE-Umgebungsvariable auf die folgende Zeichenfolge fest, und ersetzen Sie die Platzhalter durch die entsprechenden Werte.sc://<workspace-instance-name>:443/;token=<access-token-value>;x-databricks-cluster-id=<cluster-id>Initialisieren Sie dann die
DatabricksSession-Klasse wie folgt:from databricks.connect import DatabricksSession spark = DatabricksSession.builder.getOrCreate()Informationen zum Festlegen von Umgebungsvariablen finden Sie in der Dokumentation des Betriebssystems.
Die
DATABRICKS_CONFIG_PROFILE-Umgebungsvariable (für alle Azure Databricks-Authentifizierungstypen)Erstellen oder identifizieren Sie für diese Option ein Azure Databricks-Konfigurationsprofil mit dem Feld
cluster_idund allen anderen Felder, die für den Databricks-Authentifizierungstyp erforderlich sind, den Sie verwenden möchten.Die folgenden Konfigurationsprofilfelder sind für die einzelnen Authentifizierungstypen erforderlich:
- Für die Authentifizieren mit persönlichen Azure Databricks-Zugriffstoken:
hostundtoken - Für die OAuth U2M-Authentifizierung (User-to-Machine):
host,azure_tenant_id,azure_client_idundazure_client_secret - Für die Authentifizierung mit Azure-Dienstprinzipal:
host,azure_tenant_id,azure_client_id,azure_client_secretund eventuellazure_workspace_resource_id - Für die Azure CLI-Authentifizierung:
host
Legen Sie die
DATABRICKS_CONFIG_PROFILE-Umgebungsvariable auf den Namen dieses Konfigurationsprofils fest. Initialisieren Sie dann dieDatabricksSession-Klasse wie folgt:from databricks.connect import DatabricksSession spark = DatabricksSession.builder.getOrCreate()Informationen zum Festlegen von Umgebungsvariablen finden Sie in der Dokumentation des Betriebssystems.
- Für die Authentifizieren mit persönlichen Azure Databricks-Zugriffstoken:
Eine Umgebungsvariable für jede Verbindungseigenschaft (für alle Azure Databricks-Authentifizierungstypen)
Legen Sie für diese Option die
DATABRICKS_CLUSTER_ID-Umgebungsvariable und alle anderen Umgebungsvariablen fest, die für den Databricks-Authentifizierungstyp erforderlich sind, den Sie verwenden möchten.Die folgenden Umgebungsvariablen sind für die einzelnen Authentifizierungstypen erforderlich:
- Für die Authentifizieren mit persönlichen Azure Databricks-Zugriffstoken:
DATABRICKS_HOSTundDATABRICKS_TOKEN - Für die OAuth U2M-Authentifizierung (User-to-Machine):
DATABRICKS_HOST,ARM_TENANT_ID,ARM_CLIENT_IDundARM_CLIENT_SECRET - Für die Authentifizierung mit Azure-Dienstprinzipal:
DATABRICKS_HOST,ARM_TENANT_ID,ARM_CLIENT_ID,ARM_CLIENT_SECRETund eventuellDATABRICKS_AZURE_RESOURCE_ID - Für die Azure CLI-Authentifizierung:
DATABRICKS_HOST
Initialisieren Sie dann die
DatabricksSession-Klasse wie folgt:from databricks.connect import DatabricksSession spark = DatabricksSession.builder.getOrCreate()Informationen zum Festlegen von Umgebungsvariablen finden Sie in der Dokumentation des Betriebssystems.
- Für die Authentifizieren mit persönlichen Azure Databricks-Zugriffstoken:
Ein Azure Databricks-Konfigurationsprofilname mit dem Namen
DEFAULT(für alle Azure Databricks-Authentifizierungstypen)Erstellen oder identifizieren Sie für diese Option ein Azure Databricks-Konfigurationsprofil mit dem Feld
cluster_idund allen anderen Felder, die für den Databricks-Authentifizierungstyp erforderlich sind, den Sie verwenden möchten.Die folgenden Konfigurationsprofilfelder sind für die einzelnen Authentifizierungstypen erforderlich:
- Für die Authentifizieren mit persönlichen Azure Databricks-Zugriffstoken:
hostundtoken - Für die OAuth U2M-Authentifizierung (User-to-Machine):
host,azure_tenant_id,azure_client_idundazure_client_secret - Für die Authentifizierung mit Azure-Dienstprinzipal:
host,azure_tenant_id,azure_client_id,azure_client_secretund eventuellazure_workspace_resource_id - Für die Azure CLI-Authentifizierung:
host
Benennen Sie dieses Konfigurationsprofil
DEFAULT.Initialisieren Sie dann die
DatabricksSession-Klasse wie folgt:from databricks.connect import DatabricksSession spark = DatabricksSession.builder.getOrCreate()- Für die Authentifizieren mit persönlichen Azure Databricks-Zugriffstoken:
Wenn Sie die Authentifizierung mit persönlichem Zugriffstoken in Azure Databricks verwenden möchten, können Sie das enthaltene
pyspark-Hilfsprogramm verwenden, um die Konnektivität mit Ihrem Azure Databricks-Cluster wie folgt zu testen.Wenn Ihre virtuelle Umgebung immer noch aktiviert ist, führen Sie den folgenden Befehl aus:
Wenn Sie die
SPARK_REMOTE-Umgebungsvariable früher festgelegt haben, führen Sie den folgenden Befehl aus:pysparkWenn Sie die
SPARK_REMOTE-Umgebungsvariable früher nicht festgelegt haben, führen Sie stattdessen den folgenden Befehl aus:pyspark --remote "sc://<workspace-instance-name>:443/;token=<access-token-value>;x-databricks-cluster-id=<cluster-id>"Die Spark-Shell wird angezeigt, z. B.:
Python 3.10 ... [Clang ...] on darwin Type "help", "copyright", "credits" or "license" for more information. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 13.0 /_/ Using Python version 3.10 ... Client connected to the Spark Connect server at sc://...:.../;token=...;x-databricks-cluster-id=... SparkSession available as 'spark'. >>>Führen Sie an der
>>>-Eingabeaufforderung einen einfachen PySpark-Befehl aus, z. B.spark.range(1,10).show(). Wenn keine Fehler vorhanden sind, haben Sie erfolgreich eine Verbindung hergestellt.Wenn Sie die Verbindung erfolgreich hergestellt haben, drücken Sie
Ctrl + doderCtrl + z, oder führen Sie den Befehlquit()oderexit()aus, um die Spark-Shell zu beenden.
Verwenden von Databricks Connect
In diesen Abschnitten wird beschrieben, wie viele beliebte IDEs und Notebookserver für die Verwendung des Databricks Connect-Clients konfiguriert werden. Oder Sie können die integrierte Spark-Shell verwenden.
Inhalt dieses Abschnitts:
- JupyterLab mit Python
- Klassisches Jupyter Notebook mit Python
- Visual Studio Code mit Python
- PyCharm mit Python
- Eclipse mit PyDev
- Spark-Shell mit Python
JupyterLab mit Python
Hinweis
Bevor Sie beginnen, Databricks Connect zu verwenden, müssen Sie die Anforderungen erfüllen und den Client einrichten für Databricks Connect.
Um Databricks Connect V2 mit JupyterLab und Python zu verwenden, befolgen Sie diese Anweisungen.
Um JupyterLab zu installieren, führen Sie bei aktivierter virtueller Python-Umgebung den folgenden Befehl in Ihrem Terminal oder der Eingabeaufforderung aus:
pip3 install jupyterlabUm JupyterLab in Ihrem Webbrowser zu starten, führen Sie den folgenden Befehl in Ihrer aktivierten virtuellen Python-Umgebung aus:
jupyter labWenn JupyterLab nicht in Ihrem Webbrowser angezeigt wird, kopieren Sie die URL, die mit
localhostoder127.0.0.1beginnt, aus Ihrer virtuellen Umgebung, und geben Sie diese in die Adressleiste Ihres Webbrowsers ein.Erstellen eines neuen Notebooks: Klicken Sie in JupyterLab im Hauptmenü auf Datei > Neu > Notebook, wählen Sie Python 3 (ipykernel) aus, und klicken Sie auf Auswählen.
Geben Sie in der ersten Zelle des Notebooks entweder den Beispielcode oder Ihren eigenen Code ein. Wenn Sie eigenen Code verwenden, müssen Sie mindestens
DatabricksSessioninitialisieren, wie im Beispielcode gezeigt.Klicken Sie zum Ausführen des Notebooks auf Run > Run All Cells. Der gesamte Python-Code wird lokal ausgeführt, während der gesamte PySpark-Code, einschließlich DataFrame-Vorgängen, im Cluster im Azure Databricks-Remotearbeitsbereich ausgeführt wird. Die Ausführungsantworten werden an den lokalen Aufrufer zurückgesendet.
Klicken Sie zum Debuggen des Notebooks auf der Symbolleiste des Notebooks neben Python 3 (ipykernel) auf das Fehlersymbol (Enable Debugger). Legen Sie mindestens einen Breakpoint fest, und klicken Sie dann auf Run > Run All Cells. Der gesamte Python-Code wird lokal debuggt, während der gesamte PySpark-Code weiterhin im Cluster im Azure Databricks-Remotearbeitsbereich ausgeführt wird. Der Kerncode der Spark-Engine kann nicht direkt vom Client aus debuggt werden.
Klicken Sie zum Herunterfahren von JupyterLab auf File > Shut Down. Wenn der JupyterLab-Prozess weiterhin in Ihrem Terminal oder in der Eingabeaufforderung ausgeführt wird, beenden Sie diesen Prozess, indem Sie
Ctrl + cdrücken und dannyeingeben, um dies zu bestätigen.
Spezifischere Debuganweisungen finden Sie unter Debugger.
Klassisches Jupyter Notebook mit Python
Hinweis
Bevor Sie beginnen, Databricks Connect zu verwenden, müssen Sie die Anforderungen erfüllen und den Client einrichten für Databricks Connect.
Um Databricks Connect mit klassischem Jupyter Notebook und Python zu verwenden, befolgen Sie diese Anweisungen.
Um das klassische Jupyter Notebook zu installieren, führen Sie bei aktivierter virtueller Python-Umgebung den folgenden Befehl in Ihrem Terminal oder der Eingabeaufforderung aus:
pip3 install notebookUm das klassische Jupyter Notebook in Ihrem Webbrowser zu starten, führen Sie den folgenden Befehl in Ihrer aktivierten virtuellen Python-Umgebung aus:
jupyter notebookWenn das klassische Jupyter Notebook nicht in Ihrem Webbrowser angezeigt wird, kopieren Sie die URL, die mit
localhostoder127.0.0.1beginnt, aus Ihrer virtuellen Umgebung, und geben Sie diese in die Adressleiste Ihres Webbrowsers ein.Erstellen eines neuen Notizbuchs: Klicken Sie im klassischen Jupyter Notebook auf der Registerkarte Dateien auf Neu > Python 3 (ipykernel).
