Horizontales Hochskalieren von Azure Analysis Services
Durch die horizontale Skalierung können Clientabfragen auf mehrere Abfragereplikate in einem Abfragepool verteilt werden, was bei einem hohen Aufkommen von Abfrageworkloads zu kürzeren Antwortzeiten führt. Darüber hinaus kann die Verarbeitung vom Abfragepool getrennt werden, um sicherzustellen, dass Clientabfragen nicht durch Verarbeitungsvorgänge beeinträchtigt werden. Horizontales Hochskalieren kann im Azure-Portal oder mithilfe der Analysis Services-REST-API konfiguriert werden.
Horizontales Hochskalieren ist für Server im Standardtarif verfügbar. Jedes Abfragereplikat wird mit dem gleichen Tarif abgerechnet wie Ihr Server. Alle Abfragereplikate werden in der gleichen Region wie Ihr Server erstellt. Die Anzahl der von Ihnen konfigurierbaren Abfragereplikate ist durch die Region, in der sich Ihr Server befindet, eingeschränkt. Weitere Informationen finden Sie unter Verfügbarkeit nach Region. Durch horizontale Hochskalierung erhöht sich nicht die Menge an verfügbarem Arbeitsspeicher für Ihren Server. Zur Erhöhung des Arbeitsspeichers müssen Sie Ihren Plan upgraden.
Gründe für die Aufskalierung
In einer typischen Serverbereitstellung fungiert ein einzelner Server sowohl als Verarbeitungs- als auch als Abfrageserver. Wenn die Anzahl von Clientabfragen für Modelle auf dem Server die QPUs (Query Processing Units) für den Tarif Ihres Servers übersteigt oder die Modellverarbeitung mit einem hohen Aufkommen von Abfrageworkloads zusammenfällt, kann sich dies negativ auf die Leistung auswirken.
Mit der horizontalen Skalierung können Sie einen Abfragepool mit bis zu sieben zusätzlichen Abfragereplikatressourcen erstellen, sodass Sie zusammen mit Ihrem primären Server über insgesamt acht verfügen. Sie können die Anzahl von Replikaten im Abfragepool jederzeit skalieren, um die QPU-Anforderungen in kritischen Zeiten zu erfüllen, und Sie können einen Verarbeitungsserver aus dem Abfragepool herauslösen.
Verarbeitungsworkloads werden unabhängig von der Anzahl von Abfragereplikaten in einem Abfragepool nicht auf Abfragereplikate verteilt. Der primäre Server fungiert als Verarbeitungsserver. Abfragereplikate bedienen ausschließlich Abfragen für die Modelldatenbanken, die zwischen dem primären Server und den einzelnen Replikaten im Abfragepool synchronisiert werden.
Beim horizontalen Skalieren kann es bis zu fünf Minuten dauern, bis neue Abfragereplikate inkrementell in den Abfragepool aufgenommen werden. Wenn alle neuen Abfragereplikate einsatzbereit sind, kommen für neue Clientverbindungen Ressourcen im Abfragepool für den Lastenausgleich zum Einsatz. Bestehende Clientverbindungen werden nicht geändert; die Verbindung mit der bisherigen Ressource bleibt bestehen. Beim horizontalen Herunterskalieren werden alle bestehenden Clientverbindungen mit einer Abfragepoolressource, die aus dem Abfragepool entfernt wird, beendet. Clients können die Verbindung mit verbleibenden Poolressourcen wiederherstellen.
Funktionsweise
Beim ersten Konfigurieren der horizontalen Skalierung werden Modelldatenbanken auf Ihrem primären Server automatisch mit neuen Replikaten in einem neuen Abfragepool synchronisiert. Die automatische Synchronisierung erfolgt nur einmal. Bei der automatischen Synchronisierung werden die Datendateien des (im Ruhezustand im Blobspeicher verschlüsselten) primären Servers an einen zweiten Speicherort kopiert, der ebenfalls im Ruhezustand im Blobspeicher verschlüsselt ist. Replikate im Abfragepool werden dann mit Daten aus dem zweiten Datensatz aufgefüllt.
