Udvikl løsninger med dataflow
Power BI-dataflow er en virksomhedsfokuseret dataforberedelsesløsning , der muliggør et økosystem af data, der er klar til forbrug, genbrug og integration. Denne artikel præsenterer nogle almindelige scenarier, links til artikler og andre oplysninger, der kan hjælpe dig med at forstå og bruge dataflow til deres fulde potentiale.
Få adgang til Premium-funktioner i dataflow
Power BI-dataflow i Premium-kapaciteter indeholder mange vigtige funktioner, der hjælper med at opnå større skalering og ydeevne for dine dataflow, f.eks.:
- Avanceret beregning, som fremskynder ETL-ydeevnen og leverer DirectQuery-funktioner.
- Trinvis opdatering, hvor du kan indlæse data, der er ændret fra en kilde.
- Sammenkædede objekter, som du kan bruge til at referere til andre dataflow.
- Beregnede enheder, som du kan bruge til at bygge komponenter i dataflow, der indeholder mere forretningslogik.
Af disse årsager anbefaler vi, at du bruger dataflow i en Premium-kapacitet, når det er muligt. Dataflow, der bruges i en Power BI Pro-licens, kan bruges til enkle, små use cases.
Løsning
Det er muligt at få adgang til disse Premium-funktioner i dataflow på to måder:
- Angiv en Premium-kapacitet til et bestemt arbejdsområde, og medbring din egen Pro-licens til oprettelse af dataflow her.
- Medbring din egen licens til Premium pr. bruger (PREMIUM), som kræver, at andre medlemmer af arbejdsområdet også har en Premium pr. bruger-licens.
Du kan ikke bruge Premium pr. bruger-dataflow (eller andet indhold) uden for Premium pr. bruger-miljø (f.eks. i Premium eller andre SKU'er eller licenser).
I forbindelse med Premium-kapaciteter behøver dine forbrugere af dataflow i Power BI Desktop ikke eksplicitte licenser for at forbruge og publicere til Power BI. Men hvis du vil publicere til et arbejdsområde eller dele en deraf følgende semantisk model, skal du som minimum have en Pro-licens.
For Premium pr. bruger skal alle, der opretter eller bruger Premium pr. bruger-indhold, have en Premium pr. bruger-licens. Dette krav varierer fra resten af Power BI, da du udtrykkeligt skal licensere alle med Premium pr. bruger. Du kan ikke blande gratis, Pro eller endda Premium-kapaciteter med premiumindhold, medmindre du overfører arbejdsområdet til en Premium-kapacitet.
Valg af en model afhænger typisk af organisationens størrelse og mål, men følgende retningslinjer gælder.
| Teamtype | Premium pr. kapacitet | Premium pr. bruger |
|---|---|---|
| >5.000 brugere | ✔ | |
| <5.000 brugere | ✔ |
For små teams kan Premium pr. bruger bygge bro mellem gratis, Pro og Premium pr. kapacitet. Hvis du har større behov, er det den bedste fremgangsmåde at bruge en Premium-kapacitet med brugere, der har Pro-licenser.
Opret brugerdataflow med sikkerhed anvendt
Forestil dig, at du skal oprette dataflow til forbrug, men har sikkerhedskrav:
I dette scenarie har du sandsynligvis to typer arbejdsområder:
Back-end-arbejdsområder, hvor du udvikler dataflow og udvikler forretningslogik.
Brugerarbejdsområder, hvor du vil vise nogle dataflow eller tabeller til en bestemt gruppe af brugere til forbrug:
- Brugerarbejdsområdet indeholder sammenkædede tabeller, der peger på dataflowene i back end-arbejdsområdet.
- Brugerne har seeradgang til forbrugerarbejdsområdet og har ikke adgang til back end-arbejdsområdet.
- Når en bruger bruger Power BI Desktop til at få adgang til et dataflow i brugerarbejdsområdet, kan vedkommende se dataflowet. Men da dataflowet ser tomt ud i Navigator, vises de sammenkædede tabeller ikke.
Forstå sammenkædede tabeller
Sammenkædede tabeller er blot en markør til de oprindelige dataflowtabeller, og de nedarver kildens tilladelse. Hvis Power BI gjorde det muligt for den sammenkædede tabel at bruge destinationstilladelsen, kan alle brugere omgå kildetilladelsen ved at oprette en sammenkædet tabel på destinationen, der peger på kilden.
Løsning: Brug beregnede tabeller
Hvis du har adgang til Power BI Premium, kan du oprette en beregnet tabel i destinationen, der refererer til den sammenkædede tabel, som har en kopi af dataene fra den sammenkædede tabel. Du kan fjerne kolonner via projektioner og fjerne rækker via filtre. Brugeren med tilladelse til destinationsarbejdsområdet kan få adgang til data via denne tabel.
