Senkentransformation in einem Zuordnungsdatenfluss
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Datenflüsse sind sowohl in Azure Data Factory als auch in Azure Synapse-Pipelines verfügbar. Dieser Artikel gilt für Zuordnungsdatenflüsse. Wenn Sie noch nicht mit Transformationen arbeiten, lesen Sie den Einführungsartikel Transformieren von Daten mit einem Zuordnungsdatenfluss.
Nachdem Sie die Datentransformation abgeschlossen haben, schreiben Sie sie mithilfe der Senkentransformation in einen Zielspeicher. Jeder Datenfluss erfordert mindestens eine Senkentransformation. Sie können aber so viele Senken wie erforderlich hinzufügen, um Ihren Transformationsfluss zu realisieren. Um in weitere Senken zu schreiben, erstellen Sie über neue Verzweigungen und bedingte Teilungen neue Datenströme.
Jede Senkentransformation ist genau einem Datasetobjekt oder einem verknüpften Dienst zugeordnet. Die Form und Position der Daten, in die geschrieben werden soll, richtet sich nach der Senkentransformation.
Inlinedatasets
Beim Erstellen einer Senkentransformation legen Sie fest, ob Ihre Senkeninformationen innerhalb eines Datasetobjekts oder innerhalb der Senkentransformation definiert sind. Die meisten Formate sind nur in einem von beiden verfügbar. Weitere Informationen zur Verwendung eines bestimmten Connectors finden Sie im Dokument zu diesem Connector.
Wenn ein Format sowohl für Inline- als auch in einem Datasetobjekt unterstützt wird, ergeben sich Vorteile für beide. Datasetobjekte sind wiederverwendbare Entitäten, die in anderen Datenflüssen und Aktivitäten wie Kopiervorgängen genutzt werden können. Diese wiederverwendbaren Entitäten sind besonders nützlich, wenn Sie ein verstärktes Schema verwenden. Datasets befinden sich nicht in Spark. Gelegentlich müssen Sie bestimmte Einstellungen oder Schemaprojektionen in der Senkentransformation überschreiben.
Inlinedatasets werden empfohlen, wenn flexible Schemas, einmalig genutzte Senkeninstanzen oder parametrisierte Senken verwendet werden. Wenn Ihre Senke stark parametrisiert ist, können Sie mit Inline-Datasets kein „Dummy“-Objekt erstellen. Inline-Datasets befinden sich in Spark, und ihre Eigenschaften sind für den Datenfluss nativ.
Um ein Inline-Dataset zu verwenden, wählen Sie das gewünschte Format im Selektor Senkentyp aus. Anstatt ein Senkendataset auszuwählen, wählen Sie den verknüpften Dienst aus, mit dem Sie eine Verbindung herstellen möchten.
Workspace DB (nur Synapse-Arbeitsbereiche)
Bei Verwendung von Datenflüssen in Azure Synapse-Arbeitsbereichen verfügen Sie über eine zusätzliche Option, um Ihre Daten direkt in einen Datenbanktyp umzuwandeln, der in Ihrem Synapse-Arbeitsbereich vorhanden ist. Es ist dann nicht mehr erforderlich, für diese Datenbanken verknüpfte Dienste oder Datasets hinzuzufügen. Die Datenbanken, die über die Azure Synapse Datenbankvorlagen erstellt wurden, sind auch zugänglich, wenn Sie Workspace DB auswählen.
Hinweis
Der Workspace DB-Connector von Azure Synapse befindet sich zurzeit in der öffentlichen Vorschau und funktioniert nur bei Spark Lake-Datenbanken.
