Diese Architektur bietet Anleitungen zum Entwerfen einer unternehmenskritischen Workload in Azure. Sie verwendet cloudnative Funktionen, um die Zuverlässigkeit und die operative Effizienz zu maximieren. Dabei wird die Entwurfsmethodik für unternehmenskritische Well-Architected Framework-Workloads auf eine Anwendung mit Internetverbindung angewendet. Der Zugriff auf die Workload erfolgt über einen öffentlichen Endpunkt, und die Workload erfordert keine private Netzwerkkonnektivität mit anderen Unternehmensressourcen.
Wichtig
 Der Leitfaden basiert auf einer Beispielimplementierung für die Produktion, die die Entwicklung einer unternehmenskritischen Anwendung in Azure veranschaulicht. Diese Implementierung kann als Grundlage für die weitere Lösungsentwicklung bei Ihrem ersten Schritt zur Produktion verwendet werden.
Der Leitfaden basiert auf einer Beispielimplementierung für die Produktion, die die Entwicklung einer unternehmenskritischen Anwendung in Azure veranschaulicht. Diese Implementierung kann als Grundlage für die weitere Lösungsentwicklung bei Ihrem ersten Schritt zur Produktion verwendet werden.
Zuverlässigkeitsstufe
Zuverlässigkeit ist ein relatives Konzept und sollte für eine Workload, die entsprechend zuverlässig sein soll, die geschäftsspezifischen Anforderungen widerspiegeln. Dazu zählen Servicelevelziele (Service Level Objective, SLO) und Vereinbarungen zum Servicelevel (Service Level Agreement, SLA), um den Prozentsatz der Verfügbarkeit der Anwendung zu erfassen.
Für diese Architektur gilt ein Servicelevelziel (Service Level Objective, SLO) von 99,99 Prozent, was einer zulässigen jährlichen Downtime von 52 Minuten und 35 Sekunden entspricht. Alle Entwurfsentscheidungen sollten daher so getroffen werden, dass dieses Ziel-SLO erreicht werden kann.
Tipp
Um ein realistisches SLO zu definieren, ist es wichtig, die Zuverlässigkeitsziele aller Azure-Komponenten und andere Faktoren im Rahmen der Architektur zu verstehen. Weitere Informationen finden Sie unter Empfehlungen zum Definieren von Zuverlässigkeitszielen. Diese einzelnen Zahlen sollten aggregiert werden, um ein zusammengesetztes SLO zu ermitteln, das mit den Workloadzielen übereinstimmt.
Weitere Informationen finden Sie unter Unternehmenskritische Well-Architected Framework-Workloads: Entwurf für Geschäftsanforderungen.
Wichtige Entwurfsstrategien
Viele Faktoren können sich auf die Zuverlässigkeit einer Anwendung auswirken. Dazu zählen beispielsweise die Fähigkeit, sich von Fehlern zu erholen, die regionale Verfügbarkeit, die Bereitstellungseffizienz und die Sicherheit. Diese Architektur wendet eine Reihe übergeordneter Entwurfsstrategien an, die diese Faktoren berücksichtigen und sicherstellen sollen, dass die gewünschte Zuverlässigkeitsstufe erreicht wird.
Redundanz in Ebenen
Stellen Sie die Anwendung in mehreren Regionen in einem Aktiv/Aktiv-Modell bereit. Die Anwendung wird auf zwei oder drei Azure-Regionen verteilt, die aktiven Benutzerdatenverkehr verarbeiten.
Nutzen Sie Verfügbarkeitszonen für alle in Betracht gezogenen Dienste, um die Verfügbarkeit innerhalb einer einzelnen Azure-Region zu erhöhen, indem Sie die Komponenten auf physisch getrennte Rechenzentren in einer Region verteilen.
Wählen Sie Ressourcen aus, die die globale Verteilung unterstützen.
Weitere Informationen finden Sie unter Unternehmenskritische Well-Architected Framework-Workloads: Globale Verteilung.