Afstamning for privilegerede personer viser også det arbejdsområde, der refereres til, og giver brugerne mulighed for at linke tilbage for at forstå det overordnede dataflow fuldt ud. For de brugere, der ikke er privilegerede, respekteres beskyttelse af personlige oplysninger stadig. Det er kun navnet på arbejdsområdet, der vises.
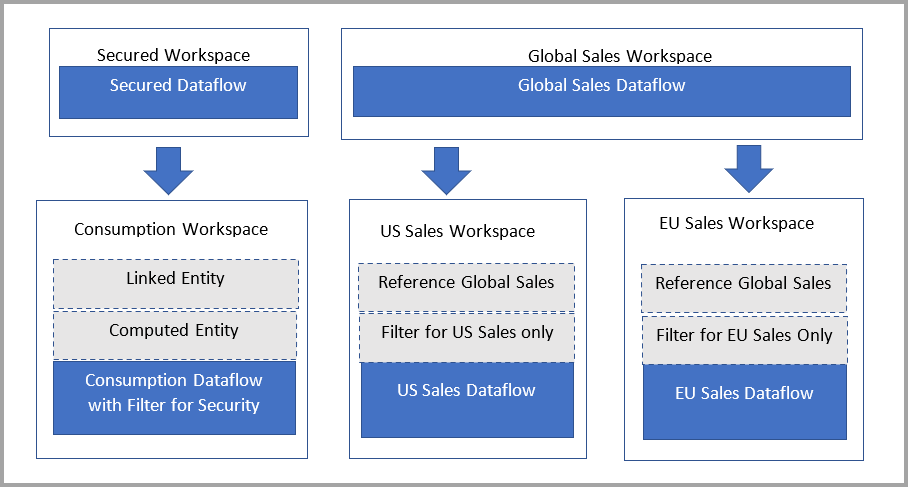
Følgende diagram illustrerer denne konfiguration. Til venstre er det arkitektoniske mønster. Til højre er et eksempel, der viser salgsdata opdelt og sikret efter område.
Reducer opdateringstiden for dataflow
Forestil dig, at du har et stort dataflow, men du vil bygge semantiske modeller ud af dette dataflow og reducere den tid, det tager at opdatere det. Opdateringer tager typisk lang tid at fuldføre fra datakilden til dataflow til den semantiske model. Lange opdateringer er svære at administrere eller vedligeholde.
Løsning: Brug tabeller med Aktivér indlæsning, der eksplicit er konfigureret til tabeller, der refereres til, og deaktiver ikke indlæsning
Power BI understøtter enkel orkestrering af dataflow som defineret i forståelsen og optimeringen af opdatering af dataflow. Hvis du vil drage fordel af orkestrering, kræver det eksplicit, at alle downstream-dataflows er konfigureret til at aktivere indlæsning.
Deaktivering af indlæsning er typisk kun relevant, når den belastning, der er ved at indlæse flere forespørgsler, annullerer fordelen ved det objekt, du udvikler.
Selvom deaktivering af indlæsning betyder, at Power BI ikke evaluerer den angivne forespørgsel, når den bruges som ingredienser, dvs. som refereres til i andre dataflow, betyder det også, at Power BI ikke behandler den som en eksisterende tabel, hvor vi kan angive en pointer til og udføre optimeringer af foldning og forespørgsel. I denne forstand er udførelse af transformationer som f.eks. en joinforbindelse eller fletning blot en joinforbindelse eller fletning af to datakildeforespørgsler. Sådanne handlinger kan have en negativ indvirkning på ydeevnen, fordi Power BI skal genindlæse den allerede beregnede logik fuldt ud igen og derefter anvende mere logik.
Hvis du vil forenkle forespørgselsbehandlingen af dit dataflow og sikre, at der udføres programoptimeringer, skal du aktivere indlæsning og sikre, at beregningsprogrammet i Power BI Premium-dataflow er angivet til standardindstillingen, som er Optimeret.
Aktivering af indlæsning giver dig også mulighed for at bevare den komplette visning af afstamning, fordi Power BI betragter et ikke-aktiveret indlæsningsdataflow som et nyt element. Hvis afstamning er vigtig for dig, skal du ikke deaktivere indlæsning for enheder eller dataflow, der er forbundet til andre dataflow.
Reducer opdateringstider for semantiske modeller
Forestil dig, at du har et stort dataflow, men du vil bygge semantiske modeller ud af det og reducere orkestrering. Opdateringer tager lang tid at fuldføre fra datakilden til dataflow til semantiske modeller, hvilket tilføjer øget ventetid.
