Suchtransformationen im Zuordnungsdatenfluss
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Datenflüsse sind sowohl in Azure Data Factory als auch in Azure Synapse-Pipelines verfügbar. Dieser Artikel gilt für Zuordnungsdatenflüsse. Wenn Sie noch nicht mit Transformationen arbeiten, lesen Sie den Einführungsartikel Transformieren von Daten mit einem Zuordnungsdatenfluss.
Verwenden Sie die Suchtransformation, um auf Daten aus einer anderen Quelle in einem Datenfluss zu verweisen. Die Suchtransformation fügt Spalten aus übereinstimmenden Daten an Ihre Quelldaten an.
Eine Suchtransformation ist mit einer linken äußeren Verknüpfung vergleichbar. Alle Zeilen aus dem primären Datenstrom sind im Ausgabedatenstrom mit zusätzlichen Spalten aus dem Suchdatenstrom enthalten.
Konfiguration
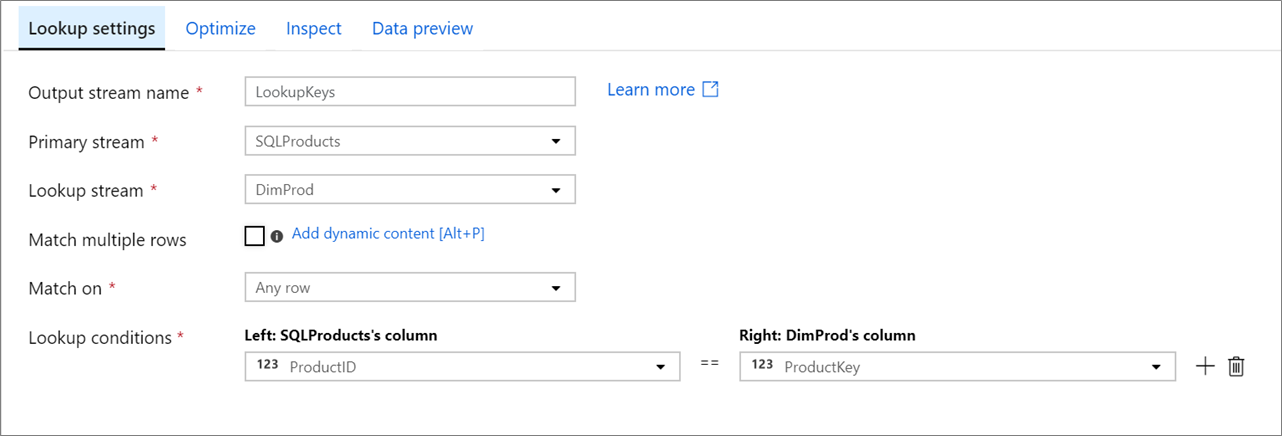
Primärer Datenstrom: Der eingehende Datenstrom. Dieser Datenstrom entspricht der linken Seite einer Verknüpfung.
Suchdatenstrom: Die Daten, die an den primären Datenstrom angefügt werden. Welche Daten hinzugefügt werden, wird durch die Suchbedingungen festgelegt. Dieser Datenstrom entspricht der rechten Seite einer Verknüpfung.
Übereinstimmung mit mehreren Zeilen: Bei Aktivierung dieser Option werden für eine Zeile mit mehreren Übereinstimmungen im primären Datenstrom mehrere Zeilen zurückgegeben. Anderenfalls wird basierend auf der Bedingung „Übereinstimmung mit“ nur eine einzelne Zeile zurückgegeben.
Übereinstimmung mit: Nur sichtbar, wenn „Übereinstimmung mit mehreren Zeilen“ nicht aktiviert ist. Wählen Sie aus, ob eine Übereinstimmung für eine beliebige Zeile, die erste Übereinstimmung oder die letzte Übereinstimmung ermittelt werden soll. Da die Ausführung bei Auswahl einer beliebigen Zeile am schnellsten ist, wird diese Einstellung empfohlen. Wenn die erste Zeile oder die letzte Zeile ausgewählt wird, müssen Sortierbedingungen angegeben werden.
Suchbedingungen: Wählen Sie aus, für welche Spalten eine Übereinstimmung ermittelt werden soll. Wenn die Gleichheitsbedingung erfüllt ist, werden die Zeilen als Übereinstimmung betrachtet. Zeigen Sie mit dem Mauszeiger auf „Berechnete Spalte“, und wählen Sie diese Option aus, um mithilfe der Ausdruckssprache für Datenflüsse einen Wert zu extrahieren.
In den Ausgabedaten sind alle Spalten beider Datenströme enthalten. Um doppelte oder unerwünschte Spalten zu löschen, fügen Sie nach Ihrer Suchtransformation eine Auswahltransformation hinzu. Spalten können auch in einer Senkentransformation gelöscht oder umbenannt werden.
Nicht-Gleichheitsverknüpfungen
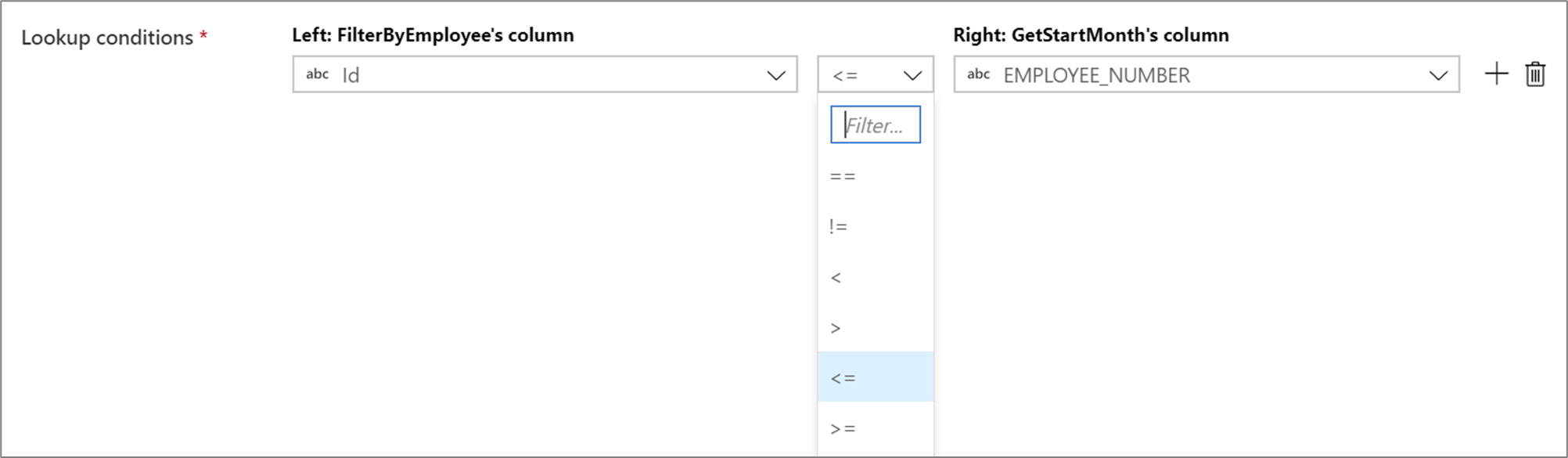
Wenn Sie in Ihren Suchbedingungen einen bedingten Operator wie „ungleich“ (!=) oder „größer als“ (>) verwenden möchten, ändern Sie die Dropdownliste des Operators zwischen den beiden Spalten. Bei Nicht-Gleichheitsverknüpfungen muss mindestens einer der beiden Datenströme mithilfe der Übertragungsoption Fixed (Fest) auf der Registerkarte Optimieren übertragen werden.
Analysieren übereinstimmender Zeilen
Nach der Suchtransformation können Sie mithilfe der Funktion isMatch() feststellen, ob bei der Suche Übereinstimmungen für einzelne Zeilen ermittelt wurden.
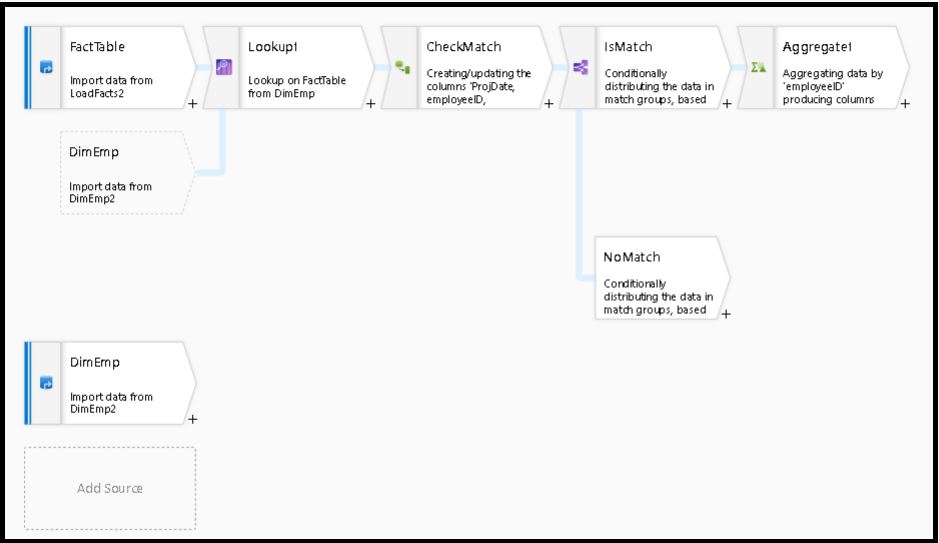
Ein Beispiel für dieses Muster ist die Verwendung der Transformation für bedingtes Teilen für die Funktion isMatch(). Im obigen Beispiel durchlaufen übereinstimmende Zeilen den obersten Stream und nicht übereinstimmende Zeilen den Stream NoMatch.
Testen von Suchbedingungen
Verwenden Sie einen kleinen Satz bekannter Daten, wenn Sie die Suchtransformation mit Datenvorschau im Debugmodus testen. Bei der Stichprobenentnahme aus einem umfangreichen Dataset können Sie nicht vorhersagen, welche Zeilen und Schlüssel zu Testzwecken gelesen werden. Das Ergebnis ist nicht deterministisch. Das bedeutet, dass für Ihre Verknüpfungsbedingungen möglicherweise keine Übereinstimmungen zurückgegeben werden.
Broadcastoptimierung
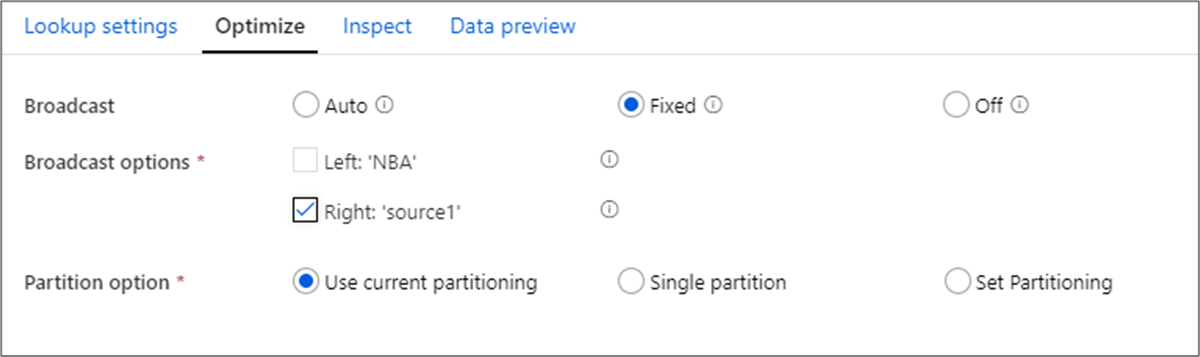
Wenn bei Join, Lookup- und Exists-Transformationen der Arbeitsspeicher des Workerknotens groß genug für einen oder beide Datenströme ist, können Sie die Leistung optimieren, indem Sie die Übertragung aktivieren. Standardmäßig entscheidet die Spark-Engine automatisch, ob eine Seite übertragen werden soll oder nicht. Klicken Sie auf Fest, um die zu übertragende Seite manuell auszuwählen.
Es wird nicht empfohlen, die Übertragung über die Option Aus zu deaktivieren, es sei denn, für Ihre Joins treten Timeoutfehler auf.
Zwischengespeicherte Suche
Wenn Sie mehrere kleinere Suchvorgänge für dieselbe Quelle ausführen, sind eine Cachesenke und zwischengespeicherte Suche möglicherweise besser geeignet als eine Suchtransformation. Gängige Beispiele, in denen eine Cachesenke besser geeignet sein könnte, ist das Suchen eines Höchstwerts in einem Datenspeicher und das Abgleichen von Fehlercodes mit einer Fehlermeldungsdatenbank. Weitere Informationen finden Sie unter Cachesenken und zwischengespeicherten Suchen.
Datenflussskript
Syntax
<leftStream>, <rightStream>
lookup(
<lookupConditionExpression>,
multiple: { true | false },
pickup: { 'first' | 'last' | 'any' }, ## Only required if false is selected for multiple
{ desc | asc }( <sortColumn>, { true | false }), ## Only required if 'first' or 'last' is selected. true/false determines whether to put nulls first
broadcast: { 'auto' | 'left' | 'right' | 'both' | 'off' }
) ~> <lookupTransformationName>
Beispiel
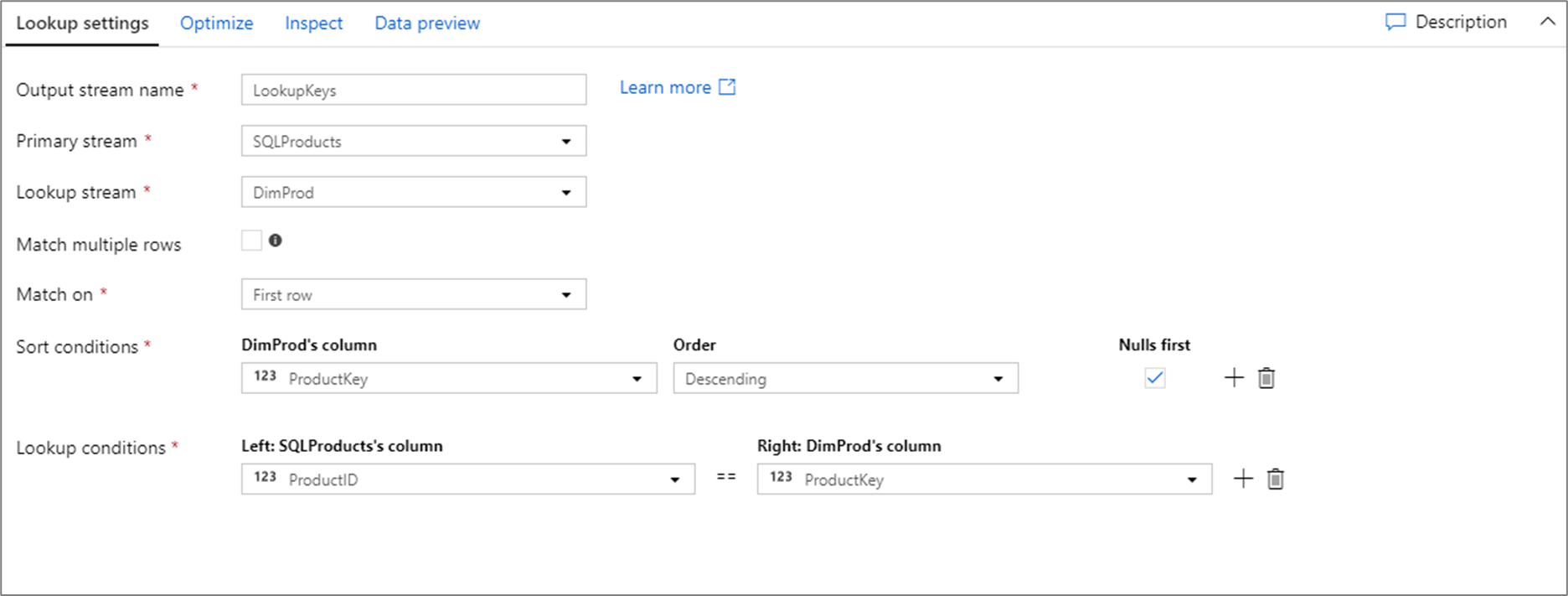
Der nachfolgende Codeausschnitt zeigt das Datenflussskript für die obige Suchkonfiguration.
SQLProducts, DimProd lookup(ProductID == ProductKey,
multiple: false,
pickup: 'first',
asc(ProductKey, true),
broadcast: 'auto')~> LookupKeys
Zugehöriger Inhalt
- Für die Join- und Exists-Transformation können mehrere Datenströme als Eingabe verwendet werden.
- Verwenden Sie eine Transformation für bedingtes Teilen mit
isMatch(), um Zeilen nach übereinstimmenden und nicht übereinstimmenden Werten aufzuteilen.