Databricks Connect für Databricks Runtime 12.2 LTS und früher
Hinweis
Databricks Connect empfiehlt, dass Sie stattdessen Databricks Connect für Databricks Runtime 13.0 und höher verwenden.
Databricks plant keine neuen Features mehr für Databricks Connect für Databricks Runtime 12.2 LTS und früher.
Mit Databricks Connect können Sie beliebte IDEs wie Visual Studio Code und PyCharm, Notebookserver und andere benutzerdefinierte Anwendungen mit Azure Databricks-Clustern verbinden.
In diesem Artikel wird erläutert, wie Databricks Connect funktioniert, wie Sie die ersten Schritte mit Databricks Connect durchführen, wie Sie Probleme beheben, die bei der Verwendung von Databricks Connect auftreten können, und es wird beschrieben, welche Unterschiede zwischen der Verwendung von Databricks Connect und der Ausführung in einem Azure Databricks-Notebook bestehen.
Übersicht
Databricks Connect ist eine Clientbibliothek für die Databricks Runtime. Damit können Sie Aufträge mithilfe von Spark-APIs schreiben und remote in einem Azure Databricks-Cluster statt in der lokalen Spark-Sitzung ausführen.
Wenn Sie beispielsweise den DataFrame-Befehl spark.read.format(...).load(...).groupBy(...).agg(...).show() mit Databricks Connect ausführen, wird die logische Darstellung des Befehls an den in Azure Databricks ausgeführten Spark-Server gesendet, um im Remotecluster ausgeführt zu werden.
Mit Databricks Connect haben Sie folgende Möglichkeiten:
- Führen Sie umfangreiche Spark-Aufträge aus jeder Python-, R-, Scala- oder Java-Anwendung aus. Überall dort, wo Sie
import pyspark,require(SparkR)oderimport org.apache.sparkverwenden können, können Sie Spark-Aufträge jetzt direkt über Ihre Anwendung ausführen, ohne IDE-Plug-Ins installieren oder Spark-Übermittlungsskripts verwenden zu müssen. - Beim Arbeiten in einem Remotecluster können Sie Code in Ihrer IDE schrittweise durchlaufen und debuggen.
- Sie können bei der Entwicklung von Bibliotheken schnell iterieren. Sie müssen den Cluster nicht neu starten, nachdem Sie die Abhängigkeiten der Python- oder Java-Bibliothek in Databricks Connect geändert haben, da alle Clientsitzungen im Cluster voneinander isoliert sind.
- Sie können Cluster im Leerlauf ohne Verlust bereits abgeschlossener Arbeitsschritte herunterfahren. Da die Clientanwendung vom Cluster entkoppelt ist, ist sie von Clusterneustarts oder -upgrades nicht betroffen, was normalerweise dazu führen würde, dass alle in einem Notebook definierten Variablen, RDDs und Datenrahmenobjekte verloren gehen.
Hinweis
Für die Python-Entwicklung mit SQL-Abfragen empfiehlt Databricks, anstelle von Databricks Connect den Databricks SQL-Connector für Python zu verwenden. Der Databricks SQL-Connector für Python ist einfacher einzurichten als Databricks Connect. Darüber hinaus analysiert und plant Databricks Connect auf Ihrem lokalen Computer ausgeführte Aufträge während der Ausführung von Aufträgen auf Remotecomputeressourcen. Dies kann das Debuggen von Laufzeitfehlern besonders erschweren. Der Databricks SQL-Connector für Python sendet SQL-Abfragen direkt an Remotecomputeressourcen und ruft Ergebnisse ab.
Anforderungen
In diesem Abschnitt werden die Anforderungen für Databricks Connect aufgelistet.
Nur die folgenden Databricks Runtime-Versionen werden unterstützt:
- Databricks Runtime 12.2 LTS ML, Databricks Runtime 12.2 LTS
- Databricks Runtime 11.3 LTS ML, Databricks Runtime 11.3 LTS
- Databricks Runtime 10.4 LTS ML, Databricks Runtime 10.4 LTS
- Databricks Runtime 9.1 LTS ML, Databricks Runtime 9.1 LTS
- Databricks Runtime 7.3 LTS
Sie müssen Python 3 auf Ihrem Entwicklungscomputer installieren, und die Nebenversion Ihrer Python-Clientinstallation muss mit der Python-Nebenversion Ihres Azure Databricks-Clusters identisch sein. In der folgenden Tabelle sind die mit der jeweiligen Databricks Runtime-Version installierten Python-Versionen aufgeführt.
Databricks Runtime-Version Python-Version 12.2 LTS ML, 12.2 LTS 3.9 11.3 LTS ML, 11.3 LTS 3.9 10.4 LTS ML, 10.4 LTS 3.8 9.1 LTS ML, 9.1 LTS 3.8 7.3 LTS 3,7 Databricks empfiehlt dringend, eine virtuelle Python-Umgebung für jede Python-Version zu aktivieren, die Sie mit Databricks Connect verwenden. Mithilfe virtueller Python-Umgebungen kann sichergestellt werden, dass Sie die richtigen Versionen von Python und Databricks Connect zusammen verwenden. Dies kann dazu beitragen, die Zeit für die Lösung damit verbundener technischer Probleme zu verkürzen.
Wenn Sie beispielsweise venv auf Ihrem Entwicklungscomputer verwenden und Ihr Cluster Python 3.9 ausführt, müssen Sie eine
venv-Umgebung mit dieser Version erstellen. Der folgende Beispielbefehl generiert die Skripts, um einevenv-Umgebung mit Python 3.9 zu aktivieren, und dieser Befehl platziert diese Skripts dann in einem ausgeblendeten Ordner mit Namen.venvinnerhalb des aktuellen Arbeitsverzeichnisses:# Linux and macOS python3.9 -m venv ./.venv # Windows python3.9 -m venv .\.venvUm diese Skripts zu verwenden, um diese
venv-Umgebung zu aktivieren, lesen Sie Funktionsweise von venvs (virtual environments, virtuelle Umgebungen).Ein weiteres Beispiel: Wenn Sie Conda auf Ihrem Entwicklungscomputer verwenden und Ihr Cluster mit Python 3.9 ausgeführt wird, müssen Sie eine Conda-Umgebung mit dieser Version erstellen. Beispiel:
conda create --name dbconnect python=3.9Um die Conda-Umgebung mit diesem Umgebungsnamen zu aktivieren, führen Sie
conda activate dbconnectaus.Die Haupt- und Nebenpaketversion von Databricks Connect muss immer mit Ihrer Databricks Runtime-Version übereinstimmen. Databricks empfiehlt, dass Sie immer das neueste Paket von Databricks Connect verwenden, die mit Ihrer Databricks Runtime-Version übereinstimmt. Beispiel: Wenn Sie einen Databricks Runtime 12.2 LTS-Cluster verwenden, müssen Sie auch das
databricks-connect==12.2.*-Paket verwenden.Hinweis
Eine Liste mit verfügbaren Databricks Connect-Releases und Wartungsupdates finden Sie in den Versionshinweisen zu Databricks Connect.
Java Runtime Environment (JRE) 8. Der Client wurde mit der JRE OpenJDK 8 getestet. Java 11 wird vom Client nicht unterstützt.
Hinweis
Für den Fall, dass unter Windows eine Fehlermeldung angezeigt wird, die besagt, dass winutils.exe von Databricks Connect nicht gefunden wurde, finden Sie weitere Informationen unter „winutils.exe“ wurde unter Windows nicht gefunden.
Einrichten des Clients
Führen Sie die folgenden Schritte aus, um den lokalen Client für Databricks Connect einzurichten.
Hinweis
Bevor Sie beginnen, den lokalen Databricks Connect-Client einzurichten, müssen Sie die Databricks Connect-Anforderungen erfüllen.
Schritt 1: Installieren des Databricks Connect-Clients
Wenn Ihre virtuelle Umgebung aktiviert ist, deinstallieren Sie PySpark, falls es bereits installiert ist, indem Sie den
uninstall-Befehl ausführen. Dieser Schritt ist erforderlich, da dasdatabricks-connect-Paket mit PySpark in Konflikt steht. Weitere Informationen finden Sie unter In Konflikt stehende PySpark-Installationen. Um zu überprüfen, ob PySpark bereits installiert ist, führen Sie denshow-Befehl aus.# Is PySpark already installed? pip3 show pyspark # Uninstall PySpark pip3 uninstall pysparkWenn Ihre virtuelle Umgebung immer noch aktiviert ist, installieren Sie den Databricks Connect-Client, indem Sie den
install-Befehl ausführen. Verwenden Sie die--upgrade-Option, um für alle vorhandenen Clientinstallationen ein Upgrade auf die angegebene Version durchzuführen.pip3 install --upgrade "databricks-connect==12.2.*" # Or X.Y.* to match your cluster version.Hinweis
Databricks empfiehlt, die Notation „Punkt-Sternchen“ anzufügen, um
databricks-connect==X.Y.*anstelle vondatabricks-connect=X.Yanzugeben, um sicherzustellen, dass das neueste Paket installiert ist.
Schritt 2: Konfigurieren von Verbindungseigenschaften
Sammeln Sie die folgenden Konfigurationseigenschaften.
Die arbeitsbereichsspezifische URL für Azure Databricks. Dies entspricht ebenfalls
https://, gefolgt von dem Wert des Serverhostnamens für Ihren Cluster. Weitere Informationen finden Sie unter Abrufen von Verbindungsdetails für eine Azure Databricks-Ressource.Ihr persönliches Azure Databricks-Zugriffstoken oder ein Microsoft Entra ID-Token (früher Azure Active Directory).
- Für den Passthrough von ADLS-Anmeldeinformationen (Azure Data Lake Storage) müssen Sie ein Microsoft Entra ID-Token verwenden. Der Passthrough von Microsoft Entra ID-Anmeldeinformationen wird nur in Standardclustern unterstützt, in denen Databricks Runtime 7.3 LTS und höher ausgeführt wird, und ist nicht kompatibel mit der Dienstprinzipalauthentifizierung.
- Weitere Informationen zur Authentifizierung mit Microsoft Entra ID-Token finden Sie unter Authentifizieren mit Microsoft Entra ID-Token.
