Bedste fremgangsmåder til oprettelse af en dimensionel model ved hjælp af dataflow
Design af en dimensionel model er en af de mest almindelige opgaver, du kan udføre med et dataflow. I denne artikel fremhæves nogle af de bedste fremgangsmåder til oprettelse af en dimensionel model ved hjælp af et dataflow.
Midlertidige dataflow
Et af nøglepunkterne i ethvert dataintegrationssystem er at reducere antallet af læsninger fra kildesystemet. I den traditionelle dataintegrationsarkitektur udføres denne reduktion ved at oprette en ny database, der kaldes en midlertidig database. Formålet med den midlertidige database er at indlæse data as-is fra datakilden i den midlertidige database efter en regelmæssig tidsplan.
Resten af dataintegrationen bruger derefter den midlertidige database som kilde til yderligere transformation og konverterer den til den dimensionelle modelstruktur.
Vi anbefaler, at du følger den samme fremgangsmåde ved hjælp af dataflow. Opret et sæt dataflow, der er ansvarlige for kun at indlæse data as-is fra kildesystemet (og kun for de tabeller, du har brug for). Resultatet gemmes derefter i dataflowets lagerstruktur (enten Azure Data Lake Storage eller Dataverse). Denne ændring sikrer, at læsehandlingen fra kildesystemet er minimal.
Derefter kan du oprette andre dataflow, der henter deres data fra midlertidige dataflow. Fordelene ved denne fremgangsmåde omfatter:
- Reduktion af antallet af læsehandlinger fra kildesystemet og reduktion af belastningen af kildesystemet som følge heraf.
- Reduktion af belastningen på datagateways, hvis der bruges en datakilde i det lokale miljø.
- Have en mellemliggende kopi af dataene til afstemningsformål, hvis kildesystemets data ændres.
- Gør transformationsdataflowet kildeuafhængigt.
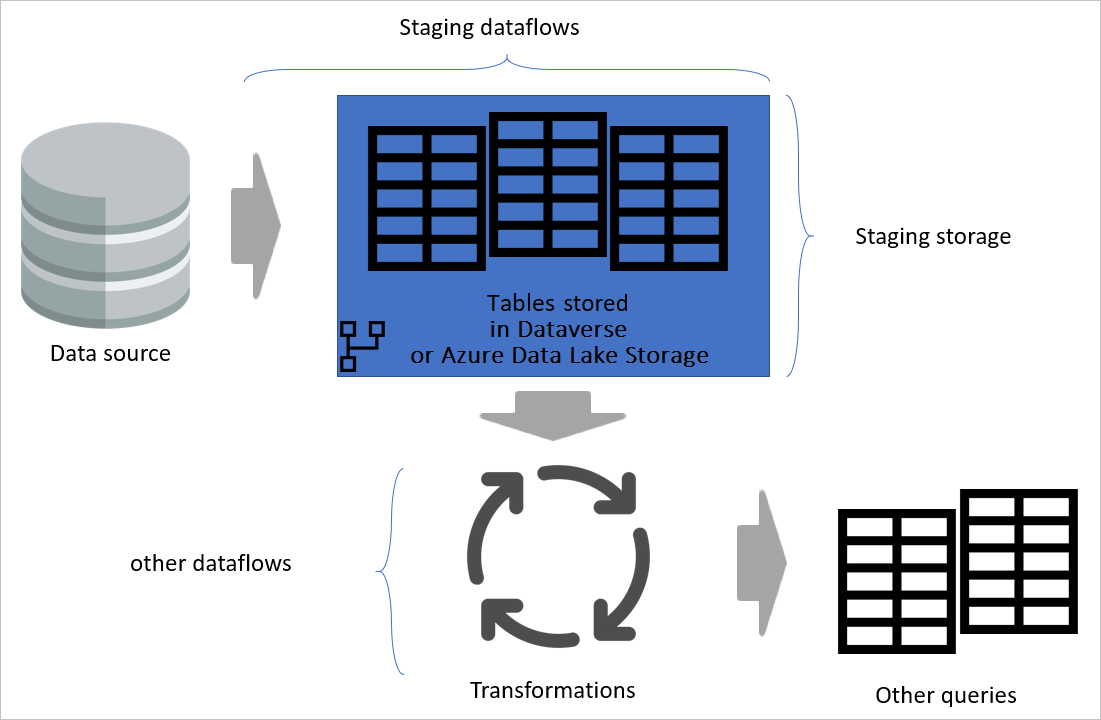
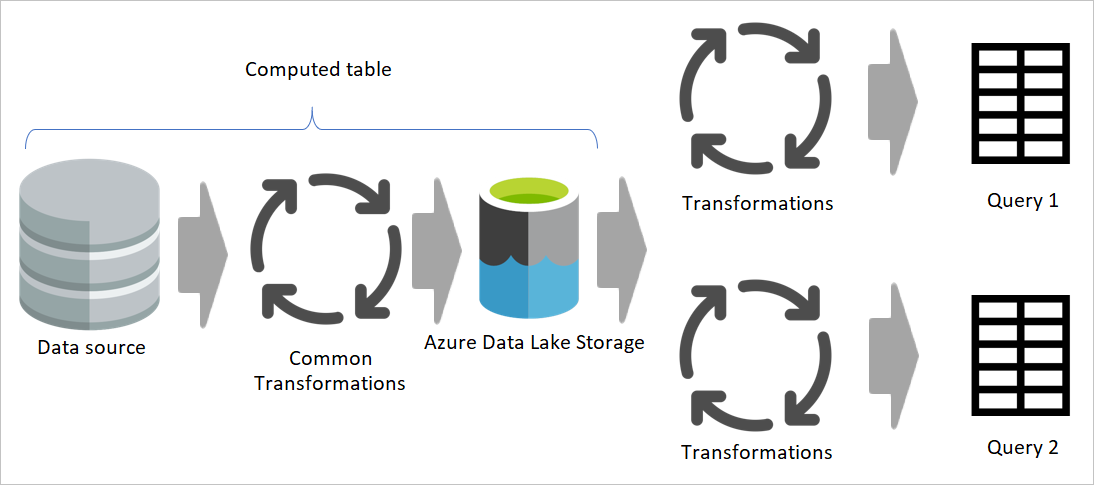
Billede, der understreger midlertidige dataflow og lagring af midlertidige data og viser de data, der tilgås fra datakilden af det midlertidige dataflow, og tabeller, der gemmes i enten Cadavers eller Azure Data Lake Storage. Tabellerne vises derefter, der transformeres sammen med andre dataflow, som derefter sendes ud som forespørgsler.
Transformationsdataflow
Når du har adskilt dine transformationsdataflow fra de midlertidige dataflow, vil transformationen være uafhængig af kilden. Denne adskillelse hjælper, hvis du overfører kildesystemet til et nyt system. Det eneste, du skal gøre i dette tilfælde, er at ændre de midlertidige dataflow. Transformationsdataflowene fungerer sandsynligvis uden problemer, fordi de kun hentes fra de midlertidige dataflow.
Denne adskillelse hjælper også, hvis kildesystemets forbindelse er langsom. Transformationsdataflowet behøver ikke at vente i lang tid for at få poster via en langsom forbindelse fra kildesystemet. Det midlertidige dataflow har allerede gjort denne del, og dataene er klar til transformationslaget.
