Was ist ein Data Lake?
Ein Data Lake ist ein Repository zur Speicherung großer Datenmengen in ihrem nativen Rohformat. Data Lake Stores sind optimiert, sodass ihre Größe auf Terabytes und Petabytes von Daten skaliert werden kann. Die Daten stammen in der Regel aus mehreren unterschiedlichen Quellen und können strukturiert, teilweise strukturiert oder unstrukturiert sein. Mithilfe eines Data Lakes können Daten ohne jegliche Transformation im ursprünglichen Zustand gespeichert werden. Diese Methode unterscheidet sich von einem herkömmlichen Data Warehouse: Hier werden die Daten bei der Erfassung transformiert und verarbeitet.
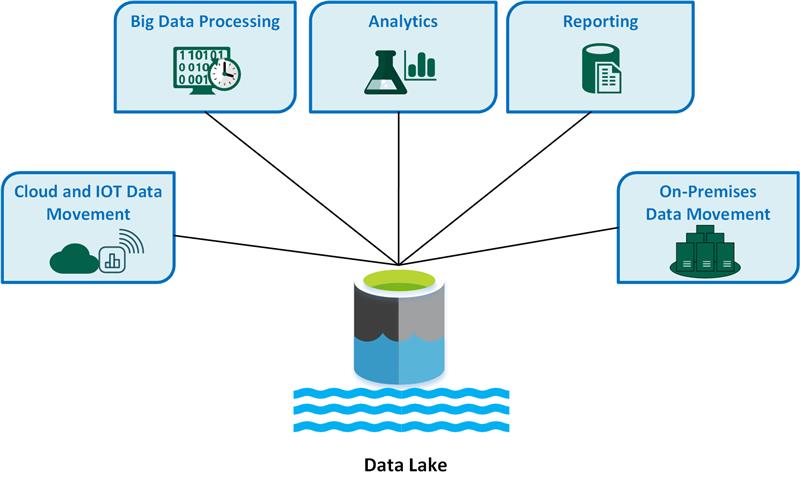
Zu den wichtigsten Anwendungsfällen von Data Lakes gehören:
- Cloud- und IOT-Datenverschiebung (Internet der Dinge)
- Big Data-Verarbeitung
- Analysen.
- Die Berichterstellung
- Lokale Datenverschiebung
Ein Data Lake bietet folgende Vorteile:
In einem Data Lake werden niemals Daten gelöscht, da sie im Rohformat gespeichert werden. Diese Funktion ist besonders in einer Big Data-Umgebung hilfreich, da Sie u. U. nicht im Voraus wissen, welche Erkenntnisse Sie aus den Daten gewinnen können.
Benutzer können die Daten untersuchen und eigene Abfragen erstellen.
Ein Data Lake ist möglicherweise schneller als herkömmliche ETL-Tools (Extrahieren, Transformieren, Laden).
Ein Data Lake ist flexibler als ein Data Warehouse, da sowohl unstrukturierte als auch teilweise strukturierte Daten gespeichert werden können.
Ein vollständige Data Lake-Lösung umfasst sowohl Speicherung als auch Verarbeitung. Data Lake Storage ist für Fehlertoleranz, unbegrenzte Skalierbarkeit und für die durchsatzstarke Erfassung von Daten in verschiedenen Formen und Größen konzipiert. Die Data Lake-Verarbeitung umfasst mindestens eine Verarbeitungsengine, die auf diese Ziele ausgerichtet ist und die in einem Data Lake gespeicherten Daten in großem Umfang verarbeiten kann.
Wann sollten Sie einen Data Lake verwenden?
Es wird empfohlen, einen Data Lake für die Datenexploration, die Datenanalyse und Machine Learning zu verwenden.
Ein Data Lake kann als Datenquelle für ein Data Warehouse fungieren. Bei Verwendung dieser Methode erfasst der Data Lake Rohdaten und transformiert sie dann in ein strukturiertes abfragbares Format. Für diese Transformation wird in der Regel eine ETL-Pipeline (Extrahieren, Transformieren, Laden) verwendet, in der die Daten erfasst und direkt transformiert werden. Relationale Quelldaten können mithilfe eines ETL-Prozesses unter Umgehung des Data Lakes direkt im Data Warehouse erfasst werden.
Sie können Data Lake Stores für das Ereignisstreaming oder für IoT-Szenarien verwenden, da Data Lakes große Mengen von relationalen und nicht relationalen Daten ohne Transformation oder Schemadefinition beständig speichern können. Data Lakes können große Mengen kleiner Schreibvorgänge mit geringer Wartezeit verarbeiten und sind für massive Durchsätze optimiert.
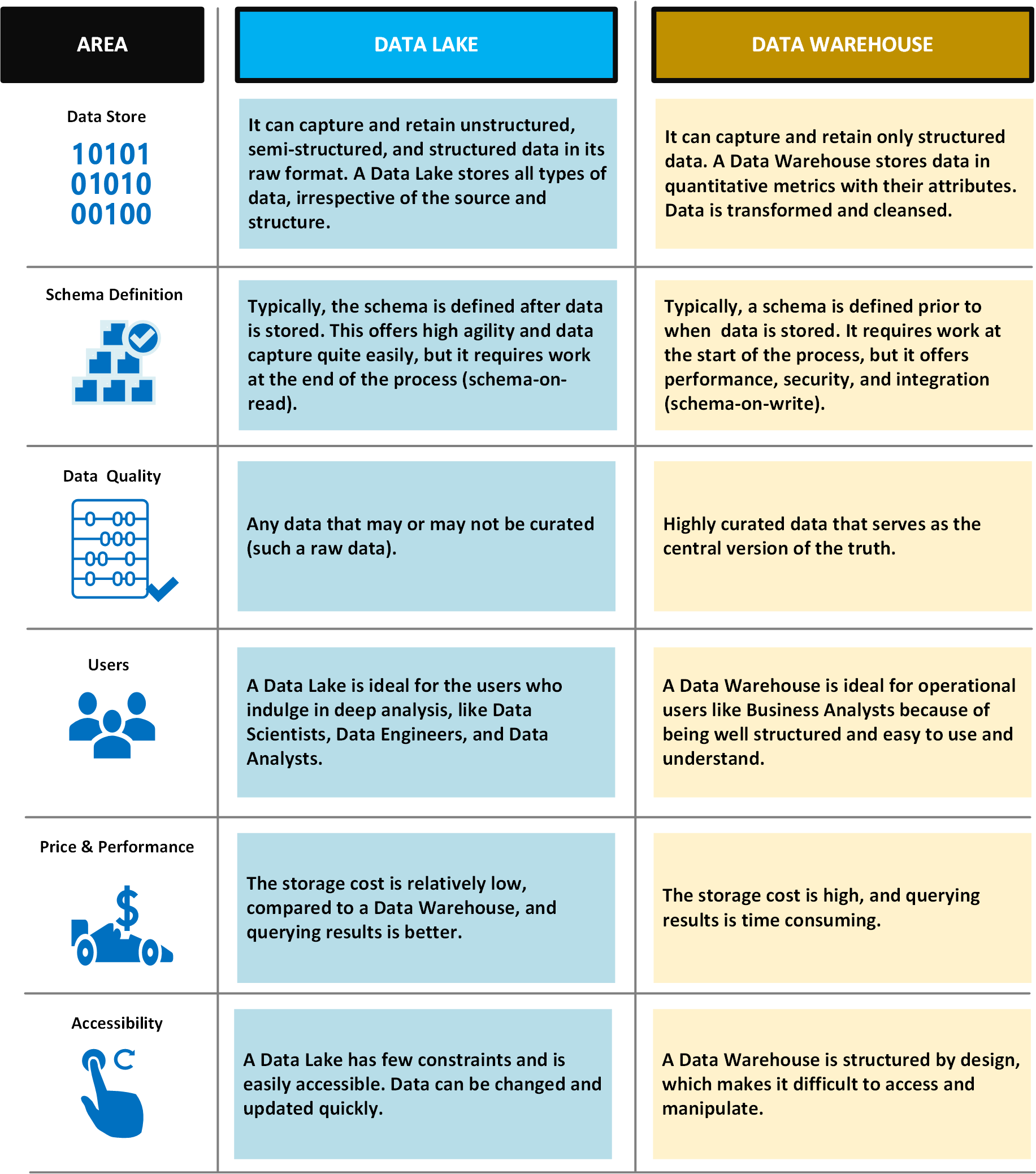
In der folgenden Tabelle werden Data Lakes und Data Warehouses verglichen:
Herausforderungen
Große Datenmengen: Die Verwaltung großer Mengen von Roh- und unstrukturierten Daten kann komplex und ressourcenintensiv sein und erfordert eine robuste Infrastruktur und geeignete Tools.