Die ID Ihres Clusters. Sie können die Cluster-ID über die URL abrufen. Hier lautet die Cluster-ID
1108-201635-xxxxxxxx. Weitere Informationen finden Sie auch unter Cluster-URL und -ID.
Die eindeutige Organisations-ID für Ihren Arbeitsbereich. Weitere Informationen finden Sie unter Abrufen von Bezeichnern für Arbeitsbereichsobjekte.
Der Port, mit dem Databricks Connect eine Verbindung in Ihrem Cluster herstellt. Der Standardport ist
15001. Wenn Ihr Cluster für die Verwendung eines anderen Ports konfiguriert wurde, wie etwa für Port8787, der bisher in Anweisungen für Azure Databricks angegeben wurde, verwenden Sie die konfigurierte Portnummer.
Konfigurieren Sie die Verbindung wie folgt.
Sie können die CLI, SQL-Konfigurationen oder Umgebungsvariablen verwenden. Die Rangfolge der Konfigurationsmethoden von oben nach unten lautet: SQL-Konfigurationsschlüssel, CLI und Umgebungsvariablen.
BEFEHLSZEILENSCHNITTSTELLE (CLI)
Führen Sie
databricks-connectaus.databricks-connect configureDie Lizenz zeigt Folgendes an:
Copyright (2018) Databricks, Inc. This library (the "Software") may not be used except in connection with the Licensee's use of the Databricks Platform Services pursuant to an Agreement ...Akzeptieren Sie die Lizenz, und geben Sie Konfigurationswerte ein. Geben Sie für Databricks-Host und Databricks-Token die Arbeitsbereichs-URL und das persönliche Zugriffstoken ein, die Sie in Schritt 1 notiert haben.
Do you accept the above agreement? [y/N] y Set new config values (leave input empty to accept default): Databricks Host [no current value, must start with https://]: <databricks-url> Databricks Token [no current value]: <databricks-token> Cluster ID (e.g., 0921-001415-jelly628) [no current value]: <cluster-id> Org ID (Azure-only, see ?o=orgId in URL) [0]: <org-id> Port [15001]: <port>Wenn eine Meldung angezeigt wird, dass das Microsoft Entra ID-Token zu lang ist, können Sie das Feld Databricks-Token leer lassen und das Token in
~/.databricks-connectmanuell eingeben.
SQL-Konfigurationen oder Umgebungsvariablen. In der folgenden Tabelle sind die SQL-Konfigurationsschlüssel und die Umgebungsvariablen aufgeführt, die den Konfigurationseigenschaften entsprechen, die Sie in Schritt 1 notiert haben. Verwenden Sie
sql("set config=value"), um einen SQL-Konfigurationsschlüssel festzulegen. Beispiel:sql("set spark.databricks.service.clusterId=0304-201045-abcdefgh")Parameter SQL-Konfigurationsschlüssel Name der Umgebungsvariable Databricks-Host spark.databricks.service.address DATABRICKS_ADDRESS Databricks-Token spark.databricks.service.token DATABRICKS_API_TOKEN Cluster-ID spark.databricks.service.clusterId DATABRICKS_CLUSTER_ID Organisations-ID spark.databricks.service.orgId DATABRICKS_ORG_ID Port spark.databricks.service.port DATABRICKS_PORT
Wenn Ihre virtuelle Umgebung noch aktiviert ist, testen Sie die Konnektivität mit Azure Databricks wie folgt.
databricks-connect testWenn der von Ihnen konfigurierte Cluster nicht ausgeführt wird, wird der Cluster vom Test gestartet und bis zum konfigurierten Zeitpunkt der automatischen Beendigung ausgeführt. Die Ausgabe sollte in etwa wie folgt aussehen:
* PySpark is installed at /.../.../pyspark * Checking java version java version "1.8..." Java(TM) SE Runtime Environment (build 1.8...) Java HotSpot(TM) 64-Bit Server VM (build 25..., mixed mode) * Testing scala command ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN MetricsSystem: Using default name SparkStatusTracker for source because neither spark.metrics.namespace nor spark.app.id is set. ../../.. ..:..:.. WARN SparkServiceRPCClient: Now tracking server state for 5ab..., invalidating prev state ../../.. ..:..:.. WARN SparkServiceRPCClient: Syncing 129 files (176036 bytes) took 3003 ms Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2... /_/ Using Scala version 2.... (Java HotSpot(TM) 64-Bit Server VM, Java 1.8...) Type in expressions to have them evaluated. Type :help for more information. scala> spark.range(100).reduce(_ + _) Spark context Web UI available at https://... Spark context available as 'sc' (master = local[*], app id = local-...). Spark session available as 'spark'. View job details at <databricks-url>/?o=0#/setting/clusters/<cluster-id>/sparkUi View job details at <databricks-url>?o=0#/setting/clusters/<cluster-id>/sparkUi res0: Long = 4950 scala> :quit * Testing python command ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN MetricsSystem: Using default name SparkStatusTracker for source because neither spark.metrics.namespace nor spark.app.id is set. ../../.. ..:..:.. WARN SparkServiceRPCClient: Now tracking server state for 5ab.., invalidating prev state View job details at <databricks-url>/?o=0#/setting/clusters/<cluster-id>/sparkUiWenn keine verbindungsbezogenen Fehler angezeigt werden (
WARN-Nachrichten sind in Ordnung), haben Sie eine Verbindung erfolgreich hergestellt.
Verwenden von Databricks Connect
Im Abschnitt wird beschrieben, wie Sie Ihren bevorzugten IDE- oder Notebookserver für die Verwendung des Clients für Databricks Connect konfigurieren.
Inhalt dieses Abschnitts:
- JupyterLab
- Klassisches Jupyter Notebook
- PyCharm
- SparkR und RStudio Desktop
- sparklyr und RStudio Desktop
- IntelliJ (Scala oder Java)
- PyDev mit Eclipse
- Eclipse
- SBT
- Spark-Shell
JupyterLab
Hinweis
Bevor Sie beginnen, Databricks Connect zu verwenden, müssen Sie die Anforderungen erfüllen und den Client einrichten für Databricks Connect.
Um Databricks Connect V2 mit JupyterLab und Python zu verwenden, befolgen Sie diese Anweisungen.
Um JupyterLab zu installieren, führen Sie bei aktivierter virtueller Python-Umgebung den folgenden Befehl in Ihrem Terminal oder der Eingabeaufforderung aus:
pip3 install jupyterlabUm JupyterLab in Ihrem Webbrowser zu starten, führen Sie den folgenden Befehl in Ihrer aktivierten virtuellen Python-Umgebung aus:
jupyter labWenn JupyterLab nicht in Ihrem Webbrowser angezeigt wird, kopieren Sie die URL, die mit
localhostoder127.0.0.1beginnt, aus Ihrer virtuellen Umgebung, und geben Sie diese in die Adressleiste Ihres Webbrowsers ein.Erstellen eines neuen Notebooks: Klicken Sie in JupyterLab im Hauptmenü auf Datei > Neu > Notebook, wählen Sie Python 3 (ipykernel) aus, und klicken Sie auf Auswählen.
Geben Sie in der ersten Zelle des Notebooks entweder den Beispielcode oder Ihren eigenen Code ein. Wenn Sie eigenen Code verwenden, müssen Sie mindestens eine Instanz von
SparkSession.builder.getOrCreate()instanziieren, wie im Beispielcode gezeigt.Klicken Sie zum Ausführen des Notebooks auf Run > Run All Cells.
Klicken Sie zum Debuggen des Notebooks auf der Symbolleiste des Notebooks neben Python 3 (ipykernel) auf das Fehlersymbol (Enable Debugger). Legen Sie mindestens einen Breakpoint fest, und klicken Sie dann auf Run > Run All Cells.
Klicken Sie zum Herunterfahren von JupyterLab auf File > Shut Down. Wenn der JupyterLab-Prozess weiterhin in Ihrem Terminal oder in der Eingabeaufforderung ausgeführt wird, beenden Sie diesen Prozess, indem Sie
Ctrl + cdrücken und dannyeingeben, um dies zu bestätigen.
Spezifischere Debuganweisungen finden Sie unter Debugger.
Klassisches Jupyter Notebook
Hinweis
Bevor Sie beginnen, Databricks Connect zu verwenden, müssen Sie die Anforderungen erfüllen und den Client einrichten für Databricks Connect.
Das Konfigurationsskript für Databricks Connect fügt das Paket automatisch ihrer Projektkonfiguration hinzu. Führen Sie für die ersten Schritte in einen Python-Kernel folgenden Code aus:
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
Verwenden Sie den folgenden Codeausschnitt, um die Kurzform %sql zum Ausführen und Visualisieren von SQL-Abfragen zu aktivieren:
from IPython.core.magic import line_magic, line_cell_magic, Magics, magics_class
@magics_class
class DatabricksConnectMagics(Magics):
@line_cell_magic
def sql(self, line, cell=None):
if cell and line:
raise ValueError("Line must be empty for cell magic", line)
try:
from autovizwidget.widget.utils import display_dataframe
except ImportError:
print("Please run `pip install autovizwidget` to enable the visualization widget.")
display_dataframe = lambda x: x
return display_dataframe(self.get_spark().sql(cell or line).toPandas())
def get_spark(self):
user_ns = get_ipython().user_ns
if "spark" in user_ns:
return user_ns["spark"]
else:
from pyspark.sql import SparkSession
user_ns["spark"] = SparkSession.builder.getOrCreate()
return user_ns["spark"]
ip = get_ipython()
ip.register_magics(DatabricksConnectMagics)
Visual Studio Code
Hinweis
Bevor Sie beginnen, Databricks Connect zu verwenden, müssen Sie die Anforderungen erfüllen und den Client einrichten für Databricks Connect.
Gehen Sie wie folgt vor, um Databricks Connect mit Visual Studio Code zu verwenden:
Überprüfen Sie, ob die Python-Erweiterung installiert ist.
Öffnen Sie die Befehlspalette (Befehl+UMSCHALT+P unter macOS und STRG+UMSCHALT+P unter Windows/Linux).
Wählen Sie einen Python-Interpreter aus. Navigieren Sie zu Code > Voreinstellungen > Einstellungen, und wählen Sie Python-Einstellungen aus.
Führen Sie
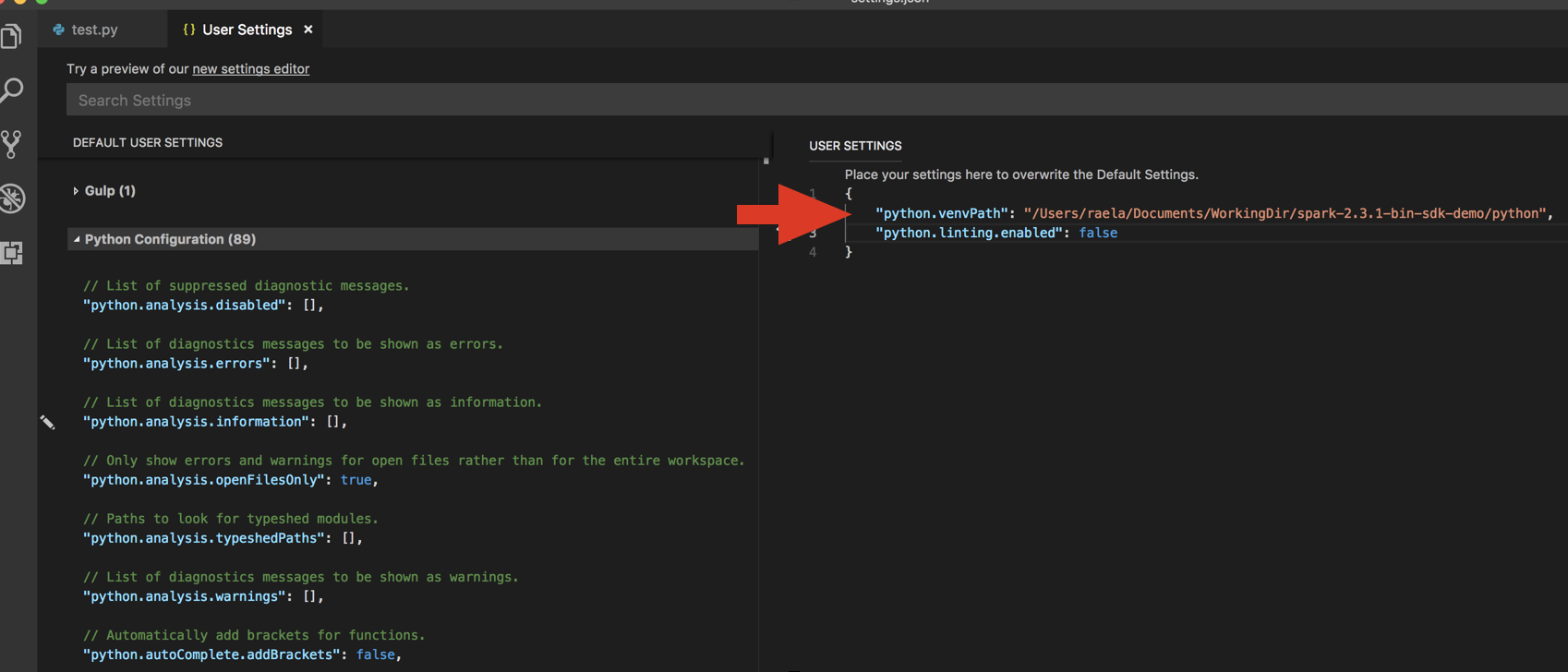
databricks-connect get-jar-diraus.Fügen Sie das vom Befehl zurückgegebene Verzeichnis den Benutzereinstellungen für JSON unter
python.venvPathhinzu. Dies sollte der Python-Konfiguration hinzugefügt werden.Deaktivieren Sie den Linter. Klicken Sie rechts auf die Punkte (…) und dann auf JSON-Einstellungen bearbeiten. Die geänderten Einstellungen lauten wie folgt:
Wenn Sie eine virtuelle Umgebung verwenden, was für die Entwicklung für Python in VS Code empfohlen wird, geben Sie in der Befehlspalette
select python interpreterein, und verweisen Sie auf Ihre Umgebung, die der Python-Version Ihres Clusters entspricht.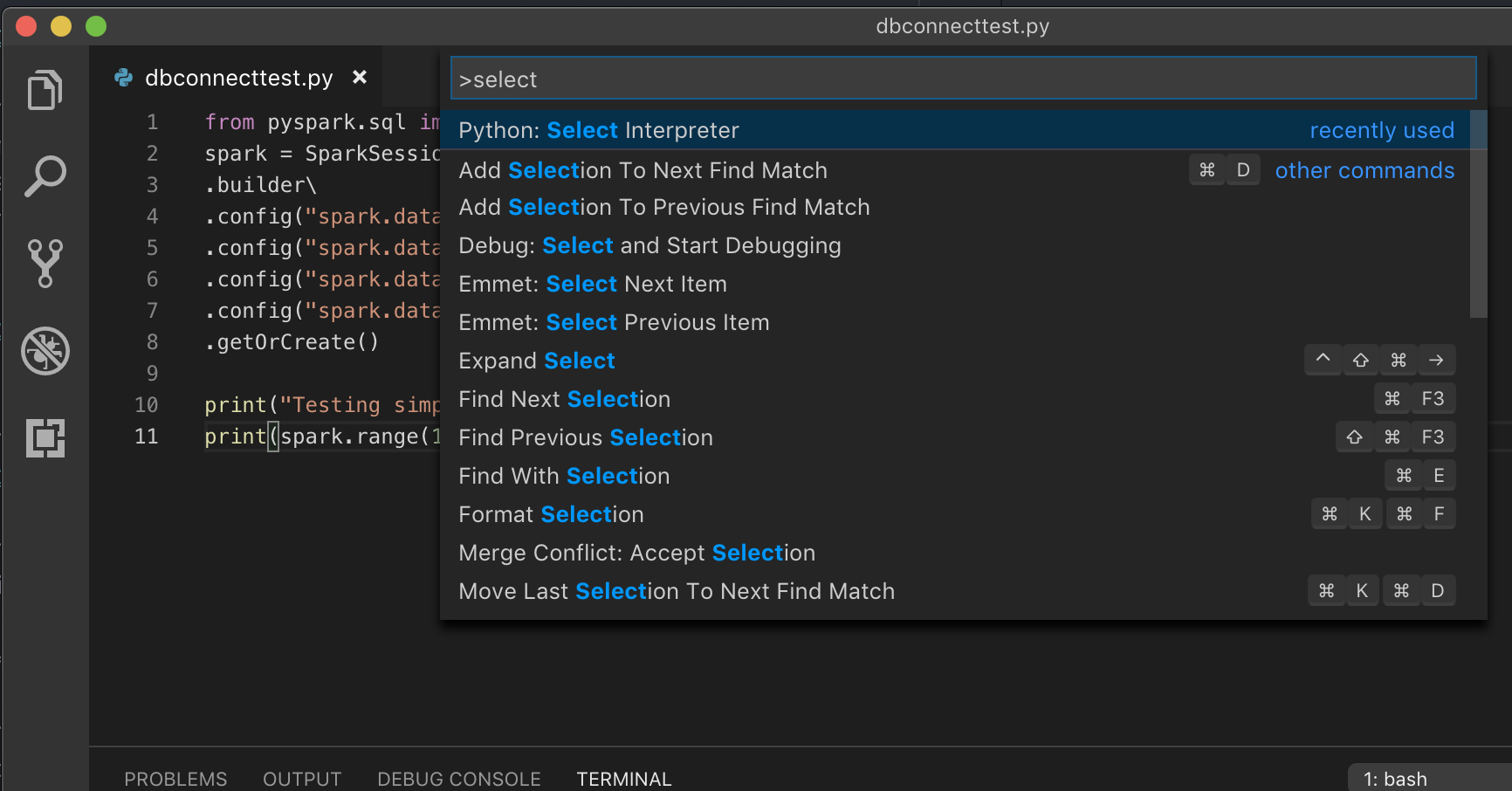
Wenn in Ihrem Cluster beispielsweise Python 3.9 verwendet wird, müssen Sie in der Entwicklungsumgebung Python 3.9 verwenden.
PyCharm
Hinweis
Bevor Sie beginnen, Databricks Connect zu verwenden, müssen Sie die Anforderungen erfüllen und den Client einrichten für Databricks Connect.
Das Konfigurationsskript für Databricks Connect fügt das Paket automatisch ihrer Projektkonfiguration hinzu.
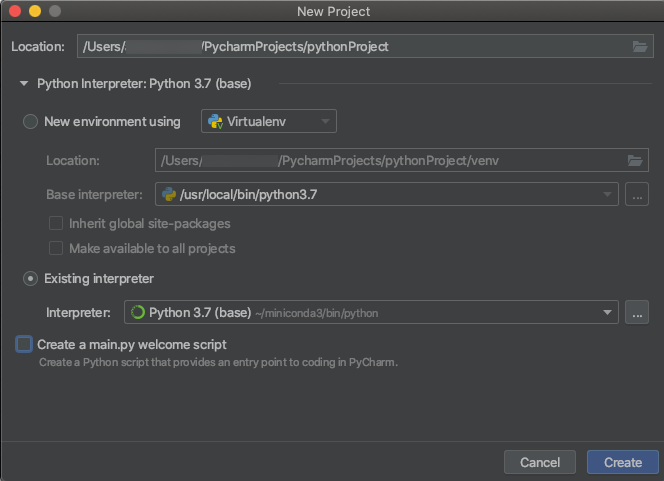
Python 3-Cluster
Wählen Sie beim Erstellen eines PyCharm-Projekts Vorhandener Interpreter aus. Wählen Sie im Dropdownmenü die Umgebung Conda aus, die Sie erstellt haben (Informationen hierzu finden Sie unter Anforderungen).
Navigieren Sie zu Ausführen > Konfigurationen bearbeiten.
Fügen Sie
PYSPARK_PYTHON=python3als Umgebungsvariable hinzu.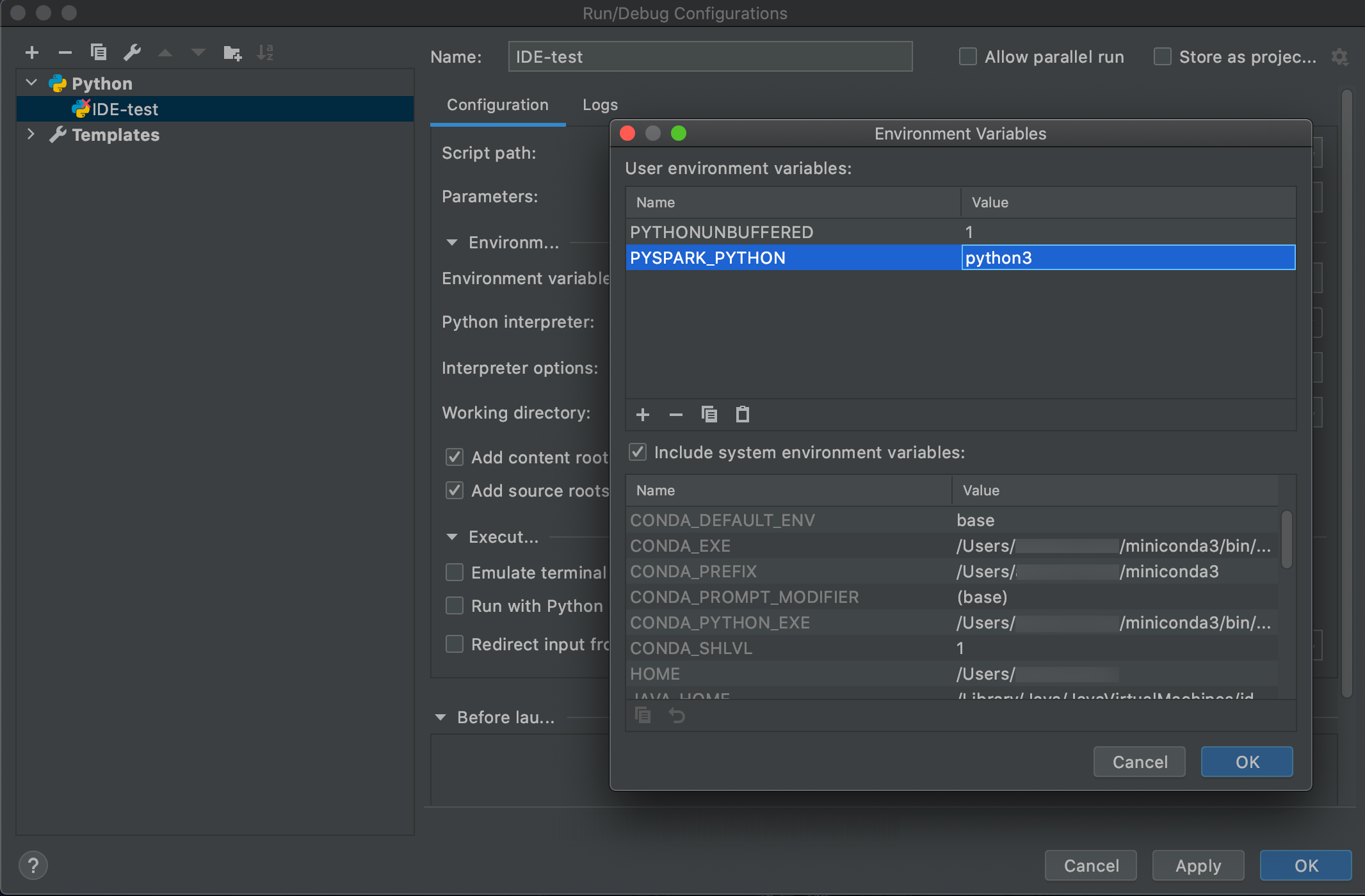
SparkR und RStudio Desktop
Hinweis
Bevor Sie beginnen, Databricks Connect zu verwenden, müssen Sie die Anforderungen erfüllen und den Client einrichten für Databricks Connect.
Gehen Sie wie folgt vor, um Databricks Connect mit SparkR und RStudio Desktop zu verwenden:
Laden Sie die Open-Source-Spark-Distribution herunter, und entpacken Sie sie auf Ihrem Entwicklungscomputer. Wählen Sie dieselbe Version wie in Ihrem Azure Databricks-Cluster aus (Hadoop 2.7).
Führen Sie
databricks-connect get-jar-diraus. Dieser Befehl gibt einen Pfad wie/usr/local/lib/python3.5/dist-packages/pyspark/jarszurück. Kopieren Sie den Dateipfad eines Verzeichnisses über dem JAR-Verzeichnisdateipfad, z. B./usr/local/lib/python3.5/dist-packages/pyspark, bei dem es sich um das VerzeichnisSPARK_HOMEhandelt.Konfigurieren Sie den Spark-Bibliothekspfad und die Spark-Startseite, indem Sie sie am Anfang Ihres R-Skripts hinzufügen. Legen Sie für
<spark-lib-path>das Verzeichnis fest, in dem Sie das Open-Source-Spark-Paket in Schritt 1 entpackt haben. Legen Sie für<spark-home-path>das Databricks Connect-Verzeichnis aus Schritt 2 fest.# Point to the OSS package path, e.g., /path/to/.../spark-2.4.0-bin-hadoop2.7 library(SparkR, lib.loc = .libPaths(c(file.path('<spark-lib-path>', 'R', 'lib'), .libPaths()))) # Point to the Databricks Connect PySpark installation, e.g., /path/to/.../pyspark Sys.setenv(SPARK_HOME = "<spark-home-path>")Initiieren Sie eine Spark-Sitzung, und beginnen Sie mit dem Ausführen von SparkR-Befehlen.
sparkR.session() df <- as.DataFrame(faithful) head(df) df1 <- dapply(df, function(x) { x }, schema(df)) collect(df1)
sparklyr und RStudio Desktop
Hinweis
Bevor Sie beginnen, Databricks Connect zu verwenden, müssen Sie die Anforderungen erfüllen und den Client einrichten für Databricks Connect.
Wichtig
Dieses Feature befindet sich in der Public Preview.
Sie können sparklyr-abhängigen Code kopieren, den Sie lokal mit Databricks Connect entwickelt haben, und ihn in einem Azure Databricks-Notebook oder gehosteten RStudio Server in Ihrem Azure Databricks-Arbeitsbereich mit wenigen oder gar keinen Codeänderungen ausführen.
Inhalt dieses Abschnitts:
- Anforderungen
- Installieren, Konfigurieren und Verwenden von sparklyr
- Ressourcen
- Einschränkungen bei sparklyr und RStudio Desktop
Anforderungen
- sparklyr 1.2 oder höher.
- Databricks Runtime 7.3 LTS oder höher mit der entsprechenden Version von Databricks Connect
Installieren, Konfigurieren und Verwenden von sparklyr
Installieren Sie sparklyr 1.2 oder höher über CRAN in RStudio Desktop, oder installieren Sie die aktuelle Masterversion aus GitHub.
# Install from CRAN install.packages("sparklyr") # Or install the latest master version from GitHub install.packages("devtools") devtools::install_github("sparklyr/sparklyr")Aktivieren die Python-Umgebung, in der die richtige Version von Databricks Connect installiert ist, und führen Sie den folgenden Befehl im Terminal aus, um
<spark-home-path>abzurufen:databricks-connect get-spark-homeInitiieren Sie eine Spark-Sitzung, und beginnen Sie mit dem Ausführen von sparklyr-Befehlen.
library(sparklyr) sc <- spark_connect(method = "databricks", spark_home = "<spark-home-path>") iris_tbl <- copy_to(sc, iris, overwrite = TRUE) library(dplyr) src_tbls(sc) iris_tbl %>% countTrennen Sie die Verbindung.
spark_disconnect(sc)
Ressourcen
Weitere Informationen finden Sie in GitHub in der Infodatei zu sparklyr.
Codebeispiele finden Sie unter sparklyr.
Einschränkungen bei sparklyr und RStudio Desktop
Folgende Funktionen werden nicht unterstützt:
- sparklyr-Streaming-APIs
- sparklyr-ML-APIs
- broom-APIs
- csv_file-Serialisierungsmodus
- spark-submit
IntelliJ (Scala oder Java)
Hinweis
Bevor Sie beginnen, Databricks Connect zu verwenden, müssen Sie die Anforderungen erfüllen und den Client einrichten für Databricks Connect.
Gehen Sie wie folgt vor, um Databricks Connect mit IntelliJ (Scala oder Java) zu verwenden:
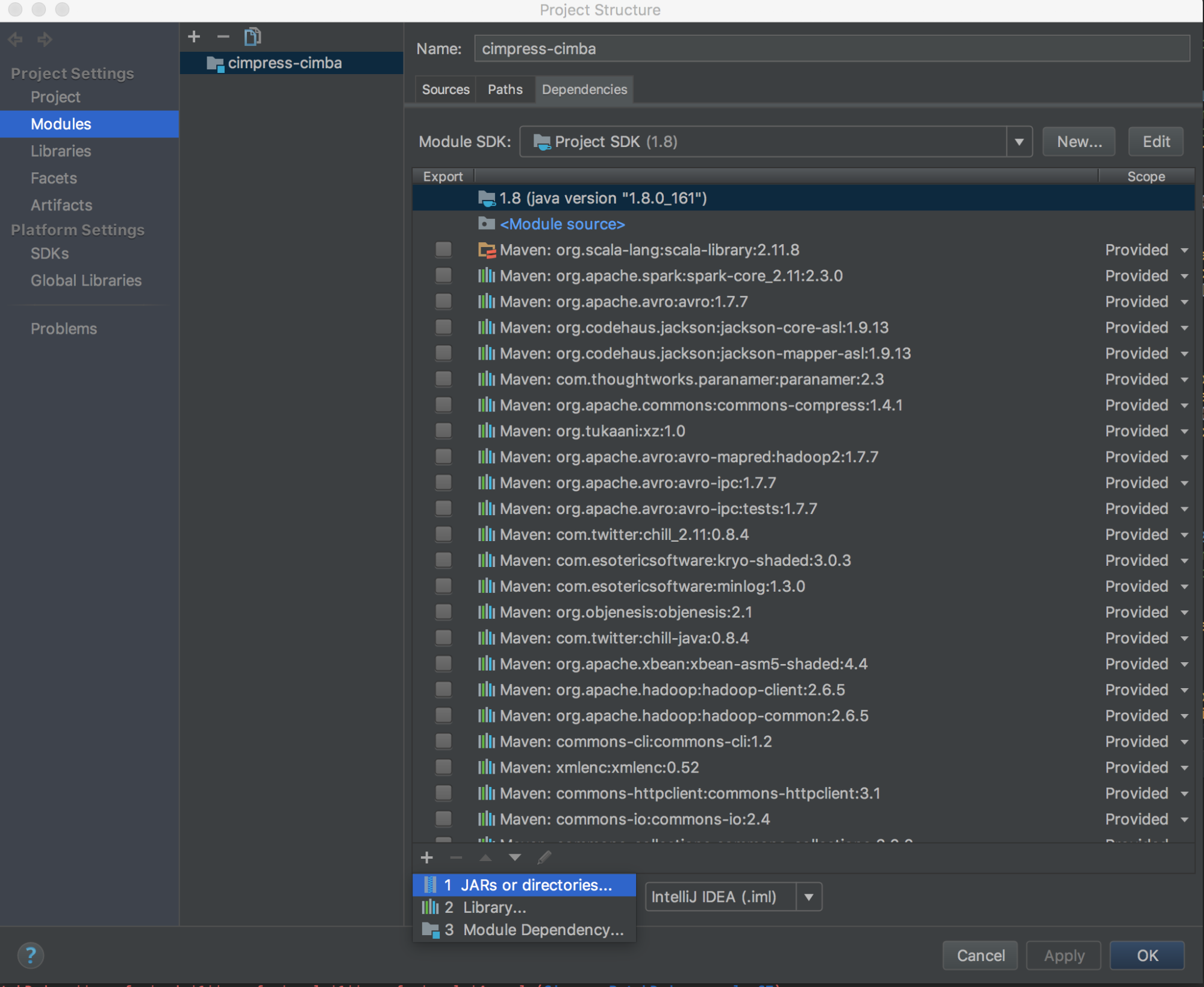
Führen Sie
databricks-connect get-jar-diraus.Verweisen Sie die Abhängigkeiten auf das vom Befehl zurückgegebene Verzeichnis. Navigieren Sie zu Datei > Projektstruktur > Module > Abhängigkeiten > ‚+‘-Zeichen > JAR-Dateien oder Verzeichnisse.
Zur Vermeidung von Konflikten sollten Sie unbedingt alle anderen Spark-Installationen aus Ihrem Klassenpfad entfernen. Wenn dies nicht möglich ist, stellen Sie sicher, dass sich die von Ihnen hinzugefügten JAR-Dateien am Anfang des Klassenpfads befinden. Sie müssen sich insbesondere vor allen anderen installierten Versionen von Spark befinden. (Andernfalls verwenden Sie entweder eine dieser anderen Spark-Versionen, und führen Sie sie lokal aus, oder der Fehler
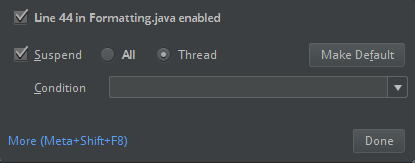
ClassDefNotFoundErrorwird ausgelöst.)Überprüfen Sie die Einstellung der Breakoutoption in IntelliJ. Der Standardwert ist Alle und verursacht Netzwerktimeouts, wenn Sie Haltepunkte für das Debuggen festlegen. Legen Sie ihn auf Thread fest, um zu vermeiden, dass die Hintergrundnetzwerkthreads beendet werden.
PyDev mit Eclipse
Hinweis
Bevor Sie beginnen, Databricks Connect zu verwenden, müssen Sie die Anforderungen erfüllen und den Client einrichten für Databricks Connect.
Um Databricks Connect und PyDev mit Eclipse zu verwenden, befolgen Sie diese Anweisungen.
- Starten Sie Eclipse.
- Erstellen eines Projekts: Klicken Sie auf Datei > Neu > Projekt > PyDev > PyDev-Projekt, und klicken Sie dann auf Weiter.
- Geben Sie einen Projektnamen an.
- Geben Sie für Project-Inhalte den Pfad zu Ihrer virtuellen Python-Umgebung an.
- Klicken Sie auf Konfigurieren Sie einen Interpreter, bevor Sie fortfahren.
- Klicken Sie auf Manuelles konfigurieren.
- Klicken Sie Neu > Suche nach ausführbarer python/pypy-Datei.
- Browsen Sie zum vollständigen Pfad zum Python-Interpreter, der in der virtuellen Umgebung referenziert ist, wählen Sie diesen aus, und klicken Sie dann auf Öffnen.
- Klicken Sie im Dialogfeld Interpreter auswählen auf OK.
- Klicken Sie im Dialogfeld Auswahl erforderlich auf OK.
- Klicken Sie im Dialogfeld Einstellungen auf Übernehmen und Schließen.
- Klicken Sie im Dialogfeld PyDev-Projekt auf Fertig stellen.
- Klicken Sie auf Perspektive öffnen.
- Fügen Sie dem Projekt eine Python-Codedatei (
.py) hinzu, die entweder den Beispielcode oder Ihren eigenen Code enthält. Wenn Sie eigenen Code verwenden, müssen Sie mindestens eine Instanz vonSparkSession.builder.getOrCreate()instanziieren, wie im Beispielcode gezeigt. - Legen Sie bei geöffneter Python-Codedatei alle Breakpoints fest, an denen der Code während der Ausführung angehalten werden soll.
- Klicken Sie auf Run > Run oder Run > Debug.
Genauere Anweisungen zum Ausführen und Debuggen finden Sie unter Ausführen eines Programms.
Eclipse
Hinweis
Bevor Sie beginnen, Databricks Connect zu verwenden, müssen Sie die Anforderungen erfüllen und den Client einrichten für Databricks Connect.
Gehen Sie wie folgt vor, um Databricks Connect und Eclipse zu verwenden:
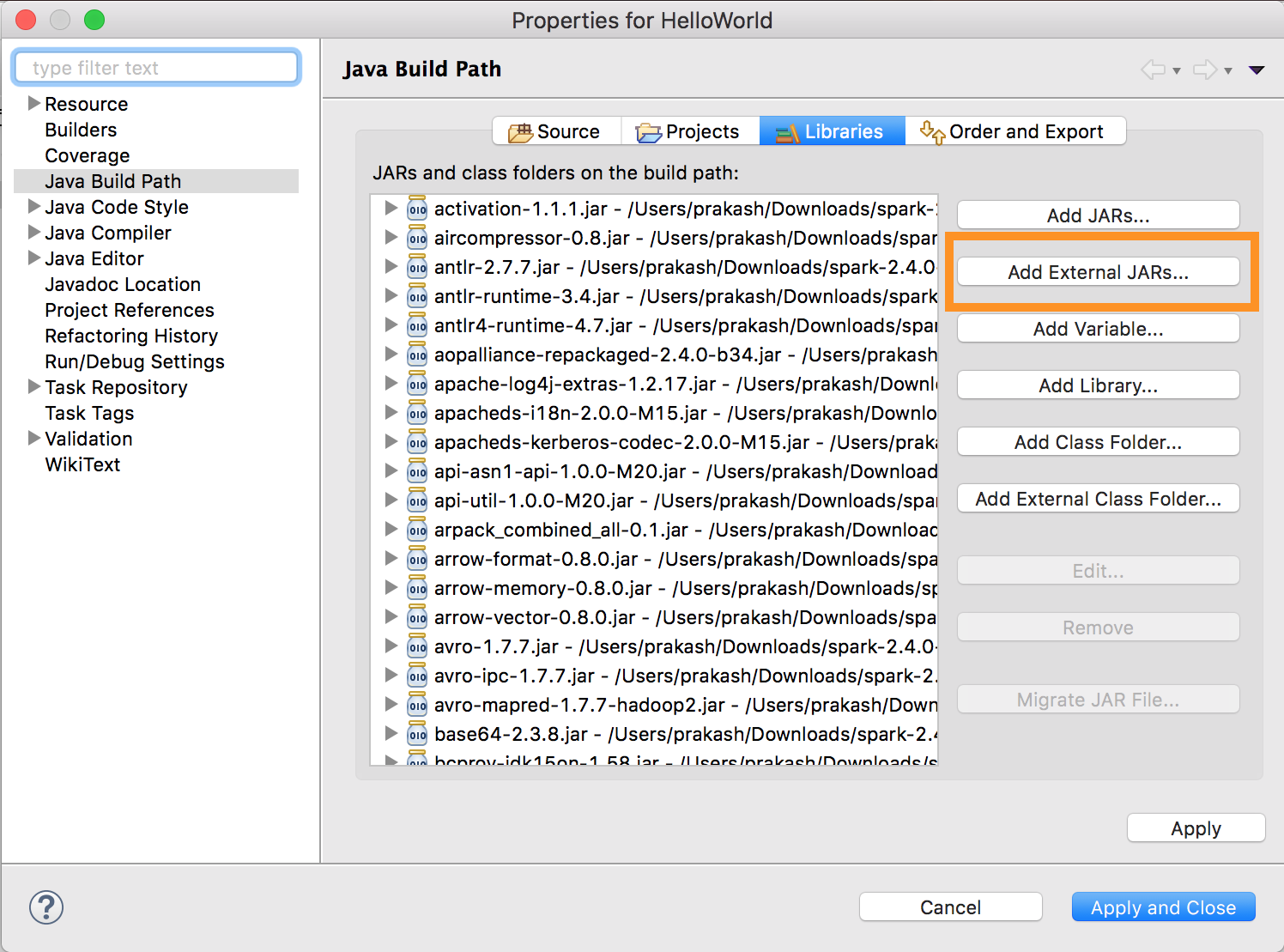
Führen Sie
databricks-connect get-jar-diraus.Verweisen Sie die Konfiguration externe JAR-Dateien auf das vom Befehl zurückgegebene Verzeichnis. Navigieren Sie zum Menü Projekt > Eigenschaften > Java-Buildpfad > Bibliotheken > Externe JAR-Dateien hinzufügen.
Zur Vermeidung von Konflikten sollten Sie unbedingt alle anderen Spark-Installationen aus Ihrem Klassenpfad entfernen. Wenn dies nicht möglich ist, stellen Sie sicher, dass sich die von Ihnen hinzugefügten JAR-Dateien am Anfang des Klassenpfads befinden. Sie müssen sich insbesondere vor allen anderen installierten Versionen von Spark befinden. (Andernfalls verwenden Sie entweder eine dieser anderen Spark-Versionen, und führen Sie sie lokal aus, oder der Fehler
ClassDefNotFoundErrorwird ausgelöst.)
SBT
Hinweis
Bevor Sie beginnen, Databricks Connect zu verwenden, müssen Sie die Anforderungen erfüllen und den Client einrichten für Databricks Connect.
Um Databricks Connect mit SBT verwenden zu können, müssen Sie Ihre build.sbt-Datei so konfigurieren, dass anstelle der üblichen Spark-Bibliotheksabhängigkeit eine Verknüpfung mit den JAR-Dateien von Databricks Connect besteht. Dazu verwenden Sie die Anweisung unmanagedBase in der folgenden Beispielbuilddatei, für die eine Scala-App mit dem Hauptobjekt com.example.Test erforderlich ist:
build.sbt
name := "hello-world"
version := "1.0"
scalaVersion := "2.11.6"
// this should be set to the path returned by ``databricks-connect get-jar-dir``
unmanagedBase := new java.io.File("/usr/local/lib/python2.7/dist-packages/pyspark/jars")
mainClass := Some("com.example.Test")
Spark-Shell
Hinweis
Bevor Sie beginnen, Databricks Connect zu verwenden, müssen Sie die Anforderungen erfüllen und den Client einrichten für Databricks Connect.
Um Databricks Connect mit der Spark-Shell und Python oder Scala zu verwenden, befolgen Sie diese Anweisungen.
Wenn Ihre virtuelle Umgebung aktiviert ist, stellen Sie sicher, dass der
databricks-connect test-Befehl unter Client einrichten erfolgreich ausgeführt wurde.Wenn Ihre virtuelle Umgebung aktiviert ist, starten Sie die Spark-Shell. Führen Sie für Python den
pyspark-Befehl aus. Führen Sie für Scala denspark-shell-Befehl aus.# For Python: pyspark# For Scala: spark-shellDie Spark-Shell wird angezeigt, z. B. für Python:
Python 3... (v3...) [Clang 6... (clang-6...)] on darwin Type "help", "copyright", "credits" or "license" for more information. Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 3.... /_/ Using Python version 3... (v3...) Spark context Web UI available at http://...:... Spark context available as 'sc' (master = local[*], app id = local-...). SparkSession available as 'spark'. >>>Für Scala:
Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Spark context Web UI available at http://... Spark context available as 'sc' (master = local[*], app id = local-...). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 3... /_/ Using Scala version 2... (OpenJDK 64-Bit Server VM, Java 1.8...) Type in expressions to have them evaluated. Type :help for more information. scala>Informationen zur Verwendung der Spark-Shell mit Python oder Scala zum Ausführen von Befehlen in Ihrem Cluster finden Sie unter Interaktive Analyse mit der Spark-Shell.
Verwenden Sie die integrierte Variable
spark, umSparkSessionin Ihrem ausgeführten Cluster darzustellen, z. B. für Python:>>> df = spark.read.table("samples.nyctaxi.trips") >>> df.show(5) +--------------------+---------------------+-------------+-----------+----------+-----------+ |tpep_pickup_datetime|tpep_dropoff_datetime|trip_distance|fare_amount|pickup_zip|dropoff_zip| +--------------------+---------------------+-------------+-----------+----------+-----------+ | 2016-02-14 16:52:13| 2016-02-14 17:16:04| 4.94| 19.0| 10282| 10171| | 2016-02-04 18:44:19| 2016-02-04 18:46:00| 0.28| 3.5| 10110| 10110| | 2016-02-17 17:13:57| 2016-02-17 17:17:55| 0.7| 5.0| 10103| 10023| | 2016-02-18 10:36:07| 2016-02-18 10:41:45| 0.8| 6.0| 10022| 10017| | 2016-02-22 14:14:41| 2016-02-22 14:31:52| 4.51| 17.0| 10110| 10282| +--------------------+---------------------+-------------+-----------+----------+-----------+ only showing top 5 rowsFür Scala:
>>> val df = spark.read.table("samples.nyctaxi.trips") >>> df.show(5) +--------------------+---------------------+-------------+-----------+----------+-----------+ |tpep_pickup_datetime|tpep_dropoff_datetime|trip_distance|fare_amount|pickup_zip|dropoff_zip| +--------------------+---------------------+-------------+-----------+----------+-----------+ | 2016-02-14 16:52:13| 2016-02-14 17:16:04| 4.94| 19.0| 10282| 10171| | 2016-02-04 18:44:19| 2016-02-04 18:46:00| 0.28| 3.5| 10110| 10110| | 2016-02-17 17:13:57| 2016-02-17 17:17:55| 0.7| 5.0| 10103| 10023| | 2016-02-18 10:36:07| 2016-02-18 10:41:45| 0.8| 6.0| 10022| 10017| | 2016-02-22 14:14:41| 2016-02-22 14:31:52| 4.51| 17.0| 10110| 10282| +--------------------+---------------------+-------------+-----------+----------+-----------+ only showing top 5 rowsUm die Spark-Shell zu beenden, drücken Sie
Ctrl + doderCtrl + z, oder führen Sie den Befehlquit()oderexit()für Python oder:qoder:quitfür Scala aus.
Codebeispiele
Dieses einfache Codebeispiel fragt die angegebene Tabelle ab, und zeigt dann die ersten 5 Zeilen der angegebenen Tabelle an. Um eine andere Tabelle zu verwenden, passen Sie den Aufruf auf spark.read.table an.
from pyspark.sql.session import SparkSession
spark = SparkSession.builder.getOrCreate()
df = spark.read.table("samples.nyctaxi.trips")
df.show(5)
Dieses längere Codebeispiel führt Folgendes aus:
- Erstellt einen In-Memory-DataFrame.
- Erstellt eine Tabelle mit dem Namen
zzz_demo_temps_tableinnerhalb desdefault-Schemas. Wenn die Tabelle mit diesem Namen bereits vorhanden ist, wird die Tabelle zuerst gelöscht. Um ein anderes Schema oder eine andere Tabelle zu verwenden, passen Sie die Aufrufe aufspark.sql,temps.write.saveAsTableoder beides an. - Speichert die Inhalte des DataFrames in der Tabelle.
- Führt eine
SELECT-Abfrage auf dem Inhalt der Tabelle aus. - Zeigt das Ergebnis der Abfrage an.
- Löscht die Tabelle.
Python
from pyspark.sql import SparkSession
from pyspark.sql.types import *
from datetime import date
spark = SparkSession.builder.appName('temps-demo').getOrCreate()
# Create a Spark DataFrame consisting of high and low temperatures
# by airport code and date.
schema = StructType([
StructField('AirportCode', StringType(), False),
StructField('Date', DateType(), False),
StructField('TempHighF', IntegerType(), False),
StructField('TempLowF', IntegerType(), False)
])
data = [
[ 'BLI', date(2021, 4, 3), 52, 43],
[ 'BLI', date(2021, 4, 2), 50, 38],
[ 'BLI', date(2021, 4, 1), 52, 41],
[ 'PDX', date(2021, 4, 3), 64, 45],
[ 'PDX', date(2021, 4, 2), 61, 41],
[ 'PDX', date(2021, 4, 1), 66, 39],
[ 'SEA', date(2021, 4, 3), 57, 43],
[ 'SEA', date(2021, 4, 2), 54, 39],
[ 'SEA', date(2021, 4, 1), 56, 41]
]
temps = spark.createDataFrame(data, schema)
# Create a table on the Databricks cluster and then fill
# the table with the DataFrame's contents.
# If the table already exists from a previous run,
# delete it first.
spark.sql('USE default')
spark.sql('DROP TABLE IF EXISTS zzz_demo_temps_table')
temps.write.saveAsTable('zzz_demo_temps_table')
# Query the table on the Databricks cluster, returning rows
# where the airport code is not BLI and the date is later
# than 2021-04-01. Group the results and order by high
# temperature in descending order.
df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " \
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " \
"GROUP BY AirportCode, Date, TempHighF, TempLowF " \
"ORDER BY TempHighF DESC")
df_temps.show()
# Results:
#
# +-----------+----------+---------+--------+
# |AirportCode| Date|TempHighF|TempLowF|
# +-----------+----------+---------+--------+
# | PDX|2021-04-03| 64| 45|
# | PDX|2021-04-02| 61| 41|
# | SEA|2021-04-03| 57| 43|
# | SEA|2021-04-02| 54| 39|
# +-----------+----------+---------+--------+
# Clean up by deleting the table from the Databricks cluster.
spark.sql('DROP TABLE zzz_demo_temps_table')
Scala
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
import java.sql.Date
object Demo {
def main(args: Array[String]) {
val spark = SparkSession.builder.master("local").getOrCreate()
// Create a Spark DataFrame consisting of high and low temperatures
// by airport code and date.
val schema = StructType(Array(
StructField("AirportCode", StringType, false),
StructField("Date", DateType, false),
StructField("TempHighF", IntegerType, false),
StructField("TempLowF", IntegerType, false)
))
val data = List(
Row("BLI", Date.valueOf("2021-04-03"), 52, 43),
Row("BLI", Date.valueOf("2021-04-02"), 50, 38),
Row("BLI", Date.valueOf("2021-04-01"), 52, 41),
Row("PDX", Date.valueOf("2021-04-03"), 64, 45),
Row("PDX", Date.valueOf("2021-04-02"), 61, 41),
Row("PDX", Date.valueOf("2021-04-01"), 66, 39),
Row("SEA", Date.valueOf("2021-04-03"), 57, 43),
Row("SEA", Date.valueOf("2021-04-02"), 54, 39),
Row("SEA", Date.valueOf("2021-04-01"), 56, 41)
)
val rdd = spark.sparkContext.makeRDD(data)
val temps = spark.createDataFrame(rdd, schema)
// Create a table on the Databricks cluster and then fill
// the table with the DataFrame's contents.