Geben Sie in der ersten Zelle des Notebooks entweder den Beispielcode oder Ihren eigenen Code ein. Wenn Sie eigenen Code verwenden, müssen Sie mindestens
DatabricksSessioninitialisieren, wie im Beispielcode gezeigt.Um das Notebook auszuführen, klicken Sie auf Zelle > Alle ausführen. Der gesamte Python-Code wird lokal ausgeführt, während der gesamte PySpark-Code, einschließlich DataFrame-Vorgängen, im Cluster im Azure Databricks-Remotearbeitsbereich ausgeführt wird. Die Ausführungsantworten werden an den lokalen Aufrufer zurückgesendet.
Fügen Sie zum Debuggen des Notebooks die folgende Codezeile am Anfang Ihres Notebooks hinzu:
from IPython.core.debugger import set_traceRufen Sie dann
set_trace()auf, um Debuggenanweisungen an diesem Punkt der Notebookausführung einzugeben. Der gesamte Python-Code wird lokal debuggt, während der gesamte PySpark-Code weiterhin im Cluster im Azure Databricks-Remotearbeitsbereich ausgeführt wird. Der Kerncode der Spark-Engine kann nicht direkt vom Client aus debuggt werden.Klicken Sie zum Herunterfahren des klassischen Jupyter Notebook auf Datei > Schließen und Anhalten. Wenn der klassische Jupyter Notebook-Prozess weiterhin in Ihrem Terminal oder in der Eingabeaufforderung ausgeführt wird, beenden Sie diesen Prozess, indem Sie
Ctrl + cdrücken und dannyeingeben, um dies zu bestätigen.
Visual Studio Code mit Python
Hinweis
Bevor Sie beginnen, Databricks Connect zu verwenden, müssen Sie die Anforderungen erfüllen und den Client einrichten für Databricks Connect.
Tipp
Die Databricks-Erweiterung für Visual Studio Code verfügt bereits über integrierten Support für Databricks Connect für Databricks Runtime 13.0 und höher. Lesen Sie Ausführen oder Debuggen von Python-Code mit Databricks Connect in der Dokumentation für die Databricks-Erweiterung für Visual Studio Code.
Um Databricks Connect mit Visual Studio Code und Python zu verwenden, befolgen Sie diese Anweisungen.
Starten Sie Visual Studio Code.
Öffnen Sie den Ordner, der Ihre virtuelle Python-Umgebung enthält (Datei > Ordner öffnen).
Aktivieren Sie im Visual Studio Code-Terminal (Ansicht > Terminal) die virtuelle Umgebung.
Legen Sie den aktuellen Python-Interpreter auf den in der virtuellen Umgebung referenzierten Interpreter fest:
- Geben Sie in der Befehlspalette (Ansicht > Befehlspalette)
Python: Select Interpreterein, und drücken Sie dann die EINGABETASTE. - Wählen Sie den Pfad zum Python-Interpreter aus, der in der virtuellen Umgebung referenziert ist.
- Geben Sie in der Befehlspalette (Ansicht > Befehlspalette)
Fügen Sie dem Ordner eine Python-Codedatei (
.py) hinzu, die entweder den Beispielcode oder Ihren eigenen Code enthält. Wenn Sie eigenen Code verwenden, müssen Sie mindestensDatabricksSessioninitialisieren, wie im Beispielcode gezeigt.Wählen Sie zum Ausführen des Codes im Hauptmenü Ausführen > Ohne Debuggen ausführen aus. Der gesamte Python-Code wird lokal ausgeführt, während der gesamte PySpark-Code, einschließlich DataFrame-Vorgängen, im Cluster im Azure Databricks-Remotearbeitsbereich ausgeführt wird. Die Ausführungsantworten werden an den lokalen Aufrufer zurückgesendet.
So debuggen Sie den Code
- Legen Sie bei geöffneter Python-Codedatei alle Breakpoints fest, an denen der Code während der Ausführung angehalten werden soll.
- Klicken Sie auf der Seitenleiste auf das Symbol Ausführen und debuggen, oder klicken Sie im Hauptmenü auf Ansicht > Ausführen.
- Klicken Sie in der Ansicht Ausführen und Debuggen auf die Schaltfläche Ausführen und Debuggen.
- Befolgen Sie die Anweisungen auf dem Bildschirm, um mit der Ausführung und dem Debuggen des Codes zu beginnen.
Der gesamte Python-Code wird lokal debuggt, während der gesamte PySpark-Code weiterhin im Cluster im Azure Databricks-Remotearbeitsbereich ausgeführt wird. Der Kerncode der Spark-Engine kann nicht direkt vom Client aus debuggt werden.
Genauere Ausführungs- und Debuganweisungen finden Sie unter Konfigurieren und Ausführen des Debuggers und Python debugging in VS Code (Python-Debugging in VS Code).
PyCharm mit Python
Hinweis
Bevor Sie beginnen, Databricks Connect zu verwenden, müssen Sie die Anforderungen erfüllen und den Client einrichten für Databricks Connect.
IntelliJ IDEA Ultimate bietet auch Plug-In-Support für PyCharm mit Python. Details finden Sie unter Python-Plug-In für IntelliJ IDEA Ultimate.
Um Databricks Connect mit PyCharm und Python zu verwenden, befolgen Sie diese Anweisungen.
- Starten Sie PyCharm.
- Erstellen Sie ein Projekt: Klicken Sie auf File > New Project.
