Konfigurieren von Inhaltsfiltern mit Azure AI Foundry
Das in Azure AI Foundry integrierte Inhaltsfiltersystem wird zusammen mit den Kernmodellen ausgeführt, einschließlich DALL-E-Imagegenerierungsmodellen. Es verwendet ein Ensemble von Mehrklassenklassifizierungsmodellen, um vier Kategorien von schädlichen Inhalten (Gewalt, Hass, sexuelle Inhalte und Selbstverletzung) auf vier Schweregraden zu erkennen (sicher, niedrig, mittel und hoch) und optionale binäre Klassifizierer zum Erkennen von Jailbreak-Risiko, bestehendem Text und Code in öffentlichen Repositorys.
Die Standardkonfiguration für die Inhaltsfilterung ist so festgelegt, dass für alle vier Kategorien von Inhaltsschäden sowohl für Eingabeaufforderungen als auch für Vervollständigungen der Mittlere Schweregrad gefiltert wird. Dies bedeutet, dass Inhalte, die mit dem Schweregrad mittel oder hoch erkannt werden, gefiltert werden, während mit dem Schweregrad „niedrig“ erkannte Inhalte nicht ausgefiltert werden. Weitere Informationen zu den Inhaltskategorien, Schweregraden und dem Verhalten des Inhaltsfiltersystems finden Sie hier.
Jailbreak-Risikoerkennung und geschützte Text- und Codemodelle sind optional und standardmäßig aktiviert. Für Jailbreak- und geschützte Materialtext- und -codemodelle ermöglicht das Konfigurierbarkeitsfeature allen Kunden, die Modelle ein- und auszuschalten. Die Modelle sind standardmäßig aktiviert und können pro Szenario deaktiviert werden. Beachten Sie, dass einige Modelle für bestimmte Szenarien aktiviert sein müssen, um die Abdeckung im Rahmen der Verpflichtung zum Urheberrecht des Kunden beizubehalten.
Hinweis
Die Kundschaft kann die Inhaltsfilter ändern und die Schweregrad-Schwellenwerte (niedrig, mittel, hoch) konfigurieren. Die Genehmigung ist erforderlich, um die Inhaltsfilter teilweise oder vollständig zu deaktivieren. Verwaltete Kunden können nur eine vollständige Inhaltsfilterung über folgendes Formular beantragen: Azure OpenAI Limited Access Review: Geänderte Content-Filter. Zu diesem Zeitpunkt ist es nicht möglich, ein verwalteter Kunde zu werden.
Inhaltsfilter können auf der Ressourcenebene konfiguriert werden. Sobald eine neue Konfiguration erstellt wurde, kann sie einer oder mehreren Bereitstellungen zugeordnet werden. Weitere Informationen zur Modellimplementierung finden Sie im Leitfaden zur Ressourcenbereitstellung.
Voraussetzungen
- Sie müssen über eine Azure OpenAI-Ressource und eine LLM-Bereitstellung (Large Language Model) verfügen, um Inhaltsfilter zu konfigurieren. Nutzen Sie einen Schnellstart, um erste Schritte auszuführen.
Grundlegendes zur Konfigurierbarkeit von Inhaltsfiltern
Azure OpenAI Service umfasst Standardsicherheitseinstellungen, die auf alle Modelle angewandt werden, mit Ausnahme von Azure OpenAI Whisper. Diese Konfigurationen bieten Ihnen standardmäßig eine verantwortungsvolle Umgebung, die Inhaltsfiltermodelle, Blockierlisten, Prompttransformation, Inhaltsanmeldeinformationen und mehr enthält. Hier erfahren Sie mehr.
Alle Kunden können darüber hinaus Inhaltsfilter konfigurieren und benutzerdefinierte Sicherheitsrichtlinien erstellen, die auf die Anforderungen ihrer Anwendungsfälle zugeschnitten sind. Das Feature für die Konfigurierbarkeit ermöglicht Kunden, die Einstellungen separat für Prompts und Vervollständigungen anzupassen, um Inhalte für jede Inhaltskategorie mit unterschiedlichen Schweregraden zu filtern, wie in der folgenden Tabelle beschrieben. Inhalte, die mit dem Schweregrad „sicher“ erkannt werden, werden in Anmerkungen gekennzeichnet, unterliegen jedoch keiner Filterung und sind nicht konfigurierbar.
