Datenqualität
Die Datenqualität ist eine Verwaltungsfunktion der Analysen auf Cloudebene. Sie befindet sich in der Datenverwaltungszielzone und ist ein Herzstück der Governance.
Überlegungen zur Datenqualität
Die Datenqualität ist die Verantwortung jeder Person, die Datenprodukte erstellt und nutzt. Ersteller müssen die globalen und Domänenregeln einhalten, während Verbraucher Dateninkonsistenzen über eine Feedbackschleife an die eigene Datendomäne melden.
Da sich die Datenqualität auf alle Daten auswirkt, die dem Board bereitgestellt werden, muss sie auf oberster Organisationsebene beginnen. Das Board sollte Einblicke in die Qualität der ihnen zur Verfügung gestellten Daten haben.
Auch wenn Sie proaktiv vorgehen, müssen Sie Datenqualitätsexperten haben, die Buckets von Daten bereinigen können, die eine Wartung erfordern. Vermeiden Sie es, diese Arbeit an ein zentrales Team zu übertragen und stattdessen auf die Datendomäne mit spezifischem Datenwissen zu zielen, um die Daten zu reinigen.
Datenqualitätsmetriken
Datenqualitätsmetriken sind wichtig, um die Qualität Ihrer Datenprodukte zu bewerten und zu erhöhen. Sie müssen sich auf globaler und Domänenebene für Qualitätsmetriken entscheiden. Mindestens empfehlen wir die folgenden Metriken:
| Metriken | Metrikdefinitionen |
|---|---|
| Vollständigkeit = Prozent der Gesamtsumme von Nicht-NULL-Werten + nicht leere Werte | Misst die Verfügbarkeit von Daten, Felder im Dataset, die nicht leer sind, und Standardwerte, die geändert wurden. Wenn z. B. ein Datensatz 01.01.1900 als Geburtsdatum enthält, ist es höchstwahrscheinlich, dass das Feld nie aufgefüllt wurde. |
| Eindeutigkeit = Prozent nicht duplizierter Werte | Misst unterschiedliche Werte in einer bestimmten Spalte im Vergleich zur Anzahl der Zeilen in der Tabelle. Wenn Sie beispielsweise vier unterschiedliche Farbwerte (rot, blau, gelb und grün) in einer Tabelle mit fünf Zeilen angegeben haben, ist dieses Feld zu 80 % (oder 4/5) eindeutig. |
| Konsistenz = % der Daten mit Mustern | Misst die Compliance innerhalb einer bestimmten Spalte mit dem jeweils erwarteten Datentyp oder Format. Zum Beispiel ein E-Mail-Feld mit formatierten E-Mail-Adressen oder ein Namensfeld mit numerischen Werten. |
| Gültigkeit = % der Referenzzuordnung | Misst erfolgreiche Datenabgleiche mit der jeweiligen Domänenverweismenge. Zum Beispiel ist ein vorgegebenes Feld Land/Region (das die Taxonomiewerte einhält) in einem Transaktionsdatensystem nicht gültig, wenn der Wert mit „US von A“ angegeben wird. |
| Genauigkeit = % der unveränderten Werte | Misst die erfolgreiche Reproduktion der vorgesehenen Werte in mehreren Systemen. Wenn beispielsweise eine Rechnung eine SKU und einen erweiterten Preis darstellt, der sich von der ursprünglichen Bestellung unterscheidet, ist das Rechnungszeilenelement ungenau. |
| Bindung = % der integrierten Daten | Misst die erfolgreiche Zuordnung zu den jeweiligen Begleitreferenzdetails in einem anderen System. Wenn beispielsweise eine Rechnung eine falsche SKU- oder Produktbeschreibung darstellt, ist das Rechnungszeilenelement nicht verbunden. |
Datenprofilerstellung
Die Datenprofilerstellung untersucht Datenprodukte, die im Datenkatalog registriert sind, und sammelt Statistiken und Informationen zu diesen Daten. Wenn Sie Zusammenfassungs- und Trendansichten über die Datenqualität im Laufe der Zeit bereitstellen möchten, speichern Sie diese Daten im Metadaten-Repository für das Datenprodukt.
Datenprofile helfen Benutzern, Fragen zu Datenprodukten zu beantworten, einschließlich:
- Können die Daten verwendet werden, um mein Geschäftsproblem zu lösen?
- Erfüllen die Daten bestimmte Standards oder Muster?
- Welche Anomalien bestehen für die Datenquelle?
- Was sind die möglichen Herausforderungen, diese Daten in meine Anwendung zu integrieren?
Benutzer können das Datenproduktprofil mithilfe eines Berichts-Dashboards innerhalb ihres Daten-Marketplace anzeigen.
Sie können z. B. über folgende Elemente berichten:
- Vollständigkeit: Gibt den Prozentsatz der Daten an, die nicht leer oder null sind.
- Eindeutigkeit: Gibt den Prozentsatz der Daten an, die nicht dupliziert werden.
- Konsistenz: Gibt Daten an, bei denen die Datenintegrität aufrechterhalten wird.
Empfehlungen zur Datenqualität
Zur Implementierung der Datenqualität müssen Sie sowohl menschliche als auch Rechenkraft wie folgt verwenden:
Verwenden Sie Lösungen, die Algorithmen, Regeln, Datenprofilerstellung und Metriken enthalten.
Setzen Sie Domänenexperten ein, die einschreiten können, wenn eine Anforderung zum Trainieren eines Algorithmus aufgrund einer hohen Anzahl von Fehlern besteht, die die Berechnungsebene passieren.
Führen Sie frühzeitig Überprüfungen aus. Herkömmliche Lösungen wenden Datenqualitätsprüfungen nach dem Extrahieren, Transformieren und Laden der Daten an. Mit der Zeit wird das Datenprodukt bereits eingesetzt und Fehler kommen bei nachgelagerten Datenprodukten auf. Stattdessen sollten Sie, wenn Daten aus der Quelle aufgenommen werden, Datenqualitätsprüfungen in der Nähe der Quellen implementieren und bevor nachgelagerte Verbraucher die Datenprodukte verwenden. Wenn eine Batcherfassung aus dem Data Lake erfolgt, führen Sie diese Überprüfungen durch, wenn Daten von der Rohdatenebene auf die Ebene der angereicherten Daten verschoben werden.
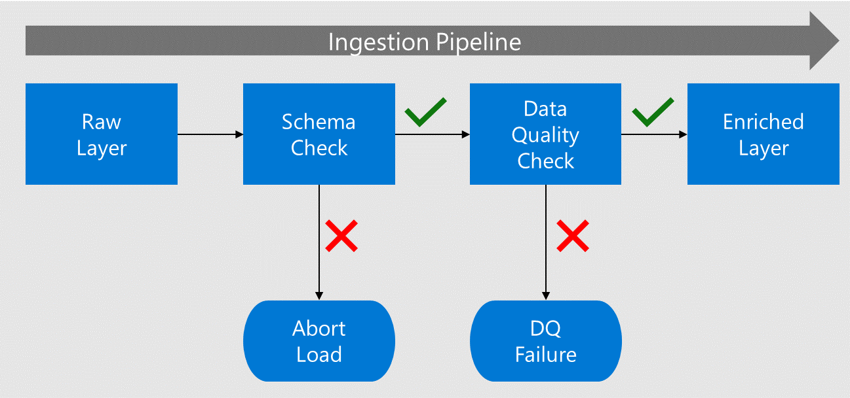
Bevor Daten auf die Ebene der angereicherten Daten verschoben werden, werden ihr Schema und ihre Spalten anhand der im Datenkatalog registrierten Metadaten überprüft.
Wenn die Daten Fehler enthalten, wird das Laden beendet, und das Datenanwendungsteam wird über den Fehler benachrichtigt.
Wenn das Schema und die Spalten erfolgreich überprüft wurden, werden die Daten in die Ebenen der angereicherten Daten mit konformen Datentypen geladen.
Bevor Sie zur angereicherten Ebene wechseln, überprüft ein Datenqualitätsprozess die Compliance der Algorithmen und Regeln.

Tipp
Definieren Sie Datenqualitätsregeln sowohl auf globaler als auch auf Domänenebene. Damit kann das Unternehmen seine Normen für jedes erstellte Datenprodukt definieren und Datendomänen können zusätzliche Regeln für ihre Domäne erstellen.
Datenqualitätslösungen
Wir empfehlen, Microsoft Purview Data Quality als Lösung für die Bewertung und Verwaltung der Datenqualität zu testen. Dies ist entscheidend für zuverlässige KI-gesteuerte Erkenntnisse und Entscheidungsfindung. Sie hat folgenden Inhalt:
- No-Code-/Low-Code-Regeln: Bewerten der Datenqualität mithilfe sofort einsatzbereiter, KI-generierter Regeln.
- KI-gesteuerte Datenprofilerstellung: Empfiehlt Spalten für die Profilerstellung und ermöglicht menschliche Eingriffe zur Optimierung.
- Datenqualitätsbewertung: Stellt Bewertungen für Datenressourcen, Datenprodukte und Governancedomänen bereit.
- Warnungen zur Datenqualität: Macht Datenbesitzer auf Qualitätsprobleme aufmerksam.
Weitere Informationen finden Sie unter Was ist Datenqualität?
Wenn Ihre Organisation entscheidet, Azure Databricks zum Bearbeiten von Daten zu implementieren, sollten Sie die Von dieser Lösung angebotenen Datenqualitätskontrollen, -tests, -überwachung und -durchsetzung bewerten. Die Verwendung von Erwartungen kann Datenqualitätsprobleme bei der Erfassung feststellen, bevor sie sich auf verwandte untergeordnete Datenprodukte auswirken. Weitere Informationen finden Sie unter Bewährte Methoden für Data Governance und KI-Governance sowie unter Datenqualitätsmanagement mit Databricks.
Sie können auch aus Partnern, Open Source und benutzerdefinierten Optionen eine Datenqualitätslösung auswählen.
Datenqualitätszusammenfassung
Die Behebung der Datenqualität kann schwerwiegende Folgen für ein Unternehmen haben. Es kann dazu führen, dass Geschäftseinheiten Datenprodukte auf unterschiedliche Weise interpretieren. Diese Fehlinterpretation kann für das Unternehmen kostspielig sein, wenn Entscheidungen auf Datenprodukten mit geringerer Datenqualität basieren. Das Beheben von Datenprodukten mit fehlenden Attributen kann eine teure Aufgabe sein und kann vollständige Neuladevorgänge von Daten aus mehreren Zeiträumen erfordern.
Überprüfen Sie die Datenqualität frühzeitig, und stellen Sie Prozesse bereit, um proaktiv eine schlechte Datenqualität zu beheben. Beispielsweise kann ein Datenprodukt erst für die Produktion freigegeben werden, wenn es eine bestimmte Vollständigkeit erreicht.
Sie können Tools nach Belieben einsetzen, müssen aber sicherstellen, dass sie Erwartungen (Regeln), Datenmetriken, Profilerstellung und die Möglichkeit, die Erwartungen zu sichern beinhalten, damit Sie globale und domänenbasierte Erwartungen implementieren können.