- Klicken Sie unter Speicherort auf das Ordnersymbol, und wählen Sie dann den Pfad zu Ihrer virtuellen Python-Umgebung aus.
- Wählen Sie Previously configured interpreter aus.
- Klicken Sie für Interpreter auf die Auslassungspunkte.
- Klicken Sie auf System Interpreter.
- Klicken Sie für Interpreter auf die Auslassungspunkte, und wählen Sie den vollständigen Pfad zum Python-Interpreter aus, der in der virtuellen Umgebung referenziert ist. Klicken Sie dann auf OK.
- Klicken Sie erneut auf OK .
- Klicken Sie auf Erstellen.
- Klicken Sie auf Create from Existing Sources.
- Fügen Sie dem Projekt eine Python-Codedatei (
.py) hinzu, die entweder den Beispielcode oder Ihren eigenen Code enthält. Wenn Sie eigenen Code verwenden, müssen Sie mindestensDatabricksSessioninitialisieren, wie im Beispielcode gezeigt. - Legen Sie bei geöffneter Python-Codedatei alle Breakpoints fest, an denen der Code während der Ausführung angehalten werden soll.
- Wählen Sie zum Ausführen des Codes Ausführen > Ausführen aus. Der gesamte Python-Code wird lokal ausgeführt, während der gesamte PySpark-Code, einschließlich DataFrame-Vorgängen, im Cluster im Azure Databricks-Remotearbeitsbereich ausgeführt wird. Die Ausführungsantworten werden an den lokalen Aufrufer zurückgesendet.
- Wählen Sie zum Debuggen des Codes Ausführen > Debuggen aus. Der gesamte Python-Code wird lokal debuggt, während der gesamte PySpark-Code weiterhin im Cluster im Azure Databricks-Remotearbeitsbereich ausgeführt wird. Der Kerncode der Spark-Engine kann nicht direkt vom Client aus debuggt werden.
- Befolgen Sie die Anweisungen auf dem Bildschirm, um mit der Ausführung oder dem Debuggen des Codes zu beginnen.
Spezifischere Ausführungs- und Debuganweisungen finden Sie unter Run without any previous configuring (Ausführen ohne vorherige Konfiguration) und Debug (Debuggen).
Eclipse mit PyDev
Hinweis
Bevor Sie beginnen, Databricks Connect zu verwenden, müssen Sie die Anforderungen erfüllen und den Client einrichten für Databricks Connect.
Um Databricks Connect und Eclipse mit PyDev zu verwenden, befolgen Sie diese Anweisungen.
- Starten Sie Eclipse.
- Erstellen eines Projekts: Klicken Sie auf Datei > Neu > Projekt > PyDev > PyDev-Projekt, und klicken Sie dann auf Weiter.
- Geben Sie einen Projektnamen an.
- Geben Sie für Project-Inhalte den Pfad zu Ihrer virtuellen Python-Umgebung an.
- Klicken Sie auf Bitte konfigurieren Sie einen Interpreter, bevor Sie fortfahren.
- Klicken Sie auf Manuelles konfigurieren.
- Klicken Sie Neu > Suche nach ausführbarer python/pypy-Datei.
- Browsen Sie zum vollständigen Pfad zum Python-Interpreter, der in der virtuellen Umgebung referenziert ist, wählen Sie diesen aus, und klicken Sie dann auf Öffnen.
- Klicken Sie im Dialogfeld Interpreter auswählen auf OK.
- Klicken Sie im Dialogfeld Auswahl erforderlich auf OK.
- Klicken Sie im Dialogfeld Einstellungen auf Übernehmen und Schließen.
- Klicken Sie im Dialogfeld PyDev-Projekt auf Fertig stellen.
- Klicken Sie auf Perspektive öffnen.
- Fügen Sie dem Projekt eine Python-Codedatei (
.py) hinzu, die entweder den Beispielcode oder Ihren eigenen Code enthält. Wenn Sie eigenen Code verwenden, müssen Sie mindestensDatabricksSessioninitialisieren, wie im Beispielcode gezeigt. - Legen Sie bei geöffneter Python-Codedatei alle Breakpoints fest, an denen der Code während der Ausführung angehalten werden soll.
- Wählen Sie zum Ausführen des Codes Ausführen > Ausführen aus. Der gesamte Python-Code wird lokal ausgeführt, während der gesamte PySpark-Code, einschließlich DataFrame-Vorgängen, im Cluster im Azure Databricks-Remotearbeitsbereich ausgeführt wird. Die Ausführungsantworten werden an den lokalen Aufrufer zurückgesendet.
- Wählen Sie zum Debuggen des Codes Ausführen > Debuggen aus. Der gesamte Python-Code wird lokal debuggt, während der gesamte PySpark-Code weiterhin im Cluster im Azure Databricks-Remotearbeitsbereich ausgeführt wird. Der Kerncode der Spark-Engine kann nicht direkt vom Client aus debuggt werden.
Genauere Anweisungen zum Ausführen und Debuggen finden Sie unter Ausführen eines Programms.
Spark-Shell mit Python
Hinweis
Bevor Sie beginnen, Databricks Connect zu verwenden, müssen Sie die Anforderungen erfüllen und den Client einrichten für Databricks Connect.
Die Spark-Shell funktioniert nur mit der Authentifizierung mit persönlichem Zugriffstoken in Azure Databricks.
Um Databricks Connect mit der Spark-Shell und Python zu verwenden, befolgen Sie diese Anweisungen.
