Intelligente Anwendungen
Gilt für: ![]() Azure SQL-Datenbank
Azure SQL-Datenbank ![]() SQL-Datenbank in Fabric
SQL-Datenbank in Fabric
Dieser Artikel enthält eine Übersicht über die Verwendung von KI-Optionen (Künstliche Intelligenz), wie OpenAI und Vektoren, um intelligente Anwendungen mit Azure SQL-Datenbank und Fabric SQL-Datenbank, die viele dieser Features mit Azure SQL-Datenbank gemein hat, zu erstellen.
Samples und Beispiele finden Sie im SQL-AI-Beispiel-Repository.
Schauen Sie sich dieses Video in der Reihe Azure SQL-Datenbank-Essentials an, um einen kurzen Überblick über die Erstellung einer KI-fähigen Anwendung zu erhalten:
Übersicht
Mit LLMs (Large Language Models) können Entwickler KI-basierte Anwendungen mit einer vertrauten Benutzeroberfläche erstellen.
Die Verwendung von LLMs in Anwendungen bringt mehr Wert und eine verbesserte Benutzererfahrung, wenn die Modelle zum richtigen Zeitpunkt auf die richtigen Daten zugreifen können, und zwar von der Datenbank Ihrer Anwendung aus. Dieser Prozess wird als RAG (Retrieval Augmented Generation) bezeichnet, und Azure SQL-Datenbank und Fabric SQL-Datenbank verfügen über viele Features, die dieses neue Muster unterstützen, sodass sie sich hervorragend zum Erstellen intelligenter Anwendungen eignen.
Die folgenden Links enthalten Beispielcode verschiedener Optionen zum Erstellen intelligenter Anwendungen:
| KI-Option | Beschreibung |
|---|---|
| Azure OpenAI | Generieren Sie Einbettungen für RAG, und integrieren Sie sie in jedes von Azure OpenAI unterstützte Modell. |
| Vektoren | Erfahren Sie, wie Sie die Datenbank speichern und abfragen. |
| Azure KI Cognitive Search | Verwenden Sie Ihre Datenbank zusammen mit Azure KI Suche, um LLM für Ihre Daten zu trainieren. |
| Intelligente Anwendungen | Erfahren Sie, wie Sie eine End-to-End-Lösung mit einem gängigen Muster erstellen, das in jedem Szenario repliziert werden kann. |
| Copilot-Skills in Azure SQL-Datenbank | Erfahren Sie mehr über die Reihe von KI-unterstützten Erfahrungen, die entwickelt wurden, um das Design, den Betrieb, die Optimierung und den Zustand von Azure SQL-Datenbank gesteuerten Anwendungen zu optimieren. |
| Copilot-Fähigkeiten in Fabric SQL-Datenbank | Erfahren Sie mehr über die Reihe von KI-unterstützten Erfahrungen, die entwickelt wurden, um das Design, den Betrieb, die Optimierung und den Zustand von SQL-Datenbank-gesteuerten Fabric-Anwendungen zu optimieren. |
Kernkonzepte für die Implementierung von RAG mit Azure OpenAI
Dieser Abschnitt enthält wichtige Konzepte, die für die Implementierung von RAG mit Azure OpenAI in Azure SQL-Datenbank oder Fabric SQL-Datenbank von entscheidender Bedeutung sind.
Retrieval Augmented Generation (RAG)
RAG ist eine Technik, die die Fähigkeit des LLM verbessert, relevante und informative Antworten zu erzeugen, indem zusätzliche Daten aus externen Quellen abgerufen werden. Beispielsweise kann RAG Artikel oder Dokumente abfragen, die domänenspezifisches Wissen im Zusammenhang mit der Frage oder Aufforderung des Benutzers enthalten. Das LLM kann diese abgerufenen Daten dann als Verweis verwenden, wenn die Antwort generiert wird. Ein einfaches RAG-Muster mit Azure SQL Database könnte beispielsweise wie folgt aussehen:
- Fügen Sie Daten in eine Tabelle ein.
- Verknüpfen Sie Azure SQL Database mit Azure AI Search.
- Erstellen Sie ein Azure OpenAI GPT4-Modell und verbinden Sie es mit Azure AI Search.
- Chatten Sie, und stellen Sie Fragen zu Ihren Daten mithilfe des trainierten Azure OpenAI-Modells aus Ihrer Anwendung und von Azure SQL-Datenbank aus.