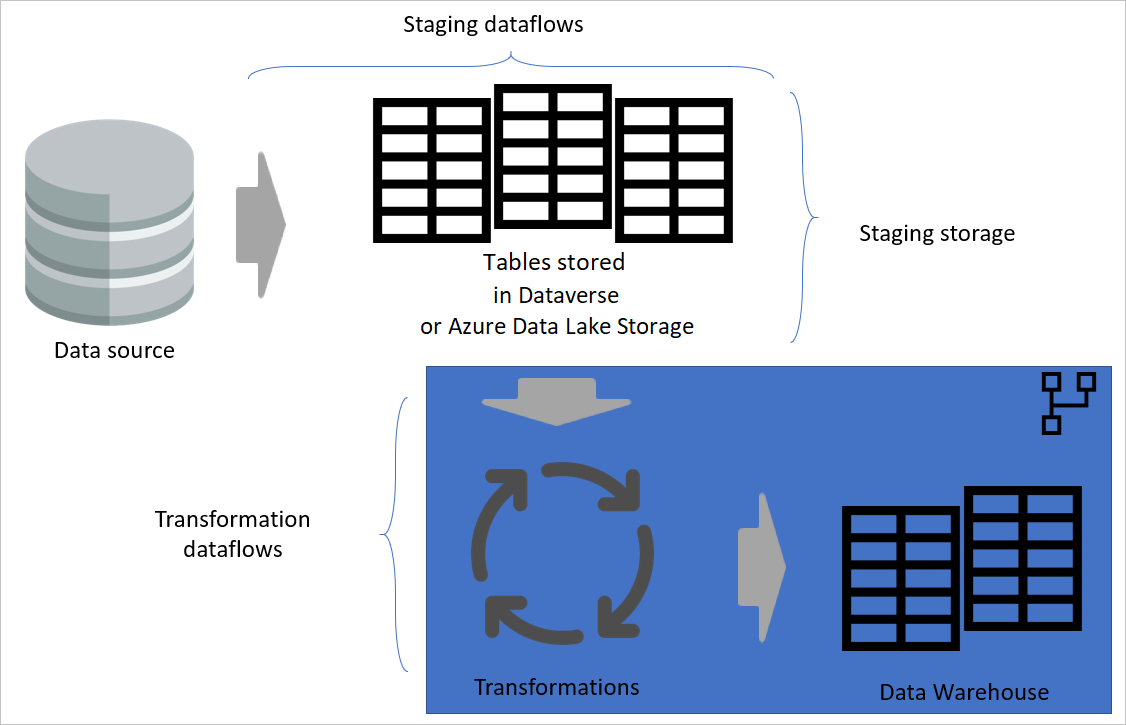
Lagdelt arkitektur
En lagdelt arkitektur er en arkitektur, hvor du udfører handlinger i separate lag. Dataflowet til midlertidig lagring og transformation kan være to lag af en arkitektur med flere lag dataflow. Hvis du forsøger at udføre handlinger i lag, sikrer du den minimale vedligeholdelse, der kræves. Når du vil ændre noget, skal du blot ændre det i det lag, hvor det er placeret. De andre lag skal alle fortsætte med at fungere fint.
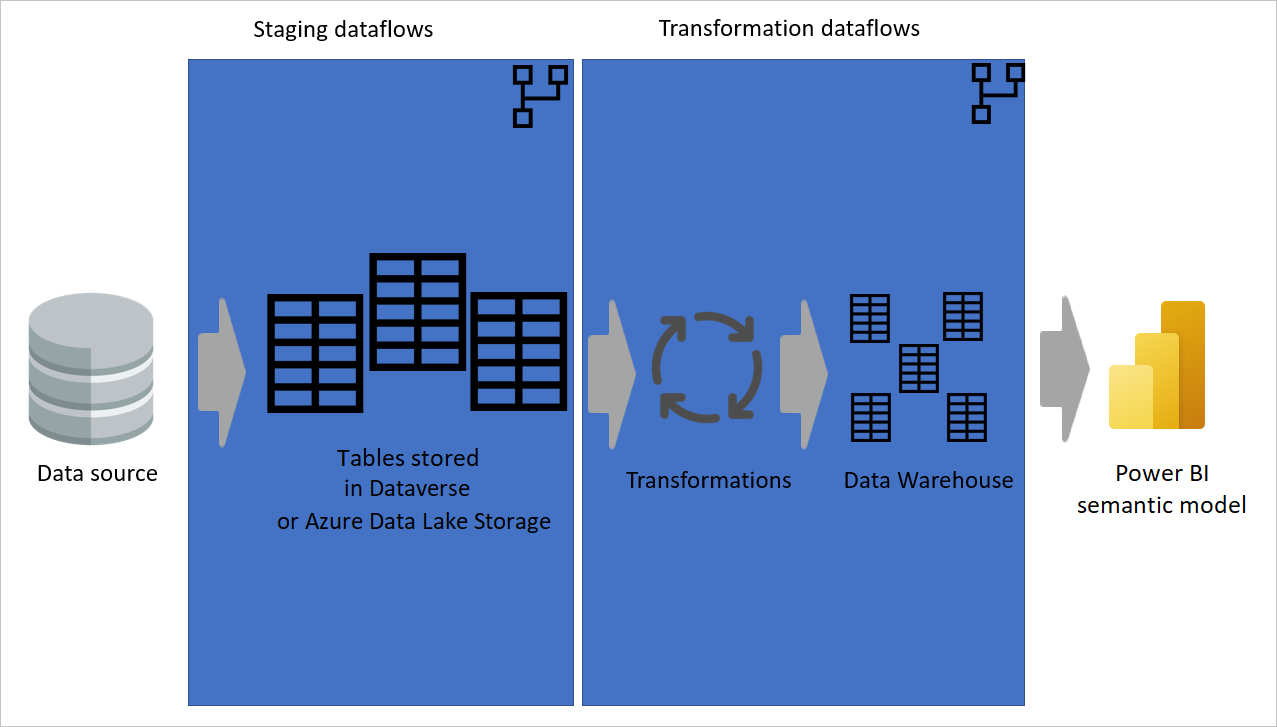
På følgende billede vises en flerlagsarkitektur for dataflow, hvor deres tabeller derefter bruges i semantiske Power BI-modeller.
