Azure 仮想マシンにおける可用性の考え方
はじめに
若干今更な感じもするタイトルではありますが、やはり Azure に初めて取り組む方にはわかりにくく、かつ重要視される部分でもありますので、改めてまとめてみたいと思います。「考え方」というタイトルの通り、本記事では技術的にはあまり深入りしないように、なるべく簡潔に記載していきたいと思います。さらに深く追求したい方向けは随所にリンクを貼っておきますので、そちらをご参照いただければと思います。
2017-10-22 追記
本記事の執筆後にも Azure は進化を続けており、可用性ゾーンや計画メンテナンスにおけるセルフサービスといった機能追加や更新が行われました。このため本記事の内容は若干古くなっておりますが、現時点でも通用する内容だと思いますし、可用性に関して選択肢が増えた状況と考えます。特に可用性ゾーンのプレビューが取れある程度知見が得られた段階で本記事を修正するか、別記事を記載しようと思います。
仮想マシン単体レベルの可用性
まず初めに基礎として、1 台だけの仮想マシンで見た場合の可用性についてです。Azure 仮想マシンの可用性を考えるうえでは以下の 3 つの要素が重要です。
- Compute CPU やメモリが利用できる
- Storage ディスクの読み書きができる
- Network 当該仮想マシンと通信することができる
ちなみにこの 3 つは仮想マシンの課金要素でもありますので、下記もご参照ください。
仮想マシンの課金の仕組み
Azure 仮想マシンは Windows Hyper-V をベースとした仮想化基盤上で動作します。Azure ポータルや PowerShell / CLI 等を利用して仮想マシンを作成すると、指定した Azure リージョンのどこかの仮想化基盤上に Compute と Storage リソースが確保され、仮想マシンとしての動作を開始します。この仮想マシンに対してネットワーク接続が可能であることによって、Azure の利用者はサービスを提供することができるわけです。
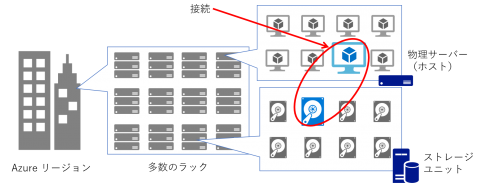
この仮想化基盤とその上で動作する仮想マシンはデータセンターのオペレーションチームによって監視・運用されています。例えばホストとなる物理サーバーに異常が検知された場合、その内容によっては再起動、あるいは他の健全な物理サーバーへの再デプロイが自動的に行われます。この仕組みは Service Healing と呼ばれ、これは全ての Azure 仮想マシンにおいて標準の機能になります。
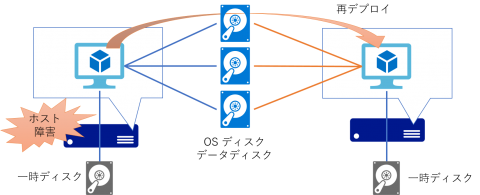
この際、仮想マシンとしても強制的に再起動が発生してしまいますので、一時的にサービスは中断されることになります。つまり Service Healing によるモニタリング間隔+仮想マシンの起動+α 程度のダウンタイムが発生します。ただし再起動先でも同一のOSディスクやデータディスクに接続されるため、そこに格納されたデータが失われることはありません。またネットワーク的にも同条件で再構成されるため、一定時間後には接続可能になりますので、利用を再開することができます。
これは言い換えれば、Azure 仮想マシンは“Active-Standby” 構成になっているかのように扱えることを意味します。また上の図では物理サーバーを2台しか記載していませんが、実際には Azure のデータセンターには仮想マシンをホストするための物理サーバーが多数配備されています。つまり 1 台の仮想マシンを作成するだけで、大量の待機系(占有ではありません)が準備されていることを意味します。以下に示される仮想マシンの利用料金には待機系を準備するコストも含まれていることになります。
Windows Virtual Machines の料金 Linux Virtual Machines の料金
なおディスクも内部的には多重化されており、仮想マシンからのすべての書き込みは3つの物理領域に書き込みが完了して初めて成功となります。これによってストレージユニットが物理的に破損した場合にも残りの 2 つからデータが復旧することが可能です。つまり最低でも 3 多重の RAID-1の構成になり、これを Azure では LRS ( Locally Redundant Storage )と呼びます。
