Schnellstart: Erstellen einer Data Factory und Pipeline mit dem .NET SDK
GILT FÜR: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Diese Schnellstartanleitung beschreibt, wie Sie mithilfe des .NET SDK eine Azure Data Factory-Instanz erstellen. Die in dieser Data Factory erstellte Pipeline kopiert Daten aus einem Ordner in einen anderen Ordner in Azure Blob Storage. Ein Tutorial zum Transformieren von Daten mithilfe von Azure Data Factory finden Sie unter Tutorial: Daten mit Spark transformieren.
Hinweis
Dieser Artikel enthält keine ausführliche Einführung in den Data Factory-Dienst. Eine Einführung in den Azure Data Factory-Dienst finden Sie unter Einführung in Azure Data Factory.
Voraussetzungen
Azure-Abonnement
Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
Azure-Rollen
Damit Sie Data Factory-Instanzen erstellen können, muss das Benutzerkonto, mit dem Sie sich bei Azure anmelden, ein Mitglied der Rolle Mitwirkender oder Besitzer oder ein Administrator des Azure-Abonnements sein. Wenn Sie die Berechtigungen anzeigen möchten, über die Sie im Abonnement verfügen, wechseln Sie zum Azure-Portal, wählen Sie in der oberen rechten Ecke Ihren Benutzernamen aus, wählen Sie Weitere Optionen (...) aus, und wählen Sie dann Meine Berechtigungen aus. Wenn Sie Zugriff auf mehrere Abonnements besitzen, wählen Sie das entsprechende Abonnement aus.
Für das Erstellen und Verwalten von untergeordneten Ressourcen für Data Factory – z.B. Datasets, verknüpfte Dienste, Pipelines, Trigger und Integration Runtimes – gelten die folgenden Anforderungen:
- Für das Erstellen und Verwalten von untergeordneten Ressourcen im Azure-Portal müssen Sie auf Ressourcengruppenebene oder höher Mitglied der Rolle Mitwirkender von Data Factory sein.
- Zum Erstellen und Verwalten von untergeordneten Ressourcen mit PowerShell oder dem SDK auf Ressourcenebene oder höher ist die Rolle Mitwirkender ausreichend.
Eine Beispielanleitung zum Hinzufügen eines Benutzers zu einer Rolle finden Sie im Artikel Hinzufügen oder Ändern von Azure-Administratorrollen, die das Abonnement oder die Dienste verwalten.
Weitere Informationen finden Sie in den folgenden Artikeln:
- Rolle „Mitwirkender von Data Factory“
- Roles and permissions for Azure Data Factory (Rollen und Berechtigungen für Azure Data Factory)
Azure-Speicherkonto
Sie verwenden in diesem Schnellstart ein allgemeines Azure Storage-Konto (Blobspeicher) als Datenspeicher vom Typ Quelle und vom Typ Ziel. Falls Sie noch nicht über ein allgemeines Azure Storage-Konto verfügen, lesen Sie zum Erstellen die Informationen unter Erstellen Sie ein Speicherkonto.
Abrufen des Speicherkontonamens
In dieser Schnellstartanleitung benötigen Sie den Namen Ihres Azure Storage-Kontos. Das folgende Verfahren enthält die Schritte zum Abrufen des Namens für Ihr Speicherkonto:
- Navigieren Sie in einem Webbrowser zum Azure-Portal, und melden Sie sich mit Ihrem Azure-Benutzernamen und dem zugehörigen Kennwort an.
- Wählen Sie im Menü des Azure-Portals die Option Alle Dienste und anschließend Storage>Speicherkonten aus. Alternativ können Sie auf einer beliebigen Seite nach Speicherkonten suchen und die entsprechende Option auswählen.
- Filtern Sie auf der Seite Speicherkonten nach Ihrem Speicherkonto (falls erforderlich), und wählen Sie dann Ihr Speicherkonto aus.
Alternativ können Sie auf einer beliebigen Seite nach Speicherkonten suchen und die entsprechende Option auswählen.
Erstellen eines Blobcontainers
In diesem Abschnitt erstellen Sie einen Blobcontainer mit dem Namen adftutorial in Azure Blob Storage.