Brug en beregnet tabel så meget som muligt
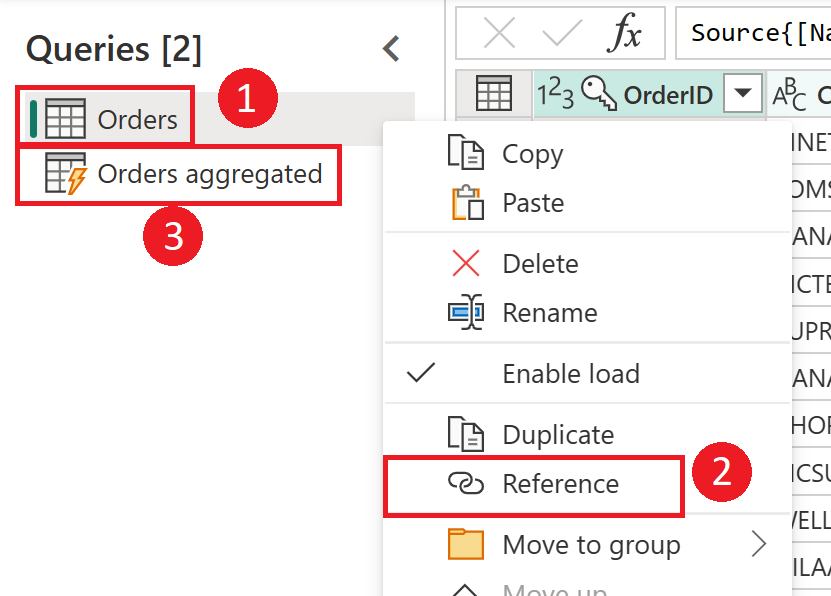
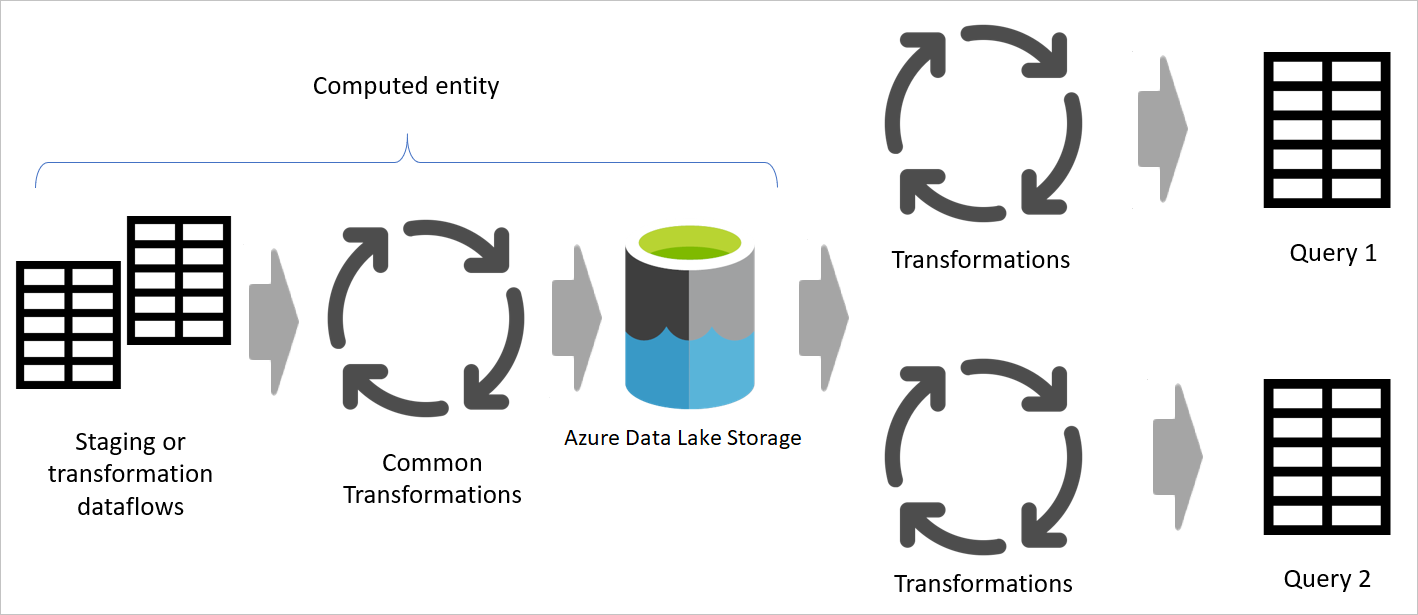
Når du bruger resultatet af et dataflow i et andet dataflow, bruger du begrebet den beregnede tabel, hvilket betyder, at du henter data fra en tabel, der allerede er behandlet og gemt. Det samme kan ske i et dataflow. Når du refererer til en tabel fra en anden tabel, kan du bruge den beregnede tabel. Dette er nyttigt, når du har et sæt transformationer, der skal udføres i flere tabeller, som kaldes almindelige transformationer.
