Was sind Geschäftskontinuität, Hochverfügbarkeit und Notfallwiederherstellung?
In diesem Artikel wird Geschäftskontinuität und die Planung dafür definiert und beschrieben. Dabei liegt der Schwerpunkt auf dem Risikomanagement durch einen Entwurf für Hochverfügbarkeit und Notfallwiederherstellung. Dieser Artikel enthält zwar keinen expliziten Leitfaden zur Erfüllung Ihrer eigenen Geschäftskontinuitätsanforderungen, er hilft Ihnen jedoch, die Konzepte zu verstehen, die im Leitfaden zur Zuverlässigkeit von Microsoft verwendet werden.
Geschäftskontinuität ist der Zustand, in dem ein Unternehmen Vorgänge während Fehlern, Ausfällen oder Katastrophen fortsetzen kann. Geschäftskontinuität erfordert eine proaktive Planung, Vorbereitung und Implementierung von ausfallsicheren Systemen und Prozessen.
Bei der Planung von Geschäftskontinuität müssen Risiken identifiziert, analysiert, klassifiziert und angemessen behandelt werden. Basierend auf den Risiken und ihrer Wahrscheinlichkeit müssen Sie bei Ihrer Planung sowohl Hochverfügbarkeit (HA) als auch die Notfallwiederherstellung (DR) berücksichtigen.
Mit Hochverfügbarkeit ist der Entwurf einer Lösung gemeint, der sie resilient gegenüber alltäglichen Risiken macht, um die Geschäftsanforderungen an die Verfügbarkeit zu erfüllen.
Bei der Notfallwiederherstellung geht es darum zu planen, wie mit ungewöhnlichen Risiken und Ausfällen bei einer Katastrophe umgegangen wird.
Geschäftskontinuität
Im Allgemeinen sind Cloudlösungen direkt an Geschäftsvorgänge gebunden. Wenn eine Cloudlösung nicht verfügbar ist oder ein schwerwiegendes Problem damit auftritt, kann dies erhebliche Auswirkungen auf Geschäftsvorgänge haben. Schwerwiegende Probleme können die Geschäftskontinuität unterbrechen.
Mögliche schwerwiegende Auswirkungen auf die Geschäftskontinuität:
- Verlust bei den Geschäftserlösen
- Unfähigkeit, Benutzenden wichtige Dienste bereitzustellen
- Verletzung einer Verpflichtung gegenüber Kunden oder anderen Parteien
Es ist wichtig, die Geschäftserwartungen und die Folgen von Fehlern zu verstehen und mit wichtigen Beteiligten zu kommunizieren, einschließlich derjenigen, die eine Workload entwerfen, implementieren und betreiben. Diese Beteiligten antworten dann mit den Kosten, die zum Erreichen dieser Ziele erforderlich sind. Es gibt in der Regel einen Prozess der Aushandlung und Überarbeitung dieser Ziele basierend auf dem Budget und anderen Einschränkungen.
Geschäftskontinuität planen
Um die Geschäftskontinuität besser steuern und negative Auswirkungen möglichst vollständig vermeiden zu können, ist es wichtig, proaktiv einen Geschäftskontinuitätsplan einzurichten. Der Geschäftskontinuitätsplan basiert auf der Risikobewertung und umfasst die Entwicklung von Methoden zur Steuerung dieser Risiken durch verschiedene Ansätze. Die spezifischen Risiken und Ansätze zur Entschärfung variieren je nach Organisation und Workload.
In einem Geschäftskontinuitätsplan werden nicht nur die Resilienzfeatures der Cloudplattform selbst, sondern auch die Features der Anwendung berücksichtigt. Ein robuster Geschäftskontinuitätsplan schließt darüber hinaus sämtliche Supportaspekte im Unternehmen ein, dazu gehören Personen, manuelle oder automatisierte Prozesse und andere Technologien.
Der Geschäftskontinuitätsplan sollte die folgenden sequenziellen Schritte umfassen:
Risikoidentifikation. Ermitteln Sie die Risiken für die Verfügbarkeit oder Funktionalität einer Workload. Mögliche Risiken können Netzwerkprobleme, Hardwarefehler, menschliche Fehler, regionale Ausfälle usw. sein. Sie sollten die Auswirkungen der einzelnen Risiken kennen.
Risikoklassifizierung Klassifizieren Sie jedes Risiko entweder als allgemeines Risiko, das in Pläne für Hochverfügbarkeit einbezogen werden sollte, oder als ungewöhnliches Risiko, das Teil der Notfallwiederherstellungsplanung sein sollte.
Risikominderung Entwerfen Sie Entschärfungsstrategien für Hochverfügbarkeit oder Notfallwiederherstellung, um Risiken durch Redundanz, Replikation, Failover und Sicherungen zu minimieren. Beziehen Sie außerdem nicht technische und prozessbasierte Gegenmaßnahmen und Kontrollen in Ihre Planung ein.
Die Geschäftskontinuitätsplanung ist ein Prozess, keine einmalige Aktion. Jeder erstellte Geschäftskontinuitätsplan sollte regelmäßig überprüft und aktualisiert werden, um sicherzustellen, dass er weiterhin relevant und effektiv ist und die aktuellen Geschäftsanforderungen unterstützt.