Das RAG-Muster mit Prompt Engineering dient dem Zweck, die Antwortqualität zu verbessern, indem es dem Modell mehr kontextbezogene Informationen bietet. RAG ermöglicht es dem Modell, eine umfassendere Wissensbasis anzuwenden, indem relevante externe Quellen in den Generierungsprozess integriert werden, was zu umfassenderen und fundierteren Antworten führt. Weitere Informationen zum Erden von LLMs finden Sie im Microsoft Community Hub unter Grounding LLMs.
Äußerungen und Prompt Engineering
Eine Äußerung (Prompt) ist ein bestimmter Text oder eine bestimmte Information, der/die als Anweisung für ein LLM dienen oder Kontextdaten liefern kann, auf denen das LLM aufbauen kann. Eine Äußerung kann verschiedene Formen annehmen, z. B. eine Frage, eine Anweisung oder sogar einen Codeschnipsel.
Eingabeaufforderungen, mit denen eine Antwort von einer LLM generiert werden kann:
- Anweisungen: instruieren das LLM
- Primäre Inhalte: liefert dem LLM Informationen, die verarbeitet werden sollen
- Beispiele: hilft bei der Konditionierung des Modells für eine bestimmte Aufgabe oder einen bestimmten Prozess
- Hinweise lenken die Ausgabe des LLM in die richtige Richtung
- Unterstützende Inhalte: stellen dem LLM ergänzende Informationen zur Verfügung, die dieses zum Generieren der Ausgabe verwenden kann
Der Prozess, mit dem gute Äußerungen für ein Szenario erstellt werden, wird als Prompt Engineering bezeichnet. Weitere Informationen zu Äußerungen und Best Practices für das Prompt Engineering finden Sie unter Azure OpenAI Service.
Token
Token sind kleine Textblöcke, die durch Aufteilen des Eingabetexts in kleinere Segmente generiert werden. Diese Segmente können entweder Wörter oder Gruppen von Zeichen sein, wobei die Länge von einem einzelnen Zeichen bis zu einem ganzen Wort variiert. Beispielsweise würde das Wort hamburger in die Token ham, bur und ger aufgeteilt, während ein kurzes, gängiges Wort wie pear als einzelnes Token betrachtet würde.
In Azure OpenAI wird der für die API bereitgestellte Eingabetext in Token umgewandelt (tokenisiert). Wie viele Token in einer einzelnen API-Anforderung verarbeitet werden, hängt von verschiedenen Faktoren ab, wie z. B. der Länge der Eingabe-, Ausgabe und Anforderungsparameter. Die Menge der verarbeiteten Token wirkt sich auch auf die Antwortzeit und den Durchsatz der Modelle aus. Die Menge an Token, die jedes Modell in einem einzelnen Anforderung/Antwort-Zyklus von Azure OpenAI verarbeiten kann, ist begrenzt. Weitere Informationen finden Sie unterKontingente und Grenzwerte von Azure OpenAI Service.
Vektoren
Vektoren sind geordnete Arrays von Zahlen (in der Regel Gleitkommazahlen), die Informationen zu einigen Daten darstellen können. Beispielsweise kann ein Bild als Vektor aus Pixelwerten dargestellt werden, oder eine Textzeichenfolge kann als Vektor oder in Form von ASCII-Werten dargestellt werden. Der Prozess des Umwandelns von Daten in eine Vektor wird als Vektorisierung bezeichnet. Weitere Informationen finden Sie unter Vektoren.
Einbettungen
Einbettungen sind Vektoren, die wichtige Merkmale von Daten darstellen. Einbettungen werden häufig mithilfe eines Deep Learning-Modells gelernt, und Machine Learning- und KI-Modelle nutzen sie als Features. Einbettungen können auch semantische Ähnlichkeiten zwischen ähnlichen Konzepten erfassen. Beispielsweise lässt sich beim Generieren von Einbettungen für die Wörter person und human erwarten, dass die Einbettungen (also die Vektordarstellungen) ähnliche Werte aufweisen, da die Wörter semantisch ähnlich sind.
Azure OpenAI bietet Modelle zum Erstellen von Einbettungen aus Textdaten. Der Dienst bricht Text in Token auf und generiert Einbettungen mithilfe von Modellen, die von OpenAI vorab trainiert wurden. Weitere Informationen finden Sie unter Erstellen von Einbettungen mit Azure OpenAI.