Løsning: Brug DirectQuery-dataflow
DirectQuery kan bruges, når indstillingen for et arbejdsområdes forbedrede beregningsprogram (ECE) er konfigureret eksplicit til Til. Denne indstilling er nyttig, når du har data, der ikke behøver at blive indlæst direkte i en Power BI-model. Hvis du konfigurerer ECE til at være slået til for første gang, sker de ændringer, der tillader DirectQuery, under den næste opdatering. Du skal opdatere den, når du gør det muligt at foretage ændringer med det samme. Opdateringer af den indledende indlæsning af dataflow kan være langsommere, fordi Power BI skriver data til både lageret og et administreret SQL-program.
Ved hjælp af DirectQuery med dataflows kan du opsummere følgende forbedringer af dine Power BI- og dataflowprocesser:
- Undgå separate opdateringsplaner: DirectQuery opretter direkte forbindelse til et dataflow, hvilket fjerner behovet for at oprette en importeret semantisk model. Ved at bruge DirectQuery med dine dataflow betyder det derfor, at du ikke længere har brug for separate opdateringsplaner for dataflowet og den semantiske model for at sikre, at dine data synkroniseres.
- Filtrering af data: DirectQuery er nyttig til at arbejde på en filtreret visning af data i et dataflow. Hvis du vil filtrere data og på denne måde arbejde med et mindre undersæt af dataene i dit dataflow, kan du bruge DirectQuery (og ECE) til at filtrere dataflowdata og arbejde med det filtrerede undersæt, du har brug for.
Normalt handler DirectQuery med opdaterede data i din semantiske model med langsommere rapportydeevne sammenlignet med importtilstand. Overvej kun denne fremgangsmåde, når:
- Din use case kræver data med lav ventetid, der kommer fra dit dataflow.
- Dataflowdataene er store.
- En import ville være for tidskrævende.
- Du er villig til at bytte cachelagret ydeevne for opdaterede data.
Løsning: Brug dataflowconnectoren til at aktivere forespørgselsdelegering og trinvis opdatering til import
Den samlede dataflowconnector kan reducere evalueringstiden betydeligt for trin, der udføres over beregnede enheder, f.eks. udføre joinforbindelser, særskilte, filtre og gruppér efter-handlinger. Der er to specifikke fordele:
- Downstream-brugere, der opretter forbindelse til dataflowconnectoren i Power BI Desktop, kan drage fordel af en bedre ydeevne i oprettelsesscenarier, fordi den nye connector understøtter forespørgselsdelegering.
- Opdateringshandlinger for semantiske modeller kan også foldes til det forbedrede beregningsprogram, hvilket betyder, at selv trinvis opdatering fra en semantisk model kan foldes til et dataflow. Denne funktion forbedrer opdateringsydeevnen og reducerer muligvis ventetiden mellem opdateringscyklusser.
Hvis du vil aktivere denne funktion for et Hvilket som helst Premium-dataflow, skal du sørge for, at beregningsprogrammet eksplicit er angivet til Til. Brug derefter dataflowconnectoren i Power BI Desktop. Du skal bruge august 2021-versionen af Power BI Desktop eller nyere for at kunne drage fordel af denne funktion.
Hvis du vil bruge denne funktion til eksisterende løsninger, skal du have et Premium- eller Premium pr. bruger-abonnement. Du skal muligvis også foretage nogle ændringer af dit dataflow som beskrevet i Brug af det forbedrede beregningsprogram. Du skal opdatere eksisterende Power Query-forespørgsler for at bruge den nye connector ved at erstatte PowerBI.Dataflows i afsnittet Kilde med PowerPlatform.Dataflows.
Kompleks oprettelse af dataflow i Power Query
Forestil dig, at du har et dataflow, der er millioner af rækker med data, men du vil bygge kompleks forretningslogik og transformationer med det. Du vil følge bedste praksis for at arbejde med store dataflow. Du skal også bruge eksempelvisningerne af dataflowet for at kunne fungere hurtigt. Men du har mange kolonner og millioner af rækker med data.
Løsning: Brug skemavisning
Du kan bruge skemavisning, som er designet til at optimere dit flow, når du arbejder med handlinger på skemaniveau, ved at placere oplysningerne om din forespørgsels kolonne foran og i midten. Skemavisning giver kontekstafhængige interaktioner til at forme din datastruktur. Skemavisning indeholder også handlinger med lavere ventetid, fordi det kun kræver, at kolonnemetadataene beregnes, og ikke de komplette dataresultater.
Arbejd med større datakilder
Forestil dig, at du kører en forespørgsel på kildesystemet, men du ikke vil give direkte adgang til systemet eller demokratisere adgangen. Du planlægger at placere det i et dataflow.
Løsning 1: Brug en visning til forespørgslen, eller optimer forespørgslen
Ved at bruge en optimeret datakilde og forespørgsel er din bedste mulighed. Datakilden fungerer ofte bedst sammen med forespørgsler, der er beregnet til den. Power Query udvikler forespørgselsdelegeringsfunktioner for at delegere disse arbejdsbelastninger. Power BI indeholder også trinvise indikatorer i Power Query Online. Læs mere om typer af indikatorer i dokumentationen til trinvise indikatorer.
Løsning 2: Brug oprindelig forespørgsel
Du kan også bruge funktionen Value.NativeQuery() M. Du angiver EnableFolding=true i den tredje parameter. Oprindelig forespørgsel er dokumenteret på dette websted for Postgres-connectoren. Det fungerer også for SQL Server-connectoren.
Løsning 3: Bryd dataflowet i dataflow til indtagelse og forbrug for at drage fordel af ECE- og Linkede-enhederne
Ved at opdele et dataflow i separate dataflow for indtagelse og forbrug kan du drage fordel af ECE og linkede enheder. Du kan få mere at vide om dette mønster og andre i dokumentationen til bedste praksis.
Sørg for, at kunderne bruger dataflow, når det er muligt
Forestil dig, at du har mange dataflow, der tjener almindelige formål, f.eks. overensstemmende dimensioner som kunder, datatabeller, produkter og geografiske områder. Dataflow er allerede tilgængelige på båndet til Power BI. Ideelt set skal kunderne primært bruge de dataflow, du har oprettet.
Løsning: Brug anbefaling til at certificere og fremhæve dataflow
Hvis du vil vide mere om, hvordan godkendelse fungerer, skal du se Anbefaling: Fremhævning og certificering af Power BI-indhold.
Programmering og automatisering i Power BI-dataflow
Forestil dig, at du har forretningsmæssige krav til at automatisere import, eksport eller opdateringer og mere orkestrering og handlinger uden for Power BI. Du har nogle få muligheder for at aktivere dette, som beskrevet i følgende tabel.
| Skriv | Mekanisme |
|---|---|
| Brug PowerAutomate-skabelonerne. | Ingen kode |
| Brug automatiseringsscripts i PowerShell. | Automation-scripts |
| Byg din egen forretningslogik ved hjælp af API'erne. | Rest API |
Du kan få flere oplysninger om opdatering under Om og optimering af opdatering af dataflow.
Sørg for at beskytte dataaktiver downstream
Du kan bruge følsomhedsmærkater til at anvende en dataklassificering og eventuelle regler, du har konfigureret for downstream-elementer, der opretter forbindelse til dine dataflow. Hvis du vil vide mere om følsomhedsmærkater, skal du se følsomhedsmærkater i Power BI. Hvis du vil gennemse nedarvning, skal du se Nedarvning af følsomhedsmærkat i Power BI.
Multi-geo-understøttelse
Mange kunder har i dag et behov for at opfylde datasuverænitet og krav til opholdstilladelse. Du kan fuldføre en manuel konfiguration af dit dataflowarbejdsområde for at være multi-geo.
Dataflow understøtter multi-geo, når de bruger funktionen bring-your-own-storage-account. Denne funktion er beskrevet i Konfiguration af dataflowlager til at bruge Azure Data Lake Gen 2. Arbejdsområdet skal være tomt, før det vedhæftes til denne funktion. Med denne specifikke konfiguration kan du gemme dataflowdata i bestemte geografiske områder efter eget valg.
Sørg for at beskytte dataaktiver bag et virtuelt netværk
Mange kunder har i dag et behov for at sikre dine dataaktiver bag et privat slutpunkt. Det gør du ved at bruge virtuelle netværk og en gateway til at forblive kompatibel. I følgende tabel beskrives den aktuelle understøttelse af virtuelle netværk, og det forklares, hvordan du bruger dataflow til at forblive kompatibel og beskytte dine dataaktiver.
| Scenarie | Status |
|---|---|
| Læs datakilder for virtuelle netværk via en gateway i det lokale miljø. | Understøttes via en gateway i det lokale miljø |
| Skriv data til en følsomhedsmærkatkonto bag et virtuelt netværk ved hjælp af en gateway i det lokale miljø. | Understøttes endnu ikke |
Relateret indhold
Følgende artikler indeholder flere oplysninger om dataflow og Power BI: