Bedste praksis for design og udvikling af komplekse dataflow
Hvis det dataflow, du udvikler, bliver større og mere komplekst, kan du her se nogle ting, du kan gøre for at forbedre dit oprindelige design.
Opdel den i flere dataflow
Gør ikke alt i ét dataflow. Et enkelt, komplekst dataflow gør ikke kun datatransformationsprocessen længere, det gør det også sværere at forstå og genbruge dataflowet. Du kan opdele dit dataflow i flere dataflow ved at adskille tabeller i forskellige dataflow eller endda én tabel i flere dataflow. Du kan bruge begrebet en beregnet tabel eller sammenkædet tabel til at bygge en del af transformationen i ét dataflow og genbruge den i andre dataflow.
Opdel datatransformationsdataflow fra midlertidige/udtrækkede dataflow
At have nogle dataflow kun til udtrækning af data (dvs. midlertidige dataflows) og andre kun til transformering af data er nyttigt, ikke kun for oprettelse af en flerlagsarkitektur, det er også nyttigt for at reducere kompleksiteten af dataflow. Nogle trin udtrækker blot data fra datakilden, f.eks. ændringer af data, navigation og datatype. Ved at adskille de midlertidige dataflow og transformationsdataflow gør du dine dataflow enklere at udvikle.
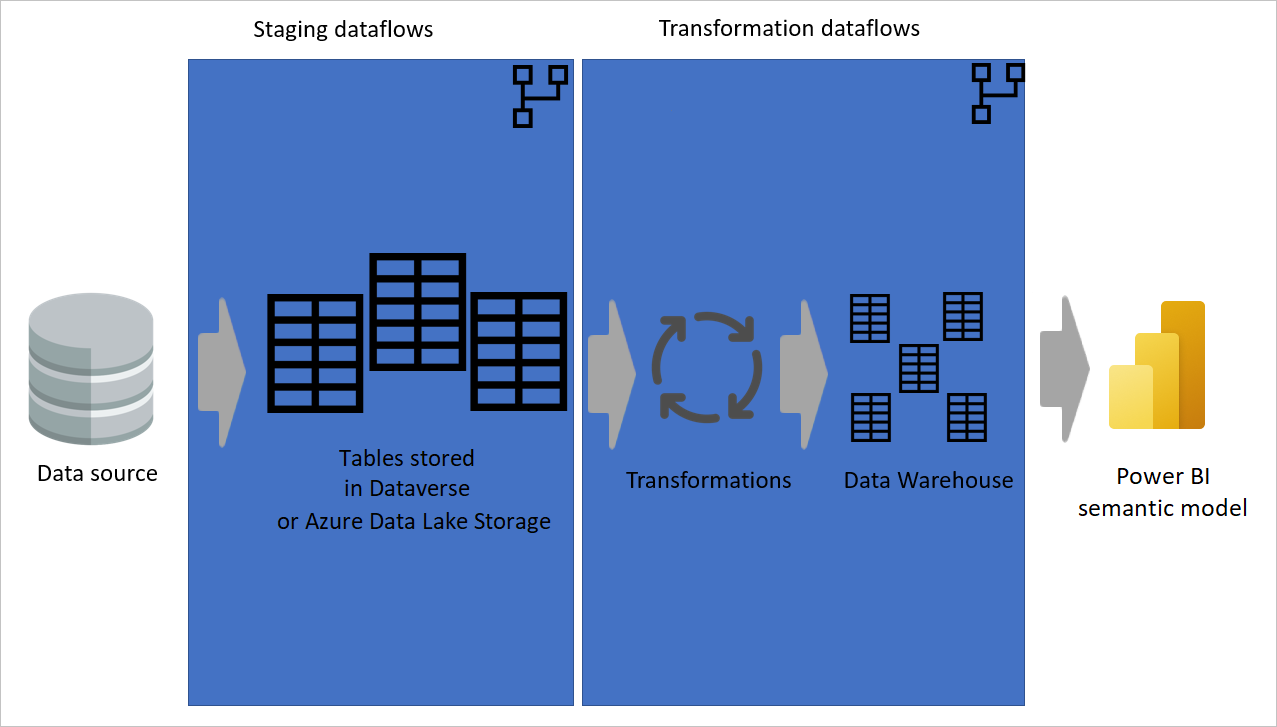
Billede, der viser data, der udtrækkes fra en datakilde til midlertidige dataflow, hvor tabellerne enten gemmes i Dataverse eller Azure Data Lake Storage. Derefter flyttes dataene til transformationsdataflow, hvor dataene transformeres og konverteres til data warehouse-strukturen. Derefter flyttes dataene til den semantiske model.
Brug brugerdefinerede funktioner
Brugerdefinerede funktioner er nyttige i scenarier, hvor der skal udføres et bestemt antal trin for en række forespørgsler fra forskellige kilder. Brugerdefinerede funktioner kan udvikles via den grafiske grænseflade i Power Query-editor eller ved hjælp af et M-script. Funktioner kan genbruges i et dataflow i så mange tabeller, der er behov for.
Det hjælper at have en brugerdefineret funktion ved kun at have en enkelt version af kildekoden, så du ikke behøver at duplikere koden. Det er derfor meget nemmere at vedligeholde Power Query-transformationslogikken og hele dataflowet. Du kan få flere oplysninger i følgende blogindlæg: Brugerdefinerede funktioner, der er nemme at bruge i Power BI Desktop.
Seddel
Nogle gange modtager du muligvis en meddelelse, der fortæller dig, at en Premium-kapacitet er påkrævet for at opdatere et dataflow med en brugerdefineret funktion. Du kan ignorere denne meddelelse og åbne datafloweditoren igen. Dette løser normalt dit problem, medmindre din funktion refererer til en "indlæsningsaktiveret" forespørgsel.
Placer forespørgsler i mapper
Brug af mapper til forespørgsler hjælper med at gruppere relaterede forespørgsler sammen. Når du udvikler dataflowet, skal du bruge lidt mere tid på at arrangere forespørgsler i mapper, der giver mening. Ved hjælp af denne fremgangsmåde kan du nemmere finde forespørgsler fremover, og det er meget nemmere at vedligeholde koden.
Brug beregnede tabeller
Beregnede tabeller gør ikke kun dit dataflow mere forståeligt, de giver også en bedre ydeevne. Når du bruger en beregnet tabel, henter de andre tabeller, der refereres til, data fra en tabel, der allerede er behandlet og gemt. Transformationen er meget enklere og hurtigere.
Udnyt det forbedrede beregningsprogram
I forbindelse med dataflow, der er udviklet i Power BI-administrationsportalen, skal du sikre dig, at du bruger det forbedrede beregningsprogram ved først at udføre joinforbindelser og filtertransformationer i en beregnet tabel, før du udfører andre typer transformationer.
Opdel mange trin i flere forespørgsler
Det er svært at holde styr på et stort antal trin i én tabel. Du bør i stedet opdele et stort antal trin i flere tabeller. Du kan bruge Aktivér indlæsning for andre forespørgsler og deaktivere dem, hvis de er mellemliggende forespørgsler, og kun indlæse den endelige tabel via dataflowet. Når du har flere forespørgsler med mindre trin i hver, er det nemmere at bruge afhængighedsdiagrammet og spore hver forespørgsel til yderligere undersøgelse i stedet for at grave i hundredvis af trin i én forespørgsel.
Tilføj egenskaber for forespørgsler og trin
Dokumentation er nøglen til at have kode, der er nem at vedligeholde. I Power Query kan du føje egenskaber til tabellerne og også til trin. Den tekst, du tilføjer i egenskaberne, vises som et værktøjstip, når du holder markøren over forespørgslen eller trinnet. Denne dokumentation hjælper dig med at vedligeholde din model i fremtiden. Med et blik på en tabel eller et trin kan du forstå, hvad der sker der, i stedet for at overveje og huske, hvad du har gjort i det pågældende trin.
Sørg for, at kapaciteten er i det samme område
Dataflow understøtter i øjeblikket ikke flere lande eller områder. Premium-kapaciteten skal være i det samme område som din Power BI-lejer.
Adskil kilder i det lokale miljø fra kilder i cloudmiljøet
Vi anbefaler, at du opretter et separat dataflow for hver type kilde, f.eks. i det lokale miljø, cloudmiljøet, SQL Server, Spark og Dynamics 365. Hvis du adskiller dataflow efter kildetype, kan du hurtigt foretage fejlfinding og undgå interne grænser, når du opdaterer dine dataflow.
Adskil dataflow baseret på den planlagte opdatering, der kræves for tabeller
Hvis du har en salgstransaktionstabel, der opdateres i kildesystemet hver time, og du har en produkttilknytningstabel, der opdateres hver uge, skal du opdele disse to tabeller i to dataflow med forskellige tidsplaner for opdatering af data.
Undgå at planlægge opdatering af sammenkædede tabeller i det samme arbejdsområde
Hvis du jævnligt låses ude af dine dataflow, der indeholder sammenkædede tabeller, kan det skyldes et tilsvarende, afhængigt dataflow i det samme arbejdsområde, der er låst under opdatering af dataflow. En sådan låsning giver transaktionsnøjagtighed og sikrer, at begge dataflow opdateres korrekt, men det kan forhindre dig i at redigere.
Hvis du konfigurerer en separat tidsplan for det sammenkædede dataflow, kan dataflow opdateres unødigt og forhindre dig i at redigere dataflowet. Der er to anbefalinger for at undgå dette problem:
- Angiv ikke en tidsplan for opdatering for et sammenkædet dataflow i det samme arbejdsområde som kildedataflowet.
- Hvis du vil konfigurere en tidsplan for opdatering separat og undgå låsefunktionsmåden, skal du flytte dataflowet til et separat arbejdsområde.