Bereitstellung und Tests für unternehmenskritische Workloads in Azure
Die Bereitstellung und Das Testen der unternehmenskritischen Umgebung ist ein wichtiger Bestandteil der Gesamtreferenzarchitektur. Die einzelnen Anwendungstempel werden mithilfe von Infrastruktur als Code aus einem Quellcode-Repository bereitgestellt. Updates für die Infrastruktur und die darüber liegende Anwendung sollten ohne Ausfallzeiten für die Anwendung eingesetzt werden. Eine DevOps-CI (Continuous Integration)-Pipeline wird empfohlen, um den Quellcode aus dem Repository abzurufen und die einzelnen Zeitstempel in Azure bereitzustellen.
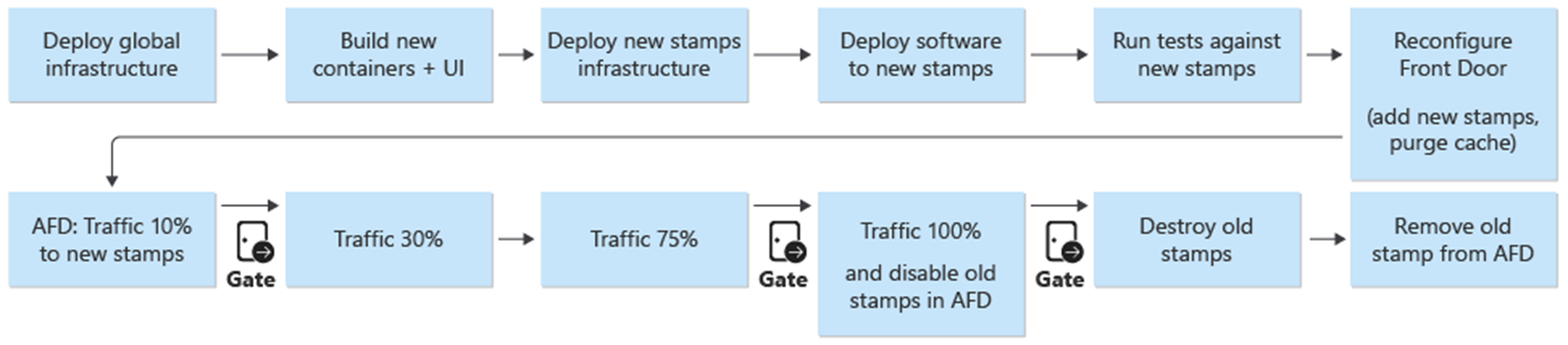
Bereitstellung und Updates sind der zentrale Prozess in der Architektur. Infrastruktur- und anwendungsbezogene Updates sollten für vollständig unabhängige Stempel bereitgestellt werden. Nur die globalen Infrastrukturkomponenten in der Architektur werden über die Stempel hinweg gemeinsam genutzt. Vorhandene Stempel in der Infrastruktur werden nicht berührt. Infrastruktur-Updates werden für diese neuen Stempel bereitgestellt. Ebenso werden die neuen Anwendungsversionen für diese neuen Stempel bereitgestellt.
Die neuen Stempel werden zu Azure Front Door hinzugefügt. Der Datenverkehr wird schrittweise in die neuen Stempel verschoben. Wenn der Datenverkehr von den neuen Stamps ohne Probleme bedient wird, werden die vorherigen Stamps gelöscht.
Penetrations-, Chaos- und Stresstests werden für die bereitgestellte Umgebung empfohlen. Proaktives Testen der Infrastruktur deckt Schwachstellen auf und zeigt, wie sich die eingesetzte Anwendung bei einem Ausfall verhält.
Einsatz
Die Bereitstellung der Infrastruktur in der Referenzarchitektur hängt von den folgenden Prozessen und Komponenten ab:
DevOps – Der Quellcode von GitHub und Pipelines für die Infrastruktur.
Updates ohne Ausfallzeiten – Updates und Upgrades werden ohne Ausfallzeiten für die bereitgestellte Anwendung in der Umgebung bereitgestellt.
Umgebungen – Kurzlebige und dauerhafte Umgebungen, die für die Architektur verwendet werden.
Geteilte und dedizierte Ressourcen – Azure-Ressourcen, die den Stempeln und der gesamten Infrastruktur zugeteilt und gemeinsam genutzt werden.
Weitere Informationen finden Sie unter Bereitstellung und Tests für unternehmenskritische Workloads in Azure: Entwurfsüberlegungen
Bereitstellung: DevOps
Die DevOps-Komponenten stellen das Quellcode-Repository und CI/CD-Pipelines für die Bereitstellung der Infrastruktur und Updates bereit. GitHub- und Azure-Pipelines wurden als Komponenten ausgewählt.
