Kopieren von Daten in einen Azure KI Search-Index mithilfe von Azure Data Factory oder Synapse Analytics
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Artikel wird beschrieben, wie Sie die Copy-Aktivität in einer Azure Data Factory- oder Azure Synapse Analytics-Pipeline verwenden, um Daten in einen Azure KI Search-Index zu kopieren. Er baut auf dem Artikel zur Übersicht über die Kopieraktivität auf, der eine allgemeine Übersicht über die Kopieraktivität enthält.
Unterstützte Funktionen
Dieser Connector für Azure KI Search wird für die folgenden Funktionen unterstützt:
| Unterstützte Funktionen | IR | Verwalteter privater Endpunkt |
|---|---|---|
| Kopieraktivität (-/Senke) | ① ② | ✓ |
① Azure Integration Runtime ② Selbstgehostete Integration Runtime
Sie können Daten aus einem beliebigen unterstützten Quelldatenspeicher in einen Suchindex kopieren. Eine Liste der Datenspeicher, die als Quellen oder Senken für die Kopieraktivität unterstützt werden, finden Sie in der Tabelle Unterstützte Datenspeicher.
Erste Schritte
Sie können eines der folgenden Tools oder SDKs verwenden, um die Kopieraktivität mit einer Pipeline zu verwenden:
- Das Tool „Daten kopieren“
- Azure-Portal
- Das .NET SDK
- Das Python SDK
- Azure PowerShell
- Die REST-API
- Die Azure Resource Manager-Vorlage
Erstellen eines verknüpften Diensts mit Azure Search über die Benutzeroberfläche
Verwenden Sie die folgenden Schritte, um einen verknüpften Dienst für Azure Search auf der Azure-Portal-Benutzeroberfläche zu erstellen.
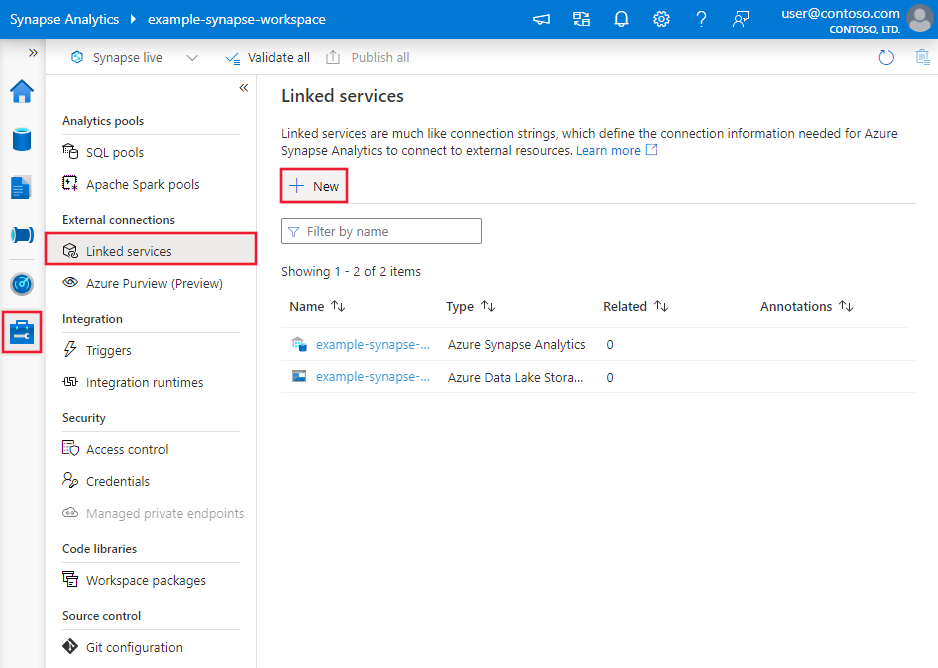
Navigieren Sie in Ihrem Azure Data Factory- oder Synapse-Arbeitsbereich zu der Registerkarte „Verwalten“, wählen Sie „Verknüpfte Dienste“ aus und klicken Sie dann auf „Neu“:
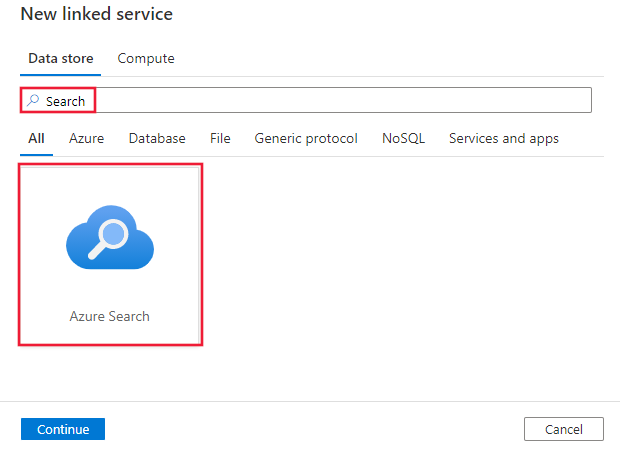
Suchen Sie nach Search und wählen Sie den Azure Search-Connector aus.
