Fein abgestufte Zugriffssteuerung auf dedizierten Rechenressourcen (ehemals einzelnutzbarer Computer)
In diesem Artikel wird die Datenfilterfunktion vorgestellt, die eine differenzierte Zugriffssteuerung für Abfragen ermöglicht, die auf dedizierter Rechenleistung ausgeführt werden (Allzweck- oder Auftrags-Computing, das mit dedizierten Zugriffsmodus konfiguriert ist). Weitere Informationen finden Sie unter Zugriffsmodi.
Diese Datenfilterung wird hinter den Kulissen mit serverlosem Computing durchgeführt.
Warum erfordern einige Abfragen für dedizierte Compute datenfilterung?
Mit Unity Catalog können Sie den Zugriff auf tabellarische Daten auf Spalten- und Zeilenebene kontrollieren (auch als feinkörnige Zugriffskontrolle bezeichnet), indem Sie die folgenden Funktionen nutzen:
Wenn Benutzer Ansichten abfragen, die Daten aus referenzierten Tabellen ausschließen, oder Tabellen abfragen, die Filter und Masken anwenden, können sie jede der folgenden Computeressourcen ohne Einschränkungen verwenden:
- SQL-Warehouses
- Standard compute (früher gemeinsam genutzter Compute)
Verwenden Sie jedoch dedizierte Rechenressourcen, um solche Abfragen auszuführen, müssen Ihre Rechenressourcen und Ihr Arbeitsbereich bestimmte Anforderungen erfüllen.
Die dedizierte Computeressource muss sich auf Databricks Runtime 15.4 LTS oder höher befinden.
Der Arbeitsbereich muss für serverloses Computing für Aufträge, Notebooks und Delta Live Tables aktiviert sein.
Um zu überprüfen, ob Ihre Arbeitsbereich-Region serverloses Computing unterstützt, siehe Funktionen mit eingeschränkter regionaler Verfügbarkeit.
Wenn Ihre dedizierte Computeressource und Ihr Arbeitsbereich diese Anforderungen erfüllen, wird die Datenfilterung automatisch ausgeführt, wenn Sie eine Ansicht oder Tabelle abfragen, die eine differenzierte Zugriffssteuerung verwendet.
Unterstützung für materialisierte Ansichten, Streamingtabellen und Standardansichten
Zusätzlich zu dynamischen Ansichten, Zeilenfiltern und Spaltenmasken ermöglicht die Datenfilterung auch Abfragen für die folgenden Ansichten und Tabellen, die nicht für dedizierte Rechenleistung unterstützt werden, die unter Databricks Runtime 15.3 und darunter ausgeführt wird:
Bei dedizierter Rechenleistung mit Databricks Runtime 15.3 und darunter muss der Benutzer, der eine Abfrage auf der Ansicht ausführt, SELECT für die Tabellen und Ansichten haben, auf die von der Ansicht verwiesen wird. Dies bedeutet, dass Ansichten nicht verwendet werden können, um eine differenzierte Zugriffssteuerung bereitzustellen. Auf Databricks Runtime 15.4 mit Datenfilterung benötigt der Benutzer, der die Ansicht abfragt, keinen Zugriff auf die referenzierten Tabellen und Ansichten.
Wie funktioniert die Datenfilterung auf dedizierter Berechnung?
Wenn eine Abfrage auf die folgenden Datenbankobjekte zugreift, übergibt die dedizierte Computeressource die Abfrage an die serverlose Berechnung, um datenfiltern zu können:
- Ansichten, die über Tabellen erstellt werden, für die der Benutzer bzw. die Benutzerin nicht über die Berechtigungen
SELECTverfügt - Dynamische Ansichten
- Tabellen mit definierten Zeilenfiltern oder Spaltenmasken
- Materialisierte Ansichten und Streamingtabellen
Im folgenden Diagramm hat ein Benutzer SELECT für table_1, view_2 und table_w_rls, auf die Zeilenfilter angewendet wurden. Der Benutzer verfügt nicht über SELECT für table_2, auf das von view_2 verwiesen wird.

Die Abfrage für table_1 wird vollständig von der dedizierten Computeressource behandelt, da keine Filterung erforderlich ist. Die Abfragen für view_2 und table_w_rls erfordern eine Datenfilterung, um die Daten zurückzugeben, auf die der Benutzer zugreifen kann. Diese Abfragen werden von der Datenfilterfunktion auf serverlosem Computing behandelt.
Welche Kosten fallen an?
Kunden werden die serverlosen Computeressourcen in Rechnung gestellt, die zum Ausführen von Datenfiltervorgängen verwendet werden. Preisinformationen finden Sie unter Plattformtarife und Add-Ons.
Sie können die Abrechnungstabelle des Systems abfragen, um zu sehen, wie viel Ihnen in Rechnung gestellt wurde. Die folgende Abfrage zeigt beispielsweise die Berechnungskosten nach Benutzern auf:
SELECT usage_date,
sku_name,
identity_metadata.run_as,
SUM(usage_quantity) AS `DBUs consumed by FGAC`
FROM system.billing.usage
WHERE usage_date BETWEEN '2024-08-01' AND '2024-09-01'
AND billing_origin_product = 'FINE_GRAINED_ACCESS_CONTROL'
GROUP BY 1, 2, 3 ORDER BY 1;
Anzeigen der Abfrageleistung, wenn die Datenfilterung aktiviert ist
Die Spark-Benutzeroberfläche für dedizierte Compute zeigt Metriken an, die Sie verwenden können, um die Leistung Ihrer Abfragen zu verstehen. Für jede Abfrage, die Sie auf der Computeressource ausführen, zeigt die Registerkarte SQL/Dataframe die Darstellung des Abfragediagramms an. Wenn eine Abfrage an der Datenfilterung beteiligt war, zeigt die Benutzeroberfläche am unteren Rand des Diagramms einen RemoteSparkConnectScan-Operatorknoten an. Dieser Knoten zeigt Metriken an, mit denen Sie die Abfrageleistung untersuchen können. Weitere Informationen finden Sie unter Anzeigen von Computeinformationen in der Apache Spark UI
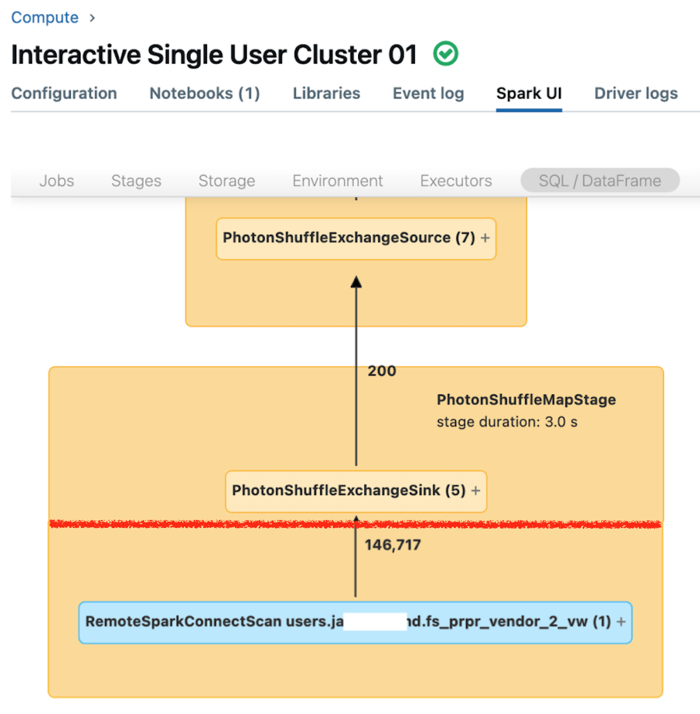
Erweitern Sie den Knotenoperator RemoteSparkConnectScan, um Metriken anzuzeigen, die sich auf Fragen wie die folgenden beziehen:
- Wie viel Zeit hat die Datenfilterung gedauert? „Gesamtdauer der Remoteausführung“ anzeigen.
- Wie viele Zeilen blieben nach der Datenfilterung übig? „Zeilenausgabe“ anzeigen.
- Wie viele Daten (in Bytes) wurden nach der Datenfilterung zurückgegeben? „Größe der Zeilenausgabe“ anzeigen.
- Wie viele Datendateien wurden partitionsgeschnitten und mussten nicht aus dem Speicher gelesen werden? „Zugeschnittene Dateien“ und „Größe der zugeschnittenen Dateien“ anzeigen.
- Wie viele Datendateien konnten nicht zugeschnitten werden und mussten aus dem Speicher gelesen werden? „Dateien gelesen“ und „Größe der gelesenen Dateien“ anzeigen.
- Von den Dateien, die gelesen werden mussten, wie viele waren bereits im Cache? „Größe der Cachetreffer“ und „Größe der Cache-Fehlversuche“ anzeigen.
Begrenzungen
Keine Unterstützung für Schreib- oder Aktualisierungsvorgänge in Tabellen, auf die Zeilenfilter oder Spaltenmasken angewendet wurden.
Insbesondere werden DML-Vorgänge wie
INSERT,DELETE,UPDATE,REFRESH TABLEundMERGEnicht unterstützt. Sie können nur aus diesen Tabellen lesen (SELECT).Self-Joins werden standardmäßig blockiert, wenn die Datenfilterung aufgerufen wird. Sie können sie jedoch zulassen, indem Sie
spark.databricks.remoteFiltering.blockSelfJoinsauf „false“ festlegen, wenn Sie diese Befehle ausführen.Bevor Sie Selbst-Joins für eine dedizierte Rechenressource aktivieren, beachten Sie, dass eine von der Datenfilterungsfunktion behandelte Selbst-Join-Abfrage verschiedene Schnappschüsse derselben Remotetabelle zurückgeben kann.
- Keine Unterstützung in Docker-Images.
- Wenn Ihr Arbeitsbereich vor November 2024 mit einer Firewall bereitgestellt wurde, müssen Sie die Ports 8443 und 8444 öffnen, um eine differenzierte Zugriffssteuerung auf dedizierten Compute zu ermöglichen. Siehe Netzwerksicherheitsgruppenregeln.