Konfigurieren von Compute (Vorversion)
Hinweis
Dies sind Anweisungen für die Legacybenutzeroberfläche zum Erstellen von Clustern, die nur der historischen Genauigkeit halber aufgeführt sind. Alle Kunden sollten die aktualisierte Benutzeroberfläche zum Erstellen von Clustern verwenden.
In diesem Artikel werden die Konfigurationsoptionen erläutert, die beim Erstellen und Bearbeiten von Azure Databricks-Clustern zur Verfügung stehen. Der Schwerpunkt liegt hierbei auf dem Erstellen und Bearbeiten von Clustern mithilfe der Benutzeroberfläche. Informationen zu weiteren Methoden finden Sie unter Databricks-CLI, Cluster-API und Databricks Terraform-Anbieter.
Hilfe bei der Entscheidung, welche Kombination von Konfigurationsoptionen Ihren Anforderungen am besten entspricht, finden Sie unter Best Practices für die Clusterkonfiguration.
Clusterrichtlinie
Mit einer Clusterrichtlinie wird die Möglichkeit zur Konfiguration von Clustern auf Grundlage bestimmter Regeln eingeschränkt. Die Richtlinienregeln beschränken die Attribute oder Attributwerte, die für die Clustererstellung verfügbar sind. Clusterrichtlinien umfassen ACLs, die ihre Verwendung auf bestimmte Benutzer und Gruppen beschränken und somit die Auswahl der Richtlinien bei der Erstellung eines Clusters einschränken.
Wählen Sie zum Konfigurieren einer Clusterrichtlinie die Clusterrichtlinie in der Dropdownliste Richtlinie aus.
Hinweis
Wenn keine Richtlinien im Arbeitsbereich erstellt wurden, wird das Dropdownmenü Richtlinie nicht angezeigt.
Es gilt Folgendes:
- Wenn Sie über die Berechtigung zum Erstellen von Clustern verfügen, können Sie die Richtlinie Unbeschränkt auswählen und vollständig konfigurierbare Cluster erstellen. Die Richtlinie Uneingeschränkt schränkt keinerlei Clusterattribute oder Attributwerte ein.
- Wenn Sie sowohl über die Berechtigung zum Erstellen von Clustern als auch über Zugriff auf Clusterrichtlinien verfügen, können Sie die Richtlinie Uneingeschränkt und die Richtlinien auswählen, auf die Sie Zugriff haben.
- Wenn Sie nur Zugriff auf Clusterrichtlinien haben, können Sie die Richtlinien auswählen, auf die Sie Zugriff haben.
Clustermodus
Hinweis
In diesem Artikel wird die Legacy-Clusterbenutzeroberfläche beschrieben. Informationen zur neuen Cluster-Benutzeroberfläche (in der Vorschau) finden Sie unter Computekonfigurationsreferenz. Dazu gehören einige Terminologieänderungen für Clusterzugriffstypen und -modi. Einen Vergleich der neuen und alten Clustertypen finden Sie unter Änderungen der Clusterbenutzeroberfläche und Clusterzugriffsmodi. Benutzeroberfläche der Vorschauversion:
- Cluster im Standardmodus werden jetzt als Cluster mit Zugriffsmodus „Keine freigegebene Isolation“ bezeichnet.
- Hohe Parallelität mit Tabellen-ACLs wird jetzt Cluster mit Zugriffsmodus „Freigegeben“ genannt.
Azure Databricks unterstützt drei Clustermodi: „Standard“, „Hohe Parallelität“ und Einzelner Knoten. Der standardmäßige Clustermodus lautet „Standard“.
Wichtig
- Wenn Ihr Arbeitsbereich dem Unity Catalog-Metastore zugewiesen ist, sind Cluster mit hoher Parallelität nicht verfügbar. Stattdessen verwenden Sie den Zugriffsmodus, um die Integrität der Zugriffskontrollen sicherzustellen und starke Isolationsgarantien durchzusetzen. Siehe auch Zugriffsmodi.
- Sie können den Clustermodus nicht mehr ändern, nachdem ein Cluster erstellt wurde. Wenn Sie einen anderen Clustermodus verwenden möchten, müssen Sie einen neuen Cluster erstellen.
Die Clusterkonfiguration umfasst eine Einstellung für die automatische Beendigung, deren Standardwert vom Clustermodus abhängt:
- Standard- und Einzelknotencluster werden standardmäßig nach 120 Minuten automatisch beendet.
- Cluster mit hoher Parallelität werden standardmäßig nicht automatisch beendet.
Standardcluster
Warnung
Cluster im Standardmodus (manchmal als „Keine freigegebene Isolation“-Cluster bezeichnet) können von mehreren Benutzern gemeinsam genutzt werden, ohne dass eine Isolation zwischen den Benutzern besteht. Wenn Sie den Clustermodus „Hohe Parallelität“ ohne zusätzliche Sicherheitseinstellungen wie Tabellen-ACLs oder Passthrough für Anmeldeinformationen verwenden, werden dieselben Einstellungen wie bei Clustern im Standardmodus verwendet. Kontoadministratoren können bei diesen Clustertypen verhindern, dass interne Anmeldeinformationen für Databricks-Arbeitsbereichsadministratoren automatisch generiert werden. Wenn Sie sicherere Optionen verwenden möchten, empfiehlt Databricks Alternativen wie Cluster mit hoher Parallelität und Tabellen ACLs.
Ein Standardcluster wird nur für Einzelbenutzer empfohlen. Standardcluster können Workloads ausführen, die in Python, SQL, R und Scala entwickelt wurden.
Cluster mit hoher Parallelität
Ein Cluster mit hoher Parallelität ist eine verwaltete Cloudressource. Der Hauptvorteil von Clustern mit hoher Parallelität besteht darin, dass sie eine differenzierte gemeinsame Nutzung ermöglichen, um eine maximale Ressourcenauslastung und eine minimale Abfragelatenz zu erzielen.
Cluster mit hoher Parallelität können Workloads ausführen, die in SQL, Python und R entwickelt wurden. Die Leistung und Sicherheit von Clustern mit hoher Parallelität wird durch die Ausführung von Benutzercode in separaten Prozessen gewährleistet, was in Scala nicht möglich ist.
Darüber hinaus unterstützen nur Cluster mit hoher Parallelität die Tabellenzugriffssteuerung.
Um einen Cluster mit hoher Parallelität zu erstellen, legen Sie den Clustermodus auf Hohe Parallelität fest.
Einzelknotencluster
Ein Cluster mit einem einzelnen Knoten umfasst keine Worker und führt Spark-Aufträge auf dem Treiberknoten aus.
Im Gegensatz dazu benötigt ein Standard-Cluster neben dem Treiberknoten mindestens einen Spark-Workerknoten, um Spark-Aufträge auszuführen.
Um einen Einzelknotencluster zu erstellen, legen Sie Clustermodus auf Einzelner Knoten fest.
Weitere Informationen zum Arbeiten mit Einzelknotenclustern finden Sie unter Einzel- oder Mehrfachknotencompute.
Pools
Um die Startzeit eines Clusters zu verkürzen, können Sie einen Cluster an einen vordefinierten Pool von im Leerlauf befindlichen Instanzen für die Treiber- und Workerknoten anfügen. Der Cluster wird unter Verwendung der Instanzen in den Pools erstellt. Wenn ein Pool nicht genügend freie Ressourcen aufweist, um die angeforderten Treiber- oder Workerknoten zu erstellen, wird der Pool erweitert, indem neue Instanzen vom Instanzanbieter zugewiesen werden. Wird ein angefügter Cluster beendet, werden die verwendeten Instanzen an die Pools zurückgegeben und können von einem anderen Cluster wiederverwendet werden.
Wenn Sie einen Pool für Workerknoten, nicht jedoch für den Treiberknoten auswählen, erbt der Treiberknoten den Pool der Workerknotenkonfiguration.
Wichtig
Wenn Sie versuchen, einen Pool für den Treiberknoten, nicht jedoch für die Workerknoten auszuwählen, kommt es zu einem Fehler, und Ihr Cluster wird nicht erstellt. Dadurch wird verhindert, dass der Treiberknoten auf die Erstellung von Workerknoten warten muss (oder umgekehrt).
Weitere Informationen zum Arbeiten mit Pools in Azure Databricks finden Sie in der Poolkonfigurationsreferenz.
Databricks Runtime
Databricks-Runtimes sind der Satz an Kernkomponenten, die in Ihren Clustern ausgeführt werden. Alle Databricks-Runtimes enthalten Apache Spark und fügen Komponenten und Updates hinzu, die die Benutzerfreundlichkeit, Leistung und Sicherheit verbessern. Weitere Informationen finden Sie unter Versionshinweise, Versionen und Kompatibilität von Databricks Runtime.
Azure Databricks stellt verschiedene Runtimetypen und unterschiedliche Versionen dieser Runtimetypen in der Dropdownliste Databricks Runtime-Version zur Verfügung, wenn Sie einen Cluster erstellen oder bearbeiten.
