Kusto-Abfragesprache in Microsoft Sentinel
Die Kusto-Abfragesprache ist die Sprache, die Sie verwenden, um in Microsoft Sentinel mit Daten zu arbeiten und diese zu bearbeiten. Die Protokolle, die Sie in Ihren Arbeitsbereich einspeisen, sind nicht viel wert, wenn Sie sie nicht analysieren können und wenn Sie die wichtigen Informationen nicht extrahieren können, die in all diesen Daten verborgen sind. Die Kusto-Abfragesprache bietet nicht nur die zum Abrufen dieser Informationen notwendige Leistungsfähigkeit und Flexibilität, sondern auch die Einfachheit, die Ihnen den schnellen Einstieg erleichtert. Wenn Sie über einen Hintergrund in der Skripterstellung oder der Arbeit mit Datenbanken verfügen, wird Ihnen ein Großteil des Inhalts dieses Artikels sehr vertraut sein. Falls nicht, ist dies kein Grund zur Sorge, da die intuitive Natur der Sprache Ihnen ermöglicht, schnell eigene Abfragen zu schreiben und den Nutzen für Ihre Organisation zu steigern.
In diesem Artikel werden die Grundlagen der Kusto-Abfragesprache vorgestellt. Dabei werden einige der am häufigsten verwendeten Funktionen und Operatoren behandelt, die 75 bis 80 Prozent der Abfragen abdecken sollten, die Sie im Tagesgeschäft benötigen. Wenn Sie sich eingehender informieren oder komplexere Abfragen ausführen möchten, können Sie die neue Arbeitsmappe zum Thema Erweiterte KQL für Microsoft Sentinel nutzen (siehe diesen Blogbeitrag zur Einführung). Weitere Informationen finden Sie auch in der offiziellen Dokumentation zur Kusto-Abfragesprache sowie in einer Vielzahl von Onlinekursen (z. B. von Pluralsight).
Hintergrund – Gründe für die Kusto-Abfragesprache
Microsoft Sentinel baut auf dem Azure Monitor-Dienst auf und verwendet zum Speichern aller Daten die Log Analytics-Arbeitsbereiche von Azure Monitor. Zu diesen Daten gehören folgende:
- Daten, die mithilfe von Microsoft Sentinel-Datenconnectors aus externen Quellen in vordefinierten Tabellen erfasst werden
- Daten, die mithilfe von benutzerdefinierten Datenconnectors sowie einigen Typen von gebrauchsfertigen Connectors aus externen Quellen in benutzerdefinierten Tabellen erfasst werden
- Von Microsoft Azure Sentinel selbst erstellte Daten, die sich aus den von Sentinel erstellten und ausgeführten Analysen ergeben, z. B. Warnungen, Incidents und UEBA-bezogene (User Entity Behavior Analytics) Informationen
- Daten, die zur Unterstützung bei der Erkennung und Analyse in Microsoft Sentinel hochgeladen werden, z. B. Threat Intelligence-Feeds und Watchlists
Die Kusto-Abfragesprache wurde als Teil des Azure Data Explorer-Diensts entwickelt und ist daher für die Suche nach Big Data-Speichern in einer Cloudumgebung optimiert. Sie verdankt ihre Inspiration dem berühmten Unterwasserforscher Jacques Cousteau (und wird deshalb auch „ku-STOH“ ausgesprochen). Die Abfragesprache soll Ihnen dabei helfen, in die Tiefen Ihrer Daten hinabzutauchen und ihre verborgenen Schätze zu heben.
Die Kusto-Abfragesprache wird auch in Azure Monitor (und somit in Microsoft Sentinel) verwendet, einschließlich einiger zusätzlicher Azure Monitor-Features zum Abrufen, Visualisieren und Analysieren von Daten in Log Analytics-Datenspeichern. In Microsoft Sentinel verwenden Sie Tools, die auf der Kusto-Abfragesprache basieren, immer dann, wenn Sie Daten visualisieren und analysieren und nach Bedrohungen suchen, sei es in vorhandenen Regeln und Arbeitsmappen oder beim Erstellen eigener.
Da die Kusto-Abfragesprache ein Teil von fast allen Arbeitsvorgängen in Microsoft Sentinel ist, hilft Ihnen ein klares Verständnis der Funktionsweise dieser Abfragesprache dabei, Ihr SIEM-System noch weiter zu optimieren.
Was ist eine Abfrage?
Eine Abfrage in der Kusto-Abfragesprache ist eine schreibgeschützte Anforderung zum Verarbeiten von Daten und Zurückgeben von Ergebnissen. Daten werden dabei keine geschrieben. Abfragen werden in Bezug auf Daten ausgeführt, die in einer SQL-ähnlichen Hierarchie von Datenbanken, Tabellen und Spalten organisiert sind.
Anforderungen werden in einfacher Sprache formuliert. Dabei wird ein Datenflussmodell verwendet, mit dem das Lesen, Schreiben und Automatisieren der Syntax vereinfacht wird. Dies wird noch im Detail erläutert.
Abfragen der Kusto-Abfragesprache bestehen aus Anweisungen, die durch Semikolons getrennt sind. Es gibt viele Arten von Anweisungen, aber nur zwei häufig verwendete Typen, die hier behandelt werden:
Tabellarische Ausdrucksanweisungen sind das, was in der Regel gemeint ist, wenn von einer Abfrage die Rede ist: der tatsächliche Text der Abfrage. Das Wichtigste an tabellarischen Ausdrucksanweisungen ist, dass sie eine tabellarische Eingabe (eine Tabelle oder einen anderen tabellarischen Ausdruck) akzeptieren und eine tabellarische Ausgabe von ihnen generiert werden kann. Mindestens eines davon ist erforderlich. Im größten noch verbliebenen Teil dieses Artikels wird diese Art von Anweisung erläutert.
Let-Anweisungen ermöglichen es Ihnen, Variablen und Konstanten außerhalb des Abfragetexts zu erstellen und zu definieren, um die Lesbarkeit und Flexibilität zu vereinfachen. Diese Anweisungen sind optional und hängen von Ihren speziellen Anforderungen ab. Diese Art von Anweisung wird am Ende des Artikels behandelt.
Demoumgebung
Sie können mit Anweisungen der Kusto-Abfragesprache, einschließlich der in diesem Artikel erläuterten, in einer Log Analytics-Demoumgebung im Azure-Portal üben. Es fällt keine Gebühr für die Verwendung dieser Übungsumgebung an, aber Sie benötigen ein Azure-Konto, um darauf zugreifen zu können.
Machen Sie sich mit der Demoumgebung vertraut. Wie Log Analytics in der Produktionsumgebung kann das System auf verschiedene Weise verwendet werden:
Auswählen einer Tabelle, für die eine Abfrage erstellt werden soll. Wählen Sie auf der Standardregisterkarte Tabellen (dargestellt im roten Rechteck oben links) eine Tabelle aus der Liste der Tabellen aus, die nach Themen gruppiert sind (unten links dargestellt). Erweitern Sie die Themen, um die einzelnen Tabellen anzuzeigen. Sie können darüber hinaus jede Tabelle erweitern, um alle zugehörigen Felder (Spalten) anzuzeigen. Doppelklicken Sie auf die Namen von Tabellen oder Feldern, um sie an der Stelle des Cursors im Abfragefenster zu platzieren. Geben Sie den Rest der Abfrage wie unten angegeben nach dem Tabellennamen ein.
Nach einer vorhandenen Abfrage suchen, die Sie untersuchen oder ändern möchten. Wählen Sie die Registerkarte Abfragen (im roten Rechteck oben links) aus, um eine Liste der sofort verfügbaren Abfragen anzuzeigen. Oder wählen Sie in der Schaltflächenleiste oben rechts Abfragen aus. Sie können die Abfragen untersuchen, die in Microsoft Sentinel sofort einsatzbereit sind. Wenn Sie auf eine Abfrage doppelklicken, wird die gesamte Abfrage im Abfragefenster an der Stelle des Cursors platziert.