// If the table already exists from a previous run,
// delete it first.
spark.sql("USE default")
spark.sql("DROP TABLE IF EXISTS zzz_demo_temps_table")
temps.write.saveAsTable("zzz_demo_temps_table")
// Query the table on the Databricks cluster, returning rows
// where the airport code is not BLI and the date is later
// than 2021-04-01. Group the results and order by high
// temperature in descending order.
val df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " +
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " +
"GROUP BY AirportCode, Date, TempHighF, TempLowF " +
"ORDER BY TempHighF DESC")
df_temps.show()
// Results:
//
// +-----------+----------+---------+--------+
// |AirportCode| Date|TempHighF|TempLowF|
// +-----------+----------+---------+--------+
// | PDX|2021-04-03| 64| 45|
// | PDX|2021-04-02| 61| 41|
// | SEA|2021-04-03| 57| 43|
// | SEA|2021-04-02| 54| 39|
// +-----------+----------+---------+--------+
// Clean up by deleting the table from the Databricks cluster.
spark.sql("DROP TABLE zzz_demo_temps_table")
}
}
Java
import java.util.ArrayList;
import java.util.List;
import java.sql.Date;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.*;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.Dataset;
public class App {
public static void main(String[] args) throws Exception {
SparkSession spark = SparkSession
.builder()
.appName("Temps Demo")
.config("spark.master", "local")
.getOrCreate();
// Create a Spark DataFrame consisting of high and low temperatures
// by airport code and date.
StructType schema = new StructType(new StructField[] {
new StructField("AirportCode", DataTypes.StringType, false, Metadata.empty()),
new StructField("Date", DataTypes.DateType, false, Metadata.empty()),
new StructField("TempHighF", DataTypes.IntegerType, false, Metadata.empty()),
new StructField("TempLowF", DataTypes.IntegerType, false, Metadata.empty()),
});
List<Row> dataList = new ArrayList<Row>();
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-03"), 52, 43));
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-02"), 50, 38));
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-01"), 52, 41));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-03"), 64, 45));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-02"), 61, 41));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-01"), 66, 39));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-03"), 57, 43));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-02"), 54, 39));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-01"), 56, 41));
Dataset<Row> temps = spark.createDataFrame(dataList, schema);
// Create a table on the Databricks cluster and then fill
// the table with the DataFrame's contents.
// If the table already exists from a previous run,
// delete it first.
spark.sql("USE default");
spark.sql("DROP TABLE IF EXISTS zzz_demo_temps_table");
temps.write().saveAsTable("zzz_demo_temps_table");
// Query the table on the Databricks cluster, returning rows
// where the airport code is not BLI and the date is later
// than 2021-04-01. Group the results and order by high
// temperature in descending order.
Dataset<Row> df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " +
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " +
"GROUP BY AirportCode, Date, TempHighF, TempLowF " +
"ORDER BY TempHighF DESC");
df_temps.show();
// Results:
//
// +-----------+----------+---------+--------+
// |AirportCode| Date|TempHighF|TempLowF|
// +-----------+----------+---------+--------+
// | PDX|2021-04-03| 64| 45|
// | PDX|2021-04-02| 61| 41|
// | SEA|2021-04-03| 57| 43|
// | SEA|2021-04-02| 54| 39|
// +-----------+----------+---------+--------+
// Clean up by deleting the table from the Databricks cluster.
spark.sql("DROP TABLE zzz_demo_temps_table");
}
}
Arbeiten mit Abhängigkeiten
In der Regel enthält eine Hauptklasse oder Python-Datei JAR-Abhängigkeitsdateien und andere Dateien. Diese JAR-Abhängigkeitsdateien und andere Dateien können durch Aufrufen von sparkContext.addJar("path-to-the-jar") oder sparkContext.addPyFile("path-to-the-file") hinzugefügt werden. Sie können mit der addPyFile() -Schnittstelle auch EGG- und ZIP-Dateien hinzufügen. Jedes Mal, wenn Sie den Code in Ihrer IDE ausführen, werden die JAR-Abhängigkeitsdateien und alle anderen Dateien im Cluster installiert.
Python
from lib import Foo
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
sc = spark.sparkContext
#sc.setLogLevel("INFO")
print("Testing simple count")
print(spark.range(100).count())
print("Testing addPyFile isolation")
sc.addPyFile("lib.py")
print(sc.parallelize(range(10)).map(lambda i: Foo(2)).collect())
class Foo(object):
def __init__(self, x):
self.x = x
Python + Java UDFs
from pyspark.sql import SparkSession
from pyspark.sql.column import _to_java_column, _to_seq, Column
## In this example, udf.jar contains compiled Java / Scala UDFs:
#package com.example
#
#import org.apache.spark.sql._
#import org.apache.spark.sql.expressions._
#import org.apache.spark.sql.functions.udf
#
#object Test {
# val plusOne: UserDefinedFunction = udf((i: Long) => i + 1)
#}
spark = SparkSession.builder \
.config("spark.jars", "/path/to/udf.jar") \
.getOrCreate()
sc = spark.sparkContext
def plus_one_udf(col):
f = sc._jvm.com.example.Test.plusOne()
return Column(f.apply(_to_seq(sc, [col], _to_java_column)))
sc._jsc.addJar("/path/to/udf.jar")
spark.range(100).withColumn("plusOne", plus_one_udf("id")).show()
Scala
package com.example
import org.apache.spark.sql.SparkSession
case class Foo(x: String)
object Test {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
...
.getOrCreate();
spark.sparkContext.setLogLevel("INFO")
println("Running simple show query...")
spark.read.format("parquet").load("/tmp/x").show()
println("Running simple UDF query...")
spark.sparkContext.addJar("./target/scala-2.11/hello-world_2.11-1.0.jar")
spark.udf.register("f", (x: Int) => x + 1)
spark.range(10).selectExpr("f(id)").show()
println("Running custom objects query...")
val objs = spark.sparkContext.parallelize(Seq(Foo("bye"), Foo("hi"))).collect()
println(objs.toSeq)
}
}
Zugreifen auf Databricks-Hilfsprogramme
In diesem Abschnitt wird beschrieben, wie Sie mit Databricks Connect auf Databricks-Hilfsprogramme zugreifen.
Sie können die Hilfsprogramme dbutils.fs und dbutils.secrets des Moduls Referenz zu Databricks-Hilfsprogrammen (dbutils) verwenden.
Die folgenden Befehle werden unterstützt: dbutils.fs.cp, dbutils.fs.head, dbutils.fs.ls, dbutils.fs.mkdirs, dbutils.fs.mv, dbutils.fs.put, dbutils.fs.rm, dbutils.secrets.get, dbutils.secrets.getBytes, dbutils.secrets.list, dbutils.secrets.listScopes.
Informationen hierzu finden Sie unter Dateisystemhilfsprogramm (dbutils.fs). Oder führen Sie dbutils.fs.help() und das Secrets-Hilfsprogramm (dbutils.secrets) oder dbutils.secrets.help() aus.
Python
from pyspark.sql import SparkSession
from pyspark.dbutils import DBUtils
spark = SparkSession.builder.getOrCreate()
dbutils = DBUtils(spark)
print(dbutils.fs.ls("dbfs:/"))
print(dbutils.secrets.listScopes())
Wenn Sie Databricks Runtime 7.3 LTS oder höher verwenden, greifen Sie mit dem folgenden get_dbutils()-Befehl auf das DBUtils-Modul zu, das sowohl in lokalen als auch in Azure Databricks-Clustern funktioniert:
def get_dbutils(spark):
from pyspark.dbutils import DBUtils
return DBUtils(spark)
Alternativ können Sie auch den folgenden get_dbutils()-Befehl verwenden:
def get_dbutils(spark):
if spark.conf.get("spark.databricks.service.client.enabled") == "true":
from pyspark.dbutils import DBUtils
return DBUtils(spark)
else:
import IPython
return IPython.get_ipython().user_ns["dbutils"]
Scala
val dbutils = com.databricks.service.DBUtils
println(dbutils.fs.ls("dbfs:/"))
println(dbutils.secrets.listScopes())
Kopieren von Dateien zwischen lokalen Dateisystemen und Remotedateisystemen
Sie können dbutils.fs verwenden, um Dateien zwischen Ihren Client- und Remotedateisystemen zu kopieren. Das Schema file:/ bezieht sich auf das lokale Dateisystem auf dem Client.
from pyspark.dbutils import DBUtils
dbutils = DBUtils(spark)
dbutils.fs.cp('file:/home/user/data.csv', 'dbfs:/uploads')
dbutils.fs.cp('dbfs:/output/results.csv', 'file:/home/user/downloads/')
Auf diese Weise können Dateien mit einer Größe von maximal 250 MB übertragen werden.
Aktivieren Sie dbutils.secrets.get.
Aufgrund von Sicherheitseinschränkungen ist die Möglichkeit zum Aufrufen von dbutils.secrets.get standardmäßig deaktiviert. Wenden Sie sich an Support von Azure Databricks, um dieses Feature für Ihren Arbeitsbereich zu aktivieren.
Festlegen von Hadoop-Konfigurationen
Auf dem Client können Sie Hadoop-Konfigurationen mithilfe der spark.conf.set-API festlegen, die für SQL- und DataFrame-Vorgänge gilt. Hadoop-Konfigurationen, die für sparkContext festgelegt werden, müssen in der Clusterkonfiguration oder mithilfe eines Notebooks festgelegt werden. Dies liegt daran, dass die für sparkContext festgelegten Konfigurationen nicht an Benutzersitzungen gebunden sind, sondern für den gesamten Cluster gelten.
Problembehandlung
Führen Sie databricks-connect test aus, um nach Konnektivitätsproblemen zu suchen. In diesem Abschnitt werden einige häufige Probleme beschrieben, die bei Databricks Connect auftreten können, und wie Sie diese beheben können.
Inhalt dieses Abschnitts:
- Python-Versionskonflikt
- Server nicht aktiviert
- In Konflikt stehende PySpark-Installationen
- Steht in Konflikt
SPARK_HOME - Widersprüchlicher oder fehlender
PATH-Eintrag für Binärdateien - In Konflikt stehende Serialisierungseinstellungen für den Cluster
winutils.exewurde unter Windows nicht gefunden- Der Dateiname, der Verzeichnisname oder die Syntax der Volumebezeichnung unter Windows ist falsch
Nicht übereinstimmende Python-Versionen
Vergewissern Sie sich, dass die lokal verwendete Python-Version mindestens dieselbe Nebenversion wie die Version im Cluster aufweist (z. B. 3.9.16 und 3.9.15 ist in Ordnung, 3.9 und 3.8 nicht).
Wenn lokal mehrere Python-Versionen installiert sind, sollten Sie sich vergewissern, dass Databricks Connect die richtige Version verwendet, indem Sie die Umgebungsvariable PYSPARK_PYTHON festlegen (z. BPYSPARK_PYTHON=python3).