Wählen Sie auf der Seite „Speicherkonto“ die Optionen Übersicht>Container aus.
Wählen Sie auf der Symbolleiste der Seite <Kontoname> - Container die Option Container aus.
Geben Sie im Dialogfeld Neuer Container als Namen adftutorial ein, und klicken Sie auf OK. Die Seite <Kontoname> - Container wird aktualisiert, woraufhin die Liste der Container den Eintrag adftutorial enthält.
Hinzufügen eines Eingabeordners und einer Datei für den Blobcontainer
In diesem Abschnitt erstellen Sie einen Ordner mit dem Namen input in dem Container, den Sie erstellt haben, und laden eine Beispieldatei in den Eingabeordner hoch. Öffnen Sie zunächst einen Text-Editor wie Notepad, und erstellen Sie eine Datei mit dem Namen emp.txt und folgendem Inhalt:
John, Doe
Jane, Doe
Speichern Sie die Datei im Ordner C:\ADFv2QuickStartPSH. (Erstellen Sie den Ordner, falls er noch nicht vorhanden ist.) Kehren Sie dann zum Azure-Portal zurück, und führen Sie die folgenden Schritte aus:
Wählen Sie auf der Seite <Kontoname> - Container, auf der Sie Ihre Arbeit unterbrochen haben, in der aktualisierten Liste der Container den Eintrag adftutorial aus.
- Falls Sie das Fenster geschlossen oder zu einer anderen Seite gewechselt haben, melden Sie sich erneut beim Azure-Portal an.
- Wählen Sie im Menü des Azure-Portals die Option Alle Dienste und anschließend Storage>Speicherkonten aus. Alternativ können Sie auf einer beliebigen Seite nach Speicherkonten suchen und die entsprechende Option auswählen.
- Wählen Sie Ihr Speicherkonto und anschließend Container>adftutorial aus.
Wählen Sie auf der Symbolleiste der Seite des Containers adftutorial die Option Hochladen aus.
Wählen Sie auf der Seite Blob hochladen das Feld Dateien aus. Navigieren Sie zur Datei emp.txt, und wählen Sie dann die Datei aus.
Erweitern Sie die Überschrift Erweitert. Die Seite wird jetzt wie folgt angezeigt:
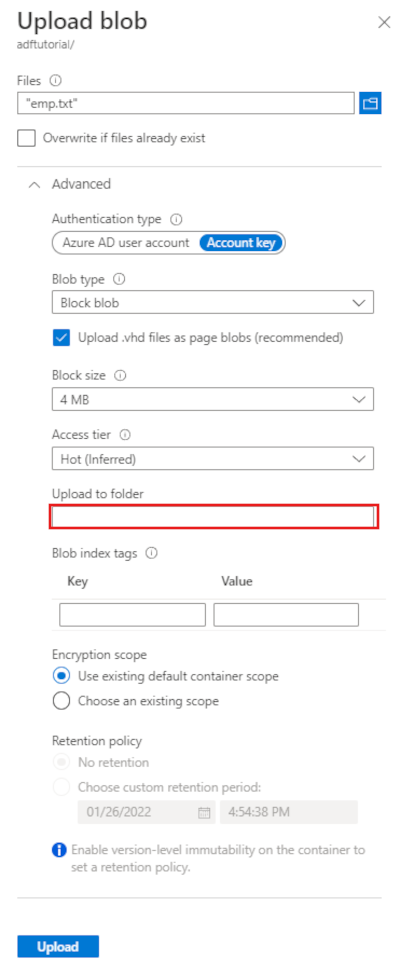
Geben Sie im Feld In Ordner hochladen den Namen input ein.
Wählen Sie die Schaltfläche Hochladen. Daraufhin sollten in der Liste die Datei emp.txt und der Status des Uploads angezeigt werden.
Wählen Sie das Symbol Schließen (das X) aus, um die Seite Blob hochladen zu schließen.
Lassen Sie die Seite des Containers adftutorial geöffnet. Sie überprüfen darauf am Ende dieser Schnellstartanleitung die Ausgabe.
Visual Studio
In der exemplarischen Vorgehensweise in diesem Artikel wird Visual Studio 2019 verwendet. Die Verfahren für Visual Studio 2013, 2015 oder 2017 unterscheiden sich geringfügig.