Unterstützte Senkentypen
Der Zuordnungsdatenfluss folgt einem Ansatz zum Extrahieren, Laden und Transformieren (ELT) und funktioniert mit Stagingdatasets in Azure. Derzeit können die folgenden Datasets in einer Senkentransformation verwendet werden.
| Connector | Format | Dataset/Inline |
|---|---|---|
| Azure Blob Storage |
Avro Text mit Trennzeichen Delta JSON ORC Parquet |
✓/✓ ✓/✓ -/✓ ✓/✓ ✓/✓ ✓/✓ |
| Azure Cosmos DB for NoSQL | ✓/- | |
| Azure Data Lake Storage Gen1 |
Avro Text mit Trennzeichen JSON ORC Parquet |
✓/- ✓/- ✓/- ✓/✓ ✓/- |
| Azure Data Lake Storage Gen2 |
Avro Common Data Model Text mit Trennzeichen Delta JSON ORC Parquet |
✓/✓ -/✓ ✓/✓ -/✓ ✓/✓ ✓/✓ ✓/✓ |
| Azure Database for MySQL | ✓/✓ | |
| Azure-Datenbank für PostgreSQL | ✓/✓ | |
| Azure Data Explorer | ✓/✓ | |
| Azure SQL-Datenbank | ✓/✓ | |
| Verwaltete Azure SQL-Datenbank-Instanz | ✓/- | |
| Azure Synapse Analytics | ✓/- | |
| Dataverse | ✓/✓ | |
| Dynamics 365 | ✓/✓ | |
| Dynamics CRM | ✓/✓ | |
| Fabric-Lakehouse | ✓/✓ | |
| SFTP |
Avro Text mit Trennzeichen JSON ORC Parquet |
✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ |
| Snowflake | ✓/✓ | |
| SQL Server | ✓/✓ |
Die für diese Connectors spezifischen Einstellungen befinden sich auf der Registerkarte Einstellungen. Informationen und Beispiele zu Datenflussskripts zu diesen Einstellungen finden Sie in der Connectordokumentation.
Der Dienst hat Zugriff auf mehr als 90 native Connectors. Um Daten aus Ihrem Datenfluss in diese anderen Quellen zu schreiben, verwenden Sie die Kopieraktivität zum Laden der Daten aus einer unterstützten Senke.
Senkeneinstellungen
Nachdem Sie eine Senke hinzugefügt haben, konfigurieren Sie sie auf der Registerkarte Senke. Hier können Sie das Dataset auswählen oder erstellen, in das die Senke schreibt. Entwicklungswerte für Datasetparameter können in Debugeinstellungen konfiguriert werden. (Der Debugmodus muss aktiviert sein.)
Im folgenden Video werden verschiedene Senkenoptionen für Dateitypen mit Texttrennzeichen beschrieben.
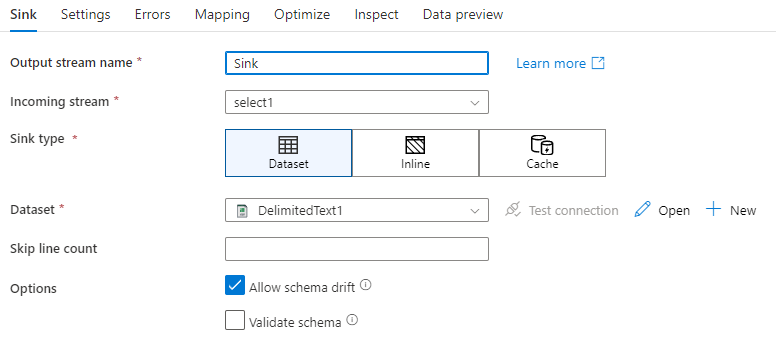
Schemaabweichung: Schemaabweichung ist die Fähigkeit des Diensts, flexible Schemas in Ihren Datenflüssen nativ zu verarbeiten, ohne Spaltenänderungen explizit definieren zu müssen. Aktivieren Sie Schemaabweichung zulassen, wenn Sie zusätzliche Spalten zusätzlich zur Definition im Datenschema der Senke schreiben möchten.