Photon-Beschleunigung
Photon ist für Cluster verfügbar, auf denen Databricks Runtime 9.1 LTS und höher ausgeführt wird.
Zum Aktivieren der Photon-Beschleunigung markieren Sie das Kontrollkästchen Photon-Beschleunigung verwenden.
Falls gewünscht, können Sie den Instanztyp in den Dropdownliste „Workertyp“ und „Treibertyp“ angeben.
Für ein optimales Preis-/Leistungsverhältnis empfiehlt Databricks die folgenden Instanztypen:
- Standard_E4ds_v4
- Standard_E8ds_v4
- Standard_E16ds_v4
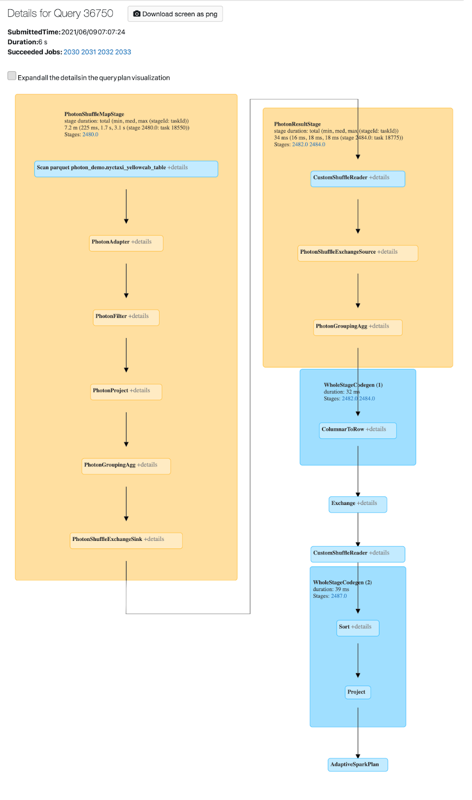
Sie können die Photon-Aktivität auf der Spark-Benutzeroberfläche anzeigen. Der folgende Screenshot zeigt einen gerichteten azyklischen Graphen (DAG) mit den Abfragedetails. Es gibt zwei Hinweise auf Photon im DAG. Zum einen beginnen die Photon-Operatoren mit „Photon“, zum Beispiel PhotonGroupingAgg. Zum anderen sind die Photon-Operatoren und -Phasen im DAG pfirsichfarben dargestellt, während die Nicht-Photon-Operatoren blau dargestellt sind.
Docker-Images
Für einige Databricks Runtime-Versionen können Sie beim Erstellen eines Clusters ein Docker-Image angeben. Zu den Anwendungsbeispielen gehören die Anpassung von Bibliotheken, eine unveränderliche Containerumgebung und die Integration von Docker CI/CD.
Sie können Docker-Images auch verwenden, um benutzerdefinierte Deep-Learning-Umgebungen für Cluster mit GPU-Geräten zu erstellen.
Anweisungen finden Sie unter Anpassen von Containern mit dem Databricks-Containerdienst und Databricks-Containerdienste in GPU-Compute.
Clusterknotentyp
Ein Cluster besteht aus einem Treiberknoten und null oder mehr Workerknoten.
Sie können separate Cloudanbieter-Instanztypen für den Treiber- und den Workerknoten auswählen, auch wenn der Treiberknoten standardmäßig denselben Instanztyp verwendet wie der Workerknoten. Es gibt verschiedene Familien von Instanztypen für unterschiedliche Anwendungsfälle, z. B. speicherintensive oder rechenintensive Workloads.
Hinweis
Wenn Ihre Sicherheitsanforderungen eine Compute-Isolation vorsehen, wählen Sie eine Standard_F72s_V2-Instanz als Ihren Workertyp. Bei diesen Instanztypen handelt es sich um isolierte VMs, die den gesamten physischen Host in Anspruch nehmen und das erforderliche Maß an Isolation bieten, um z. B. Workloads gemäß DoD IL5 (Department of Defense Impact Level 5) zu unterstützen.
Treiberknoten
Der Treiberknoten verwaltet die Zustandsinformationen zu allen an den Cluster angefügten Notebooks. Der Treiberknoten verwaltet außerdem den SparkContext und interpretiert alle Befehle, die Sie von einem Notebook oder einer Bibliothek auf dem Cluster ausführen. Darüber hinaus führt er den Apache Spark-Master aus, der mit den Spark-Executors koordiniert wird.