Erstellen einer Anwendung in Microsoft Entra ID
In den Abschnitten unter Anleitung: Verwenden des Portals zum Erstellen einer Microsoft Entra-Anwendung und eines Dienstprinzipals, der auf Ressourcen zugreifen kann folgend Sie den Anweisungen zum Durchführen dieser Aufgaben:
- Erstellen Sie unter Erstellen einer Microsoft Entra-Anwendung eine Anwendung, welche die .NET-Anwendung darstellt, die Sie in diesem Tutorial erstellen. Als Anmelde-URL können Sie wie in diesem Artikel gezeigt eine Platzhalter-URL (
https://contoso.org/exampleapp) angeben. - Rufen Sie unter Abrufen von Werten für die Anmeldung die Anwendungs-ID und die Mandanten-ID ab, und notieren Sie sich diese Werte zur späteren Verwendung in diesem Tutorial.
- Rufen Sie unter Zertifikate und Geheimnisse den Authentifizierungsschlüssel ab, und notieren Sie sich diesen Wert zur späteren Verwendung in diesem Tutorial.
- Weisen Sie unter Zuweisen der Anwendung zu einer Rolle die Anwendung der Rolle Mitwirkender auf Abonnementebene zu, damit die Anwendung Data Factorys im Abonnement erstellen kann.
Erstellen eines Visual Studio-Projekts
Erstellen Sie im nächsten Schritt in Visual Studio eine C# .NET-Konsolenanwendung:
- Starten Sie Visual Studio.
- Wählen Sie im Fenster „Start“ die Option Neues Projekt erstellen>Konsolen-App (.NET Framework) aus. .NET-Version 4.5.2 oder höher ist erforderlich.
- Geben Sie unter Projektname den Namen ADFv2QuickStart ein.
- Wählen Sie Create (Erstellen), um das Projekt zu erstellen.
Installieren von NuGet-Paketen
Klicken Sie auf Extras>NuGet-Paket-Manager>Paket-Manager-Konsole.
Führen Sie im Bereich Paket-Manager-Konsole die folgenden Befehle zum Installieren von Paketen aus. Weitere Informationen finden Sie im Azure.ResourceManager.DataFactory NuGet-Paket.
Install-Package Azure.ResourceManager.DataFactory -IncludePrerelease Install-Package Azure.Identity
Erstellen einer Data Factory
Öffnen Sie Program.cs, und fügen Sie die folgenden Anweisungen ein, um Verweise auf Namespaces hinzuzufügen.
using Azure; using Azure.Core; using Azure.Core.Expressions.DataFactory; using Azure.Identity; using Azure.ResourceManager; using Azure.ResourceManager.DataFactory; using Azure.ResourceManager.DataFactory.Models; using Azure.ResourceManager.Resources; using System; using System.Collections.Generic;Fügen Sie der Main-Methode den folgenden Code hinzu, der die Variablen festlegt. Ersetzen Sie die Platzhalter durch Ihre eigenen Werte. Eine Liste der Azure-Regionen, in denen Data Factory derzeit verfügbar ist, finden Sie, indem Sie die für Sie interessanten Regionen auf der folgenden Seite auswählen und dann Analysen erweitern, um Data Factory zu finden: Verfügbare Produkte nach Region. Die von der Data Factory verwendeten Datenspeicher (Azure Storage, Azure SQL-Datenbank usw.) und Computedienste (HDInsight und andere) können sich in anderen Regionen befinden.
// Set variables string tenantID = "<your tenant ID>"; string applicationId = "<your application ID>"; string authenticationKey = "<your authentication key for the application>"; string subscriptionId = "<your subscription ID where the data factory resides>"; string resourceGroup = "<your resource group where the data factory resides>"; string region = "<the location of your resource group>"; string dataFactoryName = "<specify the name of data factory to create. It must be globally unique.>"; string storageAccountName = "<your storage account name to copy data>"; string storageKey = "<your storage account key>"; // specify the container and input folder from which all files // need to be copied to the output folder. string inputBlobContainer = "<blob container to copy data from, e.g. containername>"; string inputBlobPath = "<path to existing blob(s) to copy data from, e.g. inputdir/file>"; //specify the contains and output folder where the files are copied string outputBlobContainer = "<blob container to copy data from, e.g. containername>"; string outputBlobPath = "<the blob path to copy data to, e.g. outputdir/file>"; // name of the Azure Storage linked service, blob dataset, and the pipeline string storageLinkedServiceName = "AzureStorageLinkedService"; string blobDatasetName = "BlobDataset"; string pipelineName = "Adfv2QuickStartPipeline";Fügen Sie der Main-Methode den folgenden Code hinzu, der eine Data Factory erstellt.
ArmClient armClient = new ArmClient( new ClientSecretCredential(tenantID, applicationId, authenticationKey, new TokenCredentialOptions { AuthorityHost = AzureAuthorityHosts.AzurePublicCloud }), subscriptionId, new ArmClientOptions { Environment = ArmEnvironment.AzurePublicCloud } ); ResourceIdentifier resourceIdentifier = SubscriptionResource.CreateResourceIdentifier(subscriptionId); SubscriptionResource subscriptionResource = armClient.GetSubscriptionResource(resourceIdentifier); Console.WriteLine("Get an existing resource group " + resourceGroupName + "..."); var resourceGroupOperation = subscriptionResource.GetResourceGroups().Get(resourceGroupName); ResourceGroupResource resourceGroupResource = resourceGroupOperation.Value; Console.WriteLine("Create a data factory " + dataFactoryName + "..."); DataFactoryData dataFactoryData = new DataFactoryData(AzureLocation.EastUS2); var dataFactoryOperation = resourceGroupResource.GetDataFactories().CreateOrUpdate(WaitUntil.Completed, dataFactoryName, dataFactoryData); Console.WriteLine(dataFactoryOperation.WaitForCompletionResponse().Content); // Get the data factory resource DataFactoryResource dataFactoryResource = dataFactoryOperation.Value;
Erstellen eines verknüpften Diensts
Fügen Sie der Main-Methode den folgenden Code hinzu, der einen verknüpften Azure Storage-Dienst erstellt.
Um Ihre Datenspeicher und Compute Services mit der Data Factory zu verknüpfen, können Sie verknüpfte Dienste in einer Data Factory erstellen. In dieser Schnellstartanleitung müssen Sie nur einen verknüpften Azure Blob Storage-Dienst für die Quell- und Senkendatenspeicher für den Kopiervorgang erstellen. In diesem Beispiel wird er als „AzureBlobStorageLinkedService“ bezeichnet.
// Create an Azure Storage linked service
Console.WriteLine("Create a linked service " + storageLinkedServiceName + "...");
AzureBlobStorageLinkedService azureBlobStorage = new AzureBlobStorageLinkedService()
{
ConnectionString = azureBlobStorageConnectionString
};
DataFactoryLinkedServiceData linkedServiceData = new DataFactoryLinkedServiceData(azureBlobStorage);
var linkedServiceOperation = dataFactoryResource.GetDataFactoryLinkedServices().CreateOrUpdate(WaitUntil.Completed, storageLinkedServiceName, linkedServiceData);
Console.WriteLine(linkedServiceOperation.WaitForCompletionResponse().Content);
Erstellen eines Datasets
Fügen Sie der Main-Methode den folgenden Code hinzu, der ein durch Trennzeichen getrenntes Text-Dataset erstellt.
Sie definieren ein Dataset, das die Daten repräsentiert, die aus einer Quelle in eine Senke kopiert werden sollen. In diesem Beispiel verweist dieses durch Trennzeichen getrennte Text-Dataset auf den verknüpften Azure Blob Storage-Dienst, den Sie im vorherigen Schritt erstellt haben. Das Dataset akzeptiert zwei Parameter, dessen Wert in einer Aktivität festgelegt ist, die das Dataset verwendet. Die Parameter werden verwendet, um den „Container“ und den „folderPath“ zu konstruieren, der auf den Ort verweist, an dem die Daten gespeichert sind.
// Create an Azure Blob dataset
DataFactoryLinkedServiceReference linkedServiceReference = new DataFactoryLinkedServiceReference(DataFactoryLinkedServiceReferenceType.LinkedServiceReference, storageLinkedServiceName);
DelimitedTextDataset delimitedTextDataset = new DelimitedTextDataset(linkedServiceReference)
{
DataLocation = new AzureBlobStorageLocation
{
Container = DataFactoryElement<string>.FromExpression("@dataset().container"),
FileName = DataFactoryElement<string>.FromExpression("@dataset().path")
},
Parameters =
{
new KeyValuePair<string, EntityParameterSpecification>("container",new EntityParameterSpecification(EntityParameterType.String)),
new KeyValuePair<string, EntityParameterSpecification>("path",new EntityParameterSpecification(EntityParameterType.String))
},
FirstRowAsHeader = false,
QuoteChar = "\"",
EscapeChar = "\\",
ColumnDelimiter = ","
};
DataFactoryDatasetData datasetData = new DataFactoryDatasetData(delimitedTextDataset);
var datasetOperation = dataFactoryResource.GetDataFactoryDatasets().CreateOrUpdate(WaitUntil.Completed, blobDatasetName, datasetData);
Console.WriteLine(datasetOperation.WaitForCompletionResponse().Content);
Erstellen einer Pipeline
Fügen Sie der Main-Methode den folgenden Code hinzu, der eine Pipeline mit einer Kopieraktivität erstellt.
In diesem Beispiel enthält diese Pipeline eine Aktivität und akzeptiert vier Parameter: den Eingabe-Blob-Container und -Pfad sowie den Ausgabe-Blob-Container und -Pfad. Die Werte für diese Parameter werden festgelegt, wenn die Pipeline ausgelöst bzw. ausgeführt wird. Die Kopieraktivität verweist für die Eingabe und Ausgabe auf das gleiche Blobdataset, das im vorherigen Schritt erstellt wurde. Wenn das Dataset als Eingabedatensatz verwendet wird, werden Eingabecontainer und Pfad angegeben. Und wenn das Dataset als Ausgabedatensatz verwendet wird, werden der Ausgabecontainer und der Pfad angegeben.
// Create a pipeline with a copy activity
Console.WriteLine("Creating pipeline " + pipelineName + "...");
DataFactoryPipelineData pipelineData = new DataFactoryPipelineData()
{
Parameters =
{
new KeyValuePair<string, EntityParameterSpecification>("inputContainer",new EntityParameterSpecification(EntityParameterType.String)),
new KeyValuePair<string, EntityParameterSpecification>("inputPath",new EntityParameterSpecification(EntityParameterType.String)),
new KeyValuePair<string, EntityParameterSpecification>("outputContainer",new EntityParameterSpecification(EntityParameterType.String)),
new KeyValuePair<string, EntityParameterSpecification>("outputPath",new EntityParameterSpecification(EntityParameterType.String))
},
Activities =
{
new CopyActivity("CopyFromBlobToBlob",new DataFactoryBlobSource(),new DataFactoryBlobSink())
{
Inputs =
{
new DatasetReference(DatasetReferenceType.DatasetReference,blobDatasetName)
{
Parameters =
{
new KeyValuePair<string, BinaryData>("container", BinaryData.FromString("\"@pipeline().parameters.inputContainer\"")),
new KeyValuePair<string, BinaryData>("path", BinaryData.FromString("\"@pipeline().parameters.inputPath\""))
}
}
},
Outputs =
{
new DatasetReference(DatasetReferenceType.DatasetReference,blobDatasetName)
{
Parameters =
{
new KeyValuePair<string, BinaryData>("container", BinaryData.FromString("\"@pipeline().parameters.outputContainer\"")),
new KeyValuePair<string, BinaryData>("path", BinaryData.FromString("\"@pipeline().parameters.outputPath\""))
}
}
}
}
}
};
var pipelineOperation = dataFactoryResource.GetDataFactoryPipelines().CreateOrUpdate(WaitUntil.Completed, pipelineName, pipelineData);
Console.WriteLine(pipelineOperation.WaitForCompletionResponse().Content);
Erstellen einer Pipelineausführung
Fügen Sie der Main-Methode den folgenden Code hinzu, der eine Pipelineausführung auslöst.
Mit diesem Code werden auch Werte des inputContainer-, inputPath-, outputContainer-und outputPath- Parameter festgelegt, die in der Pipeline mit den tatsächlichen Werten der Quell- und Sink-Blobpfade angegeben sind.
// Create a pipeline run
Console.WriteLine("Creating pipeline run...");
Dictionary<string, BinaryData> parameters = new Dictionary<string, BinaryData>()
{
{ "inputContainer",BinaryData.FromObjectAsJson(inputBlobContainer) },
{ "inputPath",BinaryData.FromObjectAsJson(inputBlobPath) },
{ "outputContainer",BinaryData.FromObjectAsJson(outputBlobContainer) },
{ "outputPath",BinaryData.FromObjectAsJson(outputBlobPath) }
};
var pipelineResource = dataFactoryResource.GetDataFactoryPipeline(pipelineName);
var runResponse = pipelineResource.Value.CreateRun(parameters);
Console.WriteLine("Pipeline run ID: " + runResponse.Value.RunId);
Überwachen einer Pipelineausführung
Fügen Sie der Main-Methode den folgenden Code hinzu, um den Status kontinuierlich zu überwachen, bis die Pipeline das Kopieren der Daten beendet hat.
// Monitor the pipeline run Console.WriteLine("Checking pipeline run status..."); DataFactoryPipelineRunInfo pipelineRun; while (true) { pipelineRun = dataFactoryResource.GetPipelineRun(runResponse.Value.RunId.ToString()); Console.WriteLine("Status: " + pipelineRun.Status); if (pipelineRun.Status == "InProgress" || pipelineRun.Status == "Queued") System.Threading.Thread.Sleep(15000); else break; }Fügen Sie der Main-Methode den folgenden Code hinzu, der Ausführungsdetails zur Kopieraktivität abruft, z.B. die Größe der Daten, die gelesen oder geschrieben werden.
// Check the copy activity run details Console.WriteLine("Checking copy activity run details..."); var queryResponse = dataFactoryResource.GetActivityRun(pipelineRun.RunId.ToString(), new RunFilterContent(DateTime.UtcNow.AddMinutes(-10), DateTime.UtcNow.AddMinutes(10))); var enumerator = queryResponse.GetEnumerator(); enumerator.MoveNext(); if (pipelineRun.Status == "Succeeded") Console.WriteLine(enumerator.Current.Output); else Console.WriteLine(enumerator.Current.Error); Console.WriteLine("\nPress any key to exit..."); Console.ReadKey();
Ausführen des Codes
Erstellen und starten Sie die Anwendung, und überprüfen Sie dann die Pipelineausführung.
Die Konsole druckt den Status der Erstellung der Data Factory, des verknüpften Diensts, der Datasets, der Pipeline und der Pipelineausführung aus. Danach wird der Status der Pipelineausführung überprüft. Warten Sie, bis Sie die Ausführungsdetails der Kopieraktivität mit der Größe der gelesen/geschriebenen Daten sehen. Überprüfen Sie anschließend mit Tools wie z. B. Azure Storage-Explorer, ob die Blobs – wie von Ihnen in den Variablen angegeben – aus „inputBlobPath“ in „outputBlobPath“ kopiert werden.
Beispielausgabe
Create a data factory quickstart-adf...
{
"name": "quickstart-adf",
"type": "Microsoft.DataFactory/factories",
"properties": {
"provisioningState": "Succeeded",
"version": "2018-06-01"
},
"location": "eastus2"
}
Create a linked service AzureBlobStorage...
{
"name": "AzureBlobStorage",
"type": "Microsoft.DataFactory/factories/linkedservices",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<storageAccountName>;",
"encryptedCredential": "<encryptedCredential>"
}
}
}
Creating dataset BlobDelimitedDataset...
{
"name": "BlobDelimitedDataset",
"type": "Microsoft.DataFactory/factories/datasets",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"type": "LinkedServiceReference",
"referenceName": "AzureBlobStorage"
},
"parameters": {
"container": {
"type": "String"
},
"path": {
"type": "String"
}
},
"typeProperties": {
"location": {
"container": {
"type": "Expression",
"value": "@dataset().container"
},
"type": "AzureBlobStorageLocation",
"fileName": {
"type": "Expression",
"value": "@dataset().path"
}
},
"columnDelimiter": ",",
"quoteChar": "\"",
"escapeChar": "\\",
"firstRowAsHeader": false
}
}
}
Creating pipeline Adfv2QuickStartPipeline...
{
"properties": {
"activities": [
{
"inputs": [
{
"type": "DatasetReference",
"referenceName": "BlobDelimitedDataset",
"parameters": {
"container": "@pipeline().parameters.inputContainer",
"path": "@pipeline().parameters.inputPath"
}
}
],
"outputs": [
{
"type": "DatasetReference",
"referenceName": "BlobDelimitedDataset",
"parameters": {
"container": "@pipeline().parameters.outputContainer",
"path": "@pipeline().parameters.outputPath"
}
}
],
"name": "CopyFromBlobToBlob",
"type": "Copy",
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "BlobSink"
}
}
}
],
"parameters": {
"inputContainer": {
"type": "String"
},
"inputPath": {
"type": "String"
},
"outputContainer": {
"type": "String"
},
"outputPath": {
"type": "String"
}
}
}
}
Creating pipeline run...
Pipeline run ID: 3aa26ffc-5bee-4db9-8bac-ccbc2d7b51c1
Checking pipeline run status...
Status: InProgress
Status: Succeeded
Checking copy activity run details...
{
"dataRead": 1048,
"dataWritten": 1048,
"filesRead": 1,
"filesWritten": 1,
"sourcePeakConnections": 1,
"sinkPeakConnections": 1,
"copyDuration": 8,
"throughput": 1.048,
"errors": [],
"effectiveIntegrationRuntime": "AutoResolveIntegrationRuntime (East US 2)",
"usedDataIntegrationUnits": 4,
"billingReference": {
"activityType": "DataMovement",
"billableDuration": [
{
"meterType": "AzureIR",
"duration": 0.06666666666666667,
"unit": "DIUHours"
}
],
"totalBillableDuration": [
{
"meterType": "AzureIR",
"duration": 0.06666666666666667,
"unit": "DIUHours"
}
]
},
"usedParallelCopies": 1,
"executionDetails": [
{
"source": {
"type": "AzureBlobStorage"
},
"sink": {
"type": "AzureBlobStorage"
},
"status": "Succeeded",
"start": "2023-12-15T10:25:33.9991558Z",
"duration": 8,
"usedDataIntegrationUnits": 4,
"usedParallelCopies": 1,
"profile": {
"queue": {
"status": "Completed",
"duration": 5
},
"transfer": {
"status": "Completed",
"duration": 1,
"details": {
"listingSource": {
"type": "AzureBlobStorage",
"workingDuration": 0
},
"readingFromSource": {
"type": "AzureBlobStorage",
"workingDuration": 0
},
"writingToSink": {
"type": "AzureBlobStorage",
"workingDuration": 0
}
}
}
},
"detailedDurations": {
"queuingDuration": 5,
"transferDuration": 1
}
}
],
"dataConsistencyVerification": {
"VerificationResult": "NotVerified"
}
}
Press any key to exit...
Überprüfen der Ausgabe
Die Pipeline erstellt den Ausgabeordner automatisch im Blobcontainer adftutorial. Anschließend wird die Datei emp.txt aus dem Eingabe- in den Ausgabeordner kopiert.
- Wählen Sie im Azure-Portal auf der Containerseite adftutorial, bei der Sie im Abschnitt Hinzufügen eines Eingabeordners und einer Datei für den Blobcontainer Ihre Arbeit unterbrochen haben, Aktualisieren aus, um den Ausgabeordner anzuzeigen.
- Wählen Sie in der Ordnerliste output aus.
- Überprüfen Sie, ob die Datei emp.txt in den Ausgabeordner kopiert wurde.
Bereinigen von Ressourcen
Um die Data Factory programmgesteuert zu löschen, fügen Sie dem Programm die folgenden Codezeilen hinzu:
Console.WriteLine("Deleting the data factory");
dataFactoryResource.Delete(WaitUntil.Completed);
Nächste Schritte
Die Pipeline in diesem Beispiel kopiert Daten in einem Azure Blob Storage von einem Speicherort in einen anderen. Arbeiten Sie die Tutorials durch, um zu erfahren, wie Sie Data Factory in anderen Szenarien verwenden können.