Schema überprüfen: Wenn „Schema überprüfen“ ausgewählt ist, führt der Datenfluss zu einem Fehler, wenn eine der Spalten in der Senkenprojektion im Senkenspeicher nicht gefunden wird oder wenn die Datentypen nicht übereinstimmen. Verwenden Sie diese Einstellung, um eine Übereinstimmung des Senkenschemas mit dem Vertrag Ihrer definierten Projektion zu erzwingen. Dies ist in Szenarios mit Datenbanksenken nützlich, um anzugeben, dass die Spaltennamen oder -typen geändert wurden.
Cachesenke
Von einer Cachesenke wird dann gesprochen, wenn Daten von einem Datenfluss in den Spark-Cache statt in einen Datenspeicher geschrieben werden. Bei Zuordnungsdatenflüssen kann mithilfe einer Cachesuche mehrmals innerhalb desselben Datenflusses auf diese Daten verwiesen werden. Dies ist nützlich, wenn Sie auf Daten als Teil eines Ausdrucks verweisen möchten, die Spalten jedoch nicht explizit damit verknüpfen möchten. Gängige Beispiele, in denen eine Cachesenke hilfreich sein kann, ist das Suchen eines Höchstwerts in einem Datenspeicher und das Abgleichen von Fehlercodes mit einer Fehlermeldungsdatenbank.
Um in eine Cachesenke zu schreiben, fügen Sie eine Senkentransformation hinzu, und wählen Sie Cache als Senkentyp aus. Im Gegensatz zu anderen Senkentypen müssen Sie kein Dataset oder keinen verknüpften Dienst auswählen, da Sie nicht in einen externen Speicher schreiben.
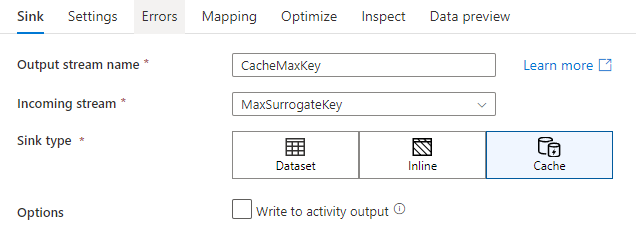
In den Senkeneinstellungen können Sie optional die Schlüsselspalten der Cachesenke angeben. Diese werden bei Verwendung der Funktion lookup() in einer Cachesuche als Übereinstimmungsbedingungen verwendet. Wenn Sie Schlüsselspalten angeben, können Sie die Funktion outputs() nicht in einer Cachesuche verwenden. Weitere Informationen zur Syntax für die Cachesuche finden Sie unter zwischengespeicherten Suchen.
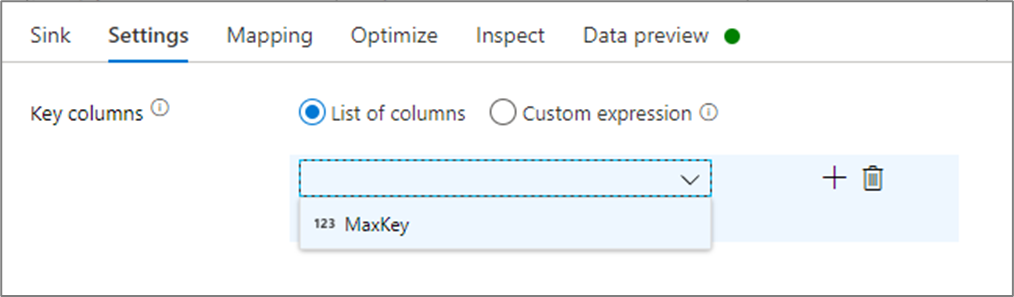
Wenn Sie beispielsweise eine einzelne Schlüsselspalte column1 in einer Cachesenke namens cacheExample angeben, wird beim Aufruf von cacheExample#lookup() mit einem Parameter festgelegt, mit welcher Zeile in der Cachesenke der Vergleich durchgeführt werden soll. Die Funktion gibt eine einzelne komplexe Spalte mit Unterspalten für jede zugeordnete Spalte aus.
Hinweis
Eine Cachesenke muss sich in einem vollständig unabhängigen Datenstrom von allen Transformationen befinden, die über eine Cachesuche darauf verweisen. Eine Cachesenke muss außerdem als erste Senke geschrieben werden.
In Aktivitätsausgabe schreiben
Die Cache-Senke kann ihre Daten optional in die Ausgabe der Datenflussaktivität schreiben, die dann als Eingabe für eine andere Aktivität in der Pipeline verwendet werden kann. Dadurch können Sie Daten schnell und einfach aus Ihrer Datenflussaktivität übergeben, ohne sie in einem Datenspeicher dauerhaft speichern zu müssen.
Hinweis: Die Ausgabe des Datenflusses, der direkt in Ihre Pipeline eingefügt wird, ist auf 2 MB beschränkt. Daher versucht Datenfluss, so viele Zeilen wie möglich zur Ausgabe hinzuzufügen, ohne dabei die Grenze von 2 MB zu überschreiten. Es kann daher vorkommen, dass Sie nicht alle Zeilen in der Aktivitätsausgabe sehen. Wenn Sie auf der Ebene der Datenflussaktivität „Nur erste Zeile“ festlegen, können Sie bei Bedarf auch die Datenausgabe aus dem Datenfluss einschränken.
Updatemethode
Für Datenbanksenkentypen enthält die Registerkarte „Einstellungen“ die Eigenschaft „Updatemethode“. Der Standardwert ist „insert“, aber es sind auch Kontrollkästchenoptionen für update, upsert und delete enthalten. Um diese zusätzlichen Optionen zu nutzen, müssen Sie vor der Senke eine Zeilenänderungstransformation hinzufügen. Mit der Zeilenänderung können Sie die Bedingungen für jede Datenbankaktion definieren. Wenn Ihre Quelle eine native CDC-Aktivierungsquelle ist, können Sie die Updatemethoden ohne Zeilenänderung festlegen, da ADF bereits die Zeilenmarkierungen für insert, update, upsert und delete kennt.
Feldzuordnung
Ähnlich wie bei einer Auswahltransformation können Sie auf der Registerkarte Zuordnung der Senke festlegen, welche eingehenden Spalten geschrieben werden. Standardmäßig werden alle Eingabespalten – auch abweichende Spalten – zugeordnet. Dieses Verhalten wird als automatische Zuordnung bezeichnet.
Wenn Sie die automatische Zuordnung deaktivieren, können Sie feste spaltenbasierte Zuordnungen oder regelbasierte Zuordnungen hinzuzufügen. Bei regelbasierten Zuordnungen können Sie Ausdrücke mit Musterabgleich schreiben. Bei der festen Zuordnung werden logische und physische Spaltennamen zugeordnet. Weitere Informationen zur regelbasierten Zuordnung finden Sie unter Spaltenmuster im Zuordnungsdatenfluss.
Benutzerdefinierte Senkenreihenfolge
Standardmäßig werden Daten ohne festgeschriebene Reihenfolge in mehrere Senken geschrieben. Die Ausführungs-Engine schreibt im Verlauf der Transformationslogik Daten parallel. Dabei kann bei jeder Ausführung die Senkenreihenfolge variieren. Um die genaue Reihenfolge der Senken anzugeben, aktivieren Sie auf der Registerkarte Allgemein des Datenflusses Benutzerdefinierte Senkenreihenfolge. Falls aktiviert, erfolgt in den Senken das Schreiben sequenziell in aufsteigender Reihenfolge.
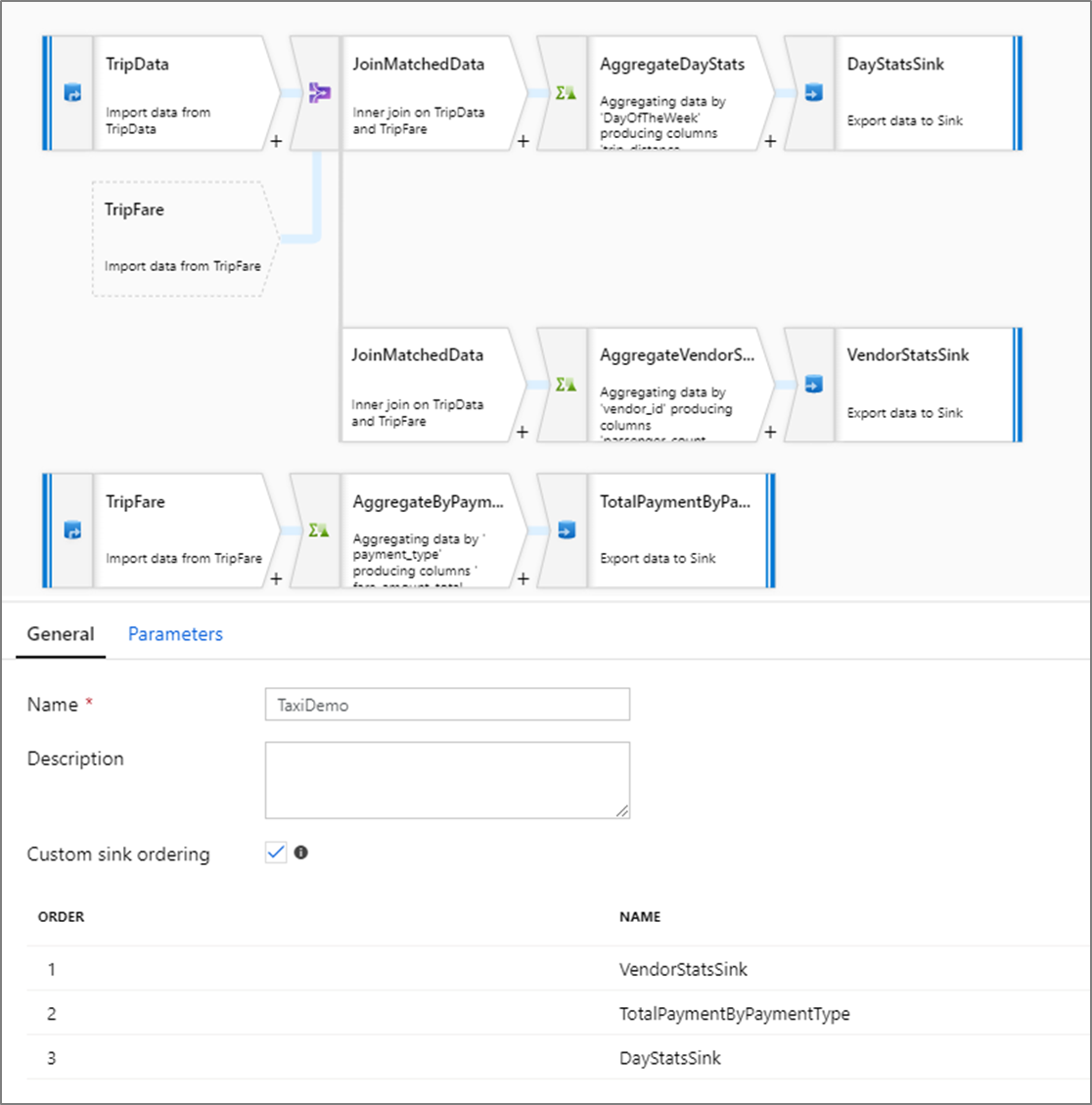
Hinweis
Bei Verwendung von zwischengespeicherten Suchen müssen Sie sicherstellen, dass die zwischengespeicherten Senken in der Senkenreihenfolge auf 1 festgelegt sind, wobei es sich um den niedrigsten (oder ersten) Rang handelt.
