Was ist Azure Chaos Studio?
Azure Chaos Studio ist ein verwalteter Dienst, der Chaos-Engineering verwendet, um Sie beim Messen, Verstehen und Verbessern der Resilienz Ihrer Cloudanwendungen und Dienste zu unterstützen. Chaos Engineering ist eine Methodik, mit der in der Realität vorkommende Fehler in Ihre Anwendung eingeschleust werden, um kontrollierte Fehlereinschleusungsexperimente durchzuführen.
Resilienz ist die Fähigkeit eines Systems, mit Störungen umzugehen und sich von Störungen zu erholen. Störungen in Anwendungen können Fehler und Ausfälle verursachen, die sich negativ auf Ihr Geschäft oder Ihren Auftrag auswirken können. Gleich, ob Sie Azure-Anwendungen entwickeln, migrieren oder betreiben, es ist wichtig, die Resilienz Ihrer Anwendung zu überprüfen und zu verbessern.
Chaos Studio hilft Ihnen, negative Folgen zu vermeiden, indem Sie überprüfen, ob Ihre Anwendung effektiv auf Unterbrechungen und Fehler reagiert. Sie können Chaos Studio verwenden, um die Resilienz gegen real auftretende Vorfälle zu testen, wie etwa Ausfälle oder hohe CPU-Auslastung auf virtuellen Computern (VMs).
Im folgenden Video finden Sie weitere Hintergrundinformationen zu Chaos Studio:
Chaos Studio-Szenarien
Sie können Chaos-Engineering für verschiedene Szenarien der Resilienzüberprüfung verwenden, die den Lebenszyklus von Dienstentwicklung und -betrieb umfassen. Es gibt zwei Arten von Szenarien:
- Shift-Right: Diese Szenarien verwenden eine Produktions- oder Vorproduktionsumgebung. In der Regel werden Shift-Right-Szenarien mit echtem Datenverkehr von Kunden oder simulierter Last ausgeführt.
- Shift-Left: Diese Szenarien können eine Entwicklungs- oder freigegebene Testumgebung verwenden. Shift-Left-Szenarien können ohne echten Kundendatenverkehr verwendet werden.
Sie können Chaos Studio für die folgenden häufigen Chaos-Engineering-Szenarien verwenden:
- Reproduzieren eines Vorfalls, der Ihre Anwendung betroffen hat, um den Fehler besser zu verstehen. Stellen Sie sicher, dass Reparaturen nach dem Vorfall verhindern, dass der Vorfall erneut auftritt.
- Vorbereiten auf ein größeres Ereignis oder die Saison mit Überprüfung von Last, Skalierung, Leistung und Resilienz an einem „Einsatztag“.
- Führen Sie Business Continuity & Disaster Recovery-Drills aus, um sicherzustellen, dass Ihre Anwendung schnell wiederhergestellt wird und wichtige Daten in einem Notfall erhalten bleiben.
- Führen Sie Hochverfügbarkeitsdrills aus, um die Resilienz einer Anwendung bei bestimmten Fehlern wie Regionsausfällen, Netzwerkkonfigurationsfehlern, Ereignissen mit hoher Auslastung oder Noisy Neighbor-Problemen zu testen.
- Entwickeln von Leistungsbenchmarks für Anwendungen
- Planen des Kapazitätsbedarfs für Produktionsumgebungen
- Ausführen von Belastungs- oder Auslastungstests
- Sicherstellen, dass Dienste, die aus einer lokalen Umgebung oder aus einer anderen Cloudumgebung migriert wurden, weiterhin resilient gegenüber bekannten Fehlern sind
- Schaffen von Vertrauen in Dienste, die auf cloudnativen Architekturen basieren
- Bestätigen, dass Livewebsite-Tools, Daten zum Systemeinblick und Bereitschaftsprozesse auch unter unerwarteten Bedingungen funktionieren
Für viele dieser Szenarien bauen Sie zunächst Resilienz mithilfe von Ad-hoc-Chaos-Experimenten auf. Anschließend überprüfen Sie kontinuierlich, dass neue Bereitstellungen die Resilienz nicht beeinträchtigen. Um dies zu überprüfen, führen Sie Chaos-Experimente als Bereitstellungsgates in Ihren Continuous Integration/Continuous Deployment-Pipelines aus.
Funktionsweise von Chaos Studio
Mit Chaos Studio können Sie die sichere, kontrollierte Fehlereinschleusung in Ihre Azure-Ressourcen koordinieren. Chaos-Experimente bilden das Herzstück von Chaos Studio. Ein Chaos-Experiment beschreibt die Fehler, die ausgeführt werden sollen, und die Ressourcen, für die es ausgeführt wird. Je nach Bedarf können Sie die parallele oder sequenzielle Ausführung von Fehlern organisieren.
Chaos Studio unterstützt zwei Arten von Fehlern:
- Dienstdirekt: Diese Fehler werden direkt auf einer Azure-Ressource ausgeführt, ohne Installation oder Instrumentierung. Zu den Beispielen gehören das Neustarten eines Azure Cache for Redis-Clusters oder das Hinzufügen von Netzwerklatenz zu Azure Kubernetes Service-Pods.
- Agentbasiert: Diese Fehler werden in VMs oder VM-Skalierungsgruppen ausgeführt, um In-Gast-Fehler zu beobachten. Zu den Beispielen zählen die Anwendung von Engpässen an virtuellem Arbeitsspeicher oder das zwangsweise Beenden von Prozessen.
Für jeden Fehler können bestimmte Parameter konfiguriert werden – etwa, welcher Prozess beendet oder wie viel Arbeitsspeicherauslastung generiert werden soll.
Beim Erstellen eines Chaos-Experiments definieren Sie einen oder mehrere Schritte, die nacheinander ausgeführt werden. Jeder Schritt enthält Branches – einen oder mehrere –, die innerhalb des Schritts parallel ausgeführt werden. Jeder Branch enthält eine oder mehrere Aktionen, wie das Einschleusen eines Fehlers oder das Abwarten einer bestimmten Zeitspanne.
Sie strukturieren die Ressourcenziele, für die die einzelnen Fehler ausgeführt werden, in Gruppen, die als Selektoren bezeichnet werden, damit Sie in jeder Aktion komfortabel auf eine Gruppe von Ressourcen verweisen können.
Das folgende Diagramm zeigt das Layout eines Chaos-Experiments in Chaos Studio:
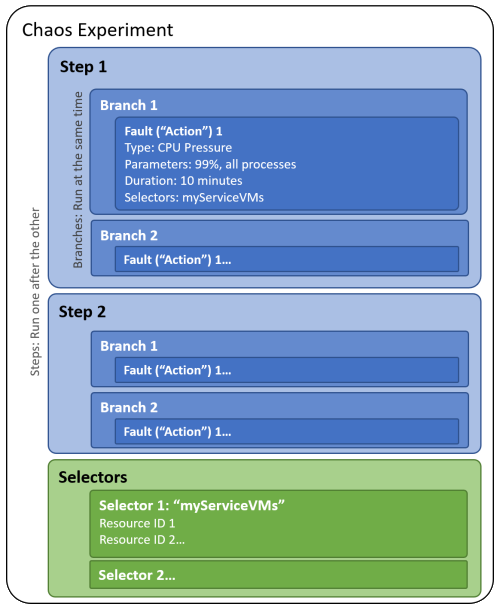
Ein Chaos-Experiment ist eine Azure-Ressource in einem Abonnement und einer Ressourcengruppe. Sie können das Azure-Portal oder die Chaos Studio-REST-API verwenden, um ein Experiment zu erstellen, zu aktualisieren, zu starten, abzubrechen und seinen Status anzuzeigen.
Nächste Schritte
Nachdem Sie nun wissen, wie Sie Chaos Engineering verwenden, können Sie Folgendes tun: