Azure OpenAI für Ihre Daten
Verwenden Sie diesen Artikel, um mehr über Azure OpenAI für Ihre Daten zu erfahren, ein Tool, das es Entwicklern erleichtert, ihre Unternehmensdaten zu verbinden, zu erfassen und zu grundieren, um schnell personalisierte Copiloten (Vorschau) zu erstellen. Es verbessert das Verständnis der Benutzer, beschleunigt den Abschluss von Vorgängen, verbessert die betriebliche Effizienz und unterstützt die Entscheidungsfindung.
Was ist Azure OpenAI für Ihre Daten
Mit Azure OpenAI für Ihre Daten können Sie erweiterte KI-Modelle wie GPT-35-Turbo und GPT-4 für Ihre eigenen Unternehmensdaten ausführen, ohne Modelle trainieren oder optimieren zu müssen. Sie können über Ihre Daten chatten und sie mit größerer Genauigkeit analysieren. Sie können Quellen angeben, um die Antworten basierend auf den neuesten Informationen, die in Ihren angegebenen Datenquellen verfügbar sind, zu unterstützen. Sie können mithilfe der REST-API, über das SDK oder die webbasierte Schnittstelle im Azure AI Foundry-Portal auf Azure OpenAI für Ihre Daten zugreifen. Sie können auch eine Web-App erstellen, die eine Verbindung mit Ihren Daten herstellt, um eine erweiterte Chatlösung zu ermöglichen oder sie direkt als Copilot im Copilot Studio (Vorschau) bereitzustellen.
Entwickeln mit Azure OpenAI On Your Data
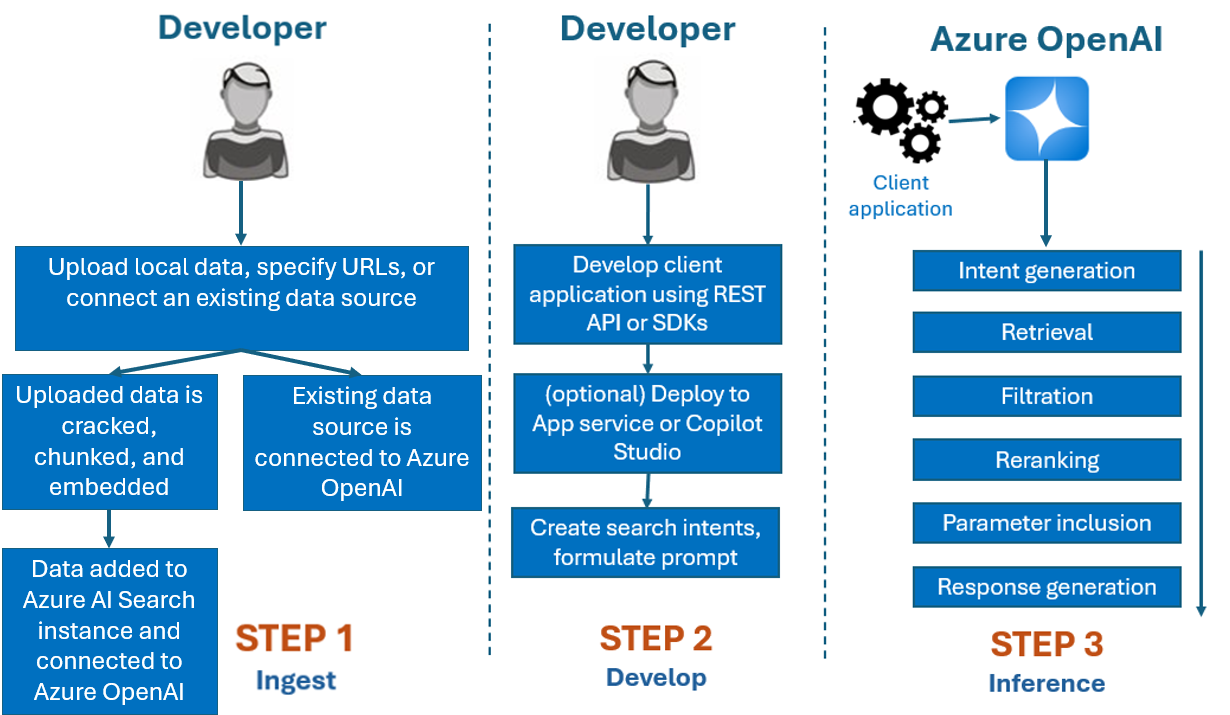
In der Regel läuft der Entwicklungsprozess mit Azure OpenAI On Your Data wie folgt ab:
Erfassung: Sie laden Dateien entweder mit dem Azure AI Foundry-Portal oder der Erfassungs-API hoch. Auf diese Weise können Ihre Daten aufgeteilt, segmentiert und in eine Instanz von Azure KI-Suche eingebettet werden, die von Azure OpenAI Modellen verwendet werden kann. Wenn Sie über eine vorhandene unterstützte Datenquelle verfügen, können Sie diese auch direkt verbinden.
Entwicklung: Beginnen Sie nach dem Testen von Azure OpenAI On Your Data mit der Entwicklung Ihrer Anwendung mithilfe der REST-API und SDKs, die in mehreren Programmiersprachen verfügbar sind. Es werden Prompts und Suchabsichten erstellt, die an Azure OpenAI Service übergeben werden sollen.
Rückschluss: Nachdem Ihre Anwendung in Ihrer bevorzugten Umgebung bereitgestellt wurde, sendet sie Prompts an Azure OpenAI, das mehrere Schritte ausführt, bevor eine Antwort zurückgegeben wird:
Absichtsgenerierung: Der Dienst bestimmt die Absicht des Benutzerprompts, um eine passende Antwort zu finden.
Abruf: Der Dienst ruft durch Abfragen relevante Datenblöcke aus der verbundenen Datenquelle ab. Dazu wird z. B. eine semantische oder Vektorsuche verwendet. Parameter wie Strenge und Anzahl der abzurufenden Dokumente dienen dazu, um den Abruf zu steuern.
Filterung und Rangfolgeänderung: Die Suchergebnisse aus dem Abrufschritt werden durch Festlegung einer Rangfolge und Filterung der Daten verbessert, um die Relevanz zu optimieren.
Antwortgenerierung: Die resultierenden Daten werden zusammen mit anderen Informationen wie der Systemnachricht an das LLM (Large Language Model) übermittelt, und die Antwort wird an die Anwendung zurückgesendet.
Zunächst verbinden Sie Ihre Datenquelle mithilfe des Azure AI Foundry-Portals und stellen dann Fragen und chatten über Ihre Daten.
Rollenbasierte Zugriffssteuerungen von Azure (Azure Role-Based Access Control, Azure RBAC) zum Hinzufügen von Datenquellen
Um Azure OpenAI für Ihre Daten vollständig zu verwenden, müssen Sie eine oder mehrere Azure RBAC-Rollen festlegen. Weitere Informationen finden Sie im Artikel zur Konfiguration von Azure OpenAI für Ihre Daten.
Datenformate und Dateitypen
Azure OpenAI für Ihre Daten unterstützt die folgenden Dateitypen:
.txt.md.html.docx.pptx.pdf
Es gibt ein Upload-Limit, und es gibt einige Vorbehalte bezüglich der Dokumentenstruktur und der möglichen Auswirkungen auf die Qualität der Antworten des Modells:
Wenn Sie Daten aus einem nicht unterstützten Format in ein unterstütztes Format konvertieren, optimieren Sie die Qualität der Modellantwort, indem Sie sicherstellen, dass die Konvertierung:
- Nicht zu erheblichen Datenverlusten führt.
- Kein unerwartetes Rauschen zu den Daten hinzufügt.
Wenn Ihre Dateien spezielle Formatierungen haben, z. B. Tabellen und Spalten oder Aufzählungszeichen, bereiten Sie Ihre Daten mit dem auf GitHub verfügbaren Datenvorbereitungsskript vor.
Für Dokumente und Datasets mit langem Text empfehlen wir die Verwendung des verfügbaren Datenaufbereitungsskripts. Das Skript teilt Daten in Blöcke auf, sodass die Antworten des Modells genauer sind. Dieses Skript unterstützt auch gescannte PDF-Dateien und -Bilder.
Unterstützte Datenquellen
Sie müssen eine Verbindung mit einer Datenquelle herstellen, um Ihre Daten hochzuladen. Wenn Sie Ihre Daten verwenden möchten, um mit einem Azure OpenAI-Modell zu chatten, werden Ihre Daten in einem Suchindex in Blöcke unterteilt, sodass relevante Daten basierend auf Benutzerabfragen gefunden werden können.
Hinweis
Ihre Daten sollten unstrukturierter Text sein, um optimale Ergebnisse zu erzielen. Wenn Sie über nicht textuelle, halbstrukturierte oder strukturierte Daten verfügen, sollten Sie sie in Text konvertieren. Wenn Ihre Dateien spezielle Formatierungen haben, z. B. Tabellen und Spalten oder Aufzählungszeichen, bereiten Sie Ihre Daten mit dem auf GitHub verfügbaren Datenvorbereitungsskript vor.
Die in eine vCore-basierte Azure Cosmos DB for MongoDB-Instanz integrierte Vektordatenbank unterstützt eine native Integration mit Azure OpenAI für Ihre Daten.
Für einige Datenquellen, z. B. das Hochladen von Dateien von Ihrem lokalen Computer (Vorschau) oder Daten, die in einem Bobspeicherkonto (Vorschau) enthalten sind, wird Azure KI-Suche verwendet. Wenn Sie die folgenden Datenquellen auswählen, werden Ihre Daten in einen Azure KI-Suche-Index erfasst.
| Daten, die über Azure KI-Suche erfasst wurden | Beschreibung |
|---|---|
| Azure KI Cognitive Search | Verwenden Sie einen vorhandenen Azure KI-Suche-Index mit Azure OpenAI für Ihre Daten. |
| Hochladen von Dateien (Vorschau) | Laden Sie Dateien von Ihrem lokalen Computer hoch, damit sie in einer Azure Blob Storage-Datenbank gespeichert und in Azure KI-Suche aufgenommen werden. |
| URL/Webadresse (Vorschau) | Webinhalte aus den URLs werden in Azure Blob Storage gespeichert. |
| Azure Blob Storage (Vorschau) | Laden Sie Dateien aus Azure Blob Storage hoch, um in einen Azure KI-Suche-Index erfasst zu werden. |

- Azure KI Cognitive Search
- Vektordatenbank in Azure Cosmos DB for MongoDB
- Azure Blob Storage (Vorschau)
- Hochladen von Dateien (Vorschau)
- URL/Webadresse (Vorschau)
- Elasticsearch (Vorschau)
- MongoDB Atlas (Vorschau)
Sie sollten die Verwendung eines Azure KI-Suche-Index in Betracht ziehen, wenn Sie eine der folgenden Aktionen ausführen möchten:
- Passen Sie den Indexerstellungsprozess an.
- Verwenden Sie einen Index wieder, der vor dem Erfassen von Daten aus anderen Datenquellen erstellt wurde.
Hinweis
- Um einen vorhandenen Index zu verwenden, muss er mindestens ein durchsuchbares Feld aufweisen.
- Legen Sie die CORS-Option Ursprungstyp zulassen auf
allund die Option Zulässige Ursprünge auf*fest. - In Ihrem Suchindex dürfen keine komplexen Felder enthalten sein.
Suchtypen
Azure OpenAI für Ihre Daten stellt die folgenden Suchtypen bereit, die Sie verwenden können, wenn Sie Ihre Datenquelle hinzufügen.
Vektorsuche mit Ada-Einbettungsmodellen, die in ausgewählten Regionen verfügbar sind
Zum Aktivieren der Vektorsuche benötigen Sie ein vorhandenes Einbettungsmodell, das in Ihrer Azure OpenAI-Ressource bereitgestellt ist. Wählen Sie beim Verbinden Ihrer Daten Ihre Einbettungsbereitstellung aus, und wählen Sie dann unter Datenverwaltung einen der Vektorsuchtypen aus. Wenn Sie Azure KI-Suche als Datenquelle verwenden, stellen Sie sicher, dass Sie über eine Vektorspalte im Index verfügen.
Wenn Sie Ihren eigenen Index verwenden, können Sie die Feldzuordnung anpassen, wenn Sie Ihre Datenquelle hinzufügen, um die Felder zu definieren, die beim Beantworten von Fragen zugeordnet werden. Wählen Sie zum Anpassen der Feldzuordnung die Option Benutzerdefinierte Feldzuordnung verwenden auf der Seite Datenquelle aus, wenn Sie Ihre Datenquelle hinzufügen.
Wichtig
- Die semantische Suche unterliegt zusätzlichen Gebühren. Sie müssen die SKU "Basic" oder eine höhere SKU auswählen, um die semantische Suche oder die Vektorsuche zu aktivieren. Weitere Informationen finden Sie unter Tarifdifferenz und Diensteinschränkungen.
