Verwenden von Spaltenmustern in Zuordnungsdatenflüssen
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In verschiedenen Transformationen von Zuordnungsdatenflüssen kann auf Vorlagenspalten mithilfe von Mustern (anstelle von hartcodierten Spaltennamen) verwiesen werden. Dieser Abgleich wird als Spaltenmuster bezeichnet. Sie können Muster definieren, um Spalten auf der Grundlage von Name, Datentyp, Stream, Ursprung oder Position abzugleichen, anstatt exakte Feldnamen zu verwenden. Spaltenmuster sind in zwei Szenarien hilfreich:
- Wenn Sie eingehende Quellfelder häufig ändern – etwa im Falle von sich ändernden Spalten in Textdateien oder NoSQL-Datenbanken. Dieses Szenario wird als Schemaabweichung bezeichnet.
- Wenn Sie einen Vorgang für eine große Gruppe von Spalten ausführen möchten, um beispielsweise alle Spalten, deren Spaltenname „total“ enthält, in einen Double-Wert umzuwandeln.
Spaltenmuster in „Abgeleitete Spalte“ und „Aggregieren“
Um ein Spaltenmuster in einer Transformation einer abgeleiteten Spalte, eines Aggregats oder eines Fensters hinzuzufügen, klicken Sie oberhalb der Spaltenliste auf Hinzufügen, oder klicken Sie auf das Pluszeichen („+“) neben einer vorhandenen abgeleiteten Spalte. Wählen Sie Spaltenmuster hinzufügen aus.
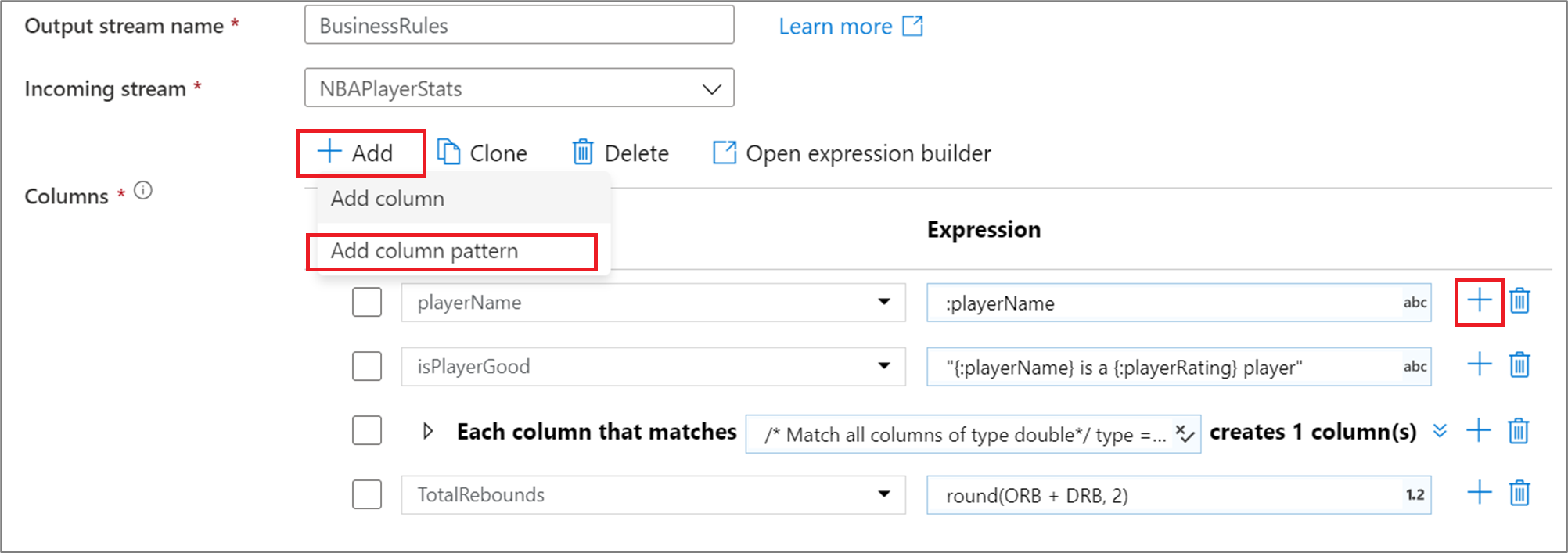
Verwenden Sie den Ausdrucks-Generator, um die Übereinstimmungsbedingung einzugeben. Erstellen Sie einen booleschen Ausdruck, um Spalten auf der Grundlage von name, type, stream, origin und position der Spalte abzugleichen. Das Muster wirkt sich sowohl auf Spalten mit Datendrift als auch auf definierte Spalten aus, bei denen die Bedingung zutrifft (also „true“ zurückgegeben wird).