GitHub- – Enthält die Quellcoderepositorys für die Anwendung und Infrastruktur.
Azure Pipelines – Die pipelines, die von der Architektur für alle Build-, Test- und Freigabeaufgaben verwendet werden.
Eine zusätzliche Komponente im Design, das für die Bereitstellung verwendet wird, ist Build-Agents. Microsoft Hosted Build Agents werden als Teil von Azure-Pipelines verwendet, um die Infrastruktur und Updates bereitzustellen. Die Verwendung von Microsoft Hosted Build Agents entfernt die Verwaltungslast für Entwickler, um den Build-Agent zu verwalten und zu aktualisieren.
Weitere Informationen zu Azure-Pipelines finden Sie unter Was ist Azure-Pipelines?.

Weitere Informationen finden Sie unter BereitstellInfrastructure-as-Code deploymentsung und Tests für unternehmenskritische Workloads in Azure: Infrastructure-as-Code-Bereitstellungen
Bereitstellung: Updates ohne Ausfallzeiten
Die Zero-Downtime-Updatestrategie in der Referenzarchitektur ist für die kritische Gesamtanwendung von zentraler Bedeutung. Die Methode des Ersetzens anstelle des Upgrades der Stempel stellt eine neue Installation der Anwendung in einen Infrastrukturstempel sicher. Die Referenzarchitektur verwendet einen blauen/grünen Ansatz und ermöglicht separate Test- und Entwicklungsumgebungen.
Es gibt zwei Hauptkomponenten der Referenzarchitektur:
Infrastructure – Azure-Dienste und -Ressourcen. Bereitgestellt mit Terraform und der zugehörigen Konfiguration.
Application – Der gehostete Dienst oder die gehostete Anwendung, der Benutzern dient. Basierend auf Docker-Containern und mit npm erstellten Artefakten in HTML und JavaScript für die Benutzeroberfläche der SPA (Single-Page-Webanwendung).
In vielen Systemen wird davon ausgegangen, dass Anwendungsupdates häufiger als Infrastrukturupdates sind. Daher werden jeweils unterschiedliche Aktualisierungsverfahren entwickelt. Mit einer öffentlichen Cloudinfrastruktur können Änderungen schneller erfolgen. Es wurde ein Bereitstellungsprozess für Anwendungsupdates und Infrastrukturupdates ausgewählt. Ein Ansatz stellt sicher, dass Infrastruktur- und Anwendungsupdates immer synchronisiert sind. Dieser Ansatz ermöglicht Folgendes:
Ein konsistenter Prozess – Weniger Chancen auf Fehler, wenn Infrastruktur- und Anwendungsupdates in einer Version absichtlich oder nicht miteinander gemischt werden.
Aktiviert die Blue/Green-Bereitstellung – Jedes Update wird mithilfe einer graduellen Migration des Datenverkehrs zur neuen Version bereitgestellt.
Einfachere Bereitstellung und Fehlersuche in der Anwendung – Der gesamte Stamp hostet nie mehrere Versionen der Anwendung nebeneinander.
Einfaches Rollback – Bei Fehlern oder Problemen kann der Datenverkehr zu den Stamps zurückgeschaltet werden, die die vorherige Version ausführen.
Beseitigung manueller Änderungen und Konfigurationsabweichungen – Jede Umgebung ist eine neue Bereitstellung.
