Erstellen von Projekten für die benutzerdefinierte Textklassifizierung
Artikel
In diesem Artikel erfahren Sie, wie Sie die Anforderungen einrichten, um mit der benutzerdefinierten Textklassifizierung zu beginnen, und ein Projekt erstellen.
Voraussetzungen
Bevor Sie mit der Verwendung der benutzerdefinierten Textklassifizierung beginnen, benötigen Sie Folgendes:
Bevor Sie mit der Verwendung der benutzerdefinierten Textklassifizierung beginnen, benötigen Sie eine Azure KI Language-Ressource. Es wird empfohlen, Ihre Sprachressource zu erstellen und ein Speicherkonto im Azure-Portal damit zu verknüpfen. Wenn Sie eine Ressource im Azure-Portal erstellen, können Sie gleichzeitig ein Azure-Speicherkonto erstellen, wobei alle erforderlichen Berechtigungen vorkonfiguriert sind. Sie können in diesem Artikel auch weiterlesen, um zu erfahren, wie Sie eine bereits vorhandene Ressource verwenden und für die Verwendung mit der benutzerdefinierten Textklassifizierung konfigurieren können.
Darüber hinaus benötigen Sie ein Azure-Speicherkonto, in das Sie Ihre .txt-Dokumente hochladen, die zum Trainieren eines Modells zum Klassifizieren von Text verwendet werden sollen.
Hinweis
Ihnen muss die Rolle Besitzer für die Ressourcengruppe zugewiesen sein, damit Sie eine Sprachressource erstellen können.
Wenn Sie eine Verbindung mit einem vorhandenen Speicherkonto herstellen, sollte ihm die Rolle Besitzer zugewiesen sein.
Erstellen von Sprachressourcen und Verbinden eines Speicherkontos
Hinweis
Sie sollten das Speicherkonto nicht in eine andere Ressourcengruppe oder ein Abonnement verschieben, nachdem sie mit der Sprachressource verknüpft wurde.
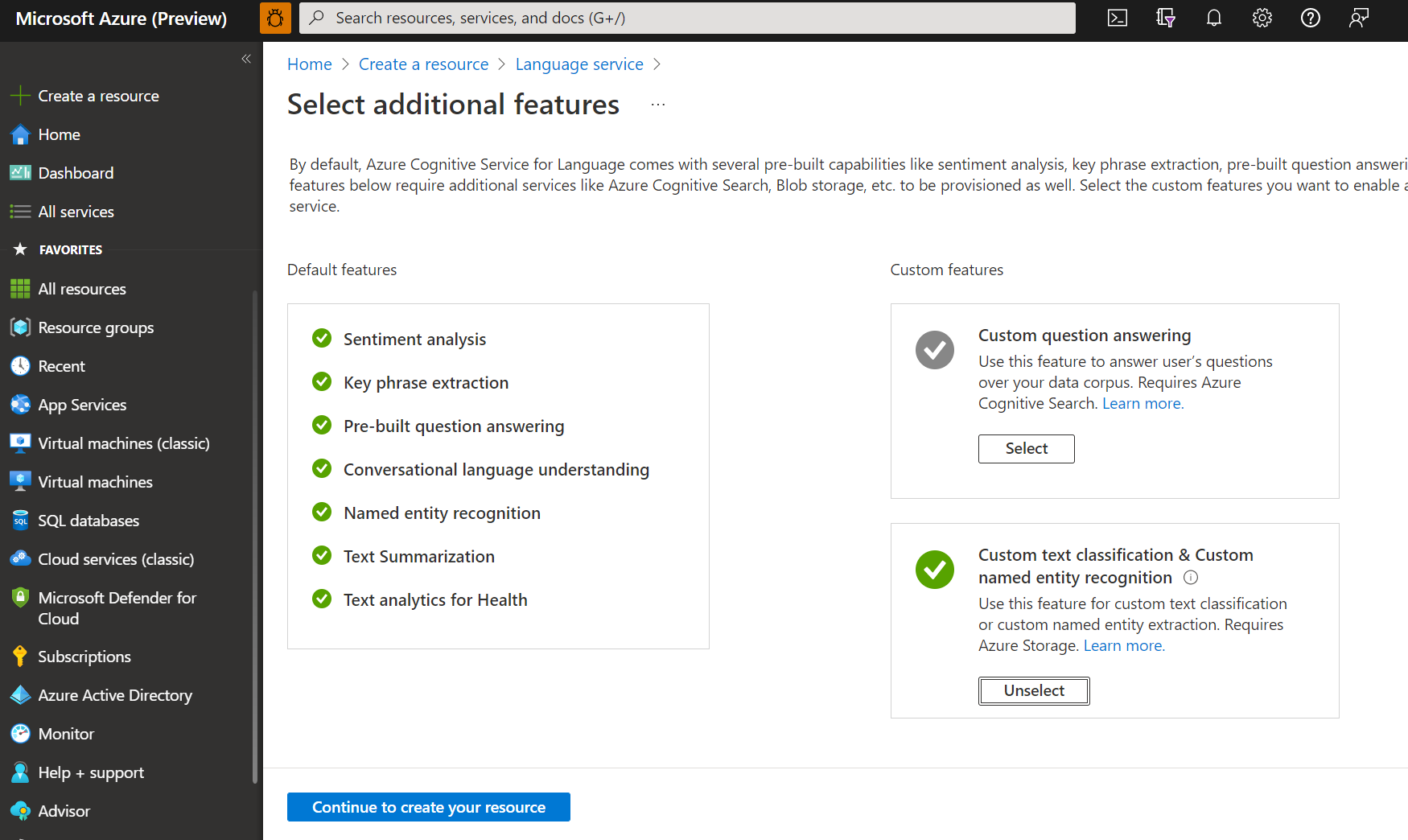
Wechseln Sie zum Azure-Portal, um eine neue Azure KI Language-Ressource zu erstellen.
Wählen Sie im angezeigten Fenster in den benutzerdefinierten Features Benutzerdefinierte Textklassifizierung und benutzerdefinierte Erkennung benannter Entitäten aus. Wählen Sie unten auf dem Bildschirm Erstellung Ihrer Ressource fortsetzen aus.
Erstellen Sie eine Sprachressource mit den folgenden Details:
Name
Erforderlicher Wert
Subscription
Ihr Azure-Abonnement.