Bereitstellungsstempel
Stellen Sie einen regionalen Stempel als Skalierungseinheit bereit, in der eine logische Gruppe von Ressourcen unabhängig bereitgestellt werden kann, um auf Änderungen hinsichtlich der Nachfrage reagieren zu können. Jeder Stempel wendet auch mehrere geschachtelte Skalierungseinheiten (z. B. Front-End-APIs und Hintergrundprozessoren) an, die unabhängig voneinander auf- und abskaliert werden können.
Weitere Informationen finden Sie unter Unternehmenskritische Well-Architected Framework-Workloads: Architektur für Skalierungseinheiten.
Zuverlässige und wiederholbare Bereitstellungen
Wenden Sie das IaC-Prinzip (Infrastructure-as-Code) unter Verwendung von Technologien wie Terraform an, um eine Versionskontrolle und einen standardisierten Betriebsansatz für Infrastrukturkomponenten zu ermöglichen.
Implementieren Sie blaue bzw. grüne Bereitstellungspipelines ohne Downtimes. Build- und Releasepipelines müssen vollständig automatisiert sein, um Stempel mithilfe von blauen bzw. grünen Bereitstellungen mit angewendeter fortlaufender Validierung als einzelne Betriebseinheit bereitzustellen.
Wenden Sie Umgebungskonsistenz auf alle berücksichtigten Umgebungen mit dem gleichen Bereitstellungspipelinecode in Produktions- und Vorabproduktionsumgebungen an. Dadurch werden Risiken beseitigt, die mit Bereitstellungs- und Prozessvariationen in allen Umgebungen verbunden sind.
Richten Sie die kontinuierliche Validierung ein, indem Sie automatisierte Tests als Teil von DevOps-Prozessen integrieren (einschließlich synchronisierter Last- und Chaostests), um die Integrität des Anwendungscodes und der zugrunde liegenden Infrastruktur vollständig zu überprüfen.
Weitere Informationen finden Sie unter Unternehmenskritische Well-Architected Framework-Workloads: Bereitstellung und Tests.
Operative Erkenntnisse
Richten Sie Verbundarbeitsarbeitsbereiche für Beobachtungsdaten ein. Überwachungsdaten für globale und regionale Ressourcen werden unabhängig voneinander gespeichert. Ein zentralisierter Speicher für Beobachtungsdaten wird nicht empfohlen, um einen Single Point of Failure zu vermeiden. Das arbeitsbereichsübergreifende Abfragen wird verwendet, um eine einheitliche Datensenke und eine zentralisierte Benutzeroberfläche für Vorgänge bereitzustellen.
Entwickeln Sie ein mehrstufiges Integritätsmodell, das die Anwendungsintegrität einem Ampelmodell für Kontextualisierung zuordnet. Integritätsbewertungen werden für jede einzelne Komponente berechnet und dann auf Benutzerflowebene aggregiert und mit wichtigen, nicht funktionalen Anforderungen wie der Leistung als Koeffizienten zum Quantifizieren der Anwendungsintegrität kombiniert.
Weitere Informationen finden Sie unter Unternehmenskritische Well-Architected Framework-Workloads: Integritätsmodellierung.
Architektur

* Laden Sie eine Visio-Datei dieser Architektur herunter.
Die Komponenten dieser Architektur können auf diese Weise weitgehend kategorisiert werden. Eine Produktdokumentation zu Azure-Diensten finden Sie unter Zugehörige Ressourcen.
Globale Ressourcen
Die globalen Ressourcen sind persistent und während der gesamten Lebensdauer des Systems verfügbar. Sie können im Kontext eines Bereitstellungsmodells für mehrere Regionen global verfügbar gemacht werden.
Hier sind die allgemeinen Überlegungen zu den Komponenten aufgeführt. Ausführliche Informationen zu den Entscheidungen finden Sie unter Globale Ressourcen.
Globaler Lastenausgleich
Ein globaler Lastenausgleich ist essenziell für das zuverlässige Routing von Datenverkehr mit einer gewissen Garantie an die regionalen Bereitstellungen basierend auf der Verfügbarkeit von Back-End-Diensten in einer Region. Außerdem sollte diese Komponente die Möglichkeit haben, eingehenden Datenverkehr beispielsweise über die Web Application Firewall zu überprüfen.
Azure Front Door wird als globaler Einstiegspunkt für den gesamten eingehenden HTTP(S)-Clientdatenverkehr genutzt, wobei WAF-Funktionen (Web Application Firewall) zum Schützen des eingehenden Layer-7-Datenverkehrs angewendet werden. Der Dienst verwendet TCP Anycast, um das Routing mithilfe des Microsoft-Backbonenetzwerks zu optimieren und im Fall einer beeinträchtigten regionalen Integrität transparente Failover zu ermöglichen. Das Routing hängt von benutzerdefinierten Integritätstests ab, die die zusammengesetzte Integrität der wichtigen regionalen Ressourcen überprüfen. Azure Front Door bietet auch ein integriertes Content Delivery Network (CDN), um statische Ressourcen für die Websitekomponente zwischenzuspeichern.
Eine weitere Option ist der Traffic Manager, bei dem es sich um einen DNS-basierten Layer-4-Lastenausgleich handelt. Fehler sind jedoch nicht für alle Clients transparent, da die DNS-Verteilung durchgeführt werden muss.
Weitere Informationen finden Sie unter Unternehmenskritische Well-Architected Framework-Workloads: Globales Datenverkehrsrouting.
Datenbank
Alle Status im Zusammenhang mit der Workload werden in einer externen Datenbank gespeichert (Azure Cosmos DB for NoSQL). Diese Option wurde ausgewählt, da sie die Features umfasst, die für die Optimierung der Leistung und Zuverlässigkeit auf Client- und Serverseite erforderlich sind. Es wird dringend empfohlen, dass für das Konto Multimaster für Schreibvorgänge aktiviert ist.
Hinweis
Während eine Schreibkonfiguration für mehrere Regionen den Goldstandard für Zuverlässigkeit darstellt, sind hinsichtlich der Kosten drastische Kompromisse erforderlich, die Sie gut überdenken sollten.
Das Konto wird in jeden regionalen Stempel repliziert, und die Zonenredundanz ist aktiviert. Zudem ist die automatische Skalierung auf Containerebene aktiviert, sodass Container den bereitgestellten Durchsatz automatische nach Bedarf skalieren.
Weitere Informationen finden Sie unter Datenplattform für unternehmenskritische Workloads.
Weitere Informationen finden Sie unter Unternehmenskritische Well-Architected Framework-Workloads: Global verteilter Datenspeicher für mehrere Schreibvorgänge.
Containerregistrierung
Azure Container Registry wird zum Speichern aller Containerimages verwendet. Der Dienst umfasst Georeplikationsfunktionen, durch die die Ressourcen als einzelne Registrierung fungieren und regionale Multimasterregistrierungen in mehreren Regionen bereitgestellt werden können.
Als Sicherheitsmaßnahme können Sie nur den Zugriff auf erforderliche Entitäten zulassen und diesen Zugriff authentifizieren. Beispielsweise ist der Administratorzugriff in der Implementierung deaktiviert. Der Computecluster kann also nur Images mit Microsoft Entra-Rollenzuweisungen pullen.
Weitere Informationen finden Sie unter Unternehmenskritische Well-Architected Framework-Workloads: Containerregistrierung.
Regionale Ressourcen
Die regionalen Ressourcen werden als Teil eines Bereitstellungsstempels in einer einzelnen Azure-Region bereitgestellt. Diese Ressourcen sind von Ressourcen in anderen Regionen unabhängig. Sie können unabhängig entfernt oder in zusätzliche Regionen repliziert werden. Sie geben untereinander jedoch globale Ressourcen füreinander frei.
In dieser Architektur stellt eine einheitliche Bereitstellungspipeline einen Stempel mit diesen Ressourcen bereit.
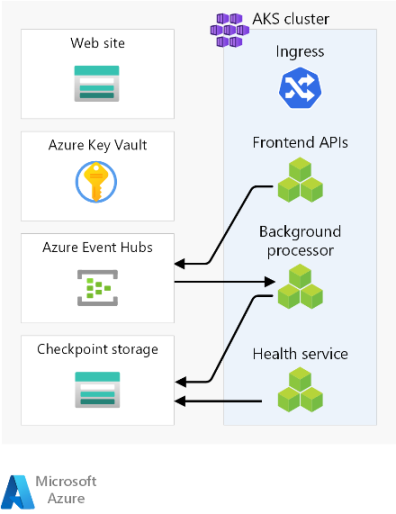
Hier sind die allgemeinen Überlegungen zu den Komponenten aufgeführt. Ausführliche Informationen zu den Entscheidungen finden Sie unter Regionale Bereitstellungsstempelressourcen.
Front-End
Diese Architektur verwendet eine Single-Page-Webanwendung (SPA), die Anforderungen an Back-End-Dienste sendet. Ein Vorteil ist, dass die für die Websitefunktionalität benötigte Compute auf den Client anstelle auf Ihre Server ausgelagert wird. Die SPA wird als statische Website in einem Azure Storage-Konto gehostet.
Eine weitere Möglichkeit stellt Azure Static Web Apps dar. Bei diesem Dienst werden zusätzliche Überlegungen wie das Verfügbarmachen von Zertifikaten, die Verbindung mit einem globalen Lastenausgleich und andere Faktoren berücksichtigt.
Statische Inhalte werden in der Regel in einem Speicher in der Nähe des Clients zwischengespeichert, wobei ein Content Delivery Network (CDN) verwendet wird, sodass die Daten schnell bereitgestellt werden können, ohne direkt mit Back-End-Servern zu kommunizieren. Dies ist eine kosteneffiziente Möglichkeit, die Zuverlässigkeit zu erhöhen und die Netzwerklatenz zu verringern. In dieser Architektur werden die integrierten CDN-Funktionen von Azure Front Door verwendet, um statische Websiteinhalte im Edgenetzwerk zwischenzuspeichern.
Computecluster
Die Back-End-Compute führt eine aus drei Microservices bestehende Anwendung aus und ist zustandslos. Die Containerisierung stellt also eine geeignete Strategie zum Hosten der Anwendung dar. Azure Kubernetes Service (AKS) wurde ausgewählt, da diese Umgebung die meisten Geschäftsanforderungen erfüllt und Kubernetes in vielen Branchen genutzt wird. AKS unterstützt erweiterte Skalierbarkeits- und Bereitstellungstopologien. Die AKS-Ebene für die Uptime-SLA wird für das Hosten unternehmenskritischer Anwendungen dringend empfohlen, da er Verfügbarkeitsgarantien für die Kubernetes-Steuerungsebene bietet.
Azure stellt andere Computedienste wie Azure Functions und Azure App Services bereit. Durch diese Optionen werden zusätzliche Verwaltungsaufgaben auf Kosten von Flexibilität und Dichte an Azure ausgelagert.
Hinweis
Vermeiden Sie das Speichern des Zustands im Computecluster, und beachten Sie dabei die Flüchtigkeit der Stempel. Speichern Sie den Status soweit möglich in einer externen Datenbank, um Skalierungs- und Wiederherstellungsvorgänge einfach zu halten. In AKS ändern sich beispielsweise Pods häufig. Durch das Anfügen des Status an Pods kommt die Last der Datenkonsistenz auf.
Weitere Informationen finden Sie unter Unternehmenskritische Well-Architected Framework-Workloads: Containerorchestrierung und Kubernetes.
Regionaler Nachrichtenbroker
Um die Leistung zu optimieren und während Spitzenlasten reaktionsfähig zu bleiben, verwendet der Entwurf das asynchrone Messaging für die Verarbeitung intensiver Systemflows. Da den Front-End-APIs eine Anforderung schnell bestätigt wird, wird diese ebenfalls in eine Warteschlange in einem Nachrichtenbroker eingereiht. Diese Nachrichten werden anschließend von einem Back-End-Dienst genutzt, der beispielsweise einen Schreibvorgang in eine Datenbank verarbeitet.
Mit Ausnahme von bestimmten Punkten (z. B. dieser Nachrichtenbroker) ist der gesamte Stempel zustandslos. Daten werden im Broker für einen kurzen Zeitraum in eine Warteschlange gestellt. Der Nachrichtenbroker muss mindestens einmal die Zustellung garantieren. Das bedeutet, dass sich Nachrichten in der Warteschlange befinden, wenn der Broker nach Wiederherstellung des Diensts nicht mehr verfügbar ist. Es liegt jedoch in der Verantwortung des Consumers, zu bestimmen, ob diese Nachrichten noch weiter verarbeitet werden müssen. Die Warteschlange wird geleert, nachdem die Nachricht verarbeitet und in einer globalen Datenbank gespeichert wurde.
Bei diesem Entwurf wird Azure Event Hubs verwendet. Ein zusätzliches Azure Storage-Konto wird zur Prüfpunkterstellung bereitgestellt. Event Hubs ist die empfohlene Wahl für Anwendungsfälle, in denen ein hoher Durchsatz erforderlich ist (z. B. beim Eventstreaming).
Bei Anwendungsfällen, die zusätzliche Nachrichtengarantien erfordern, wird Azure Service Bus empfohlen. Der Dienst ermöglicht Zweiphasencommits mit einem clientseitigen Cursor sowie Features wie eine integrierte Warteschlange für unzustellbare Nachrichten und Deduplizierungsfunktionen.
Weitere Informationen finden Sie unter Messagingdienste für unternehmenskritische Workloads.
Weitere Informationen finden Sie unter Unternehmenskritische Well-Architected Framework-Workloads: Lose gekoppelte, ereignisgesteuerte Architektur.
Regionaler Geheimnisspeicher
Jeder Stempel verfügt über eine eigene Azure Key Vault-Instanz, in der Geheimnisse und die Konfiguration gespeichert werden. Es gibt allgemeine Geheimnisse wie Verbindungszeichenfolgen für die globale Datenbank, aber auch Informationen, die für einen einzelnen Stempel eindeutig sind (z. B. die Event Hubs-Verbindungszeichenfolge). Außerdem vermeiden unabhängige Ressourcen einen Single Point of Failure.
Weitere Informationen finden Sie unter Unternehmenskritische Well-Architected Framework-Workloads: Datenintegritätsschutz.
Bereitstellungspipeline
Build- und Releasepipelines für eine unternehmenskritische Anwendung müssen vollständig automatisiert sein. Daher sollten keine manuellen Aktionen erforderlich sein. Dieser Entwurf veranschaulicht vollständig automatisierte Pipelines, die jedes Mal einen validierten Stempel bereitstellen. Eine andere Alternative besteht darin, nur parallele Updates für einen vorhandenen Stempel bereitzustellen.
Quellcoderepository
GitHub wird für die Quellcodeverwaltung verwendet, wodurch eine hochverfügbare, Git-basierte Plattform für die Zusammenarbeit an Anwendungscode und Infrastrukturcode bereitgestellt wird.
CI/CD-Pipelines (Continuous Integration/Continuous Delivery)
Automatisierte Pipelines sind für das Erstellen, Testen und Bereitstellen unternehmenskritischer Workloads in Vorproduktions- und Produktionsumgebungen erforderlich. Azure Pipelines wird aufgrund des umfangreichen Toolsets ausgewählt, das auf Azure und andere Cloudplattformen ausgerichtet werden kann.