Der Standardwert für den Treiberknotentyp entspricht dem Workerknotentyp. Sie können einen größeren Treiberknoten mit mehr Arbeitsspeicher wählen, wenn Sie umfangreiche Daten von Spark-Workern erfassen (collect()) und im Notebook analysieren möchten.
Tipp
Da der Treiberknoten alle Zustandsinformationen der angefügten Notebooks verwaltet, sollten Sie sicherstellen, nicht verwendete Notebooks vom Treiberknoten abzukoppeln.
Workerknoten
Azure Databricks Workerknoten führen die Spark-Executors und weitere Dienste aus, die für den ordnungsgemäßen Betrieb des Clusters erforderlich sind. Wenn Sie Ihre Workload mit Spark verteilen, erfolgt die gesamte verteilte Verarbeitung auf Workerknoten. Azure Databricks führt einen Executor pro Workerknoten aus, daher werden die Begriffe Executor und Worker im Zusammenhang mit der Azure Databricks-Architektur austauschbar verwendet.
Tipp
Zum Ausführen eines Spark-Auftrags benötigen Sie mindestens einen Workerknoten. In einem Cluster ohne Worker können Spark-fremde Befehle auf dem Treiberknoten ausgeführt werden, aber für Spark-Befehle kommt es zu Fehlern.
GPU-Instanztypen
Für rechenintensive Aufgaben, die eine hohe Leistung erfordern, beispielsweise im Zusammenhang mit Deep Learning, unterstützt Azure Databricks Cluster, die mit Grafikprozessoren (GPUs) beschleunigt werden. Weitere Informationen finden Sie unter GPU-fähige Computes.
Spot-Instanzen
Um Kosten zu sparen, können Sie sich für die Verwendung von Spot-Instanzen, auch bekannt als Azure Spot-VMs, entscheiden, indem Sie das Kontrollkästchen Spot-Instanzen aktivieren.

Die erste Instanz ist immer bedarfsgesteuert (der Treiberknoten ist immer bedarfsgesteuert), nachfolgende Instanzen sind Spot-Instanzen. Wenn Spot-Instanzen aufgrund von Nichtverfügbarkeit entfernt werden, werden bedarfsgesteuerte Instanzen bereitgestellt, um die entfernten Instanzen zu ersetzen.
Clustergröße und automatische Skalierung
Wenn Sie einen Azure Databricks-Cluster erstellen, können Sie entweder eine feste Anzahl von Workern für den Cluster festlegen oder eine Mindest- und Höchstanzahl von Workern für den Cluster angeben.
Wenn Sie einen Cluster mit fester Größe bereitstellen, stellt Azure Databricks sicher, dass Ihr Cluster die angegebene Anzahl an Workern aufweist. Wenn Sie einen Bereich für die Anzahl von Workern angeben, wählt Databricks die geeignete Anzahl von Workern aus, die für die Ausführung Ihres Auftrags benötigt werden. Dies wird als automatische Skalierung bezeichnet.
Bei der automatischen Skalierung weist Azure Databricks die Worker dynamisch neu zu, um die Merkmale Ihres Auftrags zu berücksichtigen. Bestimmte Abschnitte Ihrer Pipeline können rechenintensiver sein als andere, und Databricks fügt während dieser Phasen Ihres Auftrags automatisch zusätzliche Worker hinzu (und entfernt sie, wenn sie nicht mehr benötigt werden).
Die automatische Skalierung macht es einfacher, eine hohe Clusterauslastung zu erzielen, da Sie den Cluster nicht angepasst an die Workloads bereitstellen müssen. Dies gilt insbesondere für Workloads, deren Anforderungen sich im Laufe der Zeit ändern (z. B. die Erkundung eines Datasets im Laufe eines Tages), aber auch für einmalige Workloads mit kürzerer Laufzeit, deren Bereitstellungsanforderungen unbekannt sind. Die automatische Skalierung bietet somit zwei Vorteile:
- Workloads können schneller ausgeführt werden als mit einem unterdimensionierten Cluster mit fester Größe.
- Durch die automatische Skalierung von Clustern können die Gesamtkosten im Vergleich zu einem Cluster mit fester Größe gesenkt werden.
Abhängig von der festen Größe des Clusters und der Workload bietet Ihnen die automatische Skalierung einen oder beide dieser Vorteile. Die Clustergröße kann unter die ausgewählte Mindestanzahl von Workern sinken, wenn der Cloudanbieter Instanzen beendet. In diesem Fall versucht Azure Databricks fortlaufend, Instanzen erneut bereitzustellen, um die Mindestanzahl an Workern aufrecht zu erhalten.
Hinweis
Die automatische Skalierung steht für spark-submit-Aufträge nicht zur Verfügung.
Verhalten der automatischen Skalierung
- Die Skalierung erfolgt in 2 Schritten vom Mindestwert zum Höchstwert.
- Selbst wenn der Cluster sich im Leerlauf befindet, kann er durch Überprüfung des Status der Shuffledatei verkleinert werden.
- Das Herunterskalieren erfolgt basierend auf einem Prozentsatz der aktuellen Knoten.
- Auftragscluster werden per Skalierung verkleinert, wenn der Cluster in den letzten 40 Sekunden nicht ausgelastet war.
- Universelle Cluster werden herunterskaliert, wenn der Cluster in den letzten 150 Sekunden nicht ausgelastet war.
- Die Spark-Konfigurationseigenschaft
spark.databricks.aggressiveWindowDownSgibt an, wie häufig (in Sekunden) ein Cluster Skalierungsentscheidungen trifft. Das Erhöhen dieses Werts führt dazu, dass ein Cluster langsamer herunterskaliert wird. Der Höchstwert lautet 600.
Aktivieren und Konfigurieren der automatischen Skalierung
Damit Azure Databricks die Größe Ihres Clusters automatisch anpassen kann, aktivieren Sie die automatische Skalierung für den Cluster und geben die minimale und maximale Anzahl von Workern an.
Aktivieren Sie die automatische Skalierung.
Universeller Cluster: Aktivieren Sie auf der Seite „Cluster erstellen“ das Kontrollkästchen Autoskalierung aktivieren im Feld Autopilot-Optionen:

Auftragscluster: Aktivieren Sie auf der Seite „Cluster konfigurieren“ das Kontrollkästchen Autoskalierung aktivieren im Feld Autopilot-Optionen:

Konfigurieren Sie die Mindest- und Höchstanzahl von Workern.

Wenn der Cluster ausgeführt wird, zeigt die Seite mit den Clusterdetails die Anzahl von zugewiesenen Workern an. Sie können die Anzahl von zugewiesenen Workern mit der Workerkonfiguration vergleichen und bei Bedarf Anpassungen vornehmen.
Wichtig
Bei Verwendung eines Instanzpools:
- Stellen Sie sicher, dass die angeforderte Clustergröße kleiner oder gleich der Mindestanzahl von Instanzen im Leerlauf für den Pool ist. Wenn sie größer ist, entspricht die Startzeit des Clusters einem Cluster, der keinen Pool verwendet.
- Stellen Sie sicher, dass die maximale Clustergröße kleiner oder gleich der maximalen Kapazität des Pools ist. Wenn sie größer ist, kann der Cluster nicht erstellt werden.
Beispiel für die automatische Skalierung
Wenn Sie einen statischen Cluster zu einem automatisch skalierenden Cluster umkonfigurieren, passt Azure Databricks die Größe des Clusters sofort innerhalb der Mindest- und Höchstgrenzen an und startet dann die automatische Skalierung. Die folgende Tabelle veranschaulicht beispielsweise, was mit Clustern einer bestimmten Ausgangsgröße geschieht, wenn Sie einen Cluster für die automatische Skalierung zwischen 5 und 10 Knoten neu konfigurieren.
| Ursprüngliche Größe | Größe nach der Neukonfiguration |
|---|---|
| 6 | 6 |
| 12 | 10 |
| 3 | 5 |
Automatische Skalierung des lokalen Speichers
Es ist oft schwierig abzuschätzen, wie viel Speicherplatz auf dem Datenträger ein bestimmter Auftrag beanspruchen wird. Damit Sie beim Erstellen Ihres Clusters nicht selbst schätzen müssen, wie viele GB an verwaltetem Speicherplatz Sie an Ihren Cluster anfügen müssen, aktiviert Azure Databricks automatisch für alle Azure Databricks-Cluster die automatische Skalierung des lokalen Speichers.
Bei der automatischen Skalierung des lokalen Speichers überwacht Azure Databricks die Menge an freiem Speicherplatz, die auf den Spark-Workern Ihres Clusters verfügbar ist. Wenn der Speicherplatz eines Workers knapp wird, fügt Databricks automatisch einen neuen verwalteten Datenträger an den Worker an, bevor der Speicherplatz aufgebraucht ist. Datenträger werden bis zu einer Obergrenze von 5 TB Gesamtspeicherplatz pro VM angefügt (einschließlich des anfänglichen lokalen Speichers der VM).