Eine automatische Synchronisierung erfolgt nur, wenn Sie erstmals eine horizontale Skalierung eines Servers ausführen. Sie können jedoch auch eine manuelle Synchronisierung durchführen. Durch die Synchronisierung wird sichergestellt, dass die Daten auf Replikaten im Abfragepool mit den Daten im primären Server übereinstimmen. Beim Verarbeiten von (aktualisierten) Modellen auf dem primären Server ist nach dem Abschluss der Verarbeitungsvorgänge eine Synchronisierung erforderlich. Bei dieser Synchronisierung werden aktualisierte Daten aus den Dateien des primären Servers im Blobspeicher in den zweiten Datensatz kopiert. Replikate im Abfragepool werden dann mit aktualisierten Daten aus dem zweiten Datensatz im Blobspeicher aufgefüllt.
Wenn Sie einen nachfolgenden horizontalen Skalierungsvorgang ausführen und beispielsweise die Anzahl von Replikaten im Abfragepool von zwei auf fünf erhöhen, werden die neuen Replikate mit Daten aus dem zweiten Datensatz im Blobspeicher aktualisiert. Hier erfolgt keine Synchronisierung. Wenn Sie nach dem horizontalen Skalieren eine Synchronisierung durchführen, werden die neuen Replikaten im Abfragepool zweimal aufgefüllt – ein redundanter Vorgang. Bedenken Sie Folgendes, wenn Sie eine nachfolgende horizontale Skalierung durchführen:
Führen Sie vor der horizontalen Skalierung eine Synchronisierung durch, um redundante Vorgänge mit zusätzlichen Replikaten zu vermeiden. Ein gleichzeitiges Ausführen von Synchronisierung und horizontaler Skalierung ist nicht zulässig.
Beim Automatisieren von Verarbeitungs- und Skalierungsvorgängen müssen Sie zuerst die Daten auf dem primären Server verarbeiten, dann eine Synchronisierung und dann die horizontale Skalierung durchführen. So stellen Sie möglichst geringe Auswirkungen auf die Ressourcen in QPU und Arbeitsspeicher sicher.
Während horizontaler Skalierungsvorgänge sind alle Server im Abfragepool, auch der primäre Server, vorübergehend offline.
Die Synchronisierung ist auch dann zulässig, wenn keine Replikate im Abfragepool vorhanden sind. Wenn Sie mit neuen Daten aus einem Verarbeitungsvorgang auf dem primären Server von Null auf ein oder mehrere Replikate hochskalieren, führen Sie zuerst die Synchronisierung ohne Replikate im Abfragepool durch und nehmen Sie dann die horizontale Skalierung vor. Durch das Synchronisieren vor dem horizontalen Skalieren werden redundante Vorgänge mit den neu hinzugefügten Replikaten vermieden.
Wenn Sie eine Modelldatenbank auf dem primären Server löschen, wird sie nicht automatisch aus Replikaten im Abfragepool gelöscht. Sie müssen einen Synchronisierungsvorgang mit dem PowerShell-Befehl Sync-AzAnalysisServicesInstance ausführen, der die Dateien für diese Datenbank aus dem Speicherort des freigegebenen Blobs des Replikats entfernt und dann die Modelldatenbank auf den Replikaten im Abfragepool löscht. Um zu bestimmen, ob eine Modelldatenbank auf Replikaten im Abfragepool vorhanden ist, jedoch nicht auf dem primären Server, stellen Sie sicher, dass die Einstellung Verarbeitungsserver vom Abfragepool trennen auf Ja gesetzt ist. Verwenden Sie dann SQL Server Management Studio (SSMS), um mithilfe des
:rw-Qualifizierers eine Verbindung mit dem primären Server herzustellen, um herauszufinden, ob die Datenbank vorhanden ist. Stellen Sie dann eine Verbindung mit Replikaten im Abfragepool her, indem Sie eine Verbindung ohne den:rw-Qualifizierer herstellen, um zu ermitteln, ob die gleiche Datenbank ebenfalls vorhanden ist. Ist die Datenbank auf Replikaten im Abfragepool vorhanden, jedoch nicht auf dem primären Server, führen Sie einen Synchronisierungsvorgang aus.Wenn Sie eine Datenbank auf dem primären Server umbenennen, ist ein zusätzlicher Schritt erforderlich, um sicherzustellen, dass die Datenbank ordnungsgemäß mit Replikaten synchronisiert wird. Nach dem Umbenennen führen Sie eine Synchronisierung mit dem Befehl Sync-AzAnalysisServicesInstance durch. Dabei legen Sie den Parameter
-Databasemit dem alten Datenbanknamen fest. Bei dieser Synchronisierung werden die Datenbank und die Dateien mit dem alten Namen aus Replikate entfernt. Führen Sie eine weitere Synchronisierung durch. Dabei legen Sie den Parameter-Databasemit dem alten Datenbanknamen fest. Bei der zweiten Synchronisierung wird die neu benannte Datenbank in den zweiten Datensatz kopiert und alle Replikate aufgefüllt. Diese Synchronisierungen können nicht mithilfe des Befehls „Modell synchronisieren“ im Portal ausgeführt werden.