Eine weitere Option ist GitHub Actions für CI/CD-Pipelines. Der zusätzliche Vorteil besteht darin, dass Quellcode und die Pipeline verbunden werden können. Azure Pipelines wurde jedoch aufgrund der umfangreicheren CD-Funktionen ausgewählt.
Weitere Informationen finden Sie unter Unternehmenskritische Well-Architected Framework-Workloads: DevOps-Prozesse.
Build-Agents
Von Microsoft gehostete Build-Agents werden in dieser Implementierung genutzt, um die Komplexität und den Verwaltungsaufwand zu verringern. Selbstgehostete Agents können für Szenarios verwendet werden, die einen gehärteten Sicherheitsstatus erfordern.
Hinweis
Die Verwendung selbstgehosteter Agents wird in der Referenzimplementierung Unternehmenskritisch – Verbunden veranschaulicht.
Beobachtungsressourcen
Betriebsdaten aus Anwendung und Infrastruktur müssen verfügbar sein, um effektive Vorgänge zu ermöglichen und die Zuverlässigkeit zu maximieren. Diese Referenz bietet eine Grundlage für die ganzheitliche Überwachung einer Anwendung.
Einheitliche Datensenke
- Azure Log Analytics wird als einheitliche Senke zum Speichern von Protokollen und Metriken für Anwendungs- und Infrastrukturkomponenten verwendet.
- Azure Application Insights wird als APM-Tool (Application Performance Management) zum Sammeln aller Anwendungsüberwachungsdaten und deren Speicherung in Log Analytics genutzt.

Überwachungsdaten für globale und regionale Ressourcen sollten unabhängig voneinander gespeichert werden. Ein einzelner, zentralisierter Speicher für Beobachtungsdaten wird nicht empfohlen, um einen Single Point of Failure zu vermeiden. Das arbeitsbereichsübergreifende Abfragen wird verwendet, um eine zentralisierte Benutzeroberfläche bereitzustellen.
In dieser Architektur muss die Überwachung von Ressourcen innerhalb einer Region unabhängig vom Stempel selbst erfolgen, da die Überwachung auch beim Entfernen eines Stempels noch möglich sein soll. Jeder regionale Stempel verfügt über einen eigenen dedizierten Application Insights- und Log Analytics-Arbeitsbereich. Die Ressourcen werden pro Region bereitgestellt, überdauern aber die Stempel.
Ebenso werden Daten aus freigegebenen Diensten wie Azure Front Door, Azure Cosmos DB und Container Registry in einer dedizierten Instanz des Log Analytics-Arbeitsbereichs gespeichert.
Datenarchivierung und -analyse
Operative Daten, die für aktive Vorgänge nicht erforderlich sind, werden für Datenaufbewahrungszwecke und zum Bereitstellen einer Analysequelle für AIOps, die zum Optimieren des Anwendungsintegritätsmodells und betrieblicher Verfahren angewendet werden können, aus Log Analytics in Azure Storage-Konten exportiert.
Weitere Informationen finden Sie unter Unternehmenskritische Well-Architected Framework-Workloads: Vorhersageaktionen und KI-Vorgänge.
Anforderungs- und Prozessorflows
Diese Abbildung zeigt den Anforderungs- und Hintergrundprozessorflow der Referenzimplementierung.

Dieser Datenfluss wird in den folgenden Abschnitten beschrieben.
Websiteanforderungsflow
Eine Anforderung für die Webbenutzeroberfläche wird an einen globalen Lastenausgleich gesendet. Für diese Architektur ist Azure Front Door der globale Lastenausgleich.
