Attributverwendung mithilfe von Tags
In diesem Artikel wird erläutert, wie Benutzerdefinierte und Standardtags verwendet werden, um Workloads bestimmten Arbeitsbereichen, Teams, Projekten und Benutzern zuzuordnen.
Um die Kosten zu überwachen und die Nutzung von Azure Databricks den Geschäftsbereichen und Teams Ihrer Organisation genau zuzuordnen (z. B. für Rückbuchungen), können Sie Arbeitsbereiche (Ressourcengruppen) und Computeressourcen mit Tags versehen. Diese Tags werden an detaillierte Kostenanalyseberichte verteilt, auf die Sie im Azure-Portal zugreifen können. Hinweis: Tagdaten können global repliziert werden. Verwenden Sie keine Tagnamen oder Werte, die die Sicherheit Ihrer Ressourcen gefährden könnten. Verwenden Sie beispielsweise keine Tagnamen, die personenbezogene oder vertrauliche Informationen enthalten.
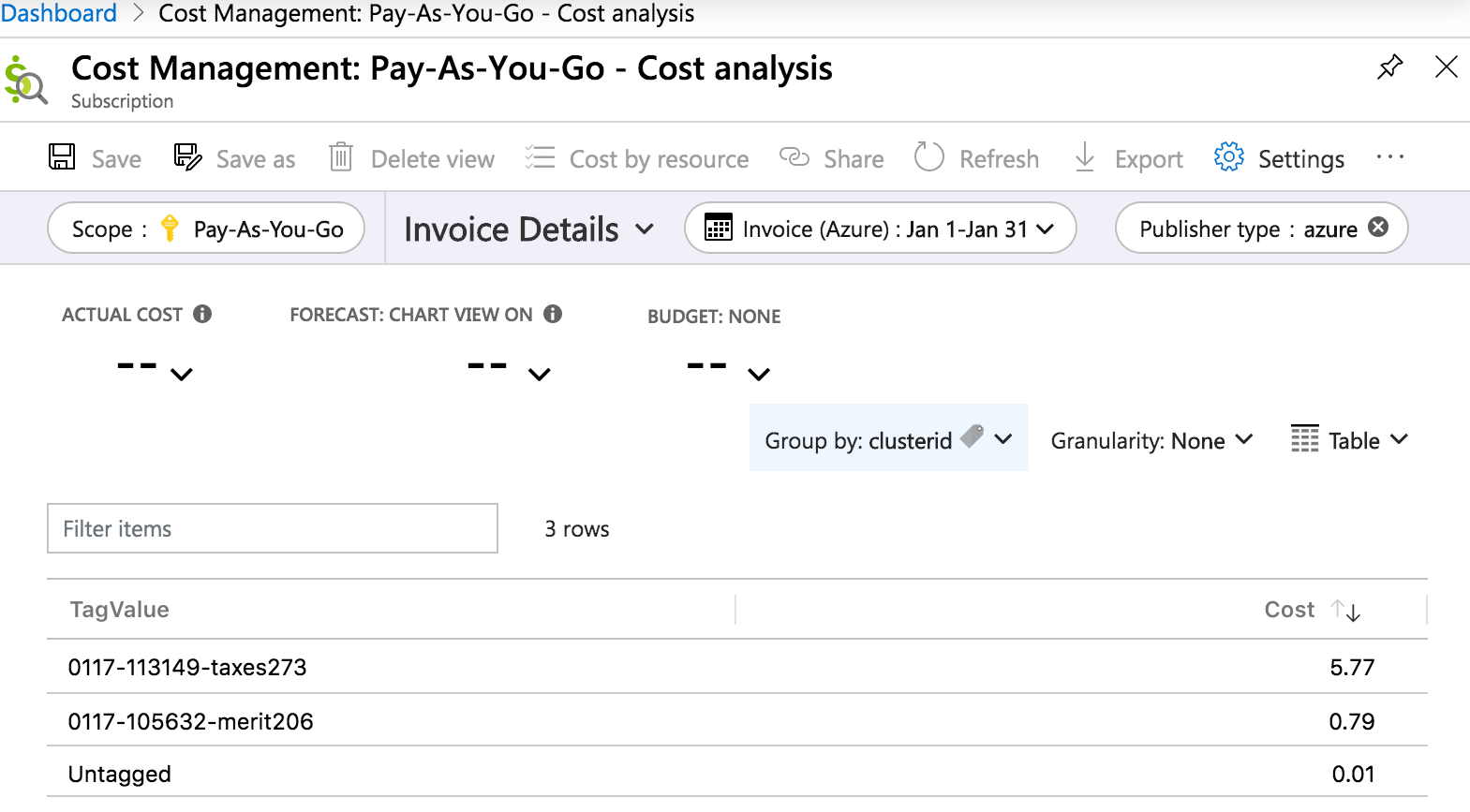
Hier sehen Sie einen Bericht mit den Rechnungsdetails der Kostenanalyse im Azure-Portal, in dem die Kosten nach clusterid-Tag für einen Zeitraum von einem Monat angegeben werden:
Markierte Objekte und Ressourcen
| Object | Taggingschnittstelle (UI) | Taggingschnittstelle (API) |
|---|---|---|
| Arbeitsbereich | Azure-Portal | Azure-Ressourcen-API |
| Pool | Pool-Benutzeroberfläche im Azure Databricks-Arbeitsbereich | Instanzpool-API |
| All-Purpose Compute und Job Compute | Compute-Benutzeroberfläche im Azure Databricks-Arbeitsbereich | Cluster-API |
| SQL-Warehouse | SQL-Warehouse-Benutzeroberfläche im Azure Databricks-Arbeitsbereich | Warehouses-API |
Warnung
Weisen Sie einem Cluster kein benutzerdefiniertes Tag mit dem Schlüssel Name zu. Jeder Cluster verfügt über ein Tag Name, dessen Wert von Azure Databricks festgelegt wird. Wenn Sie den Wert für den Schlüssel Name ändern, kann der Cluster nicht mehr von Azure Databricks nachverfolgt werden. Dies hat zur Folge, dass der Cluster im Leerlauf möglicherweise nicht beendet wird, sodass weiterhin Nutzungskosten anfallen.
Standardtags
Azure Databricks fügt All-Purpose Compute die folgenden Standardtags hinzu:
| Tagschlüssel | Wert |
|---|---|
Vendor |
Konstanter Wert: Databricks |
ClusterId |
Interne Azure Databricks-ID des Clusters |
ClusterName |
Name des Clusters |
Creator |
Benutzername (E-Mail-Adresse) des Benutzers, der den Cluster erstellt hat |
In Auftragsclustern wendet Azure Databricks auch die folgenden Standardtags an:
| Tagschlüssel | Wert |
|---|---|
RunName |
Auftragsname |
JobId |
Auftrags-ID |
Azure Databricks fügt allen Pools die folgenden Standardtags hinzu:
| Tagschlüssel | Wert |
|---|---|
Vendor |
Konstanter Wert: Databricks |
DatabricksInstancePoolCreatorId |
Interne Azure Databricks-ID des Benutzers, der den Pool erstellt hat |
DatabricksInstancePoolId |
Interne Azure Databricks-ID des Pools |
Auf Computeressourcen, die von Lakehouse Monitoring verwendet werden, wendet Azure Databricks auch die folgenden Tags an:
| Tagschlüssel | Wert |
|---|---|
LakehouseMonitoring |
true |
LakehouseMonitoringTableId |
ID der überwachten Tabelle |
LakehouseMonitoringWorkspaceId |
ID des Arbeitsbereichs, in dem der Monitor erstellt wurde |
LakehouseMonitoringMetastoreId |
ID des Metastores, in dem die überwachte Tabelle vorhanden ist |
Markieren von serverlosen Computeworkloads
Wichtig
Dieses Feature befindet sich in Public Preview.
Um serverlose Computeverwendung für Benutzer, Gruppen oder Projekte zuzuordnen, können Sie Budgetrichtlinien verwenden. Wenn einem Benutzer eine Budgetrichtlinie zugewiesen wird, wird die serverlose Verwendung automatisch mit den Tags der Richtlinie markiert. Siehe Attributserverlose Verwendung mit Budgetrichtlinien.
Tagweitergabe
Arbeitsbereichs-, Pool- und Clustertags werden von Azure Databricks aggregiert und für Berichte zur Kostenanalyse an Azure-VMs weitergegeben. Pool- und Clustertags werden jedoch unterschiedlich voneinander weitergegeben.
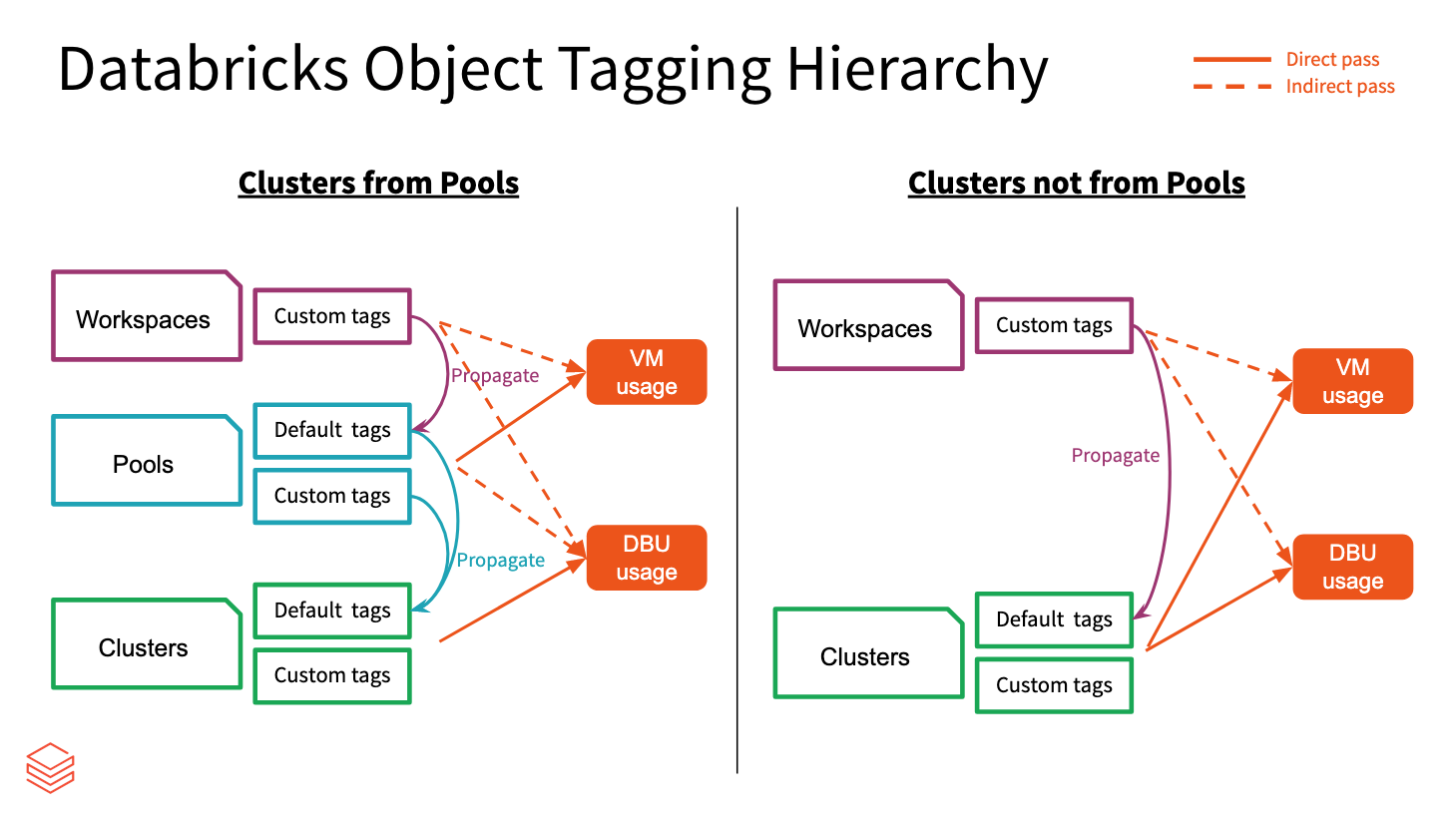
Arbeitsbereichs- und Pooltags werden aggregiert und als Ressourcentags der Azure-VMs zugewiesen, die die Pools hosten.
Arbeitsbereichs- und Clustertags werden aggregiert und als Ressourcentags der Azure-VMs zugewiesen, die die Cluster hosten.
Wenn Cluster aus Pools erstellt werden, werden nur Arbeitsbereichstags und Pooltags an die VMs weitergegeben. Clustertags werden nicht weitergegeben, um die Startleistung des Poolclusters beizubehalten.
Tagkonfliktlösung
Wenn ein benutzerdefiniertes Clustertag, Pooltag oder Arbeitsbereichstag den gleichen Namen wie ein Standardcluster- oder Pooltag von Azure Databricks hat, wird dem benutzerdefinierten Tag bei der Verteilung ein x_ vorangestellt.
Wenn ein Arbeitsbereich beispielsweise mit vendor = Azure Databricksgekennzeichnet ist, steht dieses Tag in Konflikt mit dem Standardclustertag vendor = Databricks. Die Tags werden daher als x_vendor = Azure Databricks und vendor = Databricksweitergegeben.
Einschränkungen
- Es kann bis zu einer Stunde dauern, bis benutzerdefinierte Arbeitsbereichstags nach jeder Änderung an Azure Databricks weitergeleitet werden.
- Einer Azure-Ressource können nicht mehr als 50 Tags zugewiesen werden. Wenn die Gesamtanzahl aggregierter Tags diesen Grenzwert überschreitet, werden Tags mit dem Präfix
x_in alphabetischer Reihenfolge ausgewertet, und Tags, die den Grenzwert überschreiten, werden ignoriert. Wenn alle Tags mit dem Präfixx_ignoriert werden und die Anzahl über dem Limit des Grenzwerts liegt, werden die verbleibenden Tags in alphabetischer Reihenfolge ausgewertet, und Tags, die den Grenzwert überschreiten, werden ignoriert. - Tagtasten und -werte können nur Buchstaben, Leerzeichen, Zahlen oder die Zeichen
+, , ,-,=,._, .:/@Tags, die andere Zeichen enthalten, sind ungültig. - Wenn Sie Tagschlüsselnamen oder -werte ändern, werden diese Änderungen erst nach dem Neustart des Clusters oder der Poolerweiterung wirksam.
- Wenn Konflikte zwischen den benutzerdefinierten Tags des Clusters und den benutzerdefinierten Tags des Pools auftreten, kann der Cluster nicht erstellt werden.
- Neu hinzugefügte Arbeitsbereichstags werden nicht automatisch auf vorhandene Rechenressourcen übertragen. Wenn Sie neue Tags übertragen möchten, öffnen Sie die Detailseite der Computeressource, klicken Sie auf Bearbeiten, und wählen Sie dann Bestätigen und neu starten aus.
Best Practices für das Tagging
- Da Tags manuell eingegeben werden können, sollte Ihre Organisation die Schlüsselwertpaare standardisieren. Databricks empfiehlt die Entwicklung einer Geschäftsrichtlinie für die Benennung von Schlüsseln und Werten, die Sie für alle Benutzer und Benutzerinnen freigeben können.
- Alle Ressourcen sollten mit allgemeinen Schlüsseln markiert werden, die den Verbrauch einer Geschäftseinheit oder einem Projekt zuordnen. Beispielsweise kann eine vom Finanzteam für das Jahresbudget erstellte Auftragscomputeressource die Tags
business-unit:financeundproject:annual-budgetenthalten. - Um präzisere Erkenntnisse zu gewinnen, weisen Sie Tags mit hochspezifischen Schlüsseln zu. Sie können z. B. Schlüssel basierend auf Rollen, Produkten, Diensten oder Kunden erstellen.
- Gegebenenfalls sollten Administratoren von Arbeitsbereichen Tags mithilfe von Rechenrichtlinien und Budgetrichtlinien erzwingen. Weitere Informationen finden Sie unter Erzwingung benutzerdefinierter Tags.