Risikoidentifizierung
Die erste Phase der Geschäftskontinuitätsplanung besteht darin, die Risiken für die Verfügbarkeit oder Funktionalität einer Workload zu ermitteln. Jedes Risiko sollte analysiert werden, um ihre Wahrscheinlichkeit und den Schweregrad zu kennen. Der Schweregrad muss alle potenziellen Ausfallzeiten oder Datenverluste einbeziehen, aber auch, ob bestimmte Aspekte des restlichen Lösungsdesigns negative Auswirkungen ausgleichen können.
Die folgende Tabelle ist eine unvollständige Liste der Risiken, sortiert nach abnehmender Wahrscheinlichkeit:
| Beispielrisiko | Beschreibung | Häufigkeit (Wahrscheinlichkeit) |
|---|---|---|
| Vorübergehendes Netzwerkproblem | Ein temporärer Fehler bei einer Komponente des Netzwerkstapels, der nach kurzer Zeit behoben werden kann (in der Regel nach maximal wenigen Sekunden) | Regulär |
| VM-Neustart | Ein Neustart einer VM, die von Ihnen oder einem abhängigen Dienst verwendet wird. Neustarts können auftreten, wenn eine VM abstürzt oder ein Patch angewendet wird. | Regulär |
| Hardwarefehler | Ein Ausfall einer Komponente in einem Rechenzentrum, z. B. eines Hardwareknotens, eines Racks oder eines Clusters | Gelegentlich |
| Rechenzentrumsausfälle | Ein Ausfall, der sich auf einen Teil oder das gesamte Rechenzentrum auswirkt, z. B. ein Stromausfall, Netzwerkkonnektivitätsprobleme oder Probleme mit Heizung oder Kühlung | Ungewöhnlich |
| Regionale Ausfälle | Ein Ausfall, der eine ganze Metropolregion oder ein größeres Gebiet betrifft, z. B. eine große Naturkatastrophe | Sehr ungewöhnlich |
Bei der Geschäftskontinuitätsplanung geht es nicht nur um die Cloudplattform und die Infrastruktur. Es ist wichtig, auch das Risiko durch menschliche Fehler zu berücksichtigen. Darüber hinaus sollten einige Risiken, die traditionell als Sicherheits-, Leistungs- oder Betriebsrisiken angesehen werden, ebenfalls als Zuverlässigkeitsrisiken betrachtet werden, da sie sich auf die Verfügbarkeit der Lösung auswirken können.
Im Folgenden finden Sie einige Beispiele:
| Beispielrisiko | Beschreibung |
|---|---|
| Datenverlust oder -beschädigung | Daten wurden gelöscht, überschrieben oder auf andere Art beschädigt – versehentlich oder bei einer Sicherheitsverletzung wie einem Ransomware-Angriff. |
| Softwarefehler | Die Bereitstellung von neuem oder aktualisiertem Code könnte zu einem Fehler führen, der sich auf die Verfügbarkeit oder Integrität auswirkt und die Workload in einen fehlerhaften Zustand versetzt. |
| Bereitstellungen mit Fehler | Ein Fehler bei der Bereitstellung einer neuen Komponente oder Version könnte die Lösung in einen inkonsistenten Zustand versetzen. |
| Denial-of-Service-Angriffe | Das System wurde angegriffen, um die vorgesehene Verwendung der Lösung zu verhindern. |
| Nicht autorisierte Administrierende | Benutzende mit Administratorrechten haben absichtlich eine schädliche Aktion gegen das System ausgeführt. |
| Unerwartete Zunahme des Datenverkehrs einer Anwendung | Eine Datenverkehrsspitze hat die Ressourcen des Systems überlastet. |
Die Fehlermodusanalyse (Failure Mode Analysis, FMA) ist der Prozess zur Identifizierung potenzieller Möglichkeiten, Fehler bei einer Workload oder ihren Komponenten auszulösen und das Verhalten der Lösung in diesen Situationen zu analysieren. Weitere Informationen finden Sie unter Empfehlungen für die Durchführung von Fehlermodusanalysen.
Risikoklassifizierung
Geschäftskontinuitätspläne müssen sowohl allgemeine als auch ungewöhnliche Risiken berücksichtigen.
Allgemeine Risiken sind geplant und erwartbar. In einer Cloudumgebung kommt es beispielsweise häufiger zu vorübergehenden Fehlern, z. B. kurze Netzwerkausfälle, Geräteneustarts aufgrund von Patches, oder Timeouts, wenn ein Dienst ausgelastet ist, usw. Da diese Ereignisse regelmäßig auftreten, müssen Ihre Workloads entsprechend robust sein.
Eine Hochverfügbarkeitsstrategie muss jedes Risiko dieses Typs berücksichtigen und steuern.
Ungewöhnliche Risiken sind im Allgemeinen das Ergebnis eines unvorhersehbaren Ereignisses, z. B. einer Naturkatastrophe oder eines großen Netzwerkangriffs, die zu einem schwerwiegenden Ausfall führen können.
Diese seltenen Risiken werden über Notfallwiederherstellungsprozesse behandelt.
Hochverfügbarkeit und Notfallwiederherstellung sind miteinander verbunden. Daher ist es wichtig, Strategien für beide zusammen zu planen.
Es ist wichtig zu verstehen, dass die Risikoklassifizierung von der Workloadarchitektur und den Geschäftsanforderungen abhängt. Einige Risiken können für eine Workload die Hochverfügbarkeit und für eine andere Workload die Notfallwiederherstellung betreffen. Beispielsweise wird ein vollständiger Ausfall einer Azure-Region in der Regel als Notfallwiederherstellungsrisiko für Workloads in dieser Region betrachtet. Für Workloads, die mehrere Azure-Regionen in einer Aktiv-Aktiv-Konfiguration mit vollständiger Replikation, Redundanz und automatischem Regionsfailover verwenden, wird ein Regionsausfall jedoch als Hochverfügbarkeitsrisiko klassifiziert.
Risikominderung
Die Risikominderung umfasst die Entwicklung von Strategien für Hochverfügbarkeit oder Notfallwiederherstellung, um Risiken für die Geschäftskontinuität zu minimieren oder zu entschärfen. Die Risikominderung kann durch Technologien oder Personen erfolgen.
Technologiebasierte Risikominderung
Bei der technologiebasierten Risikominderung werden Risikomaßnahmen angewendet, die darauf basieren, wie die Workload implementiert und konfiguriert wird, z. B.:
- Redundanz
- Datenreplikation
- Failover
- Backups
Technologiebasierte Risikomaßnahmen müssen im Kontext des Geschäftskontinuitätsplans berücksichtigt werden.
Zum Beispiel:
Anforderungen an Ausfallzeiten: Einige Geschäftskontinuitätspläne sind aufgrund strenger Anforderungen an die Hochverfügbarkeit nicht in der Lage, Ausfallzeiten zu tolerieren. Es gibt bestimmte technologiebasierte Maßnahmen, die möglicherweise Zeit erfordern, damit Personen benachrichtigt werden können, um darauf zu reagieren. Technologiebasierte Risikomaßnahmen, die zeitaufwendige manuelle Prozesse umfassen, sind sehr wahrscheinlich nicht geeignet, in Ihre Risikominderungsstrategie einzufließen.
Toleranz gegenüber Teilausfällen: Einige Geschäftskontinuitätspläne können einzelne Workflows in einem beeinträchtigten Zustand tolerieren. Wenn eine Lösung in einem beeinträchtigtem Zustand ausgeführt wird, sind einige Komponenten möglicherweise deaktiviert oder nicht funktionsfähig, Kerngeschäftsvorgänge können aber weiterhin ausgeführt werden. Weitere Informationen finden Sie unter Empfehlungen zu Self-healing und Selbsterhaltung.
Risikominderung durch Personen
Bei der Risikominderung durch Personen werden Risikomaßnahmen angewendet, die auf Geschäftsprozessen basieren, z. B.:
- Auslösen eines Playbook zur Reaktion
- Fallback auf den manuellen Betrieb
- Schulungen und kulturelle Veränderungen
Wichtig
Einzelpersonen, die die Workloads entwerfen, implementieren, betreiben und entwickeln, sollten geschult und dazu ermutigt werden, ihre Bedenken zu äußern und sich für das System verantwortlich zu fühlen.
Da Risikomaßnahmen durch Personen häufig länger dauern als technologiebasierte Maßnahmen und anfälliger für menschliche Fehler sind, sollte ein guter Geschäftskontinuitätsplan einen formalen Änderungskontrollprozess für alles enthalten, was den Zustand des ausgeführten Systems ändern könnte. Erwägen Sie beispielsweise die Implementierung der folgenden Prozesse:
- Testen Sie Ihre Workloads streng nach der Bedeutung der Workloads. Um Probleme bei Änderungen zu verhindern, stellen Sie sicher, dass alle Änderungen an der Workload getestet werden.
- Führen Sie strategische Qualitätshürden als Teil der sicheren Bereitstellungsmethoden Ihrer Workload ein. Weitere Informationen finden Sie unter Empfehlungen für sichere Bereitstellungsmethoden.
- Formalisieren Sie Verfahren für den Ad-hoc-Produktionszugriff und Datenänderungen. Diese Aktivitäten können, selbst wie sehr geringfügig sind, ein hohes Risiko für die Zuverlässigkeit darstellen. Zu diesen Verfahren gehören z. B. die Zusammenarbeit mit anderen technischen Fachkräften, die Verwendung von Prüflisten und Peer Reviews vor der Ausführung von Skripts oder der Anwendungen von Änderungen.
Hochverfügbarkeit
Hochverfügbarkeit bedeutet, dass eine bestimmte Workload die erforderliche tägliche Betriebszeit auch bei vorübergehenden Fehlern und kurzzeitigen Ausfällen aufrechterhalten kann. Da diese Ereignisse regelmäßig auftreten, ist es wichtig, dass jede Workload gemäß den Anforderungen der spezifischen Anwendungs- und Kundenerwartungen für Hochverfügbarkeit entworfen und konfiguriert wird. Die Hochverfügbarkeit sämtlicher Workloads ist ein Aspekt Ihres Geschäftskontinuitätsplans.
Da die Hochverfügbarkeit der einzelnen Workloads variieren kann, ist es wichtig, die Anforderungen und Kundenerwartungen bei der Festlegung von Hochverfügbarkeit zu verstehen. Eine Anwendung, die Ihre Organisation zum Bestellen von Büromaterialien verwendet, kann z. B. eine relativ geringe Betriebszeit erfordern, während bei einer kritischen Finanzanwendung möglicherweise eine viel höhere Betriebszeit erforderlich ist. Auch innerhalb einer Workload können unterschiedliche Abläufe verschiedene Anforderungen haben. In einer eCommerce-Anwendung können beispielsweise Abläufe zum Browsen und Aufgeben von Bestellungen durch die Kundschaft wichtiger sein als Abläufe zur Auftragserfüllung und Back-Office-Verarbeitung. Weitere Informationen zu Abläufen finden Sie unter Empfehlungen zum Identifizieren und Bewerten von Abläufen.
In der Regel wird die Uptime basierend auf der Anzahl von „Neunen“ im Uptimeprozentsatz gemessen. Der Uptimeprozentsatz steht in Zusammenhang mit der Downtime, die Sie über einen bestimmten Zeitraum zulassen. Im Folgenden finden Sie einige Beispiele:
- Eine Anforderung von 99,9 % an die Uptime (drei Neunen) erlaubt Ausfallzeiten von ca. 43 Minuten in einem Monat.
- Eine Anforderung von 99,95 % an die Uptime (dreieinhalb Neunen) erlaubt Ausfallzeiten von ca. 21 Minuten in einem Monat.
Je höher die Uptimeanforderung ist, desto weniger Toleranz haben Sie gegenüber Ausfällen und desto mehr Arbeit müssen Sie aufwenden, um dieses Verfügbarkeitsniveau zu erreichen. Die Uptime wird nicht anhand der Uptime einer einzelnen Komponente (z. B. eines Knotens) gemessen, sondern anhand der Verfügbarkeit der gesamten Workload.
Wichtig
Wenden Sie nicht mehr Arbeit auf Ihre Lösung an, um höhere Zuverlässigkeitsniveaus zu erreichen, als erforderlich sind. Halten Sie sich an die geschäftlichen Anforderungen, wenn Sie Ihre Entscheidungen treffen.
Elemente für den Entwurf von Hochverfügbarkeit
Um die Anforderungen an Hochverfügbarkeit einzuhalten, können mehrere Entwurfsaspekte in eine Workload einfließen. Einige allgemeine Aspekte werden in diesem Abschnitt aufgeführt und beschrieben.
Hinweis
Einige Workloads sind unternehmenskritisch. Das bedeutet, dass jede Downtime schwerwiegende Folgen für menschliches Leben und die Sicherheit oder große finanzielle Verluste nach sich ziehen kann. Wenn Sie eine unternehmenskritische Workload entwerfen, müssen Sie bestimmte Dinge beim Entwurf Ihrer Lösung und der Geschäftskontinuität berücksichtigen. Weitere Informationen finden Sie unter Azure Well-Architected Framework: Unternehmenskritische Workloads.
Azure-Dienste und -Dienstebenen mit Unterstützung für Hochverfügbarkeit
Viele Azure-Dienste sind mit Hochverfügbarkeit konzipiert und können verwendet werden, um hochverfügbare Workloads zu erstellen. Im Folgenden finden Sie einige Beispiele:
- Azure Virtual Machine Scale Sets bieten Hochverfügbarkeit für VMs, indem VM-Instanzen automatisch erstellt und verwaltet und so verteilt werden, um die Auswirkungen von Infrastrukturfehlern zu minimieren.
- Azure App Service bietet Hochverfügbarkeit durch eine Vielzahl von Ansätzen, darunter das automatische Verschieben von Workern von einem fehlerhaften Knoten zu einem fehlerfreien Knoten und das Bereitstellen von Funktionen für Self-healing bei vielen gängigen Fehlertypen.
Nutzen Sie alle Leitfaden zur Dienstzulässigkeit, um die Funktionen des Diensts zu verstehen und zu entscheiden, welche Dienstebenen verwendet werden müssen. Legen Sie außerdem fest, welche Funktionen in Ihre Hochverfügbarkeitsstrategie einbezogen werden sollen.
Überprüfen Sie die Vereinbarungen zum Servicelevel (SLAs) für jeden Dienst, um die erwartbaren Verfügbarkeitsniveaus und die Bedingungen zu verstehen, die erfüllt werden müssen. Möglicherweise müssen Sie spezielle Dienstebenen auswählen oder vermeiden, um bestimmte Verfügbarkeitsstufen zu erreichen. Einige Dienstangebote von Microsoft setzen keine SLA voraus, z. B. die Dienstebenen „Development“ und „Basic“, oder sie lassen die Zurücknahme von Ressource von einem ausgeführten System zu, z. B. spotbasierte Angebote. Außerdem bieten einige Dienstebenen Zuverlässigkeitsfeatures, wie z. B. die Unterstützung für Verfügbarkeitszonen.
Fehlertoleranz
Fehlertoleranz ist die Fähigkeit eines Systems, bei einem Fehler den Betrieb innerhalb definierter Kapazitätsgrenzen fortzusetzen. Beispielsweise kann eine Webanwendung so konzipiert sein, dass sie auch dann weiterhin ausgeführt wird, wenn ein einzelner Webserver ausfällt. Fehlertoleranz kann durch Redundanz, Failover, Partitionierung, geplante Leistungsminderung und andere Techniken erreicht werden.
Fehlertoleranz erfordert auch, dass Ihre Anwendungen vorübergehende Fehler behandeln. Wenn Sie eigenen Code erstellen, müssen Sie möglicherweise die Behandlung vorübergehender Fehler selbst aktivieren. Einige Azure-Dienste bieten eine integrierte Behandlung vorübergehender Fehler in bestimmten Situationen. Standardmäßig werden bei Azure Logic Apps z. B. fehlerhafte Anforderungen an andere Dienste automatisch wiederholt. Weitere Informationen finden Sie unter Empfehlungen für die Behandlung vorübergehender Fehler.
Redundanz
Redundanz ist die Praxis, Instanzen oder Daten zu duplizieren, um die Zuverlässigkeit der Workload zu erhöhen.
Redundanz kann erreicht werden, indem Replikate oder redundante Instanzen mit mindestens einer der folgenden Maßnahmen verteilt werden:
- Innerhalb eines Rechenzentrums (lokale Redundanz)
- Zwischen Verfügbarkeitszonen innerhalb einer Region (Zonenredundanz)
- Regionsübergreifend (Georedundanz)
Im Folgenden finden Sie Beispiele dafür, wie einige Azure-Dienste Redundanzoptionen bereitstellen:
- Mit Azure App Service können Sie mehrere Instanzen Ihrer Anwendung ausführen, um sicherzustellen, dass die Anwendung auch dann verfügbar bleibt, wenn eine Instanz ausfällt. Wenn Sie Zonenredundanz aktivieren, werden diese Instanzen auf mehrere Verfügbarkeitszonen in der verwendeten Azure-Region verteilt.
- Azure Storage bietet Hochverfügbarkeit, indem Daten automatisch mindestens dreimal repliziert werden. Sie können diese Replikate auf Verfügbarkeitszonen verteilen, indem Sie zonenredundanten Speicher (ZRS) aktivieren. Außerdem können Sie in vielen Regionen Ihre Speicherdaten auch über Regionen hinweg replizieren, indem Sie georedundanten Speicher (GRS) verwenden.
- Azure SQL-Datenbank verfügt über mehrere Replikate, um sicherzustellen, dass die Daten auch dann verfügbar bleiben, wenn ein Replikat ausfällt.
Weitere Informationen zur Redundanz finden Sie unter Empfehlungen für das Entwerfen von Redundanz und Empfehlungen für die Verwendung von Verfügbarkeitszonen und Regionen.
Skalierbarkeit und Elastizität
Skalierbarkeit und Flexibilität beschreiben die Fähigkeit eines Systems, erhöhte Lasten zu bewältigen, indem Ressourcen hinzugefügt und entfernt werden (Skalierbarkeit), und dies schnell zu erledigen, wenn sich Ihre Anforderungen ändern (Flexibilität). Skalierbarkeit und Flexibilität können einem System helfen, die Verfügbarkeit auch bei Spitzenlasten aufrechtzuerhalten.
Viele Azure-Dienste unterstützen Skalierbarkeit. Im Folgenden finden Sie einige Beispiele:
- Azure Virtual Machine Scale Sets, Azure API Management und einige andere Dienste unterstützen die Autoskalierung von Azure Monitor. Mit der Autoskalierung von Azure Monitor können Sie Richtlinien wie „wenn die CPU-Auslastung dauerhaft über 80 % liegt, eine weitere Instanz hinzufügen“ angeben.
- Azure Functions kann Instanzen dynamisch bereitstellen, um Ihre Anforderungen zu erfüllen.
- Azure Cosmos DB unterstützt Durchsatz mit Autoskalierung, bei dem der Dienst die Ihren Datenbanken zugewiesenen Ressourcen basierend auf den von Ihnen angegebenen Richtlinien automatisch verwalten kann.
Skalierbarkeit ist ein wichtiger Faktor, der bei teilweisen oder vollständigen Fehlfunktionen berücksichtigt werden sollte. Wenn ein Replikat oder eine Compute-Instanz nicht verfügbar ist, müssen die verbleibenden Komponenten möglicherweise mehr Last verarbeiten, um die Aufgaben zu bewältigen, die zuvor vom fehlerhaften Knoten verarbeitet wurden. Erwägen Sie auch eine Überbereitstellung, wenn Ihr System nicht schnell genug skaliert werden kann, um die erwarteten Änderungen bei der Last zu bewältigen.
Weitere Informationen zum Entwerfen eines skalierbaren und flexiblen Systems finden Sie in den Empfehlungen für das Entwerfen einer zuverlässigen Skalierungsstrategie.
Bereitstellungsverfahren ohne Downtime
Bereitstellungen und andere Systemänderungen bergen ein erhebliches Risiko für Ausfälle. Da ein Downtimerisiko eine Herausforderung für Hochverfügbarkeit darstellt, ist es wichtig, Bereitstellungsmethoden ohne Downtime anzuwenden, um Updates und Konfigurationsänderungen ohne erforderliche Downtime vorzunehmen.
Bereitstellungstechniken ohne Downtime sind z. B. folgende:
- Aktualisieren nur einer Teilmenge der Ressourcen gleichzeitig
- Steuern des Datenverkehrs an die neue Bereitstellung
- Überwachen sämtlicher Auswirkungen auf Ihre Benutzenden oder Ihr System
- Schnelle Behebung von Problemen, z. B. durch ein Rollback auf eine frühere, als funktionierend bekannte Bereitstellung
Weitere Informationen zu Bereitstellungstechniken ohne Downtime finden Sie unter Sichere Bereitstellungsmethoden.
Azure selbst verwendet Bereitstellungsansätze ohne Downtime für seine eigenen Dienste. Wenn Sie eigene Anwendungen erstellen, können Sie Bereitstellungen ohne Downtime durch verschiedene Ansätze erzielen, z. B.:
- Azure Container Apps bietet mehrere Revisionen Ihrer Anwendung, mit denen Bereitstellungen ohne Downtime erzielen können.
- Azure Kubernetes Service (AKS) unterstützt eine Vielzahl von Bereitstellungsverfahren ohne Downtime.
Auch wenn Bereitstellungen ohne Downtime häufig für Anwendungsbereitstellungen verwendet werden, können sie auch für Konfigurationsänderungen angewendet werden. Im Folgenden finden Sie einige Möglichkeiten, Konfigurationsänderungen sicher anzuwenden:
- Mit Azure Storage können Sie die Zugriffsschlüssel Ihres Speicherkontos in mehreren Phasen ändern, um Ausfälle während der Schlüsselrotation zu verhindern.
- Azure App Configuration bietet Featureflags, Momentaufnahmen und andere Funktionen, mit denen Sie steuern können, wie Konfigurationsänderungen angewendet werden.
Wenn Sie sich entscheiden, keine Bereitstellungen ohne Downtime zu implementieren, sollten Sie sicherstellen, dass Sie Wartungsfenster definieren, damit Sie Systemänderungen zu Uhrzeiten vornehmen können, zu denen Ihre Benutzenden sie erwarten.
Automatisiertes Testen
Es ist wichtig, die Resilienz Ihrer Lösung gegenüber Ausfällen und Fehlern zu testen, die Sie in Ihre Planung für Hochverfügbarkeit einbeziehen möchten. Viele dieser Fehler können in Testumgebungen simuliert werden. Das Testen der Fähigkeit Ihrer Lösung, verschiedene Fehlertypen automatisch zu tolerieren oder in diesen Fällen eine Wiederherstellung durchzuführen, wird als Chaos Engineering bezeichnet. Chaos Engineering ist für professionelle Organisationen mit strengen Standards für Hochverfügbarkeit von entscheidender Bedeutung. Azure Chaos Studio ist ein Chaos Engineering-Tool, das einige gängige Fehlertypen simulieren kann.
Weitere Informationen finden Sie unter Empfehlungen für das Entwerfen einer Strategie für Zuverlässigkeitstests.
Überwachung und Warnung
Durch die Überwachung werden Sie über die Integrität Ihres Systems informiert, auch wenn automatisierte Entschärfungen durchgeführt werden. Die Überwachung ist wichtig, um zu verstehen, wie Ihre Lösung sich verhält, und um frühzeitig Signale für Fehler wie erhöhte Fehlerraten oder hohen Ressourcenverbrauch zu erkennen. Mit Warnungen können Sie proaktiv über wichtige Änderungen in Ihrer Umgebung benachrichtigt werden.
Azure bietet eine Vielzahl von Überwachungs- und Warnungsfunktionen, einschließlich der folgenden:
- Azure Monitor sammelt Protokolle und Metriken von Azure-Ressourcen und Anwendungen und kann Warnungen senden und Daten auf Dashboards anzeigen.
- Azure Monitor Application Insights ermöglicht eine detaillierte Überwachung Ihrer Anwendungen.
- Azure Service Health und Azure Resource Health überwachen die Integrität der Azure-Plattform und Ihrer Ressourcen.
- Scheduled Events benachrichtigt, wann eine VM-Wartung geplant ist.
Weitere Informationen finden Sie unter Empfehlungen für das Entwerfen einer zuverlässigen Überwachungs- und Warnungsstrategie.
Notfallwiederherstellung
Eine Katastrophe ist ein spezielles, ungewöhnliches, großes Ereignis, das umfangreichere und längere Auswirkungen hat, als eine Anwendung über die Hochverfügbarkeit ihres Designs entschärfen kann. Beispiele für Katastrophen:
- Naturkatastrophen wie Hurrikane, Erdbeben, Überschwemmungen oder Brände.
- Menschliche Fehler mit großen Auswirkungen, z. B. versehentliches Löschen von Produktionsdaten oder eine falsch konfigurierte Firewall, die vertrauliche Daten offenlegt.
- Schwerwiegende Sicherheitsvorfälle, z. B. Denial of Service- oder Ransomware-Angriffe, die zu Datenbeschädigung, Datenverlust oder Dienstausfällen führen.
Bei der Notfallwiederherstellung geht es um die Planung der Reaktion in solchen Situationen.
Hinweis
Sie sollten die empfohlenen Methoden zu Ihrer Lösung befolgen, um die Wahrscheinlichkeit dieser Ereignisse zu minimieren. Selbst bei einer sorgfältigen proaktiven Planung ist es jedoch sinnvoll zu planen, wie Sie in diesen Situationen reagieren.
Anforderungen hinsichtlich der Notfallwiederherstellung
Aufgrund der Seltenheit und Schwere von Katastrophen bestehen bei der Notfallwiederherstellungsplanung unterschiedliche Erwartungen an Ihre Reaktion. Viele Organisationen akzeptieren die Tatsache, dass in einem Notfallszenario gewisse Ausfallzeiten oder Datenverluste unvermeidbar sind. Ein umfassender Notfallwiederherstellungsplan muss die folgenden kritischen Geschäftsanforderungen für jeden Ablauf berücksichtigen:
Das Recovery Point Objective (RPO) ist die maximale Dauer zulässiger Datenverluste bei einem Notfall. Das RPO wird in Zeiteinheiten gemessen, z. B. „30 Minuten bei Daten“ oder „vier Stunden bei Daten“.
Das Recovery Time Objective (RTO) ist die maximale Dauer akzeptabler Downtime im Fall einer Katastrophe, wobei die „Downtime“ durch Ihre Spezifikation definiert wird. Das RTO wird ebenfalls in Zeiteinheiten gemessen, z. B. „acht Stunden Downtime“.
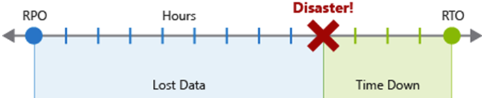
Für jede Komponente oder jeden Ablauf in der Workload können eigene RPO- und RTO-Werte gelten. Untersuchen Sie das Risiko von Notfallszenarien und potenzielle Wiederherstellungsstrategien, wenn Sie Ihre Anforderungen festlegen. Der Prozess der Festlegung eines RPO und RTO erstellt effektiv Notfallwiederherstellungsanforderungen für Ihre Workload als Ergebnis Ihrer spezifischen geschäftlichen Bedenken (Kosten, Auswirkungen, Datenverlust usw.).
Hinweis
Ein RTO und RPO von null (keine Downtime und kein Datenverlust bei einer Katastrophe) erscheint zwar als erstrebenswertes Ziel, ist in der Praxis aber nur schwierig und mit hohem Aufwand umzusetzen. Es ist wichtig, dass alle Beteiligten aus dem technischen und geschäftlichen Bereich diese Anforderungen gemeinsam besprechen und realistische Anforderungen festlegen. Weitere Informationen finden Sie unter Empfehlungen zum Definieren von Zuverlässigkeitszielen.
Pläne für die Notfallwiederherstellung
Unabhängig von der Ursache einer Katastrophe ist es wichtig, dass Sie einen klar definierten Notfallwiederherstellungsplan erstellen, der auch getestet werden kann. Dieser Plan wird als Teil des Infrastruktur- und Anwendungsentwurfs verwendet, um ihn aktiv zu unterstützen. Sie müssen möglicherweise mehrere Notfallwiederherstellungspläne für verschiedene Situationen erstellen. Notfallwiederherstellungspläne basieren häufig auf Prozesssteuerungen und manuellen Eingriffen.
Die Notfallwiederherstellung ist kein automatisches Feature von Azure. Viele Dienste bieten jedoch Features und Funktionen zur Unterstützung Ihrer Notfallwiederherstellungsstrategien. Sie sollten die Zuverlässigkeitsleitfäden für jeden Azure-Dienst überprüfen, um zu verstehen, wie der Dienst funktioniert und welche Features er bietet, und diese Features dann Ihrem Notfallwiederherstellungsplan zuordnen.
In den folgenden Abschnitten sind einige allgemeine Elemente eines Notfallwiederherstellungsplans aufgeführt. Außerdem wird beschrieben, wie Azure Ihnen dabei helfen kann, diese umzusetzen.
Failover und Failback
Einige Notfallwiederherstellungspläne umfassen die Bereitstellung einer sekundären Bereitstellung an einem anderen Standort. Wenn sich ein Notfall auf die primäre Bereitstellung der Lösung auswirkt, kann ein Failover des Datenverkehrs an den anderen Standort ausgeführt werden. Ein Failover erfordert eine sorgfältige Planung und Implementierung. Azure bietet verschiedene Dienste zur Unterstützung eines Failovers, z. B.:
- Azure Site Recovery bietet ein automatisiertes Failover für lokale Umgebungen und auf VMs gehostete Lösungen in Azure.
- Azure Front Door und Azure Traffic Manager unterstützen ein automatisiertes Failover von eingehendem Datenverkehr zwischen verschiedenen Bereitstellungen Ihrer Lösung, z. B. in verschiedenen Regionen.
Es dauert in der Regel einige Zeit, bis ein Failoverprozess einen Fehler der primären Instanz erkennt und den Wechsel zur sekundären Instanz ausführt. Stellen Sie sicher, dass das RTO der Workload der Failoverzeit entspricht.
Es ist auch wichtig, das Failback zu berücksichtigen. Dies ist der Prozess, mit dem Sie Vorgänge in der primären Region wiederherstellen, nachdem diese selbst wiederhergestellt wurde. Die Planung und Implementierung des Failback kann komplex sein. Beispielsweise können Daten in der primären Region geschrieben worden sein, nachdem das Failover gestartet wurde. Sie müssen fundierte Geschäftsentscheidungen darüber treffen, wie Sie diese Daten behandeln.
Backups
Sicherungen umfassen das Erstellen einer Kopie Ihrer Daten und das sichere Speichern dieser Daten für einen festgelegten Zeitraum. Mit Sicherungen können Sie nach Katastrophen eine Wiederherstellung durchführen, wenn kein automatisches Failover zu einem anderen Replikat möglich ist oder wenn Datenbeschädigungen aufgetreten sind.
Bei der Verwendung von Sicherungen als Komponente eines Notfallwiederherstellungsplans ist es wichtig, Folgendes zu berücksichtigen:
Speicherort: Wenn Sie Sicherungen als Teil eines Notfallwiederherstellungsplans verwenden, sollten diese getrennt von den Hauptdaten gespeichert werden. In der Regel werden Sicherungen in einer anderen Azure-Region gespeichert.
Datenverlust: Da Sicherungen in der Regel selten erstellt werden, führt die Wiederherstellung der Sicherung in der Regel zu einem Datenverlust. Aus diesem Grund sollte die Sicherungswiederherstellung nur als letztes Mittel verwendet werden. Der Notfallwiederherstellungsplan sollte darüber hinaus die Abfolge von Schritten und Wiederherstellungsversuchen angeben, die vor der Wiederherstellung aus einer Sicherung durchgeführt werden müssen. Es ist wichtig sicherzustellen, dass das Workload-RPO dem Sicherungsintervall entspricht.
Wiederherstellungszeit: Die Wiederherstellung aus einer Sicherung dauert oft einige Zeit, daher ist es wichtig, Ihre Sicherungs- und Wiederherstellungsprozesse zu testen, um ihre Integrität zu überprüfen und zu wissen, wie lange der Wiederherstellungsprozess dauert. Stellen Sie sicher, dass beim RTO einer Workload die Zeit zum Wiederherstellen Ihrer Sicherung berücksichtigt wird.
Viele Azure-Daten- und -Speicherdienste wie z. B. die folgenden unterstützen Sicherungen:
- Azure Backup bietet automatisierte Sicherungen für VM-Datenträger, Speicherkonten, AKS und eine Vielzahl anderer Quellen.
- Viele Azure-Datenbankdienste, einschließlich Azure SQL-Datenbank und Azure Cosmos DB, verfügen über eine automatisierte Sicherungsfunktion für Ihre Datenbanken.
- Azure Key Vault bietet Features zum Sichern Ihrer Geheimnisse, Zertifikate und Schlüssel.
Automatisierte Bereitstellungen
Um erforderliche Ressourcen bei einem Notfall schnell bereitzustellen und zu konfigurieren, verwenden Sie IaC-Ressourcen (Infrastructure-as-Code) wie Bicep-Dateien, ARM-Vorlagen oder Terraform-Konfigurationsdateien. Durch die Verwendung von IaC können Sie die Wiederherstellungszeit und das Fehlerpotenzial im Vergleich zur manuellen Bereitstellung und Konfiguration von Ressourcen reduzieren.
Tests und Übungen
Es ist wichtig, Ihre Notfallwiederherstellungspläne sowie Ihre allgemeinere Zuverlässigkeitsstrategie routinemäßig zu überprüfen und zu testen. Schließen Sie in Ihre Drilldowns auch alle Prozesse ein, die von Personen durchgeführt werden müssen, und konzentrieren Sie sich nicht nur auf die technischen Prozesse.
Wenn Sie Ihre Wiederherstellungsprozesse nicht in einer Notfallsimulation getestet haben, stehen Sie bei einem tatsächlichen Notfall sehr wahrscheinlich vor größeren Problemen. Außerdem können Sie durch Testen Ihrer Notfallwiederherstellungspläne und erforderlichen Prozesse die Machbarkeit Ihres RTO überprüfen.
Weitere Informationen finden Sie unter Empfehlungen für das Entwerfen einer Strategie für Zuverlässigkeitstests.
Zugehöriger Inhalt
- Lesen Sie die Leitfäden zur Zuverlässigkeit von Azure-Diensten, um zu verstehen, wie die einzelnen Azure-Dienste Zuverlässigkeit schon beim Entwurf unterstützen, und um mehr über die Funktionen zu erfahren, die Sie in Ihre Hochverfügbarkeits- und Notfallwiederherstellungspläne integrieren können.
- Unter Azure Well-Architected Framework: Säule „Zuverlässigkeit“ erfahren Sie mehr darüber, wie Sie eine zuverlässige Workload in Azure entwerfen.
- Unter Well-Architected Framework für Azure-Dienste erfahren Sie mehr darüber, wie Sie die einzelnen Azure-Dienste so konfigurieren, dass diese Ihre Anforderungen an Zuverlässigkeit und die anderen Säulen des Well-Architected Framework erfüllen.
- Weitere Informationen zur Planung der Notfallwiederherstellung finden Sie unter Empfehlungen für das Entwerfen einer Notfallwiederherstellungsstrategie.