Um die Spark-Shell zu starten und sie mit Ihrem laufenden Cluster zu verbinden, führen Sie einen der folgenden Befehle in Ihrer aktivierten virtuellen Python-Umgebung aus:
Wenn Sie die
SPARK_REMOTE-Umgebungsvariable früher festgelegt haben, führen Sie den folgenden Befehl aus:pysparkWenn Sie die
SPARK_REMOTE-Umgebungsvariable früher nicht festgelegt haben, führen Sie stattdessen den folgenden Befehl aus:pyspark --remote "sc://<workspace-instance-name>:443/;token=<access-token-value>;x-databricks-cluster-id=<cluster-id>"Die Spark-Shell wird angezeigt, z. B.:
Python 3.10 ... [Clang ...] on darwin Type "help", "copyright", "credits" or "license" for more information. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 13.x.dev0 /_/ Using Python version 3.10 ... Client connected to the Spark Connect server at sc://...:.../;token=...;x-databricks-cluster-id=... SparkSession available as 'spark'. >>>Informationen zur Verwendung der Spark-Shell mit Python zum Ausführen von Befehlen in Ihrem Cluster finden Sie unter Interactive Analysis with the Spark Shell (Interaktive Analyse mit der Spark-Shell).
Verwenden Sie die integrierte Variable
spark, umSparkSessionin Ihrem ausgeführten Cluster darzustellen, z. B.:>>> df = spark.read.table("samples.nyctaxi.trips") >>> df.show(5) +--------------------+---------------------+-------------+-----------+----------+-----------+ |tpep_pickup_datetime|tpep_dropoff_datetime|trip_distance|fare_amount|pickup_zip|dropoff_zip| +--------------------+---------------------+-------------+-----------+----------+-----------+ | 2016-02-14 16:52:13| 2016-02-14 17:16:04| 4.94| 19.0| 10282| 10171| | 2016-02-04 18:44:19| 2016-02-04 18:46:00| 0.28| 3.5| 10110| 10110| | 2016-02-17 17:13:57| 2016-02-17 17:17:55| 0.7| 5.0| 10103| 10023| | 2016-02-18 10:36:07| 2016-02-18 10:41:45| 0.8| 6.0| 10022| 10017| | 2016-02-22 14:14:41| 2016-02-22 14:31:52| 4.51| 17.0| 10110| 10282| +--------------------+---------------------+-------------+-----------+----------+-----------+ only showing top 5 rowsDer gesamte Python-Code wird lokal ausgeführt, während der gesamte PySpark-Code, einschließlich DataFrame-Vorgängen, im Cluster im Azure Databricks-Remotearbeitsbereich ausgeführt wird. Die Ausführungsantworten werden an den lokalen Aufrufer zurückgesendet.
Um die Spark-Shell zu beenden, drücken Sie
Ctrl + doderCtrl + z, oder führen Sie den Befehlquit()oderexit()aus.
Codebeispiele
Databricks bietet mehrere Beispielanwendungen, die veranschaulichen, wie Databricks Connect verwendet wird. Weitere Informationen finden Sie im Repository databricks-demos/dbconnect-examples auf GitHub.
Sie können auch die folgenden einfacheren Codebeispiele verwenden, um mit Databricks Connect zu experimentieren. In diesen Beispielen wird davon ausgegangen, dass Sie die Standardauthentifizierung für Databricks Connect verwenden.
Dieses einfache Codebeispiel fragt die angegebene Tabelle ab, und zeigt dann die ersten 5 Zeilen der angegebenen Tabelle an. Um eine andere Tabelle zu verwenden, passen Sie den Aufruf auf spark.read.table an.
from databricks.connect import DatabricksSession
spark = DatabricksSession.builder.getOrCreate()
df = spark.read.table("samples.nyctaxi.trips")
df.show(5)
Dieses längere Codebeispiel führt Folgendes aus:
- Erstellt einen In-Memory-DataFrame.
- Erstellt eine Tabelle mit dem Namen
zzz_demo_temps_tableinnerhalb desdefault-Schemas. Wenn die Tabelle mit diesem Namen bereits vorhanden ist, wird die Tabelle zuerst gelöscht. Um ein anderes Schema oder eine andere Tabelle zu verwenden, passen Sie die Aufrufe aufspark.sql,temps.write.saveAsTableoder beides an. - Speichert die Inhalte des DataFrames in der Tabelle.
- Führt eine
SELECT-Abfrage auf dem Inhalt der Tabelle aus. - Zeigt das Ergebnis der Abfrage an.
- Löscht die Tabelle.
from databricks.connect import DatabricksSession
from pyspark.sql.types import *
from datetime import date
spark = DatabricksSession.builder.getOrCreate()
# Create a Spark DataFrame consisting of high and low temperatures
# by airport code and date.
schema = StructType([
StructField('AirportCode', StringType(), False),
StructField('Date', DateType(), False),
StructField('TempHighF', IntegerType(), False),
StructField('TempLowF', IntegerType(), False)
])
data = [
[ 'BLI', date(2021, 4, 3), 52, 43],
[ 'BLI', date(2021, 4, 2), 50, 38],
[ 'BLI', date(2021, 4, 1), 52, 41],
[ 'PDX', date(2021, 4, 3), 64, 45],
[ 'PDX', date(2021, 4, 2), 61, 41],
[ 'PDX', date(2021, 4, 1), 66, 39],
[ 'SEA', date(2021, 4, 3), 57, 43],
[ 'SEA', date(2021, 4, 2), 54, 39],
[ 'SEA', date(2021, 4, 1), 56, 41]
]
temps = spark.createDataFrame(data, schema)