- Um die Qualität des Informationsabrufs und der Modellantwort zu verbessern, empfehlen wir das Aktivieren der semantischen Suche für die folgenden Datenquellensprachen: Englisch, Französisch, Spanisch, Portugiesisch, Italienisch, Deutsch, Chinesisch (Zh), Japanisch, Koreanisch, Russisch und Arabisch.
| Suchoption | Abruftyp | Zusätzliche Gebühren? | Vorteile |
|---|---|---|---|
| Schlüsselwort (keyword) | Schlüsselwortsuche | Keine zusätzlichen Gebühren. | Führt eine schnelle und flexible Analyse und Abgleichung von Abfragen über durchsuchbare Felder durch, unter Verwendung von Begriffen oder Phrasen in jeder unterstützten Sprache, mit oder ohne Operatoren. |
| semantisch | Semantische Suche | Zusätzliche Gebühren für die Verwendung der semantischen Suche. | Verbessert die Genauigkeit und Relevanz von Suchergebnissen durch Verwendung einer Neubewertung (mit KI-Modellen), um die semantische Bedeutung von Abfragebegriffen und Dokumenten zu verstehen, die von der ursprünglichen Suchbewertung zurückgegeben werden |
| vector | Vektorsuche | Zusätzliche Gebühren für Ihr Azure OpenAI-Konto bei Aufrufen des Einbettungsmodells. | Ermöglicht das Suchen von Dokumenten, die einer bestimmten Abfrageeingabe ähneln, basierend auf den Vektoreinbettungen des Inhalts. |
| Hybrid (Vektor + Stichwort) | Eine Kombination aus Vektor- und Stichwortsuche | Zusätzliche Gebühren für Ihr Azure OpenAI-Konto bei Aufrufen des Einbettungsmodells. | Führt die Ähnlichkeitssuche mit Vektorfeldern mithilfe von Vektoreinbettungen durch, unterstützt aber auch flexible Abfrageanalyse und Volltextsuche über alphanumerische Felder mithilfe von Begriffsabfragen. |
| Hybrid (Vektor + Stichwort) + Semantik | Ein Hybrid der Vektorsuche, der semantischen Suche und der Schlüsselwortsuche. | Zusätzliche Gebühren für Ihr Azure OpenAI-Konto bei Aufrufen des Einbettungsmodells und zusätzliche Gebühren für die Verwendung der semantischen Suche. | Verwendet Vektoreinbettungen, Language Understanding und flexible Abfrageanalyse, um umfangreiche Sucherfahrungen und generative KI-Apps zu erstellen, die komplexe und unterschiedliche Szenarien zum Abrufen von Informationen verarbeiten können. |
Intelligente Suche
Azure OpenAI für Ihre Daten hat die intelligente Suche für Ihre Daten aktiviert. Die semantische Suche ist standardmäßig aktiviert, wenn Sie sowohl über die semantische Suche als auch über die Schlüsselwortsuche verfügen. Wenn Sie über Einbettungsmodelle verfügen, verwendet die intelligente Suche standardmäßig die hybride und semantische Suche.
Zugriffssteuerung auf Dokumentebene
Hinweis
Die Zugriffssteuerung auf Dokumentebene wird unterstützt, wenn Sie Azure KI-Suche als Ihre Datenquelle auswählen.
Mit Azure OpenAI für Ihre Daten können Sie die Dokumente, die in Antworten für verschiedene Benutzer verwendet werden können, mit Sicherheitsfiltern der Azure KI-Suche einschränken. Wenn Sie den Zugriff auf Dokumentebene aktivieren, sind die Suchergebnisse, die von Azure KI-Suche zurückgegeben und zum Generieren einer Antwort verwendet werden, basierend auf der Benutzergruppenmitgliedschaft in Microsoft Entra gekürzt. Sie können den Zugriff auf Dokumentebene nur für vorhandene Azure KI Search-Indizes aktivieren. Weitere Informationen finden Sie im Artikel zur Netzwerk- und Zugriffskonfiguration für „Azure OpenAI für Ihre Daten“.
Zuordnung der Indexfelder
Wenn Sie einen eigenen Index verwenden, werden Sie im Azure AI Foundry-Portal aufgefordert zu definieren, welche Felder Sie beim Hinzufügen Ihrer Datenquelle zur Beantwortung von Fragen zuordnen möchten. Sie können mehrere Felder für Inhaltsdaten angeben und sollten alle Felder einschließen, die Text für Ihren Anwendungsfall enthalten.

In diesem Beispiel stellen die Felder, die Inhaltsdaten und Titel zugeordnet sind, Informationen für das Modell bereit, um Fragen zu beantworten. Title wird auch zum Betiteln von Zitattext verwendet. Das Feld, das dem Dateinamen zugeordnet ist, generiert die Zitatnamen in der Antwort.
Die korrekte Zuordnung dieser Felder trägt dazu bei sicherzustellen, dass das Modell eine bessere Antwort- und Zitatqualität aufweist. Sie können dies zusätzlich in der API mithilfe des fieldsMapping-Parameters konfigurieren.
Suchfilter (API)
Wenn Sie zusätzliche wertbasierte Kriterien für die Abfrageausführung implementieren möchten, können Sie einen Suchfilter mit dem Parameter filter in der REST-API einrichten.
So werden Daten in die Azure KI-Suche erfasst
Seit September 2024 wurden die Erfassungs-APIs auf integrierte Vektorisierung umgestellt. Dieses Update ändert nicht die vorhandenen API-Verträge. Integrierte Vektorisierung, ein neues Angebot von Azure KI-Suche, nutzt vorgefertigte Fähigkeiten zum Unterteilen in Blöcke und Einbetten der Eingabedaten. Der Azure OpenAI On Your Data-Erfassungsdienst verwendet keine benutzerdefinierten Fähigkeiten mehr. Nach der Migration zur integrierten Vektorisierung hat der Aufnahmeprozess einige Änderungen durchlaufen, und daher werden nur die folgenden Ressourcen erstellt:
{job-id}-index-
{job-id}-indexer, wenn ein Stunden- oder Tageszeitplan angegeben ist, andernfalls wird der Indexer am Ende des Erfassungsvorgangs bereinigt. {job-id}-datasource
Der Blockcontainer ist nicht mehr verfügbar, da diese Funktionalität jetzt durch die Azure KI-Suche verwaltet wird.
Datenverbindung
Sie müssen auswählen, wie Sie die Verbindung aus Azure OpenAI, Azure KI-Suche und Azure Blob Storage authentifizieren möchten. Sie können eine systemseitig zugewiesene verwaltete Identität oder einen API-Schlüssel auswählen. Durch Auswählen von API-Schlüssel als Authentifizierungstyp wird das System automatisch den API-Schlüssel für Sie auffüllen, um eine Verbindung mit Ihren Ressourcen für Azure KI-Suche, Azure OpenAI und Azure Blob Storage herzustellen. Durch Auswählen von systemseitig zugewiesene verwaltete Identität wird die Authentifizierung auf der Rollenzuweisung basieren, die Sie haben. Systemseitig zugewiesene verwaltete Identität ist aus Sicherheitsgründen standardmäßig ausgewählt.

Nachdem Sie die Schaltfläche weiter ausgewählt haben, wird Ihr Setup automatisch validiert, um die ausgewählte Authentifizierungsmethode zu verwenden. Wenn ein Fehler auftritt, lesen Sie den Artikel „Rollenzuweisungen“, um Ihr Setup zu aktualisieren.
Nachdem Sie das Setup behoben haben, wählen Sie weiter erneut aus, um zu validieren und fortzufahren. API-Benutzer können das Konfigurieren der Authentifizierung auch mit zugewiesener verwalteter Identität und API-Schlüsseln durchführen.









Bereitstellen in einem Copiloten (Vorschau), einer Teams-App (Vorschau) oder einer Web-App
Nachdem Sie Azure OpenAI mit Ihren Daten verbunden haben, können Sie diese über die Schaltfläche Bereitstellen für im Azure AI Foundry-Portal bereitstellen.

Dadurch erhalten Sie mehrere Optionen für die Bereitstellung Ihrer Lösung.
Sie können in Copilot Studio (Vorschau) direkt aus dem Azure AI Foundry-Portal in einem Copiloten bereitstellen, sodass Sie Unterhaltungserfahrungen in verschiedene Kanäle einbinden können, beispielsweise: Microsoft Teams, Websites, Dynamics 365 und andere Azure Bot Service-Kanäle. Der im Azure OpenAI-Dienst und Copilot Studio (Vorschau) verwendete Mandant sollte identisch sein. Weitere Informationen finden Sie unter Verwenden einer Verbindung zu Azure OpenAI für Ihre Daten.
Hinweis
Die Bereitstellung für einen Copiloten in Copilot Studio (Vorschau) ist nur in US-Regionen verfügbar.
Konfigurieren von Zugriff und Netzwerk für Azure OpenAI für Ihre Daten
Sie können Azure OpenAI für Ihre Daten verwenden und Daten und Ressourcen mit der rollenbasierter Zugriffssteuerung von Microsoft Entra ID, virtuellen Netzwerken und privaten Endpunkten schützen. Sie können auch die Dokumente, die in Antworten für verschiedene Benutzer verwendet werden können, mit Sicherheitsfiltern der Azure KI-Suche einschränken. Weitere Informationen finden Sie unter Netzwerk- und Zugriffskonfiguration für „Azure OpenAI für Ihre Daten“.
Bewährte Methoden
In den folgenden Abschnitten erfahren Sie, wie Sie die Qualität der Antworten verbessern können, die vom Modell gegeben werden.
Erfassungsparameter
Wenn Ihre Daten in Azure KI Search erfasst werden, können Sie die folgenden zusätzlichen Einstellungen in der Studio- oder Erfassungs-API ändern.
Blockgröße (Vorschau)
Azure OpenAI in Ihren Daten verarbeitet Ihre Dokumente, indem es sie in Blöcke aufteilt, bevor sie erfasst werden. Die Blockgröße ist die maximale Größe in Bezug auf die Anzahl der Token eines beliebigen Blocks im Suchindex. Die Blockgröße und die Anzahl der abgerufenen Dokumente steuern, wie viele Informationen (Token) in der Aufforderung enthalten sind, die an das Modell gesendet wird. Im Allgemeinen ist die Blockgröße multipliziert mit der Anzahl der abgerufenen Dokumente die Gesamtanzahl der Token, die an das Modell gesendet werden.
Festlegen der Blockgröße für Ihren Anwendungsfall
Die Standardblockgröße beträgt 1,024 Token. Angesichts der Eindeutigkeit Ihrer Daten ist jedoch möglicherweise eine andere Blockgröße (z. B. 256, 512 oder 1.536 Token) effektiver.
Durch das Anpassen der Blockgröße kann die Leistung Ihres Chatbots verbessert werden. Da das Herausfinden der optimalen Blockgröße etwas Ausprobieren erfordert, sollten Sie zunächst über die Art Ihres Datasets nachdenken. Eine kleinere Blockgröße ist in der Regel für Datasets mit direkten Fakten und weniger Kontext besser geeignet, während eine größere Blockgröße für mehr kontextbezogene Informationen vorteilhaft sein kann, obwohl sich dies auf die Abrufleistung auswirken kann.
Eine kleine Blockgröße wie 256 erzeugt präzisere Blöcke. Diese Größe bedeutet auch, dass das Modell weniger Token verwendet, um seine Ausgabe zu generieren (es sei denn, die Anzahl der abgerufenen Dokumente ist sehr hoch). Dies kostet dann unter Umständen weniger. Kleinere Blöcke bedeuten auch, dass das Modell lange Textabschnitte nicht verarbeiten und interpretieren muss, wodurch Rauschen und Ablenkungen reduziert werden. Diese Granularität und der Fokus stellen jedoch ein potenzielles Problem dar. Wichtige Informationen gehören möglicherweise nicht zu den obersten abgerufenen Blöcken, insbesondere, wenn die Anzahl der abgerufenen Dokumente auf einen niedrigen Wert wie 3 festgelegt ist.
Tipp
Beachten Sie, dass das Ändern der Blockgröße erfordert, dass Ihre Dokumente erneut aufgenommen werden. Daher empfiehlt es sich, zuerst Laufzeitparameter wie Strenge und die Anzahl der abgerufenen Dokumente anzupassen. Erwägen Sie, die Blockgröße zu ändern, wenn Sie immer noch nicht die gewünschten Ergebnisse erhalten:
- Wenn bei Fragen mit Antworten, die in Ihren Dokumenten enthalten sein sollten, eine hohe Anzahl von Antworten wie "Ich weiß nicht" auftreten, sollten Sie die Blockgröße auf 256 oder 512 reduzieren, um die Granularität zu verbessern.
- Wenn der Chatbot einige korrekte Details bereitstellt, aber andere fehlen, die in den Zitaten sichtbar werden, kann das Erhöhen der Blockgröße auf 1.536 dazu beitragen, weitere kontextbezogene Informationen zu erfassen.
Laufzeitparameter
Sie können die folgenden zusätzlichen Einstellungen im Abschnitt Datenparameter im Azure AI Foundry-Portal und in der API ändern. Sie müssen Ihre Daten nicht erneut erfassen, wenn Sie diese Parameter aktualisieren.
| Parametername | Beschreibung |
|---|---|
| Einschränken von Antworten auf Ihre Daten | Mit diesem Flag wird der Ansatz des Chatbots zur Behandlung von Abfragen konfiguriert, die nicht mit der Datenquelle zusammenhängen sowie für den Fall, dass Suchdokumente für eine vollständige Antwort nicht ausreichen. Wenn diese Einstellung deaktiviert ist, ergänzt das Modell seine Antworten zusätzlich zu Ihren Dokumenten mit eigenem Wissen. Wenn diese Einstellung aktiviert ist, versucht das Modell, sich beim Antworten ausschließlich auf Ihre Dokumente zu verlassen. Dies ist der Parameter inScope in der API und er ist standardmäßig auf „true“ festgelegt. |
| Abgerufene Dokumente | Dieser Parameter ist eine ganze Zahl, die auf 3, 5, 10 oder 20 festgelegt werden kann. Sie steuert die Anzahl der Dokumentblöcke, die für das große Sprachmodell (Large Language Model, LLM) zum Formulieren der endgültigen Antwort bereitgestellt werden. Standardmäßig ist dieser Wert auf 5 festgelegt. Der Suchvorgang kann verrauscht sein, und relevante Informationen könnten manchmal aufgrund der Blockbildung auf mehrere Blöcke im Suchindex verteilt sein. Wenn Sie eine Top-K-Zahl auswählen, z. B. 5, wird sichergestellt, dass das Modell relevante Informationen trotz der inhärenten Einschränkungen der Suche und der Segmentierung extrahieren kann. Wird eine zu hohe Zahl gewählt, kann dies das Modell jedoch möglicherweise stören. Darüber hinaus hängt die maximale Anzahl effektiv verwendbarer Dokumenten von der Version des Modells ab, da jedes über eine andere Kontextgröße und Kapazität zum Verarbeiten von Dokumenten verfügt. Wenn Sie feststellen, dass in Antworten wichtiger Kontext fehlt, versuchen Sie, den Wert dieses Parameters zu erhöhen. Dies ist der Parameter topNDocuments in der API und er ist standardmäßig auf „5“ festgelegt. |
| Strenge | Bestimmt die Aggressivität des Systems beim Filtern von Suchdokumenten basierend auf ihren Ähnlichkeitswerten. Das System fragt Azure Search oder andere Dokumentspeicher ab und entscheidet dann, welche Dokumente für große Sprachmodelle wie ChatGPT bereitgestellt werden sollen. Das Herausfiltern irrelevanter Dokumente kann die Leistung des End-to-End-Chatbots erheblich verbessern. Manche Dokumente werden von den Top-K-Ergebnissen vor der Weiterleitung an das Modell ausgeschlossen, wenn sie niedrige Ähnlichkeitswerte aufweisen. Dies wird durch einen ganzzahligen Wert zwischen 1 und 5 gesteuert. Das Festlegen dieses Werts auf 1 bedeutet, dass das System Dokumente basierend auf der Suchähnlichkeit der Benutzerabfrage nur minimal filtert. Umgekehrt weist eine Einstellung von 5 darauf hin, dass das System Dokumente aggressiv herausfiltert und dabei einen sehr hohen Schwellenwert für die Ähnlichkeit anwendet. Wenn Sie feststellen, dass der Chatbot relevante Informationen weglässt, verringern Sie die Strenge des Filters (wählen Sie einen Wert, der näher bei 1 liegt), um mehr Dokumente einzuschließen. Wenn hingegen irrelevante Dokumente die Antworten stören, erhöhen Sie den Schwellenwert (wählen Sie einen Wert, der näher bei 5 liegt). Dies ist der Parameter strictness in der API und er ist standardmäßig auf „3“ festgelegt. |
Nicht zitierte Referenzen
Es ist möglich, dass das Modell "TYPE":"UNCITED_REFERENCE" anstelle von "TYPE":CONTENT in der API für Dokumente zurückgibt, die aus der Datenquelle abgerufen werden, aber nicht im Zitat enthalten sind. Dies kann beim Debuggen nützlich sein, und Sie können dieses Verhalten steuern, indem Sie die oben beschriebene Strenge und abgerufenen Laufzeitparameter für Dokumente ändern.
Systemnachricht
Sie können eine Systemnachricht definieren, um die Antwort des Modells zu steuern, wenn Sie Azure OpenAI für Ihre Daten verwenden. Mit dieser Nachricht können Sie Ihre Antworten zusätzlich zum Retrieval Augmented Generation (RAG)-Muster anpassen, das Azure OpenAI für Ihre Daten verwendet. Die Systemmeldung wird zusätzlich zu einem internen Basisprompt verwendet, um die Erfahrung bereitzustellen. Um dies zu unterstützen, schneiden wir die Systemnachricht nach einer bestimmten Anzahl von Token ab, um sicherzustellen, dass das Modell Fragen mit Ihren Daten beantworten kann. Wenn Sie zusätzlich zum Standarderlebnis zusätzliches Verhalten definieren, stellen Sie sicher, dass Ihr Systemprompt detailliert ist und die genaue erwartete Anpassung erläutert.
Nachdem Sie „Ihr Dataset hinzufügen“ ausgewählt haben, können Sie den Abschnitt Systemmeldung im Azure AI Foundry-Portal oder den Parameter role_information in der API verwenden.

Potenzielle Verbrauchsmuster
Definieren einer Rolle
Sie können eine Rolle definieren, die Ihr Assistent sein soll. Wenn Sie z. B. einen Support-Bot erstellen, können Sie „Sie sind ein Assistent für Expertensupport für Vorfälle, der Benutzern hilft, neue Probleme zu lösen.“ hinzufügen.
Definieren des Typs der abzurufenden Daten
Sie können auch die Art der Daten hinzufügen, die Sie dem Assistenten zur Verfügung stellen.
- Definieren Sie das Thema oder den Bereich Ihres Datasets, z. B. „Finanzbericht“, „Akademisches Dokument“ oder „Vorfallbericht“. Beispielsweise können Sie für technischen Support „Sie beantworten Abfragen mithilfe von Informationen aus ähnlichen Vorfällen in den abgerufenen Dokumenten.“ hinzufügen.
- Wenn Ihre Daten bestimmte Merkmale aufweisen, können Sie diese Details zur Systemnachricht hinzufügen. Wenn Ihre Dokumente beispielsweise in Japanisch sind, können Sie „Sie rufen japanische Dokumente ab und sollten diese sorgfältig in Japanisch lesen und in Japanisch antworten.“ hinzufügen.
- Wenn Ihre Dokumente strukturierte Daten wie Tabellen aus einem Finanzbericht enthalten, können Sie diesen Fakt auch zum Systemprompt hinzufügen. Wenn Ihre Daten z. B. Tabellen enthalten, könnten Sie „Sie erhalten Daten in Form von Tabellen, die sich auf Finanzergebnisse beziehen, und Sie sollten die Tabelle Zeile für Zeile lesen, um Berechnungen durchzuführen, um Benutzerfragen zu beantworten.“ hinzufügen.