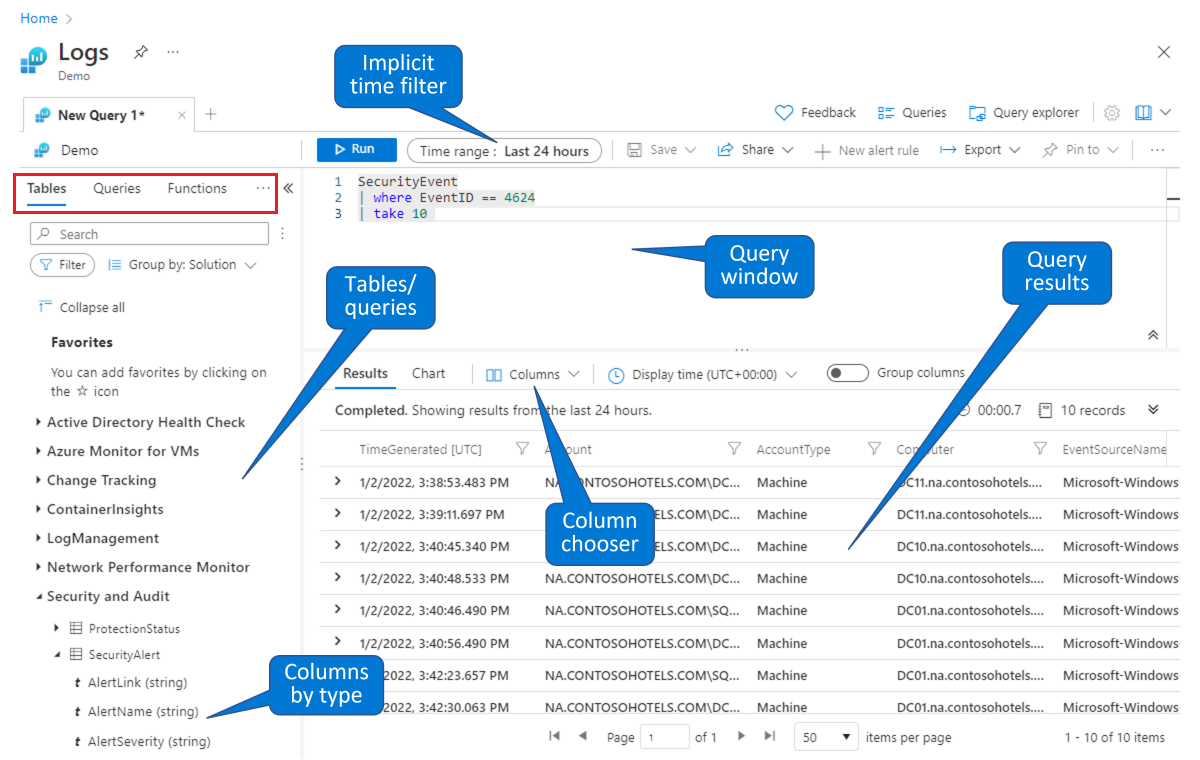
Wie in dieser Demoumgebung können Sie Daten auf der Seite Protokolle von Microsoft Azure Sentinel abfragen und filtern. Sie können eine Tabelle auswählen und einen Drilldown zum Anzeigen von Spalten ausführen. Sie können die angezeigten Standardspalten mithilfe der Spaltenauswahl ändern und den Standardzeitbereich für Abfragen festlegen. Wenn der Zeitbereich explizit in der Abfrage definiert ist, ist der Zeitfilter nicht verfügbar (abgeblendet).
Abfragestruktur
Ein guter Ausgangspunkt für das Erlernen der Kusto-Abfragesprache ist es, die allgemeine Abfragestruktur zu verstehen. Das erste, was Sie beim Betrachten einer Kusto-Abfrage bemerken werden, ist die Verwendung des senkrechten Strichs (|). Die Struktur einer Kusto-Abfrage beginnt mit dem Abrufen von Daten aus einer Datenquelle und dem anschließenden Übergeben der Daten mittels einer „Pipeline“. Bei jedem Schritt findet ein gewissen Maß an Verarbeitung statt. Schließlich werden die Daten an den nächsten Schritt übergeben. Am Ende der Pipeline erhalten Sie das Endergebnis. Die Pipeline sieht de facto wie folgt aus:
Get Data | Filter | Summarize | Sort | Select
Dieses Konzept der Weitergabe von Daten entlang der Pipeline sorgt für eine sehr intuitive Struktur, da es einfach ist, bei jedem Schritt ein mentales Bild der Daten zu erstellen.
Zur Veranschaulichung wird die folgende Abfrage erläutert, die sich mit Microsoft Entra ID-Anmeldungsprotokolle befasst. Wenn Sie die einzelnen Zeilen lesen, können Sie die Schlüsselwörter sehen, die angeben, was mit den Daten geschieht. Die relevante Phase wurde jeweils als Kommentar in die einzelnen Zeilen der Pipeline eingefügt.
Hinweis
Sie können jeder Zeile in einer Abfrage Kommentare hinzufügen, indem Sie ihnen einen doppelten Schrägstrich voranstellen (//).
SigninLogs // Get data
| evaluate bag_unpack(LocationDetails) // Ignore this line for now; we'll come back to it at the end.
| where RiskLevelDuringSignIn == 'none' // Filter
and TimeGenerated >= ago(7d) // Filter
| summarize Count = count() by city // Summarize
| sort by Count desc // Sort
| take 5 // Select
Da die Ausgabe jedes Schritts als Eingabe für den folgenden Schritt dient, kann die Reihenfolge der Schritte die Ergebnisse der Abfrage bestimmen und sich auf die Leistung auswirken. Es ist entscheidend, dass Sie die Schritte entsprechend den Informationen anordnen, die Sie mittels der Abfrage extrahieren möchten.
Tipp
- Eine gute Faustregel besteht darin, die Daten frühzeitig zu filtern, sodass Sie nur relevante Daten an die Pipeline übergeben. Dies erhöht die Leistung erheblich und stellt sicher, dass Sie nicht versehentlich irrelevante Daten in Zusammenfassungsschritte aufnehmen.
- In diesem Artikel werden einige andere Best Practices erläutert, die Sie beachten sollten. Eine ausführlichere Liste finden Sie unter Best Practices für Abfragen.
Sie sind jetzt hoffentlich mit der Gesamtstruktur einer Abfrage in der Kusto-Abfragesprache vertraut. Als Nächstes werden die eigentlichen Abfrageoperatoren behandelt, die zum Erstellen einer Abfrage verwendet werden.
Datentypen
Bevor die Abfrageoperatoren erläutert werden, werden zunächst die Datentypen beschrieben. Wie in den meisten Sprachen bestimmt der Datentyp, welche Berechnungen und Bearbeitungen für einen Wert ausgeführt werden können. Wenn Sie beispielsweise über einen Wert vom Typ Zeichenfolge verfügen, können Sie keine arithmetischen Berechnungen dafür ausführen.
In der Kusto-Abfragesprache entsprechen die meisten Datentypen den Standardkonventionen und weisen Namen auf, die Sie wahrscheinlich schon gesehen haben. Die folgende Tabelle umfasst die vollständige Liste:
Datentyptabelle
| type | Weitere(r) Name(n) | Entsprechender .NET-Typ |
|---|---|---|
bool |
Boolean |
System.Boolean |
datetime |
Date |
System.DateTime |
dynamic |
System.Object |
|
guid |
uuid, uniqueid |
System.Guid |
int |
System.Int32 |
|
long |
System.Int64 |
|
real |
Double |
System.Double |
string |
System.String |
|
timespan |
Time |
System.TimeSpan |
decimal |
System.Data.SqlTypes.SqlDecimal |
Bei den meisten Datentypen handelt es sich zwar um Standardtypen, aber mit Typen wie dynamic, timespan und guid dürften Sie weniger vertraut sein.
Dynamic weist eine Struktur auf, die dem JSON-Format sehr ähnlich ist, aber mit einem wichtigen Unterschied: In der Struktur können für die Kusto-Abfragesprache spezifische Datentypen gespeichert werden, wie es im herkömmlichen JSON-Format nicht möglich ist, z. B. ein geschachtelter Wert vom Typ dynamic oder der Datentyp timespan. Hier sehen Sie ein Beispiel für den Datentyp „dynamic“:
{
"countryOrRegion":"US",
"geoCoordinates": {
"longitude":-122.12094116210936,
"latitude":47.68050003051758
},
"state":"Washington",
"city":"Redmond"
}
Timespan ist ein Datentyp, der sich auf ein Maß für die Zeit bezieht, z. B. Stunden, Tage oder Sekunden. Verwechseln Sie timespan nicht mit datetime. Dieser Typ wird zu einem tatsächlichen Datum und einer tatsächlichen Uhrzeit ausgewertet, nicht als Maß für die Zeit. Die folgende Tabelle enthält eine Liste von timespan-Suffixen.
Timespan-Suffixe
| Funktion | BESCHREIBUNG |
|---|---|
D |
days |
H |
Stunden |
M |
minutes |
S |
Sekunden |
Ms |
Millisekunden |
Microsecond |
Mikrosekunden |
Tick |
Nanosekunden |
Guid ist ein Datentyp, der einen global eindeutigen 128-Bit-Bezeichner darstellt, der dem Standardformat [8]-[4]-[4]-[4]-[12] folgt, wobei jede [Zahl] die Anzahl der Zeichen darstellt und jedes Zeichen zwischen 0 und 9 oder a und f liegen kann.
Hinweis
Die Kusto-Abfragesprache verfügt sowohl über tabellarische als auch über skalare Operatoren. Wenn Sie im weiteren Verlauf dieses Artikels das Wort „Operator“ lesen, können Sie davon ausgehen, dass es sich um einen tabellarischen Operator handelt, sofern nichts anderes angegeben ist.
Abrufen, Einschränken, Sortieren und Filtern von Daten
Das Kernvokabular der Kusto-Abfragesprache – die Grundlage, die es Ihnen ermöglicht, die überwiegende Anzahl Ihrer Aufgaben zu erledigen – ist eine Sammlung von Operatoren zum Filtern, Sortieren und Auswählen von Daten. Die verbleibenden Aufgaben, die Sie ausführen müssen, erfordern, dass Sie Ihre Kenntnisse der Sprache erweitern, um komplexeren Anforderungen gerecht werden zu können. Dazu werden über die Befehle hinausgehend, die im obigen Beispiel verwendet wurden, die Operatoren take, sort und where behandelt.
Für jeden dieser Operatoren wird die Verwendung im vorherigen SigninLogs-Beispiel untersucht. Daneben lernen Sie entweder einen nützlichen Tipp oder eine bewährte Methode kennen.
Abrufen von Daten
In der ersten Zeile einer einfachen Abfrage wird angegeben, mit welcher Tabelle Sie arbeiten möchten. Im Fall von Microsoft Sentinel ist dies wahrscheinlich der Name eines Protokolltyps im Arbeitsbereich, z. B. SigninLogs, SecurityAlert oder CommonSecurityLog. Beispiel:
SigninLogs
Beachten Sie, dass in der Kusto-Abfragesprache bei Protokollnamen zwischen Groß-/Kleinbuchstaben unterschieden wird, sodass SigninLogs und signinLogs anders interpretiert werden. Achten Sie beim Auswählen von Namen für benutzerdefinierte Protokolle darauf, dass sie leicht identifizierbar sind und anderen Protokollen nicht zu stark ähneln.
Begrenzen von Daten: take / limit
Der take-Operator (und der identische limit-Operator) wird dazu verwendet, Ergebnisse einzuschränken, indem nur eine bestimmte Anzahl von Zeilen zurückgegeben wird. Darauf folgt eine ganze Zahl, die die Anzahl der zurückzugebenden Zeilen angibt. In der Regel wird der Operator am Ende einer Abfrage verwendet, nachdem Sie die Sortierreihenfolge bestimmt haben, und in einem solchen Fall gibt der Operator die angegebene Anzahl von Zeilen oben in der sortierten Reihenfolge zurück.
Die Verwendung von take weiter oben in der Abfrage kann nützlich sein, wenn Sie eine Abfrage testen möchten, weil keine großen Datasets zurückgegeben werden sollen. Wenn Sie den Vorgang take jedoch vor einem sort-Vorgang platzieren, werden mit take nach dem Zufallsprinzip ausgewählte Zeilen zurückgegeben – bei jeder Ausführung der Abfrage möglicherweise eine andere Gruppe von Zeilen. Nachstehend ist ein Beispiel für die Verwendung von „take“ aufgeführt:
SigninLogs
| take 5
Tipp
Wenn Sie an einer völlig neuen Abfrage arbeiten, bei der Sie möglicherweise nicht wissen, wie die Abfrage aussehen wird, kann es hilfreich sein, eine take-Anweisung an den Anfang zu setzen, um das Dataset für eine schnellere Verarbeitung und Experimente zu beschränken. Sobald Sie mit der vollständigen Abfrage zufrieden sind, können Sie den ersten take-Schritt entfernen.
Sortieren von Daten: sort / order
Der sort-Operator (und der identische order-Operator) wird dazu verwendet, die Daten nach einer angegebenen Spalte zu sortieren. Im folgenden Beispiel wurden die Ergebnisse nach TimeGenerated sortiert, und die Reihenfolge wurde mit dem Desc-Parameter auf „absteigend“ festgelegt, wobei die höchsten Werte an erster Stelle platziert werden. Für eine aufsteigende Reihenfolge würde der Parameter asc verwendet.
Hinweis
Die Standardrichtung für Sortierungen ist absteigend. Daher müssen Sie technisch gesehen nur angeben, wenn Sie Daten in aufsteigender Reihenfolge sortieren möchten. Wenn Sie jedoch in jedem Fall die Sortierrichtung angeben, wird die Abfrage leichter lesbar.
SigninLogs
| sort by TimeGenerated desc
| take 5
Wie bereits erwähnt, wird der sort-Operator vor den take-Operator gesetzt. Zunächst müssen die Daten sortiert werden, damit gewährleistet ist, dass die entsprechenden fünf Datensätze abgerufen werden.
Top
Der top-Operator ermöglicht es, die Vorgänge sort und take in einem einzigen Operator zu kombinieren:
SigninLogs
| top 5 by TimeGenerated desc
In Fällen, in denen zwei oder mehr Datensätze denselben Wert in der Spalte aufweisen, nach der Sie sortieren, können Sie weitere Spalten hinzufügen, nach denen sortiert werden soll. Fügen Sie zusätzliche Sortierspalten in einer durch Kommas getrennten Liste hinzu, die sich nach der ersten Sortierspalte befinden, aber vor dem Schlüsselwort für die Sortierreihe. Beispiel:
SigninLogs
| sort by TimeGenerated, Identity desc
| take 5
Wenn TimeGenerated zwischen mehreren Datensätzen identisch ist, wird versucht, nach dem Wert in der Spalte Identity zu sortieren.
Hinweis
Wann sort und take und wann top verwendet wird
Wenn Sie nur nach einem einzigen Feld sortieren, verwenden Sie
top, da damit eine bessere Leistung erreicht wird als mit der Kombination vonsortundtake.Wenn Sie nach mehr als einem Feld sortieren müssen (wie im letzten Beispiel oben), ist dies mit
topnicht möglich. Daher müssen Sie in diesem Fallsortundtakeverwenden.
Filtern von Daten: where
Der where-Operator ist wohl der wichtigste Operator, da er der Schlüssel dafür ist, dass Sie wirklich nur mit der Teilmenge der Daten arbeiten, die für Ihr Szenario relevant sind. Sie sollten die Daten so früh wie möglich in der Abfrage filtern, da dies die Abfrageleistung verbessert, indem die Menge der Daten reduziert wird, die in den nachfolgenden Schritten verarbeitet werden müssen. Außerdem wird so sichergestellt, dass Sie nur Berechnungen für die gewünschten Daten ausführen. Beispiel:
SigninLogs
| where TimeGenerated >= ago(7d)
| sort by TimeGenerated, Identity desc
| take 5
Mit dem where-Operator wird eine Variable, ein Vergleichsoperator (skalar) und ein Wert angegeben. In diesem Fall wurde mit >= angegeben, dass der Wert in der Spalte TimeGenerated größer als (d. h. später als) oder gleich dem Zeitpunkt vor sieben Tagen sein muss.
In der Kusto-Abfragesprache gibt es zwei Arten von Vergleichsoperatoren: Zeichenfolge und numerisch. Die folgende Tabelle enthält die vollständige Liste der numerischen Operatoren:
Numerische Operatoren
| Operator | BESCHREIBUNG |
|---|---|
+ |
Addition |
- |
Subtraktion |
* |
Multiplikation |
/ |
Division |
% |
Modulo |
< |
Kleiner als |
> |
Größer als |
== |
Gleich |
!= |
Ungleich |
<= |
Kleiner als oder gleich |
>= |
Größer als oder gleich |
in |
Entspricht einem der Elemente |
!in |
Entspricht keinem Element |
Die Liste der Zeichenfolgenoperatoren ist eine viel längere Liste, da sie über Permutationen für Groß-/kleinschreibung, Teilzeichenfolgenpositionen, Präfixe, Suffixe und vieles mehr verfügt. Der ==-Operator ist sowohl ein numerischer Operator als auch ein Zeichenfolgenoperator. Das heißt, er kann sowohl für Zahlen als auch für Text verwendet werden. Beispielsweise sind die beiden folgenden Anweisungen gültige where-Anweisungen:
| where ResultType == 0| where Category == 'SignInLogs'
Tipp
Bewährte Methode: In den meisten Fällen möchten Sie die Daten wahrscheinlich nach mehr als einer Spalte filtern oder dieselbe Spalte nach mehreren Kriterien filtern. In diesen Fällen gibt es zwei bewährte Methoden, die Sie beachten sollten.