Die an eine VM angefügten verwalteten Datenträger werden nur getrennt, wenn die VM an Azure zurückgegeben wird. Das heißt, verwaltete Datenträger werden nie von einer VM abgekoppelt, solange sie Teil eines ausgeführten Clusters sind. Zum Herunterskalieren der Nutzung von verwalteten Datenträgern empfiehlt Azure Databricks die Verwendung dieser Funktion in einem Cluster, der mit Clustergröße und automatische Skalierung oder Unerwartete Beendigung konfiguriert ist.
Verschlüsselung lokaler Datenträger
Wichtig
Dieses Feature befindet sich in der Public Preview.
Einige Instanztypen, die Sie zum Ausführen von Clustern verwenden, verfügen möglicherweise über lokal angefügte Datenträger. Azure Databricks kann Shuffledaten oder kurzlebige Daten auf diesen lokal angefügten Datenträgern speichern. Um sicherzustellen, dass alle ruhenden Daten für sämtliche Speichertypen – auch Shuffledaten, die vorübergehend auf den lokalen Datenträgern Ihres Clusters gespeichert werden – verschlüsselt werden, können Sie die Verschlüsselung der lokalen Datenträger aktivieren.
Wichtig
Ihre Workloads werden möglicherweise langsamer ausgeführt, da sich das Lesen und Schreiben verschlüsselter Daten auf und von lokalen Volumes auf die Leistung auswirkt.
Wenn die Verschlüsselung lokaler Datenträger aktiviert ist, generiert Azure Databricks lokal einen Verschlüsselungsschlüssel, der für jeden Clusterknoten eindeutig ist und zum Verschlüsseln aller auf lokalen Datenträgern gespeicherten Daten verwendet wird. Der Schlüssel ist nur lokal für den jeweiligen Clusterknoten gültig und wird zusammen mit dem Clusterknoten selbst zerstört. Während seiner Lebensdauer befindet sich der Schlüssel zur Ver- und Entschlüsselung im Arbeitsspeicher und wird verschlüsselt auf dem Datenträger gespeichert.
Zum Aktivieren der Verschlüsselung lokaler Datenträger müssen Sie die Cluster-API verwenden. Legen Sie während der Clustererstellung oder -bearbeitung Folgendes fest:
{
"enable_local_disk_encryption": true
}
Beispiele für den Aufruf dieser APIs finden Sie in der Cluster-API.
Hier ist ein Beispiel für einen Aufruf zur Clustererstellung, der die Verschlüsselung lokaler Datenträger aktiviert:
{
"cluster_name": "my-cluster",
"spark_version": "7.3.x-scala2.12",
"node_type_id": "Standard_D3_v2",
"enable_local_disk_encryption": true,
"spark_conf": {
"spark.speculation": true
},
"num_workers": 25
}
Sicherheitsmodus
Wenn Ihr Arbeitsbereich einem Unity Catalog-Metastore zugewiesen ist, verwenden Sie den Sicherheitsmodus anstelle des Clustermodus mit hoher Parallelität, um die Integrität der Zugriffssteuerungen sicherzustellen und strikte Isolationsgarantien zu erzwingen. Der Clustermodus für hohe Parallelität ist im Unity Catalog nicht verfügbar.
Treffen Sie unter Erweiterte Optionen eine Auswahl aus den folgenden Clustersicherheitsmodi:
- None (Keine): Keine Isolation. Erzwingt keine lokale Tabellenzugriffssteuerung für Arbeitsbereiche oder ein Passthrough für Anmeldeinformationen. Kein Zugriff auf Unity Catalog-Daten möglich.
- Single User (Einzelbenutzer): Kann nur von einem einzelnen Benutzer bzw. einer einzelnen Benutzerin verwendet werden (standardmäßig der oder die Benutzer*in, der oder die den Cluster erstellt hat). Für andere Benutzer*innen ist kein Anfügen an den Cluster möglich. Beim Zugriff auf eine Sicht über einen Cluster mit dem Sicherheitsmodus Single User (Einzelbenutzer) wird die Sicht mit den entsprechenden Benutzerberechtigungen ausgeführt. Einzelne Benutzercluster unterstützen Workloads mit Python, Scala und R. Init-Skripts, Bibliotheksinstallationen und DBFS-Bereitstellungen werden auf einzelnen Benutzerclustern unterstützt. Automatisierte Aufträge sollten einzelne Benutzercluster verwenden.
- User Isolation (Benutzerisolation): Kann von mehreren Benutzer*innen gemeinsam verwendet werden. Es werden ausschließlich SQL-Workloads unterstützt. Bibliotheksinstallation, Initialisierungsskripts und DBFS-Bereitstellungen sind deaktiviert, um eine strikte Isolation zwischen den Clusterbenutzern zu erzwingen.
- Table ACL only (Legacy) (Nur Tabellen-ACL [Legacy]): Erzwingt die lokale Tabellenzugriffssteuerung im Arbeitsbereich, ermöglicht jedoch keinen Zugriff auf Unity Catalog-Daten.
- Passthrough only (Legacy) (Nur Passthrough [Legacy]): Erzwingt das lokale Anmeldeinformationen-Passthrough im Arbeitsbereich, ermöglicht jedoch keinen Zugriff auf Unity Catalog-Daten.
Für Unity Catalog-Workloads werden lediglich die Sicherheitsmodi Single User (Einzelbenutzer) und User Isolation (Benutzerisolation) unterstützt.
Weitere Informationen finden Sie unter Zugriffsmodi.
Spark-Konfiguration
Um Spark-Aufträge zu optimieren, können Sie benutzerdefinierte Spark-Konfigurationseigenschaften in einer Clusterkonfiguration angeben.
Klicken Sie auf der Seite „Clusterkonfiguration“ auf die Umschaltfläche Erweiterte Optionen.
Klicken Sie auf die Registerkarte Spark.
Geben Sie in der Spark-Konfiguration die Konfigurationseigenschaften als ein Schlüssel-Wert-Paar pro Zeile ein.
Wenn Sie einen Cluster mit der Cluster-API konfigurieren, legen Sie Spark-Eigenschaften im Feld spark_conf in der API zum Erstellen neuer Cluster oder der API zum Aktualisieren der Clusterkonfiguration fest.
Databricks rät von der Verwendung globaler Initialisierungsskripts ab.
Um Spark-Eigenschaften für alle Cluster festzulegen, erstellen Sie ein globales Initialisierungsskript:
dbutils.fs.put("dbfs:/databricks/init/set_spark_params.sh","""
|#!/bin/bash
|
|cat << 'EOF' > /databricks/driver/conf/00-custom-spark-driver-defaults.conf
|[driver] {
| "spark.sql.sources.partitionOverwriteMode" = "DYNAMIC"
|}
|EOF
""".stripMargin, true)
Abrufen einer Spark-Konfigurationseigenschaft aus einem Geheimnis
Databricks empfiehlt, vertrauliche Informationen wie Kennwörter nicht als Klartext, sondern in einem Geheimnis zu speichern. Verwenden Sie die folgende Syntax, um auf ein Geheimnis in der Spark-Konfiguration zu verweisen:
spark.<property-name> {{secrets/<scope-name>/<secret-name>}}
Verwenden Sie beispielsweise folgenden Code, um eine Spark-Konfigurationseigenschaft namens password auf den Wert des in secrets/acme_app/password gespeicherten Geheimnisses festzulegen:
spark.password {{secrets/acme-app/password}}
Weitere Informationen finden Sie unter Verwalten von geheimen Schlüsseln.
Umgebungsvariablen
Sie können benutzerdefinierte Umgebungsvariablen konfigurieren, auf die Sie über Initialisierungsskripts zugreifen können, die in einem Cluster ausgeführt werden. Databricks bietet auch vordefinierte Umgebungsvariablen, die Sie in Initialisierungsskripts verwenden können. Sie können diese vordefinierten Umgebungsvariablen nicht außer Kraft setzen.
Klicken Sie auf der Seite „Clusterkonfiguration“ auf die Umschaltfläche Erweiterte Optionen.
Klicken Sie auf die Registerkarte Spark.
Legen Sie die Umgebungsvariablen im Feld Umgebungsvariablen fest.
Sie können auch Umgebungsvariablen mithilfe des Felds spark_env_vars in der API zum Erstellen neuer Cluster oder der API zum Aktualisieren der Clusterkonfiguration festlegen.
Clustertags
Mit Clustertags können Sie die Kosten von Cloudressourcen, die von verschiedenen Gruppen in Ihrer Organisation genutzt werden, problemlos überwachen. Sie können Tags als Schlüssel-Wert-Paare angeben, wenn Sie einen Cluster erstellen, und Azure Databricks wendet diese Tags auf Cloudressourcen wie VMs und Datenträgervolumes sowie auf DBU-Nutzungsberichte an.