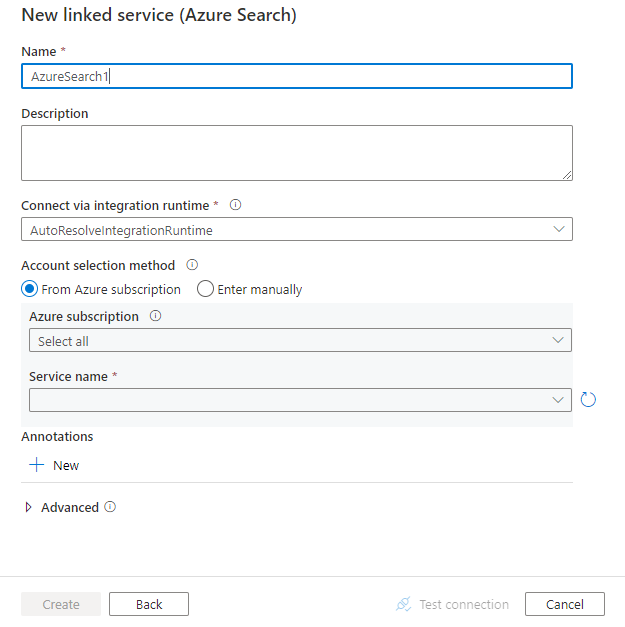
Konfigurieren Sie die Dienstdetails, testen Sie die Verbindung, und erstellen Sie den neuen verknüpften Dienst.

Details zur Connector-Konfiguration
Die folgenden Abschnitte enthalten Details zu JSON-Eigenschaften, die zum Definieren von Data Factory-Entitäten speziell für den Azure KI Search-Index verwendet werden.
Eigenschaften des verknüpften Diensts
Folgende Eigenschaften werden für den mit Azure KI Search verknüpften Dienst unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die type-Eigenschaft muss auf AzureSearch festgelegt werden. | Ja |
| url | URL für den Suchdienst | Ja |
| Schlüssel | Administratorschlüssel für den Suchdienst Markieren Sie dieses Feld als einen „SecureString“, um es sicher zu speichern, oder verweisen Sie auf ein in Azure Key Vault gespeichertes Geheimnis. | Ja |
| connectVia | Die Integrationslaufzeit, die zum Herstellen einer Verbindung mit dem Datenspeicher verwendet werden muss. Sie können die Azure-Integrationslaufzeit oder selbstgehostete Integrationslaufzeit verwenden (sofern sich Ihr Datenspeicher in einem privaten Netzwerk befindet). Wenn keine Option angegeben ist, wird die standardmäßige Azure Integration Runtime verwendet. | Nein |
Wichtig
Wenn Sie Daten aus einem Clouddatenspeicher in den Suchindex in dem mit Azure KI-Suche verknüpften Dienst kopieren, müssen Sie in connectVia auf eine Azure Integration Runtime-Instanz mit expliziter Region verweisen. Legen Sie die Region fest, in der sich Ihr Suchdienst befindet. Weitere Informationen finden Sie unter Azure Integration Runtime.
Beispiel:
{
"name": "AzureSearchLinkedService",
"properties": {
"type": "AzureSearch",
"typeProperties": {
"url": "https://<service>.search.windows.net",
"key": {
"type": "SecureString",
"value": "<AdminKey>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Dataset-Eigenschaften
Eine vollständige Liste mit den Abschnitten und Eigenschaften, die zum Definieren von Datasets zur Verfügung stehen, finden Sie im Artikel zu Datasets. Dieser Abschnitt enthält eine Liste der Eigenschaften, die vom Azure KI Search-Dataset unterstützt werden.
Beim Kopieren von Daten in Azure KI Search werden die folgenden Eigenschaften unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die type-Eigenschaft des Datasets muss auf AzureSearchIndex festgelegt werden. | Ja |
| indexName | Name des Suchindex. Der Dienst erstellt den Index nicht. Der Index muss in Azure KI Search vorhanden sein. | Ja |
Beispiel:
{
"name": "AzureSearchIndexDataset",
"properties": {
"type": "AzureSearchIndex",
"typeProperties" : {
"indexName": "products"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<Azure AI Search linked service name>",
"type": "LinkedServiceReference"
}
}
}
Eigenschaften der Kopieraktivität
Eine vollständige Liste mit den Abschnitten und Eigenschaften zum Definieren von Aktivitäten finden Sie im Artikel Pipelines. Dieser Abschnitt enthält eine Liste der Eigenschaften, die von der Azure KI Search-Quelle unterstützt werden.
Azure KISearch als Sink
Legen Sie zum Kopieren von Daten in Azure KI Search den Quelltyp in der Kopieraktivität auf AzureSearchIndexSink fest. Folgende Eigenschaften werden im Abschnitt sink der Kopieraktivität unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die type-Eigenschaft der Quelle der Kopieraktivität muss auf AzureSearchIndexSink festgelegt werden. | Ja |
| writeBehavior | Gibt an, ob ein Dokument zusammengeführt oder ersetzt werden soll, wenn es bereits im Index vorhanden ist. Siehe Eigenschaft „WriteBehavior“. Zulässige Werte sind Merge (Standard) und Upload. |
Nein |
| writeBatchSize | Lädt Daten in den Suchindex hoch, wenn die Puffergröße writeBatchSize erreicht. Einzelheiten finden Sie unter Eigenschaft „WriteBatchSize“. Zulässige Werte sind ganze Zahlen von 1 bis 1.000 (Standardwert „1.000“). |
Nein |
| maxConcurrentConnections | Die Obergrenze gleichzeitiger Verbindungen mit dem Datenspeicher während der Aktivitätsausführung. Geben Sie diesen Wert nur an, wenn Sie die Anzahl der gleichzeitigen Verbindungen begrenzen möchten. | Nein |
Eigenschaft „WriteBehavior“
AzureSearchSink fügt Daten ein/aktualisiert beim Schreiben von Daten. Dies bedeutet, dass Azure KI Search beim Schreiben eines Dokuments das bestehende Dokument aktualisiert, anstatt eine Konfliktausnahme auszulösen, wenn der Dokumentenschlüssel bereits im Suchindex vorhanden ist.
AzureSearchSink bietet die folgenden zwei Verhalten zum Einfügen/Aktualisieren (mithilfe des Azure Search SDK):
- Merge (Zusammenführen): kombiniert alle Spalten im neuen Dokument mit dem bestehenden. Bei Spalten mit Null-Wert im neuen Dokument wird der Wert im bestehenden Dokument beibehalten.
- Upload (Hochladen): Das neue Dokument ersetzt das bestehende. Bei Spalten, die nicht im neuen Dokument angegeben werden, wird der Wert auf Null gesetzt, unabhängig davon, ob ein Null-Wert im bestehenden Dokument vorhanden ist oder nicht.
Das Standardverhalten ist Merge.
Eigenschaft „writeBatchSize“
Der Azure KI Search-Dienst unterstützt das Schreiben von Dokumenten als Batch. Ein Batch kann 1 bis 1.000 Aktionen enthalten. Eine Aktion bearbeitet ein Dokument, um den Vorgang upload/merge auszuführen.
Beispiel:
"activities":[
{
"name": "CopyToAzureSearch",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure AI Search output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureSearchIndexSink",
"writeBehavior": "Merge"
}
}
}
]
Datentypunterstützung
In der folgenden Tabelle wird angegeben, ob ein Azure KI Search-Datentyp unterstützt wird oder nicht.
| Azure KI Search-Datentyp | In Azure KI Search-Senke unterstützt |
|---|---|
| String | J |
| Int32 | J |
| Int64 | J |
| Double | J |
| Boolean | J |
| DataTimeOffset | J |
| String Array | N |
| GeographyPoint | N |
Andere Datentypen (etwa ComplexType) werden derzeit nicht unterstützt. Eine vollständige Liste der unterstützten Azure KI Search-Datentypen finden Sie unter Unterstützte Datentypen (Azure KI Search).
Zugehöriger Inhalt
Eine Liste der Datenspeicher, die als Quelles und Senken für die Kopieraktivität unterstützt werden, finden Sie in der Dokumentation für Unterstützte Datenspeicher.