KI-erweiterte Werbegenerierung mit Azure Cosmos DB for MongoDB V-Kern
In diesem Leitfaden zeigen wir Ihnen, wie Sie mit unserem personalisierten KI-Assistenten Heelie dynamische Werbeinhalte erstellen können, die bei Ihrer Zielgruppe Anklang finden. Mit Azure Cosmos DB for MongoDB vCore nutzen wir die Vektorähnlichkeitssuche, um Bestandsbeschreibungen semantisch zu analysieren und mit Werbethemen abzugleichen. Der Prozess ermöglicht das Generieren von Vektoren für Bestandsbeschreibungen mithilfe von OpenAI-Einbettungen, die ihre semantische Tiefe erheblich verbessern. Diese Vektoren werden dann innerhalb der Cosmos DB for MongoDB vCore-Ressource gespeichert und indiziert. Beim Generieren von Inhalten für Werbung vektorisieren wir das Werbethema, um die am besten passenden Bestandselemente zu finden. Danach folgt ein RAG-Prozess (Retrieval Augmented Generation), bei dem die besten Treffer an OpenAI gesendet werden, um eine überzeugende Werbung zu erstellen. Die gesamte Codebasis für die Anwendung ist in einem GitHub-Repository für Ihre Referenz verfügbar.
Features
- Vektorähnlichkeitssuche: Verwendet Azure Cosmos DB für die leistungsstarke Vektorähnlichkeitssuche von MongoDB vCore, um die Semantik-Suchfunktionen zu verbessern, sodass relevante Bestandselemente einfacher auf der Grundlage des Inhalts von Werbung gefunden werden können.
- OpenAI-Einbettungen: Nutzt die modernsten Einbettungen aus OpenAI, um Vektoren für Bestandsbeschreibungen zu generieren. Dieser Ansatz ermöglicht differenziertere und semantische Übereinstimmungen zwischen dem Bestand und dem Werbeinhalt.
- Inhaltsgenerierung: Setzt die erweiterten Sprachmodelle von OpenAI ein, um ansprechende, trendorientierte Werbung zu generieren. Mit dieser Methode wird sichergestellt, dass der Inhalt nicht nur relevant, sondern auch an die Zielgruppe angepasst ist.
Voraussetzungen
- Azure OpenAI: Einrichten der Azure OpenAI-Ressource. Der Zugriff auf diesen Dienst ist aktuell nur auf Antrag verfügbar. Sie können den Zugriff auf Azure OpenAI beantragen, indem Sie das Formular unter https://aka.ms/oai/access ausfüllen. Nachdem Sie Zugriff haben, führen Sie die folgenden Schritte aus:
- Erstellen Sie eine Azure OpenAI-Ressource entsprechend diesem Schnellstart.
- Stellen Sie ein
completionsund einembeddings-Modell bereit. - Notieren Sie sich Ihre Endpunkt-, Schlüssel- und Bereitstellungsnamen.
- Cosmos DB for MongoDB vCore-Ressource: Beginnen wir damit, eine Azure Cosmos DB for MongoDB vCore-Ressource kostenlos zu erstellen, indem wir diese Schnellstartanleitung befolgen.
- Notieren Sie sich die Verbindungsdetails.
- Python-Umgebung (>= 3.9 Version) mit Paketen wie
numpy,openai,pymongo,python-dotenv,azure-core,azure-cosmos,tenacityundgradio. - Laden Sie die Datendatei herunter, und speichern Sie sie in einem bestimmten Datenordner.
Ausführen des Skripts
Bevor wir uns in den spannenden Teil der Generierung von KI-verbesserter Werbung eintauchen, müssen wir unsere Umgebung einrichten. Bei diesem Setup werden die erforderlichen Pakete installiert, um sicherzustellen, dass unser Skript reibungslos ausgeführt wird. Hier ist eine schrittweise Anleitung, um alles vorzubereiten.