Ressourcengruppe
Eine Ressourcengruppe, die Ihre Ressource enthält. Sie können eine vorhandene verwenden oder eine neue erstellen.
Einer der unterstützten Preistarife. Sie können den kostenlosen Tarif (F0) verwenden, um den Dienst auszuprobieren.
Wenn Sie in einer Meldung darauf hingewiesen werden, dass Ihr Anmeldekonto kein Besitzer der Ressourcengruppe des ausgewählten Speicherkontos ist, muss Ihrem Konto eine Besitzerrolle für die Ressourcengruppe zugewiesen werden, bevor Sie eine Sprachressource erstellen können. Wenden Sie sich an den Besitzer des Azure-Abonnements, um Unterstützung zu erhalten.
Sie können den Besitzer Ihres Azure-Abonnements ermitteln, indem Sie Ihre Ressourcengruppe durchsuchen und dem Link zum zugehörigen Abonnement folgen. Führen Sie anschließend Folgendes durch:
Wählen Sie die Registerkarte Zugriffssteuerung (IAM) aus
Wählen Sie Rollenzuweisungen aus
Filtern Sie nach Rolle:Besitzer.
Wählen Sie im Abschnitt Benutzerdefinierte Textklassifizierung und benutzerdefinierte Erkennung benannter Entitäten ein vorhandenes Speicherkonto aus, oder wählen Sie Neues Speicherkonto aus. Beachten Sie, dass Ihnen diese Werte den Einstieg erleichtern sollen und nicht unbedingt die Speicherkontowerte darstellen, die in Produktionsumgebungen verwendet werden sollten. Um Wartezeit beim Erstellen Ihres Projekts zu vermeiden, sollten Sie eine Verbindung mit Speicherkonten in derselben Region herstellen, in der sich auch Ihre Sprachressource befindet.
Speicherkontowert
Empfohlener Wert
Speicherkontoname
Beliebiger Name
Speicherkontotyp
Standardmäßiger LRS
Stellen Sie sicher, dass die verantwortungsvolle KI-Benachrichtigung überprüft wird. Wählen Sie am unteren Rand der Seite die Option Bewerten + erstellen aus.
Erstellen einer neuen Sprachressource über Language Studio
Wenn Sie sich zum ersten Mal anmelden, wird in Language Studio ein Fenster angezeigt, in dem Sie eine vorhandene Sprachressource auswählen oder eine neue erstellen können. Sie können eine Ressource auch erstellen, indem Sie auf das Einstellungssymbol in der oberen rechten Ecke klicken, Ressourcen auswählen und dann auf Neue Ressource erstellen klicken.
Erstellen Sie eine Sprachressource mit den folgenden Details:
Instanzdetails
Erforderlicher Wert
Azure-Abonnement
Ihr Azure-Abonnement
Azure-Ressourcengruppe
Ihre Azure-Ressourcengruppe
Name der Azure-Ressource
Ihr Azure-Ressourcenname
Standort
Die Region, in der sich Ihre Sprachressource befindet
Achten Sie darauf, dass Sie Verwaltete Identität aktivieren, wenn Sie eine Sprachressource erstellen.
Lesen und Bestätigen des Hinweises zu verantwortungsvoller KI
Damit Sie benutzerdefinierte Textklassifizierung verwenden können, müssen Sie Ihre Ressource mit einem Speicherkonto verbinden. Erstellen Sie ein Azure-Speicherkonto, wenn Sie noch keins besitzen. Führen Sie die folgenden Schritte aus, um Ihr erstes Projekt zu erstellen und Ihr Speicherkonto zu verbinden.
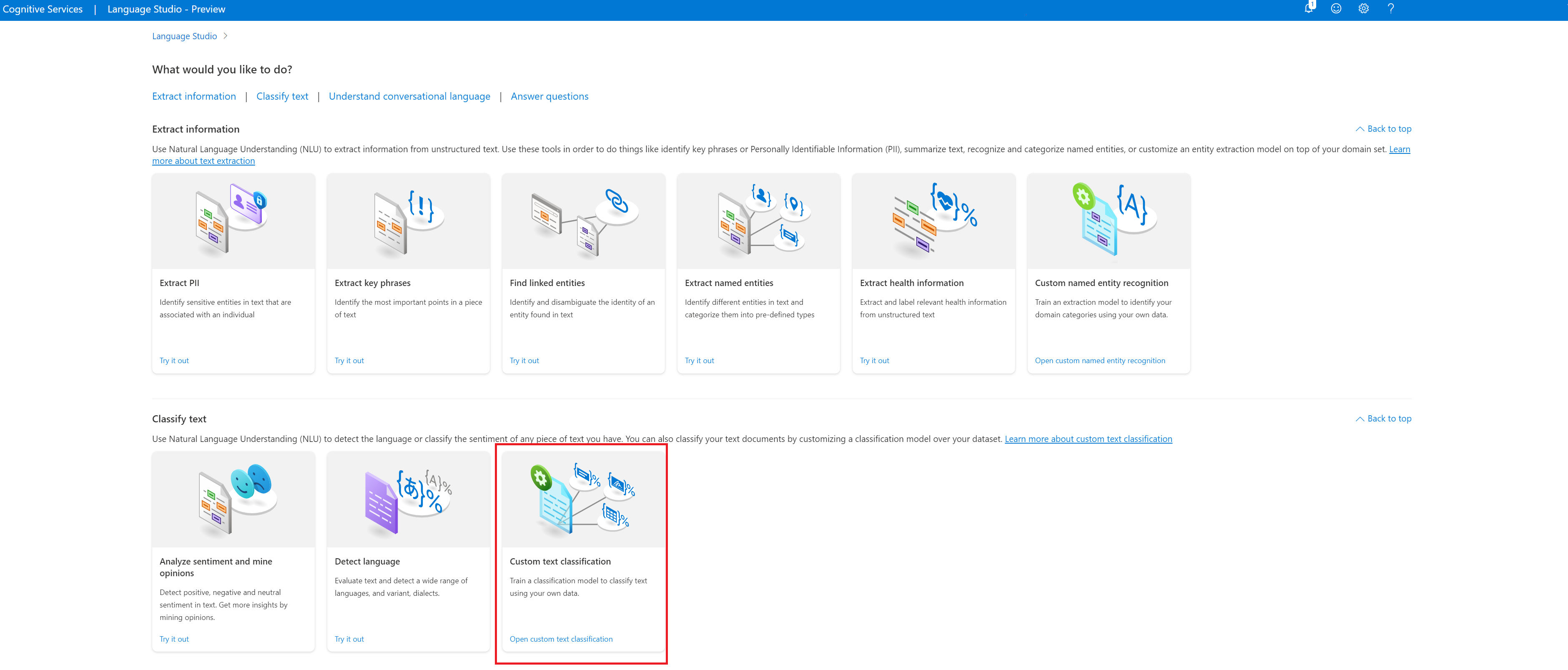
Melden Sie sich bei Language Studio an. Es wird ein Fenster angezeigt, in dem Sie Ihr Abonnement und Ihre Sprachressource auswählen können. Wählen Sie Ihre Sprachressource aus.