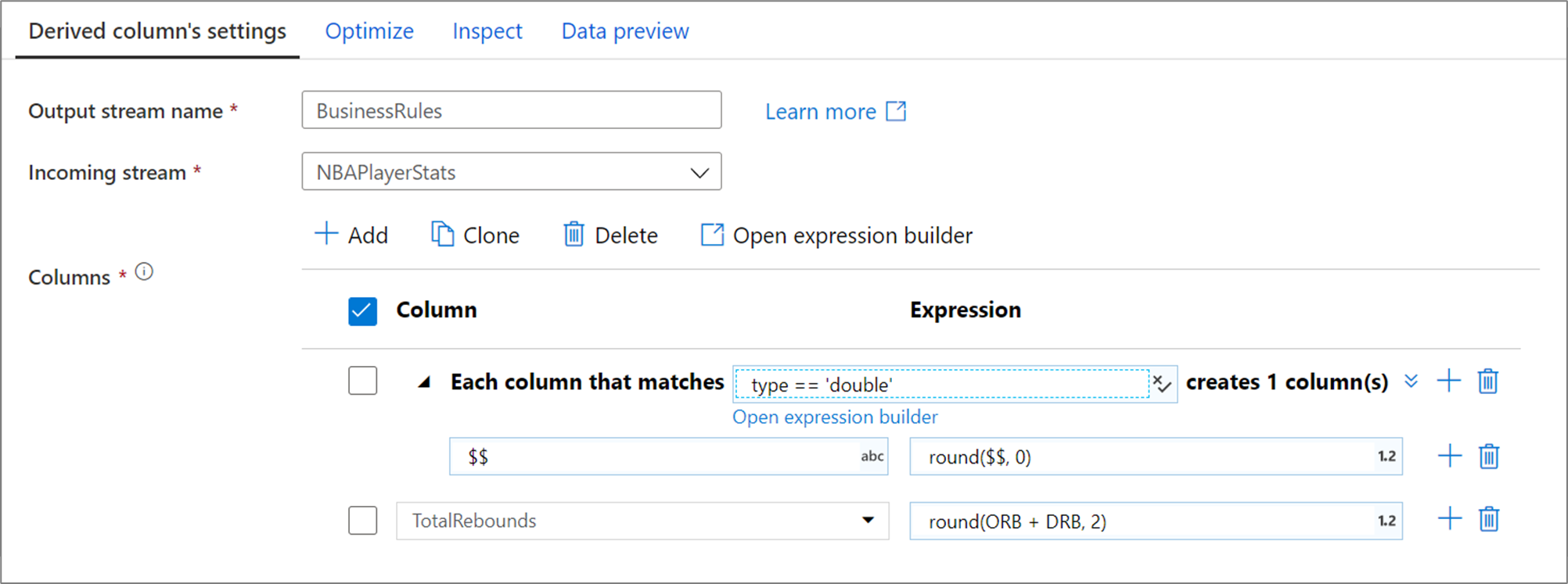
Das obige Spaltenmuster stimmt mit jeder Spalte vom Typ „Double“ überein und erstellt eine abgeleitete Spalte pro Übereinstimmung. Durch Angeben von $$ als Spaltennamensfeld wird jede übereinstimmende Spalte mit demselben Namen aktualisiert. Der Wert jeder Spalte entspricht dem vorhandenen Wert, der auf zwei Dezimalstellen gerundet wird.
Um zu überprüfen, ob die Übereinstimmungsbedingung korrekt ist, können Sie auf der Registerkarte Untersuchen das Ausgabeschema definierter Spalten überprüfen oder auf der Registerkarte Datenvorschau eine Momentaufnahme der Daten anzeigen.