| Gefilterter Schweregrad | Konfigurierbar für Eingabeaufforderungen | Konfigurierbar für Vervollständigungen | Beschreibungen |
|---|---|---|---|
| Niedrig, mittel, hoch | Ja | Ja | Strengste Filterkonfiguration. Mit den Schweregraden „Niedrig“, „Mittel“ und „Hoch“ erkannte Inhalte werden gefiltert. |
| Mittel, Hoch | Ja | Ja | Mit dem Schweregrad „Niedrig“ erkannte Inhalte werden nicht gefiltert, Inhalte mit mittlerem und hohem Schweregrad werden gefiltert. |
| Hoch | Ja | Ja | Mit den Schweregraden „Niedrig“ und „Mittel“ erkannte Inhalte werden nicht gefiltert. Nur Inhalte mit hohem Schweregrad werden gefiltert. |
| Keine Filter | Falls genehmigt1 | Falls genehmigt1 | Unabhängig vom erkannten Schweregrad wird kein Inhalt gefiltert. Genehmigung erforderlich1. |
| Nur kommentieren | Falls genehmigt1 | Falls genehmigt1 | Deaktiviert die Filterfunktion, sodass Inhalte nicht blockiert, aber Anmerkungen über die API-Antwort zurückgegeben werden. Genehmigung erforderlich1. |
1 Bei Azure OpenAI-Modelle haben nur die Kunden uneingeschränkte Kontrolle über die Inhaltsfilterung und können Inhaltsfilter deaktivieren, die für die angepasste Inhaltsfilterung zugelassen wurden. Beantragen Sie geänderte Inhaltsfilter über dieses Formular: Azure OpenAI Limited Access Review: Modified Content Filters. Für Azure Government-Kunden beantragen Sie geänderte Inhaltsfilter über dieses Formular: Azure Government – Request Modified Content Filtering for Azure OpenAI Service.
Konfigurierbare Inhaltsfilter für Eingaben (Prompts) und Ausgaben (Vervollständigungen) stehen für alle Azure OpenAI-Modelle zur Verfügung.
Inhaltsfilterkonfigurationen werden in einer Ressource im Azure KI Foundry-Portal erstellt und können Bereitstellungen zugeordnet werden. Weitere Informationen zur Konfigurierbarkeit finden Sie hier.
Kunden sind dafür verantwortlich, sicherzustellen, dass Anwendungen, die Azure OpenAI integrieren, den Verhaltenskodex einhalten.
Grundlegendes zu anderen Filtern
Sie können die folgenden Filterkategorien zusätzlich zu den Standardfiltern für Schadenkategorien konfigurieren.
| Filterkategorie | Status | Standardeinstellung | Wird auf Eingabeaufforderung oder Abschluss angewendet? | Beschreibung |
|---|---|---|---|---|
| Prompt Shields für direkte Angriffe (Jailbreak) | Allgemein verfügbar | Ein | Eingabeaufforderung von Benutzerinnen und Benutzern | Filtert/kommentiert Benutzerprompts, die möglicherweise ein Jailbreak-Risiko darstellen. Weitere Informationen zu Anmerkungen finden Sie unter Azure AI Foundry-Inhaltsfilterung. |
| Prompt Shields für indirekte Angriffe | Allgemein verfügbar | Deaktiviert | Eingabeaufforderung von Benutzerinnen und Benutzern | Filtert/kommentiert indirekte Angriffe, die auch als indirekte Promptangriffe oder domänenübergreifende Prompteinschleusungsangriffe bezeichnet werden. Sie stellen ein potenzielles Sicherheitsrisiko dar, bei dem Dritte böswillige Anweisungen innerhalb von Dokumenten platzieren, auf die das generative KI-System zugreifen und sie verarbeiten kann. Erfordert Dokumenteinbettung und -formatierung. |
| Geschütztes Material - Code | Allgemein verfügbar | Ein | Completion | Filtert geschützten Code oder ruft die Beispielzitat- und Lizenzinformationen in Anmerkungen für Codeschnipsel ab, die mit allen öffentlichen Codequellen übereinstimmen, die von GitHub Copilot unterstützt werden. Weitere Informationen zum Verwenden von Anmerkungen finden Sie im Leitfaden zur Inhaltsfilterung |
| Geschütztes Material - Text | Allgemein verfügbar | Ein | Completion | Identifiziert bekannte Textinhalte und blockiert ihre Anzeige in der Modellausgabe (z. B. Songtexte, Rezepte und ausgewählte Webinhalte). |
| Quellenübereinstimmung* | Vorschau | Aus | Completion | Erkennt, ob die Textantworten großer Sprachmodelle (LLMs) in den Quellmaterialien basieren, die von den Benutzern bereitgestellt werden. Ungroundedness bezieht sich auf Fälle, in denen die LLMs Informationen erzeugen, die nicht sachlich oder ungenau im Bezug auf die Quellmaterialien sind. Erfordert Dokumenteinbettung und -formatierung. |
Erstellen eines Inhaltsfilters in Azure AI Foundry
Für jede Modellbereitstellung in Azure KI Foundry können Sie direkt den Standardinhaltsfilter verwenden, aber Sie sollten vielleicht mehr Kontrolle haben. So können Sie z. B. einen Filter strenger oder lascher gestalten oder erweiterte Funktionen wie Prompt Shields und die Erkennung von geschütztem Material aktivieren.
Tipp
Eine Anleitung zu Inhaltsfiltern in Ihrem Azure KI Foundry-Projekt finden Sie unter Azure KI Foundry-Inhaltsfilterung.
Führen Sie folgende Schritte aus, um einen Inhaltsfilter zu erstellen:
Wechseln Sie zu Azure AI Foundry und navigieren Sie zu Ihrem Projekt. Wählen Sie dann im linken Menü die Seite Sicherheit + Sicherheit aus und wählen Sie die Registerkarte Inhaltsfilter aus.

Wählen Sie + Inhaltsfilter erstellen aus.
Geben Sie auf der Seite Grundlegende Informationen einen Namen für die Inhaltsfilterkonfiguration ein. Wählen Sie eine Verbindung aus, die dem Inhaltsfilter zugeordnet werden soll. Wählen Sie Weiteraus.

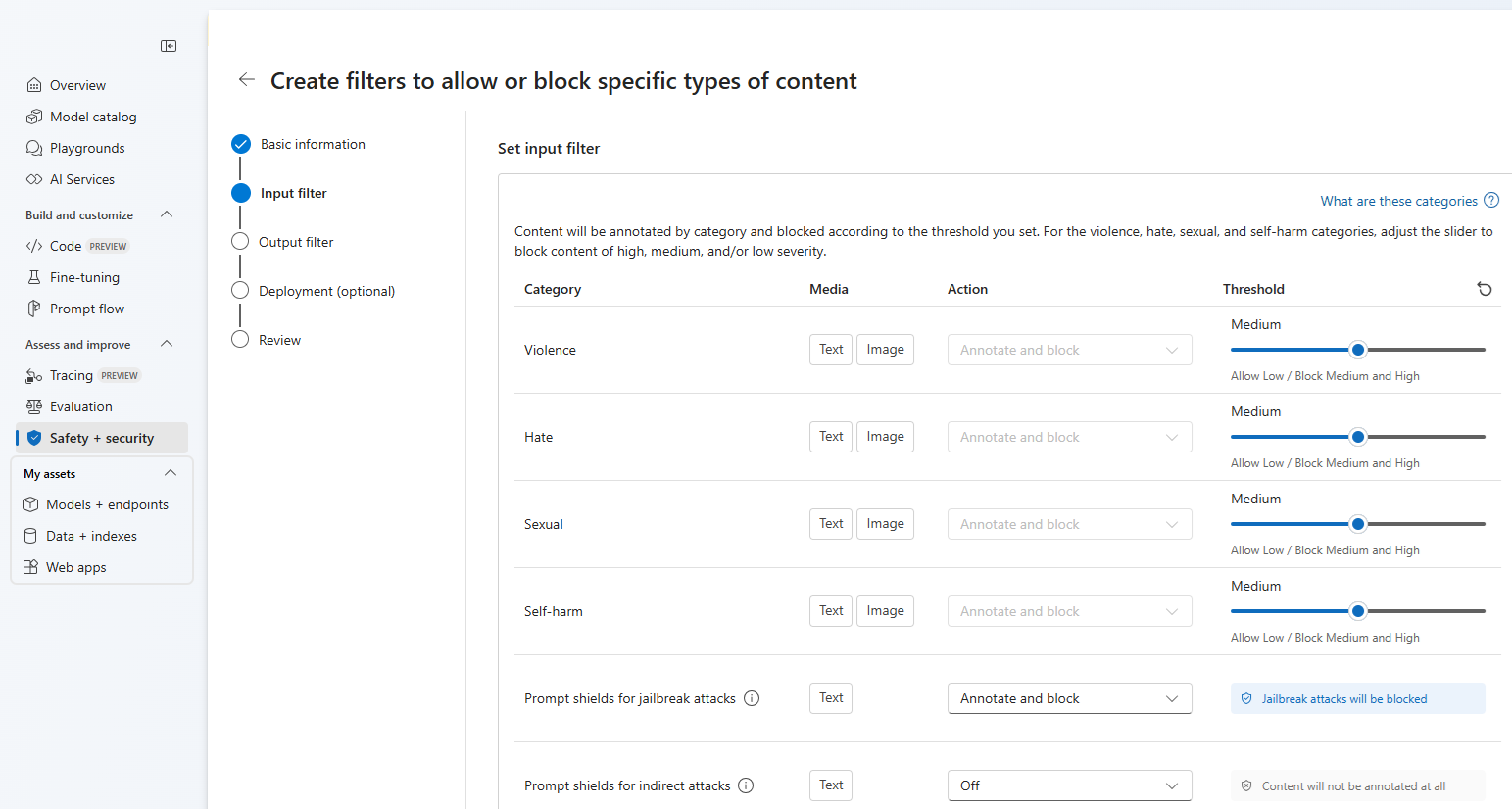
Jetzt können Sie die Eingabefilter (für Benutzerprompts) und Ausgabefilter (für die Modellvervollständigung) konfigurieren.
Auf der Seite Eingabefilter können Sie den Filter für den Eingabeprompt festlegen. Für die ersten vier Inhaltskategorien gibt es drei Schweregrade, die konfigurierbar sind: niedrig, mittel und hoch. Sie können die Schieberegler verwenden, um den Schweregradschwellenwert festzulegen, wenn Sie feststellen, dass Ihre Anwendung oder