Potenzielle Engpässe: Die Datenverarbeitung kann zu Verzögerungen und Ineffizienzen führen, insbesondere bei großen Datenmengen und unterschiedlichen Datentypen.
Risiken der Datenbeschädigung: Eine unsachgemäße Datenüberprüfung und -überwachung birgt das Risiko von Datenbeschädigungen, was die Integrität des Data Lakes gefährden kann.
Probleme bei der Qualitätskontrolle: Eine adäquate Datenqualität ist aufgrund der Vielfalt der Datenquellen und -formate eine Herausforderung. Sie müssen strenge Data Governance-Praktiken implementieren.
Leistungsprobleme: Die Abfrageleistung kann mit einem wachsenden Data Lake beeinträchtigt werden, sodass Sie die Speicher- und Verarbeitungsstrategien optimieren müssen.
Auswahl der Technologie
Beim Aufbau einer umfassenden Data Lake-Lösung in Azure sollten Sie die folgenden Technologien in Betracht ziehen:
Azure Data Lake Storage kombiniert Azure Blob Storage mit Data Lake-Funktionen, die Apache Hadoop-kompatiblen Zugriff, hierarchische Namespacefunktionen und verbesserte Sicherheit für effiziente Big Data-Analysen bieten.
Azure Databricks ist eine einheitliche Plattform, mit der Sie Daten verarbeiten, speichern, analysieren und monetarisieren können. Die Plattform unterstützt ETL-Prozesse, Dashboards, Sicherheitsfunktionen, Datenexploration, Machine Learning und generative KI.
Azure Synapse Analytics ist ein einheitlicher Dienst, mit dem Sie Daten für unmittelbare Business Intelligence- und Machine Learning-Anforderungen erfassen, untersuchen, aufbereiten, verwalten und verarbeiten können. Er ist tief in Azure Data Lakes integriert, sodass Sie große Datasets effizient abfragen und analysieren können.
Azure Data Factory ist ein cloudbasierter Datenintegrationsdienst, mit dem Sie datengesteuerte Workflows erstellen können, um die Datenverschiebung und -transformation zu orchestrieren und zu automatisieren.
Microsoft Fabric ist eine umfassende Datenplattform, die Datentechnik, Data Science, Data Warehousing, Echtzeitanalysen und Business Intelligence in einer einzigen Lösung vereinheitlicht.
Beitragende
Dieser Artikel wird von Microsoft gepflegt. Er wurde ursprünglich von folgenden Mitwirkenden geschrieben:
Hauptautor:
- Avijit Prasad | Cloudberater
Melden Sie sich bei LinkedIn an, um nicht öffentliche LinkedIn-Profile anzuzeigen.
Nächste Schritte
- Was ist OneLake?
- Einführung in Data Lake Storage
- Dokumentation zu Azure Data Lake Analytics
- Training: Einführung in Data Lake Storage
- Integration von Hadoop und Azure Data Lake Storage
- Herstellen einer Verbindung mit Data Lake Storage und Blob Storage
- Laden von Daten in Data Lake Storage mit Azure Data Factory