Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Ein Datengittermodell unterstützt Organisationen bei der Umstellung von einem zentralisierten Data Lake oder Data Warehouse auf eine domänengesteuerte Dezentralisierung von Analysedaten auf der Grundlage von vier Prinzipien: Domänenbesitz, Daten als Produkt, Self-Service-Datenplattform und rechenbezogene Partnergovernance. Data Mesh bietet die Vorteile eines verteilten Datenbesitzes sowie einer verbesserten Datenqualität und Governance, die den Geschäftserfolg und die Wertschöpfungszeit für Organisationen beschleunigen.
Datengitterimplementierung
Eine typische Datengitterimplementierung umfasst Domänenteams mit Datentechnikern, die Datenpipelinen erstellen. Das Team verwaltet operative und analytische Datenspeicher wie Data Lakes, ein Data Warehouse oder ein Data Lakehouse. Sie geben die Pipelines als Datenprodukte frei, die von anderen Domänenteams oder Data-Science-Teams genutzt werden können. Andere Teams nutzen die Datenprodukte mithilfe einer zentralen Daten-Governance-Plattform, wie im folgenden Diagramm dargestellt.
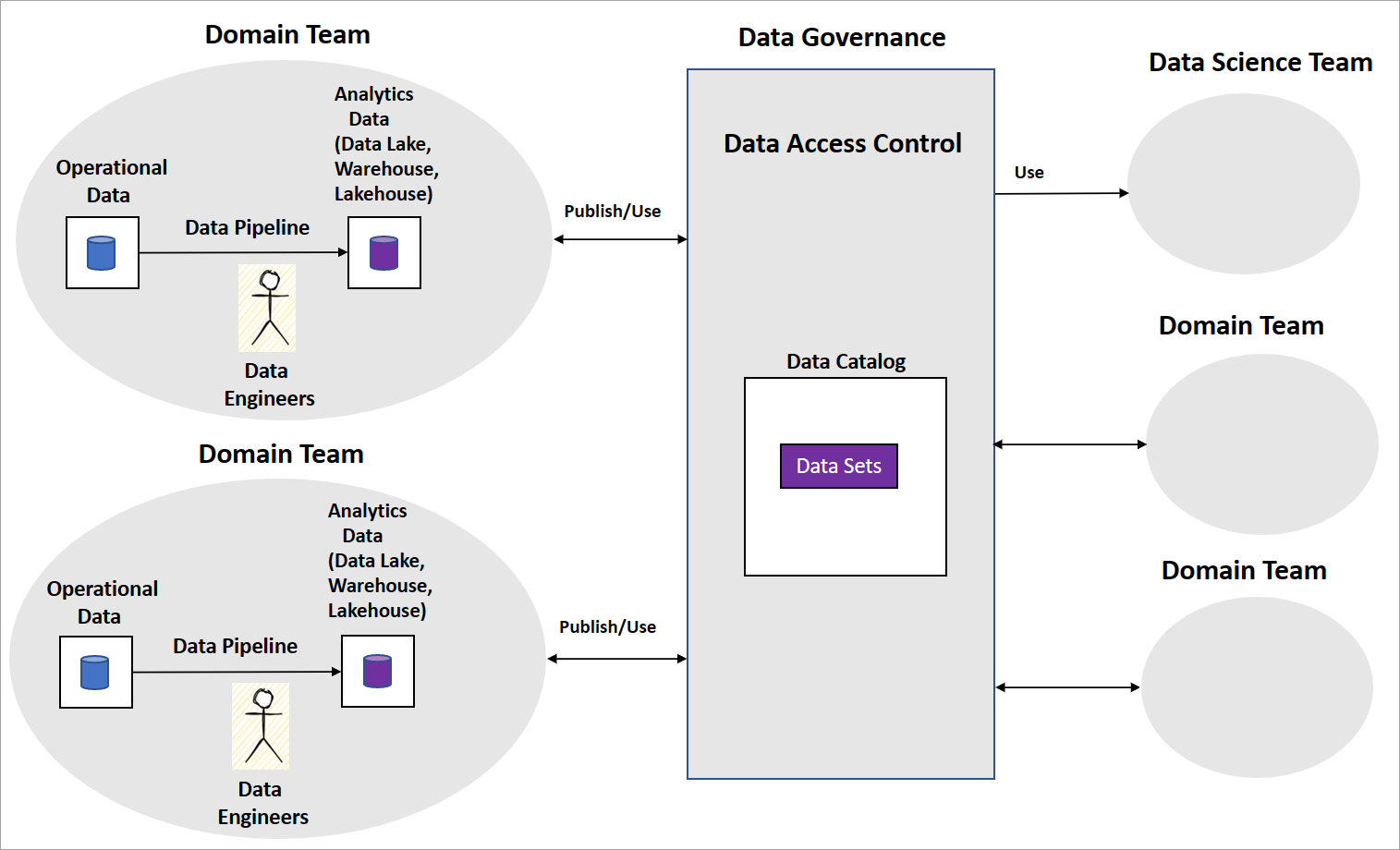
Bei einem Datengittermodell ist klar, wie Datenprodukte transformierte und aggregierte Datasets für Business Intelligence bereitstellen. Aber es macht nicht klar, welchen Ansatz Organisationen verfolgen sollten, um KI-/ML-Modelle zu erstellen. Es gibt auch keine Richtlinien zur Strukturierung ihrer Data Science-Teams, zur KI/ML-Modell-Governance und zum Teilen von KI/ML-Modellen oder -Funktionen zwischen Domänenteams.
Im folgenden Abschnitt werden einige Strategien beschrieben, mit denen Organisationen KI/ML-Funktionen innerhalb des Datengitters entwickeln können. Es wird ein Vorschlag für eine Strategie zu domänengesteuerter Featurisierung oder einem Featuregittermodell angezeigt.
KI/ML-Strategien für Datengitter
Eine gemeinsame Strategie besteht darin, dass die Organisation Data Science-Teams als Datenkonsumenten einführen kann. Diese Teams greifen je nach Anwendungsfall auf verschiedene Domänendatenprodukte im Datengittermodell zu. Sie führen Datenerkundungs- und Feature-Engineering durch, um KI/ML-Modelle zu entwickeln und zu erstellen. In einigen Fällen entwickeln Domänenteams auch eigene KI/ML-Modelle, indem sie ihre Daten und die Datenprodukte anderer Teams verwenden, um neue Features zu erweitern und abzuleiten.
Featurisierung ist das Herzstück der Modellerstellung. Sie ist in der Regel komplex und erfordert Domänenkenntnisse. Diese Strategie kann zeitaufwendig sein, da Data Science-Teams verschiedene Datenprodukte analysieren müssen. Möglicherweise verfügen sie nicht über vollständige Domänenkenntnisse, um qualitativ hochwertige Features zu erstellen. Mangel an Domänenwissen kann zu doppelten Feature engineering-Bemühungen zwischen Domänenteams führen. Außerdem können Probleme wie die Reproduzierbarkeit von KI-/ML-Modellen aufgrund inkonsistenter Featuresätze in verschiedenen Teams auftreten. Data Science- oder Domänenteams müssen Features kontinuierlich aktualisieren, wenn neue Versionen von Datenprodukten veröffentlicht werden.
Eine weitere Strategie ist es, dass Domänenteams KI/ML-Modelle in einem Format wie Open Neural Network Exchange (ONNX) freigeben, aber diese Ergebnisse sind Schwarze Kästchen und die Kombination von KI/ML-Modellen oder Features in allen Domänen wäre schwierig.
Gibt es eine Möglichkeit, den Aufbau von KI/ML-Modellen über Domänen- und Data-Science-Teams hinweg zu dezentralisieren, um die Herausforderungen zu bewältigen? Die vorgeschlagene domänengetriebene Feature-Engineering- oder Feature-Gitter-Strategie ist eine Option.
Domänengesteuerte Featurisierungs- oder Featuregittermodell-Strategie
Die domänengesteuerte Feature-Engineering- oder Feature-Mesh-Strategie bietet einen dezentralen Ansatz für die KI/ML-Modellerstellung in einer Daten-Mesh-Umgebung. Das folgende Diagramm zeigt die Strategie und wie sie die vier Hauptprinzipien des Data Mesh anspricht.
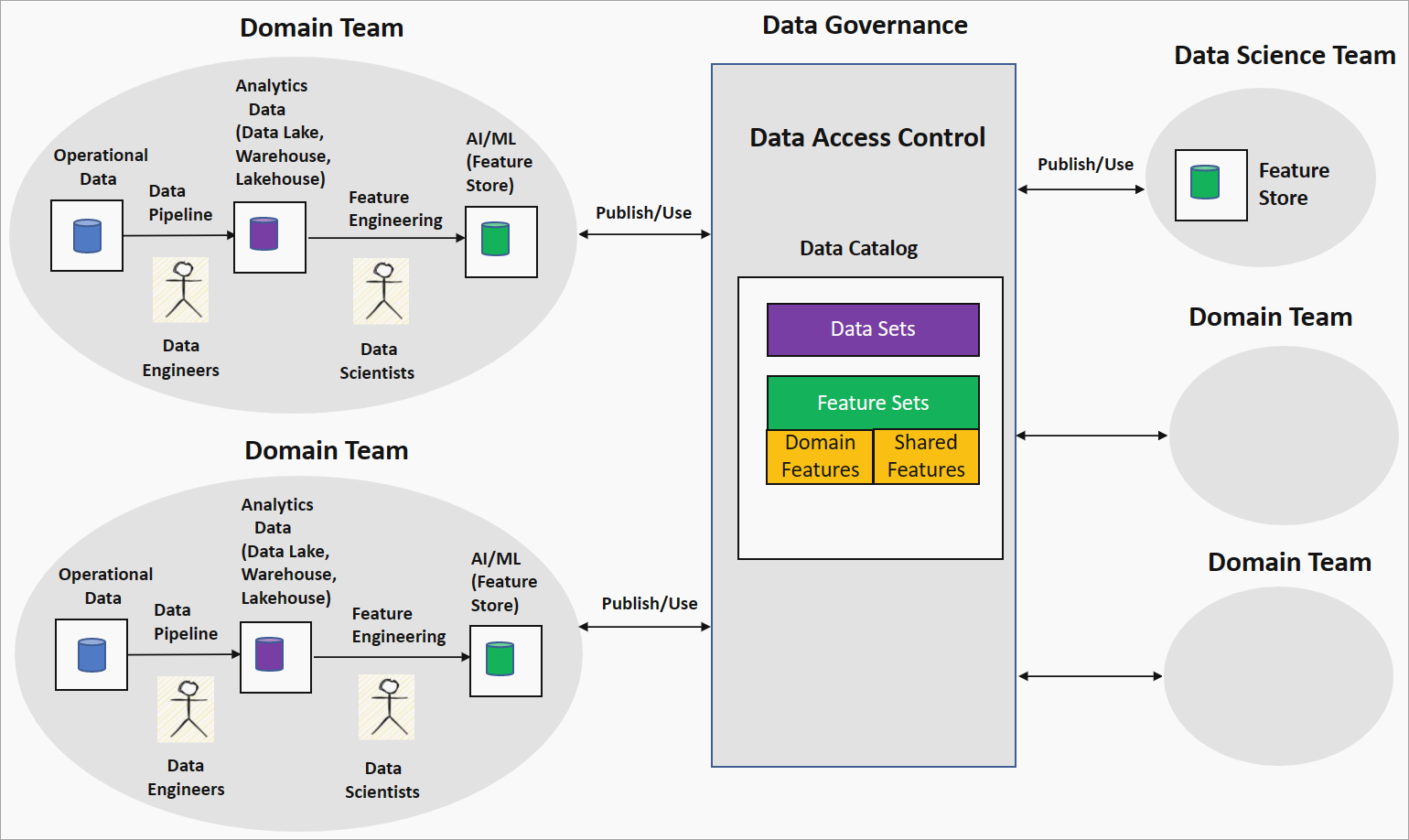
Domänenbesitz: Featurisierung nach Domänenteams
Bei dieser Strategie fasst die Organisation wissenschaftliche und technische Fachkräfte für Daten in einem Domänenteam zusammen, um bereinigte und transformierte Daten (beispielsweise in einem Data Lake) zu untersuchen. Die bei der Featurisierung generierten Features werden in einem Featurespeicher gespeichert. Ein Featurespeicher ist ein Datenrepository, das Features für Training und Rückschlüsse bereitstellt und beim Nachverfolgen von Featureversionen, Metadaten und Statistiken hilft. Diese Funktion ermöglicht es den Data Scientists im Domänenteam, eng mit Domänenexperten zusammenzuarbeiten und die Features bei Datenänderungen in der Domäne zu aktualisieren.
Daten als Produkt: Merkmalsätze
Vom Domänenteam generierte Features, die als Domänen- oder lokale Features bezeichnet werden, werden als Featuresätze im Datenkatalog in der Datengovernanceplattform veröffentlicht. Diese Featuresätze werden von Data Science-Teams oder anderen Domänenteams zum Erstellen von KI/ML-Modellen genutzt. Während der KI-/ML-Modellentwicklung können die Data-Science- oder Domänenteams domänenspezifische Merkmale kombinieren, um neue Merkmale zu erzeugen, die als geteilte oder globale Merkmale bezeichnet werden. Diese freigegebenen Features werden zur weiteren Nutzung wieder im Featuresatzkatalog veröffentlicht.
Self-Service-Datenplattform und rechenbezogene Partnergovernance: Standardisierung und Qualität von Features
Diese Strategie kann dazu führen, dass ein anderer Technologie-Stack für Feature Engineering-Pipelines und inkonsistente Featuredefinitionen zwischen Domänen-Teams verwendet wird. Die Prinzipien der Self-Service-Datenplattform stellen sicher, dass Domänenteams eine gemeinsame Infrastruktur und gemeinsame Tools verwenden, um die Featurisierungspipelines zu erstellen und die Zugriffssteuerung durchzusetzen. Das Prinzip der Federated Computational Governance gewährleistet die Interoperabilität von Featuresätzen durch globale Standardisierung und Überprüfung der Featurequalität.
Die Verwendung der domänengesteuerten Feature-Engineering- oder Feature-Mesh-Strategie bietet einen dezentralen KI/ML-Modellbauansatz für Organisationen, um die Zeit bei der Entwicklung von AI/ML-Modellen zu reduzieren. Diese Strategie trägt dazu bei, die Features in allen Domänenteams konsistent zu halten. Es vermeidet Duplikate und führt zu qualitativ hochwertigen Features für genauere KI/ML-Modelle, die den Wert für das Unternehmen erhöhen.
Datengitterimplementierung in Azure
In diesem Artikel werden die Konzepte zur Operationalisierung von KI/ML in einem Daten-Mesh beschrieben und nicht Tools oder Architekturen behandelt, um diese Strategien zu implementieren. Azure bietet Featurespeicher wie Azure Databricks und Feathr von LinkedIn. Sie können benutzerdefinierte Microsoft Purview-Connectors zum Verwalten und Steuern von Featurespeichern entwickeln.