1.1 Installieren der erforderlichen Pakete
Zunächst müssen wir einige Python-Pakete installieren. Öffnen Sie Ihr Terminal, und führen Sie die folgenden Befehle aus:
pip install numpy
pip install openai==1.2.3
pip install pymongo
pip install python-dotenv
pip install azure-core
pip install azure-cosmos
pip install tenacity
pip install gradio
pip show openai
1.2 Einrichten der OpenAI- und Azure-Clients
Nach der Installation der erforderlichen Pakete umfasst der nächste Schritt das Einrichten unserer OpenAI- und Azure-Clients für das Skript, das für die Authentifizierung unserer Anforderungen an die OpenAI-API und Azure-Dienste von entscheidender Bedeutung ist.
import json
import time
import openai
from dotenv import dotenv_values
from openai import AzureOpenAI
# Configure the API to use Azure as the provider
openai.api_type = "azure"
openai.api_key = "<AZURE_OPENAI_API_KEY>" # Replace with your actual Azure OpenAI API key
openai.api_base = "https://<OPENAI_ACCOUNT_NAME>.openai.azure.com/" # Replace with your OpenAI account name
openai.api_version = "2023-06-01-preview"
# Initialize the AzureOpenAI client with your API key, version, and endpoint
client = AzureOpenAI(
api_key=openai.api_key,
api_version=openai.api_version,
azure_endpoint=openai.api_base
)
Lösungsarchitektur
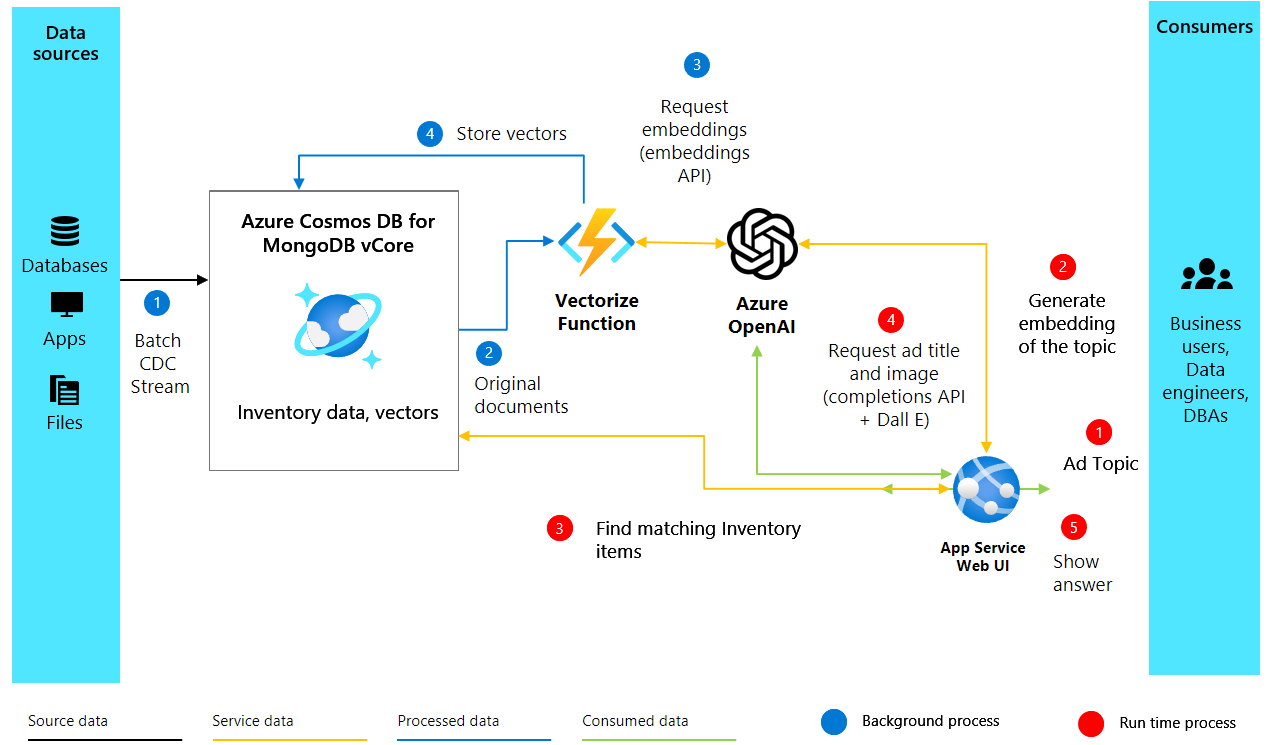
2. Erstellen von Einbettungen und Einrichten von Cosmos DB
Nach der Einrichtung unserer Umgebung und des OpenAI-Clients wechseln wir zum Kernteil unseres KI-erweiterten Werbegenerierungsprojekts. Der folgende Code erstellt Vektoreinbettungen aus Textbeschreibungen von Produkten und richtet unsere Datenbank in Azure Cosmos DB for MongoDB vCore ein, um diese Einbettungen zu speichern und zu durchsuchen.
2.1 Erstellen von Einbettungen
Um überzeugende Werbung zu generieren, müssen wir zunächst die Artikel in unserem Bestand verstehen. Dazu erstellen wir Vektoreinbettungen aus Beschreibungen unserer Elemente, mit denen wir ihre semantische Bedeutung in einer Form erfassen können, die Computer verstehen und verarbeiten können. Hier erfahren Sie, wie Sie Vektoreinbettungen für eine Elementbeschreibung mithilfe von Azure OpenAI erstellen können:
import openai
def generate_embeddings(text):
try:
response = client.embeddings.create(
input=text, model="text-embedding-ada-002")
embeddings = response.data[0].embedding
return embeddings
except Exception as e:
print(f"An error occurred: {e}")
return None
embeddings = generate_embeddings("Shoes for San Francisco summer")
if embeddings is not None:
print(embeddings)
Die Funktion verwendet eine Texteingabe – z. B. eine Produktbeschreibung – und verwendet die client.embeddings.create-Methode aus der OpenAI-API, um einen Vektoreinbettung für diesen Text zu generieren. Wir verwenden hier das text-embedding-ada-002-Modell, aber Sie können andere Modelle basierend auf Ihren Anforderungen auswählen. Wenn der Prozess erfolgreich ist, gibt er die generierten Einbettungen aus; andernfalls behandelt er Ausnahmen, indem eine Fehlermeldung ausgegeben wird.
3. Verbinden und Einrichten von Azure Cosmos DB for MongoDB vCore
Wenn unsere Einbettungen bereit sind, besteht der nächste Schritt darin, sie in einer Datenbank zu speichern und zu indizieren, die die Vektorgleichheitssuche unterstützt. Azure Cosmos DB for MongoDB vCore eignet sich perfekt für diese Aufgabe, da sie zum Speichern Ihrer Transaktionsdaten und zum Ausführen der Vektorsuche an einem zentralen Ort entwickelt wurde.
3.1 Einrichten der Verbindung
Um eine Verbindung mit Cosmos DB herzustellen, verwenden wir die Pymongo-Bibliothek, die es uns ermöglicht, einfach mit MongoDB zu interagieren. Der folgende Codeausschnitt stellt eine Verbindung mit unserer Cosmos DB for MongoDB vCore-Instanz her:
import pymongo
# Replace <USERNAME>, <PASSWORD>, and <VCORE_CLUSTER_NAME> with your actual credentials and cluster name
mongo_conn = "mongodb+srv://<USERNAME>:<PASSWORD>@<VCORE_CLUSTER_NAME>.mongocluster.cosmos.azure.com/?tls=true&authMechanism=SCRAM-SHA-256&retrywrites=false&maxIdleTimeMS=120000"
mongo_client = pymongo.MongoClient(mongo_conn)
Ersetzen Sie <USERNAME>, <PASSWORD> und <VCORE_CLUSTER_NAME> durch Ihren tatsächlichen MongoDB-Benutzernamen, das Kennwort bzw. den vCore-Clusternamen.
4. Einrichten der Datenbank und des Vektorindex in Cosmos DB
Nachdem Sie eine Verbindung mit Azure Cosmos DB hergestellt haben, müssen Sie Ihre Datenbank und Sammlung einrichten und dann einen Vektorindex erstellen, um effiziente Vektorgleichheitssuchen zu ermöglichen. Lassen Sie uns diese Schritte durchgehen.
4.1 Einrichten der Datenbank und Sammlung
Zunächst erstellen wir eine Datenbank und eine Sammlung in unserer Cosmos DB-Instanz. Folgende Funktionen stehen Ihnen dazu zur Verfügung:
DATABASE_NAME = "AdgenDatabase"
COLLECTION_NAME = "AdgenCollection"
mongo_client.drop_database(DATABASE_NAME)
db = mongo_client[DATABASE_NAME]
collection = db[COLLECTION_NAME]
if COLLECTION_NAME not in db.list_collection_names():
# Creates a unsharded collection that uses the DBs shared throughput
db.create_collection(COLLECTION_NAME)
print("Created collection '{}'.\n".format(COLLECTION_NAME))
else:
print("Using collection: '{}'.\n".format(COLLECTION_NAME))
4.2 Erstellen des Vektorindexes
Um effiziente Vektorgleichheitssuchen in unserer Sammlung durchzuführen, müssen wir einen Vektorindex erstellen. Cosmos DB unterstützt verschiedene Arten von Vektorindizes, und hier besprechen wir zwei: IVF und HNSW.
IVF
IVF steht für Inverted File Index. Dies ist der Standardvektorindizierungsalgorithmus, der auf allen Clusterebenen funktioniert. Es handelt sich um einen ANN-Ansatz (Approximate Nearest Neighbors), der Clustering verwendet, um die Suche nach ähnlichen Vektoren in einem Dataset zu beschleunigen. Um einen IVF-Index zu erstellen, verwenden Sie den folgenden Befehl:
db.command({
'createIndexes': COLLECTION_NAME,
'indexes': [
{
'name': 'vectorSearchIndex',
'key': {
"contentVector": "cosmosSearch"
},
'cosmosSearchOptions': {
'kind': 'vector-ivf',
'numLists': 1,
'similarity': 'COS',
'dimensions': 1536
}
}
]
});
Wichtig
Sie können nur einen Index pro Vektoreigenschaft erstellen. Das heißt, Sie können nicht mehr als einen Index erstellen, der auf dieselbe Vektoreigenschaft verweist. Wenn Sie den Indextyp (z. B. von IVF in HNSW) ändern möchten, müssen Sie den Index zuerst ablegen, bevor Sie einen neuen Index erstellen.
HNSW
HNSW steht für Hierarchical Navigable Small World, eine graphbasierte Datenstruktur, die Vektoren in Cluster und Untercluster partitioniert. Mit HNSW können Sie schnelle Nearest-Neighbor-Suchen mit höheren Geschwindigkeiten mit verbesserter Genauigkeit durchführen. HNSW ist eine ungefähre (ANN)-Methode. Die Einrichtung erfolgt folgendermaßen:
db.command(
{
"createIndexes": "ExampleCollection",
"indexes": [
{
"name": "VectorSearchIndex",
"key": {
"contentVector": "cosmosSearch"
},
"cosmosSearchOptions": {
"kind": "vector-hnsw",
"m": 16, # default value
"efConstruction": 64, # default value
"similarity": "COS",
"dimensions": 1536
}
}
]
}
)
Hinweis
Die HNSW-Indizierung ist nur auf M40-Clusterebenen und höher verfügbar.
5. Einfügen von Daten in die Sammlung
Fügen Sie nun die Bestandsdaten, die Beschreibungen und die entsprechenden Vektoreinbettungen enthalten, in die neu erstellte Sammlung ein. Um Daten in unsere Sammlung einzufügen, verwenden wir die von der pymongo-Bibliothek bereitgestellte insert_many()-Methode. Mit der Methode können wir mehrere Dokumente gleichzeitig in die Sammlung einfügen. Unsere Daten werden in einer JSON-Datei gespeichert, die wir laden und dann in die Datenbank einfügen.
Laden Sie die Datei shoes_with_vectors.json aus dem GitHub-Repository herunter, und speichern Sie sie in einem data-Verzeichnis in Ihrem Projektordner.
data_file = open(file="./data/shoes_with_vectors.json", mode="r")
data = json.load(data_file)
data_file.close()
result = collection.insert_many(data)
print(f"Number of data points added: {len(result.inserted_ids)}")
6. Vektorsuche in Cosmos DB for MongoDB vCore
Mit erfolgreich hochgeladenen Daten können wir nun die Leistungsfähigkeit der Vektorsuche anwenden, um die relevantesten Elemente basierend auf einer Abfrage zu finden. Der zuvor erstellte Vektorindex ermöglicht es uns, semantische Suchvorgänge innerhalb unseres Datasets durchzuführen.
6.1 Durchführen einer Vektorsuche
Zum Ausführen einer Vektorsuche definieren wir eine vector_search-Funktion, die eine Abfrage und die Anzahl der zurückzugebenden Ergebnisse verwendet. Die Funktion generiert einen Vektor für die Abfrage mithilfe der zuvor definierten generate_embeddings-Funktion, und verwendet dann die $search-Funktionalität von Cosmos DB, um die nächstgelegenen übereinstimmenden Elemente basierend auf ihren Vektoreinbettungen zu finden.
# Function to assist with vector search
def vector_search(query, num_results=3):
query_vector = generate_embeddings(query)
embeddings_list = []
pipeline = [
{
'$search': {
"cosmosSearch": {
"vector": query_vector,
"numLists": 1,
"path": "contentVector",
"k": num_results
},
"returnStoredSource": True }},
{'$project': { 'similarityScore': { '$meta': 'searchScore' }, 'document' : '$$ROOT' } }
]
results = collection.aggregate(pipeline)
return results
6.2 Durchführen einer Vektorsuchabfrage
Schließlich führen wir unsere Vektorsuchfunktion mit einer bestimmten Abfrage aus und verarbeiten die Ergebnisse, um sie anzuzeigen:
query = "Shoes for Seattle sweater weather"
results = vector_search(query, 3)
print("\nResults:\n")
for result in results:
print(f"Similarity Score: {result['similarityScore']}")
print(f"Title: {result['document']['name']}")
print(f"Price: {result['document']['price']}")
print(f"Material: {result['document']['material']}")
print(f"Image: {result['document']['img_url']}")
print(f"Purchase: {result['document']['purchase_url']}\n")
7. Generieren von Anzeigeninhalten mit GPT-4 und DALL.E
Wir kombinieren alle entwickelten Komponenten, um überzeugende Anzeigen zu erstellen, indem wir OpenAI GPT-4 für Text und DALL·E 3 für Bilder zu verwenden. Zusammen mit Vektorsuchergebnissen bilden sie eine vollständige Werbung. Außerdem stellen wir Heelie, unsere intelligente Assistentin, vor, die mit der Erstellung ansprechender Werbetaglines beauftragt wurde. Der anstehende Code zeigt Heelie in Aktion bei der Verbesserung unseres Werbeerstellungsprozesses.
from openai import OpenAI
def generate_ad_title(ad_topic):
system_prompt = '''
You are Heelie, an intelligent assistant for generating witty and cativating tagline for online advertisement.
- The ad campaign taglines that you generate are short and typically under 100 characters.
'''
user_prompt = f'''Generate a catchy, witty, and short sentence (less than 100 characters)
for an advertisement for selling shoes for {ad_topic}'''
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
]
response = client.chat.completions.create(
model="gpt-4",
messages=messages
)
return response.choices[0].message.content
def generate_ad_image(ad_topic):
daliClient = OpenAI(
api_key="<DALI_API_KEY>"
)
image_prompt = f'''
Generate a photorealistic image of an ad campaign for selling {ad_topic}.
The image should be clean, with the item being sold in the foreground with an easily identifiable landmark of the city in the background.
The image should also try to depict the weather of the location for the time of the year mentioned.
The image should not have any generated text overlay.
'''
response = daliClient.images.generate(
model="dall-e-3",
prompt= image_prompt,
size="1024x1024",
quality="standard",
n=1,
)
return response.data[0].url
def render_html_page(ad_topic):
# Find the matching shoes from the inventory
results = vector_search(ad_topic, 4)
ad_header = generate_ad_title(ad_topic)
ad_image_url = generate_ad_image(ad_topic)
with open('./data/ad-start.html', 'r', encoding='utf-8') as html_file:
html_content = html_file.read()
html_content += f'''<header>
<h1>{ad_header}</h1>
</header>'''
html_content += f'''
<section class="ad">
<img src="{ad_image_url}" alt="Base Ad Image" class="ad-image">
</section>'''
for result in results:
html_content += f'''
<section class="product">
<img src="{result['document']['img_url']}" alt="{result['document']['name']}" class="product-image">
<div class="product-details">
<h3 class="product-title" color="gray">{result['document']['name']}</h2>
<p class="product-price">{"$"+str(result['document']['price'])}</p>
<p class="product-description">{result['document']['description']}</p>
<a href="{result['document']['purchase_url']}" class="buy-now-button">Buy Now</a>
</div>
</section>
'''
html_content += '''</article>
</body>
</html>'''
return html_content
8. Zusammenfügen des Gesamtbilds
Um unsere Werbegenerierung interaktiv zu machen, verwenden wir Gradio, eine Python-Bibliothek zum Erstellen einfacher Webbenutzeroberflächen. Wir definieren eine Benutzeroberfläche, mit der Benutzer Werbethemen eingeben und dann dynamisch generieren und die resultierende Werbung anzeigen können.
import gradio as gr
css = """
button { background-color: purple; color: red; }
<style>
</style>
"""
with gr.Blocks(css=css, theme=gr.themes.Default(spacing_size=gr.themes.sizes.spacing_sm, radius_size="none")) as demo:
subject = gr.Textbox(placeholder="Ad Keywords", label="Prompt for Heelie!!")
btn = gr.Button("Generate Ad")
output_html = gr.HTML(label="Generated Ad HTML")
btn.click(render_html_page, [subject], output_html)
btn = gr.Button("Copy HTML")
if __name__ == "__main__":
demo.launch()
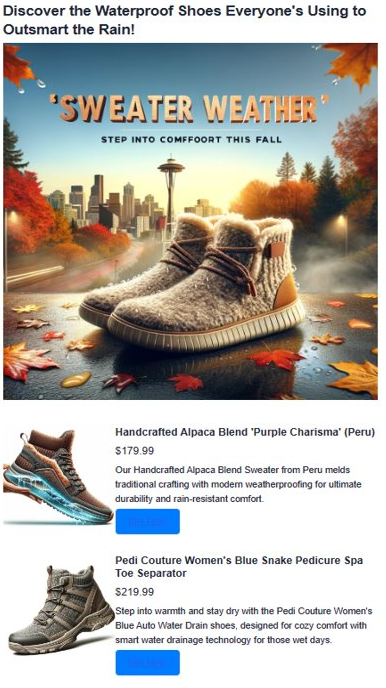
Output