Synchronisierungsmodus
Standardmäßig werden Abfragereplikate vollständig und nicht inkrementell reaktiviert. Die Reaktivierung erfolgt in Phasen. Es werden jeweils zwei gleichzeitig getrennt und angefügt (sofern mindestens drei Replikate vorhanden sind), um sicherzustellen, dass jederzeit mindestens ein Replikat für Abfragen online ist. In einigen Fällen müssen Clients möglicherweise während der Ausführung dieses Prozesses erneut eine Verbindung mit einem der Onlinereplikate herstellen. Mithilfe der Einstellung ReplicaSyncMode können Sie nun angeben, dass die Synchronisierung der Abfragereplikate parallel erfolgen soll. Die parallele Synchronisierung bietet folgende Vorteile:
- Deutliche Verringerung der Synchronisierungszeit
- Daten in unterschiedlichen Replikaten sind während des Synchronisationsvorgang eher konsistent.
- Da Datenbanken während des Synchronisierungsprozesses für Replikate online bleiben, müssen Clients keine wiederholte Verbindung herstellen.
- Der arbeitsspeicherinterne Cache wird inkrementell nur mit den geänderten Daten aktualisiert. Dies kann schneller erfolgen als eine vollständige Reaktivierung des Modells.
Einstellung „ReplicaSyncMode“
Verwenden Sie SSMS, um ReplicaSyncMode in den erweiterten Eigenschaften festzulegen. Mögliche Werte sind:
-
1(Standard): Vollständige Reaktivierung der Replikatdatenbank in Phasen (inkrementell). -
2: Parallele Optimierung der Synchronisierung.
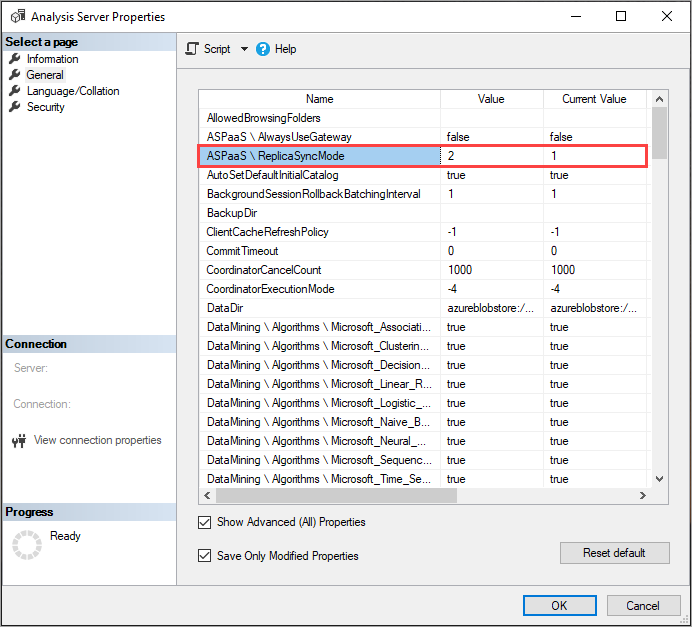
Wenn Sie ReplicaSyncMode = 2 festlegen, kann je nachdem, wie viel Cache aktualisiert werden muss, mehr Arbeitsspeicher von den Abfragereplikaten genutzt werden. Damit die Datenbank online und für Abfragen verfügbar bleibt, kann der Vorgang abhängig davon, wie viele Daten geändert wurden, bis zur doppelten Speichermenge auf dem Replikat erfordern, da sowohl alte als auch neue Segmente gleichzeitig im Arbeitsspeicher beibehalten werden. Replikatknoten verfügen über die gleiche Speicherzuordnung wie der primäre Knoten, und in der Regel ist auf dem primären Knoten zusätzlicher Arbeitsspeicher für Aktualisierungsvorgänge verfügbar. Daher ist es unwahrscheinlich, dass für die Replikate nicht genügend Arbeitsspeicher verfügbar ist. Außerdem besteht das gängigste Szenario darin, dass die Datenbank inkrementell auf dem primären Knoten aktualisiert wird, sodass die Anforderung der doppelten Speichermenge nur selten auftreten sollte. Wenn bei der Synchronisierung ein Fehler durch nicht genügend Arbeitsspeicher auftritt, wird der Vorgang mit dem Standardverfahren (Anfügen/Trennen von jeweils zwei Replikaten) erneut ausgeführt.
Getrennte Verarbeitung vom Abfragepool
Zur Optimierung der Leistung bei Verarbeitungs- und Abfragevorgängen können Sie optional Ihren Verarbeitungsserver vom Abfragepool trennen. Nach der Trennung werden neue Clientverbindungen nur den Abfragereplikaten im Abfragepool zugewiesen. Wenn Verarbeitungsvorgänge nur eine kurze Zeit dauern, können Sie Ihren Verarbeitungsserver auch nur für den Zeitraum vom Abfragepool trennen, der zur Durchführung der Verarbeitungs- und Synchronisierungsvorgänge erforderlich ist, und ihn dann wieder in den Abfragepool aufnehmen. Der Vorgang zum Trennen des Verarbeitungsservers vom Abfragepool oder zum erneuten Hinzufügen kann bis zu fünf Minuten dauern.
Überwachen der QPU-Nutzung
Überwachen Sie Ihre Server-Metriken im Azure-Portal, um zu ermitteln, ob eine horizontale Skalierung für Ihren Server erforderlich ist. Wenn regelmäßig die QPU-Obergrenze erreicht wird, übersteigt die Anzahl von Abfragen für Ihre Modelle das QPU-Limit für Ihren Tarif. Die Metrik „Warteschlangenlänge für Abfragepoolaufträge“ erhöht sich auch, wenn die Anzahl von Abfragen in der Warteschlange des Abfragethreadpools die verfügbaren QPUs übersteigt.
Eine weitere gute Metrik zum Überwachen ist die durchschnittliche QPU nach ServerResourceType. Mit dieser Metrik wird die durchschnittliche QPU für den primären Server mit dem Abfragepool verglichen.
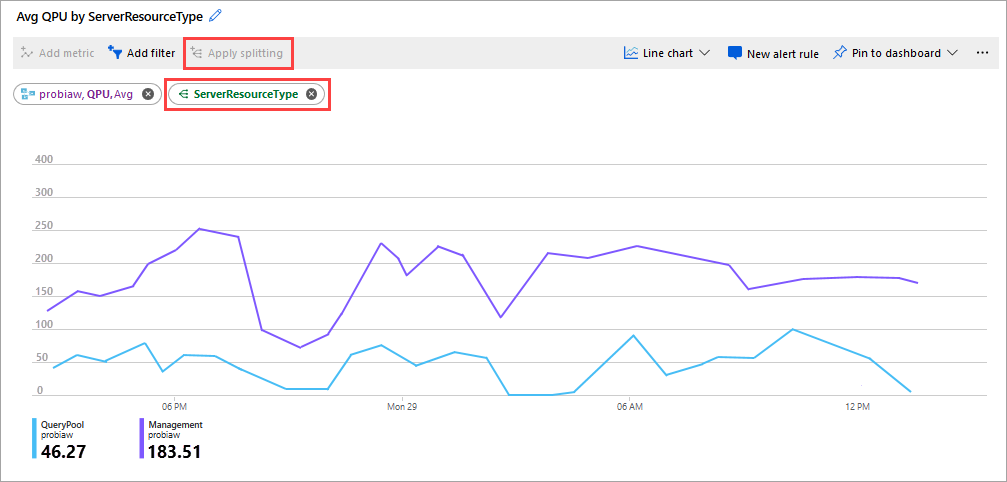
Konfigurieren von QPU nach ServerResourceType
- Klicken Sie in einem Metrik-Liniendiagramm auf Metrik hinzufügen.
- Wählen Sie unter RESSOURCE Ihren Server aus. Wählen Sie dann unter METRIKNAMESPACE die Option Standardmetriken für Analysis Services und unter METRIK die Option QPU aus, und klicken Sie unter AGGREGATION auf Durchschn.
- Klicken Sie auf Teilen anwenden.
- Wählen Sie unter WERTE die Option ServerResourceType.
Ausführliche Diagnoseprotokollierung
Verwenden Sie Azure Monitor-Protokolle für eine ausführlichere Diagnose der Serverressourcen mit horizontaler Skalierung. Bei Protokollen können Sie mithilfe von Log Analytics-Abfragen QPU und Arbeitsspeicher nach Server und Replikat unterteilen. Weitere Informationen finden Sie unter Analysieren von Protokollen im Log Analytics-Arbeitsbereich. Beispielabfragen finden Sie unter Kusto-Beispielabfragen.
Konfigurieren des horizontalen Hochskalierens
Im Azure-Portal
Klicken Sie im Portal auf Horizontale Skalierung. Wählen Sie mithilfe des Schiebereglers die Anzahl von Abfragereplikatservern aus. Die gewählte Anzahl von Replikaten kommt zu Ihrem bereits vorhandenen Server hinzu.
Klicken Sie unter Verarbeitungsserver vom Abfragepool trennen auf „Ja“, um Ihren Verarbeitungsserver von Abfrageservern auszuschließen. Clientverbindungen, die die Standardverbindungszeichenfolge (ohne
:rw) verwenden, werden an Replikate im Abfragepool umgeleitet.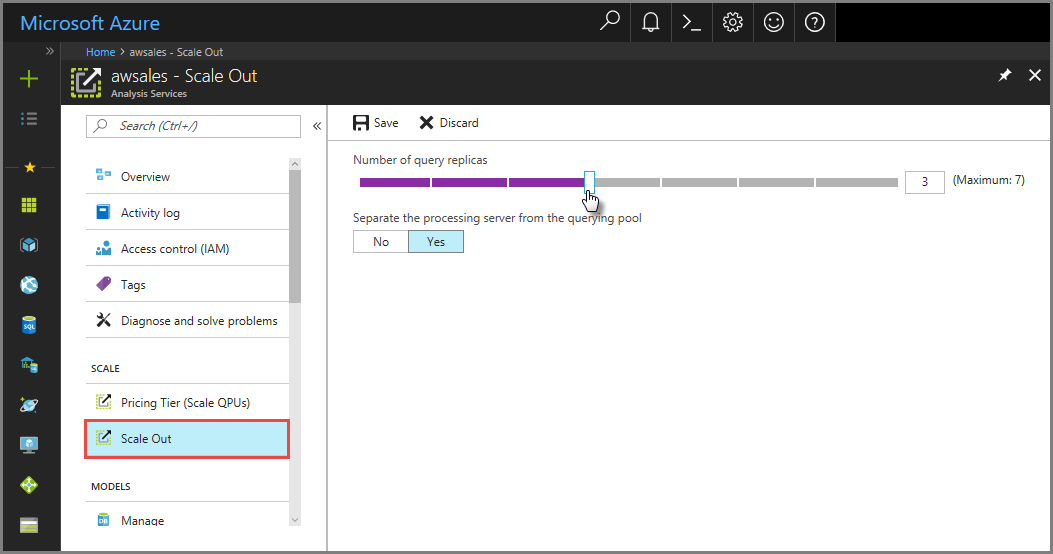
Klicken Sie auf Speichern, um Ihre neuen Abfragereplikatserver bereitzustellen.
Beim ersten Konfigurieren der horizontalen Skalierung für einen Server werden Modelle auf Ihrem primären Server automatisch mit neuen Replikaten im Abfragepool synchronisiert. Die automatische Synchronisierung erfolgt nur einmal, wenn Sie erstmals die horizontale Skalierung auf ein oder mehrere Replikate konfigurieren. Nachfolgende Änderungen an der Anzahl von Replikaten auf dem gleichen Server lösen keine weitere automatische Synchronisierung aus. Die automatische Synchronisierung wird nicht erneut ausgeführt, selbst wenn Sie den Server auf null Replikate festlegen und dann eine horizontale Skalierung auf eine bestimmte Anzahl von Replikaten vornehmen.
Synchronisieren
Synchronisierungsvorgänge müssen manuell oder mithilfe der REST-API ausgeführt werden.
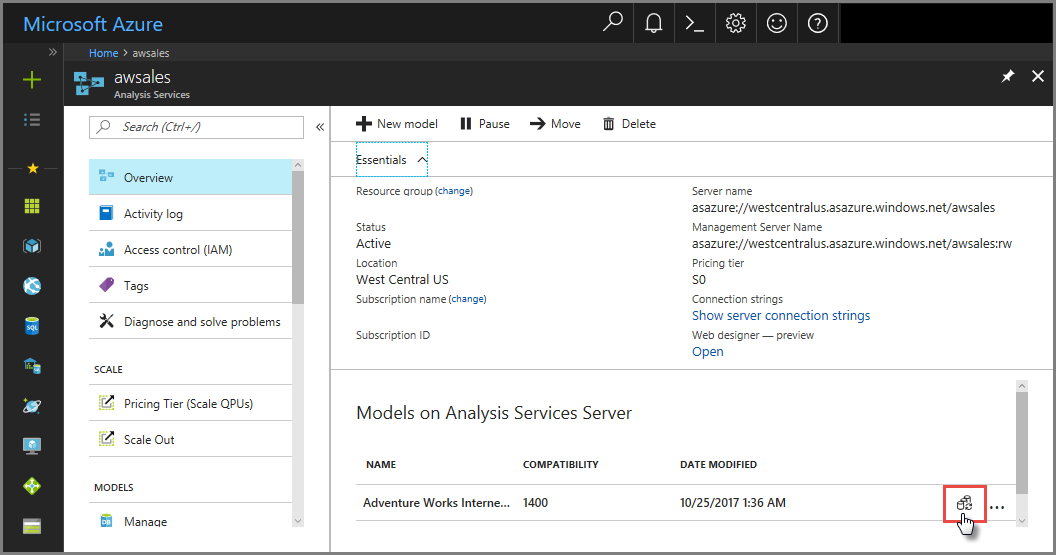
Im Azure-Portal
Klicken Sie auf Übersicht> Modell >Modell synchronisieren.
REST-API
Verwenden Sie die sync-Operation.
Synchronisieren eines Modells
POST https://<region>.asazure.windows.net/servers/<servername>:rw/models/<modelname>/sync
Abrufen des Synchronisierungsstatus
GET https://<region>.asazure.windows.net/servers/<servername>/models/<modelname>/sync
Rückgabestatuscodes:
| Code | BESCHREIBUNG |
|---|---|
| -1 | Ungültig |
| 0 | Replikation wird ausgeführt |
| 1 | Aktivierung wird ausgeführt |
| 2 | Abgeschlossen |
| 3 | Fehler |
| 4 | Ausführung wird abgeschlossen |
PowerShell
Hinweis
Es wird empfohlen, das Azure Az PowerShell-Modul für die Interaktion mit Azure zu verwenden. Informationen zu den ersten Schritten finden Sie unter Installieren von Azure PowerShell. Informationen zum Migrieren zum Az PowerShell-Modul finden Sie unter Migrieren von Azure PowerShell von AzureRM zum Az-Modul.
Vor der Verwendung von PowerShell müssen Sie das neueste Azure PowerShell-Modul installieren oder aktualisieren.
Verwenden Sie Sync-AzAnalysisServicesInstance, um die Synchronisierung auszuführen.
Verwenden Sie Set-AzAnalysisServicesServer, um die Anzahl von Abfragereplikaten festzulegen. Geben Sie den optionalen Parameter -ReadonlyReplicaCount an.
Verwenden Sie Set-AzAnalysisServicesServer, um den verarbeitenden Server vom Abfragepool zu trennen. Geben Sie den optionalen Parameter -DefaultConnectionMode an, um Readonly zu verwenden.
Weitere Informationen finden Sie unter Verwenden eines Dienstprinzipals mit dem Az.AnalysisServices-Modul.
Verbindungen
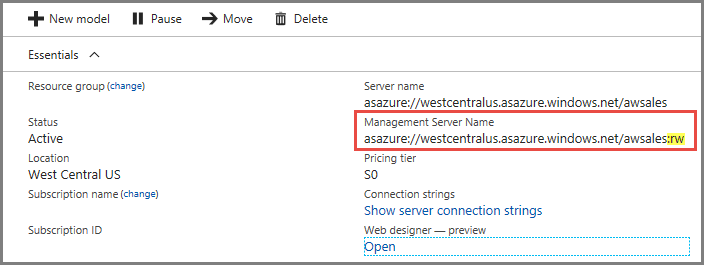
Auf der Übersichtsseite des Servers werden zwei Servernamen angezeigt. Wenn Sie noch keine horizontale Hochskalierung für einen Server konfiguriert haben, funktionieren beide Servernamen gleich. Nach dem Konfigurieren der horizontalen Hochskalierung für einen Server müssen Sie den passenden Servernamen für den jeweiligen Verbindungstyp angeben.
Für Endbenutzer-Clientverbindungen wie Power BI Desktop, Excel und benutzerdefinierte Apps muss der Servername verwendet werden.
Für SSMS, Visual Studio und Verbindungszeichenfolgen in PowerShell, Azure Functions-Apps und AMO muss der Name des Verwaltungsservers verwendet werden. Der Name des Verwaltungsservers enthält einen speziellen :rw-Qualifizierer (Lesen/Schreiben). Sämtliche Verarbeitungsvorgänge finden auf dem (primären) Verwaltungsserver statt.
Zentrales Hochskalieren, zentrales Herunterskalieren oder Horizontales Skalieren
Sie können den Tarif auf einem Server mit mehreren Replikaten ändern. Der gleiche Tarif gilt für alle Replikate. Bei einem Skalierungsvorgang werden zunächst alle Replikate gleichzeitig heruntergefahren und dann mit dem neuen Tarif gestartet.
Problembehandlung
Problem: Benutzer erhalten die Fehlermeldung Serverinstanz '<Name des Servers>' im Verbindungsmodus 'ReadOnly' nicht gefunden.
Lösung: Wenn die Option Verarbeitungsserver vom Abfragepool trennen ausgewählt wird, werden Clientverbindungen, die die Standardverbindungszeichenfolge (ohne :rw) verwenden, an Abfragepoolreplikate umgeleitet. Wenn Replikate im Abfragepool noch nicht online sind, weil die Synchronisierung noch nicht abgeschlossen ist, können umgeleitete Clientverbindungen fehlschlagen. Um Verbindungsfehler zu verhindern, müssen beim Durchführen einer Synchronisierung mindestens zwei Server im Abfragepool enthalten sein. Jeder Server wird einzeln synchronisiert, während andere Server online bleiben. Wenn der Verarbeitungsserver während der Verarbeitung nicht im Abfragepool enthalten sein soll, können Sie ihn für die Verarbeitung aus dem Pool entfernen und dann nach Abschluss der Verarbeitung, jedoch vor der Synchronisierung, wieder zum Pool hinzufügen. Verwenden Sie die Metriken „Arbeitsspeicher“ und „QPU“, um den Synchronisierungsstatus zu überwachen.
Verwandte Informationen
Überwachen von Azure Analysis ServicesVerwalten von Azure Analysis Services