På det forrige billede henter den beregnede tabel dataene direkte fra kilden. Men i arkitekturen for midlertidige dataflow og transformationsdataflow er det sandsynligt, at de beregnede tabeller hentes fra de midlertidige dataflow.
Opret et stjerneskema
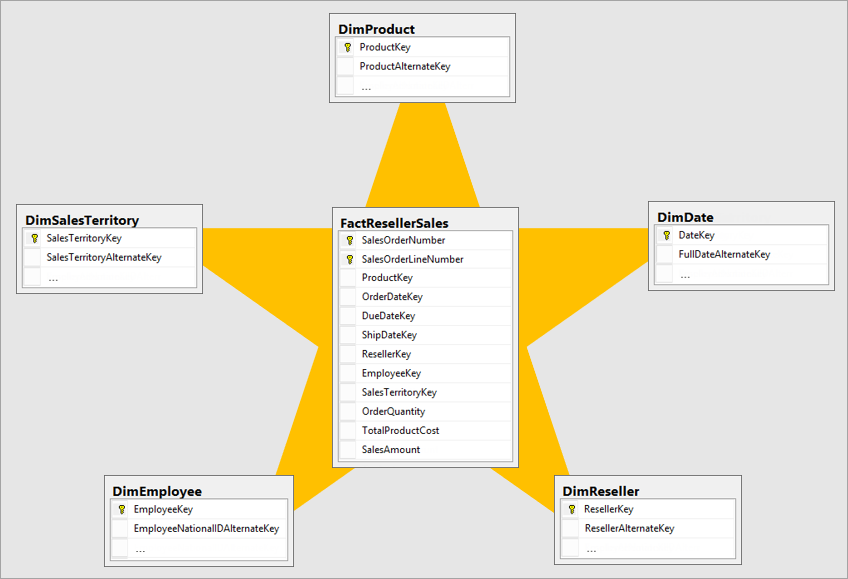
Den bedste dimensionsmodel er en stjerneskemamodel, der har dimensioner og faktatabeller, der er designet på en måde for at minimere den tid, det tager at forespørge dataene fra modellen, og som også gør det nemt at forstå for datavisualiseringsfunktionen.
Det er ikke ideelt at overføre data i det samme layout af driftssystemet til et BI-system. Datatabellerne skal ombygges. Nogle af tabellerne skal have form af en dimensionstabel, som indeholder de beskrivende oplysninger. Nogle af tabellerne bør have form af en faktatabel for at bevare de aggregerede data. Det bedste layout til faktatabeller og dimensionstabeller, der skal dannes, er et stjerneskema. Flere oplysninger: Forstå stjerneskemaet og vigtigheden af Power BI-
Brug en entydig nøgleværdi til dimensioner
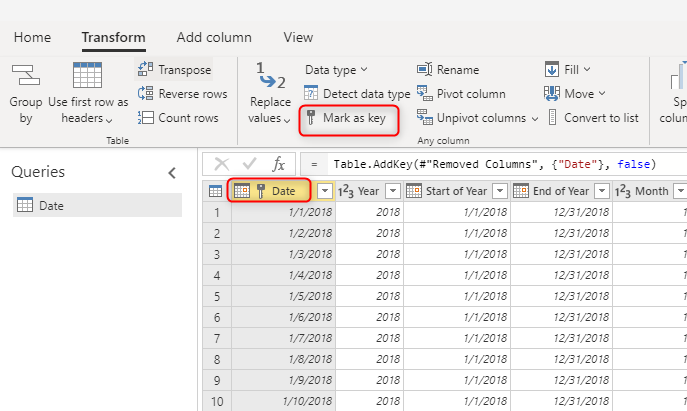
Når du opretter dimensionstabeller, skal du sørge for, at du har en nøgle til hver enkelt. Denne nøgle sikrer, at der ikke er mange til mange-relationer (eller med andre ord "svage") relationer mellem dimensioner. Du kan oprette nøglen ved at anvende en transformation for at sikre, at en kolonne eller en kombination af kolonner returnerer entydige rækker i dimensionen. Derefter kan denne kombination af kolonner markeres som en nøgle i tabellen i dataflowet.
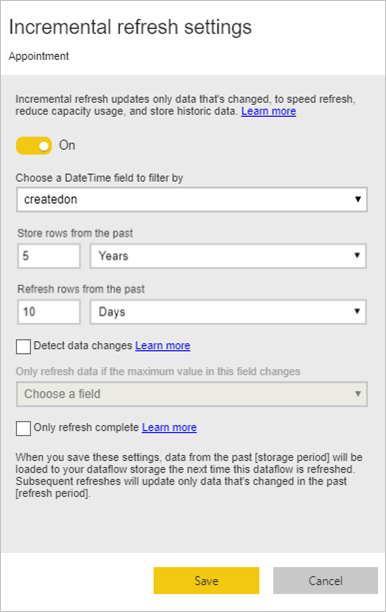
Udfører en trinvis opdatering af store faktatabeller
Faktatabeller er altid de største tabeller i den dimensionelle model. Vi anbefaler, at du reducerer antallet af rækker, der er overført for disse tabeller. Hvis du har en meget stor faktatabel, skal du sikre dig, at du bruger trinvis opdatering for den pågældende tabel. En trinvis opdatering kan udføres i den semantiske Power BI-model og også i dataflowtabellerne.
Du kan bruge trinvis opdatering til kun at opdatere en del af dataene, som er den del, der er ændret. Der er flere muligheder for at vælge, hvilken del af dataene der skal opdateres, og hvilken del der skal bevares. Flere oplysninger: Brug af trinvis opdatering med Power BI-dataflow
Reference til oprettelse af dimensioner og faktatabeller
I kildesystemet har du ofte en tabel, som du bruger til at generere både fakta- og dimensionstabeller i data warehouse. Disse tabeller er gode kandidater til beregnede tabeller og også mellemliggende dataflow. Den fælles del af processen – f.eks. datarensning og fjernelse af ekstra rækker og kolonner – kan udføres én gang. Ved at bruge en reference fra outputtet af disse handlinger kan du oprette dimensions- og faktatabellerne. Denne fremgangsmåde bruger den beregnede tabel til de almindelige transformationer.