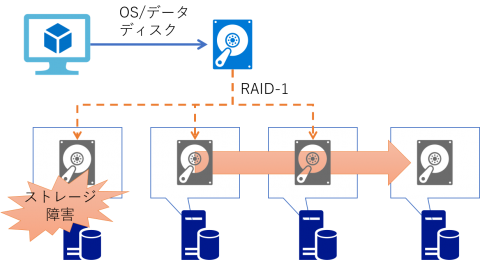
ちなみに仮想マシンに接続されている全てのディスクが Premium Storage を使用している場合には、その可用性が Microsoft によって保証されています。
Virtual Machines の SLA
お約束とお願い
このように Service Healing と LRS という仕組みによって、単体構成であっても「それなりの」可用性が得られることが分かります。ここまでが Microsoft が 「Azure 仮想マシンの可用性」として提供している範囲になりますが、「サービスとしての可用性」を考えた場合には利用者側でも考慮が必要です。端的に言えば「OS 以上のソフトウェアスタック」が全て正常に動作していることは利用者側で保証する必要がある、ということになります。
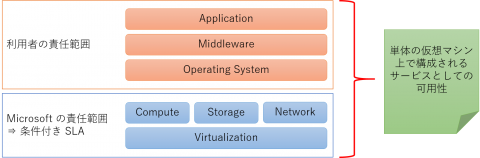
このように利用者が構築するサービスは「Azure 仮想マシン」に対して直接的・間接的な依存性を持ちます。つまり利用者は Azure 仮想マシンの特性を理解し、それを考慮してOperating System、Middleware、Application を構成する必要があるわけです。すべての特性をここに列挙することは難しいのですが、代表的なものを以下にご紹介します。
意図しない再起動に備える
まず前述の通り、Azure 仮想マシンのホストで障害が発生する可能性はゼロではありません。その場合 Azure データセンターの運用としてはホストの再起動や切り離しが行われる可能性があります。そしてそれに伴う仮想マシンの強制的な再起動ないしは再デプロイが発生する可能性があります。この運用は高度に自動化されているため、たとえデータセンターの運用チームであってもイレギュラーな対応はできません。このためサービスとしての可用性を一定水準以上に維持するためには、仮想マシンが再起動後にアプリケーションが自動復旧して正常な運用状態に戻れるように設計・実装することを強くお勧めします。
再起動に強いシステムを構築することのメリットや考え方については下記が詳しいので是非ご一読ください
大事なデータは永続化する
各仮想マシンには OS やデータ用のディスクとは別に、ホストとなるサーバーのストレージ上に配置された一時ディスクが1つ接続されています。つまり障害復旧のために仮想マシンが別のホストに再デプロイされてしまった場合には、ここに保存したデータは消えてしまうことになります。例えばアプリケーションなどがこの「一時ディスクに保存したデータ」に依存する作りになっていると、再デプロイ後に正常に稼働を再開することができないため、きわめて障害に弱いサービスになってしまいます。前述の通りストレージサービスに格納されるデータディスクは耐障害性が高いとともに永続性もありますので、重要なデータは必ずデータディスクに保存するようにしてください。
特に注意いただきたいのは既存のオンプレミス環境で動作していた Windows ベースのソフトウェアを Azure 仮想マシン上で動作させるケースです。Azure Marketplace の Windows ベースの 仮想マシンイメージはこの一時ディスクを D ドライブとして接続します。つまりソフトウェアが D ドライブへのファイル I/O に依存した作りになっていると、インストールすると動作はするが障害発生後に動かなくなる、という可能性が高くなります。たまに「I/O 先のパスがハードコードされていて設定変更できないソフトウェア」というものも存在しますので、ご注意ください。
ちなみに(ストレージではなく)仮想マシンの価格表に記載されている「ディスクサイズ」とはこの「揮発性のある一時ディスクのサイズ」を意味します。この一時ディスクは I/O 性能が高く、 VM 料金に含まれる(=追加コストが発生しない)ため、つい使いたくなりますが上記の特性を鑑みてご利用ください。
大事なデータはバックアップを取る
前述の通りディスクは内部的にはレプリカがとられていますが、これとは別にバックアップは取るようにしてください。LRS はあくまでも物理障害に備えて Azure のインフラストラクチャとして耐障害性を持たせるためにレプリカが構成されるだけで、利用者が任意のタイミングで自由にアクセスできるレプリカではありません。利用者のオペレーションミス等によってデータを誤って更新や削除(いわゆる論理破壊)をしてしまった場合、それは物理的には正常なとして更新や削除として 3 箇所に永続化されます。このため「過去のレプリカからデータを復旧する」といったオペレーションは不可能ですので、サービスの品質や運用にかかわるような重要なデータは必ずバックアップを取るようにしてください。
複数台の仮想マシンで高可用性クラスタを構成する
単体レベルの可用性が「それなり」と記載しましたが、システムの要件によってはそれで十分である場合も、不十分である場合もあります。仮想マシン単体だけで考えた場合には、可用性を向上させるアプローチとしては Premium Storage 程度しか選択肢がありません。さらに高い可用性を追求する場合には、利用者自ら仮想マシンを並列化して1つの「クラスタ」を構成する必要があります。
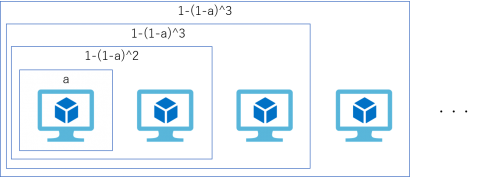
可用性が a である仮想マシンを N 台用意してクラスタを構成した場合の、クラスタ全体で見た可用性の計算式は 1 – ( 1-a )^N となります。この計算式を基にいくつかのパターンで可用性を算出し、月間の想定ダウンタイム(分)で表したものが以下の表になります。これは1日24時間の稼働、1か月を30日として計算しています。

単一障害点の排除
シングルノード SLA に定義されている可用性(a=99.9%)では月間の想定ダウンタイムは 43.2 分です。仮に単体の可用性を低めに見積もって a = 95% とした場合、 1 台構成では月間で 2160 分(=36時間=1.5日)程度の非常に大きなダウンタイムを想定する必要があります。しかしこの仮想マシンでクラスタを構成した場合、2 ノードクラスタでは108分(=1時間48分)、3ノードクラスタでは5.4分となり、シングルノード SLA を上回る可用性となります。このようにノード数を増やす効果は極めて高く、高可用性が求められるサービスでは、仮想マシン単体で考えるのではなく、クラスタ化を考慮してください。
前述の計算式が成り立つのは、各仮想マシン単体の可用性が独立している場合ですので、以下の 2 つが成り立つ必要があります。
- 相互に依存性がない
- 単一障害点を持たない
例えばサーバーAとBの2台があったとして、A が正常に稼働していないと B が正常に稼働できない場合、B は A に依存します。この場合の可用性の計算式は a^2 となり、 a < 1 ですから a^2 < a が成り立ち、2台並べることで可用性はむしろ劣化します。Azure の仮想マシンを 2 つ作成した場合、それだけで依存性を持つことはありませんので、この観点での考慮は不要です。
ネットワークや電源といった障害点をサーバ A と B が共有している場合、これらで障害が発生した場合 A と B は同時にダウンします。この場合の可用性は a となってしまいますので、可用性は全く向上していません。Azure 上で単純に複数の仮想マシンを作成すると、適宜空いている物理サーバーを探してデプロイが行われます。この時 Azure のインフラストラクチャはこれらの仮想マシンが「単一障害点を持つと問題があるか否か」を判断することができませんので、利用者側から明示的に指示してあげる必要があるわけです。
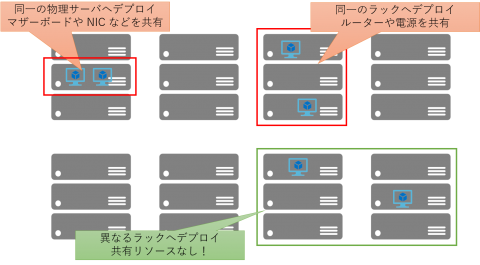
Azure インフラストラクチャに対して「これらの仮想サーバーは別々のラックにデプロイして、単一障害点を持たないようにしてね」と教えてあげるためのオプションを「可用性セット」と呼びます。可用性セットの詳細については下記等をご参照ください。
Windows VM 用の Azure 可用性セットのガイドライン Linux VM 用の Azure 可用性セットのガイドライン
可用性セットは障害に備えるだけではなく、通常運用におけるメンテナンスにおいても考慮されます。頻度は低いですが一部のメンテナンスは仮想マシンの再起動を伴う場合があります。クラスタを構成する複数の仮想マシンがメンテナンスによって同時に再起動が行われることが無いようにするためにも、可用性セットは重要になってきます。
Windows 仮想マシンの計画的なメンテナンス Linux 仮想マシンの計画的メンテナンス
なお同一の可用性セットに複数台の仮想マシンを構成した場合には、それらの仮想マシンに対して SLA が適用されます。この場合には仮想マシンに接続されているディスクは必ずしも Premium Storage である必要はありません。
クラスタを意識したソフトウェア構成
ここまでが Microsoft が 「クラスタ構成における可用性」として提供している範囲になります。しかしこれは、可用性セットに複数の仮想マシンを含んでおけば最低 でも1 台以上が利用可能であるように管理・運用される、というものになります。クラスタレベルで「サービスとしての可用性」を考える場合にはこれだけでは十分ではなく、利用者側でもクラスタ化された仮想マシン上に配備されることを意識したソフトウェア構成を考慮する必要があります。
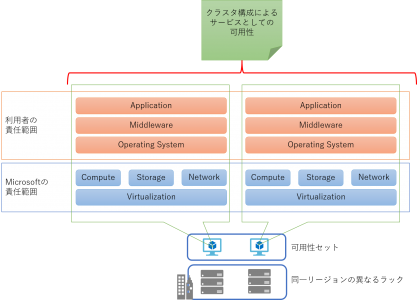
Web サーバーの場合
仮想マシンが Web アプリケーションや Web API を処理する Web サーバーの場合には、その上で動作するアプリケーションをステートレスに実装し、全てのサーバーに同じものを配置するのが一般的です。直接のリクエストは前段に配置した負荷分散装置で受け付け、処理を後段の Web サーバー群に振り分けます。負荷分散装置は Web サーバー群の正常性監視も行うことで、異常を検知した場合には処理を振り分けないようにすることでクラスタから切り離します。
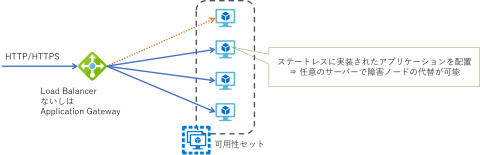
Azure では Layer 4 の負荷分散としては Load Balancer を、あるいは Layer 7 の負荷分散として Application Gateway を利用することが出来ます。
Azure Load Balancer の概要 Application Gateway の概要
DB サーバーの場合
仮想マシンの役割が DB サーバーの場合には、多くの場合 DB ソフトウェアに対応したミドルウェアが必要となります。
例えば SQL Server で高可用性構成を構築する場合には、SQL Server Always On Availability Group を使用しますが、これは Windows Server の Failover Cluster 機能も併せて構成する必要があります。これらにより複数の DB サーバー間でデータ同期を取りつつ、主系および待機系の管理を行います。この場合も接続元となるクライアントからは前段に配置した Azure Load Balancer に対して接続し、その NAT 機能を利用してその時点での主系への透過的な接続を実現します。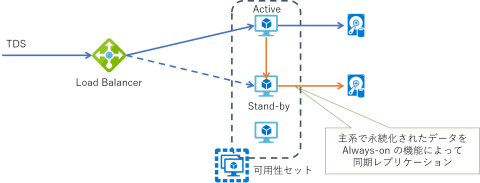 Azure Virtual Machines での SQL Server Always On 可用性グループの概要
Azure Virtual Machines での SQL Server Always On 可用性グループの概要
その他のクラスタ化オプション
Azure 仮想マシンによるクラスタを構築する場合には、前述のようなマニュアルにおる構成に以外にもいくつかの選択肢が存在します。いずれの場合も可用性セットやロードバランサーによるクラスタ構成が行われますが、利用者はその特性に合わせたアプリケーションを配置する必要があります。
Azure VM ScaleSets Azure Container Service Azure Service Fabric
面倒なら PaaS という選択肢
すべての PaaS サービスは既定で可用性が考慮された構成になっています。可用性以外も様々な非機能要件が組み込み済みのため、構築のコストやスピードという面では大きなメリットがあります。利用者に特有の要件が実装できないケースもありますので、単純に可用性の観点だけで選択することは難しいかもしれませんが、是非一度検討いただくことをお勧めします。
なお以下のような一部の PaaS サービスでは仮想マシンと同様に仮想ネットワーク上にデプロイするオプションも提供していますので、前述のクラスタと同様に扱うことが可能になっています。
App Service Environment Azure Batch Azure HDInsight
まとめ
- Azure 仮想マシンは単体構成でも「それなり」の可用性は提供されています。
- それ以上の可用性が必要な場合には複数の仮想マシンを利用したクラスタを構成してください。
- いずれの場合にも仮想マシン上で動作するアプリケーション側での対応も重要になります。