Ihr Verwendungsszenario eine andere Filterung als die Standardwerte erfordert. Mit einigen Filtern, z. B. Prompt Shields und geschützte Materialerkennung, können Sie bestimmen, ob das Modell Inhalte kommentieren und/oder blockieren soll. Wenn Sie die Option Nur kommentieren auswählen, wird das entsprechende Modell ausgeführt und die Anmerkungen werden über die API-Antwort zurückgegeben, der Inhalt wird jedoch nicht gefiltert. Zusätzlich zum Kommentieren können Sie auch Inhalte blockieren.
Wenn Ihr Anwendungsfall für geänderte Inhaltsfilter genehmigt wurde, erhalten Sie die vollständige Kontrolle über die Inhaltsfilterkonfigurationen und können die Filterung teilweise oder vollständig deaktivieren. Sie können auch das Kommentieren nur für Kategorien mit schädlichen Inhalten aktivieren (Gewalt, Hass, sexuelle Inhalte und Selbstverletzung).
Inhalte werden nach Kategorie kommentiert und entsprechend dem von Ihnen festgelegten Schwellenwert blockiert. Passen Sie den Schieberegler der Kategorien für Gewalt, Hass, Sexualität und Selbstverletzung an, um Inhalte mit hohem, mittlerem oder geringem Schweregrad zu blockieren.
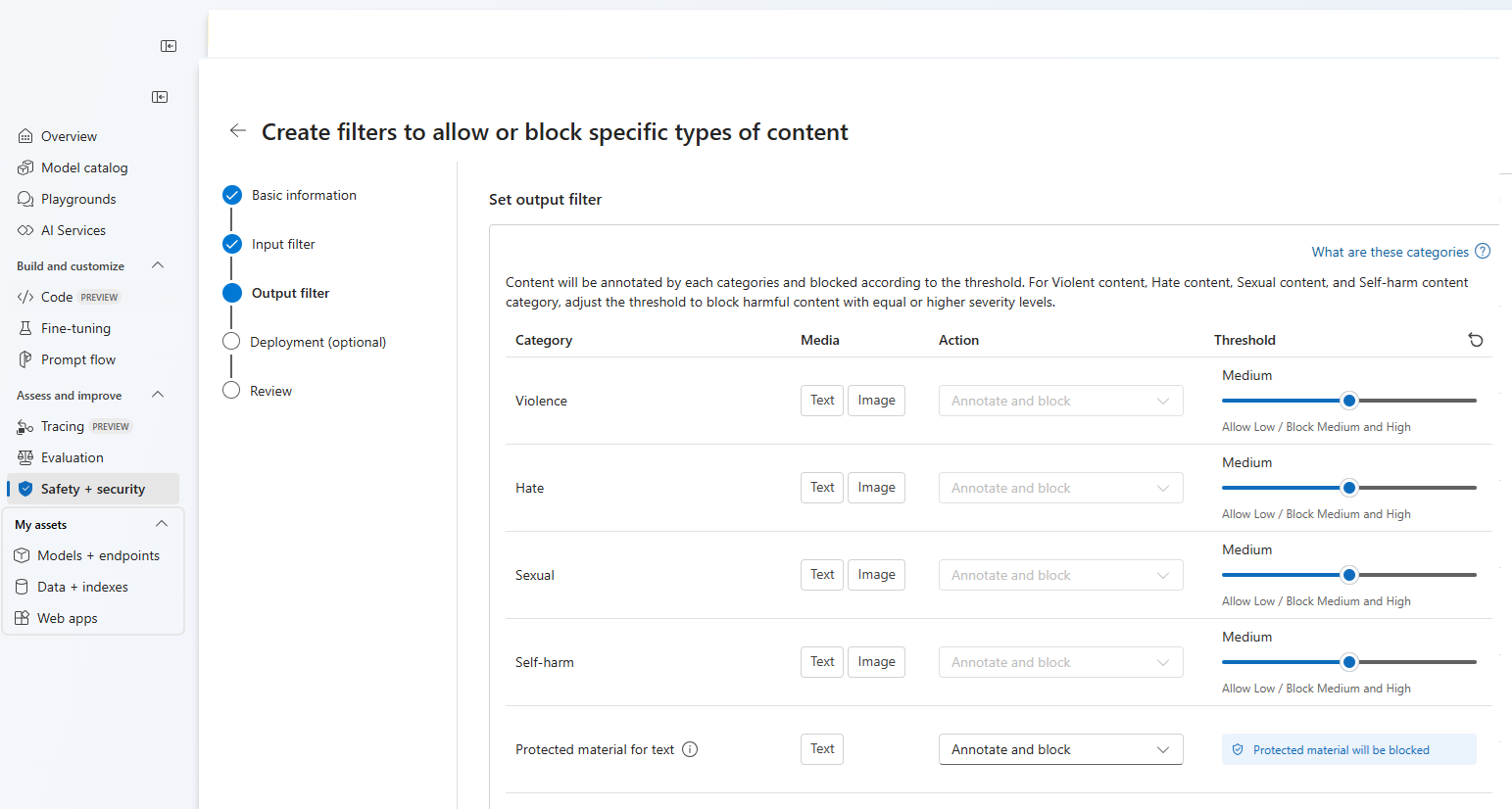
Auf der Seite Ausgabefilter können Sie den Ausgabefilter konfigurieren, der auf alle Ausgabeinhalte angewendet wird, die von Ihrem Modell generiert werden. Konfigurieren Sie die einzelnen Filter wie zuvor. Diese Seite bietet auch die Option „Streamingmodus“, mit der Sie Inhalte nahezu in Echtzeit filtern können, während sie vom Modell generiert werden, wodurch die Wartezeit reduziert wird. Wählen Sie anschließend Weiter aus.
Inhalte werden nach den einzelnen Kategorien kommentiert und entsprechend dem Schwellenwert blockiert. Passen Sie bei der Kategorie für gewalttätige Inhalte, Hassinhalte, sexuelle Inhalte und Inhalte mit Bezug auf Selbstverletzung den Schwellenwert an, um schädliche Inhalte mit gleichem oder höherem Schweregrad zu blockieren.
Optional können Sie auf der Seite Bereitstellung den Inhaltsfilter einer Bereitstellung zuordnen. Wenn eine ausgewählte Bereitstellung bereits über einen Filter verfügt, müssen Sie bestätigen, dass Sie ihn ersetzen möchten. Sie können den Inhaltsfilter auch später einer Bereitstellung zuordnen. Klicken Sie auf Erstellen.
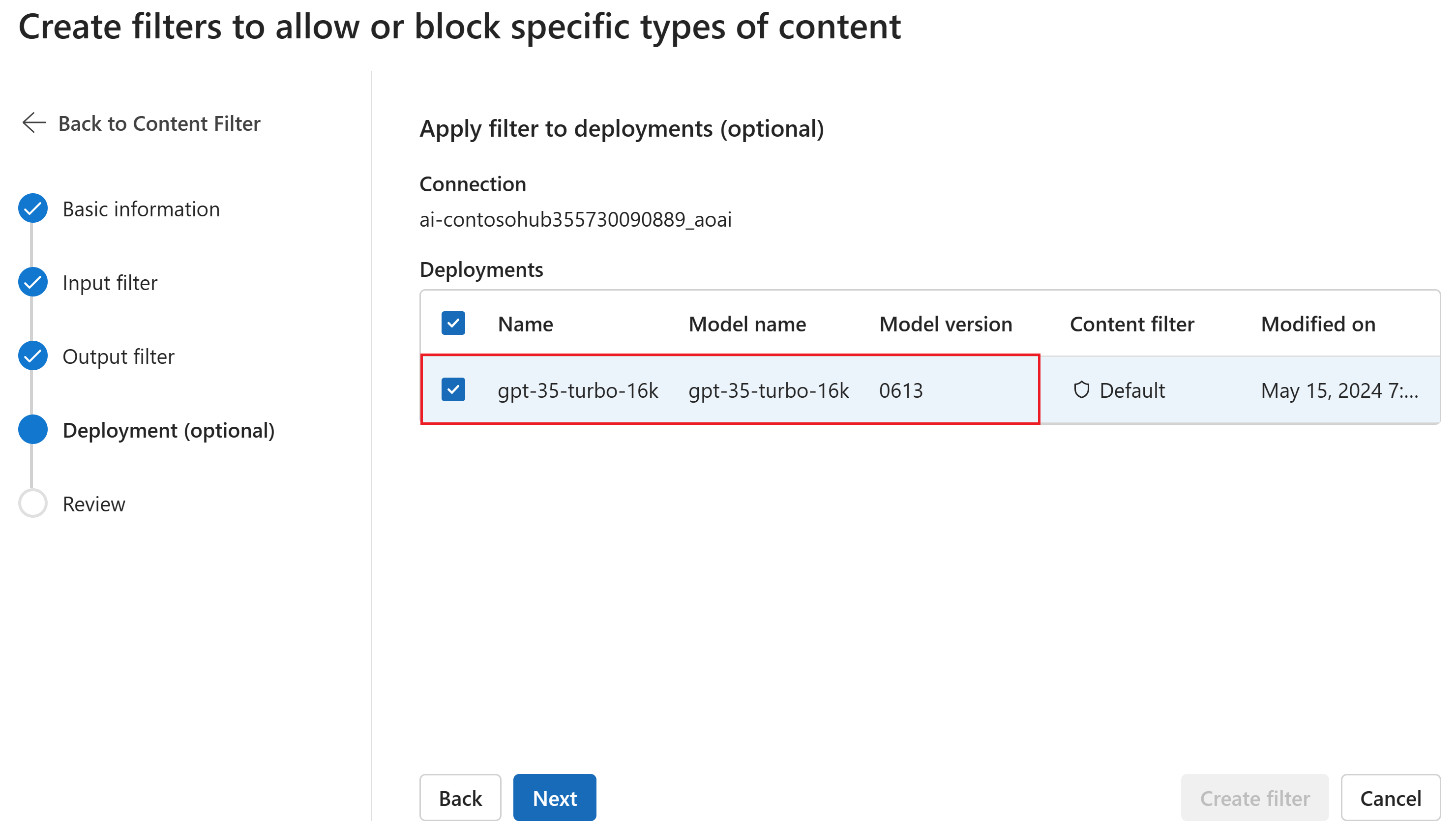
Inhaltsfilterkonfigurationen werden auf Hubebene im Azure AI Foundry-Portal erstellt. In der Azure OpenAI Service-Dokumentation erfahren Sie mehr über die Konfigurierbarkeit.