Weitere Informationen finden Sie unter Bereitstellung und Testen für unternehmenskritische Workloads auf Azure: Kurzlebige Blau-Grün-Bereitstellungen
Verzweigungsstrategie
Die Grundlage der Updatestrategie ist die Verwendung von Verzweigungen innerhalb des Git-Repositorys. Die Referenzarchitektur verwendet drei Arten von Verzweigungen:
| Zweig | Beschreibung |
|---|---|
feature/* und fix/* |
Die Einstiegspunkte für jede Änderung. Entwickler erstellen diese Verzweigungen und sollten einen beschreibenden Namen erhalten, z. B. feature/catalog-update oder fix/worker-timeout-bug. Wenn Änderungen zur Zusammenführung bereit sind, wird ein PR (Pull Request) für die main-Verzweigung erstellt. Mindestens ein Prüfer muss alle Pullanforderungen genehmigen. Mit begrenzten Ausnahmen muss jede änderung, die in einer PR vorgeschlagen wird, über die End-to-End-Validierungspipeline (E2E) ausgeführt werden. Entwickler sollten die E2E-Pipeline verwenden, um Änderungen an einer vollständigen Umgebung zu testen und zu debuggen. |
main |
Der sich kontinuierlich vorwärts bewegende und stabile Zweig. Wird hauptsächlich für Integrationstests verwendet. Änderungen an main werden nur über Pullanforderungen vorgenommen. Eine Verzweigungsrichtlinie untersagt das direkte Schreiben. Nächtliche Releases in der permanenten integration (int)-Umgebung werden automatisch von der main-Verzweigung ausgeführt. Die main Branch gilt als stabil. Es sollte sicher angenommen werden, dass zu jeder Zeit eine Version daraus erstellt werden kann. |
release/* |
Release-Verzweigungen werden nur aus der main-Verzweigung erstellt. Die Zweige folgen dem Format release/2021.7.X. Verzweigungsrichtlinien werden verwendet, damit nur Repo-Administratoren release/*-Verzweigungen erstellen dürfen. Nur diese Verzweigungen werden verwendet, um die prod-Umgebung bereitzustellen. |
Weitere Informationen finden Sie unter Bereitstellung und Tests für unternehmenskritische Workloads in Azure: Verzweigungsstrategie
Hotfixes
Wenn ein Hotfix dringend aufgrund eines Fehlers oder eines anderen Problems erforderlich ist und der reguläre Releaseprozess nicht durchlaufen kann, ist ein Hotfixpfad verfügbar. Wichtige Sicherheitsupdates und Fixes für die Benutzererfahrung, die während des anfänglichen Tests nicht entdeckt wurden, gelten als gültige Beispiele für Hotfixes.
Der Hotfix muss in einer neuen fix-Verzweigung erstellt und dann mit einem regulären PR in main zusammengeführt werden. Anstatt eine neue Release-Verzweigung zu erstellen, wird der Hotfix im Verfahren des „Cherrypicking“ in eine bestehende Release-Verzweigung eingefügt. Diese Verzweigung wird bereits in der prod-Umgebung bereitgestellt. Die CI/CD Pipeline, die ursprünglich den Release Branch mit allen Tests bereitgestellt hat, wird erneut ausgeführt und stellt den Hotfix als Element der Pipeline bereit.
Um wichtige Probleme zu vermeiden, ist es wichtig, dass der Hotfix ein paar isolierte Commits enthält, die leicht ausgewählt und in den Release-Branch integriert werden können. Wenn isolierte Commits nicht in die Release-Verzweigung integriert werden können, ist es ein Hinweis darauf, dass die Änderung nicht als Hotfix qualifiziert ist. Stellen Sie die Änderung als vollständige neue Version bereit. Kombinieren Sie es mit einem Rollback auf eine frühere stabile Version, bis die neue Version bereitgestellt werden kann.
Bereitstellung: Umgebungen
Die Referenzarchitektur verwendet zwei Typen von Umgebungen für die Infrastruktur:
Kurzlebig – Die E2E-Pipeline zur Validierung wird für die Bereitstellung kurzlebiger Umgebungen verwendet. Kurzlebige Umgebungen werden für reine Validierungs- oder Debuggingumgebungen für Entwickler verwendet. Validierungsumgebungen können aus der
feature/*-Branch erstellt, Tests unterzogen werden können und anschließend zerstört werden können, wenn alle Tests erfolgreich waren. Debugumgebungen werden auf die gleiche Weise wie die Validierung bereitgestellt, werden jedoch nicht sofort zerstört. Diese Umgebungen sollten nicht länger als ein paar Tage existieren und sollten gelöscht werden, wenn der entsprechende PR der Funktionsverzweigung zusammengeführt wird.Permanent – In den permanenten Umgebungen gibt es
integration (int)undproduction (prod)Versionen. Diese Umgebungen leben kontinuierlich und werden nicht zerstört. In den Umgebungen werden feste Domänennamen wieint.mission-critical.appverwendet. In einer realen Implementierung der Referenzarchitektur sollte einestaging(Preprod)-Umgebung hinzugefügt werden. Diestaging-Umgebung wird verwendet, umrelease-Verzweigungen mit demselben Updateprozess wie beiprod(Blau-Grün-Bereitstellung) bereitzustellen und zu überprüfen.Integration (int) – Die Version
intwird jede Nacht vom Branchmainmit demselben Prozess wieprodbereitgestellt. Die Umstellung des Datenverkehrs ist schneller als bei der vorherigen Release-Einheit. Anstatt den Datenverkehr wie beiprodschrittweise über mehrere Tage hinweg umzustellen, wird der Prozess fürintinnerhalb weniger Minuten oder Stunden abgeschlossen. Diese schnellere Umstellung stellt sicher, dass die aktualisierte Umgebung am nächsten Morgen bereit ist. Alte Stempel werden automatisch gelöscht, wenn alle Tests in der Pipeline erfolgreich sind.Production (prod) – Die
prodVersion wird nur vonrelease/*Branches bereitgestellt. Die Verkehrsumstellung verwendet differenziertere Schritte. Ein Gate für die manuelle Genehmigung befindet sich zwischen jedem Schritt. Jede Version erstellt neue regionale Stempel und stellt die neue Anwendungsversion auf den Stempeln bereit. Vorhandene Stempel werden im Prozess nicht berührt. Die wichtigste Erwägung fürprodist, dass es „Always-On“ sein sollte. Es sollten nie geplante oder ungeplante Ausfallzeiten auftreten. Die einzige Ausnahme sind grundlegende Änderungen an der Datenbankebene. Möglicherweise ist ein geplantes Wartungsfenster erforderlich.
Bereitstellung: Freigegebene und dedizierte Ressourcen
Die permanenten Umgebungen (int und prod) innerhalb der Referenzarchitektur weisen unterschiedliche Arten von Ressourcen auf, je nachdem, ob sie mit der gesamten Infrastruktur geteilt oder einem einzelnen Stempel zugeordnet sind. Ressourcen können einer bestimmten Version zugeordnet und nur vorhanden sein, bis die nächste Releaseeinheit übernommen wird.
Release-Einheiten
Eine Release-Einheit besteht aus mehreren regionalen Stempeln pro bestimmter Release-Version. Stempel enthalten alle Ressourcen, die nicht mit anderen Stempeln geteilt werden. Diese Ressourcen sind virtuelle Netzwerke, Azure Kubernetes-Dienstcluster, Event Hubs und Azure Key Vault. Azure Cosmos DB und ACR sind mit Terraform-Datenquellen konfiguriert.
Global freigegebene Ressourcen
Alle ressourcen, die zwischen Freigabeeinheiten gemeinsam genutzt werden, werden in einer unabhängigen Terraform-Vorlage definiert. Diese Ressourcen umfassen Front Door, Azure Cosmos DB, Containerregistrierung (ACR), Log Analytics-Arbeitsbereiche sowie weitere ressourcen zur Überwachung. Diese Ressourcen werden bereitgestellt, bevor der erste regionale Stempel einer Release-Einheit bereitgestellt wird. Auf die Ressourcen wird in den Terraform-Vorlagen für die Stempel verwiesen.
Haustür
Während Front Door eine weltweit gemeinsam genutzte Ressource über Regionen hinweg ist, unterscheidet sich die Konfiguration geringfügig von den anderen globalen Ressourcen. Front Door muss nach der Bereitstellung eines neuen Stempels neu konfiguriert werden. Front Door muss neu konfiguriert werden, um den Datenverkehr schrittweise auf die neuen Stempel umzustellen.
Die Back-End-Konfiguration von Front Door kann nicht direkt in der Terraform-Vorlage definiert werden. Die Konfiguration wird mithilfe von Terraform-Variablen eingefügt. Die Variablenwerte werden erstellt, bevor die Terraform-Bereitstellung gestartet wird.
Die Konfiguration der einzelnen Komponenten für die Bereitstellung von Front Door wird wie folgt definiert:
Frontend- – Die Sitzungsaffinität ist so konfiguriert, dass Benutzer während einer einzelnen Sitzung nicht zwischen verschiedenen Versionen der Benutzeroberfläche wechseln.
Origins – Front Door ist mit zwei Arten von Ursprungsgruppen konfiguriert:
Eine Ursprungsgruppe für statischen Speicher, die der Benutzeroberfläche dient. Die Gruppe enthält die Websitespeicherkonten aus allen aktuell aktiven Release-Einheiten. Verschiedene Gewichtungen können den Ursprüngen aus unterschiedlichen Release-Einheiten zugewiesen werden, um den Datenverkehr schrittweise zu einer neueren Einheit zu verschieben. Jeder Ursprung aus einer Freigabeeinheit sollte die gleiche Gewichtung aufweisen.
Eine Ursprungsgruppe für die API, die auf Azure Kubernetes Service gehostet wird. Wenn Versionseinheiten mit verschiedenen API-Versionen vorhanden sind, ist für jede Releaseeinheit eine API-Ursprungsgruppe vorhanden. Wenn alle Releaseeinheiten dieselbe kompatible API bieten, werden alle Ursprünge derselben Gruppe hinzugefügt und unterschiedlichen Gewichtungen zugewiesen.
Routingregeln : Es gibt zwei Arten von Routingregeln:
Eine Routingregel für die Benutzeroberfläche, die mit der Ui-Speicherursprunggruppe verknüpft ist.
Eine Routingregel für jede API, die derzeit von den Ursprüngen unterstützt wird. Beispiel:
/api/1.0/*und/api/2.0/*.
Wenn in einer Veröffentlichung eine neue Version der Back-End-APIs eingeführt wird, werden die Änderungen in der als Teil der Veröffentlichung bereitgestellten UI sichtbar. Eine bestimmte Version der Benutzeroberfläche ruft immer eine bestimmte Version der API-URL auf. Benutzer, die von einer UI-Version bedient werden, verwenden automatisch die entsprechende Back-End-API. Für unterschiedliche Instanzen der API-Version sind spezifische Routingregeln erforderlich. Diese Regeln sind mit den entsprechenden Ursprungsgruppen verknüpft. Wenn keine neue API eingeführt wurde, werden alle API-bezogenen Routingregeln mit der einzelnen Ursprungsgruppe verknüpft. In diesem Fall spielt es keine Rolle, ob ein Benutzer die Benutzeroberfläche aus einer anderen Version als die API erhält.
Bereitstellung: Bereitstellungsprozess
Eine blaue/grüne Bereitstellung ist das Ziel des Bereitstellungsprozesses. Ein neues Release von einer release/*-Verzweigung wird in der prod-Umgebung bereitgestellt. Der Benutzerdatenverkehr wird schrittweise auf die Stempel für das neue Release verschoben.
Als erster Schritt im Bereitstellungsprozess einer neuen Version wird die Infrastruktur für die neue Releaseeinheit mit Terraform bereitgestellt. Die Ausführung der Infrastruktur-Bereitstellungspipeline stellt die neue Infrastruktur aus einer ausgewählten Release-Verzweigung bereit. Parallel zur Infrastrukturbereitstellung werden die Container-Images erstellt oder importiert und in die global geteilte Containerregistrierung (ACR) übertragen. Wenn die vorherigen Prozesse abgeschlossen sind, wird die Anwendung auf den Stempeln bereitgestellt. Aus Implementierungssicht ist es eine Pipeline mit mehreren abhängigen Stufen. Die gleiche Pipeline kann für Hotfixbereitstellungen erneut ausgeführt werden.
Nachdem die neue Einheit bereitgestellt und validiert wurde, wird die neue Einheit zu Front Door hinzugefügt, um den Datenverkehr der Benutzer zu empfangen.
Ein Schalter/Parameter, der zwischen Versionen unterscheidet, die eine neue API-Version einführen und solchen, die dies nicht tun, sollte geplant werden. Wenn die Veröffentlichung eine neue API-Version einführt, muss eine neue Ursprungsgruppe mit den API-Backends erstellt werden. Alternativ können neue API-Back-Ends zu einer vorhandenen Ursprungsgruppe hinzugefügt werden. Neue Benutzeroberflächenspeicherkonten werden der entsprechenden vorhandenen Ursprungsgruppe hinzugefügt. Gewichtungen für neue Ursprünge sollten entsprechend der gewünschten Verkehrsaufteilung festgelegt werden. Eine neue Routingregel wie zuvor beschrieben muss erstellt werden, die der entsprechenden Ursprungsgruppe entspricht.
Als Teil der Ergänzung der neuen Release-Einheit sollten die Gewichte der neuen Ursprünge auf das gewünschten Minimum an Benutzerdatenverkehr festgelegt werden. Wenn keine Probleme festgestellt werden, sollte der Benutzerverkehr über einen bestimmten Zeitraum auf die neue Ursprungsgruppe ausgeweitet werden. Um die Gewichtungsparameter anzupassen, sollten dieselben Bereitstellungsschritte erneut mit den gewünschten Werten ausgeführt werden.
Release-Einheit Nachbereitung
Als Teil der Bereitstellungspipeline für eine Release-Einheit gibt es eine Zerstörungsphase, in der alle Stempel entfernt werden, sobald eine Release-Einheit nicht mehr benötigt wird. Der gesamte Datenverkehr wird auf eine neue Release-Version umgestellt. Diese Phase umfasst die Entfernung von Release-Einheits-Verweisen von Front Door. Diese Entfernung ist wichtig, um die Veröffentlichung einer neuen Version zu einem späteren Zeitpunkt zu ermöglichen. Front Door muss auf eine einzelne rlease-Einheit verweisen, um in Zukunft auf das nächste Release vorbereitet zu werden.
Checklists
Im Rahmen der Veröffentlichungsrhythmen sollte eine Prüfliste vor und nach der Veröffentlichung verwendet werden. Das folgende Beispiel enthält Elemente, die mindestens in einer Checkliste enthalten sein sollten.
Prüfliste vor der Veröffentlichung – Überprüfen Sie vor dem Starten einer Veröffentlichung Folgendes:
Stellen Sie sicher, dass der neueste Status der
main-Verzweigung erfolgreich in derint-Umgebung bereitgestellt und getestet wurde.Aktualisieren Sie die Änderungsprotokolldatei über einen PR an die
main-Verzweigung.Erstellen Sie aus der
main-Verzweigung einerelease/-Verzweigung.
Post-Release-Checkliste – Bevor alte Stempel zerstört und ihre Referenzen aus Front Door entfernt werden, überprüfen Sie, ob:
Cluster empfangen keinen eingehenden Datenverkehr mehr.
Event Hubs und andere Nachrichtenwarteschlangen enthalten keine unverarbeiteten Nachrichten.
Bereitstellung: Einschränkungen und Risiken der Updatestrategie
Die in dieser Referenzarchitektur beschriebene Updatestrategie weist einige Einschränkungen und Risiken auf, die erwähnt werden sollten:
Höhere Kosten : Bei der Veröffentlichung von Updates sind viele der Infrastrukturkomponenten zweimal für den Veröffentlichungszeitraum aktiv.
Komplexität von Front Door – Der Updateprozess bei Front Door ist komplex zu implementieren und zu pflegen. Die Möglichkeit, effektive blau/grüne Bereitstellungen ohne Ausfallzeiten auszuführen, hängt davon ab, dass sie ordnungsgemäß funktioniert.
Kleine Änderungen zeitaufwendig – Der Updateprozess führt zu einem längeren Veröffentlichungsprozess für kleine Änderungen. Diese Einschränkung kann teilweise mit dem Hotfixprozess abgemildert werden, der im vorherigen Abschnitt beschrieben wird.
Bereitstellung: Überlegungen zur Vorwärtskompatibilität von Anwendungsdaten
Die Updatestrategie kann mehrere Versionen einer API und Arbeitskomponenten unterstützen, die gleichzeitig ausgeführt werden. Da Azure Cosmos DB zwischen zwei oder mehr Versionen geteilt wird, besteht die Möglichkeit, dass Datenelemente, die von einer Version geändert wurden, möglicherweise nicht immer mit der Version der API oder den Mitarbeitern übereinstimmen, die sie verwenden. Die API-Ebenen und -Mitarbeiter müssen den Vorwärtskompatibilitätsentwurf implementieren. Frühere Versionen der API- oder Arbeitskomponenten verarbeiten Daten, die von einer späteren API- oder Workerkomponentenversion eingefügt wurden. Es ignoriert Teile, die es nicht versteht.
Testen
Die Referenzarchitektur enthält unterschiedliche Tests, die in verschiedenen Phasen der Testimplementierung verwendet werden.
Zu diesen Tests gehören:
Komponententests – Diese Tests überprüfen, ob die Geschäftslogik der Anwendung wie erwartet funktioniert. Die Referenzarchitektur enthält eine Beispielsuite von Komponententests, die automatisch vor jedem Containerbuild von Azure Pipelines ausgeführt werden. Wenn ein Test fehlschlägt, wird die Pipeline beendet. Die Erstellung und Bereitstellung wird gestoppt. Der Entwickler muss das Problem beheben, bevor die Pipeline erneut ausgeführt werden kann.
Auslastungstests – Diese Tests helfen dabei, die Kapazität, Skalierbarkeit und potenzielle Engpässe für eine bestimmte Workload oder einen bestimmten Stapel zu bewerten. Die Referenzimplementierung enthält einen Nutzerlastgenerator zur Erstellung synthetischer Lastmuster, die zur Simulation des realen Datenverkehrs verwendet werden können. Der Ladegenerator kann auch unabhängig von der Referenzimplementierung verwendet werden.
Smoke-Tests – Diese Tests ermitteln, ob die Infrastruktur und der Workload verfügbar sind und sich wie erwartet verhalten. Buildakzeptanztests werden als Teil jeder Bereitstellung ausgeführt.
UI-Tests – Diese Tests überprüfen, ob die Benutzeroberfläche bereitgestellt wurde und wie erwartet funktioniert. Die aktuelle Implementierung erfasst nur Screenshots mehrerer Seiten nach der Bereitstellung ohne tatsächliche Tests.
Failure Injection Tests – Diese Tests können automatisiert oder manuell ausgeführt werden. Automatisierte Tests in der Architektur integrieren Azure Chaos Studio als Teil der Bereitstellungspipelinen.
Weitere Informationen finden Sie unter Bereitstellung und Tests für unternehmenskritische Workloads in Azure: Kontinuierliche Validierung und Tests
Tests: Frameworks
Die Online-Referenzimplementierung nutzt, wann immer möglich, bestehende Testmöglichkeiten und Frameworks.
| Rahmenwerk | Testen | Beschreibung |
|---|---|---|
| NUnit | Einheit | Dieses Framework wird für Komponententests des .NET Core-Teils der Implementierung verwendet. Azure Pipelines führt Einheitstests automatisch aus, bevor Container gebaut werden. |
| JMeter mit Azure Load Testing | Einlesen | Azure Load Testing ist ein verwalteter Dienst, der zum Ausführen Apache JMeter Ladetestdefinitionen verwendet wird. |
| Heuschrecke | Einlesen | Locust ist ein Open-Source-Lastentestframework, das in Python geschrieben wurde. |
| Playwright | Benutzeroberfläche und Buildakzeptanz | Playwright ist eine Open Source-Node.js-Bibliothek, um Chromium, Firefox und WebKit mit einer einzigen API zu automatisieren. Die Playwright-Testdefinition kann auch unabhängig von der Referenzimplementierung verwendet werden. |
| Azure Chaos Studio | Fehlereinschleusung | Die Referenzimplementierung verwendet Azure Chaos Studio als optionalen Schritt in der E2E-Validierungspipeline, um Fehler für die Resilienzüberprüfung zu injizieren. |
Tests: Fehlereinschleusungstests und Chaos Engineering
Verteilte Anwendungen sollten ausfallsicher gegenüber Dienst- und Komponentenausfällen sein. Fehlerinjektionstests (auch als Fault Injection oder Chaos Engineering bezeichnet) bezeichnen die Praxis, bei der Anwendungen und Dienste realen Belastungen und Ausfällen ausgesetzt werden.
Resilienz ist eine Eigenschaft eines gesamten Systems und das Einfügen von Fehlern hilft, Probleme in der Anwendung zu finden. Durch die Behebung dieser Probleme können Sie die Ausfallsicherheit von Anwendungen auf unzuverlässige Bedingungen, fehlende Abhängigkeiten und andere Fehler überprüfen.
Manuelle und automatische Tests können anhand der Infrastruktur ausgeführt werden, um Fehler und Probleme in der Implementierung zu finden.
Automatisch
In der Referenzarchitektur ist Azure Chaos Studio integriert, um eine Reihe von Azure Chaos Studio-Experimenten bereitzustellen und auszuführen, die verschiedene Fehler auf Stempelebene einschleusen. Chaosexperimente können als optionaler Teil der E2E-Bereitstellungspipeline ausgeführt werden. Wenn die Tests ausgeführt werden, wird der optionale Auslastungstest immer parallel ausgeführt. Der Auslastungstest wird verwendet, um eine Belastung des Clusters zu erzeugen und die Auswirkung der eingefügten Fehler zu überprüfen.
Handbuch
Die manuellen Fehlerinjektionstests sollten in einer E2E-Validierungsumgebung durchgeführt werden. Diese Umgebung stellt vollständige repräsentative Tests ohne Risiko von Störungen aus anderen Umgebungen sicher. Die meisten der mit den Tests erzeugten Fehler können direkt in der „Application Insights“-Ansicht Live-Metriken beobachtet werden. Die verbleibenden Fehler sind in der Fehleransicht und den entsprechenden Protokolltabellen verfügbar. Andere Fehler erfordern ein tieferes Debuggen, z. B. die Verwendung von kubectl, um das Verhalten innerhalb von Azure Kubernetes Service zu beobachten.
Zwei Beispiele für Fehlereinschleusungstests für die Referenzarchitektur sind:
DNS (Domain Name Service) – basierte Fehlerinjektion – Ein Testfall, der mehrere Probleme simulieren kann. DNS-Auflösungsfehler aufgrund des Ausfalls eines DNS-Servers oder von Azure DNS. DNS-basierte Tests können allgemeine Verbindungen zwischen einem Client und einem Dienst simulieren, z. B. wenn der BackgroundProcessor- keine Verbindung mit den Event Hubs herstellen kann.
In Einzelhostszenarien können Sie die lokale
hostsDatei ändern, um die DNS-Auflösung zu überschreiben. In einer größeren Umgebung mit mehreren dynamischen Servern wie AKS ist einehostsDatei nicht machbar. Azure Private DNS Zones können als Alternative zu Fehlerszenarien in Tests verwendet werden.Azure Event Hubs und Azure Cosmos DB sind zwei der Azure-Dienste, die in der Referenzimplementierung verwendet werden, die zum Einfügen von DNS-basierten Fehlern verwendet werden können. Die DNS-Auflösung von Event Hubs kann mit einer Azure Privates DNS-Zone bearbeitet werden, die an das virtuelle Netzwerk eines der Stempel gebunden ist. Azure Cosmos DB ist ein global replizierter Dienst mit bestimmten regionalen Endpunkten. Die Manipulation der DNS-Einträge für diese Endpunkte kann einen Fehler für eine bestimmte Region simulieren und das Failover von Clients testen.
Firewall blockiert Zugriff – Die meisten Azure-Dienste unterstützen Firewall-Zugriffsbeschränkungen basierend auf virtuellen Netzwerken und/oder IP-Adressen. In der Referenzinfrastruktur werden diese Einschränkungen verwendet, um den Zugriff auf Azure Cosmos DB oder Event Hubs einzuschränken. Eine einfache Vorgehensweise besteht darin, vorhandene Zulassungs-Regeln zu entfernen oder neue Blockierungs-Regeln hinzuzufügen. Dieses Verfahren kann Firewall-Fehlkonfigurationen oder Dienstausfälle simulieren.
Die folgenden Beispieldienste in der Referenzimplementierung können mit einem Firewalltest getestet werden:
Dienst Ergebnis Key Vault Wenn der Zugang zu Key Vault blockiert ist, ist die direkteste Auswirkung das Fehlschlagen des Erzeugens neuer Pods. Der Key Vault CSI-Treiber, der Geheimnisse beim Podstart abruft, kann seine Aufgaben nicht ausführen und verhindert, dass der Pod gestartet wird. Entsprechende Fehlermeldungen können mit kubectl describe po CatalogService-deploy-my-new-pod -n workloadbeobachtet werden. Vorhandene Pods funktionieren weiterhin, obwohl die gleiche Fehlermeldung beobachtet wird. Die Ergebnisse der regelmäßigen Aktualisierungsprüfung auf geheime Schlüssel generieren die Fehlermeldung. Obwohl ungetestet, funktioniert die Ausführung einer Bereitstellung nicht, wenn der Key Vault nicht zugänglich ist. Terraform- und Azure CLI-Aufgaben innerhalb der Pipeline führen Anforderungen an Key Vault aus.Event Hubs Wenn der Zugriff auf Event Hubs blockiert wird, schlagen neue Nachrichten fehl, die vom CatalogService und vom HealthService gesendet werden. Nachrichtenabrufe durch den BackgroundProcess beginnen langsam zu scheitern, bis sie innerhalb weniger Minuten komplett ausfallen. Azure Cosmos DB Das Entfernen der vorhandenen Firewallrichtlinie für ein virtuelles Netzwerk führt dazu, dass der Integritätsdienst mit minimaler Verzögerung fehlschlägt. Dieses Verfahren simuliert nur einen bestimmten Fall, einen gesamten Azure Cosmos DB-Ausfall. Die meisten Fehlerfälle, die auf regionaler Ebene auftreten, werden automatisch mit einem transparenten Failover des Clients zu einer anderen Azure Cosmos DB-Region abgemildert. Die zuvor beschriebenen DNS-basierten Fehlerinjektionstests sind ein aussagekräftigerer Test für Azure Cosmos DB. Container Registry (ACR) Wenn der Zugriff auf ACR blockiert ist, funktioniert die Erstellung neuer Pods, die zuvor auf einem AKS-Knoten abgerufen und zwischengespeichert wurden, weiterhin. Die Erstellung funktioniert aufgrund des K8s pullPolicy=IfNotPresent-Flags für die Bereitstellung noch. Knoten können keine neuen Pods erzeugen und schlagen sofort mitErrImagePullFehlern fehl, wenn der Knoten nicht vor der Blockierung ein Image zieht und zwischenspeichert.kubectl describe podzeigt die entsprechende403 ForbiddenMeldung an.AKS Ingress Load-Balancer Die Änderung der Eingangsregeln für HTTP(S)(Ports 80 und 443) in der von AKS verwalteten Netzwerksicherheitsgruppe (NSG) zu Verweigern führt dazu, dass der Datenverkehr von Benutzern oder aus dem Integritätstest den Cluster nicht erreicht. Bei der Prüfung dieses Fehlers ist es schwierig, die Grundursache zu ermitteln, die als Blockade zwischen dem Netzwerkpfad von Front Door und einem regionalen Stempel simuliert wurde. Front Door erkennt diesen Fehler sofort und nimmt den Stempel aus der Rotation.