Sie können mehrere where-Anweisungen in einem einzigen Schritt kombinieren, indem Sie das Schlüsselwort and verwenden. Beispiel:
SigninLogs
| where Resource == ResourceGroup
and TimeGenerated >= ago(7d)
Wenn Sie wie oben mithilfe des Schlüsselworts and mehrere Filter in eine einzelne where-Anweisung einbinden, erzielen Sie eine bessere Leistung, wenn Sie Filter, die nur auf eine einzelne Spalte verweisen, an erster Stelle platzieren. Eine bessere Möglichkeit zum Schreiben der obigen Abfrage wäre also folgende:
SigninLogs
| where TimeGenerated >= ago(7d)
and Resource == ResourceGroup
In diesem Beispiel verweist der erste Filter auf eine einzelne Spalte (TimeGenerated), während der zweite auf zwei Spalten verweist (Resource und ResourceGroup).
Zusammenfassen von Daten
Summarize ist einer der wichtigsten tabellarischen Operatoren in der Kusto-Abfragesprache, aber auch einer der komplexeren Operatoren, mit dem Sie sich nicht so leicht vertraut machen werden, wenn Sie sich mit Abfragesprachen im Allgemeinen noch nicht so gut auskennen. Mit summarize soll eine Tabelle mit Daten eingespeist und eine neue Tabelle ausgegeben werden, die anhand von einer oder mehreren Spalten aggregiert wird.
Struktur der summarize-Anweisung
Die grundlegende Struktur einer summarize-Anweisung sieht folgendermaßen aus:
| summarize <aggregation> by <column>
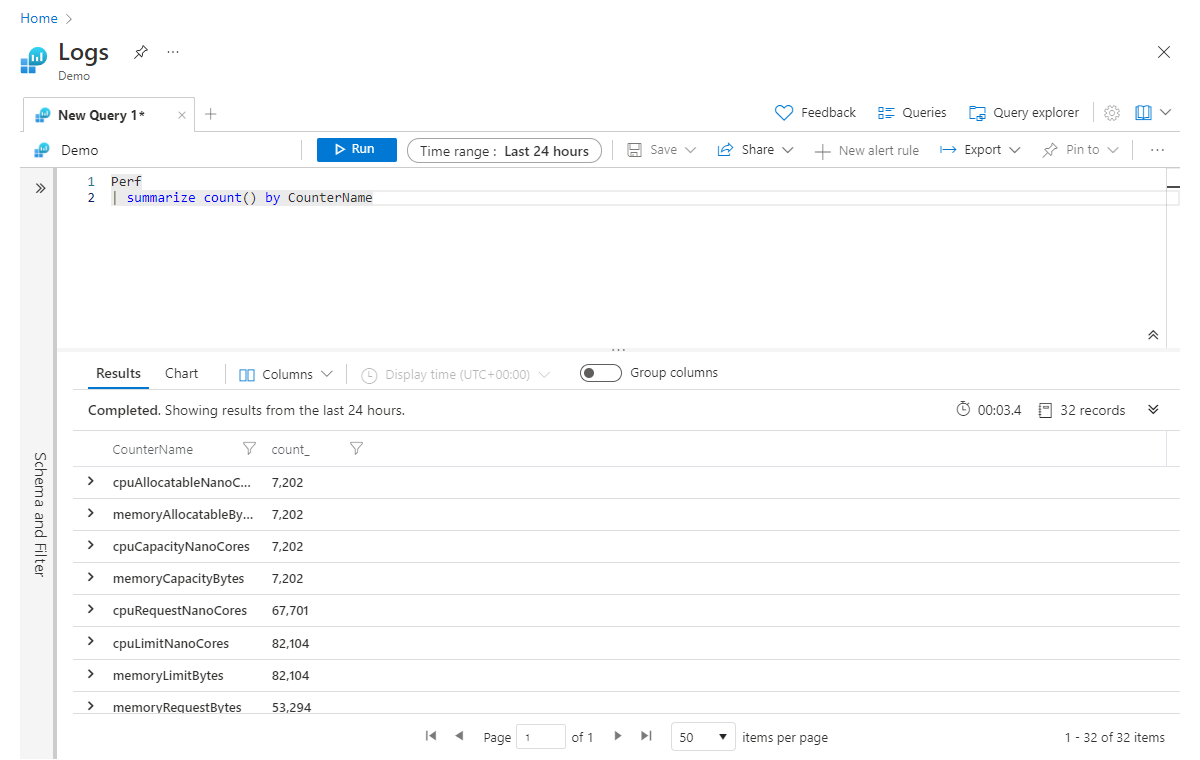
Mit folgender Anweisung würde beispielsweise die Anzahl der Datensätze für jeden CounterName-Wert in der Perf-Tabelle zurückgegeben:
Perf
| summarize count() by CounterName
Da die Ausgabe von summarize eine neue Tabelle ist, werden Spalten, die nicht explizit in der summarize-Anweisung angegeben sind, nicht an die Pipeline übergeben. Sehen Sie sich dieses Beispiel an, in dem dieses Konzept veranschaulicht wird:
Perf
| project ObjectName, CounterValue, CounterName
| summarize count() by CounterName
| sort by ObjectName asc
In der zweiten Zeile wird angegeben, dass nur die Spalten ObjectName, CounterValue und CounterName von Interesse sind. Anschließend wird mit der summarize-Anweisung die Datensatzanzahl nach CounterName abgerufen. Dann wird versucht, die Daten in aufsteigender Reihenfolge basierend auf der Spalte ObjectName zu sortieren. Leider schlägt diese Abfrage mit einem Fehler fehl (mit dem Hinweis, dass objectName unbekannt ist), da bei der Zusammenfassung mit summarize nur die Spalten Count und CounterName in die neue Tabelle aufgenommen wurden. Zur Vermeidung dieses Fehlers können Sie einfach ObjectName wie folgt am Ende des summarize-Schritts hinzufügen:
Perf
| project ObjectName, CounterValue , CounterName
| summarize count() by CounterName, ObjectName
| sort by ObjectName asc
Sie könnten die summarize-Zeile folgendermaßen für sich im Kopf lesen: „Die Anzahl der Datensätze nach CounterName zusammenfassen und nach ObjectName gruppieren“. Sie können am Ende der summarize-Anweisung weitere Spalten hinzufügen, die jeweils durch Kommas getrennt sind.
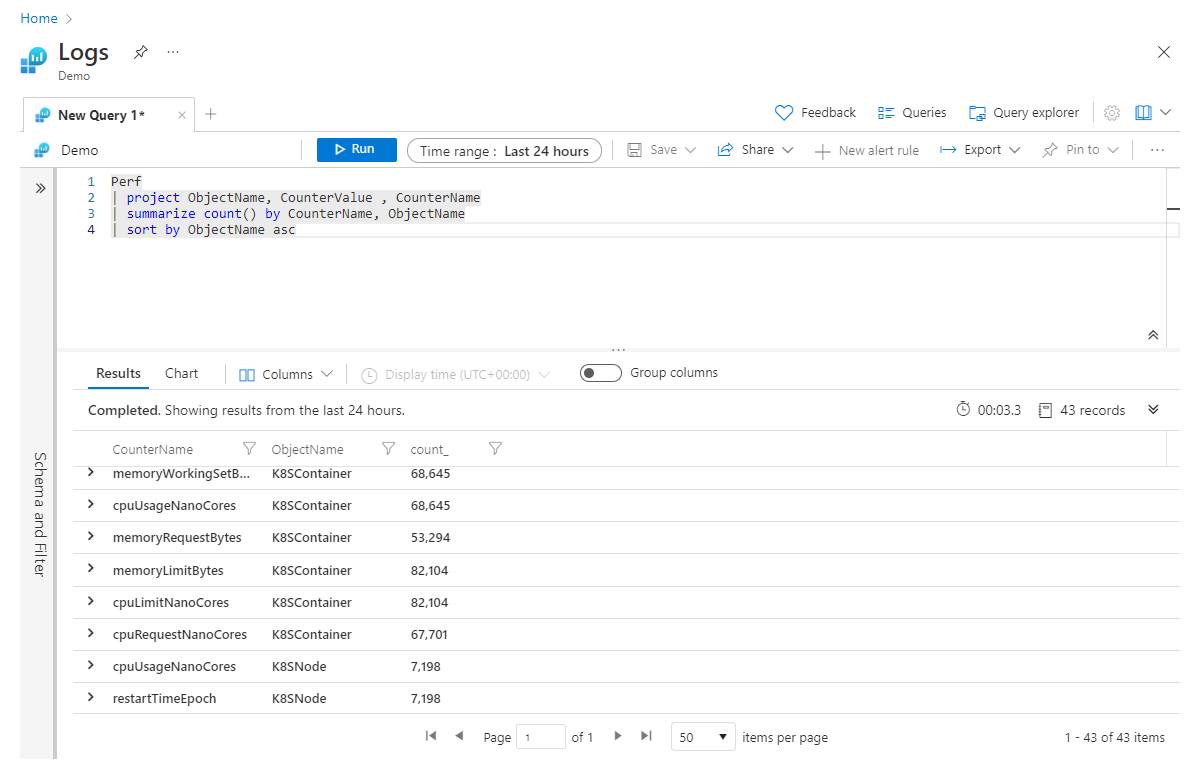
Wenn aufbauend auf dem vorherigen Beispiel mehrere Spalten gleichzeitig aggregiert werden sollen, können Sie dies erreichen, indem Sie dem summarize-Operator Aggregationen hinzufügen, die durch Kommas getrennt sind. Im folgenden Beispiel wird nicht nur die Anzahl aller Datensätze abgerufen, sondern auch eine Summe der Werte in der Spalte CounterValue für alle Datensätze (die mit beliebigen Filtern in der Abfrage übereinstimmen):
Perf
| project ObjectName, CounterValue , CounterName
| summarize count(), sum(CounterValue) by CounterName, ObjectName
| sort by ObjectName asc
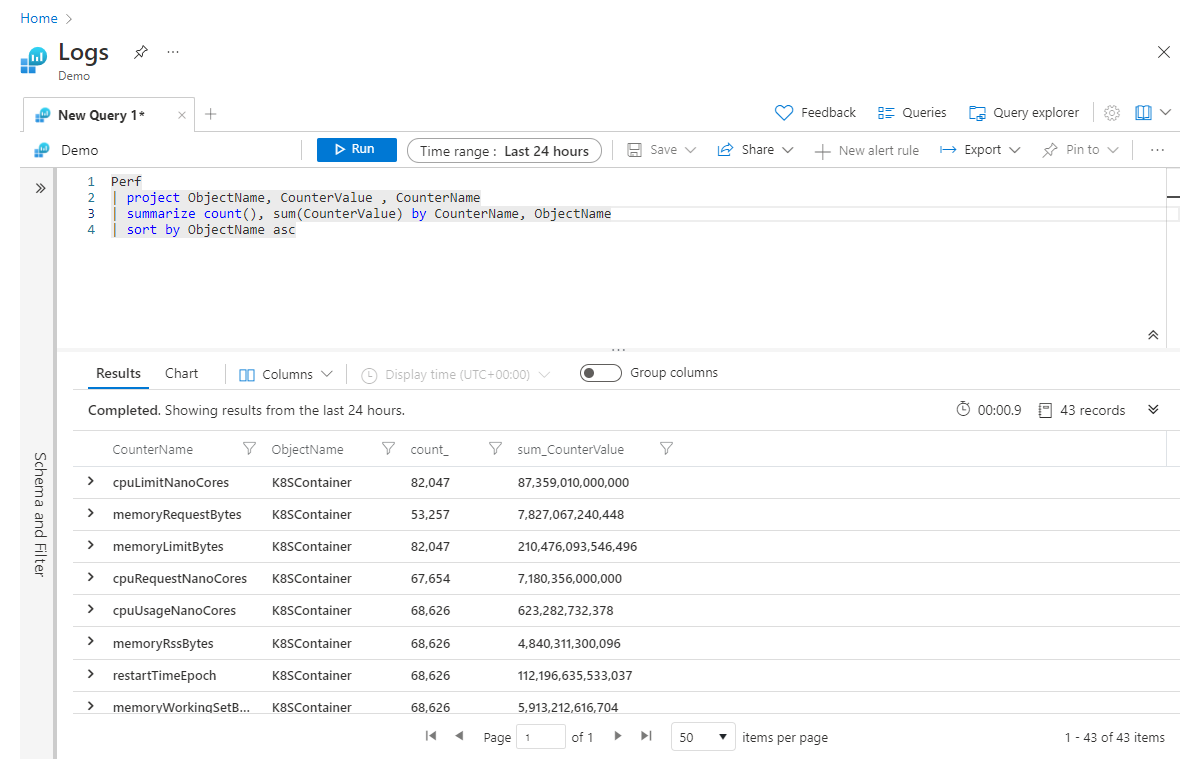
Umbenennen aggregierter Spalten
An dieser Stelle ist es sinnvoll, das Thema von Spaltennamen für diese aggregierten Spalten zu behandeln. Am Anfang dieses Abschnitts wurde erläutert, dass mit dem summarize-Operator eine Tabelle mit Daten eingespeist und eine neue Tabelle generiert wird und dass nur die Spalten, die Sie in der summarize-Anweisung angeben, in der Pipeline weitergegeben werden. Wenn Sie das obige Beispiel ausführen würden, würden daher die resultierenden Spalten für die Aggregation count_ und sum_CounterValue sein.
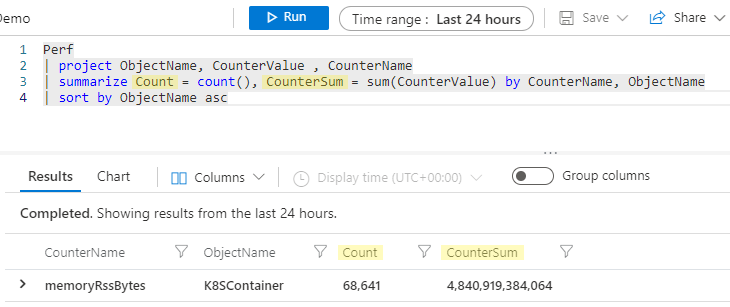
Von der Kusto-Engine wird automatisch ein Spaltenname erstellt, ohne dass der Benutzer diesen explizit ändern muss. Häufig werden Sie den Namen der neuen Spalte jedoch aussagekräftiger anlegen wollen. Sie können die Spalte in der summarize-Anweisung problemlos umbenennen, indem Sie einen neuen Namen, gefolgt von = und der Aggregation, wie folgt angeben:
Perf
| project ObjectName, CounterValue , CounterName
| summarize Count = count(), CounterSum = sum(CounterValue) by CounterName, ObjectName
| sort by ObjectName asc
Nun heißen die zusammengefassten Spalten Count und CounterSum.
Über den summarize-Operator gibt es viel mehr zu sagen, als hier behandelt werden kann, aber Sie sollten die Zeit investieren, sich eingehender damit vertraut zu machen, da er eine wichtige Komponente für jede Datenanalyse ist, die Sie für Microsoft Sentinel-Daten durchführen möchten.
Referenz für Aggregationen
Es gibt viele Aggregationsfunktionen, aber einige der am häufigsten verwendeten sind sum(), count() und avg(). Nachstehend ist eine unvollständige Liste aufgeführt (siehe die vollständige Liste):
Aggregationsfunktionen
| Funktion | BESCHREIBUNG |
|---|---|
arg_max() |
Gibt mindestens einen Ausdruck zurück, wenn das Argument maximiert ist. |
arg_min() |
Gibt mindestens einen Ausdruck zurück, wenn das Argument minimiert ist. |
avg() |
Gibt einen Durchschnittswert für die Gruppe zurück. |
buildschema() |
Gibt das minimale Schema zurück, das alle Werte der dynamischen Eingabe zulässt. |
count() |
Gibt eine Anzahl der Gruppe zurück. |
countif() |
Gibt eine Anzahl mit dem Prädikat der Gruppe zurück. |
dcount() |
Gibt eine ungefähre eindeutige Anzahl der Gruppenelemente zurück. |
make_bag() |
Gibt einen Eigenschaftenbehälter dynamischer Werte in der Gruppe zurück. |
make_list() |
Gibt eine Liste aller Werte in der Gruppe zurück. |
make_set() |
Gibt einen Satz unterschiedlicher Werte in der Gruppe zurück. |
max() |
Gibt den Höchstwert in der Gruppe zurück. |
min() |
Gibt den Mindestwert in der Gruppe zurück. |
percentiles() |
Gibt das ungefähre Quantil der Gruppe zurück. |
stdev() |
Gibt die Standardabweichung für die Gruppe zurück. |
sum() |
Gibt die Summe der Elemente in der Gruppe zurück. |
take_any() |
Gibt einen zufälligen, nicht leeren Wert für die Gruppe zurück. |
variance() |
Gibt die Varianz für die Gruppe zurück. |
Auswählen: Hinzufügen und Entfernen von Spalten
Sobald Sie mehr mit Abfragen arbeiten, stellen Sie möglicherweise fest, dass Sie über mehr Informationen verfügen, als Sie zu den jeweiligen Themen benötigen (d. h. zu viele Spalten in der Tabelle). Vielleicht benötigen Sie aber auch mehr Informationen als Sie haben (d. h. Sie müssen eine neue Spalte hinzufügen, die die Ergebnisse aus der Analyse anderer Spalten enthält). Im Folgenden werden einige der Schlüsseloperatoren für die Arbeit mit Spalten erläutert.
Project und project-away
Project entspricht in etwa den select-Anweisungen vieler Sprachen. Mit dieser Anweisung können Sie auswählen, welche Spalten Sie beibehalten möchten. Die Reihenfolge der zurückgegebenen Spalten stimmt dabei mit der Reihenfolge der Spalten überein, die Sie in der project-Anweisung auflisten, wie im folgenden Beispiel veranschaulicht:
Perf
| project ObjectName, CounterValue, CounterName
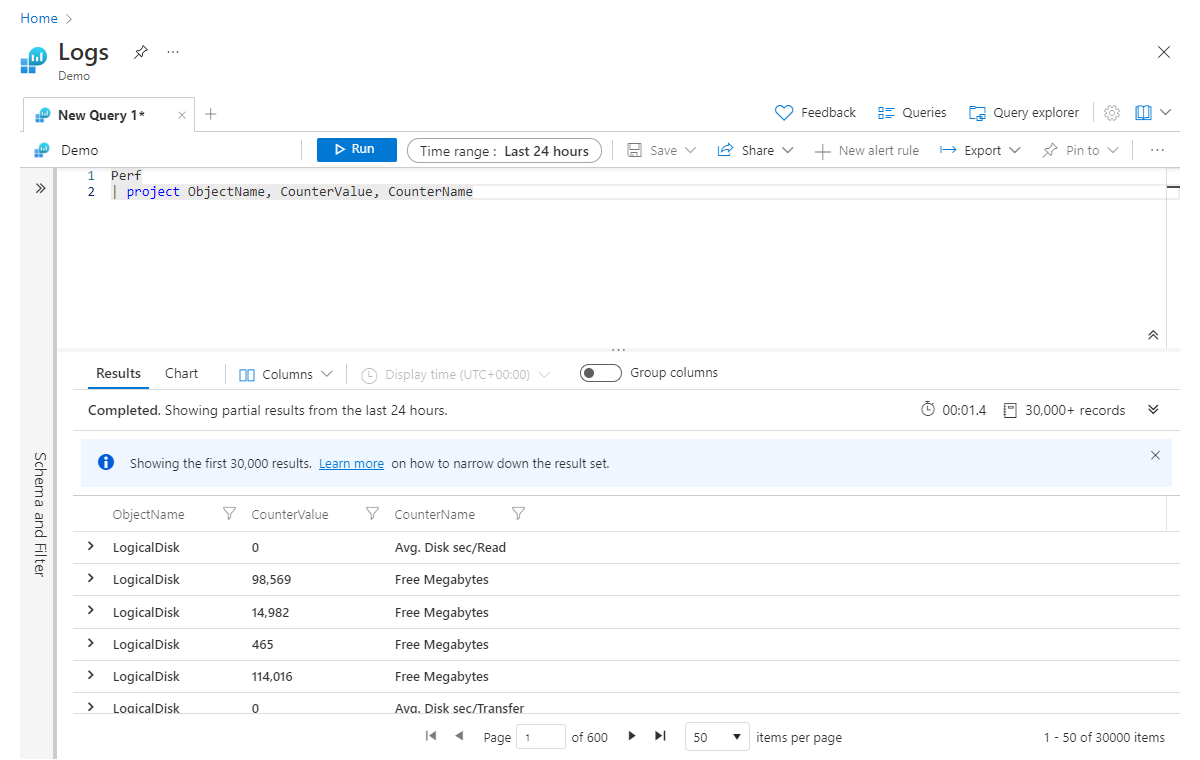
Wie Sie sich vorstellen können, verfügen Sie bei der Arbeit mit sehr umfangreichen Datasets möglicherweise über viele Spalten, die Sie beibehalten möchten, und die Angabe all dieser Spalten nach Namen würde viel Arbeit beim Eingeben machen. In diesen Fällen verfügen Sie über die Anweisung project-away, mit der Sie statt der beizubehaltenden Spalten angeben können, welche Spalten entfernt werden sollen, wie nachstehend dargestellt ist:
Perf
| project-away MG, _ResourceId, Type
Tipp
Es kann nützlich sein, project an zwei Stellen in Abfragen zu verwenden, am Anfang und noch mal am Ende. Wenn Sie project frühzeitig in der Abfrage verwenden, können Sie die Leistung verbessern, indem Sie große Datenblöcke aussortieren, die Sie nicht an die Pipeline übergeben müssen. Wenn Sie die Anweisung am Ende noch mal verwenden, können Sie alle Spalten aussortieren, die möglicherweise in vorherigen Schritten erstellt wurden und in der endgültigen Ausgabe nicht benötigt werden.
Erweitern
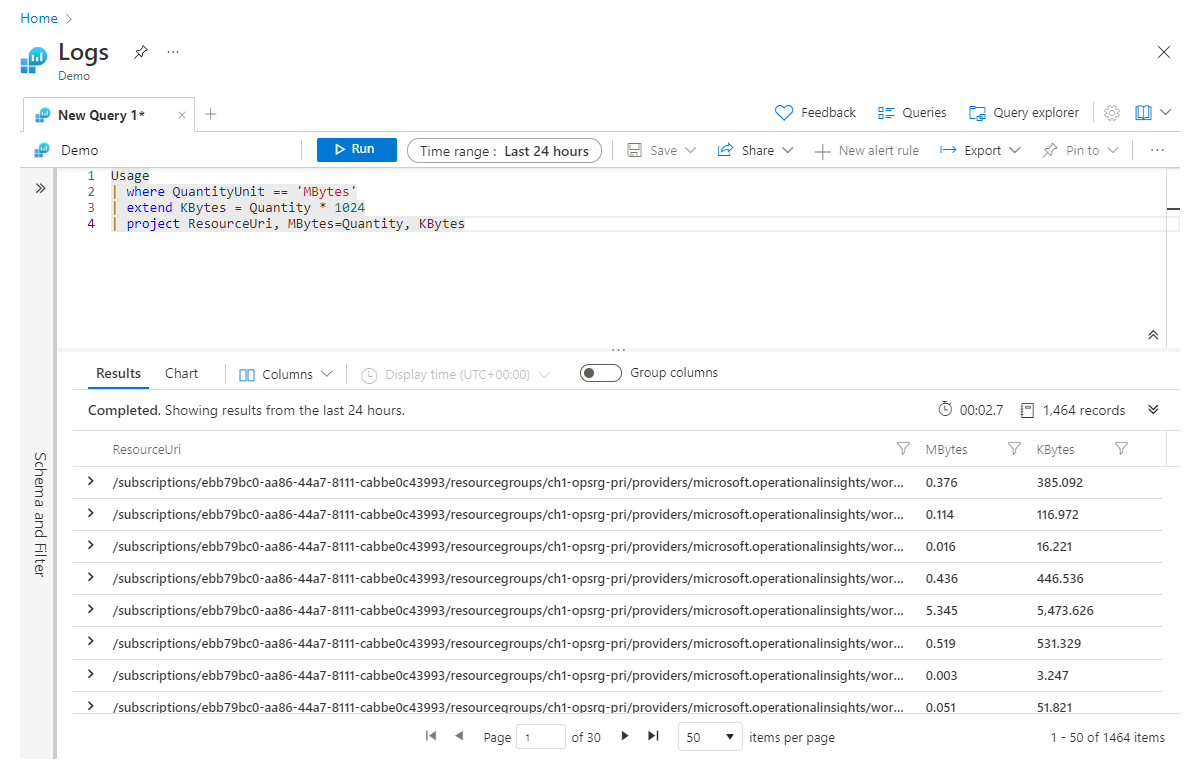
Extend wird zum Erstellen einer neuen berechneten Spalte verwendet. Dies kann nützlich sein, wenn Sie eine Berechnung für vorhandene Spalten durchführen und die Ausgabe für jede Zeile anzeigen möchten. Im folgenden einfachen Beispiel wird eine neue Spalte mit der Bezeichnung Kbytes berechnet, die sich berechnen lässt, indem der MB-Wert (in der bestehenden Spalte Quantity) mit 1.024 multipliziert wird.
Usage
| where QuantityUnit == 'MBytes'
| extend KBytes = Quantity * 1024
| project ResourceUri, MBytes=Quantity, KBytes
In der letzten Zeile der project-Anweisung wurde die Spalte Quantity in Mbytes umbenannt, damit leicht ersichtlich ist, welche Maßeinheit für die jeweilige Spalte relevant ist.
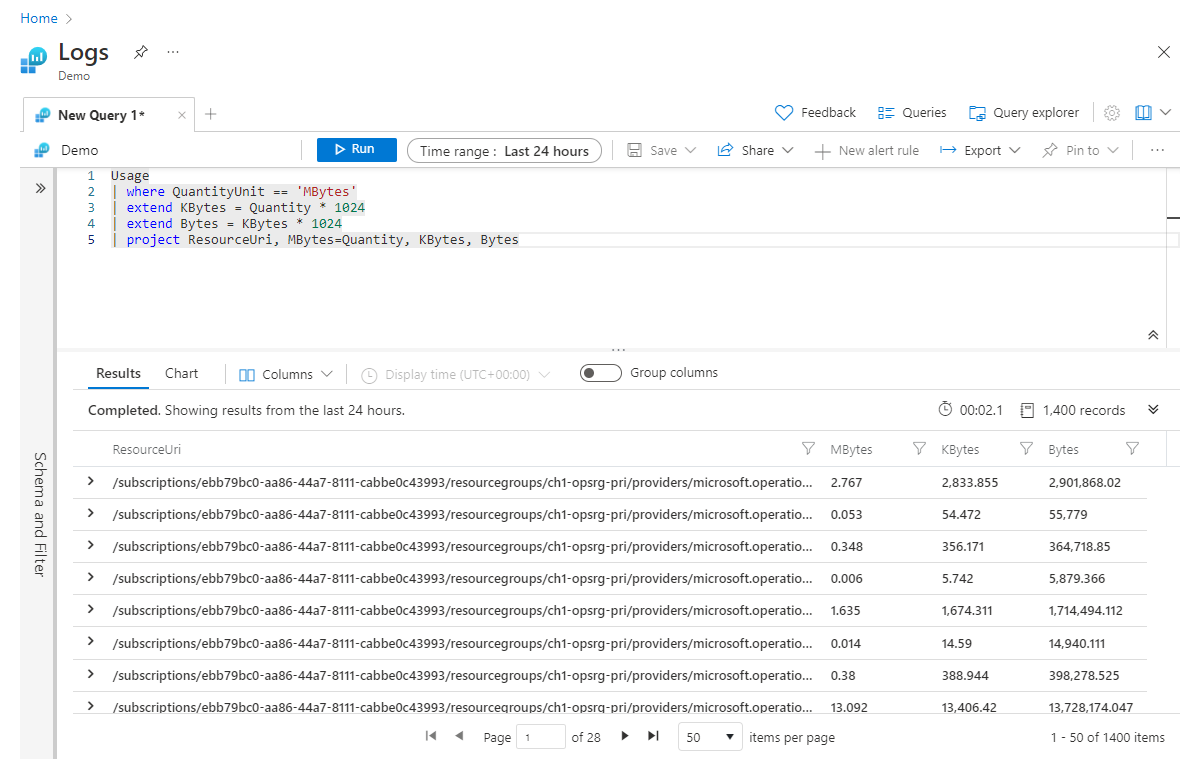
Es ist zu beachten, dass extend auch mit bereits berechneten Spalten funktioniert. Beispielsweise können Sie eine weitere Spalte mit der Bezeichnung Bytes hinzufügen, die ausgehend von Kbytes berechnet wird:
Usage
| where QuantityUnit == 'MBytes'
| extend KBytes = Quantity * 1024
| extend Bytes = KBytes * 1024
| project ResourceUri, MBytes=Quantity, KBytes, Bytes
Verknüpfen von Tabellen
Ein Großteil Ihrer Arbeit in Microsoft Sentinel kann mithilfe eines einzigen Protokolltyps ausgeführt werden, aber es gibt Fälle, in denen Sie Daten korrelieren oder eine Suche in Bezug auf andere Daten durchführen möchten. Wie die meisten Abfragesprachen bietet die Kusto-Abfragesprache einige Operatoren, die zum Ausführen verschiedener Jointypen verwendet werden. In diesem Abschnitt werden die am häufigsten verwendeten Operatoren erläutert: union und join.
Union
Union akzeptiert zwei oder mehr Tabellen und gibt all ihre Zeilen zurück. Beispiel:
OfficeActivity
| union SecurityEvent
Dadurch werden alle Zeilen aus den Tabellen OfficeActivity und SecurityEvent zurückgegeben. Union bietet einige Parameter, die dazu verwendet werden können, das Verhalten der Vereinigung anzupassen. Zwei der nützlichsten sind withsource und kind:
OfficeActivity
| union withsource = SourceTable kind = inner SecurityEvent
Mit dem Parameter withsource können Sie den Namen einer neuen Spalte angeben, deren Wert in einer bestimmten Zeile der Name der Tabelle ist, aus der die Zeile stammt. Im obigen Beispiel wurde die Spalte SourceTable genannt, und je nach Zeile ist der Wert entweder OfficeActivity oder SecurityEvent.
Der andere Parameter, der angegeben wurde, war kind. Dieser Parameter verfügt über zwei Optionen: inner oder outer. Im obigen Beispiel wurde inner angegeben. Dies bedeutet, dass die einzigen Spalten, die während der Vereinigung beibehalten werden, diejenigen sind, die in beiden Tabellen vorhanden sind. Wenn wir alternativ dazu outer (den Standardwert) angegeben hätten, würden alle Spalten aus beiden Tabellen zurückgegeben.
Join
Join funktioniert ähnlich wie union, mit der Ausnahme, dass zum Erstellen einer neuen Tabelle Zeilen statt Tabellen verbunden werden. Wie bei den meisten Datenbanksprachen gibt es mehrere Arten von Verknüpfungen, die Sie ausführen können. Die allgemeine join-Syntax sieht wie folgt aus:
T1
| join kind = <join type>
(
T2
) on $left.<T1Column> == $right.<T2Column>
Nach dem join-Operator wird die Art der Verknüpfung angegeben, die ausgeführt werden soll, gefolgt von einer offenen Klammer. Innerhalb der Klammern geben Sie die Tabelle an, die Sie verknüpfen möchten, sowie alle anderen Abfrageanweisungen für diese Tabelle, die Sie hinzufügen möchten. Nach der schließenden Klammer wird das Schlüsselwort on verwendet, gefolgt von der linken Spalte (Schlüsselwort $left.<columnName>) und der rechten Spalte ($right.<columnName>), die durch den Operator == getrennt sind. Hier ist ein Beispiel für einen inneren Join:
OfficeActivity
| where TimeGenerated >= ago(1d)
and LogonUserSid != ''
| join kind = inner (
SecurityEvent
| where TimeGenerated >= ago(1d)
and SubjectUserSid != ''
) on $left.LogonUserSid == $right.SubjectUserSid
Hinweis
Wenn beide Tabellen denselben Namen für die Spalten haben, für die Sie einen Join ausführen, müssen Sie $left und $right nicht verwenden; stattdessen können Sie einfach den Spaltennamen angeben. Die Verwendung von $left und $right ist jedoch expliziter und wird im Allgemeinen als bewährte Methode angesehen.
Die folgende Tabelle enthält als Referenz eine Liste der verfügbaren Jointypen.
Verknüpfungstypen
| Join-Typ | BESCHREIBUNG |
|---|---|
inner |
Gibt eine einzelne für jede Kombination übereinstimmender Zeilen aus beiden Tabellen zurück. |
innerunique |
Gibt Zeilen aus der linken Tabelle mit unterschiedlichen Werten im verknüpften Feld zurück, die eine Übereinstimmung in der rechten Tabelle aufweisen. Dies ist der nicht angegebene Standardjointyp. |
leftsemi |
Gibt alle Datensätze aus der linken Tabelle zurück, die eine Übereinstimmung in der rechten Tabelle aufweisen. Es werden nur Spalten aus der linken Tabelle zurückgegeben. |
rightsemi |
Gibt alle Datensätze aus der rechten Tabelle zurück, die eine Übereinstimmung in der linken Tabelle aufweisen. Es werden nur Spalten aus der rechten Tabelle zurückgegeben. |
leftanti/leftantisemi |
Gibt alle Datensätze aus der linken Tabelle zurück, die keine Übereinstimmung in der rechten Tabelle aufweisen. Es werden nur Spalten aus der linken Tabelle zurückgegeben. |
rightanti/rightantisemi |
Gibt alle Datensätze aus der rechten Tabelle zurück, die keine Übereinstimmung in der linken Tabelle aufweisen. Es werden nur Spalten aus der rechten Tabelle zurückgegeben. |
leftouter |
Gibt alle Datensätze aus der linken Tabelle zurück. Für Datensätze, die keine Übereinstimmung in der rechten Tabelle aufweisen, sind die Zellenwerte NULL. |
rightouter |
Gibt alle Datensätze aus der rechten Tabelle zurück. Für Datensätze, die keine Übereinstimmung in der linken Tabelle aufweisen, sind die Zellenwerte NULL. |
fullouter |
Gibt alle Datensätze aus der linken und der rechten Tabelle zurück, die Übereinstimmungen aufweisen oder keine Übereinstimmungen aufweisen. Nicht übereinstimmende Werte sind NULL. |
Tipp
Es ist eine bewährte Methode, die kleinste Tabelle auf der linken Seite anzuordnen. In einigen Fällen kann die Einhaltung dieser Regel große Leistungsvorteile bieten, abhängig von den Typen von Joins, die Sie ausführen, und der Größe der Tabellen.
Evaluieren
Sie erinnern sich vielleicht, dass vorhin im ersten Beispiel der evaluate-Operator in einer der Zeilen vorhanden war. Der evaluate-Operator wird seltener verwendet als die Operatoren, die zuvor behandelt wurden. Es lohnt sich jedoch, zu wissen, wie der evaluate-Operator funktioniert. Hier ist noch einmal die erste Abfrage aufgeführt, bei der in der zweiten Zeile der evaluate-Operator angezeigt wird.
SigninLogs
| evaluate bag_unpack(LocationDetails)
| where RiskLevelDuringSignIn == 'none'
and TimeGenerated >= ago(7d)
| summarize Count = count() by city
| sort by Count desc
| take 5
Mit diesem Operator können Sie verfügbare Plug-Ins aufrufen (im Wesentlichen integrierte Funktionen). Viele dieser Plug-Ins sind auf das Gebiet Data Science ausgelegt, z. B. autocluster, diffpatterns und sequence_detect, sodass Sie erweiterte Analysen durchführen und statistische Anomalien und Ausreißer erkennen können.
Das im obigen Beispiel verwendete Plug-In wurde als bag_unpack bezeichnet und erleichtert es ganz erheblich, einen Block dynamischer Daten in Spalten zu konvertieren. Beachten Sie, dass dynamische Daten ein Datentyp sind, der dem JSON-Format sehr ähnlich ist, wie im folgenden Beispiel gezeigt:
{
"countryOrRegion":"US",
"geoCoordinates": {
"longitude":-122.12094116210936,
"latitude":47.68050003051758
},
"state":"Washington",
"city":"Redmond"
}
In diesem Fall sollten die Daten nach Stadt zusammengefasst werden, aber city (Stadt) ist als Eigenschaft in der Spalte LocationDetails enthalten. Damit die Eigenschaft city in der Abfrage verwendet werden konnte, musste sie zunächst mithilfe von bag_unpack in eine Spalte konvertiert werden.
In den ursprünglichen Pipelineschritten sah das Ganze folgendermaßen aus:
Get Data | Filter | Summarize | Sort | Select
Nach Einbeziehung des Operators evaluate, ist nun ersichtlich, dass dieser eine neue Phase in der Pipeline darstellt, die jetzt wie folgt aussieht:
Get Data | Parse | Filter | Summarize | Sort | Select
Es gibt viele weitere Beispiele für Operatoren und Funktionen, die dazu verwendet werden können, Datenquellen zu analysieren und so in ein besser lesbares und bearbeitbares Format zu überführen. Sie können sich über diese und den Rest der Kusto-Abfragesprache in der vollständigen Dokumentation und in der entsprechenden Arbeitsmappe informieren.
Let-Anweisungen
Nachdem wir nun viele der wichtigsten Operatoren und Datentypen behandelt haben, wird abschließend noch die let-Anweisung erläutert. Diese bietet eine hervorragende Möglichkeit, die Lesbarkeit, Bearbeitbarkeit und Verwaltbarkeit von Abfragen zu optimieren.
Mit der let-Anweisung können Sie eine Variable erstellen und festlegen oder einem Ausdruck einen Namen zuweisen. Dieser Ausdruck kann ein einzelner Wert, aber auch eine ganze Abfrage sein. Im Folgenden finden Sie ein einfaches Beispiel:
let aWeekAgo = ago(7d);
SigninLogs
| where TimeGenerated >= aWeekAgo
Hier wurde der Name aWeekAgo angegeben und auf die Ausgabe einer timespan-Funktion festgelegt, die einen datetime-Wert zurückgibt. Die let-Anweisung wird dann mit einem Semikolon beendet. Nun ist eine neue Variable mit der Bezeichnung aWeekAgo verfügbar, die überall in der Abfrage verwendet werden kann.
Wie bereits erwähnt, können Sie eine let-Anweisung verwenden, um eine ganze Abfrage zu erstellen und dem Ergebnis einen Namen zu geben. Da Abfrageergebnisse tabellarische Ausdrücke sind und als Eingaben von Abfragen verwendet werden können, können Sie dieses benannte Ergebnis als Tabelle behandeln, um eine weitere Abfrage dafür auszuführen. Hier sehen Sie eine geringfügige Änderung am vorherigen Beispiel:
let aWeekAgo = ago(7d);
let getSignins = SigninLogs
| where TimeGenerated >= aWeekAgo;
getSignins
In diesem Fall wurde eine zweite let-Anweisung erstellt, bei der die gesamte Abfrage von einer neuen Variablen mit der Bezeichnung getSignins umschlossen wurde. Genau wie zuvor wird die let-Anweisung mit einem Semikolon beendet. Anschließend wird die Variable in der letzten Zeile aufgerufen, die die Abfrage ausführen wird. Beachten Sie, dass in der zweiten let-Anweisung aWeekAgo verwendet werden konnte. Dies liegt daran, dass „aWeekAgo“ in der vorherigen Zeile festgelegt wurde. Wenn die let-Anweisungen so ausgetauscht würden, dass getSignins an erster Stelle angeordnet wäre, würde ein Fehler ausgegeben.
Jetzt kann getSignins als Grundlage für eine andere Abfrage (im selben Fenster) verwendet werden:
let aWeekAgo = ago(7d);
let getSignins = SigninLogs
| where TimeGenerated >= aWeekAgo;
getSignins
| where level >= 3
| project IPAddress, UserDisplayName, Level
Let-Anweisungen bieten Ihnen mehr Leistung und Flexibilität beim Organisieren von Abfragen. In Let-Anweisungen können skalare und tabellarische Werte definiert und benutzerdefinierte Funktionen erstellt werden. Diese Anweisungen sind praktisch, wenn Sie komplexere Abfragen organisieren, mit denen möglicherweise mehrere Joins ausgeführt werden.
Nächste Schritte
In diesem Artikel konnte das Thema zwar nur oberflächlich erläutert werden, aber Sie haben nun die erforderliche Grundlage erhalten, und es wurden die Teile behandelt, die Sie am häufigsten verwenden werden, um Ihre Arbeit in Microsoft Sentinel zu erledigen.
Advanced KQL for Microsoft Sentinel – Arbeitsmappe
Nutzen Sie direkt in Microsoft Azure Sentinel eine Arbeitsmappe für die Kusto-Abfragesprache: Advanced KQL for Microsoft Sentinel (Erweiterte KQL für Microsoft Sentinel). Sie beinhaltet Einzelschrittanleitungen und Beispiele für viele Situationen, die bei den täglichen Vorgängen im Bereich der Sicherheit wahrscheinlich auftreten. Außerdem finden Sie darin viele vorgefertigte, gebrauchsfertige Beispiele für Analyseregeln, Arbeitsmappen, Huntingregeln und weitere Elemente, bei denen Kusto-Abfragen verwendet werden. Starten Sie diese Arbeitsmappe auf dem Blatt Arbeitsmappen in Microsoft Azure Sentinel.
In dem hervorragenden Blogbeitrag Advanced KQL Framework Workbook – Empowering you to become KQL-savvy (Englisch) können Sie nachlesen, wie Sie diese Arbeitsmappe verwenden.
Weitere Ressourcen
Nutzen Sie diese Sammlung von Lern-, Trainings- und Qualifikationsressourcen, um Ihre Kenntnisse der Kusto-Abfragesprache zu erweitern und zu vertiefen.