Die WAF-Regeln werden ausgewertet. WAF-Regeln wirken sich positiv auf die Zuverlässigkeit des Systems aus, indem sie vor einer Vielzahl von Angriffen wie Cross-Site Scripting (XSS) und SQL-Injektion schützen. Azure Front Door gibt einen Fehler an die Antragsteller*innen zurück, wenn eine WAF-Regel verletzt wird, und der Verarbeitungsvorgang wird beendet. Wenn keine WAF-Regeln verletzt werden, setzt Azure Front Door die Verarbeitung fort.
Azure Front Door verwendet Routingregeln, um zu bestimmen, an welchen Back-End-Pool eine Anforderung weitergeleitet werden soll. Abgleichen von Anforderungen mit einer Routingregel In dieser Referenzimplementierung ermöglichen die Routingregeln Azure Front Door das Weiterleiten von Benutzeroberflächenanforderungen und Front-End-API-Anforderungen an unterschiedliche Back-End-Ressourcen. In diesem Fall stimmt das Muster „/*“ mit der Routingregel für die Benutzeroberfläche überein. Diese Regel leitet die Anforderung an einen Back-End-Pool weiter, der Speicherkonten mit statischen Websites enthält, die die Single-Page-Webanwendung (SPA) hosten. Azure Front Door verwendet die Priorität und Gewichtung, die den Back-Ends im Pool zugewiesen ist, um das Back-End auszuwählen, an das die Anforderung weitergeleitet werden soll. Methoden für das Routing von Datenverkehr an den Ursprung Azure Front Door nutzt Integritätstests, um sicherzustellen, dass Anforderungen nicht an Back-Ends weitergeleitet werden, die nicht fehlerfrei sind. Die SPA wird über das ausgewählte Speicherkonto mit statischer Website bereitgestellt.
Hinweis
Die Begriffe Back-End-Pools und Back-Ends in Azure Front Door (klassisch) werden in den Azure Front Door-Tarifen „Standard“ oder „Premium“ als Ursprungsgruppen und Ursprünge bezeichnet.
Die SPA führt einen API-Aufruf an den Azure Front Door-Front-End-Host durch. Das Muster der API-Anforderungs-URL lautet „/api/*“.
Front-End-API-Anforderungsflow
Die WAF-Regeln werden wie in Schritt 2 ausgewertet.
Azure Front Door gleicht die Anforderung über das „/api/*“-Muster mit der API-Routingregel ab. Die API-Routingregel leitet die Anforderung an einen Back-End-Pool weiter, der die öffentlichen IP-Adressen für NGINX-Eingangsdatencontroller enthält, die wissen, wie Anforderungen an den richtigen Dienst in Azure Kubernetes Service (AKS) weitergeleitet werden. Wie zuvor verwendet Azure Front Door die Priorität und Gewichtung, die den Back-Ends zugewiesen ist, um das richtige Back-End für den NGINX-Eingangsdatencontroller auszuwählen.
Bei GET-Anforderungen führt die Front-End-API Lesevorgänge in einer Datenbank aus. Für diese Referenzimplementierung ist die Datenbank eine globale Azure Cosmos DB-Instanz. Azure Cosmos DB umfasst mehrere Features, die dafür sorgen, dass sich der Dienst für unternehmenskritische Workloads eignet. Dazu zählt die Möglichkeit, problemlos Schreibvorgänge für mehrere Regionen zu konfigurieren, wodurch automatische Failover für Lese- und Schreibvorgänge in sekundären Regionen möglich sind. Die API verwendet das mit Wiederholungslogik konfigurierte Client-SDK, um mit Azure Cosmos DB zu kommunizieren. Das SDK bestimmt die optimale Reihenfolge der verfügbaren Azure Cosmos DB-Regionen, mit denen basierend auf dem Parameter ApplicationRegion kommuniziert werden soll.
Bei POST- oder PUT-Anforderungen führt die Front-End-API Schreibvorgänge in einen Nachrichtenbroker aus. In der Referenzimplementierung ist Azure Event Hubs der Nachrichtenbroker. Alternativ können Sie Service Bus auswählen. Ein Handler liest später Nachrichten aus dem Nachrichtenbroker und führt alle erforderlichen Schreibvorgänge an Azure Cosmos DB aus. Die API verwendet das Client-SDK, um Schreibvorgänge auszuführen. Der Client kann für Wiederholungen konfiguriert werden.
Hintergrundprozessorflow
Die Hintergrundprozessoren verarbeiten Nachrichten vom Nachrichtenbroker. Sie verwenden das Client-SDK, um Lesevorgänge auszuführen. Der Client kann für Wiederholungen konfiguriert werden.
Die Hintergrundprozessoren führen die entsprechenden Schreibvorgänge in der globalen Azure Cosmos DB-Instanz aus. Sie verwenden das Client-SDK, das mit Wiederholungsvorgängen konfiguriert ist, um eine Verbindung mit Azure Cosmos DB herzustellen. Die bevorzugte Regionsliste des Clients kann mit mehreren Regionen konfiguriert werden. Wenn bei einem Schreibvorgang ein Fehler auftritt, wird der Wiederholungsvorgang für die nächste bevorzugte Region ausgeführt.
Entwurfsbereiche
Es wird empfohlen, sich beim Definieren Ihrer unternehmenskritischen Architektur die Empfehlungen und bewährten Methoden für diese Entwurfsbereiche durchzulesen.
| Entwurfsbereich | BESCHREIBUNG |
|---|---|
| Anwendungsentwurf | Entwurfsmuster, die die Skalierung und Fehlerbehandlung ermöglichen |
| Anwendungsplattform | Infrastrukturoptionen und Risikominderungen in Bezug auf potenzielle Fehlerfälle |
| Datenplattform | Auswahlmöglichkeiten im Zusammenhang mit Datenspeichertechnologien, basierend auf der Auswertung von erforderlichen Merkmalen wie Volumen, Geschwindigkeit, Vielfalt und Richtigkeit |
| Netzwerk und Konnektivität | Netzwerküberlegungen für das Routing des eingehenden Datenverkehrs an Stempel |
| Integritätsmodellierung | Überlegungen zur Beobachtbarkeit, basierend auf der mit der Analyse der Auswirkungen auf Kund*innen korrelierten Überwachung, um die allgemeine Anwendungsintegrität zu ermitteln |
| Bereitstellung und Tests | Strategien für CI/CD-Pipelines und Automatisierungsaspekte, einschließlich integrierter Testszenarios wie synchronisierte Auslastungstests und Fehlerinjektionstests (Chaostests) |
| Sicherheit | Entschärfung von Angriffsvektoren durch das Zero Trust-Modell von Microsoft |
| Betriebsprozeduren | Prozesse im Zusammenhang mit Bereitstellung, Schlüsselverwaltung, Patching und Updates |
** Gibt Überlegungen zum Entwurfsbereich an, die für diese Architektur spezifisch sind.
Zugehörige Ressourcen
Eine Produktdokumentation zu den in dieser Architektur verwendeten Azure-Diensten finden Sie in den folgenden Artikeln.
- Azure Front Door
- Azure Cosmos DB
- Azure Container Registry
- Azure Log Analytics
- Azure Key Vault
- Azure Service Bus
- Azure Kubernetes Service
- Azure Application Insights
- Azure Event Hubs
- Azure Blob Storage
Bereitstellen dieser Architektur
Stellen Sie die Referenzimplementierung bereit, um ein umfassendes Verständnis der berücksichtigten Ressourcen zu erhalten, einschließlich deren Operationalisierung in einem unternehmenskritischen Kontext. Er enthält einen Bereitstellungsleitfaden, der einen lösungsorientierten Ansatz für die unternehmenskritische Anwendungsentwicklung in Azure veranschaulichen soll.
Nächste Schritte
Wenn Sie die Baselinearchitektur um Netzwerksteuerungen für den ein- und ausgehenden Datenverkehr erweitern möchten, betrachten Sie diese Architektur.