# Create a table on the Databricks cluster and then fill
# the table with the DataFrame's contents.
# If the table already exists from a previous run,
# delete it first.
spark.sql('USE default')
spark.sql('DROP TABLE IF EXISTS zzz_demo_temps_table')
temps.write.saveAsTable('zzz_demo_temps_table')
# Query the table on the Databricks cluster, returning rows
# where the airport code is not BLI and the date is later
# than 2021-04-01. Group the results and order by high
# temperature in descending order.
df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " \
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " \
"GROUP BY AirportCode, Date, TempHighF, TempLowF " \
"ORDER BY TempHighF DESC")
df_temps.show()
# Results:
#
# +-----------+----------+---------+--------+
# |AirportCode| Date|TempHighF|TempLowF|
# +-----------+----------+---------+--------+
# | PDX|2021-04-03| 64| 45|
# | PDX|2021-04-02| 61| 41|
# | SEA|2021-04-03| 57| 43|
# | SEA|2021-04-02| 54| 39|
# +-----------+----------+---------+--------+
# Clean up by deleting the table from the Databricks cluster.
spark.sql('DROP TABLE zzz_demo_temps_table')
Migrieren zur aktuellen Databricks Connect-Version
Befolgen Sie diese Anleitungen, um Ihr vorhandenes Python-Codeprojekt oder Ihre Codierungsumgebung von Databricks Connect für Databricks Runtime 12.2 LTS und tiefer zu Databricks Connect für Databricks Runtime 13.0 und höher zu migrieren.
Hinweis
Databricks Connect für Databricks Runtime 13.0 und höher unterstützt derzeit nur Python-basierte Projekte und Codierungsumgebungen.
Installieren Sie die richtige Version von Python, wie in den Anforderungen aufgeführt, um Ihrem Azure Databricks-Cluster zu entsprechen, sofern dies noch nicht lokal installiert ist.
Führen Sie ein Upgrade für Ihre virtuelle Python-Umgebung durch, um bei Bedarf die richtige Version von Python für Ihren Cluster zu verwenden. Anweisungen finden Sie in der Dokumentation des Anbieters Ihrer virtuellen Umgebung.
Wenn Ihre virtuelle Umgebung aktiviert ist, deinstallieren Sie PySpark aus Ihrer virtuellen Umgebung:
pip3 uninstall pysparkWährend Ihre virtuelle Umgebung immer noch aktiviert ist, deinstallieren Sie Databricks Connect für Databricks Runtime 12.2 LTS und tiefer:
pip3 uninstall databricks-connectWenn Ihre virtuelle Umgebung immer noch aktiviert ist, installieren Sie Databricks Connect für Databricks Runtime 13.0 und höher:
pip3 install --upgrade "databricks-connect==13.1.*" # Or X.Y.* to match your cluster version.Hinweis
Databricks empfiehlt, die Notation „Punkt-Sternchen“ anzufügen, um
databricks-connect==X.Y.*anstelle vondatabricks-connect=X.Yanzugeben, um sicherzustellen, dass das neueste Paket installiert ist. Dies ist zwar keine Anforderung, aber es hilft sicherzustellen, dass Sie die aktuellen unterstützten Features für diesen Cluster verwenden können.Aktualisieren Sie Ihren Python-Code, um die
spark-Variable zu initialisieren (die eine Instanziierung derDatabricksSession-Klasse darstellt, ähnlich wieSparkSessionin PySpark). Codebeispiele finden Sie unter Schritt 2: Konfigurieren von Verbindungseigenschaften.
Zugreifen auf Databricks-Hilfsprogramme
In diesem Abschnitt wird beschrieben, wie Sie mit Databricks Connect auf Databricks-Hilfsprogramme zugreifen.
Sie können Databricks File System (DBFS)-Funktionen von innerhalb eines Azure Databricks-Arbeitsbereichs aufrufen. Verwenden Sie dazu die Variable dbfs der WorkspaceClient-Klasse. Dieser Ansatz ähnelt dem Aufrufen von Databricks-Hilfsprogrammen über die dbfs-Variable aus einem Notebook innerhalb eines Arbeitsbereichs. Die WorkspaceClient-Klasse gehört zum Databricks-SDK für Python, das in Databricks Connect für Databricks Runtime 13.0 und höher enthalten ist.
Tipp
Sie können auch das enthaltene Databricks-SDK für Python verwenden, um auf jede verfügbare Databricks-REST-API zuzugreifen, nicht nur auf die DBFS-API. Weitere Informationen finden Sie unter Databricks-SDK auf PyPI.
Um WorkspaceClient zu initialisieren, müssen Sie genügend Informationen bereitstellen, um das Databricks-SDK für Python mit dem Arbeitsbereich zu authentifizieren. Sie haben beispielsweise folgende Möglichkeiten:
Codieren Sie die Arbeitsbereichs-URL und Ihr Zugriffstoken direkt in Ihrem Code, und initialisieren Sie dann
WorkspaceClientwie folgt. Obwohl diese Option unterstützt wird, wird diese Option von Databricks nicht empfohlen, da sie vertrauliche Informationen wie beispielsweise Zugriffstoken verfügbar machen kann, wenn Ihr Code in die Versionskontrolle eingecheckt oder anderweitig freigegeben wird:w = WorkspaceClient(host = "https://<workspace-instance-name>", token = "<access-token-value")Erstellen oder spezifizieren Sie ein Konfigurationsprofil, das die Felder
hostundtokenenthält, und initialisieren Sie dann denWorkspaceClientwie folgt:w = WorkspaceClient(profile = "<profile-name>")Legen Sie die Umgebungsvariablen
DATABRICKS_HOSTundDATABRICKS_TOKENauf die gleiche Weise fest, wie Sie diese für Databricks Connect festgelegt haben, und initialisieren SieWorkspaceClientdann wie folgt:w = WorkspaceClient()
Das Databricks-SDK für Python erkennt die SPARK_REMOTE-Umgebungsvariable für Databricks Connect nicht.
Weitere Azure Databricks-Authentifizierungsoptionen für das Databricks-SDK für Python sowie Informationen zum Initialisieren von AccountClient innerhalb des Databricks-SDK für Python für den Zugriff auf verfügbare Databricks-REST-APIs auf Kontoebene statt auf Arbeitsbereichsebene finden Sie unter Databricks-SDK in PyPI.
Das folgende Beispiel erstellt eine Datei mit dem Namen zzz_hello.txt im DBFS-Stamm innerhalb des Arbeitsbereichs, schreibt Daten in die Datei, schließt die Datei, liest die Daten aus der Datei und löscht die Datei anschließend. In diesem Beispiel wird davon ausgegangen, dass die Umgebungsvariablen DATABRICKS_HOST und DATABRICKS_TOKEN bereits festgelegt wurden:
from databricks.sdk import WorkspaceClient
import base64
w = WorkspaceClient()
file_path = "/zzz_hello.txt"
file_data = "Hello, Databricks!"
# The data must be base64-encoded before being written.
file_data_base64 = base64.b64encode(file_data.encode())
# Create the file.
file_handle = w.dbfs.create(
path = file_path,
overwrite = True
).handle
# Add the base64-encoded version of the data.
w.dbfs.add_block(
handle = file_handle,
data = file_data_base64.decode()
)
# Close the file after writing.
w.dbfs.close(handle = file_handle)
# Read the file's contents and then decode and print it.
response = w.dbfs.read(path = file_path)
print(base64.b64decode(response.data).decode())
# Delete the file.
w.dbfs.delete(path = file_path)
Tipp
Sie können auch über auf das Databricks Utilities-Hilfsprogramm Geheimnisse über w.secrets zugreifen, auf das Hilfsprogramm Aufträge über w.jobs, und auf das Hilfsprogramm Bibliothek über w.libraries.
Deaktivieren von Databricks Connect
Databricks Connect-Dienste (und die zugrunde liegenden Spark Connect-Dienste) können für jeden Cluster deaktiviert werden. Um den Databricks Connect-Dienst zu deaktivieren, legen Sie die folgende Spark-Konfiguration für den Cluster fest.
spark.databricks.service.server.enabled false
Nach der Deaktivierung werden alle Databricks Connect-Abfragen, die den Cluster erreichen, mit einer entsprechenden Fehlermeldung abgelehnt.
Festlegen von Hadoop-Konfigurationen
Auf dem Client können Sie Hadoop-Konfigurationen mithilfe der spark.conf.set-API festlegen, die für SQL- und DataFrame-Vorgänge gilt. Hadoop-Konfigurationen, die für sparkContext festgelegt werden, müssen in der Clusterkonfiguration oder mithilfe eines Notebooks festgelegt werden. Dies liegt daran, dass die für sparkContext festgelegten Konfigurationen nicht an Benutzersitzungen gebunden sind, sondern für den gesamten Cluster gelten.
Problembehandlung
In diesem Abschnitt werden einige häufige Probleme beschrieben, die bei Databricks Connect auftreten können, und wie Sie diese beheben können.
Inhalt dieses Abschnitts:
- Fehler: StatusCode.UNAVAILABLE, StatusCode.UNKNOWN, Fehler bei DNS-Auflösung oder „Received http2 header with status 500“ (HTTP2-Header mit Status 500 empfangen)
- Python-Versionskonflikt
- In Konflikt stehende PySpark-Installationen
- Widersprüchlicher oder fehlender
PATH-Eintrag für Binärdateien - Der Dateiname, der Verzeichnisname oder die Syntax der Volumebezeichnung unter Windows ist falsch
Fehler: StatusCode.UNAVAILABLE, StatusCode.UNKNOWN, Fehler bei DNS-Auflösung oder „Received http2 header with status 500“ (HTTP2-Header mit Status 500 empfangen)
Problem: Wenn Sie versuchen, Code mit Databricks Connect auszuführen, erhalten Sie eine Fehlermeldung, die Zeichenfolgen wie StatusCode.UNAVAILABLE, StatusCode.UNKNOWN, DNS resolution failed oder Received http2 header with status: 500 enthält.
Mögliche Ursache: Databricks Connect kann Ihren Cluster nicht erreichen.
Empfohlene Lösungen:
- Überprüfen Sie, ob der Name Ihrer Arbeitsbereichsinstanz korrekt ist. Wenn Sie Umgebungsvariablen verwenden, überprüfen Sie, ob die zugehörige Umgebungsvariable auf Ihrem lokalen Entwicklungscomputer verfügbar und korrekt ist.
- Überprüfen Sie, ob die Cluster-ID korrekt ist. Wenn Sie Umgebungsvariablen verwenden, überprüfen Sie, ob die zugehörige Umgebungsvariable auf Ihrem lokalen Entwicklungscomputer verfügbar und korrekt ist.
- Überprüfen Sie, ob Ihr Cluster über die richtige benutzerdefinierte Clusterversion verfügt, die mit Databricks Connect kompatibel ist.