Wählen Sie im Abschnitt Text klassifizieren von Language Studio die Option Custom text classification aus.
Wählen Sie im oberen Menü Ihrer Projektseite Neues Projekt erstellen aus. Durch das Erstellen eines Projekts können Sie Daten bezeichnen sowie Ihre Modelle trainieren, auswerten, verbessern und bereitstellen.
Nachdem Sie auf Neues Projekt erstellen geklickt haben, wird ein Fenster angezeigt, in dem Sie eine Verbindung mit Ihrem Speicherkonto herstellen können. Wenn Sie bereits ein Speicherkonto verbunden haben, wird das verbundene Speicherkonto angezeigt. Falls nicht, wählen Sie Ihr Speicherkonto im angezeigten Dropdownmenü aus, und klicken Sie auf Speicherkonto verbinden. Dadurch werden die erforderlichen Rollen für Ihr Speicherkonto festgelegt. Dieser Schritt gibt möglicherweise einen Fehler zurück, wenn Sie nicht als Besitzer des Speicherkontos zugewiesen sind.
Hinweis
Sie müssen diesen Schritt nur einmal für jede neue Sprachressource durchführen, die Sie verwenden.
Dieser Prozess kann nicht rückgängig gemacht werden – wenn Sie ein Speicherkonto mit Ihrer Sprachressource verbinden, können Sie die Verbindung später nicht trennen.
Sie können Ihre Sprachressource nur mit einem Speicherkonto verbinden.
Wählen Sie den Projekttyp aus. Sie können entweder ein Projekt für die Klassifizierung mit mehreren Bezeichnungen erstellen, bei dem jedes Dokument zu einer oder mehreren Klassen gehören kann. Alternativ können Sie ein Projekt für die Klassifizierung mit einer einzelnen Bezeichnung erstellen, bei dem jedes Dokument nur einer Klasse zugewiesen werden kann. Der ausgewählte Typ kann später nicht geändert werden. Erfahren Sie mehr über die Projekttypen.
Geben Sie die Projektinformationen ein, einschließlich eines Namens, einer Beschreibung und der Sprache der Dokumente in Ihrem Projekt. Wenn Sie das Beispieldataset verwenden, wählen Sie Englisch aus. Sie können den Namen Ihres Projekts später nicht mehr ändern. Wählen Sie Weiter aus.
Tipp
Ihr Dataset muss nicht zur Gänze in derselben Sprache vorliegen. Sie können mehrere Dokumente verwenden, jedes mit jeweils anderen unterstützten Sprachen. Wenn Ihr Dataset Dokumente in verschiedenen Sprachen enthält oder Sie zur Laufzeit mit Text mit verschiedenen Sprachen rechnen, wählen Sie die Option Mehrsprachiges Dataset aktivieren aus, wenn Sie die grundlegenden Informationen für Ihr Projekt eingeben. Diese Option kann später auf der Seite Projekteinstellungen aktiviert werden.
Wählen Sie den Container aus, in den Sie Ihr Dataset hochgeladen haben.
Hinweis
Wenn Sie Ihre Daten bereits beschriftet haben, stellen Sie sicher, dass sie dem unterstützten Format entsprechen, und wählen Sie Ja, meine Dokumente sind bereits beschriftet, und ich habe die JSON-Bezeichnungsdatei formatiert aus. Wählen Sie die Bezeichnungsdatei im unten angezeigten Dropdownmenü aus.
Wenn Sie eins der Beispieldatasets verwenden, verwenden Sie die enthaltene JSON-Datei webOfScience_labelsFile oder movieLabels. Wählen Sie Weiteraus.
Überprüfen Sie die eingegebenen Daten, und wählen Sie Projekt erstellen aus.
Sie können eine neue Ressource und ein Speicherkonto mithilfe der folgenden CLI-Vorlage und Parameterdateien erstellen, die auf GitHub gehostet werden.
Bearbeiten Sie die folgenden Werte in der Parameterdatei:
Parametername
Wertbeschreibung
name
Name Ihrer Sprachressource
location
Die Region, in der Ihre Ressource gehostet wird. Weitere Informationen finden Sie unter Unterstützung für Regionen.
sku
Der Tarif Ihrer Ressource. Weitere Informationen finden Sie unter Diensteinschränkungen.
Der Prozess zum Verbinden eines Speicherkontos mit Ihrer Sprachressource kann nicht rückgängig gemacht werden. Die Verbindung kann später nicht getrennt werden.
Sie können Ihre Sprachressource nur mit einem Speicherkonto verbinden.
Verwenden einer bereits vorhandenen Sprachressource
Anforderung
BESCHREIBUNG
Regions
Stellen Sie sicher, dass Ihre vorhandene Ressource in einer der unterstützten Regionen bereitgestellt wird. Wenn Sie keine Ressource haben, müssen Sie eine neue Ressource in einer unterstützten Region erstellen.
Stellen Sie sicher, dass die Einstellung für die verwaltete Identität der Ressource aktiviert ist. Lesen Sie andernfalls den nächsten Abschnitt.
Falls Sie noch nicht über ein Konto verfügen, müssen Sie ein Azure-Speicherkonto erstellen, um die benutzerdefinierte Textklassifizierung zu verwenden.
Aktivieren der Identitätsverwaltung für Ihre Ressource
Für Ihre Sprachressource muss Identitätsverwaltung aktiviert sein. Aktivieren Sie sie wie folgt über das Azure-Portal:
Navigieren Sie zu Ihrer Sprachressource.
Wählen Sie im Menü auf der linken Seite unter Ressourcenverwaltung die Option Identität aus.
Legen Sie auf der Registerkarte Systemseitig zugewiesen die Option Status unbedingt auf Ein fest.
Für Ihre Sprachressource muss Identitätsverwaltung aktiviert sein. Aktivieren Sie sie wie folgt über Language Studio:
Auswählen des Einstellungssymbols in der rechten oberen Ecke des Bildschirms
Wählen Sie Ressourcen aus.
Aktivieren Sie das Kontrollkästchen Verwaltete Identität für Ihre Azure KI Language-Ressource.
Aktivieren des Features für benutzerdefinierte Textklassifizierung
Aktivieren Sie unbedingt das Feature Benutzerdefinierte Textklassifizierung/Benutzerdefinierte benannte Entitätserkennung im Azure-Portal.
Navigieren Sie im Azure-Portal zu Ihrer Sprachressource.
Wählen Sie im Menü auf der linken Seite im Abschnitt Ressourcenverwaltung die Option Features aus.
Aktivieren Sie das Feature Benutzerdefinierte Textklassifizierung/Benutzerdefinierte benannte Entitätserkennung.
Herstellen einer Verbindung mit Ihrem Speicherkonto
Wählen Sie Übernehmen aus.
Wichtig
Vergewissern Sie sich, dass Ihrer Sprachressource die Rolle Mitwirkender an Storage-Blobdaten für das Speicherkonto zugewiesen ist, mit dem Sie eine Verbindung herstellen.
Festlegen von Rollen für Ihre Azure KI Language-Ressource und Ihr Speicherkonto
Führen Sie die folgenden Schritte aus, um die erforderlichen Rollen für Ihr Sprachressource und Ihr Speicherkonto festzulegen.
Rollen für Ihre Azure KI Language-Ressource
Wechseln Sie im Azure-Portal zu Ihrem Speicherkonto oder Ihrer Sprachressource.
Wählen Sie im linken Navigationsmenü Access Control (IAM) aus.
Wählen Sie Hinzufügen aus, um Rollenzuweisungen hinzuzufügen, und wählen Sie dann die entsprechende Rolle für Ihr Konto aus.
Ihnen sollte die Rolle Besitzer oder Mitwirkender für Ihre Sprachressource zugewiesen sein.
Wählen Sie unter Zugriff zuweisen zu die Option Benutzer, Gruppe oder Dienstprinzipal aus.
Wählen Sie Mitglieder auswählen aus.
Wählen Sie Ihren Benutzernamen aus. Sie können im Feld Auswählen nach Benutzernamen suchen. Wiederholen Sie diesen Vorgang für alle Rollen.
Wiederholen Sie diese Schritte für alle Benutzerkonten, die Zugriff auf diese Ressource benötigen.
Rollen für Ihr Speicherkonto
Navigieren Sie im Azure-Portal zu Ihrem Speicherkonto.
Wählen Sie im linken Navigationsmenü Access Control (IAM) aus.
Wählen Sie Hinzufügen aus, um Rollenzuweisungen hinzuzufügen, und wählen Sie dann die Rolle Mitwirkender an Storage-Blobdaten für das Speicherkonto aus.
Wählen Sie unter Zugriff zuweisen zu die Option Verwaltete Identität aus.
Wählen Sie Mitglieder auswählen aus.
Wählen Sie Ihr Abonnement und Sprache als verwaltete Identität aus. Sie können im Feld Auswählen nach Benutzernamen suchen.
Wichtig
Wenn Sie über ein virtuelles Netzwerk oder einen privaten Endpunkt verfügen, achten Sie darauf, Azure-Diensten auf der Liste der vertrauenswürdigen Dienste den Zugriff auf dieses Speicherkonto erlauben im Azure-Portal zu aktivieren.
Aktivieren von CORS für Ihr Speicherkonto
Achten Sie darauf, Methoden (GET, PUT, DELETE) zuzulassen, wenn Sie CORS (Cross-Origin Resource Sharing) aktivieren.
Legen Sie das Feld „Zulässige Ursprünge“ auf https://language.cognitive.azure.com fest. Lassen Sie alle Header zu, indem Sie den Werten für zulässige Header * hinzufügen, und legen Sie das maximale Alter auf 500 fest.
Erstellen eines Projekts zur benutzerdefinierten Textklassifizierung
Nachdem Ihre Ressource und der Speichercontainer konfiguriert wurden, erstellen Sie ein neues benutzerdefiniertes Textklassifizierungsprojekt. Ein Projekt ist ein Arbeitsbereich zum Erstellen Ihrer benutzerdefinierten KI-Modelle auf der Grundlage Ihrer Daten. Auf Ihr Projekt können nur Sie und andere Personen zugreifen, die Zugriff auf die verwendete Azure-Ressource haben. Wenn Sie beschriftete Daten haben, können Sie sie importieren, um zu beginnen.
Melden Sie sich bei Language Studio an. Es wird ein Fenster angezeigt, in dem Sie Ihr Abonnement und Ihre Sprachressource auswählen können. Wählen Sie Ihre Sprachressource aus.
Wählen Sie im Abschnitt Text klassifizieren von Language Studio die Option Custom text classification aus.
Wählen Sie im oberen Menü Ihrer Projektseite Neues Projekt erstellen aus. Durch das Erstellen eines Projekts können Sie Daten bezeichnen sowie Ihre Modelle trainieren, auswerten, verbessern und bereitstellen.
Nachdem Sie auf Neues Projekt erstellen geklickt haben, wird ein Fenster angezeigt, in dem Sie eine Verbindung mit Ihrem Speicherkonto herstellen können. Wenn Sie bereits ein Speicherkonto verbunden haben, wird das verbundene Speicherkonto angezeigt. Falls nicht, wählen Sie Ihr Speicherkonto im angezeigten Dropdownmenü aus, und klicken Sie auf Speicherkonto verbinden. Dadurch werden die erforderlichen Rollen für Ihr Speicherkonto festgelegt. Dieser Schritt gibt möglicherweise einen Fehler zurück, wenn Sie nicht als Besitzer des Speicherkontos zugewiesen sind.
Hinweis
Sie müssen diesen Schritt nur einmal für jede neue Sprachressource durchführen, die Sie verwenden.
Dieser Prozess kann nicht rückgängig gemacht werden – wenn Sie ein Speicherkonto mit Ihrer Sprachressource verbinden, können Sie die Verbindung später nicht trennen.
Sie können Ihre Sprachressource nur mit einem Speicherkonto verbinden.
Wählen Sie den Projekttyp aus. Sie können entweder ein Projekt für die Klassifizierung mit mehreren Bezeichnungen erstellen, bei dem jedes Dokument zu einer oder mehreren Klassen gehören kann. Alternativ können Sie ein Projekt für die Klassifizierung mit einer einzelnen Bezeichnung erstellen, bei dem jedes Dokument nur einer Klasse zugewiesen werden kann. Der ausgewählte Typ kann später nicht geändert werden. Erfahren Sie mehr über die Projekttypen.
Geben Sie die Projektinformationen ein, einschließlich eines Namens, einer Beschreibung und der Sprache der Dokumente in Ihrem Projekt. Wenn Sie das Beispieldataset verwenden, wählen Sie Englisch aus. Sie können den Namen Ihres Projekts später nicht mehr ändern. Wählen Sie Weiter aus.
Tipp
Ihr Dataset muss nicht zur Gänze in derselben Sprache vorliegen. Sie können mehrere Dokumente verwenden, jedes mit jeweils anderen unterstützten Sprachen. Wenn Ihr Dataset Dokumente in verschiedenen Sprachen enthält oder Sie zur Laufzeit mit Text mit verschiedenen Sprachen rechnen, wählen Sie die Option Mehrsprachiges Dataset aktivieren aus, wenn Sie die grundlegenden Informationen für Ihr Projekt eingeben. Diese Option kann später auf der Seite Projekteinstellungen aktiviert werden.
Wählen Sie den Container aus, in den Sie Ihr Dataset hochgeladen haben.
Hinweis
Wenn Sie Ihre Daten bereits beschriftet haben, stellen Sie sicher, dass sie dem unterstützten Format entsprechen, und wählen Sie Ja, meine Dokumente sind bereits beschriftet, und ich habe die JSON-Bezeichnungsdatei formatiert aus. Wählen Sie die Bezeichnungsdatei im unten angezeigten Dropdownmenü aus.
Wenn Sie eins der Beispieldatasets verwenden, verwenden Sie die enthaltene JSON-Datei webOfScience_labelsFile oder movieLabels. Wählen Sie Weiteraus.
Überprüfen Sie die eingegebenen Daten, und wählen Sie Projekt erstellen aus.
Um mit der Erstellung eines benutzerdefinierten Textklassifizierungsmodells zu beginnen, müssen Sie ein Projekt erstellen. Durch das Erstellen eines Projekts können Sie Daten bezeichnen sowie Ihre Modelle trainieren, auswerten, verbessern und bereitstellen.
Hinweis
Beim Projektnamen wird bei allen Vorgängen die Groß-/Kleinschreibung beachtet.
Erstellen Sie eine PATCH-Anforderung mithilfe der folgenden URL, Header und des JSON-Texts, um Ihr Projekt zu erstellen.
Anforderungs-URL
Verwenden Sie die folgende URL, um ein Projekt zu erstellen. Ersetzen Sie die folgenden Platzhalter durch Ihre eigenen Werte.
Der Name für Ihr Projekt. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet.
myProject
{API-VERSION}
Die Version der von Ihnen aufgerufenen API. Der hier referenzierte Wert gilt für die neueste veröffentlichte Version. Weitere Informationen zu anderen verfügbaren API-Versionen finden Sie unter Modelllebenszyklus.
2022-05-01
Header
Verwenden Sie den folgenden Header, um Ihre Anforderung zu authentifizieren.
Schlüssel
Wert
Ocp-Apim-Subscription-Key
Der Schlüssel für Ihre Ressource. Wird für die Authentifizierung Ihrer API-Anforderungen verwendet.
Body
Verwenden Sie den folgenden JSON-Code in Ihrer Anforderung. Ersetzen Sie die folgenden Platzhalter durch Ihre eigenen Werte.
Der Name des Projekts. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet.
myProject
language
{LANGUAGE-CODE}
Eine Zeichenfolge, die den Sprachcode für die in Ihrem Projekt verwendeten Dokumente angibt. Wählen Sie bei einem mehrsprachigen Projekt den Sprachcode für die Sprache aus, die in den meisten der Dokumente verwendet wird. Weitere Informationen zu unterstützten Sprachcodes finden Sie unter Sprachunterstützung.
en-us
projectKind
customMultiLabelClassification
Die Art Ihres Projekts
customMultiLabelClassification
multilingual
true
Ein boolescher Wert, der es ermöglicht, dass Ihr Dataset Dokumente in mehreren Sprachen enthält. Wenn Ihr Modell bereitgestellt wird, können Sie das Modell in jeder unterstützten Sprache abfragen (nicht unbedingt in Ihren Trainingsdokumenten enthalten). Informationen zur Unterstützung mehrerer Sprachen finden Sie unter Sprachunterstützung.
true
storageInputContainerName
{CONTAINER-NAME}
Dies ist der Name Ihres Azure-Speichercontainers, in den Sie Ihre Dokumente hochgeladen haben.
Der Name des Projekts. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet.
myProject
language
{LANGUAGE-CODE}
Eine Zeichenfolge, die den Sprachcode für die in Ihrem Projekt verwendeten Dokumente angibt. Wählen Sie bei einem mehrsprachigen Projekt den Sprachcode für die Sprache aus, die in den meisten der Dokumente verwendet wird. Weitere Informationen zu unterstützten Sprachcodes finden Sie unter Sprachunterstützung.
en-us
projectKind
customSingleLabelClassification
Die Art Ihres Projekts
customSingleLabelClassification
multilingual
true
Ein boolescher Wert, der es ermöglicht, dass Ihr Dataset Dokumente in mehreren Sprachen enthält. Wenn Ihr Modell bereitgestellt wird, können Sie das Modell in jeder unterstützten Sprache abfragen (nicht unbedingt in Ihren Trainingsdokumenten enthalten). Informationen zur Unterstützung mehrerer Sprachen finden Sie unter Sprachunterstützung.
true
storageInputContainerName
{CONTAINER-NAME}
Dies ist der Name Ihres Azure-Speichercontainers, in dem Sie Ihre Dokumente hochgeladen haben.
myContainer
Diese Anforderung gibt die Antwort 201 zurück, was bedeutet, dass das Projekt erstellt wurde.
Diese Anforderung gibt in diesem Fall einen Fehler zurück:
Die ausgewählte Ressource verfügt nicht über die richtige Berechtigung für das Speicherkonto.
Importieren eines Projekts zur benutzerdefinierten Textklassifizierung
Wenn Sie bereits beschriftete Daten haben, können Sie sie verwenden, um mit dem Dienst zu beginnen. Achten Sie darauf, dass Ihre Daten dem akzeptierten Datenformat entsprechen.
Melden Sie sich bei Language Studio an. Es wird ein Fenster angezeigt, in dem Sie Ihr Abonnement und Ihre Sprachressource auswählen können. Wählen Sie Ihre Sprachressource aus.
Wählen Sie im Abschnitt Text klassifizieren von Language Studio die Option Custom text classification aus.
Wählen Sie im oberen Menü Ihrer Projektseite Neues Projekt erstellen aus. Durch das Erstellen eines Projekts können Sie Daten bezeichnen sowie Ihre Modelle trainieren, auswerten, verbessern und bereitstellen.
Nachdem Sie Neues Projekt erstellen ausgewählt haben,wird ein Bildschirm angezeigt, auf dem Sie eine Verbindung mit Ihrem Speicherkonto herstellen können. Wenn Sie Ihr Speicherkonto nicht finden können, vergewissern Sie sich, dass Sie beim Erstellen der Ressource die empfohlenen Schritte durchgeführt haben. Wenn Sie bereits ein Speicherkonto mit Ihrer Sprachressource verbunden haben, wird Ihr verbundenes Speicherkonto angezeigt.
Hinweis
Sie müssen diesen Schritt nur einmal für jede neue Sprachressource durchführen, die Sie verwenden.
Dieser Prozess kann nicht rückgängig gemacht werden – wenn Sie ein Speicherkonto mit Ihrer Sprachressource verbinden, können Sie die Verbindung später nicht trennen.
Sie können Ihre Sprachressource nur mit einem Speicherkonto verbinden.
Wählen Sie den Projekttyp aus. Sie können entweder ein Projekt für die Klassifizierung mit mehreren Bezeichnungen erstellen, bei dem jedes Dokument zu einer oder mehreren Klassen gehören kann. Alternativ können Sie ein Projekt für die Klassifizierung mit einer einzelnen Bezeichnung erstellen, bei dem jedes Dokument nur einer Klasse zugewiesen werden kann. Der ausgewählte Typ kann später nicht geändert werden.
Geben Sie die Projektinformationen ein, einschließlich eines Namens, einer Beschreibung und der Sprache der Dokumente in Ihrem Projekt. Sie können den Namen Ihres Projekts später nicht mehr ändern. Wählen Sie Weiter aus.
Tipp
Ihr Dataset muss nicht zur Gänze in derselben Sprache vorliegen. Sie können mehrere Dokumente verwenden, jedes mit jeweils anderen unterstützten Sprachen. Wenn Ihr Dataset Dokumente in verschiedenen Sprachen enthält oder Sie zur Laufzeit mit Text mit verschiedenen Sprachen rechnen, wählen Sie die Option Mehrsprachiges Dataset aktivieren aus, wenn Sie die grundlegenden Informationen für Ihr Projekt eingeben. Diese Option kann später auf der Seite Projekteinstellungen aktiviert werden.
Wählen Sie den Container aus, in den Sie Ihr Dataset hochgeladen haben.
Wählen Sie Ja, meine Dokumente sind bereits bezeichnet, und ich habe die JSON-Bezeichnungsdatei formatiert. und dann die Bezeichnungsdatei im unten angegebenen Dropdownmenü aus, um Ihre Datei mit JSON-Bezeichnungen zu importieren. Achten Sie darauf, dass sie dem unterstützten Format entspricht.
Wählen Sie Weiter aus.
Überprüfen Sie die eingegebenen Daten, und wählen Sie Projekt erstellen aus.
Übermitteln Sie eine POST-Anforderung mithilfe der folgenden URL, der Header und des JSON-Texts, um Ihre Bezeichnungsdatei zu importieren. Stellen Sie sicher, dass die Bezeichnungsdatei dem akzeptierten Format entspricht.
Wenn bereits ein Projekt mit demselben Namen existiert, werden die Daten dieses Projekts ersetzt.
Der Name für Ihr Projekt. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet.
myProject
{API-VERSION}
Die Version der von Ihnen aufgerufenen API. Der hier referenzierte Wert gilt für die neueste veröffentlichte Version. Weitere Informationen zu anderen verfügbaren API-Versionen finden Sie hier.
2022-05-01
Header
Verwenden Sie den folgenden Header, um Ihre Anforderung zu authentifizieren.
Schlüssel
Wert
Ocp-Apim-Subscription-Key
Der Schlüssel für Ihre Ressource. Wird für die Authentifizierung Ihrer API-Anforderungen verwendet.
Body
Verwenden Sie den folgenden JSON-Code in Ihrer Anforderung. Ersetzen Sie die folgenden Platzhalter durch Ihre eigenen Werte.
Die Version der von Ihnen aufgerufenen API. Die hier verwendete Version muss mit der API-Version in der URL identisch sein. Weitere Informationen zu anderen verfügbaren API-Versionen finden Sie hier.
2022-05-01
projectName
{PROJECT-NAME}
Der Name des Projekts. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet.
myProject
projectKind
customMultiLabelClassification
Die Art Ihres Projekts
customMultiLabelClassification
language
{LANGUAGE-CODE}
Eine Zeichenfolge, die den Sprachcode für die in Ihrem Projekt verwendeten Dokumente angibt. Wählen Sie bei einem mehrsprachigen Projekt den Sprachcode für die Sprache aus, die in den meisten der Dokumente verwendet wird. Informationen zur Unterstützung mehrerer Sprachen finden Sie unter Sprachunterstützung.
en-us
multilingual
true
Ein boolescher Wert, der es ermöglicht, dass Ihr Dataset Dokumente in mehreren Sprachen enthält. Wenn Ihr Modell bereitgestellt wird, können Sie das Modell in jeder unterstützten Sprache abfragen (nicht unbedingt in Ihren Trainingsdokumenten enthalten). Informationen zur Unterstützung mehrerer Sprachen finden Sie unter Sprachunterstützung.
true
storageInputContainerName
{CONTAINER-NAME}
Dies ist der Name Ihres Azure-Speichercontainers, in den Sie Ihre Dokumente hochgeladen haben.
myContainer
Klassen
[]
Hierbei handelt es sich um ein Array mit allen Klassen, die im Projekt enthalten sind. Dies sind die Klassen, denen Sie Ihre Dokumente zuordnen möchten.
[]
Dokumente
[]
Dies ist ein Array, das alle Dokumente in Ihrem Projekt und die für dieses Dokument beschrifteten Klassen enthält.
[]
location
{DOCUMENT-NAME}
Dies ist der Speicherort der Dokumente im Speichercontainer. Da sich alle Dokumente im Stammverzeichnis des Containers befinden, sollte dies der Dokumentname sein.
doc1.txt
dataset
{DATASET}
Dies ist der Testsatz, in den dieses Dokument bei der Aufteilung vor dem Training aufgenommen wird. Weitere Informationen zur Datenteilung finden Sie unter Trainieren eines Modells. Mögliche Werte für dieses Feld sind Train und Test.
Die Version der von Ihnen aufgerufenen API. Die hier verwendete Version muss mit der API-Version in der URL identisch sein.
2022-05-01
projectName
{PROJECT-NAME}
Der Name des Projekts. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet.
myProject
projectKind
customSingleLabelClassification
Die Art Ihres Projekts
customSingleLabelClassification
language
{LANGUAGE-CODE}
Eine Zeichenfolge, die den Sprachcode für die in Ihrem Projekt verwendeten Dokumente angibt. Wählen Sie bei einem mehrsprachigen Projekt den Sprachcode für die Sprache aus, die in den meisten der Dokumente verwendet wird. Weitere Informationen zu unterstützten Sprachcodes finden Sie unter Sprachunterstützung.
en-us
multilingual
true
Ein boolescher Wert, der es ermöglicht, dass Ihr Dataset Dokumente in mehreren Sprachen enthält. Wenn Ihr Modell bereitgestellt wird, können Sie das Modell in jeder unterstützten Sprache abfragen (nicht unbedingt in Ihren Trainingsdokumenten enthalten). Informationen zur Unterstützung mehrerer Sprachen finden Sie unter Sprachunterstützung.
true
storageInputContainerName
{CONTAINER-NAME}
Dies ist der Name Ihres Azure-Speichercontainers, in den Sie Ihre Dokumente hochgeladen haben.
myContainer
Klassen
[]
Hierbei handelt es sich um ein Array mit allen Klassen, die im Projekt enthalten sind. Dies sind die Klassen, denen Sie Ihre Dokumente zuordnen möchten.
[]
Dokumente
[]
Dies ist ein Array mit allen Dokumenten in Ihrem Projekt und Angaben dazu, zu welcher Klasse dieses Dokument gehört.
[]
location
{DOCUMENT-NAME}
Dies ist der Speicherort der Dokumente im Speichercontainer. Da sich alle Dokumente im Stammverzeichnis des Containers befinden, sollte dies der Dokumentname sein.
doc1.txt
dataset
{DATASET}
Dies ist der Testsatz, in den dieses Dokument bei der Aufteilung vor dem Training aufgenommen wird. Weitere Informationen zur Datenteilung finden Sie unter Trainieren eines Modells. Mögliche Werte für dieses Feld sind Train und Test.
Train
Nachdem Sie Ihre API-Anforderung gesendet haben, erhalten Sie eine Antwort vom Typ 202, die angibt, dass der Auftrag ordnungsgemäß übermittelt wurde. Extrahieren Sie in den Antwortheadern den operation-location-Wert. Er weist das folgende Format auf:
{JOB-ID} wird verwendet, um Ihre Anforderung zu identifizieren, da es sich um einen asynchronen Vorgang handelt. Sie verwenden diese URL, um den Status des Importauftrags abzurufen.
Mögliche Fehlerszenarios für diese Anforderung:
Die ausgewählte Ressource verfügt nicht über die richtigen Berechtigungen für das Speicherkonto.
Das angegebene storageInputContainerName-Element ist nicht vorhanden.
Ein ungültiger Sprachcode wird verwendet, oder der Sprachcodetyp ist keine Zeichenfolge.
Der Wert multilingual ist eine Zeichenfolge und kein boolescher Wert.
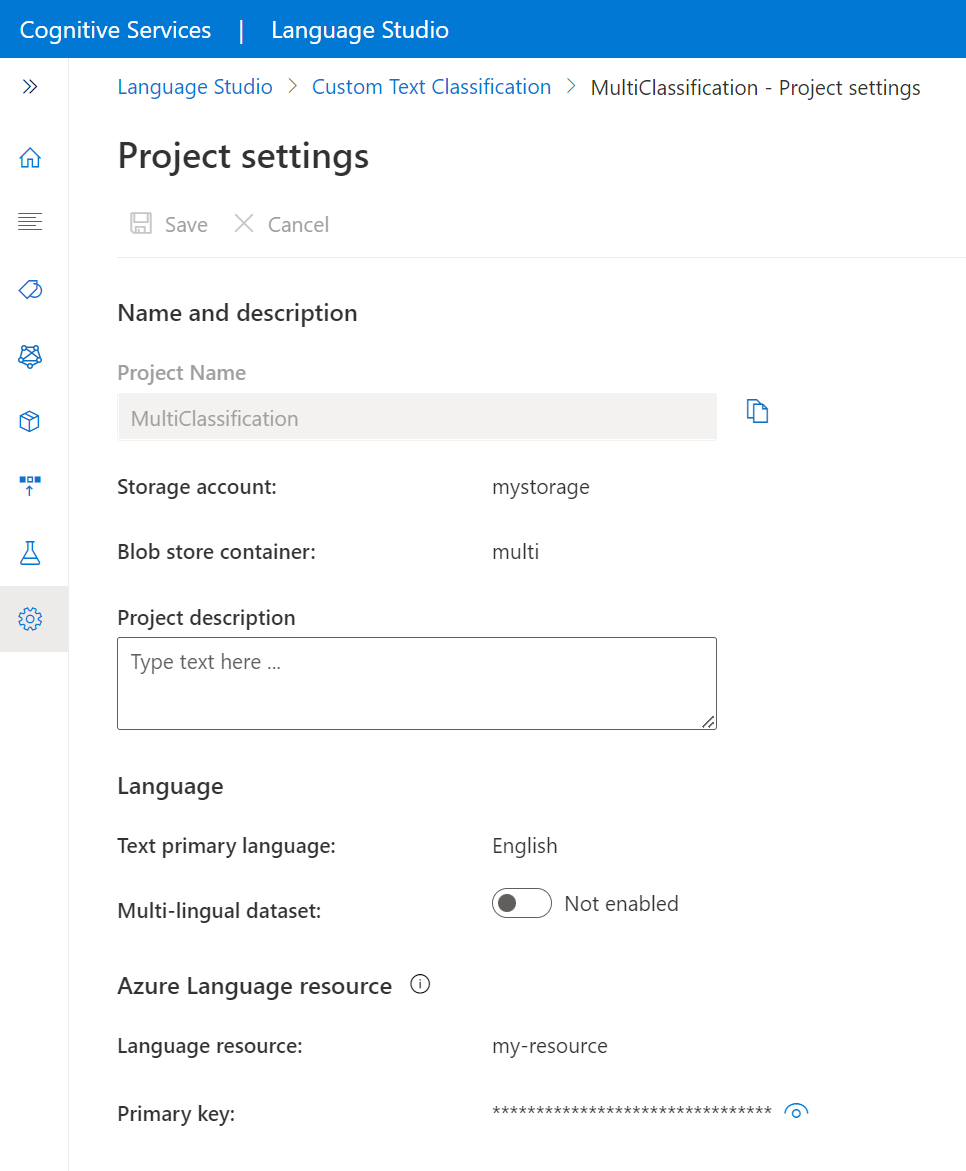
Navigieren Sie in Language Studio zur Seite mit den Projekteinstellungen.
Sie können Projektdetails anzeigen.
Auf dieser Seite können Sie in den Projekteinstellungen die Projektbeschreibung aktualisieren und das mehrsprachige Dataset aktivieren/deaktivieren.
Sie können auch das verbundene Speicherkonto und den Container Ihrer Sprachressource anzeigen.
Außerdem können Sie auf dieser Seite den Primärschlüssel der Ressource abrufen.
Wenn Sie Details zum Projekt zur benutzerdefinierten Textklassifizierung abrufen möchten, übermitteln Sie mithilfe der folgenden URL und Header eine GET-Anforderung. Ersetzen Sie die Platzhalterwerte durch eigene Werte.
Mögliche Werte sind customSingleLabelClassification oder customMultiLabelClassification.
storageInputContainerName
{CONTAINER-NAME}
Der Name Ihres Azure-Speichercontainers, in den Sie Ihre Dokumente hochgeladen haben
myContainer
projectName
{PROJECT-NAME}
Der Name des Projekts. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet.
myProject
multilingual
Ein boolescher Wert, der es ermöglicht, dass Ihr Dataset Dokumente in mehreren Sprachen enthält. Wenn Ihr Modell bereitgestellt wird, können Sie das Modell in jeder unterstützten Sprache abfragen (nicht unbedingt in Ihren Trainingsdokumenten enthalten). Weitere Informationen zur Unterstützung mehrerer Sprachen finden Sie unter Sprachunterstützung.
true
language
{LANGUAGE-CODE}
Eine Zeichenfolge, die den Sprachcode für die in Ihrem Projekt verwendeten Dokumente angibt. Wählen Sie bei einem mehrsprachigen Projekt den Sprachcode für die Sprache aus, die in den meisten der Dokumente verwendet wird. Weitere Informationen zu unterstützten Sprachcodes finden Sie unter Sprachunterstützung.
en-us
Nachdem Sie Ihre API-Anforderung gesendet haben, erhalten Sie eine Antwort vom Typ 200, die angibt, dass die Anforderung erfolgreich war, sowie den JSON-Antworttext mit Ihren Projektdetails.
Wenn Sie Ihr Projekt nicht mehr benötigen, können Sie das Projekt mithilfe von Language Studio löschen. Wählen Sie oben Benutzerdefinierte Textklassifizierung und anschließend das Projekt aus, das Sie löschen möchten. Wählen Sie im oberen Menü Löschen aus, um das Projekt zu löschen.
Wenn Sie Ihr Projekt nicht mehr benötigen, können Sie es mit der folgenden DELETE-Anforderung löschen. Ersetzen Sie die Platzhalterwerte durch eigene Werte.
Der Name für Ihr Projekt. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet.
myProject
{API-VERSION}
Die Version der von Ihnen aufgerufenen API. Der hier referenzierte Wert gilt für die neueste veröffentlichte Version. Weitere Informationen zu anderen verfügbaren API-Versionen finden Sie hier.
2022-05-01
Header
Verwenden Sie den folgenden Header, um Ihre Anforderung zu authentifizieren.
Schlüssel
Wert
Ocp-Apim-Subscription-Key
Der Schlüssel für Ihre Ressource. Wird für die Authentifizierung Ihrer API-Anforderungen verwendet.
Nachdem Sie Ihre API-Anforderung gesendet haben, erhalten Sie eine Antwort vom Typ 202, die anzeigt, dass Ihr Projekt erfolgreich gelöscht wurde. Ein erfolgreicher Aufruf enthält einen Operation-Location-Header, mit dem der Auftragsstatus überprüft wird.
Nächste Schritte
Sie sollten eine Vorstellung von dem Projektschema haben, das Sie zum Bezeichnen Ihrer Daten verwenden werden.
Nachdem das Projekt erstellt wurde, können Sie mit dem Bezeichnen Ihrer Daten beginnen, wodurch Ihr Textklassifizierungsmodell darüber informiert wird, wie Text interpretiert wird, und für das Training und die Auswertung verwendet wird.