Vektorsuche
Die Vektorsuche ist der Prozess der Suche nach allen Vektoren in einem Dataset, die semantisch einem bestimmten Abfragevektor ähneln. Wenn also ein Abfragevektor für das Wort human vorhanden ist und das gesamte Wörterbuch nach semantisch ähnlichen Wörtern durchsucht wird, ist zu erwarten, dass das Wort person als gute Entsprechung gefunden wird. Diese Nähe bzw. dieser Abstand wird mit einer Ähnlichkeitsmetrik wie beispielsweise der Kosinusähnlichkeit gemessen. Je ähnlicher die Vektoren sind, desto kleiner ist der Abstand zwischen ihnen.
Stellen Sie sich ein Szenario vor, in dem Sie eine Abfrage für Millionen von Dokumenten ausführen und das ähnlichste Dokument in Ihren Daten finden möchten. Sie können mithilfe von Azure OpenAI Einbettungen für Ihre Daten und Abfragedokumente erstellen. Dann können Sie eine Vektorsuche durchführen, um die ähnlichsten Dokumente in Ihrem Dataset zu suchen. Die Durchführung einer Vektorsuche für einige wenige Beispiele ist noch recht einfach. Die Durchführung derselben Suche über Tausende oder Millionen von Datenpunkten hinweg ist dagegen eine echte Herausforderung. Zwischen verschiedenen Suchmethoden – der umfassenden Suche und der ANN-Suche (Approximate Nearest Neighbor) – müssen Kompromisse eingegangen werden, beispielsweise in Bezug auf Latenz, Durchsatz, Genauigkeit und Kosten. All diese Faktoren können von den Anforderungen Ihrer Anwendung abhängen.
Vektoren in der Azure SQL-Datenbank können effizient gespeichert und abgefragt werden, wie in den nächsten Abschnitten beschrieben, sodass eine genaue Pixelwiederholung mit hoher Leistung möglich ist. Sie müssen nicht zwischen Genauigkeit und Geschwindigkeit entscheiden: Sie können beides haben. Das Speichern von Vektoreinbettungen zusammen mit den Daten in einer integrierten Lösung minimiert die Notwendigkeit, für eine Synchronisierung der Daten zu sorgen, und beschleunigt die Time-to-Market bei der Entwicklung von KI-Apps.
Azure OpenAI
Das Einbetten ist der Prozess der Darstellung der realen Welt als Daten. Text, Bilder oder Sounds können in Einbettungen konvertiert werden. Azure OpenAI-Modelle können reale Informationen in Einbettungen transformieren. Die Modelle sind als REST-Endpunkte verfügbar und können somit mithilfe der gespeicherten Systemprozedur sp_invoke_external_rest_endpoint problemlos von Azure SQL-Datenbank genutzt werden:
DECLARE @retval INT, @response NVARCHAR(MAX);
DECLARE @payload NVARCHAR(MAX);
SET @payload = JSON_OBJECT('input': @text);
EXEC @retval = sp_invoke_external_rest_endpoint @url = 'https://<openai-url>/openai/deployments/<model-name>/embeddings?api-version=2023-03-15-preview',
@method = 'POST',
@credential = [https://<openai-url>/openai/deployments/<model-name>],
@payload = @payload,
@response = @response OUTPUT;
SELECT CAST([key] AS INT) AS [vector_value_id],
CAST([value] AS FLOAT) AS [vector_value]
FROM OPENJSON(JSON_QUERY(@response, '$.result.data[0].embedding'));
Die Verwendung eines Aufrufs eines REST-Diensts zum Abrufen von Einbettungen ist nur eine der Integrationsoptionen, die Sie beim Arbeiten mit SQL-Datenbank und OpenAI haben. Mit jedem der verfügbaren Modelle können Sie auf Daten zugreifen, die in Azure SQL-Datenbank gespeichert sind, um Lösungen zu erstellen, in denen Ihre Benutzer mit den Daten interagieren können, z. B. das folgende Beispiel.
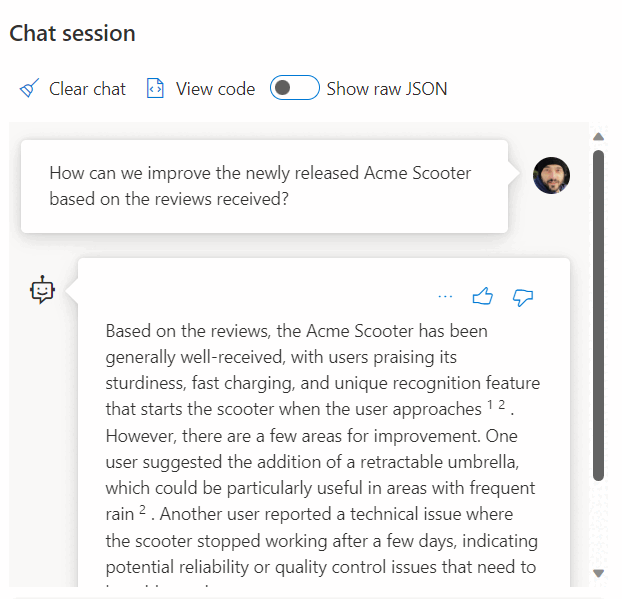
Weitere Beispiele zur Verwendung von SQL-Datenbank und OpenAI finden Sie in den folgenden Artikeln:
- Generieren von Bildern mit Azure OpenAI Service (DALL-E) und Azure SQL-Datenbank
- Verwenden von OpenAI REST-Endpunkten mit Azure SQL-Datenbank
Vektoren
Vektordatentyp
Im November 2024 wurde der neue Vektordatentyp in Azure SQL-Datenbank eingeführt.
Der dedizierte Vektortyp ermöglicht eine effiziente und optimierte Speicherung von Vektordaten und bietet eine Reihe von Funktionen, mit denen Entwickler die Implementierung der Vektor- und Ähnlichkeitssuche optimieren können. Die Berechnung des Abstands zwischen zwei Vektoren kann in einer Codezeile mithilfe der neuen VECTOR_DISTANCE Funktion erfolgen. Weitere Informationen zum Vektordatentyp und den zugehörigen Funktionen finden Sie in der Übersicht über Vektoren im SQL-Datenbankmodul.
Zum Beispiel:
CREATE TABLE [dbo].[wikipedia_articles_embeddings_titles_vector]
(
[article_id] [int] NOT NULL,
[embedding] [vector](1536) NOT NULL,
)
GO
SELECT TOP(10)
*
FROM
[dbo].[wikipedia_articles_embeddings_titles_vector]
ORDER BY
VECTOR_DISTANCE('cosine', @my_reference_vector, embedding)
Vektoren in älteren Versionen von SQL Server
Während ältere Versionen des SQL Server-Moduls bis einschließlich SQL Server 2022 keinen nativen Vektortyp aufweisen, ist ein Vektor nicht mehr als ein geordnetes Tupel, und relationale Datenbanken eignen sich hervorragend zum Verwalten von Tupeln. Sie können sich ein Tupel als formalen Begriff für eine Zeile in einer Tabelle vorstellen.
Azure SQL-Datenbank unterstützt auch Columnstore-Indizes und die Ausführung im Batchmodus. Ein vektorbasierter Ansatz wird für die Batchmodusverarbeitung verwendet. Dies bedeutet, dass jede Spalte in einem Batch über einen eigenen Speicherort verfügt, an dem sie als Vektor gespeichert ist. Dies ermöglicht eine schnellere und effizientere Verarbeitung von Daten in Batches.
Im folgenden Beispiel wird gezeigt, wie ein Vektor in SQL-Datenbank gespeichert werden kann:
CREATE TABLE [dbo].[wikipedia_articles_embeddings_titles_vector]
(
[article_id] [int] NOT NULL,
[vector_value_id] [int] NOT NULL,
[vector_value] [float] NOT NULL
)
GO
CREATE CLUSTERED COLUMNSTORE INDEX ixc
ON dbo.wikipedia_articles_embeddings_titles_vector
ORDER (article_id);
GO
Ein Beispiel, das eine gemeinsame Teilmenge von Wikipedia-Artikeln mit bereits mit OpenAI generierten Einbettungen verwendet, finden Sie unter Vector-Ähnlichkeitssuche mit Azure SQL-Datenbank und OpenAI.
Eine weitere Option für die Nutzung der Vektorsuche in der Azure SQL-Datenbank ist die Integration mit Azure AI mithilfe der integrierten Vektorisierungsfunktionen: Vektorsuche mit Azure SQL-Datenbank und Azure AI Search
Azure KI Cognitive Search
Implementierung von RAG-Mustern mit Azure SQL Database und Azure AI Search. Dank der Integration von Azure AI Search mit Azure OpenAI und Azure SQL Database können Sie unterstützte Chatmodelle auf Daten ausführen, die in Azure SQL Database gespeichert sind, ohne Modelle trainieren oder feinabstimmen zu müssen. Wenn Sie Modelle für Ihre Daten ausführen, können Sie darüber hinaus chatten und Ihre Daten mit höherer Genauigkeit und Geschwindigkeit analysieren.