Bei Clustern, die aus Pools gestartet werden, werden die benutzerdefinierten Clustertags nur auf DBU-Nutzungsberichte angewendet und nicht an Cloudressourcen weitergegeben.
Ausführliche Informationen dazu, wie Pool- und Clustertagtypen zusammenarbeiten, finden Sie unter Attributverwendung mithilfe von Tags.
Der Einfachheit halber wendet Azure Databricks vier Standardtags auf jeden Cluster an: Vendor, Creator, ClusterName und ClusterId.
Darüber hinaus wendet Azure Databricks auf Auftragscluster die zwei Standardtags RunName und JobId an.
Auf Ressourcen, die von Databricks SQL verwendet werden, wendet Azure Databricks außerdem das Standardtag SqlWarehouseId an.
Warnung
Weisen Sie einem Cluster kein benutzerdefiniertes Tag mit dem Schlüssel Name zu. Jeder Cluster verfügt über ein Tag Name, dessen Wert von Azure Databricks festgelegt wird. Wenn Sie den Wert für den Schlüssel Name ändern, kann der Cluster nicht mehr von Azure Databricks nachverfolgt werden. Dies hat zur Folge, dass der Cluster im Leerlauf möglicherweise nicht beendet wird, sodass weiterhin Nutzungskosten anfallen.
Sie können benutzerdefinierte Tags hinzufügen, wenn Sie einen Cluster erstellen. So konfigurieren Sie Clustertags
Klicken Sie auf der Seite „Clusterkonfiguration“ auf die Umschaltfläche Erweiterte Optionen.
Klicken Sie unten auf der Seite auf die Registerkarte Tags.

Fügen Sie für jedes benutzerdefinierte Tag ein Schlüssel-Wert-Paar hinzu. Sie können bis zu 43 benutzerdefinierte Tags hinzufügen.
SSH-Zugriff auf Cluster
Aus Sicherheitsgründen ist der SSH-Port in Azure Databricks standardmäßig geschlossen. Wenn Sie den SSH-Zugriff auf Ihre Spark-Cluster aktivieren möchten, wenden Sie sich an Azure Databricks-Support.
Hinweis
SSH kann nur aktiviert werden, wenn Ihr Arbeitsbereich in Ihrem eigenen virtuellen Azure-Netzwerk bereitgestellt wird.
Übermittlung des Clusterprotokolls
Beim Erstellen eines Clusters können Sie einen Speicherort angeben, an dem die Protokolle für den Spark-Treiberknoten, die Workerknoten und die Ereignisse bereitgestellt werden. Protokolle werden alle fünf Minuten an das ausgewählte Ziel übermittelt. Wenn ein Cluster beendet wird, garantiert Azure Databricks die Bereitstellung aller bis zur Beendigung des Clusters erstellten Protokolle.
Das Ziel der Protokolle hängt von der Cluster-ID ab. Wenn das angegebene Ziel dbfs:/cluster-log-delivery lautet, werden die Clusterprotokolle für 0630-191345-leap375 in dbfs:/cluster-log-delivery/0630-191345-leap375 bereitgestellt.
So konfigurieren Sie den Speicherort für die Protokollbereitstellung
Klicken Sie auf der Seite „Clusterkonfiguration“ auf die Umschaltfläche Erweiterte Optionen.
Klicken Sie auf die Registerkarte Protokollierung.
Wählen Sie einen Zieltyp aus.
Geben Sie den Clusterprotokollpfad ein.
Hinweis
Dieses Feature ist auch in der REST-API verfügbar. Weitere Informationen finden Sie unter Cluster-API.
Initskripts
Ein Skript zur Clusterknoteninitialisierung – oder Initialisierungsskript – ist ein Shellskript, das beim Start der einzelnen Clusterknoten ausgeführt wird, bevor die JVM des Spark-Treibers oder -Workers gestartet wird. Sie können Initialisierungsskripts unter anderem für folgende Aufgaben verwenden: Installieren von Paketen und Bibliotheken, die nicht in der Databricks-Laufzeitumgebung enthalten sind, Ändern des JVM-Systemklassenpfads, Festlegen von Systemeigenschaften und Umgebungsvariablen, die von der JVM verwendet werden, oder Ändern der Spark-Konfigurationsparameter.
Sie können Initialisierungsskripts an einen Cluster anfügen, indem Sie den Abschnitt Erweiterte Optionen erweitern und auf die Registerkarte Initialisierungsskripts klicken.
Ausführliche Anweisungen finden Sie unter Was sind Initskripts?.