Definieren des Ausgabenstils
Sie können die Ausgabe des Modells auch ändern, indem Sie eine Systemnachricht definieren. Wenn Sie beispielsweise sicherstellen möchten, dass der Assistenten auf Französisch antwortet, können Sie einen Prompt wie „Sie sind ein KI-Assistent, der Benutzern, die Französisch verstehen, hilft, Informationen zu finden. Die Benutzerfragen können in Englisch oder Französisch sein. Bitte lesen Sie die abgerufenen Dokumente sorgfältig und beantworten Sie diese auf Französisch. Bitte übersetzen Sie das Wissen aus Dokumenten in Französisch, um sicherzustellen, dass alle Antworten auf Französisch sind.“.
Bekräftigen des kritischen Verhaltens
Azure OpenAI für Ihre Daten funktioniert, indem es Anweisungen an ein großes Sprachmodell in Form von Prompts sendet, um Benutzerabfragen mithilfe Ihrer Daten zu beantworten. Wenn für die Anwendung ein bestimmtes Verhalten kritisch ist, können Sie das Verhalten in der Systemnachricht wiederholen, um ihre Genauigkeit zu erhöhen. Um das Modell beispielsweise so zu leiten, dass nur aus Dokumenten geantwortet wird, können Sie „Bitte antworten Sie nur mithilfe von abgerufenen Dokumenten und ohne Ihr Wissen zu verwenden. Bitte generieren Sie Zitate zu den abgerufenen Dokumente für jede Behauptung in Ihrer Antwort. Wenn die Frage des Benutzers nicht mithilfe von abgerufenen Dokumenten beantwortet werden kann, erläutern Sie bitte den Grund, warum Dokumente für Benutzerabfragen relevant sind. Antworten Sie in jedem Fall nicht mit Ihrem eigenen Wissen.“.
Prompt Engineering-Tricks
Es gibt viele Tricks im Prompt Engineering, die Sie ausprobieren können, um die Ausgabe zu verbessern. Ein Beispiel hierfür ist die Prompt-Gedankenkette, in der Sie Folgendes hinzufügen können: „Lassen Sie uns Schritt für Schritt über Informationen in abgerufenen Dokumenten nachdenken, um Benutzerabfragen zu beantworten. Extrahieren Sie relevantes Wissen für Benutzerabfragen Schritt für Schritt aus Dokumenten, und bilden Sie eine Antwort von unten nach oben aus den extrahierten Informationen aus relevanten Dokumenten.“.
Hinweis
Mit der Systemmeldung wird die Art und Weise geändert, in der der GPT-Assistent basierend auf der abgerufenen Dokumentation auf eine Benutzerfrage antwortet. Sie wirkt sich nicht auf den Abrufvorgang aus. Wenn Sie Anweisungen für den Abrufprozess bereitstellen möchten, ist es besser, diese in die Fragen aufzunehmen. Die Systemmeldung ist nur ein Leitfaden. Das Modell entspricht möglicherweise nicht jeder angegebenen Anweisung, da es mit bestimmten Verhaltensweisen wie Objektivität vorbereitet wurde und umstrittene Aussagen vermeidet. Unerwartetes Verhalten kann auftreten, wenn die Systemmeldung diesen Verhaltensweisen widerspricht.
Einschränken von Antworten auf Ihre Daten
Diese Option regt das Modell dazu an, nur mit Ihren Daten zu reagieren, und ist standardmäßig aktiviert. Wenn Sie diese Option deaktivieren, kann das Modell sein internes Wissen beim Antworten leichter anwenden. Bestimmen Sie die richtige Auswahl basierend auf Ihrem Anwendungsfall und Szenario.
Interagieren mit dem Modell
Verwenden Sie die folgenden Methoden, um optimale Ergebnisse zu erzielen, wenn Sie mit dem Modell chatten.
Aufgezeichnete Unterhaltungen
- Löschen Sie den Chatverlauf, bevor Sie mit einer neuen Unterhaltung beginnen (oder eine Frage stellen, die sich nicht auf die vorherigen bezieht).
- Es ist zu erwarten, dass unterschiedliche Antworten auf dieselbe Frage zwischen der ersten Konversationskurve und den nachfolgenden Umläufen angezeigt werden, da der Unterhaltungsverlauf den aktuellen Zustand des Modells ändert. Wenn Sie falsche Antworten erhalten, melden Sie dies als Qualitätsfehler.
Modellantwort
Wenn Sie mit der Modellantwort für eine bestimmte Frage nicht zufrieden sind, versuchen Sie, die Frage spezifischer oder generischer zu stellen, um zu sehen, wie das Modell antwortet, und gestalten Sie Ihre Frage entsprechend um.
Es hat sich gezeigt, dass die Eingabeaufforderung als Denkkette effektiv ist, um das Modell dazu zu bringen, die gewünschten Ausgaben für komplexe Fragen/Aufgaben zu erzeugen.
Fragelänge
Vermeiden Sie es, lange Fragen zu stellen, und teilen Sie diese nach Möglichkeit in mehrere Fragen auf. Die GPT-Modelle haben Grenzwerte für die Anzahl von Token, die sie akzeptieren können. Tokenlimits werden für die Benutzerfrage, die Systemnachricht, die abgerufenen Suchdokumente (Blöcke), die internen Eingabeaufforderungen, den Konversationsverlauf (falls vorhanden) und die Antwort angerechnet. Wenn die Frage den Tokengrenzwert überschreitet, wird sie abgeschnitten.
Mehrsprachige Unterstützung
Derzeit unterstützen Schlüsselwortsuche und semantische Suche in Azure OpenAI für Ihre Daten Abfragen in derselben Sprache wie die Daten im Index. Wenn Ihre Daten beispielsweise auf Japanisch sind, müssen die Eingabeabfragen auch in Japanisch sein. Für den mehrsprachigen Dokumentabruf wird empfohlen, den Index mit aktivierter Vektorsuche zu erstellen.
Um die Qualität des Informationsabrufs und der Modellantwort zu verbessern, wird empfohlen, die semantische Suche für die folgenden Sprachen zu aktivieren: Englisch, Französisch, Spanisch, Portugiesisch, Italienisch, Deutschland, Chinesisch (Zh), Japanisch, Koreanisch, Russisch, Arabisch
Es wird empfohlen, eine Systemmeldung zu verwenden, um das Modell darüber zu informieren, dass Ihre Daten in einer anderen Sprache vorliegen. Beispiel:
*"*Sie sind ein KI-Assistent, der Benutzern helfen soll, Informationen aus abgerufenen japanischen Dokumenten zu extrahieren. Bitte sehen Sie sich die japanischen Dokumente genau an, bevor Sie eine Antwort formulieren. Die Anfrage des Benutzers wird auf Japanisch gestellt, und Sie müssen auch auf Japanisch antworten."
Wenn Sie über Dokumente in mehreren Sprachen verfügen, empfiehlt es sich, einen neuen Index für jede Sprache zu erstellen und sie separat mit Azure OpenAI zu verbinden.
Streamingdaten
Sie können eine Streaminganforderung mithilfe des stream-Parameters senden, sodass Daten inkrementell gesendet und empfangen werden können, ohne auf die gesamte API-Antwort zu warten. Dies kann die Leistung und Benutzererfahrung verbessern, insbesondere bei großen oder dynamischen Daten.
{
"stream": true,
"dataSources": [
{
"type": "AzureCognitiveSearch",
"parameters": {
"endpoint": "'$AZURE_AI_SEARCH_ENDPOINT'",
"key": "'$AZURE_AI_SEARCH_API_KEY'",
"indexName": "'$AZURE_AI_SEARCH_INDEX'"
}
}
],
"messages": [
{
"role": "user",
"content": "What are the differences between Azure Machine Learning and Azure AI services?"
}
]
}
Unterhaltungsverlauf für bessere Ergebnisse
Wenn Sie mit einem Modell chatten, hilft die Bereitstellung eines Verlaufs des Chats dem Modell, Ergebnisse von höherer Qualität zu erzielen. Sie müssen die context Eigenschaft der Assistentennachrichten nicht in Ihre API-Anforderungen einschließen, um eine bessere Antwortqualität zu erzielen. Beispiele finden Sie in der API-Referenzdokumentation.
Funktionsaufruf
Bei einigen Azure OpenAI-Modellen können Sie Tools und tool_choice Parameter definieren, um Funktionsaufrufe zu ermöglichen. Sie können Funktionsaufrufe über die REST-API/chat/completionseinrichten. Wenn sich tools und Datenquellen in der Anforderung befinden, wird die folgende Richtlinie angewendet.
- Wenn
tool_choicenoneist, werden die Tools ignoriert, und nur die Datenquellen werden verwendet, um die Antwort zu generieren. - Andernfalls werden die Datenquellen ignoriert, wenn
tool_choicenicht angegeben ist oder alsautoObjekt angegeben wird, und die Antwort enthält ggf. den Namen der ausgewählten Funktionen und die Argumente. Selbst wenn das Modell entscheidet, dass keine Funktion ausgewählt wird, werden die Datenquellen weiterhin ignoriert.
Wenn die oben genannte Richtlinie Ihre Anforderungen nicht erfüllt, ziehen Sie weitere Optionen in Betracht, z. B.: Prompt flow oder Assistenten-API.
Schätzung des Tokenverbrauchs für Azure OpenAI für Ihre Daten
Der Dienst „Azure OpenAI On Your Data Retrieval Augmented Generation“ (RAG) nutzt sowohl einen Suchdienst (z. B. Azure KI-Suche) als auch die Generierung (Azure OpenAI-Modelle), um Benutzern Antworten auf ihre Fragen basierend auf bereitgestellten Daten zu liefern.
Im Rahmen dieser RAG-Pipeline gibt es drei allgemeine Schritte:
Umwandeln der Benutzerabfrage in eine Liste der Suchabsichten: Dazu rufen Sie das Modell mit einem Prompt auf, der Anweisungen, die Frage des Benutzers und den Unterhaltungsverlauf enthält. Nennen wir das Absichtsprompt.
Für jede Absicht werden mehrere Dokumentblöcke aus dem Suchdienst abgerufen. Nach dem Herausfiltern irrelevanter Blöcke basierend auf dem vom Benutzer angegebenen Schwellenwert für Genauigkeit und dem Neusortieren bzw. Aggregieren der Blöcke basierend auf der internen Logik wird die vom Benutzer angegebene Anzahl an Dokumentblöcken ausgewählt.
Diese Dokumentblöcke werden zusammen mit der Benutzerfrage, dem Unterhaltungsverlauf, den Rolleninformationen und den Anweisungen an das Modell gesendet, um die finale Modellantwort zu generieren. Nennen wir das Generierungsprompt.
Insgesamt erfolgen zwei Aufrufe an das Modell:
Zur Verarbeitung der Absicht: Die Tokenschätzung für den Absichtsprompt umfasst diejenigen für die Benutzerfrage, den Unterhaltungsverlauf und die Anweisungen, die an das Modell für die Absichtsgenerierung gesendet wurden.
Zum Generieren der Antwort: Die Tokenschätzung für den Generierungsprompt umfasst diejenigen für die Benutzerfrage, den Unterhaltungsverlauf, die abgerufene Liste der Dokumentblöcke, die Rolleninformationen und die Anweisungen, die zur Generierung gesendet werden.
Die modellgenerierten Ausgabetoken (sowohl für Absichten als auch Antwort) müssen für die Gesamttokenschätzung berücksichtigt werden. Durch das Addieren aller vier nachfolgenden Spalten erhalten Sie die durchschnittlichen Gesamttoken, die zum Generieren einer Antwort verwendet werden.
| Modell | Tokenanzahl für Generierungsprompt | Tokenanzahl für Absichtsprompt | Tokenanzahl für Antwort | Tokenanzahl für Absicht |
|---|---|---|---|---|
| gpt-35-turbo-16k | 4297 | 1366 | 111 | 25 |
| gpt-4-0613 | 3997 | 1385 | 118 | 18 |
| gpt-4-1106-preview | 4538 | 811 | 119 | 27 |
| gpt-35-turbo-1106 | 4854 | 1372 | 110 | 26 |
Die obigen Zahlen basieren auf Tests mit einem Datasets mit:
- 191 Unterhaltungen
- 250 Fragen
- 10 durchschnittliche Token pro Frage
- 4 Nachrichtenwechseln pro Unterhaltung im Durchschnitt
Und die folgenden Parameter:
| Einstellung | Wert |
|---|---|
| Anzahl der abgerufenen Dokumente | 5 |
| Strenge | 3 |
| Blockgröße | 1024 |
| Antworten auf erfasste Daten beschränken? | True |
Diese Schätzungen variieren je nach den für die obigen Parameter festgelegten Werten. Wenn beispielsweise die Anzahl der abgerufenen Dokumente auf 10 und die Genauigkeit auf 1 festgelegt ist, steigt die Tokenanzahl. Wenn zurückgegebene Antworten nicht auf die erfassten Daten beschränkt sind, gibt es weniger Anweisungen für das Modell, und die Anzahl der Token sinkt.
