Tutorial: Kopieren von Daten auf Azure Data Box Heavy über NFS
In diesem Tutorial erfahren Sie, wie Sie über die lokale Webbenutzeroberfläche eine Verbindung herstellen und Daten von Ihrem Hostcomputer auf Ihr Azure Data Box Heavy-Gerät kopieren.
In diesem Tutorial lernen Sie Folgendes:
- Voraussetzungen
- Herstellen einer Verbindung mit Data Box Heavy
- Kopieren von Daten auf Data Box Heavy
Voraussetzungen
Stellen Sie Folgendes sicher, bevor Sie beginnen:
- Sie haben die Schritte unter Tutorial: Verkabeln und Herstellen einer Verbindung mit der Azure Data Box ausgeführt.
- Sie haben Ihr Data Box Heavy-Gerät erhalten, und die Bestellung wird im Portal mit dem Status Geliefert angezeigt.
- Sie verfügen über einen Hostcomputer mit den Daten, die Sie auf Data Box Heavy kopieren möchten. Für Ihren Hostcomputer müssen die folgenden Bedingungen erfüllt sein:
- Es muss ein unterstütztes Betriebssystem ausgeführt werden.
- Er muss mit einem Hochgeschwindigkeitsnetzwerk verbunden sein. Zur Erzielung der höchstmöglichen Kopiergeschwindigkeit können zwei 40-GbE-Verbindungen (jeweils eine pro Knoten) parallel genutzt werden. Falls Sie über keine 40-GbE-Verbindung verfügen, sollten Sie zwei Verbindungen mit mindestens 10 GbE verwenden (jeweils eine pro Knoten).
Herstellen einer Verbindung mit Data Box Heavy
Je nach ausgewähltem Speicherkonto erstellt Data Box Heavy bis zu:
- Drei Freigaben für jedes verknüpfte Speicherkonto für GPv1 und GPv2
- Eine Freigabe für Storage Premium
- Eine Freigabe für das Blob Storage-Konto
Diese Freigaben werden auf beiden Knoten des Geräts erstellt.
Unter Blockblob- und Seitenblobfreigaben:
- Entitäten der ersten Ebene sind Container.
- Entitäten der zweiten Ebene sind Blobs.
Unter Freigaben für Azure Files:
- Entitäten der ersten Ebene sind Freigaben.
- Entitäten der zweiten Ebene sind Dateien.
Die folgende Tabelle enthält den UNC-Pfad zu den Freigaben auf Ihrem Data Box Heavy-Gerät und die Azure Storage-Pfad-URL für den Datenupload. Die endgültige URL des Azure Storage-Pfads kann aus dem UNC-Freigabepfad abgeleitet werden.
| Storage | UNC-Pfad |
|---|---|
| Azure-Blockblobs | //<DeviceIPAddress>/<StorageAccountName_BlockBlob>/<ContainerName>/files/a.txthttps://<StorageAccountName>.blob.core.windows.net/<ContainerName>/files/a.txt |
| Azure-Seitenblobs | //<DeviceIPAddress>/<StorageAccountName_PageBlob>/<ContainerName>/files/a.txthttps://<StorageAccountName>.blob.core.windows.net/<ContainerName>/files/a.txt |
| Azure Files | //<DeviceIPAddress>/<StorageAccountName_AzFile>/<ShareName>/files/a.txthttps://<StorageAccountName>.file.core.windows.net/<ShareName>/files/a.txt |
Wenn Sie einen Linux-Hostcomputer verwenden, führen Sie die folgenden Schritte aus, um Ihr Gerät für NFS-Clientzugriff zu konfigurieren:
Geben Sie die IP-Adressen der zulässigen Clients an, die auf die Freigabe zugreifen können. Wechseln Sie in der lokalen Webbenutzeroberfläche zur Seite Verbindung herstellen und Daten kopieren. Klicken Sie unter NFS-Einstellungen auf NFS-Clientzugriff.