- Azure OpenAI Service in Ihren Daten
- Retrieval Augmented Generation (RAG) in Azure KI Search
- Vektorsuche mit Azure SQL-Datenbank und Azure AI Search
Intelligente Anwendungen
Azure SQL-Datenbank kann verwendet werden, um intelligente Anwendungen zu erstellen, die KI-Features enthalten, wie z. B. Empfehlungen und RAG (Retrieval Augmented Generation):

Ein End-to-End-Beispiel zum Erstellen einer KI-fähigen Anwendung mithilfe von Sitzungen als Beispieldatensatz finden Sie unter:
- Wie ich eine Sitzungs-Empfehlung in einer Stunde mit OpenAI erstellt habe.
- Verwenden der erweiterten Abrufgenerierung zum Erstellen eines Konferenzsitzungs-Assistenten
LangChain-Integration
LangChain ist ein bekanntes Framework für die Entwicklung von Anwendungen, die von Sprachmodellen unterstützt werden. Beispiele, die zeigen, wie LangChain zum Erstellen eines Chatbots auf Ihren eigenen Daten verwendet werden kann, finden Sie unter:
- Erstellen Sie einen Chatbot für Ihre eigenen Daten in einer Stunde mit Azure SQL, Langchain und Chainlit: Erstellen Sie einen Chatbot mit dem RAG-Muster auf Ihren eigenen Daten mithilfe der Langchain zum Orchestrieren von LLM-Aufrufen und Chainlit für die Benutzeroberfläche.
- Erstellen Sie Ihren eigenen DB Copilot für Azure SQL mit Azure OpenAI GPT-4: Erstellen Sie eine copilot-ähnliche Erfahrung, um Ihre Datenbanken mit natürlicher Sprache abzufragen.
Integration des semantischen Kernels
Der semantische Kernel ist ein Open-Source-SDK, mit dem Sie auf einfache Weise Agents erstellen können, die Ihren vorhandenen Code aufrufen können. Als hoch erweiterbares SDK können Sie den semantischen Kernel mit Modellen aus OpenAI, Azure OpenAI, Hugging Face und mehr verwenden! Indem Sie Ihren vorhandenen C#-, Python- und Java-Code mit diesen Modellen kombinieren, können Sie Agents erstellen, die Fragen beantworten und Prozesse automatisieren.
- Der ultimative Chatbot?: Erstellen Sie einen Chatbot auf Ihren eigenen Daten mithilfe von NL2SQL- und RAG-Mustern für die ultimative Benutzererfahrung.
- OpenAI Embeddings Sample: Ein Beispiel, das zeigt, wie Semantischer Kernel und Kernelspeicher zum Arbeiten mit Einbettungen in eine .NET-Anwendung mit SQL Server als Vektordatenbank verwendet werden.
- Semantic Kernel & Kernel Memory – SQL Connector – Stellt eine Verbindung mit einer SQL-Datenbank für den semantischen Kernel für die Erinnerungen bereit.
Microsoft Copilot-Skills in Azure SQL-Datenbank
Microsoft Copilot-Skills in Azure SQL-Datenbank (Vorschau) besteht aus einer Reihe KI-gestützter Umgebungen, die darauf ausgelegt sind, die Gestaltung, den Betrieb, die Optimierung und die Integrität von auf Azure SQL-Datenbank basierenden Anwendungen zu beschleunigen. Copilot kann die Produktivität verbessern, indem er natürliche Sprache für SQL-Konvertierung und Selbsthilfe für die Datenbankverwaltung bietet.
Copilot liefert relevante Antworten auf Benutzerfragen und vereinfacht die Datenbankverwaltung durch Nutzung von Datenbankkontext, Dokumentation, dynamischen Verwaltungssichten, Abfragespeicher und anderen Wissensquellen. Zum Beispiel:
- Datenbankadministratoren können Datenbanken unabhängig verwalten und Probleme beheben oder mehr über die Leistung und Funktionen Ihrer Datenbank erfahren.