Nicht übereinstimmende Python-Versionen
Vergewissern Sie sich, dass die lokal verwendete Python-Version mindestens dieselbe Nebenversion wie die Version im Cluster aufweist (z. B. 3.10.11 und 3.10.10 ist in Ordnung, 3.10 und 3.9 nicht).
Wenn lokal mehrere Python-Versionen installiert sind, sollten Sie sich vergewissern, dass Databricks Connect die richtige Version verwendet, indem Sie die Umgebungsvariable PYSPARK_PYTHON festlegen (z. BPYSPARK_PYTHON=python3).
In Konflikt stehende PySpark-Installationen
Das databricks-connect-Paket steht im Konflikt mit PySpark. Wenn beides installiert ist, treten beim Initialisieren des Spark-Kontexts in Python Fehler auf. Dies kann sich auf verschiedene Weise manifestieren, z. B. durch Fehlermeldungen wie „stream corrupted“ (Datenstrom beschädigt) oder „class not found“ (Klasse nicht gefunden). Wenn PySpark in Ihrer Python-Umgebung installiert ist, müssen Sie es vor dem Installieren von databricks-connect deinstallieren. Stellen Sie nach der Deinstallation von PySpark sicher, dass das Databricks Connect-Paket vollständig neu installiert wird:
pip3 uninstall pyspark
pip3 uninstall databricks-connect
pip3 install --upgrade "databricks-connect==13.1.*" # or X.Y.* to match your specific cluster version.
Widersprüchlicher oder fehlender PATH-Eintrag für Binärdateien
Es ist möglich, dass Ihr PATH so konfiguriert ist, dass Befehle wie spark-shell eine andere zuvor installierte Binärdatei anstelle der mit Databricks Connect bereitgestellten Binärdatei ausführen. Sie sollten entweder dafür sorgen, dass die Databricks Connect-Binärdateien Vorrang haben, oder die zuvor installierten Binärdateien entfernen.
Wenn Sie Befehle wie spark-shell nicht ausführen können, kann es auch sein, dass Ihr PATH von pip3 install nicht automatisch eingerichtet wurde. Dann müssen Sie Ihrem PATH das Installationsverzeichnis bin manuell hinzufügen. Es ist möglich, Databricks Connect mit IDEs zu verwenden, auch wenn dies nicht eingerichtet ist.
Der Dateiname, der Verzeichnisname oder die Syntax der Volumebezeichnung unter Windows ist falsch
Wenn Sie Databricks Connect unter Windows verwenden und folgende Fehlermeldung angezeigt wird:
The filename, directory name, or volume label syntax is incorrect.
Databricks Connect wurde in einem Verzeichnis mit einem Leerzeichen in Ihrem Pfad installiert. Sie können dieses Problem vermeiden, indem Sie die Installation in einem Verzeichnispfad ohne Leerzeichen vornehmen oder indem Sie den Pfad im Kurznamenformat konfigurieren.
Einschränkungen
Databricks Connect unterstützt die folgenden Azure Databricks-Funktionen und Drittanbieterplattformen nicht.
PySpark-Einschränkungen für Datenrahmen-API
- Die
SparkContext-Klasse und ihre Methoden sind nicht verfügbar. - RDDs (Resilient Distributed Datasets, resiliente verteilte Datasets) und Datasets werden nicht unterstützt. Nur Datenrahmen werden unterstützt.
Einschränkungen von Azure Databricks und Databricks Connect
- Abfragen mit einer Dauer von mehr als 3.600 Sekunden werden nicht unterstützt und schlagen fehl.
- Das Synchronisieren der lokalen Entwicklungsumgebung mit dem Remotecluster wird nicht unterstützt.
- Stellen Sie sicher, dass die Python-Version und alle Python-Pakete, die Sie in Ihrer lokalen Entwicklungsumgebung verwenden, so weit wie möglich mit den im Cluster installierten entsprechenden Komponenten übereinstimmen, um die Kompatibilität von Code zu gewährleisten und unerwartete Laufzeitfehler zu reduzieren.
- Nur Python wird unterstützt. R, Scala und Java werden nicht unterstützt.
- Verteiltes Training wird nicht unterstützt.
- MLflow wird unterstützt, aber kein Modellrückschluss mit
mlflow.pyfunc.spark_udf(spark, ...). Sie können das Modell lokal mitmlflow.pyfunc.load_model(<model>)laden oder es als benutzerdefinierte Pandas-UDF umschließen. - Sie können die Log4j-Protokollebene nicht über
SparkContextändern. - Mosaic ist nicht unterstützt.
Einschränkungen von Azure Databricks-Clustern
Der Azure Databricks-Arbeitsbereichsbenutzer, der ein Zugriffstoken zugeordnet ist, das von Databricks Connect verwendet wird, muss über die Berechtigungen Kann anfügen an oder höher für den Zielcluster verfügen.
CREATE TABLE table AS SELECT ...SQL-Befehle funktionieren nicht immer. Verwenden Sie stattdessenspark.sql("SELECT ...").write.saveAsTable("table").Der Passthrough von Azure Active Directory-Anmeldeinformationen wird nur in Standardclustern unterstützt, in denen Databricks Runtime 7.3 LTS und höher ausgeführt wird, und ist nicht kompatibel mit der Dienstprinzipalauthentifizierung.
Azure Active Directory (AD)-Token werden nicht automatisch aktualisiert und laufen eine Stunde nach ihrer anfänglichen Generierung ab.
Die folgenden Databricks-Hilfsprogramme: