Kopieren und Transformieren von Daten von und zu einem REST-Endpunkt mithilfe von Azure Data Factory
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Artikel wird beschrieben, wie Sie die Kopieraktivität in Azure Data Factory verwenden, um Daten von und zu einem REST-Endpunkt zu kopieren. Dieser Artikel baut auf dem Artikel zur Kopieraktivität in Azure Data Factory auf, der eine allgemeine Übersicht über die Kopieraktivität enthält.
Dies sind die Unterschiede zwischen diesem REST-Connector, dem HTTP-Connector und dem Webtabellenconnector:
- REST-Connector: Dieser unterstützt insbesondere das Kopieren von Daten aus RESTful-APIs.
- HTTP-Connector: Dieser dient allgemein dazu, Daten von jedem HTTP-Endpunkt abzurufen, z. B. um Dateien herunterzuladen. Solange der REST-Connector noch nicht verfügbar ist, verwenden Sie möglicherweise den HTTP-Connector, um Daten aus RESTful-APIs zu kopieren. Dieser wird unterstützt, verfügt jedoch über weniger Funktionen als der REST-Connector.
- Webtabellenconnector: Dieser extrahiert Tabelleninhalte aus einer HTML-Webseite.
Unterstützte Funktionen
Dieser REST-Connector wird für die folgenden Funktionen unterstützt:
| Unterstützte Funktionen | IR |
|---|---|
| Kopieraktivität (Quelle/Senke) | ① ② |
| Zuordnungsdatenfluss (Quelle/Senke) | ① |
① Azure Integration Runtime ② Selbstgehostete Integration Runtime
Eine Liste der als Quellen/Senken unterstützten Datenspeicher finden Sie unter Unterstützte Datenspeicher.
Dieser allgemeine REST-Connector unterstützt Folgendes:
- Kopieren von Daten von einem REST-Endpunkt mithilfe der Methoden GET oder POST und Kopieren von Daten in einen REST-Endpunkt mithilfe der Methoden POST, PUT oder PATCH.
- Kopieren von Daten mithilfe einer der folgenden Authentifizierungen: Anonym, Standard, Dienstprinzipal, Anmeldeinformationen für OAuth2 Client, Systemseitig zugewiesene verwaltete Identität und Benutzerseitig zugewiesene verwaltete Identität.
- Die Paginierung in den REST-APIs.
- Wenn REST die Quelle ist: Kopieren der unveränderten REST-JSON-Antwort oder Analysieren der Antwort mithilfe der Schemazuordnung. In JSON wird lediglich die Antwortnutzlast unterstützt.
Tipp
Um eine Anforderung für den Datenabruf zu testen, bevor Sie den REST-Connector in Data Factory konfigurieren, informieren Sie sich über die API-Spezifikation für Header- und Textanforderungen. Sie können Tools wie Visual Studio, Invoke-RestMethod in PowerShell oder einen Webbrowser zum Überprüfen verwenden.
Voraussetzungen
Wenn sich Ihr Datenspeicher in einem lokalen Netzwerk, in einem virtuellen Azure-Netzwerk oder in einer virtuellen privaten Amazon-Cloud befindet, müssen Sie eine selbstgehostete Integration Runtime konfigurieren, um eine Verbindung herzustellen.
Handelt es sich bei Ihrem Datenspeicher um einen verwalteten Clouddatendienst, können Sie die Azure Integration Runtime verwenden. Ist der Zugriff auf IP-Adressen beschränkt, die in den Firewallregeln genehmigt sind, können Sie Azure Integration Runtime-IPs zur Positivliste hinzufügen.
Sie können auch das Feature managed virtual network integration runtime (Integration Runtime für verwaltete virtuelle Netzwerke) in Azure Data Factory verwenden, um auf das lokale Netzwerk zuzugreifen, ohne eine selbstgehostete Integration Runtime zu installieren und zu konfigurieren.
Weitere Informationen zu den von Data Factory unterstützten Netzwerksicherheitsmechanismen und -optionen finden Sie unter Datenzugriffsstrategien.
Erste Schritte
Sie können eines der folgenden Tools oder SDKs verwenden, um die Kopieraktivität mit einer Pipeline zu verwenden:
- Das Tool „Daten kopieren“
- Azure-Portal
- Das .NET SDK
- Das Python SDK
- Azure PowerShell
- Die REST-API
- Die Azure Resource Manager-Vorlage
Erstellen eines verknüpften REST-Diensts über die Benutzeroberfläche
Verwenden Sie die folgenden Schritte, um einen verknüpften REST-Dienst auf der Azure-Portal Benutzeroberfläche zu erstellen.
Navigieren Sie in Ihrem Azure Data Factory- oder Synapse-Arbeitsbereich zur Registerkarte „Verwalten“, und wählen Sie „Verknüpfte Dienste“ und anschließend „Neu“ aus:
Suchen Sie nach REST, und wählen Sie den REST-Connector aus.
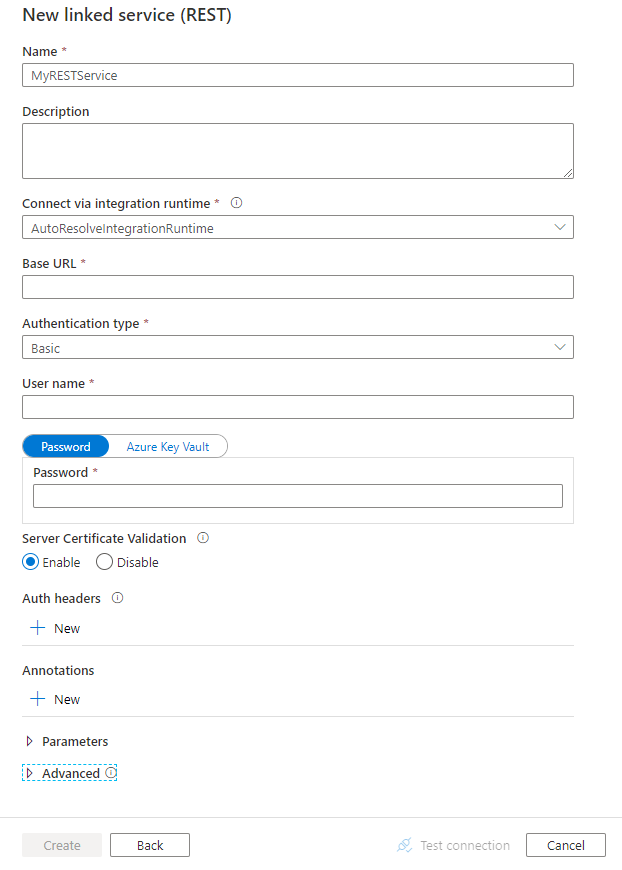
Konfigurieren Sie die Dienstdetails, testen Sie die Verbindung, und erstellen Sie den neuen verknüpften Dienst.

Details zur Connectorkonfiguration
In den folgenden Abschnitten finden Sie Details zu Eigenschaften, mit denen Sie Data Factory-Entitäten definieren können, die für den REST-Connector spezifisch sind.
Eigenschaften des verknüpften Diensts
Folgende Eigenschaften werden für den mit REST verknüpften Dienst unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft muss auf RestService festgelegt werden. | Ja |
| url | Die Basis-URL des REST-Diensts. | Ja |
| enableServerCertificateValidation | Hiermit wird festgelegt, ob das serverseitige TLS-/SSL-Zertifikat beim Herstellen einer Verbindung mit dem Endpunkt überprüft werden soll. | Nein (der Standardwert ist TRUE) |
| authenticationType | Typ der Authentifizierung für die Verbindung mit dem REST-Dienst. Zulässige Werte: Anonymous, Basic, AadServicePrincipal, OAuth2ClientCredential und ManagedServiceIdentity. Außerdem können Sie Authentifizierungsheader in der authHeaders-Eigenschaft konfigurieren. Weitere Informationen zu anderen Eigenschaften und Beispiele finden Sie weiter unten in den jeweiligen Abschnitten. |
Ja |
| authHeaders | Zusätzliche HTTP-Anforderungsheader für die Authentifizierung. Wenn Sie beispielsweise die Authentifizierung mit einem API-Schlüssel verwenden möchten, können Sie als Authentifizierungstyp „Anonym“ auswählen und im Header den API-Schlüssel angeben. |
Nein |
| connectVia | Die Integration Runtime, die zum Herstellen einer Verbindung mit dem Datenspeicher verwendet werden soll. Weitere Informationen finden Sie im Abschnitt Voraussetzungen. Wenn keine Option angegeben ist, verwendet diese Eigenschaft die standardmäßige Azure Integration Runtime. | Nein |
Ausführliche Informationen zu verschiedenen Authentifizierungstypen finden Sie in den entsprechenden Abschnitten.
- Standardauthentifizierung
- Dienstprinzipalauthentifizierung
- Authentifizierung mit OAuth2-Clientanmeldeinformationen
- Authentifizierung mit einer systemseitig zugewiesenen verwalteten Identität
- Authentifizierung mit einer benutzerseitig zugewiesenen verwalteten Identität
- Anonyme Authentifizierung
Verwenden der Standardauthentifizierung
Legen Sie die authenticationType-Eigenschaft auf Basic fest. Geben Sie zusätzlich zu den im vorherigen Abschnitt beschriebenen generischen Eigenschaften die folgenden Eigenschaften an:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| userName | Der Benutzername, der für den Zugriff auf den REST-Endpunkt verwendet werden soll. | Ja |
| password | Das Kennwort für den Benutzer (der Wert userName). Markieren Sie dieses Feld als Typ SecureString, um es sicher in Data Factory zu speichern. Sie können auch auf ein Geheimnis verweisen, das in Azure Key Vault gespeichert ist. | Ja |
Beispiel
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"authenticationType": "Basic",
"url" : "<REST endpoint>",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Verwenden der Dienstprinzipalauthentifizierung
Legen Sie die authenticationType-Eigenschaft auf AadServicePrincipal fest. Geben Sie zusätzlich zu den im vorherigen Abschnitt beschriebenen generischen Eigenschaften die folgenden Eigenschaften an:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| servicePrincipalId | Geben Sie die Client-ID der Microsoft Entra-Anwendung an. | Ja |
| servicePrincipalCredentialType | Geben Sie die Art der Anmeldeinformationen für die Dienstprinzipalauthentifizierung an. Zulässige Werte sind ServicePrincipalKey und ServicePrincipalCert. |
No |
| Für ServicePrincipalKey | ||
| servicePrincipalKey | Geben Sie den Schlüssel der Microsoft Entra-Anwendung an. Markieren Sie dieses Feld als SecureString, um es sicher in Data Factory zu speichern, oder verweisen Sie auf ein in Azure Key Vault gespeichertes Geheimnis. | No |
| Für ServicePrincipalCert | ||
| servicePrincipalEmbeddedCert | Geben Sie das base64-codierte Zertifikat Ihrer in Microsoft Entra ID registrierten Anwendung an, und stellen Sie sicher, dass der Zertifikatsinhaltstyp PKCS #12 lautet. Markieren Sie dieses Feld als SecureString, um es sicher zu speichern, oder verweisen Sie auf ein in Azure Key Vault gespeichertes Geheimnis. In diesem Abschnitt erfahren Sie, wie Sie das Zertifikat im Azure Key Vault speichern. | No |
| servicePrincipalEmbeddedCertPassword | Geben Sie das Kennwort Ihres Zertifikats an, falls Ihr Zertifikat mit einem Kennwort geschützt ist. Markieren Sie dieses Feld als SecureString, um es sicher zu speichern, oder verweisen Sie auf ein in Azure Key Vault gespeichertes Geheimnis. | Nein |
| tenant | Geben Sie die Mandanteninformationen (Domänenname oder Mandanten-ID) für Ihre Anwendung an. Diese können Sie abrufen, indem Sie den Mauszeiger über den rechten oberen Bereich im Azure-Portal bewegen. | Ja |
| aadResourceId | Geben Sie die Microsoft Entra-Ressource an, die Sie zur Autorisierung anfordern (z. B. https://management.core.windows.net). |
Ja |
| azureCloudType | Geben Sie für die Dienstprinzipalauthentifizierung die Art der Azure-Cloudumgebung an, bei der Ihre Microsoft Entra-Anwendung registriert ist. Zulässige Werte sind AzurePublic, AzureChina, AzureUsGovernment und AzureGermany. Standardmäßig wird die Cloudumgebung der Data Factory verwendet. |
No |
Beispiel 1: Verwenden der Dienstprinzipal-Schlüsselauthentifizierung
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"authenticationType": "AadServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalKey",
"servicePrincipalKey": {
"value": "<service principal key>",
"type": "SecureString"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"aadResourceId": "<Azure AD resource URL e.g. https://management.core.windows.net>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Beispiel 2: Verwenden der Dienstprinzipal-Zertifikatauthentifizierung
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"authenticationType": "AadServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalCert",
"servicePrincipalEmbeddedCert": {
"type": "SecureString",
"value": "<the base64 encoded certificate of your application registered in Microsoft Entra ID>"
},
"servicePrincipalEmbeddedCertPassword": {
"type": "SecureString",
"value": "<password of your certificate>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"aadResourceId": "<Azure AD resource URL e.g. https://management.core.windows.net>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Speichern des Dienstprinzipalzertifikats in Azure Key Vault
Ihnen stehen zwei Optionen zum Speichern des Dienstprinzipalzertifikats in Azure Key Vault zur Verfügung:
Option 1:
Konvertieren Sie das Dienstprinzipalzertifikat in eine Base64-Zeichenfolge. Mehr dazu erfahren Sie in diesem Artikel.
Speichern Sie die Base64-Zeichenfolge als geheimen Schlüssel im Azure Key Vault.
Option 2:
Wenn Sie das Zertifikat nicht aus Azure Key Vault herunterladen können, können Sie diese Vorlage verwenden, um das konvertierte Dienstprinzipalzertifikat als geheimen Schlüssel in Azure Key Vault zu speichern.

Verwenden der Authentifizierung mit OAuth2-Clientanmeldeinformationen
Legen Sie die authenticationType-Eigenschaft auf OAuth2ClientCredential fest. Geben Sie zusätzlich zu den im vorherigen Abschnitt beschriebenen generischen Eigenschaften die folgenden Eigenschaften an:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| tokenEndpoint | Der Tokenendpunkt des Autorisierungsservers zum Abrufen des Zugriffstokens | Ja |
| clientId | Die Client-ID, die Ihrer Anwendung zugeordnet ist | Ja |
| clientSecret | Der geheime Clientschlüssel, der Ihrer Anwendung zugeordnet ist. Markieren Sie dieses Feld als Typ SecureString, um es sicher in Data Factory zu speichern. Sie können auch auf ein Geheimnis verweisen, das in Azure Key Vault gespeichert ist. | Ja |
| scope | Der Umfang des erforderlichen Zugriffs. Er beschreibt, welche Art von Zugriff angefordert wird. | Nein |
| resource | Der Zieldienst oder die Zielressource, für den bzw. die Zugriff angefordert wird | Nein |
Beispiel
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"enableServerCertificateValidation": true,
"authenticationType": "OAuth2ClientCredential",
"clientId": "<client ID>",
"clientSecret": {
"type": "SecureString",
"value": "<client secret>"
},
"tokenEndpoint": "<token endpoint>",
"scope": "<scope>",
"resource": "<resource>"
}
}
}
Verwenden der systemseitig zugewiesenen Authentifizierung mit einer verwalteten Identität
Legen Sie die authenticationType-Eigenschaft auf ManagedServiceIdentity fest. Geben Sie zusätzlich zu den im vorherigen Abschnitt beschriebenen generischen Eigenschaften die folgenden Eigenschaften an:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| aadResourceId | Geben Sie die Microsoft Entra-Ressource an, die Sie zur Autorisierung anfordern (z. B. https://management.core.windows.net). |
Ja |
Beispiel
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"authenticationType": "ManagedServiceIdentity",
"aadResourceId": "<AAD resource URL e.g. https://management.core.windows.net>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Verwenden der benutzerseitig zugewiesenen Authentifizierung mit einer verwalteten Identität
Legen Sie die authenticationType-Eigenschaft auf ManagedServiceIdentity fest. Geben Sie zusätzlich zu den im vorherigen Abschnitt beschriebenen generischen Eigenschaften die folgenden Eigenschaften an:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| aadResourceId | Geben Sie die Microsoft Entra-Ressource an, die Sie zur Autorisierung anfordern (z. B. https://management.core.windows.net). |
Ja |
| Anmeldeinformationen | Geben Sie die benutzerseitig zugewiesene verwaltete Identität als Anmeldeinformationsobjekt an. | Ja |
Beispiel
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"authenticationType": "ManagedServiceIdentity",
"aadResourceId": "<Azure AD resource URL e.g. https://management.core.windows.net>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Authentifizierungs-Header verwenden
Darüber hinaus können Sie neben den integrierten Authentifizierungstypen auch Anforderungsheader für die Authentifizierung konfigurieren.
Beispiel: Verwenden der Authentifizierung mit API-Schlüssel
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint>",
"authenticationType": "Anonymous",
"authHeaders": {
"x-api-key": {
"type": "SecureString",
"value": "<API key>"
}
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Dataset-Eigenschaften
Dieser Abschnitt enthält eine Liste der Eigenschaften, die das REST-Dataset unterstützt.
Eine vollständige Liste mit den Abschnitten und Eigenschaften, die zum Definieren von Datasets zur Verfügung stehen, finden Sie unter Datasets und verknüpfte Dienste.
Zum Kopieren von Daten aus REST werden die folgenden Eigenschaften unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft des Datasets muss auf RestResource festgelegt sein. | Ja |
| relativeUrl | Eine relative URL zu der Ressource, die die Daten enthält. Wenn die Eigenschaft nicht angegeben ist, wird nur die URL verwendet, die in der Definition des verknüpften Diensts angegeben ist. Der HTTP-Connector kopiert Daten aus der kombinierten URL: [URL specified in linked service]/[relative URL specified in dataset]. |
Nein |
Wenn Sie requestMethod, additionalHeaders, requestBody und paginationRules im Dataset festgelegt haben, wird es weiterhin unverändert unterstützt. Es wird jedoch empfohlen, zukünftig das neue Modell in der Aktivität zu verwenden.
Beispiel:
{
"name": "RESTDataset",
"properties": {
"type": "RestResource",
"typeProperties": {
"relativeUrl": "<relative url>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<REST linked service name>",
"type": "LinkedServiceReference"
}
}
}
Eigenschaften der Kopieraktivität
Dieser Abschnitt enthält eine Liste der Eigenschaften, die von der REST-Quelle und -Senke unterstützt werden.
Eine vollständige Liste mit den verfügbaren Abschnitten und Eigenschaften zum Definieren von Aktivitäten finden Sie unter Pipelines.
REST als Quelle
Folgende Eigenschaften werden im Abschnitt source der Kopieraktivität unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft der Quelle der Kopieraktivität muss auf RestSource festgelegt werden. | Ja |
| requestMethod | Die HTTP-Methode. Zulässige Werte sind GET (Standardwert) und POST. | Nein |
| additionalHeaders | Zusätzliche HTTP-Anforderungsheader | Nein |
| requestBody | Der Text der HTTP-Anforderung. | Nein |
| paginationRules | Die Paginierungsregeln zum Zusammenstellen der nächsten Seitenanforderungen. Ausführliche Informationen finden Sie im Abschnitt Unterstützung der Paginierung. | Nein |
| httpRequestTimeout | Das Timeout (der Wert TimeSpan) für die HTTP-Anforderung, um eine Antwort zu empfangen. Bei diesem Wert handelt es sich um das Timeout zum Empfangen einer Antwort, nicht um das Timeout zum Lesen von Antwortdaten. Der Standardwert ist 00:01:40. | Nein |
| requestInterval | Die Wartezeit vor dem Senden der Anforderung für die nächste Seite. Der Standardwert lautet 00:00:01 | Nein |
Hinweis
Der REST-Connector ignoriert jeden in additionalHeaders angegebenen "Accept"-Header. Da der REST-Connector nur Antworten in JSON unterstützt, wird automatisch eine Kopfzeile vom Typ Accept: application/json generiert.
Das Objektarray als Antworttext wird in der Paginierung nicht unterstützt.
Beispiel 1: Verwenden der GET-Methode mit der Paginierung
"activities":[
{
"name": "CopyFromREST",
"type": "Copy",
"inputs": [
{
"referenceName": "<REST input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "RestSource",
"additionalHeaders": {
"x-user-defined": "helloworld"
},
"paginationRules": {
"AbsoluteUrl": "$.paging.next"
},
"httpRequestTimeout": "00:01:00"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Beispiel 2: Verwenden der POST-Methode
"activities":[
{
"name": "CopyFromREST",
"type": "Copy",
"inputs": [
{
"referenceName": "<REST input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "RestSource",
"requestMethod": "Post",
"requestBody": "<body for POST REST request>",
"httpRequestTimeout": "00:01:00"
},
"sink": {
"type": "<sink type>"
}
}
}
]
REST als Senke
Folgende Eigenschaften werden im Abschnitt sink der Kopieraktivität unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die type-Eigenschaft der Senke der Kopieraktivität muss auf RestSink festgelegt werden. | Ja |
| requestMethod | Die HTTP-Methode. Zulässige Werte sind POST (Standardwert), PUT und PATCH. | Nein |
| additionalHeaders | Zusätzliche HTTP-Anforderungsheader | Nein |
| httpRequestTimeout | Das Timeout (der Wert TimeSpan) für die HTTP-Anforderung, um eine Antwort zu empfangen. Bei diesem Wert handelt es sich um das Timeout für den Empfang einer Antwort, nicht um das Timeout für das Schreiben der Daten. Der Standardwert ist 00:01:40. | Nein |
| requestInterval | Das Zeitintervall zwischen verschiedenen Anforderungen in Millisekunden. Der Wert für das Anforderungsintervall sollte eine Zahl zwischen 10 und 60000 sein. | Nein |
| httpCompressionType | Der HTTP-Komprimierungstyp, der zum Senden von Daten mit der optimalen Komprimierungsstufe verwendet werden soll. Zulässige Werte sind none und gzip. | Nein |
| writeBatchSize | Die Anzahl von Datensätzen, die pro Batch in die REST-Senke geschrieben werden sollen. Der Standardwert ist 10.000. | Nein |
Ein REST-Connector als Senke funktioniert mit den REST-APIs, die JSON akzeptieren. Die Daten werden im JSON-Format mit dem folgenden Muster gesendet. Bei Bedarf können Sie die Kopieraktivität Schemazuordnung verwenden, um die Quelldaten so zu strukturieren, dass sie der erwarteten Nutzlast von der Rest-API entsprechen.
[
{ <data object> },
{ <data object> },
...
]
Beispiel:
"activities":[
{
"name": "CopyToREST",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<REST output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "RestSink",
"requestMethod": "POST",
"httpRequestTimeout": "00:01:40",
"requestInterval": 10,
"writeBatchSize": 10000,
"httpCompressionType": "none",
},
}
}
]
Eigenschaften von Mapping Data Flow
REST wird in Datenflüssen sowohl für Integrationsdatasets als auch für Inlinedatasets unterstützt.
Quellentransformation
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| requestMethod | Die HTTP-Methode. Zulässige Werte sind GET und POST. | Ja |
| relativeUrl | Eine relative URL zu der Ressource, die die Daten enthält. Wenn die Eigenschaft nicht angegeben ist, wird nur die URL verwendet, die in der Definition des verknüpften Diensts angegeben ist. Der HTTP-Connector kopiert Daten aus der kombinierten URL: [URL specified in linked service]/[relative URL specified in dataset]. |
Nein |
| additionalHeaders | Zusätzliche HTTP-Anforderungsheader | Nein |
| httpRequestTimeout | Das Timeout (der Wert TimeSpan) für die HTTP-Anforderung, um eine Antwort zu empfangen. Bei diesem Wert handelt es sich um das Timeout für den Empfang einer Antwort, nicht um das Timeout für das Schreiben der Daten. Der Standardwert ist 00:01:40. | Nein |
| requestInterval | Das Zeitintervall zwischen verschiedenen Anforderungen in Millisekunden. Der Wert für das Anforderungsintervall sollte eine Zahl zwischen 10 und 60000 sein. | Nein |
| QueryParameters.request_query_parameter OR QueryParameters['request_query_parameter'] | „request_query_parameter“ wird vom Benutzer definiert und verweist auf einen Abfrageparameternamen in der nächsten HTTP-Anforderungs-URL. | Nein |
Senkentransformation
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| additionalHeaders | Zusätzliche HTTP-Anforderungsheader | Nein |
| httpRequestTimeout | Das Timeout (der Wert TimeSpan) für die HTTP-Anforderung, um eine Antwort zu empfangen. Bei diesem Wert handelt es sich um das Timeout für den Empfang einer Antwort, nicht um das Timeout für das Schreiben der Daten. Der Standardwert ist 00:01:40. | Nein |
| requestInterval | Das Zeitintervall zwischen verschiedenen Anforderungen in Millisekunden. Der Wert für das Anforderungsintervall sollte eine Zahl zwischen 10 und 60000 sein. | Nein |
| httpCompressionType | Der HTTP-Komprimierungstyp, der zum Senden von Daten mit der optimalen Komprimierungsstufe verwendet werden soll. Zulässige Werte sind none und gzip. | Nein |
| writeBatchSize | Die Anzahl von Datensätzen, die pro Batch in die REST-Senke geschrieben werden sollen. Der Standardwert ist 10.000. | Nein |
Sie können die Methoden delete, insert, update und upsert sowie die relativen Zeilendaten festlegen, die für CRUD-Vorgänge an die REST-Senke gesendet werden sollen.
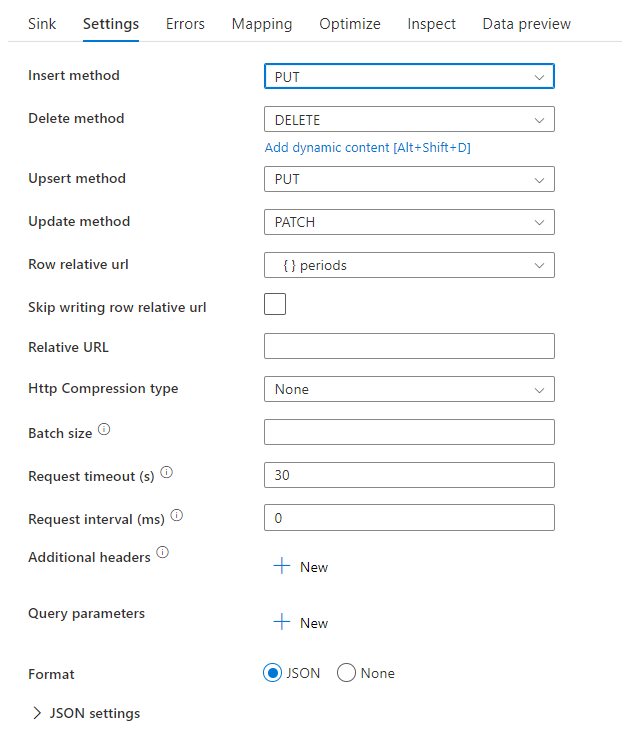
Beispiel-Datenflussskript
Beachten Sie die Verwendung einer Zeilenänderungstransformation vor der Senke, um ADF anzuweisen, welche Art von Aktion mit Ihrer REST-Senke erfolgen soll. Das heißt, insert, update, upsert, delete.
AlterRow1 sink(allowSchemaDrift: true,
validateSchema: false,
deletable:true,
insertable:true,
updateable:true,
upsertable:true,
rowRelativeUrl: 'periods',
insertHttpMethod: 'PUT',
deleteHttpMethod: 'DELETE',
upsertHttpMethod: 'PUT',
updateHttpMethod: 'PATCH',
timeout: 30,
requestFormat: ['type' -> 'json'],
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink1
Hinweis
Der Datenfluss generiert insgesamt N+1 API-Aufrufe bei der Verarbeitung von N Seiten. Dazu gehört ein erster Aufruf, um das Schema abzuleiten, gefolgt von N Aufrufen, die der Anzahl der aus der Quelle abgerufenen Seiten entsprechen.
Unterstützung der Paginierung
Beim Kopieren von Daten aus REST-APIs begrenzt die REST-API die Größe der Antwortnutzdaten üblicherweise auf einen angemessenen Wert. Beim Zurückgeben großer Datenmengen wird das Ergebnis auf mehrere Seiten aufgeteilt, und die Anrufer werden zum Senden aufeinanderfolgender Anforderungen aufgefordert, um die nächste Seite der Ergebnisse abzurufen. In der Regel ist die Anforderung für eine Seite dynamisch und besteht aus den Informationen, die von der Antwort der vorherigen Seite zurückgegeben werden.
Dieser generische REST-Connector unterstützt die folgenden Paginierungsmuster:
- Absolute oder relative URL der nächsten Anforderung = Eigenschaftswert im aktuellen Antworttext
- Absolute oder relative URL der nächsten Anforderung = Headerwert in aktuellen Antwortheadern
- Abfrageparameter der nächsten Anforderung = Eigenschaftswert im aktuellen Antworttext
- Abfrageparameter der nächsten Anforderung = Headerwert in aktuellen Antwortheadern
- Header der nächsten Anforderung = Eigenschaftswert im aktuellen Antworttext
- Header der nächsten Anforderung = Headerwert in aktuellen Antwortheadern
Paginierungsregeln werden als Wörterbuch in einem Dataset definiert, das mindestens ein Schlüssel-Wert-Paar enthält, bei dem die Groß-/Kleinschreibung berücksichtigt wird. Die Konfiguration wird ab der zweiten Seite zum Generieren der Anforderung verwendet. Der Connector beendet die Iteration, wenn er den HTTP-Statuscode 204 (Kein Inhalt) empfängt oder einer der JSONPath-Ausdrücke in „paginationRules“ NULL zurückgibt.
In Paginierungsregeln unterstützte Schlüssel:
| Schlüssel | BESCHREIBUNG |
|---|---|
| AbsoluteUrl | Gibt die URL für die nächste Anforderung an. Sie kann eine absolute oder eine relative URL sein. |
| QueryParameters.request_query_parameter OR QueryParameters['request_query_parameter'] | „request_query_parameter“ wird vom Benutzer definiert und verweist auf einen Abfrageparameternamen in der nächsten HTTP-Anforderungs-URL. |
| Headers.request_header OR Headers['request_header'] | „request_header“ wird vom Benutzer definiert und verweist auf einen Headernamen in der nächsten HTTP-Anforderung. |
| EndCondition:end_condition | „end_condition“ ist benutzerdefiniert und gibt die Bedingung an, die die Paginierungsschleife in der nächsten HTTP-Anforderung beendet. |
| MaxRequestNumber | Gibt die maximale Anzahl von Paginierungsanforderungen an. Falls leer gelassen, gilt kein Grenzwert. |
| SupportRFC5988 | Standardmäßig ist dieser Schlüssel auf TRUE festgelegt, wenn keine Paginierungsregel definiert ist. Sie können diese Regel deaktivieren, indem Sie supportRFC5988 auf FALSE festlegen oder diese Eigenschaft aus dem Skript entfernen. |
In Paginierungsregeln unterstützte Werte:
| Wert | BESCHREIBUNG |
|---|---|
| Headers.response_header ODER Headers['response_header'] | „response_header“ wird vom Benutzer definiert und verweist auf einen Headernamen in der aktuellen HTTP-Antwort, den Wert, der zum Ausgeben der nächsten Anforderung verwendet wird. |
| Ein mit „$“ beginnender JSONPath-Ausdruck (stellt den Stamm des Antworttexts dar) | Der Antworttext sollte nur ein JSON-Objekt enthalten, und das Array des Objekts, da der Antworttext nicht unterstützt wird. Der JSONPath-Ausdruck sollte einen einzelnen primitiven Wert zurückgeben, der zum Ausgeben der nächsten Anforderung verwendet wird. |
Hinweis
Die Paginierungsregeln in Zuordnungsdatenflüssen unterscheiden sich in den folgenden Aspekten von der Copy-Aktivität:
- Der Bereich wird in Zuordnungsdatenflüssen nicht unterstützt.
['']wird in Zuordnungsdatenflüssen nicht unterstützt. Verwenden Sie stattdessen{}, um das Sonderzeichen mit Escapezeichen zu versehen. Beispielsweise enthältbody.{@odata.nextLink}den JSON-Knoten@odata.nextLink, der ein Sonderzeichen aufweist (.).- Die Endbedingung wird in Zuordnungsdatenflüssen unterstützt, aber die Bedingungssyntax ist anders als bei der Copy-Aktivität.
bodywird anstelle von$verwendet, um den Antworttext abzugeben. Auch wirdheaderstattheadersverwendet, um den Antwortheader anzugeben. Hier finden Sie zwei Beispiele, in denen dieser Unterschied deutlich wird:- Beispiel 1:
Copy-Aktivität: "EndCondition:$.data": "Empty"
Zuordnungsdatenflüsse: "EndCondition:body.data": "Empty" - Beispiel 2:
Copy-Aktivität: "EndCondition:headers.complete": "Exist"
Zuordnungsdatenflüsse: "EndCondition:header.complete": "Exist"
- Beispiel 1:
Beispiele für Paginierungsregeln
In diesem Abschnitt werden Beispiele mit Einstellungen für Paginierungsregeln aufgeführt.
Beispiel 1: Variablen in QueryParameters
In diesem Beispiel werden die Konfigurationsschritte demonstriert, die durchgeführt werden müssen, um mehrere Anforderungen zu senden, deren Variablen sich in QueryParameters befinden.
Mehrere Anforderungen:
baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=0,
baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=1000,
......
baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=10000
Schritt 1:Geben Sie sysparm_offset={offset} wie in den folgenden Screenshots gezeigt entweder in Basis-URL oder Relative URL ein:
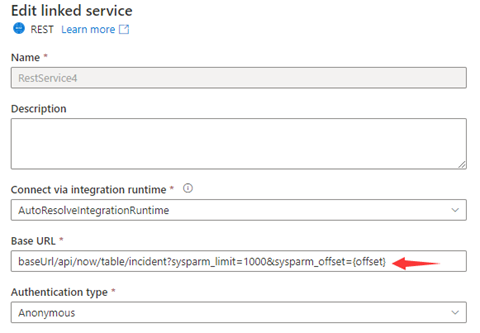
oder
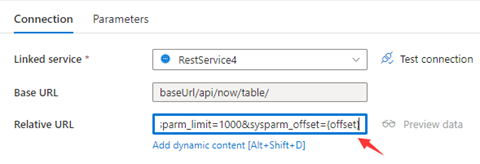
Schritt 2: Legen Sie die Pagination rules (Paginierungsregeln) entweder auf Option 1 oder Option 2 fest:
Option 1: "QueryParameters.{offset}" : "RANGE:0:10000:1000"
Option 2: "AbsoluteUrl.{offset}" : "RANGE:0:10000:1000"
Beispiel 2: Variablen in AbsoluteUrl
In diesem Beispiel werden die Konfigurationsschritte demonstriert, die durchgeführt werden müssen, um mehrere Anforderungen zu senden, deren Variablen sich in AbsoluteUrl befinden.
Mehrere Anforderungen:
BaseUrl/api/now/table/t1
BaseUrl/api/now/table/t2
......
BaseUrl/api/now/table/t100
Schritt 1: Geben Sie {id} entweder auf der Konfigurationsseite des verknüpften Diensts in Basis-URL oder im Bereich „Datasetverbindung“ in Relative URL ein.
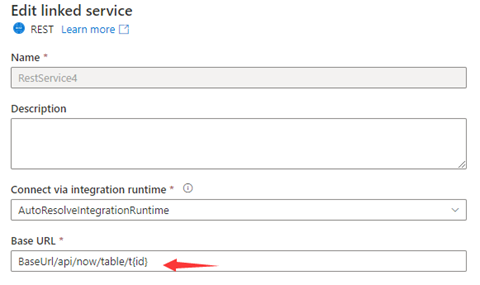
oder
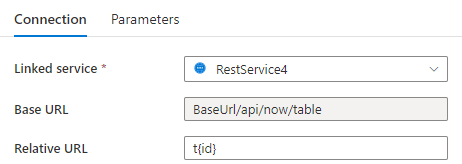
Schritt 2: Legen Sie die Pagination rules auf "AbsoluteUrl.{id}" :"RANGE:1:100:1" fest.
Beispiel 3: Variablen in Headern
In diesem Beispiel werden die Konfigurationsschritte gezeigt, die durchgeführt werden müssen, um mehrere Anforderungen zu senden, deren Variablen sich in Headern befinden.
Mehrere Anforderungen:
RequestUrl: https://example/table
Anforderung 1: Header(id->0)
Anforderung 2: Header(id->10)
......
Anforderung 100: Header(id->100)
Schritt 1: Geben Sie {id} in Additional headers (Weitere Header) ein.
Schritt 2: Legen Sie die Pagination rules auf "Headers.{id}" : "RARNGE:0:100:10" fest.
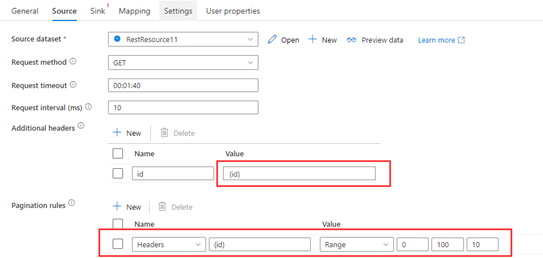
Beispiel 4: Die Variablen befinden sich in AbsoluteUrl/QueryParameters/Headern, die Endvariable ist nicht vordefiniert, und die Endbedingung basiert auf der Antwort
In diesem Beispiel werden die Konfigurationsschritte erklärt, die erforderlich sind, um mehrere Anforderungen zu senden, deren Variablen sich in AbsoluteUrl/QueryParameters/Headern befinden, wobei die Endvariable nicht definiert ist. Für verschiedene Antworten werden in Beispiel 4.1-4.6 verschiedene Einstellungen der Endbedingungsregel gezeigt.
Mehrere Anforderungen:
Request 1: baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=0,
Request 2: baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=1000,
Request 3: baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=2000,
......
In diesem Beispiel wurden zwei Antworten gefunden:
Antwort 1:
{
Data: [
{key1: val1, key2: val2
},
{key1: val3, key2: val4
}
]
}
Antwort 2:
{
Data: [
{key1: val5, key2: val6
},
{key1: val7, key2: val8
}
]
}
Schritt 1: Legen Sie den Bereich der Pagination rules auf Beispiel 1 fest, und lassen Sie das Ende des Bereichs mit "AbsoluteUrl.{offset}": "RANGE:0::1000" leer.
Schritt 2: Legen Sie die unterschiedlichen Endbedingungsregeln gemäß der unterschiedlichen letzten Antworten fest. Hier einige Beispiele:
Beispiel 4.1: Die Paginierung endet, wenn der Wert des bestimmten Knoten in der Antwort leer ist
Die REST-API gibt die letzte Antwort in der folgenden Struktur zurück:
{ Data: [] }Legen Sie die Endbedingungsregel auf "EndCondition:$.data": "Empty" fest, um die Paginierung zu beenden, wenn der Wert des bestimmten Knotens als Antwort leer ist.

Beispiel 4.2: Die Paginierung endet, wenn der Wert des spezifischen Knotens in der Antwort nicht vorhanden ist
Die REST-API gibt die letzte Antwort in der folgenden Struktur zurück:
{}Legen Sie die Endbedingungsregel auf "EndCondition:$.data": "NonExist" fest, um die Paginierung zu beenden, wenn der Wert des bestimmten Knotens in der Antwort nicht vorhanden ist.

Beispiel 4.3: Die Paginierung endet, wenn der Wert des bestimmten Knotens als Antwort vorhanden ist
Die REST-API gibt die letzte Antwort in der folgenden Struktur zurück:
{ Data: [ {key1: val991, key2: val992 }, {key1: val993, key2: val994 } ], Complete: true }Legen Sie die Endbedingungsregel auf "EndCondition:$.Complete": "Exist" fest, um die Paginierung zu beenden, wenn der Wert des bestimmten Knotens als Antwort vorhanden ist.

Beispiel 4.4: Die Paginierung endet, wenn der Wert des bestimmten Knotens als Antwort ein benutzerdefinierter „const“-Wert ist
Die REST-API gibt die Antwort in der folgenden Struktur zurück:
{ Data: [ {key1: val1, key2: val2 }, {key1: val3, key2: val4 } ], Complete: false }......
Die letzte Antwort ist in der folgenden Struktur:
{ Data: [ {key1: val991, key2: val992 }, {key1: val993, key2: val994 } ], Complete: true }Legen Sie die Endbedingungsregel auf "EndCondition:$.Complete": "Const:true" fest, um die Paginierung zu beenden, wenn der Wert des bestimmten Knotens als Antwort ein benutzerdefinierter „const“-Wert ist.

Beispiel 4.5: Die Paginierung endet, wenn der Wert des Headerschlüssels als Antwort dem benutzerdefinierten „cosnt“-Wert entspricht
Die Headerschlüssel in REST-API-Antworten werden in der folgenden Struktur angezeigt:
Antwortheader 1:
header(Complete->0)
......
„Letzte Antwort“-Header:header(Complete->1)Legen Sie die Endbedingungsregel auf "EndCondition:headers.Complete": "Const:1" fest, um die Paginierung zu beenden, wenn der Wert des Headerschlüssels als Antwort dem benutzerdefinierten „const“-Wert entspricht.

Beispiel 4.6: Die Paginierung endet, wenn der Schlüssel im Antwortheader vorhanden ist
Die Headerschlüssel in REST-API-Antworten werden in der folgenden Struktur angezeigt:
Antwortheader 1:
header()
......
„Letzte Antwort“-Header:header(CompleteTime->20220920)Legen Sie die Endbedingungsregel auf "EndCondition:headers.CompleteTime": "Exist" fest, um die Paginierung zu beenden, wenn der Schlüssel im Antwortheader vorhanden ist.

Beispiel 5: Festlegen der Endbedingung zur Vermeidung endloser Anforderungen, wenn keine Bereichsregel definiert ist
In diesem Beispiel werden die Konfigurationsschritte gezeigt, die zum Senden mehrerer Anforderungen erforderlich sind, wenn die Bereichsregel nicht verwendet wird. Die Endbedingung kann wie in Beispiel 4.1-4.6 festgelegt werden, um endlose Anforderungen zu vermeiden. Die REST-API gibt eine Antwort in der folgenden Struktur zurück. In diesem Fall wird die URL der nächsten Seite in paging.next dargestellt.
{
"data": [
{
"created_time": "2017-12-12T14:12:20+0000",
"name": "album1",
"id": "1809938745705498_1809939942372045"
},
{
"created_time": "2017-12-12T14:14:03+0000",
"name": "album2",
"id": "1809938745705498_1809941802371859"
},
{
"created_time": "2017-12-12T14:14:11+0000",
"name": "album3",
"id": "1809938745705498_1809941879038518"
}
],
"paging": {
"cursors": {
"after": "MTAxNTExOTQ1MjAwNzI5NDE=",
"before": "NDMyNzQyODI3OTQw"
},
"previous": "https://graph.facebook.com/me/albums?limit=25&before=NDMyNzQyODI3OTQw",
"next": "https://graph.facebook.com/me/albums?limit=25&after=MTAxNTExOTQ1MjAwNzI5NDE="
}
}
...
Die letzte Antwort lautet:
{
"data": [],
"paging": {
"cursors": {
"after": "MTAxNTExOTQ1MjAwNzI5NDE=",
"before": "NDMyNzQyODI3OTQw"
},
"previous": "https://graph.facebook.com/me/albums?limit=25&before=NDMyNzQyODI3OTQw",
"next": "Same with Last Request URL"
}
}
Schritt 1: Legen Sie die Pagination rules auf "AbsoluteUrl": "$.paging.next" fest.
Schritt 2: Wenn next in der letzten Antwort immer mit der letzten Anforderungs-URL identisch und nicht leer ist, werden endlose Anforderungen gesendet. Diese Endbedingung kann verwendet werden, um endlose Anforderungen zu vermeiden. Legen Sie daher die Endbedingungsregel wie in Beispiel 4.1-4.6 fest.
Beispiel 6: Festlegen der maximalen Anforderungsanzahl zur Vermeidung endloser Anforderungen
Legen Sie MaxRequestNumber (die maximale Anzahl der Anforderungen) wie im folgenden Screenshot gezeigt fest, um endlose Anforderungen zu vermeiden:

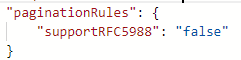
Beispiel 7: Die Paginierungsregel „RFC 5988“ wird standardmäßig unterstützt
Das Back-End erhält die nächste URL automatisch über die RFC 5988-Formatlinks in der Kopfzeile.

Tipp
Wenn Sie diese Standardpaginierungsregel nicht aktivieren möchten, können Sie supportRFC5988 im Skript auf false festlegen oder einfach löschen.
Beispiel 8a: Die nächste Anforderungs-URL befindet sich im Antworttext, wenn die Paginierung in Zuordnungsdatenflüssen verwendet wird
In diesem Beispiel wird gezeigt, wie die Paginierungsregel und die Endbedingungsregel in Zuordnungsdatenflüssen festgelegt werden, wenn die nächste Anforderungs-URL aus dem Antworttext kommt.
Im Folgenden finden Sie das Antwortschema:
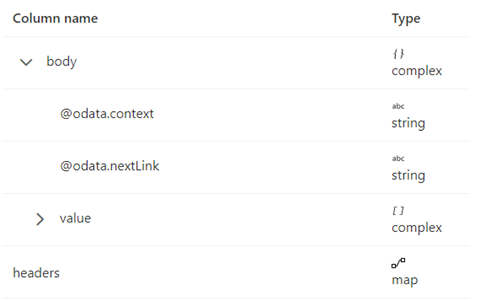
Die Paginierungsregeln sollte wie im folgenden Screenshot gezeigt festgelegt werden:

Standardmäßig wird die Paginierung angehalten, wenn „body.{@odata.nextLink}**“ NULL lautet oder leer ist.
Wenn der Wert von @odata.nextLink im letzten Antworttext jedoch der letzten Anforderungs-URL gleicht, führt dies zu einer Endlosschleife. Definieren Sie Endbedingungsregeln, um dies zu vermeiden.
Wenn Wert in der letzten Antwort Leer ist, kann die Endbedingungsregel wie folgt festgelegt werden:

Wenn der Wert des vollständigen Schlüssels im Antwortheader gleich TRUE ist, gibt dies das Ende der Paginierung an, und die Endbedingungsregel kann wie im Folgenden dargestellt festgelegt werden:
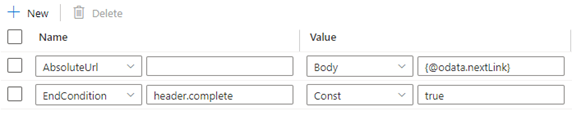
Beispiel 8b: Die nächste Anforderungs-URL befindet sich im Antworttext, wenn die Paginierung in der Copy-Aktivität verwendet wird
In diesem Beispiel wird veranschaulicht, wie die Paginierungsregel in einer Copy-Aktivität festgelegt wird, wenn die nächste Anforderungs-URL im Antworttext enthalten ist.
Im Folgenden finden Sie das Antwortschema:
Die Paginierungsregeln sollte wie im folgenden Screenshot gezeigt festgelegt werden:

Beispiel 9: Das Antwortformat ist XML, und die nächste Anforderungs-URL wird aus dem Antworttext erstellt, wenn die Paginierung in Zuordnungsdatenflüssen verwendet wird
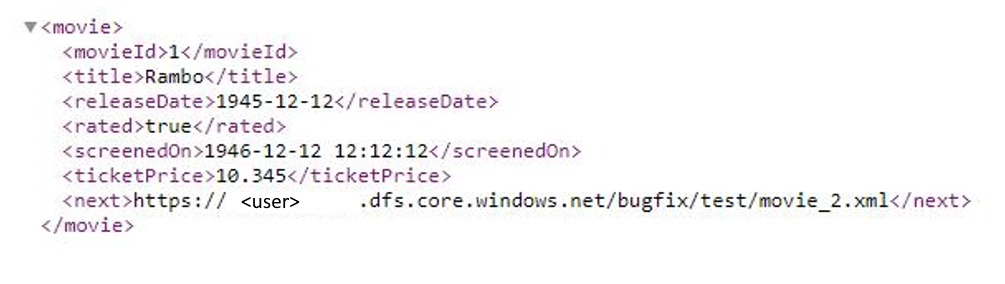
In diesem Beispiel wird angegeben, wie die Paginierungsregel in Zuordnungsdatenflüssen festgelegt wird, wenn das Antwortformat XML und die nächste Anforderungs-URL aus dem Antworttext stammt. Wie im folgenden Screenshot gezeigt, lautet die erste URL https://<user>.dfs.core.windows.NET/bugfix/test/movie_1.xml.
Im Folgenden finden Sie das Antwortschema:
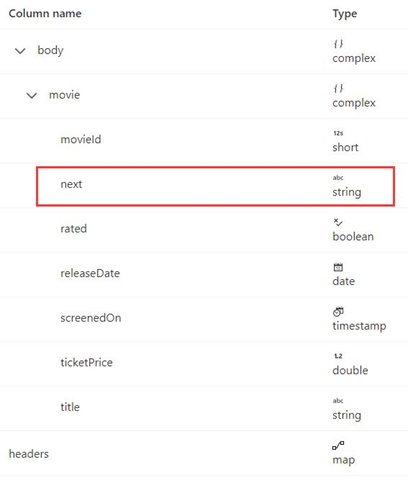
Die Syntax der Paginierungsregel ist mit der im Beispiel 8 identisch und sollte wie im folgenden Beispiel festgelegt werden:

Exportieren der unveränderten JSON-Antwort
Sie können diesen REST-Connector verwenden, um die unveränderte JSON-Antwort der REST-API in verschiedene dateibasierte Speicher zu exportieren. Um eine solche vom Schema unabhängige Kopie zu erzielen, überspringen Sie den Abschnitt „structure“ (auch schema genannt) im Dataset und die Schemazuordnung in der Kopieraktivität.
Schemazuordnung
Informationen zum Kopieren von Daten aus dem REST-Endpunkt in eine tabellarische Senke finden Sie unter Schemazuordnung.
Zugehöriger Inhalt
Eine Liste der Datenspeicher, die von der Kopieraktivität als Quellen und Senken in Azure Data Factory unterstützt werden, finden Sie unter Unterstützte Datenspeicher und Formate.