Überprüfen Sie auf der Registerkarte Überprüfen Ihre Einstellungen, und wählen Sie dann Filter erstellen aus.



Verwenden einer Blockliste als Filter
Sie können eine Sperrliste entweder als Eingabe- oder Ausgabefilter oder als beides anwenden. Aktivieren Sie die Option Sperrliste auf der Seite Eingabefilter und/oder auf der Seite Ausgabefilter. Wählen Sie eine oder mehrere Sperrlisten aus dem Dropdown-Menü aus oder verwenden Sie die integrierte Sperrliste für Obszönitäten. Sie können mehrere Sperrlisten im selben Filter kombinieren.
Anwenden eines Inhaltsfilters
Der Prozess der Filtererstellung bietet Ihnen die Möglichkeit, den Filter auf die gewünschten Bereitstellungen anzuwenden. Sie können Inhaltsfilter auch jederzeit ändern oder aus Ihren Bereitstellungen entfernen.
Führen Sie die folgenden Schritte aus, um einen Inhaltsfilter auf eine Bereitstellung anzuwenden:
Wechseln Sie zu Azure AI Foundry und wählen Sie ein Projekt aus.
Wählen Sie Modelle + Endpunkte im linken Bereich und dann eine Ihrer Bereitstellungen aus, und wählen Sie dann Bearbeiten aus.

Wählen Sie im Fenster Bereitstellung aktualisieren den Inhaltsfilter aus, den Sie auf die Bereitstellung anwenden möchten. Wählen Sie dann Speichern und schließen aus.

Sie können bei Bedarf eine Inhaltsfilterkonfiguration auch bearbeiten und löschen. Bevor Sie eine Inhaltsfilterkonfiguration löschen, müssen Sie die Zuweisung für jede Bereitstellung auf der Registerkarte Bereitstellungen aufheben und ersetzen.


Jetzt können Sie zum Playground wechseln, um zu testen, ob der Inhaltsfilter wie erwartet funktioniert.
Feedback zur Inhaltsfilterung
Wenn ein Problem mit der Inhaltsfilterung auftritt, wählen Sie oben im Playground die Schaltfläche Feedback zu Filtern aus. Dies ist im Playground für Bilder, Chat und Vervollständigungen aktiviert, sobald Sie einen Prompt übermitteln.
Wenn das Dialogfeld angezeigt wird, wählen Sie das entsprechende Problem mit der Inhaltsfilterung aus. Geben Sie möglichst viele Details zum Problem mit der Inhaltsfilterung an, z. B. den spezifischen Fehler bei der Prompt- und Inhaltsfilterung. Schließen Sie keine privaten oder vertraulichen Informationen ein.
Wenn Sie Unterstützung benötigen, erstellen Sie ein Supportticket.
Bewährte Methoden befolgen
Wir empfehlen, Ihre Entscheidungen zur Konfiguration der Inhaltsfilterung durch einen iterativen Identifizierungs- (z. B. Red-Team-Tests, Stresstests und Analysen) und Messprozess zu unterstützen, um für ein bestimmtes Modell, eine bestimmte Anwendung und ein bestimmtes Einsatzszenario relevante potenzielle Schäden zu ermitteln. Wiederholen Sie nach der Implementierung von Risikominderungen wie Inhaltsfilterung die Messung, um ihre Effektivität zu testen. Empfehlungen und bewährte Methoden für Verantwortungsvolle KI für Azure OpenAI, die auf dem Microsoft Responsible AI Standard basiert, finden Sie in der Übersicht über verantwortungsvolle KI für Azure OpenAI.
Zugehöriger Inhalt
- Erfahren Sie mehr über Verantwortungsvolle KI-Methoden für Azure OpenAI: Übersicht über verantwortungsvolle KI-Methoden für Azure OpenAI-Modelle.
- Erfahren Sie mehr über Inhaltsfilterkategorien und Schweregrade mit Azure AI Foundry.
- Erfahren Sie mehr über Rote Teams in unserem Artikel: Einführung in das Red Teaming großer Sprachmodelle (LLMs).