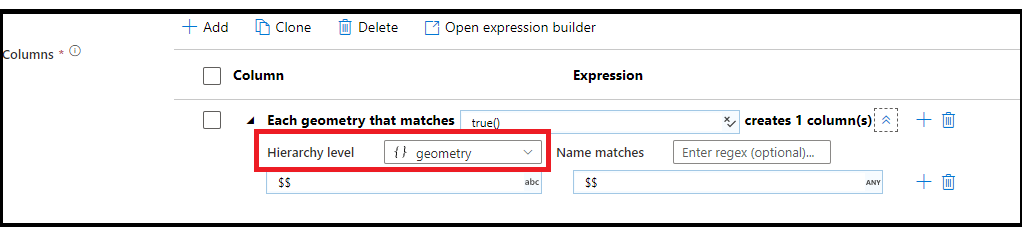
Hierarchischer Musterabgleich
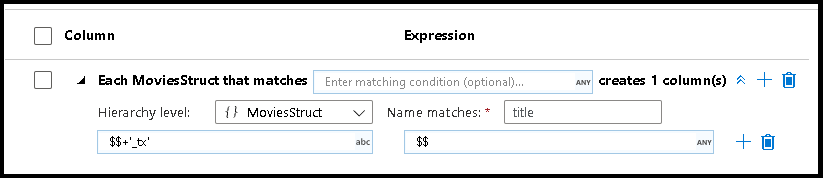
Sie können auch einen Musterabgleich in komplexen hierarchischen Strukturen erstellen. Erweitern Sie den Abschnitt Each MoviesStruct that matches, in dem Sie für jede Hierarchie im Datenstrom aufgefordert werden. Anschließend können Sie übereinstimmende Muster für Eigenschaften innerhalb der ausgewählten Hierarchie erstellen.
Vereinfachen von Strukturen
Wenn Ihre Daten komplexe Strukturen wie Arrays, hierarchische Strukturen und Zuordnungen aufweisen, können Sie mit Transformation für Vereinfachen Arrays auflösen und Ihre Daten denormalisieren. Verwenden Sie für Strukturen und Zuordnungen die Transformation für abgeleitete Spalten mit Spaltenmustern, um eine vereinfachte relationale Tabelle aus den Hierarchien zu erstellen. Sie können ähnliche Spaltenmuster wie in diesem Beispiel verwenden, wodurch die Geography-Hierarchie in eine relationale Tabellenform vereinfacht wird:
Regelbasierte Zuordnung in „Auswählen“ und „Senke“
Beim Zuordnen von Spalten in Quell- und Auswahltransformationen können Sie entweder eine feste Zuordnung oder regelbasierte Zuordnungen hinzufügen. Gleichen Sie basierend auf den Werten name, type, stream, origin und position von Spalten ab. Es kann eine beliebige Kombination aus festen und regelbasierten Zuordnungen verwendet werden. Standardmäßig werden alle Projektionen mit mehr als 50 Spalten auf eine regelbasierte Zuordnung festgelegt, die einen Abgleich auf Übereinstimmung für jede Spalte vornimmt und den eingegebenen Namen ausgibt.
Klicken Sie zum Hinzufügen einer regelbasierten Zuordnung auf Zuordnung hinzufügen, und wählen Sie Rule-based mapping (Regelbasierte Zuordnung) aus.

Jede regelbasierte Zuordnung erfordert zwei Eingaben: die Bedingung, gemäß der der Abgleich auf Übereinstimmung erfolgen soll, und den Namen jeder zugeordneten Spalte. Beide Werte werden über den Ausdrucks-Generator eingegeben. Geben Sie im linken Ausdrucksfeld Ihre boolesche Übereinstimmungsbedingung ein. Geben Sie im rechten Ausdrucksfeld das Zuordnungsziel für die übereinstimmende Spalte an.

Verwenden Sie die $$-Syntax, um auf den eingegebenen Namen einer übereinstimmenden Spalte zu verweisen. Nehmen wir das obige Bild als Beispiel: Ein Benutzer wünscht einen Abgleich auf Übereinstimmung aller Zeichenfolgenspalten, deren Namen kürzer als sechs Zeichen sind. Wenn eine eingehende Spalte mittest benannt wurde, wird die Spalte durch den Ausdruck $$ + '_short' in test_short umbenannt. Wenn dies die einzige vorhandene Zuordnung ist, werden alle Spalten, die die Bedingung nicht erfüllen, aus den ausgegebenen Daten entfernt.
Muster stimmen sowohl mit abweichenden als auch definierten Spalten überein. Um zu prüfen, welche definierten Spalten von einer Regel zugeordnet werden, klicken Sie neben der Regel auf das Brillensymbol. Überprüfen Sie die Ausgabe mithilfe der Datenvorschau.
Zuordnung mit regulärem Ausdruck
Wenn Sie auf das nach unten zeigende Chevronsymbol klicken, können Sie eine RegEx-Zuordnungsbedingung angeben. Eine RegEx-Zuordnungsbedingung gleicht alle Spaltennamen ab, die der angegebenen RegEx-Bedingung entsprechen. Sie kann in Kombination mit standardmäßigen regelbasierten Zuordnungen verwendet werden.

Das obige Beispiel stimmt mit dem RegEx-Muster (r) oder einem beliebigen Spaltennamen überein, der den Kleinbuchstaben r enthält. Ähnlich wie bei der standardmäßigen regelbasierten Zuordnung werden alle übereinstimmenden Spalten von der Bedingung auf der rechten Seite mit der $$-Syntax geändert.
Regelbasierte Hierarchien
Wenn Ihre definierte Projektion eine Hierarchie hat, können Sie die regelbasierte Zuordnung verwenden, um die Unterspalten der Hierarchie zuzuordnen. Geben Sie eine Übereinstimmungsbedingung und die komplexe Spalte an, deren Unterspalten Sie zuordnen möchten. Jede übereinstimmende Unterspalte wird mithilfe der rechts angegebenen Regel „Name as“ (Benennen als) ausgegeben.
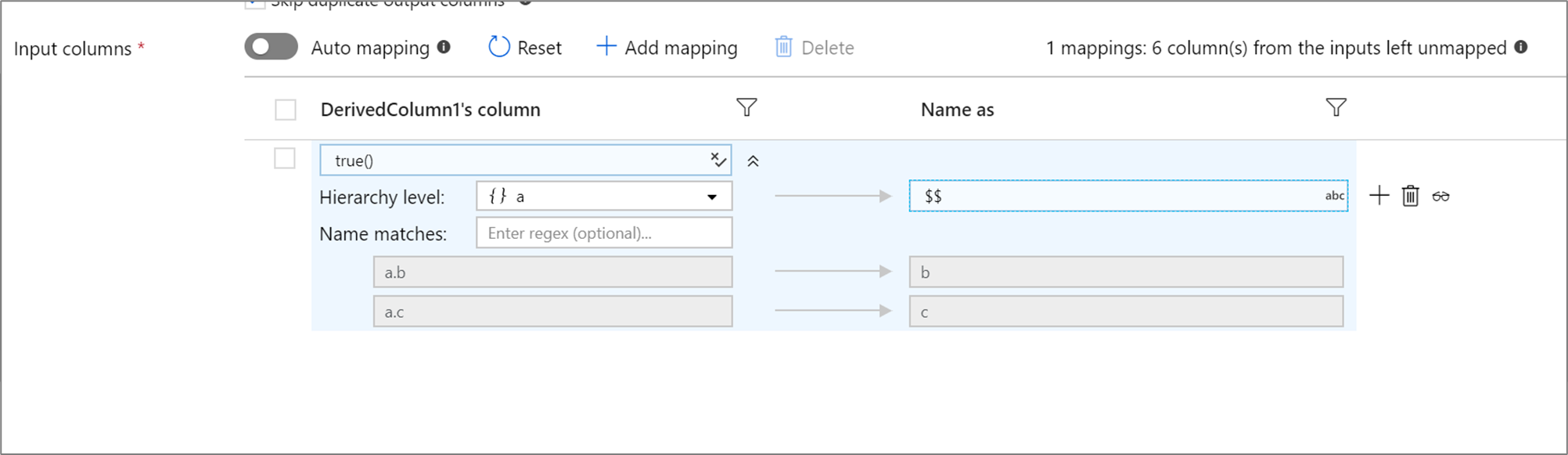
Das obige Beispiel stimmt mit allen Unterspalten der komplexen Spalte a überein. a enthält die beiden Unterspalten b und c. Das Ausgabeschema weist die beiden Spalten b und c auf, da die Bedingung „Name as“ $$ ist.
Ausdruckswerte für den Musterabgleich
$$wird zur Laufzeit in den Namen oder Wert der jeweiligen Übereinstimmung umgewandelt. Stellen Sie sich$$als Entsprechung zuthisvor.$0wird zur Laufzeit in die aktuelle Übereinstimmung des Spaltennamens für skalare Typen umgewandelt. Bei hierarchischen Typen stellt$0den Hierarchiepfad der übereinstimmenden Spalte dar.namestellt den Namen der einzelnen eingehenden Spalten dar.typestellt den Datentyp der einzelnen eingehenden Spalten dar. Die Liste der Datentypen im Datenflusstypsystem finden Sie hier.streamstellt den Namen dar, der dem jeweiligen Datenstrom oder der Transformation in Ihrem Flow zugeordnet ist.positionist die Ordinalposition von Spalten in Ihrem Datenfluss.originist die Transformation, von der eine Spalte stammt oder bei der sie zuletzt aktualisiert wurde.
Zugehöriger Inhalt
- Informieren Sie sich ausführlicher über die Ausdruckssprache von Zuordnungsdatenflüssen für Datentransformationen.
- Verwenden Sie Spaltenmuster in der Senkentransformation und der Auswahltransformation mit regelbasierter Zuordnung.