Leistung und Problembehandlung für die SAP-Datenextraktion
Dieser Artikel ist Teil der Artikelreihe „SAP-Erweiterungs- und Innovationsdaten: Bewährte Methoden“.
- Identifizieren von SAP-Datenquellen
- Auswählen des besten SAP-Connectors
- Leistung und Problembehandlung für die SAP-Datenextraktion
- Datenintegrationssicherheit für SAP in Azure
- Generische SAP-Datenintegrationsarchitektur
Es gibt viele Möglichkeiten, für die Datenintegration eine Verbindung mit dem SAP-System herzustellen. In den folgenden Abschnitten werden allgemeine und connectorspezifische Überlegungen und Empfehlungen beschrieben.
Leistung
Es ist wichtig, optimale Einstellungen für die Quelle und das Ziel zu konfigurieren, damit Sie bei der Datenextraktion und Datenverarbeitung die beste Leistung erzielen können.
Allgemeine Hinweise
- Stellen Sie sicher, dass die richtigen SAP-Parameter für eine maximale Anzahl gleichzeitiger Verbindungen festgelegt sind.
- Erwägen Sie die Verwendung des SAP-Gruppenanmeldetyps für bessere Leistung und Lastverteilung.
- Stellen Sie sicher, dass der virtuelle Computer (VM) mit der selbstgehosteten Integration Runtime (SHIR) angemessen dimensioniert und hochverfügbar ist.
- Wenn Sie mit großen Datasets arbeiten, überprüfen Sie, ob der von Ihnen verwendete Connector eine Partitionierungsfunktion bietet. Viele der SAP-Connectors unterstützen Partitionierungs- und Parallelisierungsfunktionen, um das Laden von Daten zu beschleunigen. Wenn Sie diese Methode verwenden, werden Daten in kleinere Blöcke gepackt, die mit mehreren parallelen Prozessen geladen werden können. Weitere Informationen finden Sie in der Connector-spezifischen Dokumentation.
Allgemeine Empfehlungen
Verwenden Sie die SAP-Transaktion RZ12, um Werte für die maximale Anzahl gleichzeitiger Verbindungen zu ändern.
SAP-Parameter für RFC – RZ12: Der folgende Parameter kann die Anzahl der RFC-Aufrufe einschränken, die für einen Benutzer oder eine Anwendung zulässig sind. Stellen Sie daher sicher, dass diese Einschränkung keinen Engpass verursacht.
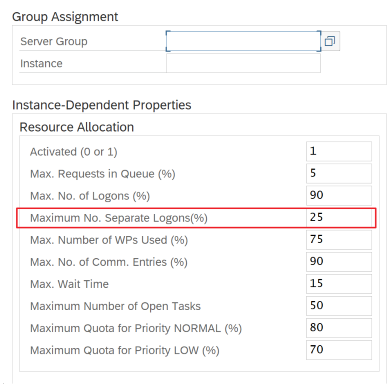
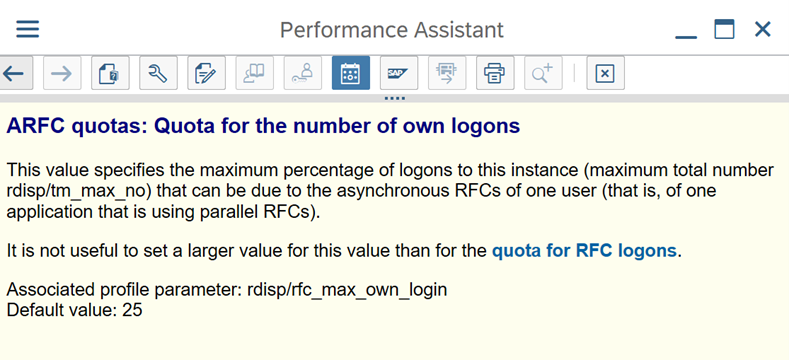
Verbindung mit SAP mithilfe der Anmeldegruppe: SHIR (Self-Hosted Integration Runtime) sollte eine Verbindung mit SAP herstellen, indem eine SAP-Anmeldegruppe (über den Nachrichtenserver) und nicht ein bestimmter Anwendungsserver verwendet wird, um eine Workloadverteilung auf alle verfügbaren Anwendungsserver sicherzustellen.
Hinweis
Dataflow Spark-Cluster und SHIR sind leistungsfähig. Viele interne SAP-Kopieraktivitäten, z. B. 16, können ausgelöst und ausgeführt werden. Wenn der Wert für die Anzahl gleichzeitiger Verbindungen des SAP-Servers jedoch klein ist, z. B. 8, liest die Funktion „perf“ Daten von der SAP-Seite.
Beginnen Sie mit 4 vCPUs und 16-GB-VMs für SHIR. Die folgenden Schritte zeigen die Verbindung des Dialogarbeitsprozesses in SAP mit SHIR.