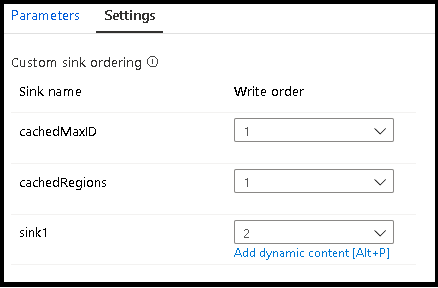
Senkengruppen
Sie können Senken gruppieren, indem Sie für eine Reihe von Senken die gleiche Auftragsnummer anwenden. Der Dienst behandelt diese Senken als Gruppen, die parallel ausgeführt werden können. Optionen für die parallele Ausführung werden in der Pipeline-Datenflussaktivität angezeigt.
Errors
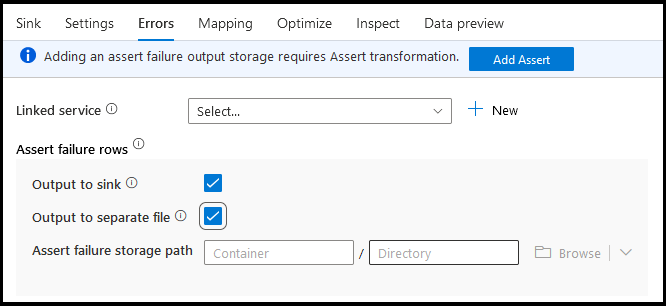
Auf der Registerkarte „Senkenfehler“ können Sie die Fehlerzeilenbehandlung konfigurieren, um die Ausgabe für Datenbanktreiberfehler und fehlgeschlagene Assertionen zu erfassen und umzuleiten.
Beim Schreiben in Datenbanken können aufgrund von Einschränkungen durch das Ziel Fehler bei bestimmten Datenzeilen auftreten. Standardmäßig scheitert eine Datenflussausführung beim ersten erhaltenen Fehler. In bestimmten Connectors können Sie eine Option Bei Fehler fortsetzen auswählen, die einen Abschluss des Datenflusses auch dann ermöglicht, wenn einzelne Zeilen Fehler aufweisen. Diese Funktion ist derzeit nur in Azure SQL-Datenbank und Azure Synapse verfügbar. Weitere Informationen finden Sie unter Fehlerzeilenbehandlung in Azure SQL-Datenbank.
Es folgt ein Videotutorial zur automatischen Verwendung der Fehlerzeilenbehandlung für Datenbanken in Ihrer Senkentransformation.
Für Assertionsfehlerzeilen können Sie den Upstream für die Assertionstransformation in Ihrem Datenfluss verwenden und dann fehlgeschlagene Assertionen in eine Ausgabedatei hier auf der Registerkarte „Senkenfehler“ umleiten. Sie haben hier auch die Möglichkeit, Zeilen mit Assertionsfehlern zu ignorieren und diese Zeilen nicht an den Senkenzieldatenspeicher auszugeben.
Datenvorschau in Senken
Beim Abrufen einer Datenvorschau im Debugmodus werden keine Daten in die Senke geschrieben. Es wird eine Momentaufnahme der Daten zurückgegeben, aber nichts in das Ziel geschrieben. Um das Schreiben von Daten in die Senke zu überprüfen, führen Sie einen Pipelinedebugvorgang in der Pipelinecanvas aus.
Datenflussskript
Beispiel
Es folgt ein Beispiel einer Senkentransformation und des zugehörigen Datenflussskripts:
sink(input(
movie as integer,
title as string,
genres as string,
year as integer,
Rating as integer
),
allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:false,
updateable:true,
upsertable:false,
keys:['movie'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true,
saveOrder: 1,
errorHandlingOption: 'stopOnFirstError') ~> sink1
Zugehöriger Inhalt
Da Sie nun Ihren Datenfluss erstellt haben, fügen Sie Ihrer Pipeline eine Aktivität zur Ausführung eines Datenflusses hinzu.