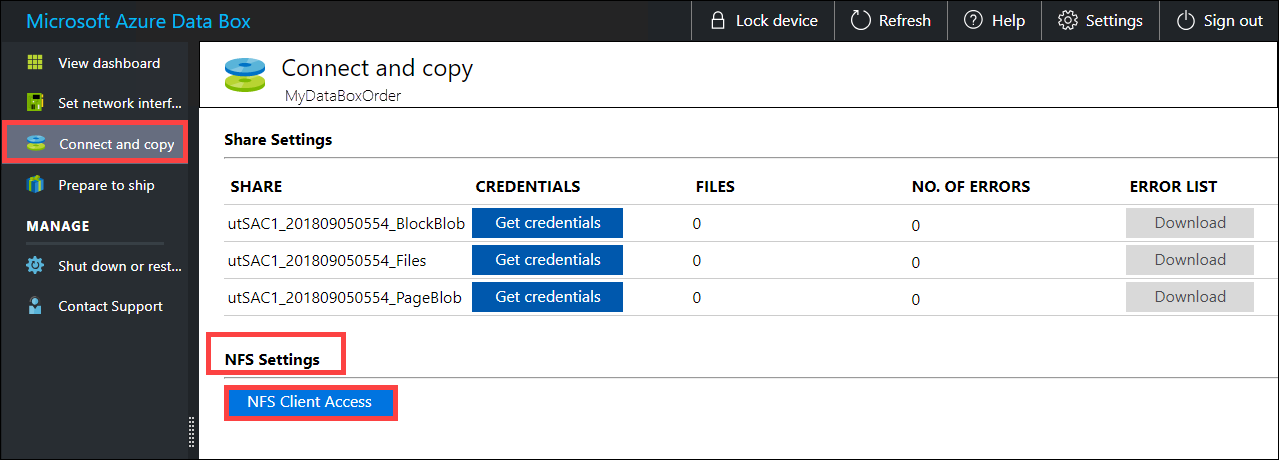
Geben Sie die IP-Adresse des NFS-Clients an, und klicken Sie auf Hinzufügen. Sie können den Zugriff für mehrere NFS-Clients konfigurieren, indem Sie diesen Schritt wiederholen. Klicken Sie auf OK.
Stellen Sie sicher, dass auf dem Linux-Hostcomputer eine unterstützte Version des NFS-Clients installiert ist. Verwenden Sie die jeweilige Version für Ihre Linux-Distribution.
Führen Sie nach der Installation des NFS-Clients den folgenden Befehl aus, um die NFS-Freigabe auf Ihrem Data Box-Gerät einzubinden:
sudo mount <Data Box Heavy device IP>:/<NFS share on Data Box Heavy device> <Path to the folder on local Linux computer>Das folgende Beispiel zeigt, wie Sie über NFS eine Verbindung mit einer Data Box Heavy-Freigabe herstellen. Die IP-Adresse von Data Box Heavy lautet
10.161.23.130, und die FreigabeMystoracct_Blobwird in den virtuellen Ubuntu-Computer eingebunden (Einbindungspunkt:/home/databoxheavyubuntuhost/databoxheavy).sudo mount -t nfs 10.161.23.130:/Mystoracct_Blob /home/databoxheavyubuntuhost/databoxheavyFür Mac-Clients müssen Sie eine zusätzliche Option wie folgt hinzufügen:
sudo mount -t nfs -o sec=sys,resvport 10.161.23.130:/Mystoracct_Blob /home/databoxheavyubuntuhost/databoxheavyErstellen Sie immer einen Ordner für die Dateien, die Sie unter die Freigabe kopieren möchten, und kopieren Sie die Dateien dann in diesen Ordner. Der Ordner, der unter der Blockblob- und der Seitenblob Freigabe erstellt wurde, entspricht einem Container, in den Daten als Blobs hochgeladen werden. Es ist nicht möglich, Dateien direkt in den root-Ordner im Speicherkonto zu kopieren.
Kopieren von Daten auf Data Box Heavy
Nachdem Sie eine Verbindung mit den Data Box Heavy-Freigaben hergestellt haben, müssen im nächsten Schritt die Daten kopiert werden. Bevor Sie mit dem Kopieren der Daten beginnen, sollten Sie folgende Aspekte beachten:
Stellen Sie sicher, dass Sie die Daten in Freigaben kopieren, die das richtige Datenformat aufweisen. Kopieren Sie beispielsweise die Blockblobdaten in die Freigabe für Blockblobs. Kopieren Sie VHDs in Seitenblobs. Wenn das Datenformat nicht mit dem entsprechenden Freigabetyp übereinstimmt, tritt später beim Hochladen der Daten in Azure ein Fehler auf.
Achten Sie beim Kopieren der Daten auf die Einhaltung der Größenbeschränkungen, die im Artikel zu den Grenzwerten für Azure Storage und Data Box Heavy beschrieben sind.
Falls von Data Box Heavy hochgeladene Daten gleichzeitig von anderen Anwendungen außerhalb von Data Box Heavy hochgeladen werden, kann dies zu Fehlern bei Uploadaufträgen und zu Datenbeschädigungen führen.
Es wird empfohlen, SMB und NFS nicht gleichzeitig zu verwenden und Daten nicht an dasselbe Endziel in Azure zu kopieren. In solchen Fällen kann das endgültige Ergebnis nicht bestimmt werden.
Erstellen Sie immer einen Ordner für die Dateien, die Sie unter die Freigabe kopieren möchten, und kopieren Sie die Dateien dann in diesen Ordner. Der Ordner, der unter der Blockblob- und der Seitenblob Freigabe erstellt wurde, entspricht einem Container, in den Daten als Blobs hochgeladen werden. Es ist nicht möglich, Dateien direkt in den root-Ordner im Speicherkonto zu kopieren.
Bei der Erfassung von groß- und kleinschreibungsabhängigen Verzeichnis- und Dateinamen aus einer NFS-Freigabe in NFS auf einem Data Box Heavy-Gerät gilt Folgendes:
- Die Groß-/Kleinschreibung im Namen wird beibehalten.
- Bei den Dateien wird die Groß-/Kleinschreibung nicht berücksichtigt.
Falls Sie also beispielsweise
SampleFile.txtundSamplefile.Txtauf das Gerät kopieren, bleiben die Groß-/Kleinbuchstaben im Namen erhalten. Die zweite Datei überschreibt jedoch die erste, da sie als die gleiche Datei betrachtet wird.
Wenn Sie einen Linux-Hostcomputer verwenden, verwenden Sie ein Kopierhilfsprogramm wie Robocopy. Einige der verfügbaren Alternativen in Linux sind rsync, FreeFileSync, Unison oder Ultracopier.
Der cp-Befehl ist eine der besten Optionen zum Kopieren eines Verzeichnisses. Weitere Informationen zur Verwendung finden Sie auf den Handbuchseiten zum cp-Befehl.
Befolgen Sie die nachstehenden Richtlinien, wenn Sie die rsync-Option für einen Multithread-Kopiervorgang verwenden:
Installieren Sie je nach Dateisystem, das Ihr Linux-Client verwendet, das CIFS Utils- oder NFS Utils-Paket.
sudo apt-get install cifs-utilssudo apt-get install nfs-utilsInstallieren Sie Rsync und Parallel (variiert abhängig von der Linux-Version).
sudo apt-get install rsyncsudo apt-get install parallelErstellen Sie einen Bereitstellungspunkt.
sudo mkdir /mnt/databoxheavyBinden Sie das Volume ein.
sudo mount -t NFS4 //Databox-heavy-IP-Address/share_name /mnt/databoxheavySpiegeln Sie die Verzeichnisstruktur des Ordners.
rsync -za --include='*/' --exclude='*' /local_path/ /mnt/databoxheavyKopieren Sie Dateien.
cd /local_path/; find -L . -type f | parallel -j X rsync -za {} /mnt/databoxheavy/{}Hierbei gibt j die Anzahl von Parallelisierungen und X die Anzahl paralleler Kopien an.
Wir empfehlen, mit 16 parallelen Kopien zu beginnen und die Anzahl von Threads je nach verfügbaren Ressourcen zu erhöhen.
Wichtig
Folgende Linux-Dateitypen werden nicht unterstützt: symbolische Verknüpfungen, Zeichendateien, Blockdateien, Sockets und Pipes. Diese Dateitypen führen zu Fehlern bei der Versandvorbereitung.
Öffnen Sie den Zielordner, um die kopierten Dateien anzuzeigen und zu überprüfen. Falls während des Kopierprozesses Fehler auftreten, laden Sie zur Problembehandlung die Fehlerdateien herunter. Weitere Informationen finden Sie unter View error log during data copy (Anzeigen des Fehlerprotokolls beim Kopieren von Daten). Eine detaillierte Liste mit Fehlern beim Kopieren von Dateien finden Sie unter Troubleshoot issues related to Azure Data Box and Azure Data Box Heavy (Behandeln von Problemen mit Azure Data Box und Azure Data Box Heavy).