- Überprüfen Sie, ob der Kunde einen schlechten physischen Computer verwendet, um SHIR einzurichten und zu installieren, um eine interne SAP-Kopie auszuführen.
- Navigieren Sie zum Azure Data Factory-Portal, und suchen Sie den zugehörigen verknüpften SAP CDC-Dienst, der im Datenfluss verwendet wird. Überprüfen Sie den SHIR-Namen, auf den verwiesen wird.
- Überprüfen Sie die Einstellungen für CPU, Arbeitsspeicher, Netzwerk und Datenträger des physischen Computers, auf dem SHIR installiert ist.
- Überprüfen Sie, wie viele
diawp.exeauf dem SHIR-Computer ausgeführt werden. Eindiawp.exekann eine Kopieraktivität ausführen. Die Anzahl vondiawp.exebasiert auf den Einstellungen für CPU, Arbeitsspeicher, Netzwerk und Datenträger des Computers.
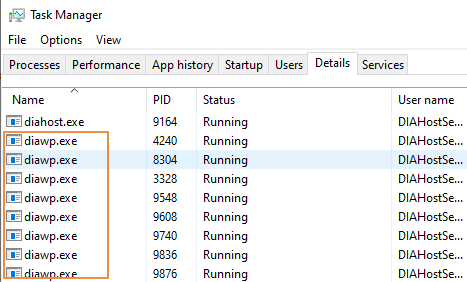
Wenn Sie mehrere Partitionen gleichzeitig auf SHIR ausführen möchten, verwenden Sie eine leistungsstarke VM, um SHIR einzurichten. Oder verwenden Sie die Funktion zum aufskalieren, indem Sie SHIR-Features für Hochverfügbarkeit und Skalierbarkeit verwenden, um über mehrere Knoten zu verfügen. Weitere Informationen finden Sie unter Hochverfügbarkeit und Skalierbarkeit.
Partitionen
Im folgenden Abschnitt wird der Partitionierungsprozess für einen SAP CDC-Connector beschrieben. Der Prozess ist für einen SAP-Tabellen- und einen SAP BW Open Hub-Connector identisch.

Die Skalierung kann für die selbstgehostete IR oder die Azure IR durchgeführt werden, abhängig von Ihren Leistungsanforderungen. Überprüfen Sie die CPU-Auslastung des SHIR, um Metriken anzuzeigen, die Ihnen bei der Entscheidung für Ihren Skalierungsansatz helfen. Der SHIR kann je nach Ihren Anforderungen vertikal oder horizontal skaliert werden. Wir empfehlen, die Azure IR zu einem niedrigeren SKU bereitzustellen. Skalieren Sie hoch, um Ihre durch Auslastungstests ermittelten Leistungsanforderungen zu erfüllen, anstatt unnötig am oberen Ende zu beginnen.
Hinweis
Wenn Sie eine Kapazität von 70 % erreichen, können Sie für SHIR hochskalieren oder aufskalieren.

Die Partitionierung ist für anfängliche oder große vollständige Ladevorgänge nützlich und ist in der Regel für Deltaladevorgänge nicht erforderlich. Wenn Sie die Partition nicht angeben, ruft standardmäßig 1 „Producer“ im SAP-System (in der Regel ein Batchprozess) die Quelldaten in die Warteschlange für operative Daten (Operational Data Queue, ODQ) ab, und SHIR ruft die Daten aus ODQ ab. Standardmäßig verwendet SHIR vier Threads, um die Daten aus der ODQ abzurufen, sodass zu diesem Zeitpunkt potenziell vier Dialogprozesse in SAP belegt sind.
Die Idee der Partitionierung besteht darin, ein großes Anfangsdataset in mehrere kleinere, nicht zusammenhängende Teilmengen aufzuteilen, die idealerweise gleich groß sind und parallel verarbeitet werden können. Diese Methode reduziert die Zeit, die benötigt wird, um die Daten aus der Quelltabelle linear in die ODQ zu übertragen. Bei dieser Methode wird davon ausgegangen, dass auf SAP-Seite genügend Ressourcen vorhanden sind, um das Laden zu bewältigen.
Hinweis
- Die Anzahl der parallel ausgeführten Partitionen wird durch die Anzahl der Treiberkerne in der Azure IR begrenzt. Eine Lösung für diese Einschränkung ist derzeit in Vorbereitung.
- Jede Einheit oder jedes Paket in der SAP-Transaktion ODQMON ist eine einzelne Datei im Stagingordner.
Entwurfsüberlegungen beim Ausführen der Pipelines mittels CDC
Überprüfen Sie die Dauer von SAP bis Phase.
Überprüfen Sie die Runtime-Leistung in der Senke.
Erwägen Sie die Verwendung des Partitionierungsfeatures, um die Leistung für einen besseren Durchsatz zu erhöhen.
Wenn die Dauer von SAP bis Phase langsam ist, sollten Sie die Größe von SHIR an höhere Spezifikationen anpassen.
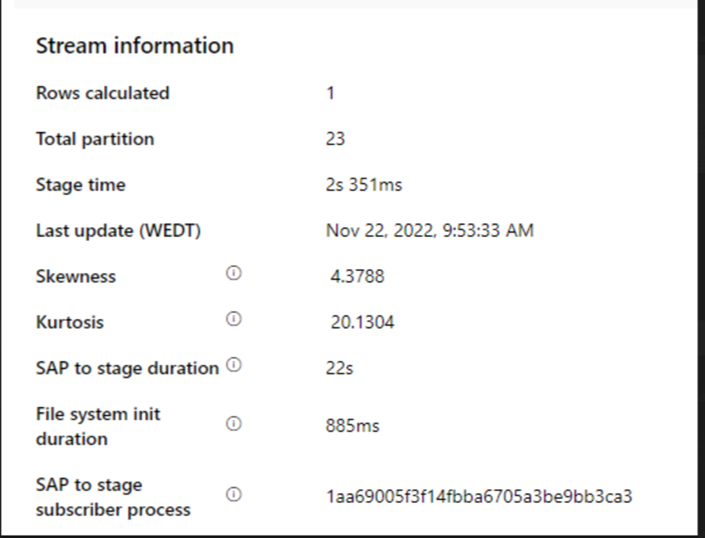
Überprüfen Sie, ob die Verarbeitungszeit der Senke zu langsam ist.
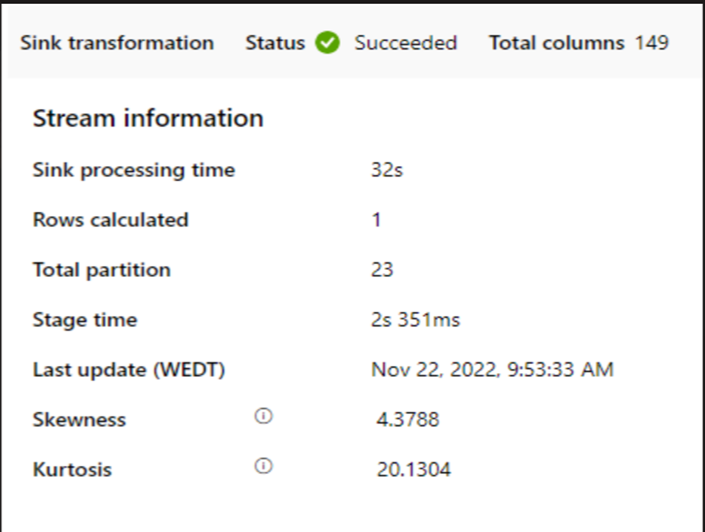
Wenn ein kleiner Cluster zum Ausführen des Zuordnungsdatenflusses verwendet wird, könnte sich dies auf die Leistung an der Senke auswirken. Verwenden Sie einen großen Cluster, z. B. 16 + 256 Kerne, damit die Funktion „perf“ die Daten von der Phase liest und in die Senke schreibt.
Für große Datenvolumen wird empfohlen, die Last zu partitionieren, um parallele Aufträge auszuführen, aber die Anzahl der Partitionen kleiner oder gleich den Azure IR-Kernen zu halten, die auch als Spark-Clusterkerne bezeichnet werden.
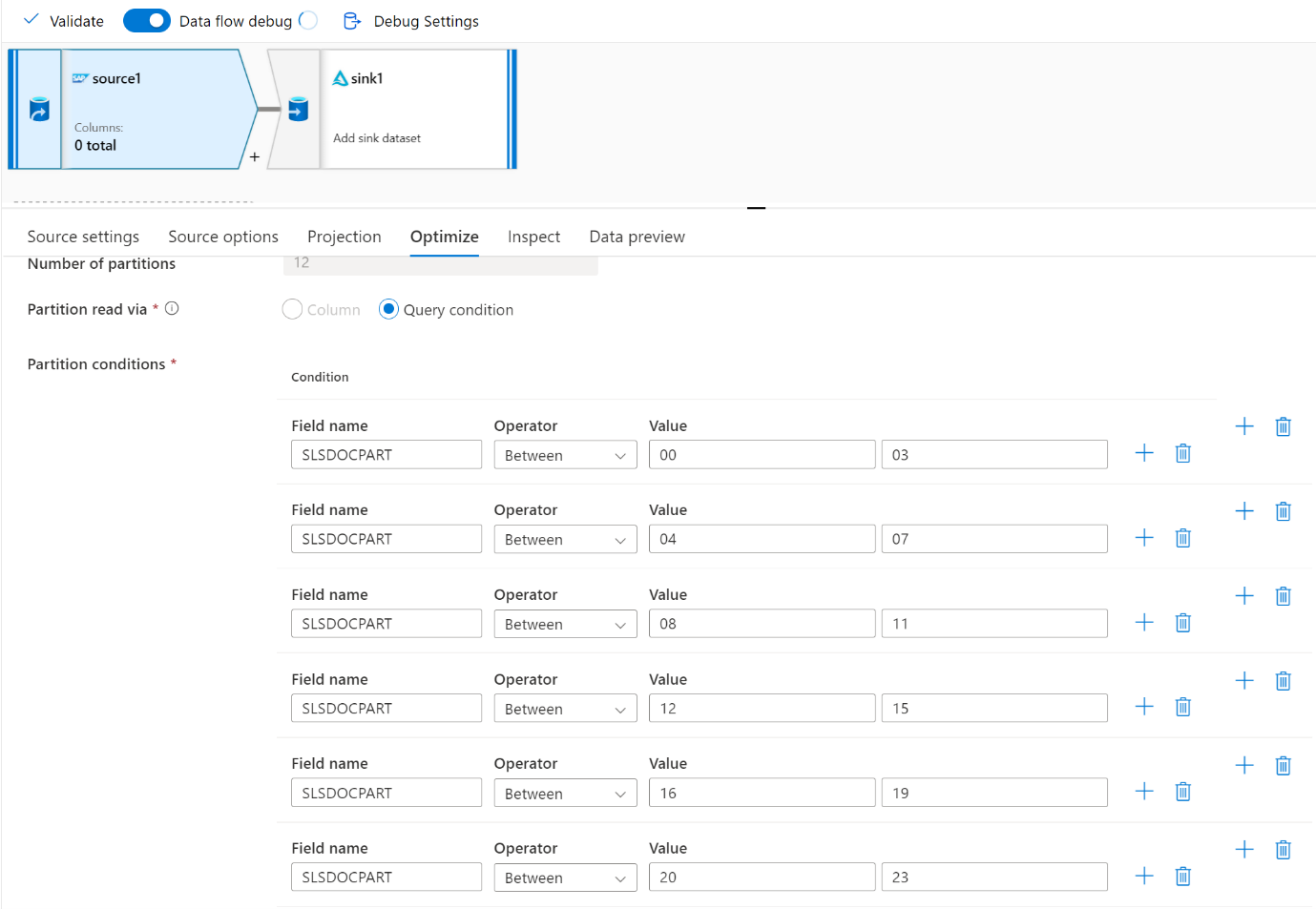
Verwenden Sie die Registerkarte Optimieren, um die Partitionen zu definieren. Sie können die Quellpartitionierung im CDC-Connector verwenden.
Hinweis
- Es besteht eine direkte Korrelation zwischen der Anzahl der Partitionen mit SHIR-Kernen und Azure IR-Knoten.
- Der SAP CDC-Connector wird unter ODQMON im SAP-System als Odata-Abonnententyp „Odata-Zugriff für operative Datenbereitstellung“ aufgeführt.
Entwurfsüberlegungen bei der Verwendung eines Tabellenconnectors
- Optimieren Sie die Partitionierung für eine bessere Leistung.
- Berücksichtigen Sie den Grad der Parallelität aus der SAP-Tabelle.
- Erwägen Sie einen Einzeldateientwurf für die Zielsenke.
- Vergleichen Sie den Durchsatz, wenn Sie große Datenvolumen verwenden.
Entwurfsempfehlungen bei Verwendung eines Tabellenconnectors
Partitionieren: Wenn Sie im SAP-Tabellenconnector partitionieren, wird eine zugrunde liegende SELECT-Anweisung in mehrere unterteilt, indem WHERE-Klauseln für ein geeignetes Feld verwendet werden, z. B. ein Feld mit hoher Kardinalität. Wenn Ihre SAP-Tabelle eine große Menge an Daten enthält, aktivieren Sie die Partitionierung, um die Daten in kleinere Partitionen aufzuteilen. Versuchen Sie, die Anzahl der Partitionen (Parameter
maxPartitionsNumber) so zu optimieren, dass die Partitionen klein genug sind, um Speicherabbilder in SAP zu vermeiden, aber groß genug, um die Extraktion zu beschleunigen.Parallelität: Der Grad der Kopierparallelität (Parameter
parallelCopies) funktioniert gemeinsam mit der Partitionierung und weist den SHIR an, parallele RFC-Aufrufe an das SAP-System zu tätigen. Wenn Sie diesen Parameter also beispielsweise auf 4 festlegen, generiert der Dienst gleichzeitig vier Abfragen und führt sie basierend auf der von Ihnen angegebenen Partitionsoption und den entsprechenden Einstellungen aus. Jede Abfrage ruft einen Teil der Daten aus Ihrer SAP-Tabelle ab.Um optimale Ergebnisse zu erzielen, sollte die Anzahl der Partitionen ein Vielfaches des Grads der Kopierparallelität sein.
Wenn Sie Daten aus der SAP-Tabelle in binäre Senken kopieren, wird die tatsächliche parallele Anzahl automatisch basierend auf der in SHIR verfügbaren Arbeitsspeichermenge angepasst. Notieren Sie sich die SHIR-VM-Größe für jeden Testzyklus, den Grad der Kopierparallelität und die Anzahl der Partitionen. Beobachten Sie die Leistung der SHIR-VM, die Leistung des SAP-Quellsystems und den gewünschten im Vergleich zum tatsächlichen Grad der Parallelität. Verwenden Sie einen iterativen Prozess, um die optimalen Einstellungen und die ideale Größe für die SHIR-VM zu identifizieren. Berücksichtigen Sie alle Erfassungspipelines, die gleichzeitig Daten aus einem oder mehreren SAP-Systemen laden.
Beobachten Sie die beobachtete Anzahl von RFC-Aufrufen an SAP im Vergleich zum konfigurierten Grad der Parallelität. Wenn die Anzahl der RFC-Aufrufe an SAP kleiner ist als der Grad der Parallelität, vergewissern Sie sich, dass die SHIR-VM über genügend Arbeitsspeicher und CPU-Ressourcen verfügt. Wählen Sie bei Bedarf eine größere VM aus. Das SAP-Quellsystem ist so konfiguriert, dass die Anzahl paralleler Verbindungen begrenzt wird. Weitere Informationen finden Sie im Abschnitt Allgemeine Empfehlungen in diesem Artikel.
Anzahl der Dateien: Wenn Sie Daten in einen dateibasierten Datenspeicher kopieren und die Zielsenke als Ordner konfiguriert ist, werden standardmäßig mehrere Dateien generiert. Wenn Sie die
fileName-Eigenschaft in der Senke festlegen, werden die Daten in eine einzelne Datei geschrieben. Es wird empfohlen, in einen Ordner als mehrere Dateien zu schreiben, da so ein höherer Schreibdurchsatz im Vergleich zum Schreiben in eine einzelne Datei erzielt wird.Leistungsbenchmark: Es wird empfohlen, die Übung zum Leistungsbenchmarking zu verwenden, um große Datenmengen zu erfassen. Diese Methode variiert Parameter wie Partitionierung, Grad der Parallelität und Anzahl von Dateien, um die optimale Einstellung für die gegebene Architektur, das Volumen und den Typ der Daten zu bestimmen. Sammeln Sie Daten aus Tests im folgenden Format.


Problembehandlung
Wenn die Extraktion aus dem SAP-System langsam ist oder fehlschlägt, verwenden Sie SAP-Protokolle von SM37, und gleichen Sie diese mit den Messwerten in Data Factory ab.
Wenn nur ein Batchauftrag ausgelöst wird, stellen Sie die SAP-Quellpartitionen ein, um eine Leistungsverbesserung des Zuordnungsdatenflusses in Data Factory zu erreichen. Weitere Informationen finden Sie in Schritt 6 unter Eigenschaften des Zuordnungsdatenflusses.
Wenn mehrere Batchaufträge im SAP-System ausgelöst werden, und es einen erheblichen Unterschied zwischen den Startzeiten der einzelnen Batchaufträge gibt, ändern Sie die Größe der Azure IR. Wenn Sie die Anzahl der Treiberknoten in Azure IR erhöhen, erhöht sich die Parallelität von Batchaufträgen auf der SAP-Seite.
Hinweis
Die maximale Anzahl von Treiberknoten für Azure IR beträgt 16. Jeder Treiberknoten kann nur einen Batchprozess auslösen.
Überprüfen Sie die Protokolle in SHIR. Wechseln Sie zum Anzeigen von Protokollen zur SHIR-VM. Öffnen Sie Ereignisanzeige > Anwendungen und Dienstprotokolle > Connectors > Integration Runtime.
Wechseln Sie zum Senden von Protokollen an den Support zur SHIR-VM. Öffnen Sie Integration Runtime-Konfigurationsmanager > Diagnose > Protokolle senden. Diese Aktion sendet die Protokolle der letzten sieben Tage und stellt Ihnen eine Berichts-ID bereit. Sie benötigen diese Berichts-ID und die RunId Ihrer Ausführung. Dokumentieren Sie die Berichts-ID zur späteren Referenz.
Wenn Sie den SAP CDC-Connector in einem SLT-Szenario verwenden:
Stellen Sie sicher, dass die Voraussetzungen erfüllt sind. Rollen sind für den SLT-Benutzer (SAP Landscape Transformation) erforderlich, z. B. ADFSLTUSER in OLTP-Systemen oder ECC, damit die SLT-Replikation funktioniert. Weitere Informationen finden Sie unter Welche Autorisierungen und Rollen sind erforderlich.
Wenn in einem SLT-Szenario Fehler auftreten, lesen Sie die Empfehlungen für die Analyse. Isolieren und testen Sie das Szenario zuerst innerhalb der SAP-Lösung. Testen Sie es beispielsweise außerhalb von Data Factory, indem Sie das von SAP
RODPS_REPL_TESTin SE38 bereitgestellte Testprogramm ausführen. Wenn das Problem auf der SAP-Seite liegt, erhalten Sie den gleichen Fehler, wenn Sie den Bericht verwenden. Sie können die Datenextraktion in SAP mithilfe des TransaktionscodesODQMONanalysieren.Wenn die Replikation funktioniert, wenn Sie diesen Testbericht verwenden, aber nicht mit Data Factory, wenden Sie sich an den Azure- oder Data Factory-Support.
Das folgende Beispiel zeigt einen Bericht für
RODPS_REPL_TESTin SE38: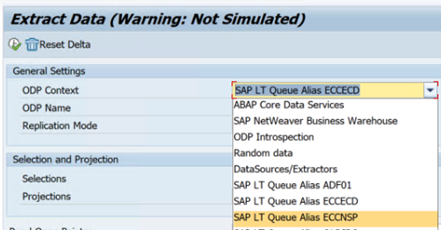
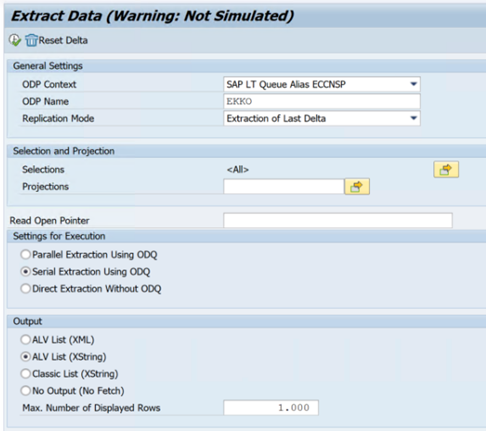

Das folgende Beispiel zeigt den Transaktionscode
ODQMON: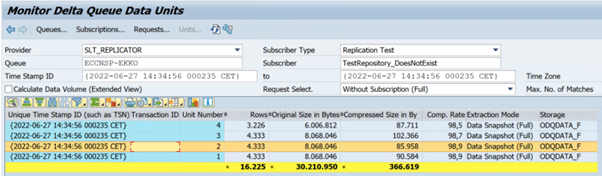
Wenn der verknüpfte Data Factory-Dienst eine Verbindung mit dem SLT-System herstellt, werden die IDs für die SLT-Massenübertragungen nicht angezeigt, wenn Sie das Feld Kontext aktualisieren.
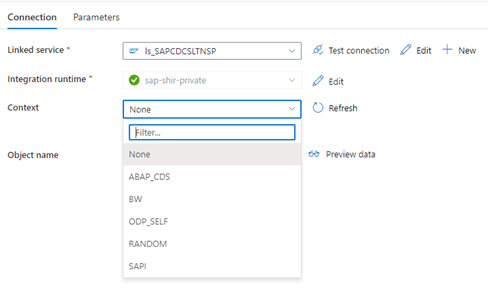
Um das ODP/ODQ-Replikationsszenario für den SAP LT-Replikationsserver auszuführen, aktivieren Sie die folgende BAdI (Business Add-In)-Implementierung.
BAdI:
BADI_ODQ_QUEUE_MODELErweiterungsimplementierung:
ODQ_ENH_SLT_REPLICATIONNavigieren Sie im Transaktions-LTRC zur Registerkarte Expertenfunktion, und wählen Sie Aktivieren/Deaktivieren der BAdI-Implementierung aus, um die Implementierung zu aktivieren.
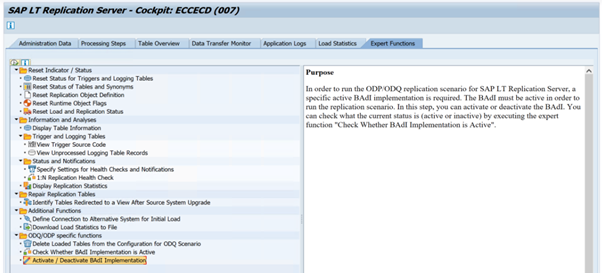
Wählen Sie Ja aus.
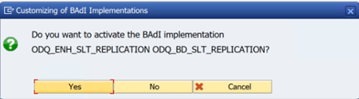
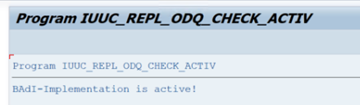
Wählen Sie im Ordner ODQ/ODP-spezifische Funktionen die Option Überprüfen, ob die BAdI-Implementierung aktiv ist aus.

Das Dialogfeld zeigt die Programmaktivität an.
Abonnements zurücksetzen. Um mit einer neuen Extraktion zu beginnen oder die Replikation von Daten zu beenden, entfernen Sie das Abonnement im ODQMON. Durch diese Aktion werden auch Einträge aus LTRC entfernt. Nach dem Zurücksetzen des Abonnements kann es einige Minuten dauern, bis die Auswirkung in LTRC angezeigt wird. Planen von ODP-Housekeepingaufträgen (Operational Data Provisioning), um die Deltawarteschlangen sauber zu halten, z. B.
ODQ_CLEANUP_CLIENT_004CDS_VIEW (DHCDCMON-Transaktion). Ab S/4HANA 1909 repliziert SAP Daten aus CDS-Ansichten, die datenbasierte Trigger anstelle von Datumsspalten verwenden. Das Konzept ähnelt SLT, aber anstatt die LTRC-Transaktion zu verwenden, um sie zu überwachen, verwenden Sie die DHCDCMON-Transaktion.
SLT-Problembehandlung
Der SLT-Replikationsserver bietet Datenreplikation in Echtzeit aus SAP-Quellen und/oder Nicht-SAP-Quellen zu SAP-Zielen und/oder Nicht-SAP-Zielen. Es gibt drei Arten von Toolsets zum Überwachen der Extraktion aus SLT in Azure.
- ODQMON ist das generelle Überwachungstool für die Datenextraktion. Starten Sie die Analyse mit ODQMON, um Dateninkonsistenzen nachzuverfolgen, für eine anfängliche Leistungsanalyse sowie um Abonnement- und Extraktionsanforderungen zu öffnen.
- LTRC ist die Transaktion, die zum Überprüfen der Leistungsanalyse gedacht ist. Dies ist nützlich, wenn Sie Probleme mit der Datenreplikation vom Quellsystem in ODP haben, da Sie den Dataflow überwachen und Inkonsistenzen finden können.
- SM37 bietet eine detaillierte Überwachung der einzelnen SLT-Extraktionsschritte.
Das normale Housekeeping sollte mit ODQMON erfolgen, wobei Sie das Abonnement direkt verwalten können. LTRC sollten Sie nicht für dasselbe verwenden.
Beim Extrahieren von Daten aus SLT können Probleme auftreten, z. B.:
Die Extraktion wird nicht ausgeführt. Überprüfen Sie, ob die SAP CDC-Verbindung eine Verbindung in ODQMON erstellt hat, und überprüfen Sie, ob das Abonnement vorhanden ist.
Dateninkonsistenzen. Überprüfen Sie ODQMON, um die einzelne Anforderung von Daten anzuzeigen, und vergewissern Sie sich, dass Sie dort Daten sehen können. Wenn Sie die Daten in ODQMON, aber nicht in Azure Synapse oder Data Factory sehen können, sollte die Untersuchung auf Azure-Seite erfolgen. Wenn Sie die Daten in ODQMON nicht sehen können, führen Sie eine Analyse des SLT-Frameworks mithilfe von LTRC durch.
Leistungsprobleme. Die Datenextraktion ist ein zweistufiger Ansatz. Zunächst liest SLT Daten aus dem Quellsystem und überträgt sie an ODP. Im zweiten Schritt übernimmt der SAP CDC-Connector die Daten von ODP und überträgt sie in den ausgewählten Datenspeicher. Mit der LTRC-Transaktion können Sie den ersten Teil des Extraktionsprozesses analysieren. Um die Datenextraktion aus ODP in Azure zu analysieren, verwenden Sie ODQMON und Data Factory oder Synapse-Überwachungstools.
Hinweis
Weitere Informationen finden Sie in den folgenden Ressourcen:
SLT-Leistung
Im anfänglichen Lademodus (ODPSLT) gibt es drei Schritte, um Daten aus SLT in ODP zu extrahieren:
- Erstellen von Migrationsobjekten. Dieser Vorgang dauert nur ein paar Sekunden.
- Zugreifen auf die Planberechnung, die die Quelltabelle in kleinere Blöcke aufteilt. Dieser Schritt hängt vom anfänglichen Lademodus ab, den Sie während der SLT-Konfiguration auswählen, sowie von der Größe der Tabelle. Die ressourcenoptimierte Option wird empfohlen.
- Der Datenladevorgang überträgt die Daten aus dem Quellsystem in ODP.
Jeder Schritt wird von den Hintergrundaufträgen gesteuert. Sie können die SM37- und LTRC-Transaktionen verwenden, um die Dauer zu überwachen. Wenn Ihr System überlastet ist, werden die Hintergrundaufträge möglicherweise später gestartet, da nicht genügend kostenlose Batcharbeitsprozesse vorhanden sind. Wenn Sich Aufgaben im Leerlauf befinden, leidet die Leistung.
Wenn die Berechnung des Zugriffsplans lange dauert und Ihr anfänglicher Lademodus auf „leistungsoptimiert“ festgelegt ist, ändern Sie ihn in „ressourcenoptimiert“, und führen Sie die Extraktion erneut aus. Wenn das Laden der Daten sehr lange dauert, erhöhen Sie die Anzahl der parallelen Threads in der Konfiguration.
Wenn Sie eine eigenständige Architektur für die SLT-Replikation verwenden (dedizierter SLT-Replikationsserver), kann sich der Netzwerkdurchsatz zwischen Quellsystem und Replikationsserver auf die Extraktionsleistung auswirken.
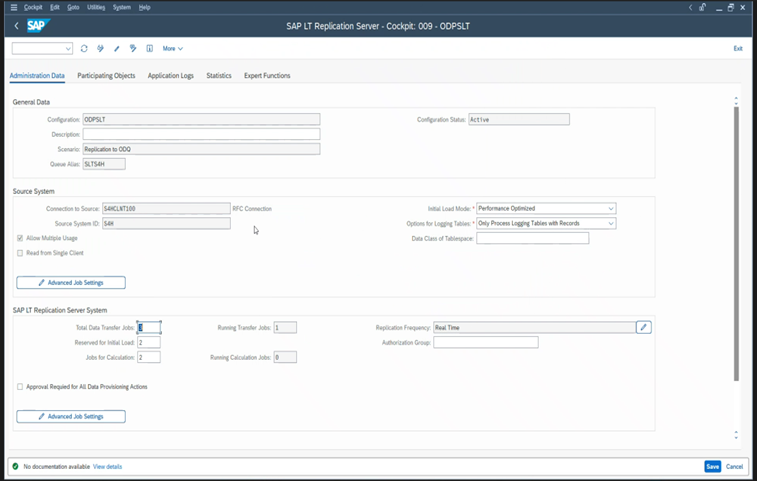
Für die Replikation:
- Stellen Sie sicher, dass Sie über genügend Datenübertragungsaufträge verfügen, die nicht für das anfängliche Laden reserviert sind.
- Vergewissern Sie sich, dass in der Ladestatistik kein nicht verarbeiteter Datensatz der Protokollierungstabelle vorhanden ist.
- Stellen Sie sicher, dass die Replikationsoption auf „Echtzeit“ festgelegt ist.
Erweiterte Replikationseinstellungen sind in LTRS verfügbar. Weitere Informationen finden Sie im Leitfaden zur Problembehandlung für SLT.
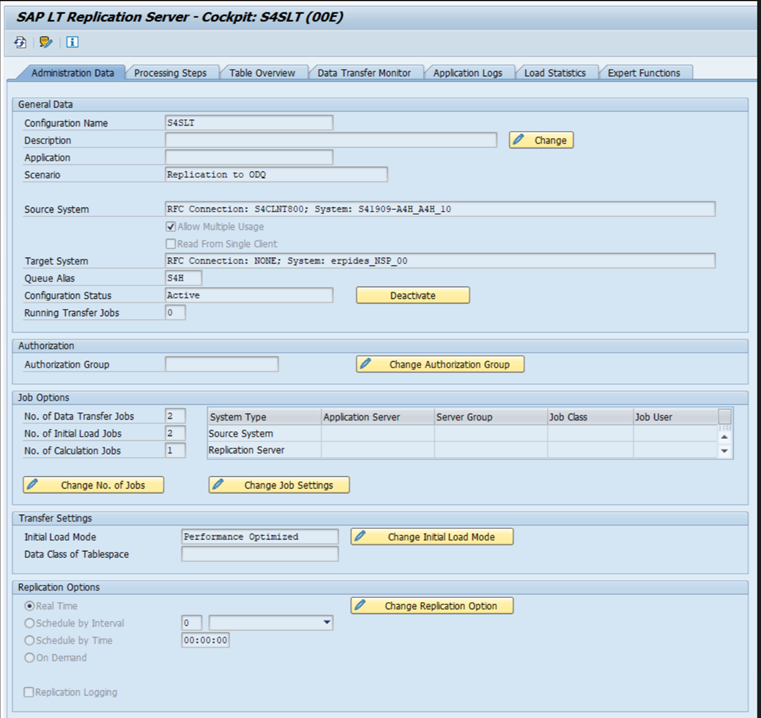
Unterschiedliche SAP-Releases verfügen über unterschiedliche LTRC-Benutzeroberflächen. Die folgenden Screenshots zeigen dieselbe Seite für zwei verschiedene Releases.
SAP S/4HANA:
SAP ECC:


Monitor
Informationen zum Überwachen der SAP-Datenextraktion finden Sie in den folgenden Ressourcen: