Erfassen von Apache Spark-Anwendungsprotokollen und -Metriken mithilfe eines Azure Storage-Kontos
Die Diagnoseemittererweiterung von Synapse Apache Spark ist eine Bibliothek, die es der Apache Spark-Anwendung ermöglicht, Protokolle, Ereignisprotokolle und Metriken an ein einzelnes Ziel oder an mehrere Ziele wie Azure Log Analytics, Azure Storage und Azure Event Hubs auszugeben.
In diesem Tutorial erfahren Sie, wie Sie die Diagnoseemittererweiterung von Synapse Apache Spark verwenden, um Protokolle, Ereignisprotokolle und Metriken von Apache Spark-Anwendungen an Ihr Azure-Speicherkonto auszugeben.
Sammeln von Protokollen und Metriken im Speicherkonto
Schritt 1: Erstellen eines Speicherkontos
Diagnoseprotokolle und Metriken können in bereits vorhandenen Azure Storage-Konten gesammelt werden. Sollten Sie über kein Konto verfügen, können Sie ein Azure Blob Storage-Konto oder ein Speicherkonto für die Verwendung mit Azure Data Lake Storage Gen2 erstellen.
Schritt 2: Erstellen einer Apache Spark-Konfigurationsdatei
Erstellen Sie eine Datei namens diagnostic-emitter-azure-storage-conf.txt, und kopieren Sie den folgenden Inhalt in die Datei. Alternativ können Sie eine Beispielvorlagendatei für die Apache Spark-Poolkonfiguration herunterladen.
spark.synapse.diagnostic.emitters MyDestination1
spark.synapse.diagnostic.emitter.MyDestination1.type AzureStorage
spark.synapse.diagnostic.emitter.MyDestination1.categories Log,EventLog,Metrics
spark.synapse.diagnostic.emitter.MyDestination1.uri https://<my-blob-storage>.blob.core.windows.net/<container-name>/<folder-name>
spark.synapse.diagnostic.emitter.MyDestination1.auth AccessKey
spark.synapse.diagnostic.emitter.MyDestination1.secret <storage-access-key>
Geben Sie in der Konfigurationsdatei die folgenden Parameter an: <my-blob-storage>, <container-name>, <folder-name>, <storage-access-key>.
Eine ausführlichere Beschreibung der Parameter finden Sie unter Azure Storage-Konfigurationen.
Schritt 3: Hochladen der Apache Spark-Konfigurationsdatei in Synapse Studio und Verwendung im Spark-Pool
- Öffnen Sie die Apache Spark-Konfigurationsseite (Verwalten –> Apache Spark-Konfigurationen).
- Klicken Sie auf die Schaltfläche Importieren, um die Apache Spark-Konfigurationsdatei in Synapse Studio hochzuladen.
- Navigieren Sie in Synapse Studio zu Ihrem Apache Spark-Pool (Verwalten –> Apache Spark-Pools).
- Klicken Sie rechts neben Ihrem Apache Spark-Pool auf die Schaltfläche ..., und wählen Sie Apache Spark-Konfiguration aus.
- Sie können die soeben hochgeladene Konfigurationsdatei im Dropdownmenü auswählen.
- Klicken Sie auf Anwenden, nachdem Sie die Konfigurationsdatei ausgewählt haben.
Schritt 4: Anzeigen der Protokolldateien im Azure-Speicherkonto
Nachdem Sie einen Auftrag an den konfigurierten Apache Spark-Pool übermittelt haben, sollten die Protokolle und Metrikdateien im Zielspeicherkonto angezeigt werden.
Die Protokolle werden für verschiedene Anwendungen nach dem Muster <workspaceName>.<sparkPoolName>.<livySessionId> in entsprechenden Pfaden platziert.
Alle Protokolldateien liegen im JSON-Zeilenformat – auch „newline-delimited JSON“ (durch Zeilenvorschübe getrennter JSON-Code) oder kurz „ndjson“ genannt – vor, was für die Datenverarbeitung praktisch ist.
Verfügbare Konfigurationen
| Konfiguration | BESCHREIBUNG |
|---|---|
spark.synapse.diagnostic.emitters |
Erforderlich. Kommagetrennte Liste der Zielnamen von Diagnoseemittern. Zum Beispiel, MyDest1,MyDest2 |
spark.synapse.diagnostic.emitter.<destination>.type |
Erforderlich. Integrierter Zieltyp. Um das Azure-Speicherziel zu aktivieren, muss AzureStorage in dieses Feld eingeschlossen werden. |
spark.synapse.diagnostic.emitter.<destination>.categories |
Optional. Kommagetrennte Liste der ausgewählten Protokollkategorien. Verfügbare Werte: DriverLog, ExecutorLog, EventLog, Metrics. Ist diese Option nicht festgelegt, werden standardmäßig alle Kategorien verwendet. |
spark.synapse.diagnostic.emitter.<destination>.auth |
Erforderlich. AccessKey für die Verwendung der Speicherkontoautorisierung per Zugriffsschlüssel. SAS für die Autorisierung mit Shared Access Signatures (SAS). |
spark.synapse.diagnostic.emitter.<destination>.uri |
Erforderlich. Der Ordner-URI des Zielblobcontainers. Muss dem folgenden Muster entsprechen: https://<my-blob-storage>.blob.core.windows.net/<container-name>/<folder-name>. |
spark.synapse.diagnostic.emitter.<destination>.secret |
Optional. Der Inhalt des Geheimnisses: Zugriffsschlüssel (AccessKey) oder SAS. |
spark.synapse.diagnostic.emitter.<destination>.secret.keyVault |
Erforderlich, wenn .secret nicht angegeben wird. Der Name der Azure Key Vault-Instanz, in der das Geheimnis (Zugriffsschlüssel oder SAS) gespeichert ist. |
spark.synapse.diagnostic.emitter.<destination>.secret.keyVault.secretName |
Erforderlich, wenn .secret.keyVault angegeben wird. Der Name des Azure Key Vault-Geheimnisses, in dem das Geheimnis (Zugriffsschlüssel oder SAS) gespeichert ist. |
spark.synapse.diagnostic.emitter.<destination>.secret.keyVault.linkedService |
Optional. Der Name des mit Azure Key Vault verknüpften Diensts. Bei Aktivierung in der Synapse-Pipeline ist dieser Name erforderlich, um das Geheimnis aus AKV abzurufen. (Stellen Sie sicher, dass MSI über Leseberechtigung für AKV verfügt.) |
spark.synapse.diagnostic.emitter.<destination>.filter.eventName.match |
Optional. Kommagetrennte Liste mit Spark-Ereignisnamen, um anzugeben, welche Ereignisse gesammelt werden sollen. Beispiel: SparkListenerApplicationStart,SparkListenerApplicationEnd |
spark.synapse.diagnostic.emitter.<destination>.filter.loggerName.match |
Optional. Kommagetrennte Liste mit log4j-Protokollierungsnamen, um anzugeben, welche Protokolle gesammelt werden sollen. Beispiel: org.apache.spark.SparkContext,org.example.Logger |
spark.synapse.diagnostic.emitter.<destination>.filter.metricName.match |
Optional. Kommagetrennte Liste mit Spark-Metriknamensuffixen, um anzugeben, welche Metriken gesammelt werden sollen. Beispiel: jvm.heap.used |
Beispiel für Protokolldaten
Hier sehen Sie einen exemplarischen Protokolldatensatz im JSON-Format:
{
"timestamp": "2021-01-02T12:34:56.789Z",
"category": "Log|EventLog|Metrics",
"workspaceName": "<my-workspace-name>",
"sparkPool": "<spark-pool-name>",
"livyId": "<livy-session-id>",
"applicationId": "<application-id>",
"applicationName": "<application-name>",
"executorId": "<driver-or-executor-id>",
"properties": {
// The message properties of logs, events and metrics.
"timestamp": "2021-01-02T12:34:56.789Z",
"message": "Registering signal handler for TERM",
"logger_name": "org.apache.spark.util.SignalUtils",
"level": "INFO",
"thread_name": "main"
// ...
}
}
Synapse-Arbeitsbereich mit aktiviertem Schutz vor Datenexfiltration
Azure Synapse Analytics-Arbeitsbereiche unterstützen die Aktivierung des Schutzes vor Datenexfiltration für Arbeitsbereiche. Mit Exfiltrationsschutz können die Protokolle und Metriken nicht direkt an die Zielendpunkte gesendet werden. In diesem Szenario können Sie entsprechende verwaltete private Endpunkte für verschiedene Zielendpunkte erstellen oder IP-Firewallregeln erstellen.
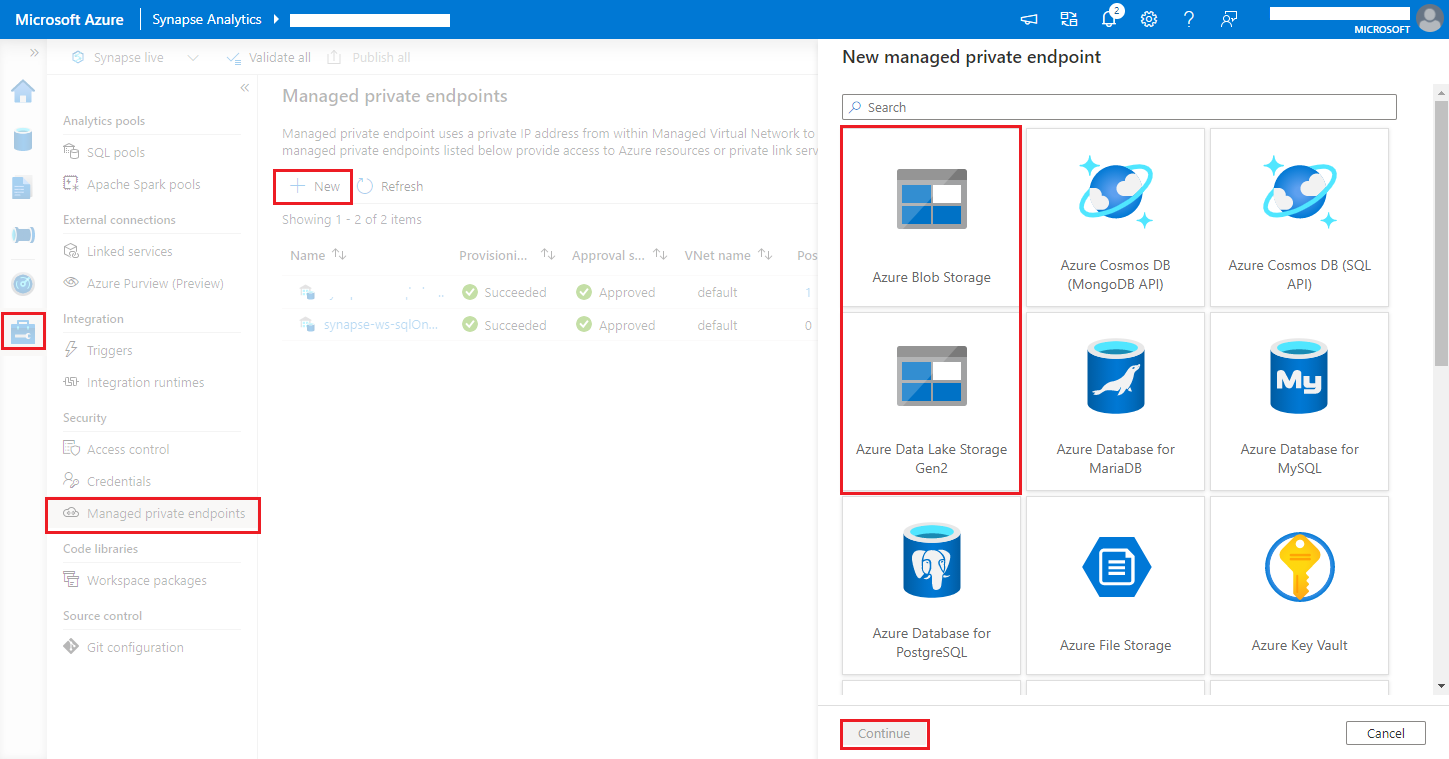
Navigieren Sie zu Synapse Studio > Manage > Managed private endpoints („Synapse Studio“ > „Verwalten“ > „Verwaltete private Endpunkte“). Klicken Sie auf die Schaltfläche New (Neu), und wählen Sie Azure Blob Storage oder Azure Data Lake Storage Gen2 und anschließend Continue (Weiter) aus.
Hinweis
Sowohl Azure Blob Storage als auch Azure Data Lake Storage Gen2 werden unterstützt. Aber wir konnten das abfss://-Format nicht parsen. Azure Data Lake Storage Gen2-Endpunkte sollten als Blob-URL formatiert werden:
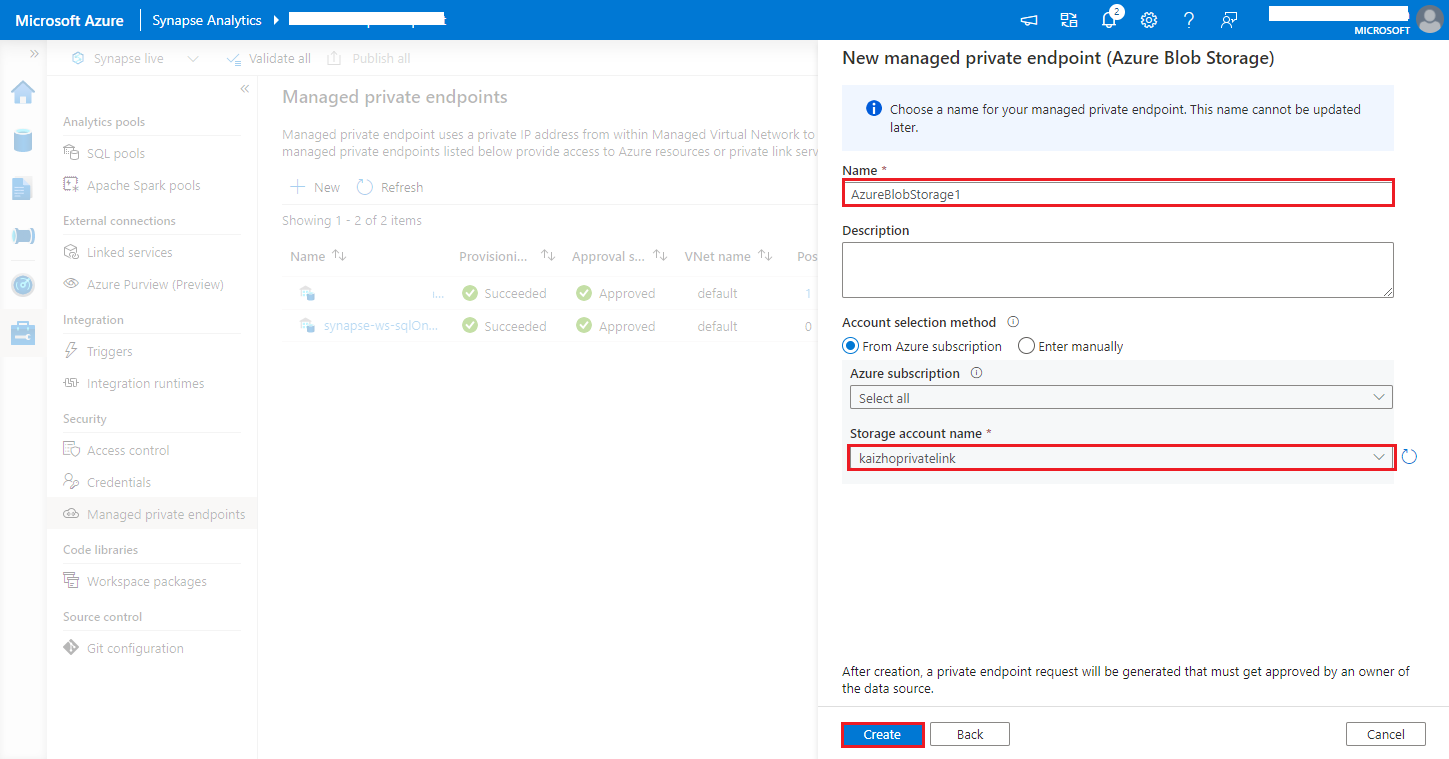
https://<my-blob-storage>.blob.core.windows.net/<container-name>/<folder-name>Wählen Sie unter Storage account name (Speicherkontoname) Ihr Azure Storage-Konto aus, und klicken Sie auf die Schaltfläche Create (Erstellen).
Die Bereitstellung des privaten Endpunkts dauert einige Minuten.
Navigieren Sie im Azure-Portal zu Ihrem Speicherkonto. Wählen Sie unter Netzwerk>Private Endpunktverbindungen die bereitgestellte Verbindung und anschließend Genehmigen aus.