Die Schätzungen hängen auch von der Art der Dokumente und Fragen ab. Wenn beispielsweise offene Fragen gestellt werden, sind die Antworten wahrscheinlich länger. Ebenso würde eine längere Systemmeldung zu einem längeren Prompt führen, der mehr Token verbraucht, und wenn der Unterhaltungsverlauf lang ist, ist der Prompt länger.
| Modell | Maximale Tokenanzahl für Systemmeldung |
|---|---|
| GPT-35-0301 | 400 |
| GPT-35-0613-16K | 1.000 |
| GPT-4-0613-8K | 400 |
| GPT-4-0613-32K | 2.000 |
| GPT-35-turbo-0125 | 2.000 |
| GPT-4-turbo-0409 | 4000 |
| GPT-4o | 4000 |
| GPT-4o-mini | 4000 |
In der obigen Tabelle ist die maximale Anzahl von Token angegeben, die für die Systemmeldung verwendet werden können. Informationen zum Anzeigen der maximalen Token für die Modellantwort finden Sie im Artikel Modelle. Darüber hinaus werden Token auch von Folgendem genutzt:
Der Metaprompt: Wenn Sie Antworten vom Modell auf den zugrundeliegenden Dateninhalt beschränken (
inScope=Truein der API), ist die maximale Tokenanzahl höher. Andernfalls (z. B. beiinScope=False) ist die maximale Tokenanzahl niedriger. Diese Zahl ist abhängig von der Tokenlänge der Benutzerfrage und des Konversationsverlaufs variabel. Diese Schätzung umfasst den Basisprompt und die Prompts für das Umschreiben der Abfrage für den Abruf.Benutzerfrage und Verlauf: Variabel, aber auf 2000 Token begrenzt.
Abgerufene Dokumente (Blöcke): Die Anzahl der von den abgerufenen Dokumentblöcken verwendeten Token hängt von mehreren Faktoren ab. Die obere Grenze hierfür ist die Anzahl der abgerufenen Dokumentblöcke, die mit der Blockgröße multipliziert werden. Sie wird jedoch auf der Grundlage der für das jeweilige Modell verfügbaren Token nach Zählung der übrigen Felder gekürzt.
20 % der verfügbaren Token sind für die Modellantwort reserviert. Die verbleibenden 80 % der verfügbaren Token umfassen den Meta-Prompt, die Benutzerfrage und den Konversationsverlauf sowie die Systemmeldung. Das verbleibende Tokenbudget wird von den abgerufenen Dokumentblöcken verwendet.
Verwenden Sie das folgende Codebeispiel, um die Anzahl der von Ihrer Eingabe verbrauchten Token (z. B. Ihre Frage, die Systemmeldung, Rolleninformationen) zu berechnen.
import tiktoken
class TokenEstimator(object):
GPT2_TOKENIZER = tiktoken.get_encoding("gpt2")
def estimate_tokens(self, text: str) -> int:
return len(self.GPT2_TOKENIZER.encode(text))
token_output = TokenEstimator.estimate_tokens(input_text)
Problembehandlung
Um Probleme durch fehlgeschlagene Vorgänge zu beheben, achten Sie immer auf Fehler oder Warnungen, die entweder in der API-Antwort oder im Azure AI Foundry-Portal angegeben sind. Hier sind einige der häufigsten Fehler und Warnungen:
Fehlgeschlagener Erfassungsauftrag
Kontingentbeschränkungen
Ein Index mit dem Namen X im Dienst Y konnte nicht erstellt werden. Das Indexkontingent wurde für diesen Dienst überschritten. Sie müssen entweder zuerst nicht verwendete Indizes löschen, eine Verzögerung zwischen Indexerstellungsanforderungen hinzufügen oder den Dienst auf höhere Grenzwerte aktualisieren.
Das Standardindexerkontingent von X wurde für diesen Dienst überschritten. Zurzeit verfügen Sie über X Standardindexer. Sie müssen entweder zuerst nicht verwendete Indexer löschen, den Indexer „executionMode“ ändern oder den Dienst für höhere Grenzwerte aktualisieren.
Lösung:
Führen Sie ein Upgrade auf ein höheres Preisniveau aus, oder löschen Sie nicht verwendete Ressourcen.
Timeoutprobleme bei der Vorverarbeitung
Skill konnte wegen eines Fehlers bei der Anforderung der Web-API nicht ausgeführt werden.
Skill konnte wegen ungültiger Antwort auf den Web-API-Skill nicht ausgeführt werden.
Lösung:
Unterteilen Sie die Eingabedokumente in kleinere Dokumente, und versuchen Sie es erneut.
Berechtigungsprobleme
Diese Anforderung ist zum Durchführen dieses Vorgangs nicht autorisiert
Lösung:
Dies bedeutet, dass mit den angegebenen Anmeldeinformationen nicht auf das Speicherkonto zugegriffen werden kann. Bitte überprüfen Sie in diesem Fall die an die API übergebenen Speicherkontoanmeldeinformationen, und stellen Sie sicher, dass das Speicherkonto nicht hinter einem privaten Endpunkt verborgen ist (wenn kein privater Endpunkt für diese Ressource konfiguriert ist).
503 Fehler beim Senden von Abfragen mit Azure KI-Suche
Jede Benutzernachricht kann in mehrere Suchabfragen übersetzt werden, die alle parallel an die Suchressource gesendet werden. Dies kann zu Drosselungsverhalten führen, wenn die Anzahl der Suchreplikate und Partitionen niedrig ist. Die maximale Anzahl von Abfragen pro Sekunde, die eine einzelne Partition und ein einzelnes Replikat unterstützen können, reichen möglicherweise nicht aus. Ziehen Sie in diesem Fall in Betracht, Ihre Replikate und Partitionen zu erhöhen, oder fügen Sie in Ihrer Anwendung Ruhezustands-/Wiederholungslogik hinzu. Weitere Informationen finden Sie in der Azure KI-Suche-Dokumentation.
Regionale Verfügbarkeit und Modellunterstützung
Hinweis
Die folgenden Modelle werden von Azure OpenAI für Ihre Daten nicht unterstützt:
- o1-Modelle
- o3-Modelle
| Region | gpt-35-turbo-16k (0613) |
gpt-35-turbo (1106) |
gpt-4-32k (0613) |
gpt-4 (1106-preview) |
gpt-4 (0125-preview) |
gpt-4 (0613) |
gpt-4o** |
gpt-4 (turbo-2024-04-09) |
|---|---|---|---|---|---|---|---|---|
| Australien (Osten) | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| Kanada, Osten | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| East US | ✅ | ✅ | ✅ | |||||
| USA (Ost) 2 | ✅ | ✅ | ✅ | ✅ | ||||
| Frankreich, Mitte | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| Japan, Osten | ✅ | |||||||
| USA Nord Mitte | ✅ | ✅ | ✅ | |||||
| Norwegen, Osten | ✅ | ✅ | ||||||
| USA Süd Mitte | ✅ | ✅ | ||||||
| Indien (Süden) | ✅ | ✅ | ||||||
| Schweden, Mitte | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ||
| Schweiz, Norden | ✅ | ✅ | ✅ | |||||
| UK, Süden | ✅ | ✅ | ✅ | ✅ | ||||
| USA (Westen) | ✅ | ✅ | ✅ |
**Dies ist eine Nur-Text-Implementierung
Wenn sich Ihre Azure OpenAI-Ressource in einer anderen Region befindet, werden Sie Azure OpenAI für Ihre Daten nicht verwenden können.