- Entwickler können Fragen zu ihren Daten stellen wie in Text oder Unterhaltung, um eine T-SQL-Abfrage zu generieren. Entwickler können auch erfahren, wie sie Abfragen schneller schreiben können, indem sie detaillierte Erläuterungen der generierten Abfrage ausführen.
Hinweis
Microsoft Copilot-Skills in Azure SQL-Datenbank stehen derzeit als Vorschau für eine begrenzte Anzahl von Early Adoptern zur Verfügung. Gehen Sie zum Registrieren für dieses Programm zu Anfordern des Zugriffs auf Copilot in Azure SQL-Datenbank: Vorschau.
Die Vorschau von Copilot für Azure SQL-Datenbank umfasst zwei Azure-Portal Erfahrungen:
| Speicherort im Portal | Erfahrungen |
|---|---|
| Azure-Portal-Abfrage-Editor | Natürliche Sprache zu SQL: Diese Umgebung im Abfrage-Editor des Azure-Portals für Azure SQL-Datenbank übersetzt Abfragen in natürlicher Sprache in SQL, was die Datenbankinteraktionen intuitiver werden lässt. Ein Lernprogramm und Beispiele für natürliche Sprache für SQL-Funktionen finden Sie unter „Natürliche Sprache zu SQL“ im Azure-Portal Abfrage-Editor (Vorschau). |
| Microsoft Copilot für Azure | Azure Copilot-Integration: Diese Erfahrung fügt Azure SQL-Fähigkeiten zu Microsoft Copilot für Azure hinzu, bietet Kunden selbstgeführte Unterstützung, was es ihnen ermöglicht, ihre Datenbanken zu verwalten und Probleme unabhängig zu lösen. |
Mehr Informationen finden Sie unter Häufig gestellte Fragen zu Microsoft Copilot-Skills in Azure SQL-Datenbank (Vorschau).
Microsoft Copilot-Fähigkeiten in Fabric SQL-Datenbank (Vorschau)
Copilot für SQL-Datenbank in Microsoft Fabric (Vorschau) umfasst integrierte KI-Unterstützung mit den folgenden Features:
Codeabschluss: Beginnen Sie mit dem Schreiben von T-SQL im SQL-Abfrage-Editor, und Copilot generiert automatisch einen Codevorschlag, um die Abfrage abzuschließen. Mit der Tabulatortaste kann der Vorschlag akzeptiert werden. Alternativ können Sie mit der Eingabe fortfahren, um den Vorschlag zu ignorieren.
Schnelle Aktionen: Im Menüband des SQL-Abfrage-Editors sind die Optionen Korrigieren und Erläutern schnelle Aktionen. Markieren Sie eine SQL-Abfrage Ihrer Wahl und wählen Sie eine der schnellen interaktiven Schaltflächen aus, um die ausgewählte Aktion für Ihre Abfrage auszuführen.
Beheben: Copilot kann Fehler in Ihrem Code beheben, wenn Fehlermeldungen auftreten. Zu den Fehlerszenarien können falscher/ununterstützter T-SQL-Code, falsche Rechtschreibungen und mehr gehören. Copilot wird auch Kommentare bereitstellen, die die Änderungen erläutern und bewährte SQL-Methoden vorschlagen.
Erläutern: Copilot kann Erklärungen Ihrer SQL-Abfrage und Ihres Datenbankschemas im Kommentarformat bereitstellen.
Chatbereich: Verwenden Sie den Chatbereich, um Fragen in natürlicher Sprache an Copilot zu stellen. Copilot antwortet mit einer generierten SQL-Abfrage oder natürlicher Sprache basierend auf der gestellten Frage.
Natürliche Sprache in SQL: Generieren Sie T-SQL-Code aus Nur-Text-Anforderungen, und erhalten Sie Vorschläge von Fragen, die Sie zur Beschleunigung Ihres Workflows stellen können.
Dokumentbasierte F&A: Stellen Sie Copilot Fragen zu allgemeinen SQL-Datenbankfunktionen, die in natürlicher Sprache beantwortet werden. Copilot hilft auch bei der Suche nach Dokumentationen im Zusammenhang mit Ihrer Anfrage.
Copilot für SQL-Datenbank verwendet Tabellen- und Ansichtsnamen, Spaltennamen, Primärschlüssel und Fremdschlüsselmetadaten, um T-SQL-Code zu generieren. Copilot für SQL-Datenbank verwendet keine Daten in Tabellen, um T-SQL-Vorschläge zu generieren.