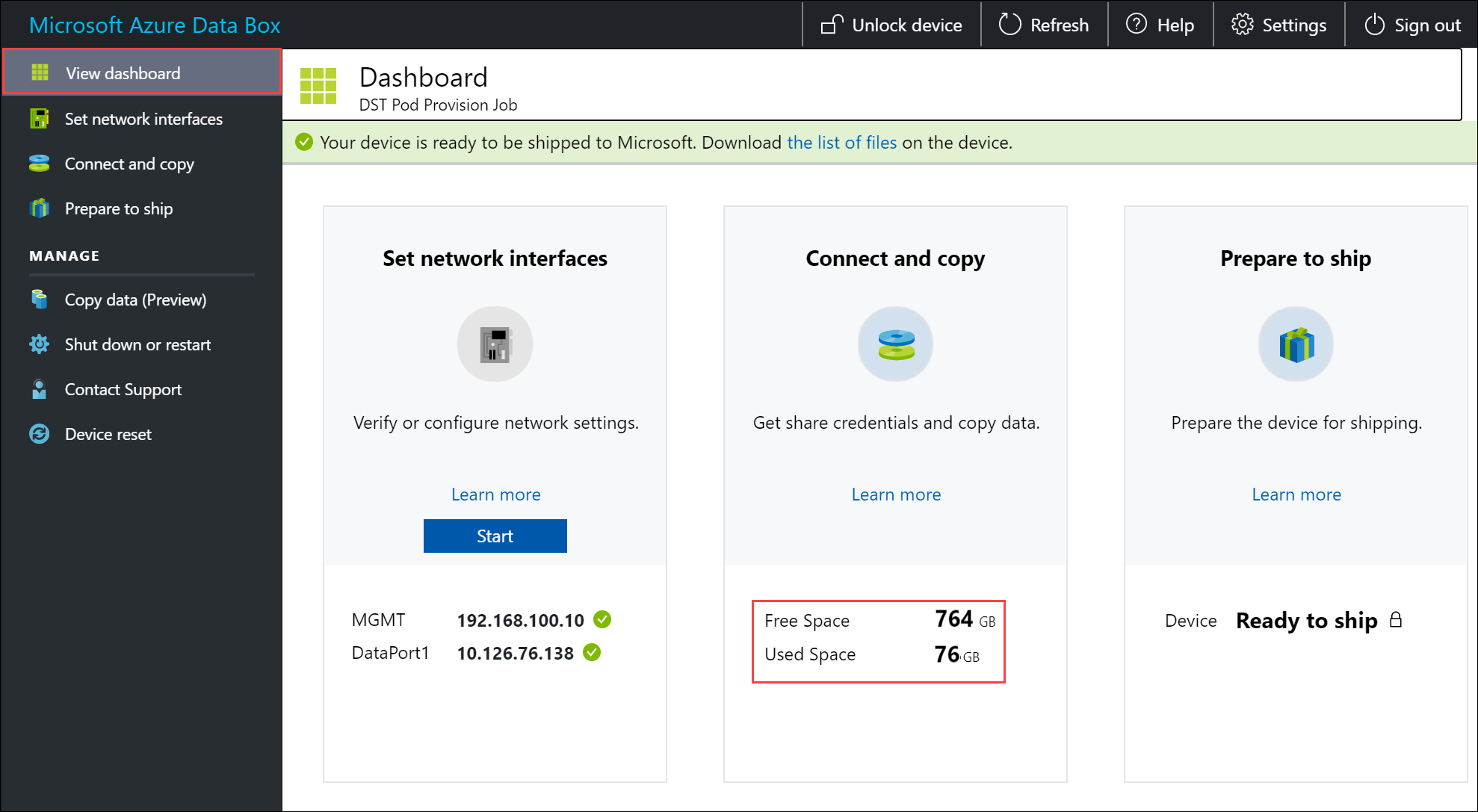
Um die Datenintegrität zu gewährleisten, wird inline eine Prüfsumme berechnet, während die Daten kopiert werden. Überprüfen Sie nach Abschluss des Kopiervorgangs den belegten Speicherplatz und den freien Speicherplatz auf Ihrem Gerät.
Nächste Schritte
In diesem Tutorial wurden unter anderem folgende Informationen zu Azure Data Box Heavy vermittelt:
- Voraussetzungen
- Herstellen einer Verbindung mit Data Box Heavy
- Kopieren von Daten auf Data Box Heavy
Fahren Sie mit dem nächsten Tutorial fort, um zu erfahren, wie Sie Ihre Data Box zurück an Microsoft senden.