Server nicht aktiviert
Vergewissern Sie sich, dass im Cluster der Spark-Server mit spark.databricks.service.server.enabled true aktiviert ist. Wenn dies der Fall ist, werden im Treiberprotokoll die folgenden Zeilen angezeigt:
../../.. ..:..:.. INFO SparkConfUtils$: Set spark config:
spark.databricks.service.server.enabled -> true
...
../../.. ..:..:.. INFO SparkContext: Loading Spark Service RPC Server
../../.. ..:..:.. INFO SparkServiceRPCServer:
Starting Spark Service RPC Server
../../.. ..:..:.. INFO Server: jetty-9...
../../.. ..:..:.. INFO AbstractConnector: Started ServerConnector@6a6c7f42
{HTTP/1.1,[http/1.1]}{0.0.0.0:15001}
../../.. ..:..:.. INFO Server: Started @5879ms
In Konflikt stehende PySpark-Installationen
Das databricks-connect-Paket steht im Konflikt mit PySpark. Wenn beides installiert ist, treten beim Initialisieren des Spark-Kontexts in Python Fehler auf. Dies kann sich auf verschiedene Weise manifestieren, z. B. durch Fehlermeldungen wie „stream corrupted“ (Datenstrom beschädigt) oder „class not found“ (Klasse nicht gefunden). Wenn PySpark in Ihrer Python-Umgebung installiert ist, müssen Sie es vor dem Installieren von databricks-connect deinstallieren. Stellen Sie nach der Deinstallation von PySpark sicher, dass das Databricks Connect-Paket vollständig neu installiert wird:
pip3 uninstall pyspark
pip3 uninstall databricks-connect
pip3 install --upgrade "databricks-connect==12.2.*" # or X.Y.* to match your specific cluster version.
Konflikt mit SPARK_HOME
Wenn Sie Spark bereits auf Ihrem Computer verwendet haben, kann Ihre IDE so konfiguriert sein, dass sie eine dieser anderen Versionen von Spark anstelle von Databricks Connect Spark verwendet. Dies kann sich auf verschiedene Weise manifestieren, z. B. durch Fehlermeldungen wie „stream corrupted“ (Datenstrom beschädigt) oder „class not found“ (Klasse nicht gefunden). Sie können erkennen, welche Version von Spark verwendet wird, indem Sie den Wert der Umgebungsvariablen SPARK_HOME überprüfen:
Python
import os
print(os.environ['SPARK_HOME'])
Scala
println(sys.env.get("SPARK_HOME"))
Java
System.out.println(System.getenv("SPARK_HOME"));
Lösung
Wenn SPARK_HOME auf eine andere Spark-Version als die im Client festgelegt ist, sollten Sie die Variable SPARK_HOME löschen und es erneut versuchen.
Überprüfen Sie die Einstellungen Ihrer IDE-Umgebungsvariablen, die .bashrc-, .zshrc- oder .bash_profile-Datei und alle anderen Stellen, an denen Umgebungsvariablen festgelegt werden können. Wahrscheinlich müssen Sie Ihre IDE beenden und neu starten, um den alten Zustand zu bereinigen. Wenn das Problem weiterhin besteht, müssen Sie möglicherweise sogar ein neues Projekt erstellen.
Sie sollten SPARK_HOME nicht auf einen neuen Wert festlegen müssen. Das Löschen der Einstellung sollte genügen.
Widersprüchlicher oder fehlender PATH-Eintrag für Binärdateien
Es ist möglich, dass Ihr PATH so konfiguriert ist, dass Befehle wie spark-shell eine andere zuvor installierte Binärdatei anstelle der mit Databricks Connect bereitgestellten Binärdatei ausführen. Das kann dazu führen, dass bei databricks-connect test ein Fehler auftritt. Sie sollten entweder dafür sorgen, dass die Databricks Connect-Binärdateien Vorrang haben, oder die zuvor installierten Binärdateien entfernen.
Wenn Sie Befehle wie spark-shell nicht ausführen können, kann es auch sein, dass Ihr PATH von pip3 install nicht automatisch eingerichtet wurde. Dann müssen Sie Ihrem PATH das Installationsverzeichnis bin manuell hinzufügen. Es ist möglich, Databricks Connect mit IDEs zu verwenden, auch wenn dies nicht eingerichtet ist. Der Befehl databricks-connect test funktioniert in diesem Fall jedoch nicht.
In Konflikt stehende Serialisierungseinstellungen für den Cluster
Wenn beim Ausführen von databricks-connect test Fehlermeldungen wie „stream corrupted“ (Datenstrom beschädigt) angezeigt werden, kann dies auf inkompatible Clusterserialisierungskonfigurationen zurückzuführen sein. So kann dieses Problem beispielsweise auftreten, wenn die spark.io.compression.codec-Konfiguration festgelegt wird. Dieses Problem können Sie beheben, indem Sie diese Konfigurationen aus den Clustereinstellungen entfernen oder die Konfiguration im Databricks Connect-Client festlegen.
wurde unter Windows nicht gefundenwinutils.exe
Wenn Sie Databricks Connect unter Windows verwenden und folgende Fehlermeldung angezeigt wird:
ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
Befolgen Sie die Anweisungen zum Konfigurieren des Hadoop-Pfads unter Windows.
Der Dateiname, der Verzeichnisname oder die Syntax der Volumebezeichnung unter Windows ist falsch
Wenn Sie Windows und Databricks Connect verwenden und folgende Fehlermeldung angezeigt wird, gilt Folgendes:
The filename, directory name, or volume label syntax is incorrect.
Java oder Databricks Connect wurde in einem Verzeichnis mit einem Leerzeichen im Pfad installiert. Sie können dieses Problem vermeiden, indem Sie die Installation in einem Verzeichnispfad ohne Leerzeichen vornehmen oder indem Sie den Pfad im Kurznamenformat konfigurieren.
Authentifizieren mit Microsoft Entra ID-Token
Hinweis
Die folgenden Informationen gelten nur für Databricks Connect-Versionen 7.3.5 bis 12.2.x.
Databricks Connect für Databricks Runtime 13.3 LTS und höher unterstützt derzeit keine Microsoft Entra ID-Token.
Wenn Sie Databricks Connect (7.3.5 bis 12.2.x) verwenden, können Sie sich mithilfe eines Microsoft Entra ID-Tokens anstelle eines persönlichen Zugriffstokens authentifizieren. Microsoft Entra ID-Token haben eine begrenzte Lebensdauer. Wenn das Microsoft Entra ID-Token abläuft, tritt beim Ausführen von Databricks Connect der Fehler Invalid Token auf.
Für die Databricks Connect-Versionen 7.3.5 bis 12.2.x können Sie das Microsoft Entra ID-Token in Ihrer ausgeführten Databricks Connect-Anwendung bereitstellen. Ihre Anwendung muss das neue Zugriffstoken abrufen und auf den SQL-Konfigurationsschlüssel spark.databricks.service.token festlegen.
Python
spark.conf.set("spark.databricks.service.token", new_aad_token)
Scala
spark.conf.set("spark.databricks.service.token", newAADToken)
Nachdem Sie das Token aktualisiert haben, kann die Anwendung weiterhin dieselbe SparkSession und alle Objekte und Status verwenden, die im Kontext der Sitzung erstellt werden. Zur Vermeidung von zeitweilig auftretenden Fehlern empfiehlt Databricks, ein neues Token bereitzustellen, bevor das alte Token abläuft.
Sie können die Lebensdauer des Microsoft Entra ID-Tokens verlängern, sodass es während der Ausführung einer Anwendung nicht abläuft. Fügen Sie dazu TokenLifetimePolicy mit einer entsprechend langen Lebensdauer an die Microsoft Entra ID-Autorisierungsanwendung an, die Sie zum Abrufen des Zugriffstokens verwendet haben.
Hinweis
Beim Microsoft Entra ID-Passthrough werden zwei Token verwendet: das oben beschriebene Microsoft Entra ID-Zugriffstoken, das Sie in Databricks Connect (7.3.5 bis 12.2.x) konfigurieren, und das ADLS-Passthroughtoken für die jeweilige Ressource, die Databricks beim Verarbeiten der Anforderung generiert. Die Lebensdauer von ADLS-Passthroughtoken kann nicht mithilfe von Richtlinien für die Gültigkeitsdauer von Microsoft Entra ID-Token verlängert werden. Wenn Sie einen Befehl an den Cluster senden, der länger als eine Stunde braucht und erst nach einer Stunde auf eine ADLS-Ressource zugreift, tritt ein Fehler auf.
Begrenzungen
Strukturiertes Streaming.
Ausführen von Code, der nicht Teil eines Spark-Auftrags im Remotecluster ist.
Native Scala-, Python- und R-APIs für Delta-Tabellenvorgänge (z. B.
DeltaTable.forPath) werden nicht unterstützt. Die SQL-API (spark.sql(...)) mit Delta Lake-Vorgängen und die Spark-API (z. B.spark.read.load) für Delta-Tabellen werden jedoch beide unterstützt.Kopieren in.
Verwenden von SQL-Funktionen, Python- oder Scala-UDFs, die Teil des Serverkatalogs sind. Lokal eingeführte Scala- und Python-UDFs funktionieren jedoch.
Apache Zeppelin 0.7.x und früher.
Herstellen einer Verbindung mit Clustern mit Tabellenzugriffssteuerung.
Herstellen einer Verbindung mit Clustern mit aktivierter Prozessisolation (d. h., wenn
spark.databricks.pyspark.enableProcessIsolationauftruefestgelegt ist).Delta
CLONE-SQL-Befehl.Globale temporäre Ansichten.
Koalas und
pyspark.pandasCREATE TABLE table AS SELECT ...SQL-Befehle funktionieren nicht immer. Verwenden Sie stattdessenspark.sql("SELECT ...").write.saveAsTable("table").Der Passthrough von Microsoft Entra ID-Anmeldeinformationen wird nur in Standardclustern unterstützt, in denen Databricks Runtime 7.3 LTS und höher ausgeführt wird, und ist nicht kompatibel mit der Dienstprinzipalauthentifizierung.
Die folgende Referenz zu Databricks-Hilfsprogrammen (dbutils):