Generieren von Einbettungen mit Azure KI-Modellinferenz
Wichtig
Die in diesem Artikel markierten Elemente (Vorschau) sind aktuell als öffentliche Vorschau verfügbar. Diese Vorschauversion wird ohne Vereinbarung zum Servicelevel bereitgestellt und sollte nicht für Produktionsworkloads verwendet werden. Manche Features werden möglicherweise nicht unterstützt oder sind nur eingeschränkt verwendbar. Weitere Informationen finden Sie unter Zusätzliche Nutzungsbestimmungen für Microsoft Azure-Vorschauen.
In diesem Artikel wird erläutert, wie Sie die Einbettungs-API bei Modellen verwenden, die in Azure KI-Modellinferenz in Azure KI Services bereitgestellt werden.
Voraussetzungen
Um Einbettungsmodelle in Ihrer Anwendung zu verwenden, benötigen Sie Folgendes:
Ein Azure-Abonnement. Wenn Sie GitHub-Modelle verwenden, können Sie Ihre Erfahrung upgraden und während dem Prozess ein Azure-Abonnement erstellen. Lesen Sie in diesem Fall Upgrade von GitHub-Modellen auf die Azure KI-Modellinferenz.
Eine Azure KI Services-Ressource. Weitere Informationen finden Sie unter Erstellen einer Azure KI Services-Ressource.
Endpunkt-URL und -Schlüssel
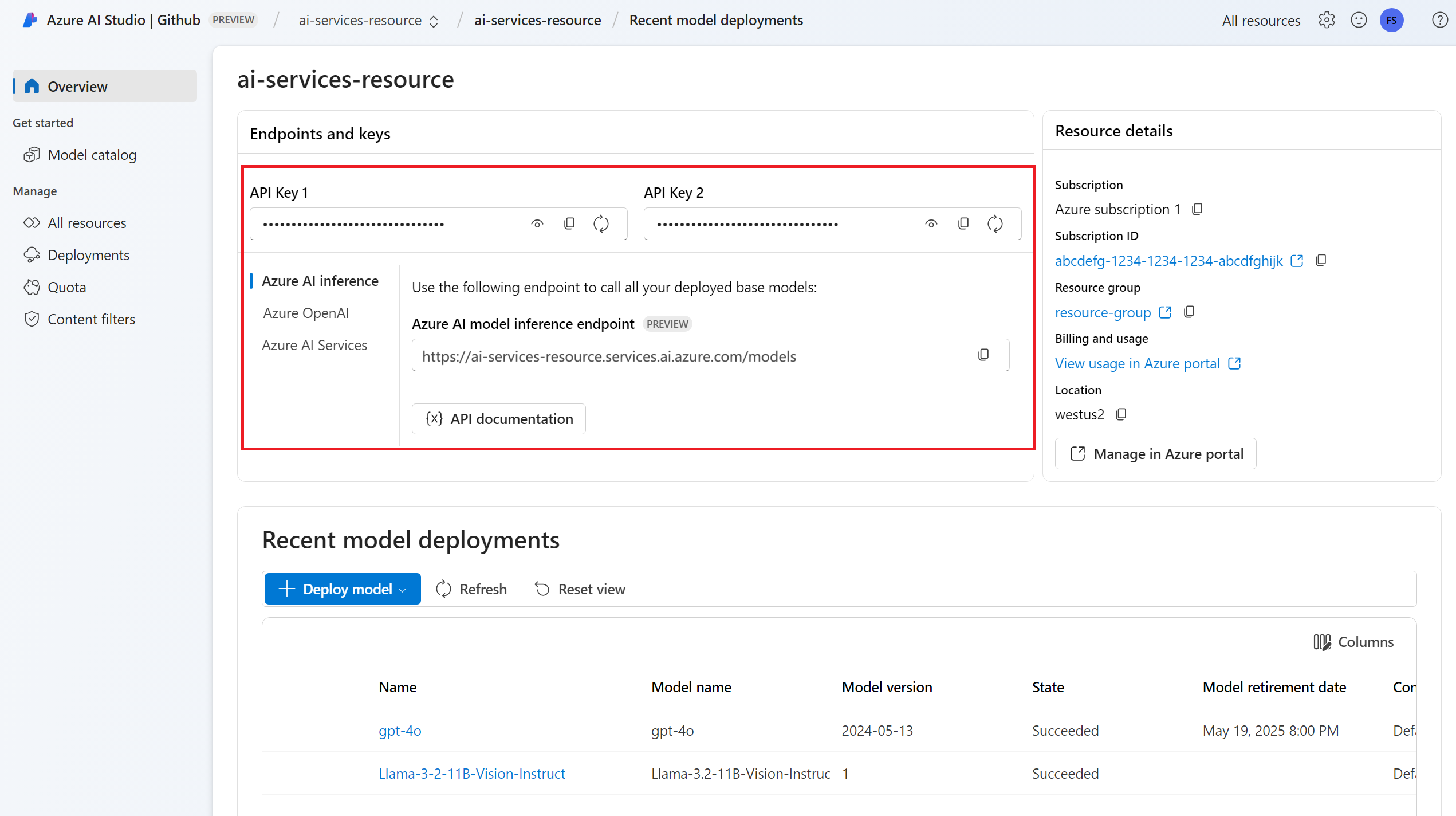

Bereitgestelltes Einbettungsmodell. Wenn Sie kein Modell haben, lesen Sie den Artikel Hinzufügen und Konfigurieren von Modellen für Azure KI Services, um Ihrer Ressource ein Einbettungsmodell hinzuzufügen.
Installieren Sie das Azure KI-Inferenzpaket mit dem folgenden Befehl:
pip install -U azure-ai-inferenceTipp
Lesen Sie mehr über das Azure KI-Inferenzpaket und die zugehörige Referenz.
Verwenden von Einbettungen
Erstellen Sie als Erstes einen Client zum Nutzen des Modells. Der folgende Code verwendet eine Endpunkt-URL und einen Schlüssel, die in Umgebungsvariablen gespeichert sind.
import os
from azure.ai.inference import EmbeddingsClient
from azure.core.credentials import AzureKeyCredential
model = EmbeddingsClient(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=AzureKeyCredential(os.environ["AZURE_INFERENCE_CREDENTIAL"]),
model="text-embedding-3-small"
)
Wenn Sie die Ressource mit Unterstützung vonMicrosoft Entra ID konfiguriert haben, können Sie den folgenden Codeschnipsel verwenden, um einen Client zu erstellen:
import os
from azure.ai.inference import EmbeddingsClient
from azure.core.credentials import AzureKeyCredential
model = EmbeddingsClient(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredential(),
model="text-embedding-3-small"
)
Erstellen von Einbettungen
Erstellen Sie eine Einbettungsanforderung, um die Ausgabe des Modells anzuzeigen.
response = model.embed(
input=["The ultimate answer to the question of life"],
)
Tipp
Berücksichtigen Sie beim Erstellen einer Anforderung das Tokeneingabelimit für das Modell. Wenn Sie größere Textmengen einbetten müssen, benötigen Sie eine Segmentierungsstrategie.
Die Antwort lautet wie folgt, wobei Sie die Nutzungsstatistiken des Modells sehen können:
import numpy as np
for embed in response.data:
print("Embeding of size:", np.asarray(embed.embedding).shape)
print("Model:", response.model)
print("Usage:", response.usage)
Es kann nützlich sein, Einbettungen in Eingabebatches zu berechnen. Der Parameter inputs kann eine Liste von Zeichenfolgen sein, wobei jede Zeichenfolge eine andere Eingabe ist. Die Antwort wiederum ist eine Liste der Einbettungen, wobei jede Einbettung der Eingabe an derselben Position entspricht.
response = model.embed(
input=[
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter",
],
)
Die Antwort lautet wie folgt, wobei Sie die Nutzungsstatistiken des Modells sehen können:
import numpy as np
for embed in response.data:
print("Embeding of size:", np.asarray(embed.embedding).shape)
print("Model:", response.model)
print("Usage:", response.usage)
Tipp
Berücksichtigen Sie beim Erstellen von Anforderungsbatches das Batchlimit für die einzelnen Modelle. Für die meisten Modelle gilt ein Batchlimit von 1.024.
Angeben von Einbettungsdimensionen
Sie können die Anzahl der Dimensionen für die Einbettungen angeben. Im folgenden Beispielcode wird gezeigt, wie Einbettungen mit 1.024 Dimensionen erstellt werden. Beachten Sie, dass nicht alle Einbettungsmodelle die Angabe der Anzahl von Dimensionen in der Anforderung unterstützen. In diesen Fällen wird ein 422-Fehler zurückgegeben.
response = model.embed(
input=["The ultimate answer to the question of life"],
dimensions=1024,
)
Erstellen verschiedener Typen von Einbettungen
Einige Modelle können mehrere Einbettungen für dieselbe Eingabe generieren, je nachdem, welche Verwendung geplant ist. Mit dieser Funktion können Sie genauere Einbettungen für RAG-Muster abrufen.
Das folgende Beispiel zeigt, wie Einbettungen erstellt werden, die zum Erstellen einer Einbettung für ein Dokument verwendet werden, das in einer Vektordatenbank gespeichert wird:
from azure.ai.inference.models import EmbeddingInputType
response = model.embed(
input=["The answer to the ultimate question of life, the universe, and everything is 42"],
input_type=EmbeddingInputType.DOCUMENT,
)
Wenn Sie an einer Abfrage arbeiten, um ein solches Dokument abzurufen, können Sie den folgenden Codeschnipsel verwenden, um die Einbettungen für die Abfrage zu erstellen und die Abrufleistung zu maximieren.
from azure.ai.inference.models import EmbeddingInputType
response = model.embed(
input=["What's the ultimate meaning of life?"],
input_type=EmbeddingInputType.QUERY,
)
Beachten Sie, dass nicht alle Einbettungsmodelle die Angabe des Eingabetyps in der Anforderung unterstützen. In diesen Fällen wird ein 422-Fehler zurückgegeben. Standardmäßig werden Einbettungen vom Typ Text zurückgegeben.
Wichtig
Die in diesem Artikel markierten Elemente (Vorschau) sind aktuell als öffentliche Vorschau verfügbar. Diese Vorschauversion wird ohne Vereinbarung zum Servicelevel bereitgestellt und sollte nicht für Produktionsworkloads verwendet werden. Manche Features werden möglicherweise nicht unterstützt oder sind nur eingeschränkt verwendbar. Weitere Informationen finden Sie unter Zusätzliche Nutzungsbestimmungen für Microsoft Azure-Vorschauen.
In diesem Artikel wird erläutert, wie Sie die Einbettungs-API bei Modellen verwenden, die in Azure KI-Modellinferenz in Azure KI Services bereitgestellt werden.
Voraussetzungen
Um Einbettungsmodelle in Ihrer Anwendung zu verwenden, benötigen Sie Folgendes:
Ein Azure-Abonnement. Wenn Sie GitHub-Modelle verwenden, können Sie Ihre Erfahrung upgraden und während dem Prozess ein Azure-Abonnement erstellen. Lesen Sie in diesem Fall Upgrade von GitHub-Modellen auf die Azure KI-Modellinferenz.
Eine Azure KI Services-Ressource. Weitere Informationen finden Sie unter Erstellen einer Azure KI Services-Ressource.
Endpunkt-URL und -Schlüssel
Bereitgestelltes Einbettungsmodell. Wenn Sie kein Modell haben, lesen Sie den Artikel Hinzufügen und Konfigurieren von Modellen für Azure KI Services, um Ihrer Ressource ein Einbettungsmodell hinzuzufügen.
Installieren Sie die Azure-Inferenzbibliothek für JavaScript mit dem folgenden Befehl:
npm install @azure-rest/ai-inferenceTipp
Lesen Sie mehr über das Azure KI-Inferenzpaket und die zugehörige Referenz.
Verwenden von Einbettungen
Erstellen Sie als Erstes einen Client zum Nutzen des Modells. Der folgende Code verwendet eine Endpunkt-URL und einen Schlüssel, die in Umgebungsvariablen gespeichert sind.
import ModelClient from "@azure-rest/ai-inference";
import { isUnexpected } from "@azure-rest/ai-inference";
import { AzureKeyCredential } from "@azure/core-auth";
const client = new ModelClient(
process.env.AZURE_INFERENCE_ENDPOINT,
new AzureKeyCredential(process.env.AZURE_INFERENCE_CREDENTIAL),
"text-embedding-3-small"
);
Wenn Sie die Ressource mit Unterstützung vonMicrosoft Entra ID konfiguriert haben, können Sie den folgenden Codeschnipsel verwenden, um einen Client zu erstellen:
import ModelClient from "@azure-rest/ai-inference";
import { isUnexpected } from "@azure-rest/ai-inference";
import { DefaultAzureCredential } from "@azure/identity";
const client = new ModelClient(
process.env.AZURE_INFERENCE_ENDPOINT,
new DefaultAzureCredential(),
"text-embedding-3-small"
);
Erstellen von Einbettungen
Erstellen Sie eine Einbettungsanforderung, um die Ausgabe des Modells anzuzeigen.
var response = await client.path("/embeddings").post({
body: {
input: ["The ultimate answer to the question of life"],
}
});
Tipp
Berücksichtigen Sie beim Erstellen einer Anforderung das Tokeneingabelimit für das Modell. Wenn Sie größere Textmengen einbetten müssen, benötigen Sie eine Segmentierungsstrategie.
Die Antwort lautet wie folgt, wobei Sie die Nutzungsstatistiken des Modells sehen können:
if (isUnexpected(response)) {
throw response.body.error;
}
console.log(response.embedding);
console.log(response.body.model);
console.log(response.body.usage);
Es kann nützlich sein, Einbettungen in Eingabebatches zu berechnen. Der Parameter inputs kann eine Liste von Zeichenfolgen sein, wobei jede Zeichenfolge eine andere Eingabe ist. Die Antwort wiederum ist eine Liste der Einbettungen, wobei jede Einbettung der Eingabe an derselben Position entspricht.
var response = await client.path("/embeddings").post({
body: {
input: [
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter",
],
}
});
Die Antwort lautet wie folgt, wobei Sie die Nutzungsstatistiken des Modells sehen können:
if (isUnexpected(response)) {
throw response.body.error;
}
console.log(response.embedding);
console.log(response.body.model);
console.log(response.body.usage);
Tipp
Berücksichtigen Sie beim Erstellen von Anforderungsbatches das Batchlimit für die einzelnen Modelle. Für die meisten Modelle gilt ein Batchlimit von 1.024.
Angeben von Einbettungsdimensionen
Sie können die Anzahl der Dimensionen für die Einbettungen angeben. Im folgenden Beispielcode wird gezeigt, wie Einbettungen mit 1.024 Dimensionen erstellt werden. Beachten Sie, dass nicht alle Einbettungsmodelle die Angabe der Anzahl von Dimensionen in der Anforderung unterstützen. In diesen Fällen wird ein 422-Fehler zurückgegeben.
var response = await client.path("/embeddings").post({
body: {
input: ["The ultimate answer to the question of life"],
dimensions: 1024,
}
});
Erstellen verschiedener Typen von Einbettungen
Einige Modelle können mehrere Einbettungen für dieselbe Eingabe generieren, je nachdem, welche Verwendung geplant ist. Mit dieser Funktion können Sie genauere Einbettungen für RAG-Muster abrufen.
Das folgende Beispiel zeigt, wie Einbettungen erstellt werden, die zum Erstellen einer Einbettung für ein Dokument verwendet werden, das in einer Vektordatenbank gespeichert wird:
var response = await client.path("/embeddings").post({
body: {
input: ["The answer to the ultimate question of life, the universe, and everything is 42"],
input_type: "document",
}
});
Wenn Sie an einer Abfrage arbeiten, um ein solches Dokument abzurufen, können Sie den folgenden Codeschnipsel verwenden, um die Einbettungen für die Abfrage zu erstellen und die Abrufleistung zu maximieren.
var response = await client.path("/embeddings").post({
body: {
input: ["What's the ultimate meaning of life?"],
input_type: "query",
}
});
Beachten Sie, dass nicht alle Einbettungsmodelle die Angabe des Eingabetyps in der Anforderung unterstützen. In diesen Fällen wird ein 422-Fehler zurückgegeben. Standardmäßig werden Einbettungen vom Typ Text zurückgegeben.
Wichtig
Die in diesem Artikel markierten Elemente (Vorschau) sind aktuell als öffentliche Vorschau verfügbar. Diese Vorschauversion wird ohne Vereinbarung zum Servicelevel bereitgestellt und sollte nicht für Produktionsworkloads verwendet werden. Manche Features werden möglicherweise nicht unterstützt oder sind nur eingeschränkt verwendbar. Weitere Informationen finden Sie unter Zusätzliche Nutzungsbestimmungen für Microsoft Azure-Vorschauen.
In diesem Artikel wird erläutert, wie Sie die Einbettungs-API bei Modellen verwenden, die in Azure KI-Modellinferenz in Azure KI Services bereitgestellt werden.
Voraussetzungen
Um Einbettungsmodelle in Ihrer Anwendung zu verwenden, benötigen Sie Folgendes:
Ein Azure-Abonnement. Wenn Sie GitHub-Modelle verwenden, können Sie Ihre Erfahrung upgraden und während dem Prozess ein Azure-Abonnement erstellen. Lesen Sie in diesem Fall Upgrade von GitHub-Modellen auf die Azure KI-Modellinferenz.
Eine Azure KI Services-Ressource. Weitere Informationen finden Sie unter Erstellen einer Azure KI Services-Ressource.
Endpunkt-URL und -Schlüssel
Bereitgestelltes Einbettungsmodell. Wenn Sie kein Modell haben, lesen Sie den Artikel Hinzufügen und Konfigurieren von Modellen für Azure KI Services, um Ihrer Ressource ein Einbettungsmodell hinzuzufügen.
Fügen Sie das Azure KI-Inferenzpaket zum Projekt hinzu:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-ai-inference</artifactId> <version>1.0.0-beta.1</version> </dependency>Tipp
Lesen Sie mehr über das Azure KI-Inferenzpaket und die zugehörige Referenz.
Wenn Sie Entra ID verwenden, benötigen Sie außerdem das folgende Paket:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-identity</artifactId> <version>1.13.3</version> </dependency>Importieren Sie den folgenden Namespace:
package com.azure.ai.inference.usage; import com.azure.ai.inference.EmbeddingsClient; import com.azure.ai.inference.EmbeddingsClientBuilder; import com.azure.ai.inference.models.EmbeddingsResult; import com.azure.ai.inference.models.EmbeddingItem; import com.azure.core.credential.AzureKeyCredential; import com.azure.core.util.Configuration; import java.util.ArrayList; import java.util.List;
Verwenden von Einbettungen
Erstellen Sie als Erstes einen Client zum Nutzen des Modells. Der folgende Code verwendet eine Endpunkt-URL und einen Schlüssel, die in Umgebungsvariablen gespeichert sind.
EmbeddingsClient client = new EmbeddingsClient(
URI.create(System.getProperty("AZURE_INFERENCE_ENDPOINT")),
new AzureKeyCredential(System.getProperty("AZURE_INFERENCE_CREDENTIAL")),
"text-embedding-3-small"
);
Wenn Sie die Ressource mit Unterstützung vonMicrosoft Entra ID konfiguriert haben, können Sie den folgenden Codeschnipsel verwenden, um einen Client zu erstellen:
client = new EmbeddingsClient(
URI.create(System.getProperty("AZURE_INFERENCE_ENDPOINT")),
new DefaultAzureCredential(),
"text-embedding-3-small"
);
Erstellen von Einbettungen
Erstellen Sie eine Einbettungsanforderung, um die Ausgabe des Modells anzuzeigen.
EmbeddingsOptions requestOptions = new EmbeddingsOptions()
.setInput(Arrays.asList("The ultimate answer to the question of life"));
Response<EmbeddingsResult> response = client.embed(requestOptions);
Tipp
Berücksichtigen Sie beim Erstellen einer Anforderung das Tokeneingabelimit für das Modell. Wenn Sie größere Textmengen einbetten müssen, benötigen Sie eine Segmentierungsstrategie.
Die Antwort lautet wie folgt, wobei Sie die Nutzungsstatistiken des Modells sehen können:
System.out.println("Embedding: " + response.getValue().getData());
System.out.println("Model: " + response.getValue().getModel());
System.out.println("Usage:");
System.out.println("\tPrompt tokens: " + response.getValue().getUsage().getPromptTokens());
System.out.println("\tTotal tokens: " + response.getValue().getUsage().getTotalTokens());
Es kann nützlich sein, Einbettungen in Eingabebatches zu berechnen. Der Parameter inputs kann eine Liste von Zeichenfolgen sein, wobei jede Zeichenfolge eine andere Eingabe ist. Die Antwort wiederum ist eine Liste der Einbettungen, wobei jede Einbettung der Eingabe an derselben Position entspricht.
requestOptions = new EmbeddingsOptions()
.setInput(Arrays.asList(
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter"
));
response = client.embed(requestOptions);
Die Antwort lautet wie folgt, wobei Sie die Nutzungsstatistiken des Modells sehen können:
Tipp
Berücksichtigen Sie beim Erstellen von Anforderungsbatches das Batchlimit für die einzelnen Modelle. Für die meisten Modelle gilt ein Batchlimit von 1.024.
Angeben von Einbettungsdimensionen
Sie können die Anzahl der Dimensionen für die Einbettungen angeben. Im folgenden Beispielcode wird gezeigt, wie Einbettungen mit 1.024 Dimensionen erstellt werden. Beachten Sie, dass nicht alle Einbettungsmodelle die Angabe der Anzahl von Dimensionen in der Anforderung unterstützen. In diesen Fällen wird ein 422-Fehler zurückgegeben.
Erstellen verschiedener Typen von Einbettungen
Einige Modelle können mehrere Einbettungen für dieselbe Eingabe generieren, je nachdem, welche Verwendung geplant ist. Mit dieser Funktion können Sie genauere Einbettungen für RAG-Muster abrufen.
Das folgende Beispiel zeigt, wie Einbettungen erstellt werden, die zum Erstellen einer Einbettung für ein Dokument verwendet werden, das in einer Vektordatenbank gespeichert wird:
List<String> input = Arrays.asList("The answer to the ultimate question of life, the universe, and everything is 42");
requestOptions = new EmbeddingsOptions(input, EmbeddingInputType.DOCUMENT);
response = client.embed(requestOptions);
Wenn Sie an einer Abfrage arbeiten, um ein solches Dokument abzurufen, können Sie den folgenden Codeschnipsel verwenden, um die Einbettungen für die Abfrage zu erstellen und die Abrufleistung zu maximieren.
input = Arrays.asList("What's the ultimate meaning of life?");
requestOptions = new EmbeddingsOptions(input, EmbeddingInputType.QUERY);
response = client.embed(requestOptions);
Beachten Sie, dass nicht alle Einbettungsmodelle die Angabe des Eingabetyps in der Anforderung unterstützen. In diesen Fällen wird ein 422-Fehler zurückgegeben. Standardmäßig werden Einbettungen vom Typ Text zurückgegeben.
Wichtig
Die in diesem Artikel markierten Elemente (Vorschau) sind aktuell als öffentliche Vorschau verfügbar. Diese Vorschauversion wird ohne Vereinbarung zum Servicelevel bereitgestellt und sollte nicht für Produktionsworkloads verwendet werden. Manche Features werden möglicherweise nicht unterstützt oder sind nur eingeschränkt verwendbar. Weitere Informationen finden Sie unter Zusätzliche Nutzungsbestimmungen für Microsoft Azure-Vorschauen.
In diesem Artikel wird erläutert, wie Sie die Einbettungs-API bei Modellen verwenden, die in Azure KI-Modellinferenz in Azure KI Services bereitgestellt werden.
Voraussetzungen
Um Einbettungsmodelle in Ihrer Anwendung zu verwenden, benötigen Sie Folgendes:
Ein Azure-Abonnement. Wenn Sie GitHub-Modelle verwenden, können Sie Ihre Erfahrung upgraden und während dem Prozess ein Azure-Abonnement erstellen. Lesen Sie in diesem Fall Upgrade von GitHub-Modellen auf die Azure KI-Modellinferenz.
Eine Azure KI Services-Ressource. Weitere Informationen finden Sie unter Erstellen einer Azure KI Services-Ressource.
Endpunkt-URL und -Schlüssel
Bereitgestelltes Einbettungsmodell. Wenn Sie kein Modell haben, lesen Sie den Artikel Hinzufügen und Konfigurieren von Modellen für Azure KI Services, um Ihrer Ressource ein Einbettungsmodell hinzuzufügen.
Installieren Sie das Azure KI-Inferenzpaket mit dem folgenden Befehl:
dotnet add package Azure.AI.Inference --prereleaseTipp
Lesen Sie mehr über das Azure KI-Inferenzpaket und die zugehörige Referenz.
Wenn Sie Entra ID verwenden, benötigen Sie außerdem das folgende Paket:
dotnet add package Azure.Identity
Verwenden von Einbettungen
Erstellen Sie als Erstes einen Client zum Nutzen des Modells. Der folgende Code verwendet eine Endpunkt-URL und einen Schlüssel, die in Umgebungsvariablen gespeichert sind.
EmbeddingsClient client = new EmbeddingsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
new AzureKeyCredential(Environment.GetEnvironmentVariable("AZURE_INFERENCE_CREDENTIAL")),
"text-embedding-3-small"
);
Wenn Sie die Ressource mit Unterstützung vonMicrosoft Entra ID konfiguriert haben, können Sie den folgenden Codeschnipsel verwenden, um einen Client zu erstellen:
client = new EmbeddingsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
new DefaultAzureCredential(includeInteractiveCredentials: true),
"text-embedding-3-small"
);
Erstellen von Einbettungen
Erstellen Sie eine Einbettungsanforderung, um die Ausgabe des Modells anzuzeigen.
EmbeddingsOptions requestOptions = new EmbeddingsOptions()
{
Input = {
"The ultimate answer to the question of life"
},
};
Response<EmbeddingsResult> response = client.Embed(requestOptions);
Tipp
Berücksichtigen Sie beim Erstellen einer Anforderung das Tokeneingabelimit für das Modell. Wenn Sie größere Textmengen einbetten müssen, benötigen Sie eine Segmentierungsstrategie.
Die Antwort lautet wie folgt, wobei Sie die Nutzungsstatistiken des Modells sehen können:
Console.WriteLine($"Embedding: {response.Value.Data}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Es kann nützlich sein, Einbettungen in Eingabebatches zu berechnen. Der Parameter inputs kann eine Liste von Zeichenfolgen sein, wobei jede Zeichenfolge eine andere Eingabe ist. Die Antwort wiederum ist eine Liste der Einbettungen, wobei jede Einbettung der Eingabe an derselben Position entspricht.
EmbeddingsOptions requestOptions = new EmbeddingsOptions()
{
Input = {
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter"
},
};
Response<EmbeddingsResult> response = client.Embed(requestOptions);
Die Antwort lautet wie folgt, wobei Sie die Nutzungsstatistiken des Modells sehen können:
Tipp
Berücksichtigen Sie beim Erstellen von Anforderungsbatches das Batchlimit für die einzelnen Modelle. Für die meisten Modelle gilt ein Batchlimit von 1.024.
Angeben von Einbettungsdimensionen
Sie können die Anzahl der Dimensionen für die Einbettungen angeben. Im folgenden Beispielcode wird gezeigt, wie Einbettungen mit 1.024 Dimensionen erstellt werden. Beachten Sie, dass nicht alle Einbettungsmodelle die Angabe der Anzahl von Dimensionen in der Anforderung unterstützen. In diesen Fällen wird ein 422-Fehler zurückgegeben.
Erstellen verschiedener Typen von Einbettungen
Einige Modelle können mehrere Einbettungen für dieselbe Eingabe generieren, je nachdem, welche Verwendung geplant ist. Mit dieser Funktion können Sie genauere Einbettungen für RAG-Muster abrufen.
Das folgende Beispiel zeigt, wie Einbettungen erstellt werden, die zum Erstellen einer Einbettung für ein Dokument verwendet werden, das in einer Vektordatenbank gespeichert wird:
var input = new List<string> {
"The answer to the ultimate question of life, the universe, and everything is 42"
};
var requestOptions = new EmbeddingsOptions(input, EmbeddingInputType.DOCUMENT);
Response<EmbeddingsResult> response = client.Embed(requestOptions);
Wenn Sie an einer Abfrage arbeiten, um ein solches Dokument abzurufen, können Sie den folgenden Codeschnipsel verwenden, um die Einbettungen für die Abfrage zu erstellen und die Abrufleistung zu maximieren.
var input = new List<string> {
"What's the ultimate meaning of life?"
};
var requestOptions = new EmbeddingsOptions(input, EmbeddingInputType.QUERY);
Response<EmbeddingsResult> response = client.Embed(requestOptions);
Beachten Sie, dass nicht alle Einbettungsmodelle die Angabe des Eingabetyps in der Anforderung unterstützen. In diesen Fällen wird ein 422-Fehler zurückgegeben. Standardmäßig werden Einbettungen vom Typ Text zurückgegeben.
Wichtig
Die in diesem Artikel markierten Elemente (Vorschau) sind aktuell als öffentliche Vorschau verfügbar. Diese Vorschauversion wird ohne Vereinbarung zum Servicelevel bereitgestellt und sollte nicht für Produktionsworkloads verwendet werden. Manche Features werden möglicherweise nicht unterstützt oder sind nur eingeschränkt verwendbar. Weitere Informationen finden Sie unter Zusätzliche Nutzungsbestimmungen für Microsoft Azure-Vorschauen.
In diesem Artikel wird erläutert, wie Sie die Einbettungs-API bei Modellen verwenden, die in Azure KI-Modellinferenz in Azure KI Services bereitgestellt werden.
Voraussetzungen
Um Einbettungsmodelle in Ihrer Anwendung zu verwenden, benötigen Sie Folgendes:
Ein Azure-Abonnement. Wenn Sie GitHub-Modelle verwenden, können Sie Ihre Erfahrung upgraden und während dem Prozess ein Azure-Abonnement erstellen. Lesen Sie in diesem Fall Upgrade von GitHub-Modellen auf die Azure KI-Modellinferenz.
Eine Azure KI Services-Ressource. Weitere Informationen finden Sie unter Erstellen einer Azure KI Services-Ressource.
Endpunkt-URL und -Schlüssel
- Bereitgestelltes Einbettungsmodell. Wenn Sie kein Modell haben, lesen Sie den Artikel Hinzufügen und Konfigurieren von Modellen für Azure KI Services, um Ihrer Ressource ein Einbettungsmodell hinzuzufügen.
Verwenden von Einbettungen
Um die Texteinbettungen zu nutzen, verwenden Sie die Route /embeddings, die an die Basis-URL angefügt ist, zusammen mit den in api-key angegebenen Anmeldeinformationen. Der Header Authorization wird auch im Format Bearer <key> unterstützt.
POST https://<resource>.services.ai.azure.com/models/embeddings?api-version=2024-05-01-preview
Content-Type: application/json
api-key: <key>
Wenn Sie die Ressource mit Unterstützung von Microsoft Entra ID konfiguriert haben, übergeben Sie das Token im Authorization-Header:
POST https://<resource>.services.ai.azure.com/models/embeddings?api-version=2024-05-01-preview
Content-Type: application/json
Authorization: Bearer <token>
Erstellen von Einbettungen
Erstellen Sie eine Einbettungsanforderung, um die Ausgabe des Modells anzuzeigen.
{
"input": [
"The ultimate answer to the question of life"
]
}
Tipp
Berücksichtigen Sie beim Erstellen einer Anforderung das Tokeneingabelimit für das Modell. Wenn Sie größere Textmengen einbetten müssen, benötigen Sie eine Segmentierungsstrategie.
Die Antwort lautet wie folgt, wobei Sie die Nutzungsstatistiken des Modells sehen können:
{
"id": "0ab1234c-d5e6-7fgh-i890-j1234k123456",
"object": "list",
"data": [
{
"index": 0,
"object": "embedding",
"embedding": [
0.017196655,
// ...
-0.000687122,
-0.025054932,
-0.015777588
]
}
],
"model": "text-embedding-3-small",
"usage": {
"prompt_tokens": 9,
"completion_tokens": 0,
"total_tokens": 9
}
}
Es kann nützlich sein, Einbettungen in Eingabebatches zu berechnen. Der Parameter inputs kann eine Liste von Zeichenfolgen sein, wobei jede Zeichenfolge eine andere Eingabe ist. Die Antwort wiederum ist eine Liste der Einbettungen, wobei jede Einbettung der Eingabe an derselben Position entspricht.
{
"input": [
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter"
]
}
Die Antwort lautet wie folgt, wobei Sie die Nutzungsstatistiken des Modells sehen können:
{
"id": "0ab1234c-d5e6-7fgh-i890-j1234k123456",
"object": "list",
"data": [
{
"index": 0,
"object": "embedding",
"embedding": [
0.017196655,
// ...
-0.000687122,
-0.025054932,
-0.015777588
]
},
{
"index": 1,
"object": "embedding",
"embedding": [
0.017196655,
// ...
-0.000687122,
-0.025054932,
-0.015777588
]
}
],
"model": "text-embedding-3-small",
"usage": {
"prompt_tokens": 19,
"completion_tokens": 0,
"total_tokens": 19
}
}
Tipp
Berücksichtigen Sie beim Erstellen von Anforderungsbatches das Batchlimit für die einzelnen Modelle. Für die meisten Modelle gilt ein Batchlimit von 1.024.
Angeben von Einbettungsdimensionen
Sie können die Anzahl der Dimensionen für die Einbettungen angeben. Im folgenden Beispielcode wird gezeigt, wie Einbettungen mit 1.024 Dimensionen erstellt werden. Beachten Sie, dass nicht alle Einbettungsmodelle die Angabe der Anzahl von Dimensionen in der Anforderung unterstützen. In diesen Fällen wird ein 422-Fehler zurückgegeben.
{
"input": [
"The ultimate answer to the question of life"
],
"dimensions": 1024
}
Erstellen verschiedener Typen von Einbettungen
Einige Modelle können mehrere Einbettungen für dieselbe Eingabe generieren, je nachdem, welche Verwendung geplant ist. Mit dieser Funktion können Sie genauere Einbettungen für RAG-Muster abrufen.
Das folgende Beispiel zeigt, wie Einbettungen erstellt werden, die zum Erstellen einer Einbettung für ein Dokument verwendet werden, das in einer Vektordatenbank gespeichert wird:
{
"input": [
"The answer to the ultimate question of life, the universe, and everything is 42"
],
"input_type": "document"
}
Wenn Sie an einer Abfrage arbeiten, um ein solches Dokument abzurufen, können Sie den folgenden Codeschnipsel verwenden, um die Einbettungen für die Abfrage zu erstellen und die Abrufleistung zu maximieren.
{
"input": [
"What's the ultimate meaning of life?"
],
"input_type": "query"
}
Beachten Sie, dass nicht alle Einbettungsmodelle die Angabe des Eingabetyps in der Anforderung unterstützen. In diesen Fällen wird ein 422-Fehler zurückgegeben. Standardmäßig werden Einbettungen vom Typ Text zurückgegeben.